Хотите ли вы в джавке треды, которые не жрут память как не в себя и не тормозят? Хорошее похвальное желание, и на данный вопрос отвечает этот выпуск.
Объясняем работу Project Loom на коробках с пиццей! Налетай!
Состав поставки:
- Видеокаст (основная часть). Для тех, кто любит потреблять видео.
- Полная текстовая расшифровка статьи. Там есть ссылки!
Всё это снимается и пишется специально для Хабра.

 Мы живём в жестоком новом мире, где лайки стоят больше, чем деньги. Блогер может сделать за лайки практически всё, что угодно. Финальная стадия международного капитализма и технологической распущенности.
Мы живём в жестоком новом мире, где лайки стоят больше, чем деньги. Блогер может сделать за лайки практически всё, что угодно. Финальная стадия международного капитализма и технологической распущенности.
Знаю, что вам ваши лайчики дались нелегким трудом. Неизвестно, какие мерзости вы вообще делаете, чтобы заработать. Возможно, отвечаете на комментарии, которые вам на самом деле не нравятся, людям, которых вы ненавидите, и так зарабатываете себе вожделенные плюсики. Я не хочу об этом знать вообще. Лайки не пахнут. Просто отслюнявьте мне немножко лайчиков, и я сделаю вид, что не знаю, откуда они. Это всё, что имеет значение для продажного блогера типа меня.
Все лайчонки пойдут на создание нового контента. Спасибо.
Позывные
Привет, джаваны, Олег на связи.
Часто ли вы видите у себя на веб-сервисе вот такую картинку: вначале все было хорошо, потом к вам пришёл миллион китайцев, сервис наделал миллион тредов и захлебнулся к чертям собачьим?
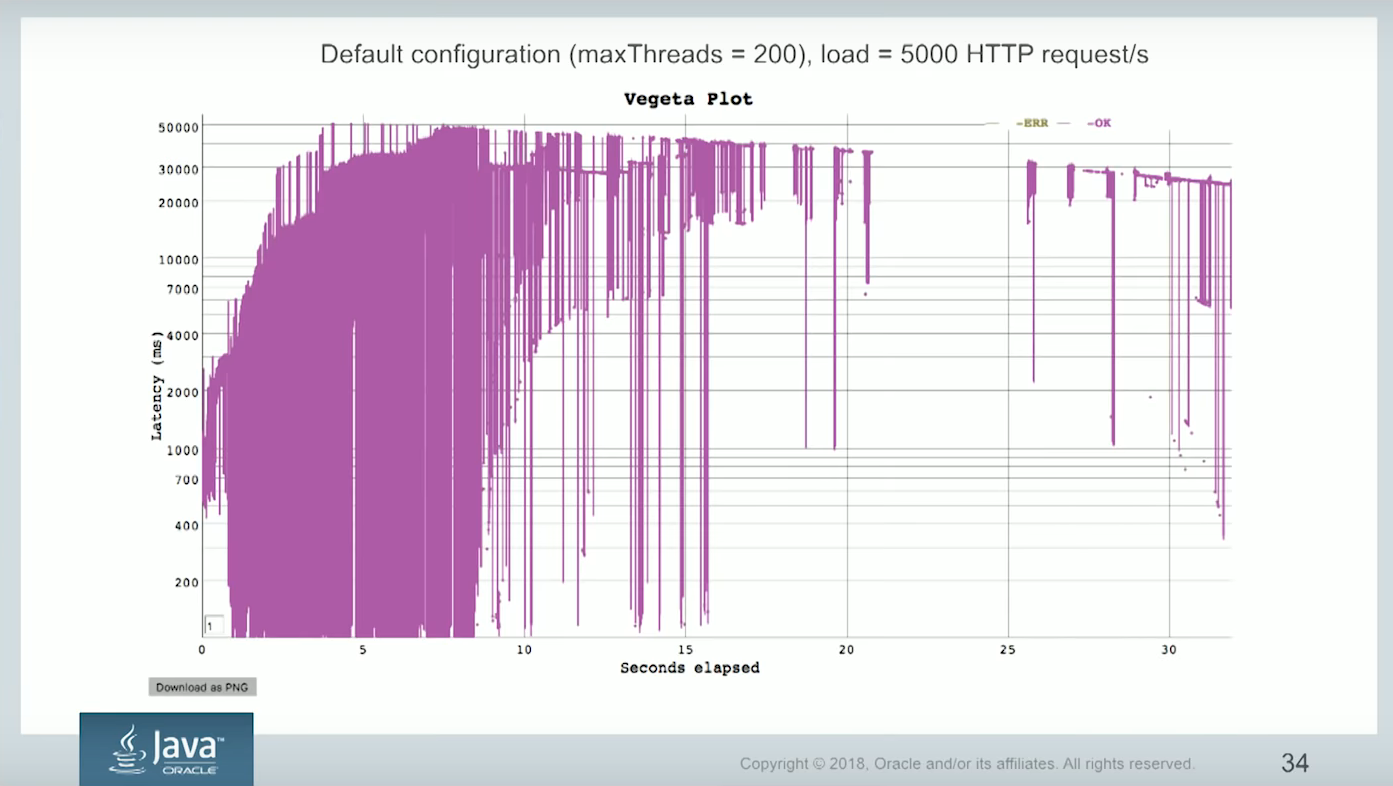
Хотите ли вы вот такую няшную картинку?

Иначе говоря, хотите ли вы в джавке треды, которые не жрут память как не в себя и не тормозят? Хорошее похвальное желание, и на данный вопрос отвечает этот выпуск.
Мы будем заниматься, по сути, распаковкой нового фреймворка. Помните, как Wylsacom распаковывал айфоны? Кое-кто уже и не помнит старых обзорщиков, а всё почему? Потому что Хабр — оплот мейнстрима, а проплаченные видосы — это, извините, лучи поноса. В этом посте мы будем заниматься исключительно техническим хардкором.
