Всем добра! Ну вот и подошло время для очередного нашего курса по Девопсу. Наверное, это один из самых стабильных и эталонных курсов, но при этом и самый разнообразный по обучающимся, так как ни одна группа ещё не была похожа на другую: то в одной разработчики почти полностью, то в следующей инженеры, то админы и так далее. А так же это значит, что пришла пора интересных и полезных материалов, а так же онлайн-встреч.
Поехали.
В этой статье собраны рекомендации по запуску production-grade Kubernetes кластера в условиях on-premise дата-центра или периферийных локаций (edge location).
Что значит production-grade?
Если коротко, production-grade означает предвосхищение ошибок и подготовку восстановления с минимальным количеством проблем и отсрочек.

Эта статья посвящена on-premise развертыванию Kubernetes на гипервизоре или bare-metal платформе, с учетом ограниченного количества ресурсов поддержки в сравнении с увеличением основных публичных облаков. Тем не менее, часть этих рекомендаций может быть полезна и для публичного облака, если бюджет ограничивает выбранные ресурсы.
Развертывание однонодового bare-metal Minikube может быть простым и дешевым процессом, но это не production-grade. И наоборот, вам не удастся достичь уровня Google с Borg в оффлайн-магазине, филиале или периферийной локации, хотя вряд ли вам это и нужно.
В этой статье описаны советы по достижении развертывания Kubernetes производственного уровня, даже в ситуации ограничения ресурсов.
Важные компоненты в Kubernetes кластере
Перед тем как углубиться в детали, важно понять общую архитектуру Kubernetes.
Кластер Kubernetes — высоко распределенная система на базе управляющего уровня (control plane) и архитектуре кластеризованных воркер-нод, как показано ниже:
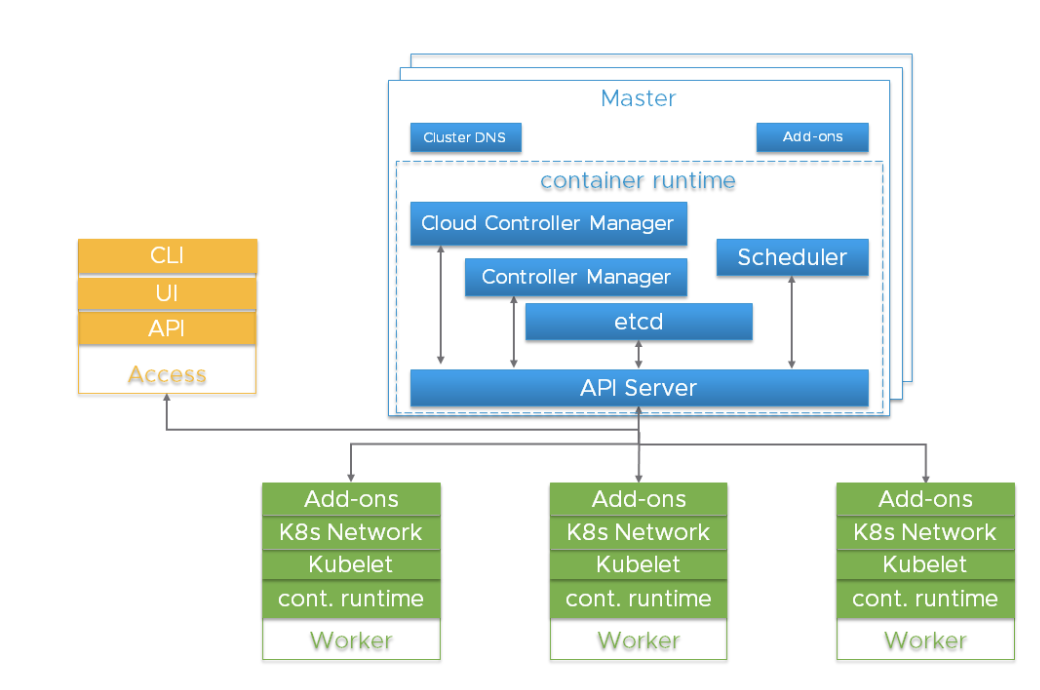
Обычно компоненты API Server, Controller Manager и Scheduler расположены в нескольких инстансах нод управляющего уровня (его называют Master). Master-ноды обычно также включают в себя etcd, однако существуют крупные и высокодоступные сценарии, требующие запуска etcd на независимых хостах. Компоненты могут быть запущены как контейнеры и, опционально, под наблюдением Kubernetes, то есть работать как статические поды.
Для высокой доступности используются избыточные инстансы этих компонентов. Значимость и необходимый уровень избыточности может разниться.
Риски этих компонентов включают в себя аппаратные сбои, программные баги, плохие обновления, человеческие ошибки, сетевые перебои и перегрузку системы приводящие к исчерпанию ресурсов. Избыточность может снизить воздействие этих опасностей. В дополнении, благодаря функциям платформы гипервизора (ресурсное планирование, высокая доступность) можно преумножить результаты использовании операционной системы Linux, Kubernetes и среды запуска контейнеров (container runtime).
API Server использует несколько инстансов балансировщика нагрузки для достижения масштабируемости и доступности. Балансировщик нагрузки — важный компонент для высокой доступности. Несколько A-записей DNS API сервера могут послужить альтернативой при отсутствии балансировщика.
kube-scheduler и kube-controller-manager участвуют в процессе выбора лидера вместо использования балансировщика нагрузок. Поскольку cloud-controller-manager используется для определенных типов инфраструктуры хостинга, реализация которых может различаться, их мы обсуждать не будем — только обозначим, что они являются компонентом управляющего уровня.
Поды, запущенные на воркере Kubernetes, управляются kubelet-агентом. Каждый инстанс воркера запускает kubelet-агента и CRI-совместимую среду запуска контейнеров. Сам Kubernetes спроектирован для мониторинга и восстановления после сбоев воркер-нод. Но для функций критических нагрузок, управления ресурсами гипервизора и изоляции нагрузок может применяться для улучшения доступности и повышения предсказуемости их работы.
etcd
etcd — это постоянное хранилище для всех объектов Kubernetes. Доступность и восстанавливаемость etcd кластера должна быть первоочередной задачей при развертывании production-grade Kubernetes.
etcd кластер, состоящий из пяти нод — лучший вариант, если вы можете его позволить. Почему? Потому что вы сможете обслуживать один, и при этом все равно выдержать сбой. Кластер из трех нод — минимум, который мы можем рекомендовать, для production-grade сервиса, даже если доступен только один хост-гипервизор. Более семи нод также не рекомендуется, за исключением очень больших инсталляций, охватывающих несколько зон доступности.
Минимальные рекомендации для хостинга ноды etcd кластера — 2GB RAM и 8GB SSD жесткого диска. Обычно, 8GB RAM и 20GB на жестком диске достаточно. Производительность диска влияет на время восстановления ноды после сбоя. Ознакомьтесь, чтобы узнать детали.
В особых случаях подумайте о нескольких etcd кластерах
Для очень больших Kubernetes кластеров, задумайтесь об использовании отдельного etcd кластера для событий Kubernetes, чтобы слишком большой количество событий не повлияло на основной Kubernetes API сервис. При использовании сети Flannel, конфигурация сохраняется в etcd, и требования версии могут отличаться от Kubernetes. Это может усложнить резервное копирование etcd, поэтому советуем использовать отдельный etcd кластер специально для flannel.
Однохостовое развертывание
Список рисков доступности включает в себя оборудование, программное обеспечение и человеческий фактор. Если вы ограничены одним хостом, использование избыточного хранилища, памяти с коррекцией ошибок и двойного источник питания может улучшить защищенность от сбоев оборудования. Запуск гипервизора на физическом хосте позволяет использовать избыточные компоненты ПО и добавляет операционные преимущества, связанные с развертыванием, обновлением и контролем использования ресурсов. Даже в стрессовых ситуациях поведение остается повторяемым и предсказуемым. Например, даже если вы можете себе позволить только запуск синглтонов с мастер-сервисов, они должны быть защищены от перегрузки и истощения ресурсов, конкурируя с рабочей нагрузкой вашего приложения. Гипервизор может быть более эффективен и прост в использовании, чем настройка приоритетов в планировщике Linux, cgroups, флагов Kubernetes и т.д.
Вы можете развернуть три виртуальных машины etcd, если это позволяют ресурсы на хосте. Каждая из ВМ должна поддерживаться отдельным физическим устройством хранения или использовать отдельные части хранилища при помощи избыточности (мирроринг, RAID и тд.).
Двойные избыточные инстансы API сервера, планировщика и менеджера контроллера являются следующим апгрейдом, если у вашего единственного хоста хватает для этого ресурсов.
Варианты однохостового развертывания, от наименее подходящих для продакшена к наиболее
Развертывание на два хоста
С двумя хостами проблемы хранилища etcd аналогичны однохостовому варианту — вам необходима избыточность. Предпочтительно запускать три encd инстанса. Может показаться неинтуитивным, но лучше сконцентрировать все etcd ноды на одном хосте. Вы не увеличите надежность, разделив их на 2+1 между двумя хостами — потеря ноды с большинством encd инстансов ведет к перебою, независимо от того является ли большинством 2 или 3. Если хосты неодинаковые, поместите etcd кластер целиком на более надежный из них.
Рекомендуется запуск избыточных API серверов, kube-scheduler’ов и kube-controller-manager’ов. Они должны быть разделены между хостами для минимизации рисков сбоев среды запуска контейнеров, операционной системы и оборудования.
Запуск слоя гипервизора на физических хостах позволит работать с избыточными компонентами программ, обеспечивая управление потреблением ресурсов. А также обладает операционным преимуществом планового обслуживания.
Варианты развертывания на два хоста, от наименее подходящих для продакшена к наиболее
Развертывание на три (и более) хоста
Переход к бескомпромиссному production-grade сервису. Рекомендуем разделить etcd между тремя хостами. Один сбой оборудования уменьшит объем возможных рабочих нагрузок приложения, но не обернется полным выходом сервиса из строя.
Очень большие кластеры потребуют большего количества инстансов.
Запуск слоя гипервизора обеспечивает эксплуатационные преимущества и улучшенную изолированность рабочих нагрузок приложения. Это выходит за рамки статьи, но на уровне трех и более хостов, могут быть доступны улучшенные функции (кластеризованное избыточное разделяемое хранилище, управление ресурсами с динамическим балансировщиком нагрузки, автоматизированный мониторинг состояния с живой миграцией и аварийным переключением).
Варианты развертывания на три (и более) хоста от наименее подходящих для продакшена к наиболее
Настройка конфигурации Kubernetes
Ноды Master и Worker должны быть защищены от перегрузки и истощения ресурсов. Функции гипервизора могут использоваться для изолирования критически важных компонентов и резервирования ресурсов. Существуют также настройки конфигурации Kubernetes, которые могут тормозить такие вещи, как скорость вызовов API. Некоторые установочные комплекты и коммерческие дистрибутивы заботятся об этом, но если вы выполняете самостоятельное развертывание Kubernetes, настройки по умолчанию могут оказаться неподходящими, особенно, при малых ресурсах или слишком большом кластере.