Сначала две минуты на завязку, отказ от ответственности и прочую фигню, которую надо сказать. Можно ее пропустить, если вам лень.
Во-первых, всё сказанное в ролике — это мои личные мысли, и никакого отношения к работодателю или славной корпорации Oracle, мировому правительству ящериков и черту в ступе они не имеют. Я даже пишу это в три часа ночи, чтобы ну вот точно было ясно, что это моя личная инициатива, моя личная фигня. Все совпадения чисто случайны.
Но есть еще одна бонусная цель. Мы постоянно разговариваем о корутинах в Kotlin. Вот недавно были интервью с Ромой Елизаровым, богом корутин, и с Пашей Финкельштейном, который на них собирается писать бэкенды. Скоро будет интервью с Андреем Бреславом — который отец Kotlin. И везде так или иначе упоминается проект Loom, потому что это аналог корутин. И если вы не знаете, что такое Loom, вам при чтении этих интервью вам может стать стрёмно. Вот есть какие-то клевые чуваки, они обсуждают крутые вещи. А есть ты, и ты не с ними, ты чмо. Это очень тупо.
Не делайте так, прочитайте, что такое Loom, в этой статье, или дальше смотрите это видео, я все объясню.
Итак, в чем завязка. Есть такой чувак, Рон Пресслер.

В прошлом году он пошел в рассылку, заявил, что треды в джаве — отстой, и предложил похачить рантайм и починить это. И все бы над ним посмеялись и закидали камнями, говном, если бы не тот факт, что ранее он написал Quasar, и это вообще-то очень круто. Можно долго ругаться на Квазар, но он как бы есть и работает, и в большой картине всего это, скорее, достижение.
Есть чертово количество говнокодеров, которые ничего не делают, просто говорят. Ну и поймите правильно, я такой же. Или вот есть люди, которые вроде бы клевые инженеры, но вообще в несознанке, они такие говорят: «В джаве надо улучшить треды». Что улучшить? Что — треды?