Потребление ресурсов управляемым уровнем коррелирует с количеством подов и показателем оттока подов. Очень большие и очень маленькие кластеры получат преимущество от измененных настроек замедления запросов kube-apiserver и памяти.
На нодах воркера должен быть настроен Node Allocatable на основе разумной поддерживаемой плотности нагрузки на каждую ноду. Пространства имен могут быть созданы для разделения кластера воркер-ноды на несколько виртуальных кластеров c квотами для CPU и памяти.
Безопасность
У каждого кластера Kubernetes есть корневой Центр Сертификации (Certificate Authority, CA). The Controller Manager, API Server, Scheduler, kubelet client, kube-proxy и сертификаты администратора должны быть сгенерированы и установлены. Если вы пользуетесь инструментом или дистрибутивом установки, то возможно вам не придется с этим разбираться самостоятельно. Ручной процесс описывается здесь. Вы должны быть готовы переустановить сертификаты в случае расширения или замены нод.
Поскольку Kubernetes полностью управляется API, крайне важно контролировать и ограничивать список тех, кто имеет доступ к кластеру. Параметры шифрования и аутентификации рассмотрены в этой документации.
Рабочие нагрузки приложения в Kubernetes основаны на образах контейнера. Вам необходимо, чтобы источник и содержимое этих образов были надежными. Почти всегда это означает, что вы будете хостить образа контейнера в локальном репозитории. Использование образов из публичного интернета может вызвать проблемы надежности и безопасности. Необходимо выбрать репозиторий, обладающий поддержкой подписи образа, сканированием безопасности, контролем доступа к отправке и загрузке образов и логированием активности.
Процессы должны быть настроены для поддержки применения обновлений прошивки хоста, гипервизора, ОС6, Kubernetes и других зависимостей. Мониторинг версий необходим для поддержки аудита.
Рекомендации:
Kubernetes объекты типа secret подходят для хранения небольших объемов конфиденциальных данных. Они хранятся в etcd. Их можно смело использовать для хранения учетных данных Kubernetes API, но бывают случаи, когда для рабочая нагрузка или расширение самого кластера требуют более полнофункционального решения. Проект HashiCorp Vault — популярное решение, если вам нужно больше, чем могут обеспечить встроенные secret объекты.
Аварийное восстановление и Резервное копирование

Реализация избыточности через использование нескольких хостов и ВМ помогает уменьшить количество некоторых типов сбоев. Но такие сценарии, как стихийное бедствие, плохой апдейт, хакерская атака, баги ПО или человеческая ошибка, все еще могут обернуться сбоями.
Критически важная часть производственного развертывания — ожидание необходимости восстановления в будущем.
Также стоит отметить, что часть ваших вложений в дизайн, документацию и автоматизацию процесса восстановления может быть повторно использована, если потребуются крупномасштабные реплицированные развертывания на нескольких площадках.
Среди элементов аварийного восстановления стоит отметить бэкапы (и возможно реплики), замены, запланированный процесс, людей, которые будут выполнять этот процесс, и регулярное обучение. Частые тестовые упражнения и принципы Chaos Engineering могут быть использованы для проверки вашей готовности.
Из-за требований доступности возможно придется хранить локальные копии ОС, компонентов Kubernetes и образов контейнера, чтобы позволить восстановление даже при Интернет сбое. Возможность деплоя замещающих хостов и нод в ситуации “физической изоляции” улучшает безопасность и увеличивает скорость развертывания.
Все объекты Kubernetes хранятся в etcd. Периодическое резервное копирование данных etcd-кластера — важный элемент в восстановление кластеров Kubernetes при аварийных сценариях, например при потере всех мастер-нод.
Резервное копирование etcd кластера может быть выполнено с помощью встроенного в etcd механизма снапшотов и копирования результата на хранение в другой домен сбоя. Файлы снимков содержат все состояния Kubernetes и критически важную информацию. Зашифруйте файлы снимков, чтобы защитить конфиденциальные данные Kubernetes.
Имейте в виду, что некоторые расширения Kubernetes могут хранить состояния в отдельных etcd кластерах, постоянных томах или с помощью какого-то другого механизма. Если эти состояния критически важны, у них должна быть резервная копия и план восстановления.
Но некоторые важные состояния хранятся вне etcd. Сертификаты, образы контейнера, другие настройки и состояния, связанные с операциями, могут управляться автоматическим инструментом установки/обновления. Даже если эти файлы можно сгенерировать заново, резервная копия или реплика ускорят восстановление после сбоя. Задумайтесь о необходимости резервной копии и плана восстановления для следующих объектов:
Предложения для производственных нагрузок
Anti-affinity спецификации могут быть использованы для разделения кластеризованных сервисов между резервными хостами. Но в данном случае настройки используются, только если под запланирован. Это значит, что Kubernetes может перезапустить вышедшую из строя ноду вашего кластеризованного приложения, но не обладает встроенным механизмом для повторной балансировки после сбоя. Эта тема заслуживает отдельной статьи, но дополнительная логика может быть полезна для достижения оптимального размещения рабочих нагрузок после того, как хост или воркер-нода восстанавливаются или расширяются. Функция Приоритезации и Вытеснения Подов может использоваться для выбора желаемой сортировки в случае недостатка ресурсов, вызванного сбоем.