Людям вообще лень думать.
Как там в анекдоте:
Летят в самолете Петька и Василий Иванович.
Василий Иванович спрашивает: — Петька, приборы?
Петька отвечает: — 200!
Василий Иванович: — А что 200?
Петька: — А что приборы?
Расскажу историю. Я был этой весной на Украине, мы летели из Беларуси (вы понимаете, почему напрямую из Питера нельзя). И на таможне мы сидели что-то часа два, не меньше. Таможенники весьма приятные, на полном серьезе спрашивали, является ли Java устаревшей технологией. Рядом сидели люди, которые летят на ту же конфу. И я же типа докладчик, должен понтануться, стою и, как положено, бесстыже рассказываю о вещах, которые вообще не использую. И по пути рассказал о дистрибутиве JDK под названием Liberica, это такой JDK для Raspberry Pi.
И что вы думаете. Не проходит и полгода, как ко мне в телегу стучится чел и говорит, что вот, гляди, мы запилили на Либерике решение в прод, и у меня уже есть доклад про это на белорусскую конфу jfuture.by. Вот это подход. Это не евангелист какой-то паршивый, а норм чувак, норм инженер.
Кстати, у нас скоро будет конференция Joker 2018, на которой будут и Андрей Бреслав (очевидно, шарящий в корутинах), и Паша Финкельштейн, а о поддержке Loom в Spring можно будет спросить у Джоша Лонга. Ну и ещё куча крутых видных экспертов, налетай!
И вот, возвращаясь к тредам. Люди пытаются сквозь свои деграднувшие два нейрона мысль провести, такие наматывают сопли на кулак, и бормочут: "В джаве треды не так, в джаве треды не так". Приборы! Что приборы? Это вообще ад.
И вот приходит Пресслер, нормальный не деграднувший чувак, и вначале делает вменяемое описание. А через год пилит рабочую демку. Все это я говорил, чтобы вы поняли, что нормальное описание проблем, нормальная документация — это такой героизм особого рода. А демка — это вообще космос. Это первый человек, который вообще что-то сделал в этом направлении. Ему больше всего надо.
Вместе с демкой Пресслер выступил на конференции и выпустил вот такое видео:
По сути, вся эта статья — это некий обзор на сказанное там. Я совершенно не претендую на уникальность этого материала, всё, что есть в этой статье, придумал Рон.
Обсуждение идёт по поводу трех болезненных тем:
- Continations
- Fibers
- Tail-calls
Вероятно, его так задолбало пилить Квазар и бороться с его глюками, что вот сил нет — надо пихать это в рантайм.
Было это год назад, и с тех пор они пилили прототип. Некоторые уже потеряли надежду, что мы когда-то увидим демку, но месяц назад её-таки родили и показали, что видно по этому твиту.
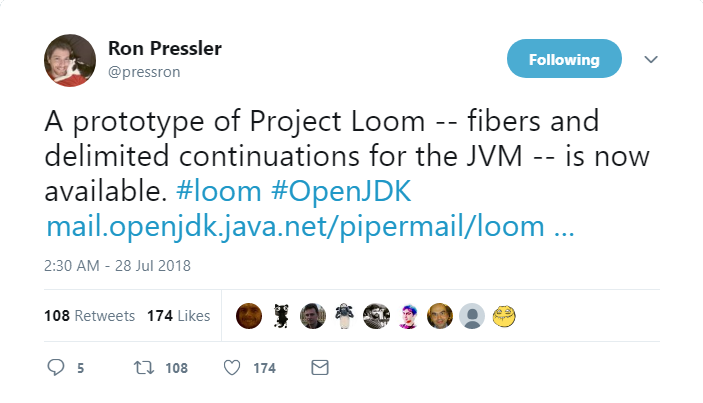
Все три болезненные темы в этой демке имеются или прямо в коде, или хотя бы присутствуют морально. Ну да, tail calls они пока не осилили, но хотят.
Проблематика
Несчастные пользователи, прикладные разработчики, когда делают API, принуждены выбирать между двумя стульями. На одном стуле встроены пики, на другом — растут цветы. И ни то, ни другое нам не подходит.

Например, если ты пишешь сервис, который работает синхронно, он отлично работает с легаси-кодом, его легко дебажить и мониторить перформанс. Проблемы возникнут с пропускной способностью и масштабируемостью. Просто потому, что количество тредов, которые сейчас можно запустить на простой железяке, на commodity hardware — ну допустим, две тысячи. Это сильно меньше, чем количество соединений, которые можно бы открыть к этому серверу. Коих с точки зрения неткода может быть чуть ли не бесконечно.
(Ну и да, это как-то связано с тем, что сокеты в джаве устроены дебильно, но это тема другого разговора)
Представьте, вы пишете какую-нибудь MMO.
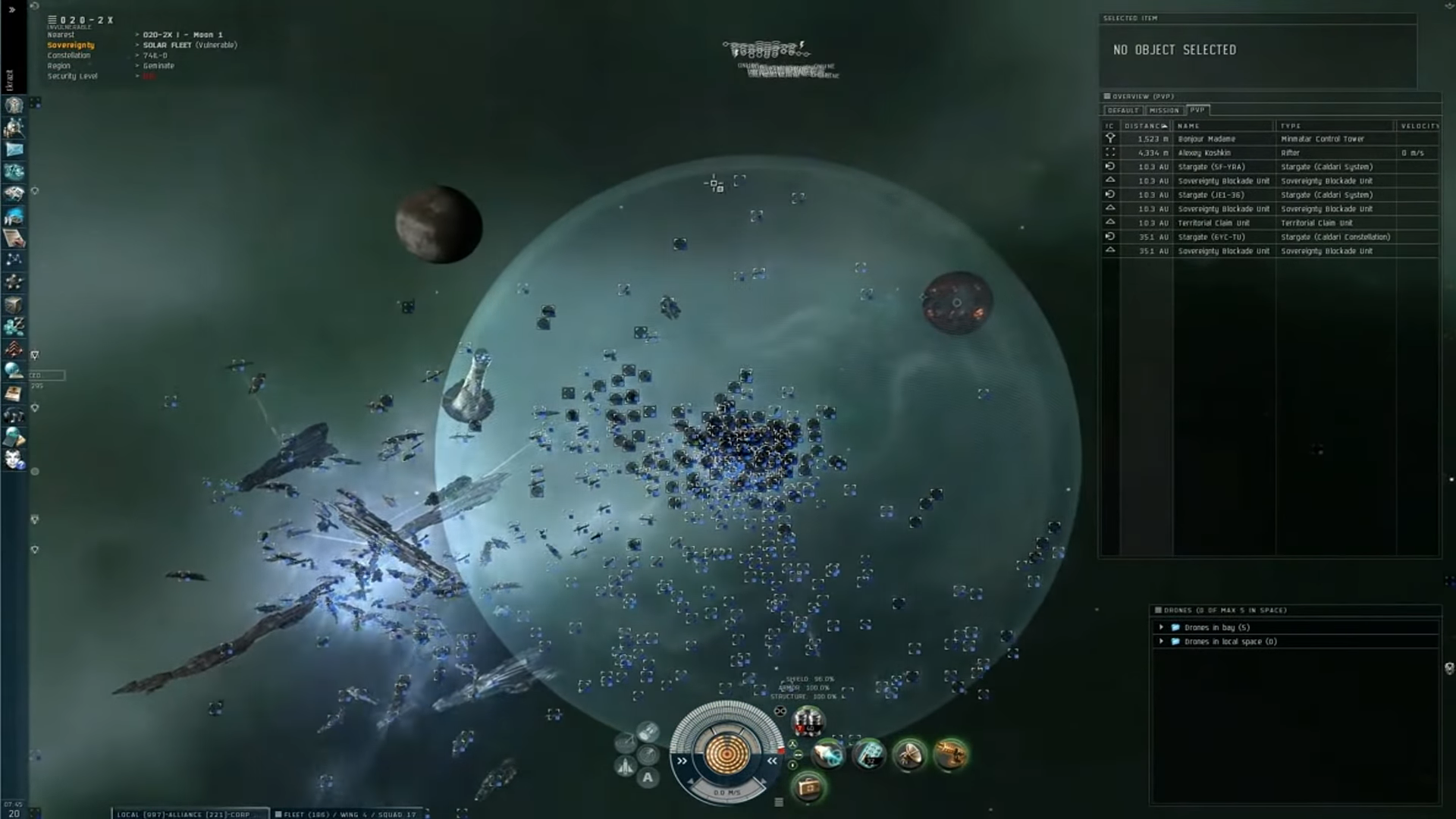
Например, во время Северной Войны в EVE Online в одной точке пространства собрались две тысячи четыреста пилотов, каждый из которых — условно, будь это написано на Java, — был бы не один тред, а несколько. И пилот, понятно, — это сложная бизнес-логика, а не выдача какого-нибудь HTML, который можно руками поразлинеивать в лупе.
Время отклика в той битве было настолько большим, что ждать выстрела игроку приходилось несколько минут. Насколько знаю, CCP специально под ту битву бросило огромные аппаратные ресурсы своего кластера.
Хотя, я, наверное, зря привожу в пример именно EVE, потому что, насколько понимаю, у них всё написано на Python, а в Python с многопоточностью всё ещё хуже, чем у нас — и можно считать плохой конкарренси фичей языка. Но зато пример наглядный и с картинками.
Если вас заинтересовала тематика ММО вообще и история «Северной Войны» в частности, недавно на канале БУЛДЖАТь (что бы ни значило это название) появился очень хороший ролик на эту тему, смотреть с моей временной метки.