В случае stateful-сервисов, внешние смонтированные тома — стандарт рекомендаций Kubernetes для некластеризованных сервисов (например, для типичной SQL базы данных). Сейчас, снапшоты внешних томов, управляемые Kubernetes, находятся в категории roadmap feature request, и, скорее всего, связаны с интеграцией Container Storage Interface (CSI). Таким образом, создание резервных копий такого сервиса потребует внутри-подовых действий, зависящих от конкретного приложения, что выходит за рамки этой статьи. Поэтому, пока мы ждем улучшения поддержки Kubernetes для воркфлоу снапшотов и резервного копирования, стоит задуматься о запуске сервиса базы данных не в контейнере, а в виртуальный машине, и открыть ее Kubernetes нагрузкам.
Кластеризованные stateful-сервисы (например, Cassandra) могут получить преимущество за счет разделения между хостами, используя локальные постоянные тома, если ресурсы это позволяют. Для этого потребуются развертывания нескольких воркер-нод Kubernetes (могут быть ВМ на гипервизор-хостах) для сохранения кворума в точке отказа.
Другие предложения
Логи и метрики (если собирать и хранить их) полезны для диагностики сбоев, но с учетом разнообразия доступных технологий, мы не будем их рассматривать в этой статье. При наличии подключения к интернету, желательно хранить логи и метрики снаружи, централизованно.
В производственном развертывании должны использоваться инструменты автоматической установки, настройки и обновления (например, Ansible, BOSH, Chef, Juju, kubeadm, Puppet и т.д). Ручной процесс слишком трудоемкий и сложный для масштабирования, в нем легко совершить ошибки и столкнуться с проблемами повторяемости. Сертифицированные дистрибутивы, вероятно, будут включать в себя средство для сохранения настроек при обновлении, но, если же вы используете собственный тулчейн для установки и настройки, то хранение, бэкап и восстановление конфигурационных артефактов имеет огромное значение. Стоит задуматься об использовании системы контроля версии, вроде Git, для хранения компонентов и настроек развертывания.
Восстановление
Ранбуки, в которых задокументированы процессы восстановления, должны быть протестированы и сохранены оффлайн — возможно даже распечатаны. Когда сотрудника вызывают в 2 часа ночи пятницы, импровизация — не лучший вариант. Лучше выполнить все пункты из запланированного и протестированного чеклиста — к которому есть доступ как у сотрудников в офисе, так и у удаленных.
Финальные мысли

Покупка билета на самолет коммерческих авиалиний — простой и безопасный процесс. Но если вы летите в отдаленное место с короткой взлетно-посадочной полосой, коммерческий полет на Airbus A320 — неподходящий вариант. Это не значит, что авиаперелет вообще не должен рассматриваться. Это означает только то, что необходимы компромиссы.
В контексте авиации, поломка двигателя в однодвигательном судне означает крушение. С двумя двигателями, минимум, будет больше возможностей решить, где произойдет крушение. Kubernetes на малом количестве хостов аналогичен, и если ваш бизнес-кейс оправдывает, стоит задуматься об увеличении флота, состоящего из больших и малых машин (например, FedEx, Amazon).
При проектировании production-grade решения Kubernetes у вас есть много возможностей и вариантов. Простая статья не может дать все ответы и не имеет понятия о именно ваших приоритетах. Тем не менее, надеемся, что она предоставила список вещей, о которых стоит подумать, а также некоторые полезные рекомендации. Есть варианты, которые остались нерассмотренными (например, запуск компонентов Kubernetes с помощью self-hosting, а не статических подов). Возможно о них стоит поговорить в следующих статьях, при наличии достаточного интереса. Кроме того, из-за высокой скорости улучшения Kubernetes, если ваша поисковая система нашла эту статью после 2019 года, некоторые ее материалы могли уже сильно устареть.
THE END
Как всегда ждём ваши вопросы и комментарии и тут, и можно зайти на День открытых дверей к Александру Титову.
Поехали.
В этой статье собраны рекомендации по запуску production-grade Kubernetes кластера в условиях on-premise дата-центра или периферийных локаций (edge location).
Что значит production-grade?
- Безопасная установка;
- Управление развертыванием осуществляется с помощью повторяющегося и записанного процесса;
- Работа предсказуема и последовательна;
- Можно безопасно проводить обновления и настройку;
- Для обнаружения и диагностики ошибок и нехватки ресурсов есть логирование и мониторинг;
- Сервис обладает достаточной “высокой доступностью” с учетом имеющихся ресурсов, включая ограничения в деньгах, физическом пространстве, мощности и тд.
- Процесс восстановления доступен, задокументирован и протестирован для использования в случае сбоев.
Если коротко, production-grade означает предвосхищение ошибок и подготовку восстановления с минимальным количеством проблем и отсрочек.
Эта статья посвящена on-premise развертыванию Kubernetes на гипервизоре или bare-metal платформе, с учетом ограниченного количества ресурсов поддержки в сравнении с увеличением основных публичных облаков. Тем не менее, часть этих рекомендаций может быть полезна и для публичного облака, если бюджет ограничивает выбранные ресурсы.
Развертывание однонодового bare-metal Minikube может быть простым и дешевым процессом, но это не production-grade. И наоборот, вам не удастся достичь уровня Google с Borg в оффлайн-магазине, филиале или периферийной локации, хотя вряд ли вам это и нужно.
В этой статье описаны советы по достижении развертывания Kubernetes производственного уровня, даже в ситуации ограничения ресурсов.
Важные компоненты в Kubernetes кластере
Перед тем как углубиться в детали, важно понять общую архитектуру Kubernetes.