Возвращаемся к теме.
С другой стороны, можно использовать какой-нибудь асинхронный фреймворк. Он масштабируется. Но мы тут же попадём на очень сложную отладку, сложное профилирование перформанса, мы не сможем бесшовно это интегрировать с легаси, придётся очень много чего переписать, обернуть в мерзотные обертки, и вообще ощущать себя, как будто нас только что изнасиловали. Несколько раз подряд. Целыми днями, на самом деле, всё время, пока мы это пишем, так придется себя чувствовать.
Я поинтересовался у эксперта, известного академика Эскобара, что он думает по этому поводу:

Что же делать? На помощь спешат так называемые файберы.
В общем случае, файберы — это такие легкие треды, которые тоже шарят адресное пространство (потому что чудес не бывает, вы понимаете). Но в отличие от обычных тредов используют не вытесняющую многозадачность, а кооперативную многозадачность. Подробней стоит почитать на Википедии.
Файберы могут на себе реализовать плюсы как синхронного, так и асинхронного программирования. В результате повышается утилизация железа, и мы используем меньше серверов в кластере на ту же самую задачу. Ну и в карман за это получаем лавандосики. Бабосы. Лавэ. Денежки. Ну, вы поняли. За сэкономленные сервера.
На распутье
Первое, что хочется обсудить. Люди не понимают разницы между континуациями и файберами.
Сейчас будет Культпросвет!
Огласим факт: Continuation и Fiber — это разные вещи.
Continuations
Файберы построены поверх механики под названием Continuations.
Continuations (если точнее, delimited continuations) — это некое вычисление, исполнение, кусок программы, который может заснуть, потом проснуться и продолжить выполнение с того места, как заснул. Его иногда можно даже склонировать или сериализовать, даже в тот момент, пока он спит.
Я буду использовать слово «континуация», а не «продолжение» (как это написано на Википедии), потому что все мы общаемся на рунглише. Используя нормальную русскую терминологию, можно легко прийти к ситуации, когда разница между русским и английским термином становится слишком большой и никто больше не понимает смысла сказанного.
Ещё я иногда буду использовать слово «вытеснение» вместо английского варианта «yield». Просто слово «yield» — оно какое-то уж совсем мерзковатое. Поэтому будет «вытеснение».
Так вот. Очень важно, что никакого конкарренси внутри континуации не должно быть. Она сама по себе — минимальный примитив этого процесса.
Можно думать о континуации как о Runnable, у которого внутри можно вызвать метод pause(). Именно внутри и напрямую, потому что многозадачность у нас кооперативная. И потом можно запустить его ещё раз, и вместо того, чтобы всё считать заново, он продолжит с места, где остановился. Такая магия. К магии мы еще вернемся.
Где взять демку с работающими континуациями — мы обсудим в самом конце. Сейчас поговорим о том, что там есть.
Сам класс континуации лежит по адресу в java.base, все ссылки будут в описании. (src/java.base/share/classes/java/lang/Continuation.java). Но этот класс очень большой, объемный, поэтому имеет смысл посмотреть только на какую-то выжимку из него.
public class Continuation implements Runnable {
public Continuation(ContinuationScope scope, Runnable body);
public final void run();
public static void yield(ContinuationScope scope);
public boolean isDone();
protected void onPinned(Reason reason) {
throw new IllegalStateException("Pinned: " + reason);
}
}Заметьте, что на самом деле файл этот постоянно меняется. Например, по состоянию на предыдущий день континуация не реализовывала интерфейс Runnable. Относитесь к этому как к некой зарисовке.
Взгляните на конструктор. body — это код, который вы пытаетесь запускать, а scope — это некий скоп, позволяющий вкладывать континуации в континуации.
Соответственно, можно или заранить этот код до конца методом run, или вытеснить его с каким-то конкретным скопом с помощью метода yield (скоп тут нужен для чего-то типа пробрасывания эксепшенов по вложенным обработчикам, но нам это неважно как пользователям). Можно спросить с помощью метода isDone, завершилось ли всё до конца.
И по причинам, продиктованным исключительно нуждами текущей реализации (но скорей всего, в релиз тоже попадёт), совершенно не всегда можно сделать yield. Например, если внутри континуации у нас случился переход в нативный код и на стеке появился нативный фрейм, то зайилдить нельзя. Ещё так произойдет, если попытаться вытесниться, пока внутри тела континуации взят нативный монитор, типа синхронизованного метода. По умолчанию, при попытке зайилдить такое, выбрасывается исключение… но файберы, построенные поверх континуаций, перегружают этот метод и делают кое-что другое. Об этом будет чуть позже.
Использовать это можно примерно следующим образом:
Continuation cont = new Continuation(SCOPE, () -> {
while (true) {
System.out.println("before");
Continuation.yield(SCOPE);
System.out.println("after");
}
});
while (!cont.isDone()) {
cont.run();
}Это пример из презентации Пресслера. Опять, это не «всамделишный» код, это какая-то зарисовка.
Это зарисовка о том, что мы делаем континуацию, в середине этой континуации вытесняемся и потом в бесконечном цикле спрашиваем — отработала ли континуация до конца и надо ли её продолжить.
Но вообще, не предполагается, что обычные прикладные программисты будут касаться этого API. Оно предназначено для создателей системных фреймворков. Системообразующие фреймворки вроде Spring Framework сразу же заадоптят этот фичу, как только она выйдет. Вот увидите. Считайте это за предсказание. Такое, лайтовое предсказание, потому что здесь всё довольно очевидно. Все данные для предсказания есть. Это слишком важная фича, чтобы ее не заадоптить. Поэтому не нужно заранее беспокоиться, что кто-то вас будет истязать кодированием вот в таком виде. Ну а если вы — разработчик Spring, то знали, на что шли.