Кластер Kubernetes — высоко распределенная система на базе управляющего уровня (control plane) и архитектуре кластеризованных воркер-нод, как показано ниже:
Обычно компоненты API Server, Controller Manager и Scheduler расположены в нескольких инстансах нод управляющего уровня (его называют Master). Master-ноды обычно также включают в себя etcd, однако существуют крупные и высокодоступные сценарии, требующие запуска etcd на независимых хостах. Компоненты могут быть запущены как контейнеры и, опционально, под наблюдением Kubernetes, то есть работать как статические поды.
Для высокой доступности используются избыточные инстансы этих компонентов. Значимость и необходимый уровень избыточности может разниться.
| Роли | Последствия потери | Рекомендуемые инстансы | |
|---|---|---|---|
| etcd | Поддерживает состояние всех объектов Kubernetes | Катастрофические потери хранилища. Потеря большей части = Kubernetes теряет управляющий уровень, API Server зависит от etcd, read-only вызовы API, которым не требуется кворум, как и уже созданные рабочие нагрузки, могут продолжать работать. | нечетное число, 3+ |
| API Server | Предоставляет API для внешнего и внутреннего использования | Невозможно остановить, запустить, обновить новые поды. Scheduler и Controller Manager зависят от API Server. Нагрузки продолжаются, если не зависят от вызовов API (операторы, кастомные контроллеры, CRD и тд) | 2+ |
| kube-scheduler | Размещает поды на нодах | Поды невозможно размещать, приоритизировать и перемещаться между ними. | 2+ |
| kube-controller-manager | Управляет многими контроллерами | Основные контуры управления, отвечающие за состояние, прекращают работать. Ломается интеграция in-tree облачного провайдера. | 2+ |
| cloud-controller-manager (CCM) | Интеграция out-of-tree облачных провайдеров | Ломается интеграция облачного провайдера | 1 |
| Дополнения (например, DNS) | Различные | Различные | Зависит от дополнения (например, 2+ для DNS) |
Риски этих компонентов включают в себя аппаратные сбои, программные баги, плохие обновления, человеческие ошибки, сетевые перебои и перегрузку системы приводящие к исчерпанию ресурсов. Избыточность может снизить воздействие этих опасностей. В дополнении, благодаря функциям платформы гипервизора (ресурсное планирование, высокая доступность) можно преумножить результаты использовании операционной системы Linux, Kubernetes и среды запуска контейнеров (container runtime).
API Server использует несколько инстансов балансировщика нагрузки для достижения масштабируемости и доступности. Балансировщик нагрузки — важный компонент для высокой доступности. Несколько A-записей DNS API сервера могут послужить альтернативой при отсутствии балансировщика.
kube-scheduler и kube-controller-manager участвуют в процессе выбора лидера вместо использования балансировщика нагрузок. Поскольку cloud-controller-manager используется для определенных типов инфраструктуры хостинга, реализация которых может различаться, их мы обсуждать не будем — только обозначим, что они являются компонентом управляющего уровня.
Поды, запущенные на воркере Kubernetes, управляются kubelet-агентом. Каждый инстанс воркера запускает kubelet-агента и CRI-совместимую среду запуска контейнеров. Сам Kubernetes спроектирован для мониторинга и восстановления после сбоев воркер-нод. Но для функций критических нагрузок, управления ресурсами гипервизора и изоляции нагрузок может применяться для улучшения доступности и повышения предсказуемости их работы.
etcd
etcd — это постоянное хранилище для всех объектов Kubernetes. Доступность и восстанавливаемость etcd кластера должна быть первоочередной задачей при развертывании production-grade Kubernetes.
etcd кластер, состоящий из пяти нод — лучший вариант, если вы можете его позволить. Почему? Потому что вы сможете обслуживать один, и при этом все равно выдержать сбой. Кластер из трех нод — минимум, который мы можем рекомендовать, для production-grade сервиса, даже если доступен только один хост-гипервизор. Более семи нод также не рекомендуется, за исключением очень больших инсталляций, охватывающих несколько зон доступности.
Минимальные рекомендации для хостинга ноды etcd кластера — 2GB RAM и 8GB SSD жесткого диска. Обычно, 8GB RAM и 20GB на жестком диске достаточно. Производительность диска влияет на время восстановления ноды после сбоя. Ознакомьтесь, чтобы узнать детали.
В особых случаях подумайте о нескольких etcd кластерах
Для очень больших Kubernetes кластеров, задумайтесь об использовании отдельного etcd кластера для событий Kubernetes, чтобы слишком большой количество событий не повлияло на основной Kubernetes API сервис. При использовании сети Flannel, конфигурация сохраняется в etcd, и требования версии могут отличаться от Kubernetes. Это может усложнить резервное копирование etcd, поэтому советуем использовать отдельный etcd кластер специально для flannel.
Однохостовое развертывание
Список рисков доступности включает в себя оборудование, программное обеспечение и человеческий фактор. Если вы ограничены одним хостом, использование избыточного хранилища, памяти с коррекцией ошибок и двойного источник питания может улучшить защищенность от сбоев оборудования. Запуск гипервизора на физическом хосте позволяет использовать избыточные компоненты ПО и добавляет операционные преимущества, связанные с развертыванием, обновлением и контролем использования ресурсов. Даже в стрессовых ситуациях поведение остается повторяемым и предсказуемым. Например, даже если вы можете себе позволить только запуск синглтонов с мастер-сервисов, они должны быть защищены от перегрузки и истощения ресурсов, конкурируя с рабочей нагрузкой вашего приложения. Гипервизор может быть более эффективен и прост в использовании, чем настройка приоритетов в планировщике Linux, cgroups, флагов Kubernetes и т.д.