И вот уже поверх континуаций построены файберы.
Fibers
Итак, что в нашем случае означают файберы.
Это некая абстракция, представляющая из себя:
- Легкие треды, обрабатываемые в самой JVM, а не в операционной системе;
- С крайне низкими оверхедами на создание, поддержание жизни, переключение задач;
- Которые можно запускать миллионы раз.
Многие технологии пытаются сделать файберы тем или иным образом. Например, в Kotlin есть корутины, реализованные на очень умной генерации байткода. ОЧЕНЬ УМНОЙ. Но рантайм — более правильное место для реализации подобных вещей.
Как минимум, JVM уже умеет хорошо справляться с тредами, а всё, что нам нужно — это упростить процесс кодирования многопоточности. Можно использовать асинхронные API, но это вряд ли стоит называть «упрощением»: даже использование таких штук, как Reactor, Spring Project Reactor, позволяющих писать вроде-бы-линейный код, не особо поможет при необходимости отладки сложных проблем.
Итак, файбер.
Файбер состоит из двух компонентов. Это:
- Continuation (континуейшен)
- Scheduler (скедьюлер)
То есть:
- Континуация
- Планировщик

Можете сами решить, кто здесь планировщик. Я думаю, планировщик тут именно Джей.
- Файбер оборачивает код, который вы хотите исполнить, в континуации
- Планировщик запускает их на пуле из carrier threads
Буду называть их тредами-носителями.

В текущем прототипе используется java.util.concurrent.Executor, а встроенный планировщик — ForkJoinPool. Всё у нас есть. В будущем там может появиться что-то поумней, но пока вот так.
Как ведет себя континуация:
- Вытесняется (yield), когда происходит блокировка (например, на IO);
- Продолжается, когда готова продолжиться (например, IO-операция завершилась и можно двигаться дальше).
Текущий статус работ:
- Основной фокус на философии, концепциях;
- API не зафиксировано, оно есть «для галочки». Это исследовательский прототип;
- Есть готовый закодированный работающий прототип класса
java.lang.Fiber.
О нем пойдет речь.
Что уже запилили в файбер:
- В нем работает запуск задач;
- Паркинг-анпаркинг на тред-носитель;
- Ожидание завершения файбера.
Принципиальная схема
mount();
try {
cont.run();
} finally () {
unmount();
}- Мы можем смонтировать файбер на тред-носитель;
- Потом запустить континуацию;
- И ждать, пока она не вытеснится или честно не остановится;
- В конце концов, мы всегда уходим с треда.
Этот псевдокод выполнится на планировщике ForkJoinPool или на каком-то другом (который в конце концов окажется в финальной версии).
Использование в реальности
Fiber f = Fiber.execute( () -> {
System.out.println("Good Morning!");
readLock.lock();
try {
System.out.println("Good Afternoon");
} finally {
readLock.unlock();
}
System.out.println("Good Night");
});Глядите, мы создаем файбер, в котором:
- приветствуем всех;
- блочимся на РЕЕНТРАНТ ЛОКЕ;
- по возвращении поздравляем с обедом;
- в конце концов отпускаем лок;
- и прощаемся.
Всё очень просто.
Мы не вызываем вытеснение напрямую. Сам Project Loom знает, что при срабатывании readLock.lock(); ему стоит вмешаться и неявно сделать вытеснение. Пользователь этого не видит, но оно там происходит.
Стеки, повсюду стеки!