Вы можете развернуть три виртуальных машины etcd, если это позволяют ресурсы на хосте. Каждая из ВМ должна поддерживаться отдельным физическим устройством хранения или использовать отдельные части хранилища при помощи избыточности (мирроринг, RAID и тд.).
Двойные избыточные инстансы API сервера, планировщика и менеджера контроллера являются следующим апгрейдом, если у вашего единственного хоста хватает для этого ресурсов.
Варианты однохостового развертывания, от наименее подходящих для продакшена к наиболее
| Тип | Характеристики | Результат |
|---|---|---|
| Синглтон etcd и мастер-компоненты. | Домашняя лаборатория, совсем не production-grade. Несколько единых точек отказа (Single Point of Failure, SPOF). Восстановление медленное, а при потере хранилища отсутствует вовсе. | |
| Улучшение избыточности хранилища | etcd синглтон и мастер-компоненты, etcd хранилище — избыточно. | Как минимум, вы сможете восстановиться после сбоя устройства хранения. |
| Избыточность управляемого уровня | Нет гипервизора, несколько инстансов компонентов управляемого уровня в статических подах. | Появилась защита от багов ПО, но ОС и среда запуска контейнеров все еще единые точки отказа с разрушительными обновлениями. |
| Добавление гипервизора | Запуск трех избыточных инстансов управляемого уровня в ВМ. | Появилась защита от багов ПО и человеческой ошибки и операционное преимущество в установке, управлении ресурсами, мониторинге и безопасности. Обновления ОС и среды запуска контейнеров менее разрушительны. Гипервизор — единственная единая точка отказа. |
Развертывание на два хоста
С двумя хостами проблемы хранилища etcd аналогичны однохостовому варианту — вам необходима избыточность. Предпочтительно запускать три encd инстанса. Может показаться неинтуитивным, но лучше сконцентрировать все etcd ноды на одном хосте. Вы не увеличите надежность, разделив их на 2+1 между двумя хостами — потеря ноды с большинством encd инстансов ведет к перебою, независимо от того является ли большинством 2 или 3. Если хосты неодинаковые, поместите etcd кластер целиком на более надежный из них.
Рекомендуется запуск избыточных API серверов, kube-scheduler’ов и kube-controller-manager’ов. Они должны быть разделены между хостами для минимизации рисков сбоев среды запуска контейнеров, операционной системы и оборудования.
Запуск слоя гипервизора на физических хостах позволит работать с избыточными компонентами программ, обеспечивая управление потреблением ресурсов. А также обладает операционным преимуществом планового обслуживания.
Варианты развертывания на два хоста, от наименее подходящих для продакшена к наиболее
| Тип | Характеристики | Результат |
|---|---|---|
| Два хоста, без избыточного хранилища. Синглтон etcd и мастер компоненты на одном хосте. | etcd — единая точка отказа, нет смысла запускать два на других мастер-сервисах. Разделение между двумя хостами увеличивает риск сбоев управляемого уровня. Потенциальное преимущество изоляции ресурсов за счет запуска управляемого уровня на одном хосте и рабочих нагрузок приложения на другом. При потере хранилища восстановление отсутствует. | |
| Улучшение избыточности хранилища | Синглтон etcd и мастер компоненты на одном хосте, etcd хранилище избыточно. | Как минимум, вы сможете восстановиться после сбоя устройства хранения. |
| Избыточность управляемого уровня | Нет гипервизора, несколько инстансов компонентов управляемого уровня в статических подах. etcd кластер на одном хосте, другие компоненты управляемого уровня разделены. | Сбой оборудования, обновление прошивки, операционной системы и среды запуска контейнеров на хосте без etcd менее разрушительны. |
| Добавление гипервизора на оба хоста | В виртуальных машинах запущены три избыточных компонента управляемого уровня, etcd кластер на одном хосте, компоненты управляемого уровня разделены. Рабочие нагрузки приложения могут находиться на обеих нодах ВМ. | Улучшенная изолированность нагрузок приложения. Обновления операционной системы и среды запуска контейнеров менее разрушительны. Плановое обслуживание оборудования/прошивки становится неразрушительным, если гипервизор поддерживает ВМ-миграцию. |
Развертывание на три (и более) хоста
Переход к бескомпромиссному production-grade сервису. Рекомендуем разделить etcd между тремя хостами. Один сбой оборудования уменьшит объем возможных рабочих нагрузок приложения, но не обернется полным выходом сервиса из строя.
Очень большие кластеры потребуют большего количества инстансов.
Запуск слоя гипервизора обеспечивает эксплуатационные преимущества и улучшенную изолированность рабочих нагрузок приложения. Это выходит за рамки статьи, но на уровне трех и более хостов, могут быть доступны улучшенные функции (кластеризованное избыточное разделяемое хранилище, управление ресурсами с динамическим балансировщиком нагрузки, автоматизированный мониторинг состояния с живой миграцией и аварийным переключением).
Варианты развертывания на три (и более) хоста от наименее подходящих для продакшена к наиболее
| Тип | Характеристики | Результат |
|---|---|---|
| Три хоста. Инстанс etcd на каждой ноде. Мастер-компоненты на каждой ноде. | Потеря ноды снижает производительность, но не ведет к падению Kubernetes. Сохраняется возможность восстановления. | |
| Добавление гипервизора на хосты | В виртуальных машинах на трех хостах запущены etcd, API сервер, планировщики, менеджер контроллера. Рабочие нагрузки запущены в ВМ на каждом хосте. | Добавлена защита от багов ОС/среды запуска контейнеров/ПО и человеческих ошибок. Эксплуатационные преимущества по установке, обновлению, управлению ресурсами, мониторингу и безопасности. |
Настройка конфигурации Kubernetes
Ноды Master и Worker должны быть защищены от перегрузки и истощения ресурсов. Функции гипервизора могут использоваться для изолирования критически важных компонентов и резервирования ресурсов. Существуют также настройки конфигурации Kubernetes, которые могут тормозить такие вещи, как скорость вызовов API. Некоторые установочные комплекты и коммерческие дистрибутивы заботятся об этом, но если вы выполняете самостоятельное развертывание Kubernetes, настройки по умолчанию могут оказаться неподходящими, особенно, при малых ресурсах или слишком большом кластере.
Потребление ресурсов управляемым уровнем коррелирует с количеством подов и показателем оттока подов. Очень большие и очень маленькие кластеры получат преимущество от измененных настроек замедления запросов kube-apiserver и памяти.
На нодах воркера должен быть настроен Node Allocatable на основе разумной поддерживаемой плотности нагрузки на каждую ноду. Пространства имен могут быть созданы для разделения кластера воркер-ноды на несколько виртуальных кластеров c квотами для CPU и памяти.
Безопасность
У каждого кластера Kubernetes есть корневой Центр Сертификации (Certificate Authority, CA). The Controller Manager, API Server, Scheduler, kubelet client, kube-proxy и сертификаты администратора должны быть сгенерированы и установлены. Если вы пользуетесь инструментом или дистрибутивом установки, то возможно вам не придется с этим разбираться самостоятельно. Ручной процесс описывается здесь. Вы должны быть готовы переустановить сертификаты в случае расширения или замены нод.
Поскольку Kubernetes полностью управляется API, крайне важно контролировать и ограничивать список тех, кто имеет доступ к кластеру. Параметры шифрования и аутентификации рассмотрены в этой документации.
Рабочие нагрузки приложения в Kubernetes основаны на образах контейнера. Вам необходимо, чтобы источник и содержимое этих образов были надежными. Почти всегда это означает, что вы будете хостить образа контейнера в локальном репозитории. Использование образов из публичного интернета может вызвать проблемы надежности и безопасности. Необходимо выбрать репозиторий, обладающий поддержкой подписи образа, сканированием безопасности, контролем доступа к отправке и загрузке образов и логированием активности.
Процессы должны быть настроены для поддержки применения обновлений прошивки хоста, гипервизора, ОС6, Kubernetes и других зависимостей. Мониторинг версий необходим для поддержки аудита.
Рекомендации:
- Усильте настройки безопасности по умолчанию для компонентов управляемого уровня (например, блокировка воркер нод);
- Используйте Политику Безопасности Подов;
- Задумайтесь об интеграции NetworkPolicy, доступной для вашего сетевого решения, включая выполнение отслеживания, мониторинга и устранения неполадок;
- Используйте RBAC для принятия решений об авторизации;
- Задумайтесь о физической безопасности, особенно при развертывании в периферийных или удаленных локациях, которые могут остаться без наблюдения. Добавьте шифрование хранилища, чтобы ограничить последствия кражи устройств, и защиту от подключения вредоносных устройств, например, USB-ключей;
- Защитите текстовые учетные данные облачного провайдера (ключи доступа, токены, пароли и тд).
Kubernetes объекты типа secret подходят для хранения небольших объемов конфиденциальных данных. Они хранятся в etcd. Их можно смело использовать для хранения учетных данных Kubernetes API, но бывают случаи, когда для рабочая нагрузка или расширение самого кластера требуют более полнофункционального решения. Проект HashiCorp Vault — популярное решение, если вам нужно больше, чем могут обеспечить встроенные secret объекты.
Аварийное восстановление и Резервное копирование
Реализация избыточности через использование нескольких хостов и ВМ помогает уменьшить количество некоторых типов сбоев. Но такие сценарии, как стихийное бедствие, плохой апдейт, хакерская атака, баги ПО или человеческая ошибка, все еще могут обернуться сбоями.
Критически важная часть производственного развертывания — ожидание необходимости восстановления в будущем.
Также стоит отметить, что часть ваших вложений в дизайн, документацию и автоматизацию процесса восстановления может быть повторно использована, если потребуются крупномасштабные реплицированные развертывания на нескольких площадках.
Среди элементов аварийного восстановления стоит отметить бэкапы (и возможно реплики), замены, запланированный процесс, людей, которые будут выполнять этот процесс, и регулярное обучение. Частые тестовые упражнения и принципы Chaos Engineering могут быть использованы для проверки вашей готовности.
Из-за требований доступности возможно придется хранить локальные копии ОС, компонентов Kubernetes и образов контейнера, чтобы позволить восстановление даже при Интернет сбое. Возможность деплоя замещающих хостов и нод в ситуации “физической изоляции” улучшает безопасность и увеличивает скорость развертывания.
Все объекты Kubernetes хранятся в etcd. Периодическое резервное копирование данных etcd-кластера — важный элемент в восстановление кластеров Kubernetes при аварийных сценариях, например при потере всех мастер-нод.
Резервное копирование etcd кластера может быть выполнено с помощью встроенного в etcd механизма снапшотов и копирования результата на хранение в другой домен сбоя. Файлы снимков содержат все состояния Kubernetes и критически важную информацию. Зашифруйте файлы снимков, чтобы защитить конфиденциальные данные Kubernetes.
Имейте в виду, что некоторые расширения Kubernetes могут хранить состояния в отдельных etcd кластерах, постоянных томах или с помощью какого-то другого механизма. Если эти состояния критически важны, у них должна быть резервная копия и план восстановления.
Но некоторые важные состояния хранятся вне etcd. Сертификаты, образы контейнера, другие настройки и состояния, связанные с операциями, могут управляться автоматическим инструментом установки/обновления. Даже если эти файлы можно сгенерировать заново, резервная копия или реплика ускорят восстановление после сбоя. Задумайтесь о необходимости резервной копии и плана восстановления для следующих объектов:
- Пар сертификатов и ключей: CA, API Server, Apiserver-kubelet-client, аутентификация ServiceAccount, “Front proxy”, клиент Front proxy;
- Важные записи DNS;
- Назначения и резервирования IP/подсети;
- Внешний балансировщик загрузки;
- Файлы kubeconfig;
- LDAP и прочие детали аутентификации;
- Аккаунт и конфигурационные данные облачного провайдера.
Предложения для производственных нагрузок
Anti-affinity спецификации могут быть использованы для разделения кластеризованных сервисов между резервными хостами. Но в данном случае настройки используются, только если под запланирован. Это значит, что Kubernetes может перезапустить вышедшую из строя ноду вашего кластеризованного приложения, но не обладает встроенным механизмом для повторной балансировки после сбоя. Эта тема заслуживает отдельной статьи, но дополнительная логика может быть полезна для достижения оптимального размещения рабочих нагрузок после того, как хост или воркер-нода восстанавливаются или расширяются. Функция Приоритезации и Вытеснения Подов может использоваться для выбора желаемой сортировки в случае недостатка ресурсов, вызванного сбоем.
В случае stateful-сервисов, внешние смонтированные тома — стандарт рекомендаций Kubernetes для некластеризованных сервисов (например, для типичной SQL базы данных). Сейчас, снапшоты внешних томов, управляемые Kubernetes, находятся в категории roadmap feature request, и, скорее всего, связаны с интеграцией Container Storage Interface (CSI). Таким образом, создание резервных копий такого сервиса потребует внутри-подовых действий, зависящих от конкретного приложения, что выходит за рамки этой статьи. Поэтому, пока мы ждем улучшения поддержки Kubernetes для воркфлоу снапшотов и резервного копирования, стоит задуматься о запуске сервиса базы данных не в контейнере, а в виртуальный машине, и открыть ее Kubernetes нагрузкам.
Кластеризованные stateful-сервисы (например, Cassandra) могут получить преимущество за счет разделения между хостами, используя локальные постоянные тома, если ресурсы это позволяют. Для этого потребуются развертывания нескольких воркер-нод Kubernetes (могут быть ВМ на гипервизор-хостах) для сохранения кворума в точке отказа.
Другие предложения
Логи и метрики (если собирать и хранить их) полезны для диагностики сбоев, но с учетом разнообразия доступных технологий, мы не будем их рассматривать в этой статье. При наличии подключения к интернету, желательно хранить логи и метрики снаружи, централизованно.
В производственном развертывании должны использоваться инструменты автоматической установки, настройки и обновления (например, Ansible, BOSH, Chef, Juju, kubeadm, Puppet и т.д). Ручной процесс слишком трудоемкий и сложный для масштабирования, в нем легко совершить ошибки и столкнуться с проблемами повторяемости. Сертифицированные дистрибутивы, вероятно, будут включать в себя средство для сохранения настроек при обновлении, но, если же вы используете собственный тулчейн для установки и настройки, то хранение, бэкап и восстановление конфигурационных артефактов имеет огромное значение. Стоит задуматься об использовании системы контроля версии, вроде Git, для хранения компонентов и настроек развертывания.
Восстановление
Ранбуки, в которых задокументированы процессы восстановления, должны быть протестированы и сохранены оффлайн — возможно даже распечатаны. Когда сотрудника вызывают в 2 часа ночи пятницы, импровизация — не лучший вариант. Лучше выполнить все пункты из запланированного и протестированного чеклиста — к которому есть доступ как у сотрудников в офисе, так и у удаленных.
Финальные мысли
Покупка билета на самолет коммерческих авиалиний — простой и безопасный процесс. Но если вы летите в отдаленное место с короткой взлетно-посадочной полосой, коммерческий полет на Airbus A320 — неподходящий вариант. Это не значит, что авиаперелет вообще не должен рассматриваться. Это означает только то, что необходимы компромиссы.
В контексте авиации, поломка двигателя в однодвигательном судне означает крушение. С двумя двигателями, минимум, будет больше возможностей решить, где произойдет крушение. Kubernetes на малом количестве хостов аналогичен, и если ваш бизнес-кейс оправдывает, стоит задуматься об увеличении флота, состоящего из больших и малых машин (например, FedEx, Amazon).
При проектировании production-grade решения Kubernetes у вас есть много возможностей и вариантов. Простая статья не может дать все ответы и не имеет понятия о именно ваших приоритетах. Тем не менее, надеемся, что она предоставила список вещей, о которых стоит подумать, а также некоторые полезные рекомендации. Есть варианты, которые остались нерассмотренными (например, запуск компонентов Kubernetes с помощью self-hosting, а не статических подов). Возможно о них стоит поговорить в следующих статьях, при наличии достаточного интереса. Кроме того, из-за высокой скорости улучшения Kubernetes, если ваша поисковая система нашла эту статью после 2019 года, некоторые ее материалы могли уже сильно устареть.
THE END
Как всегда ждём ваши вопросы и комментарии и тут, и можно зайти на День открытых дверей к Александру Титову.