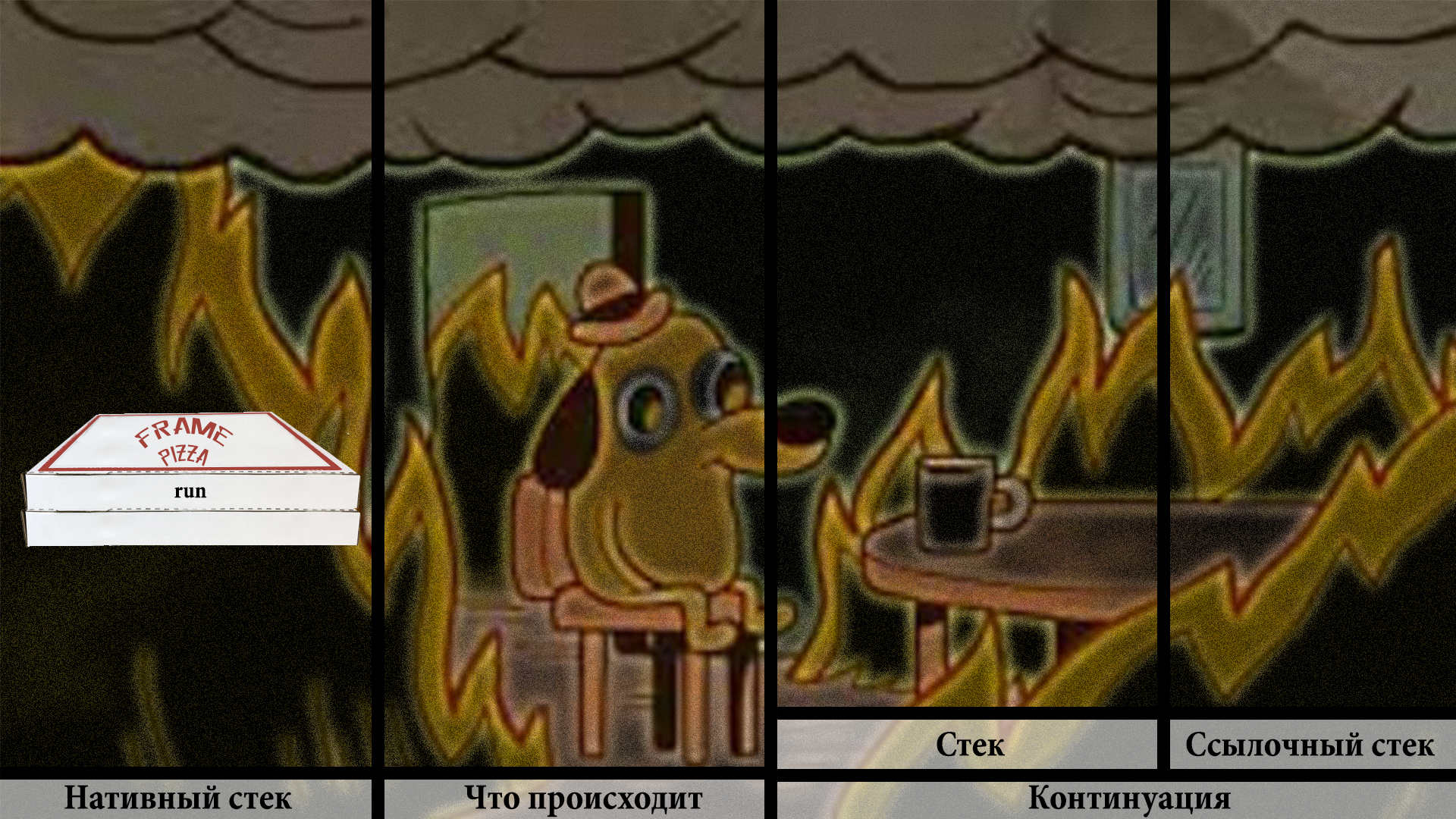
Давайте на примере стека с пиццей продемонстрируем, что происходит.
Вначале тред-носитель находится в состоянии ожидания, и ничего не происходит.

Вершина стека наверху, напоминаю.
Потом файбер запланировали к исполнению, и таск файбера начал запускаться

Внутри себя он, очевидно, запускает континуацию, в которой уже находится настоящий код.
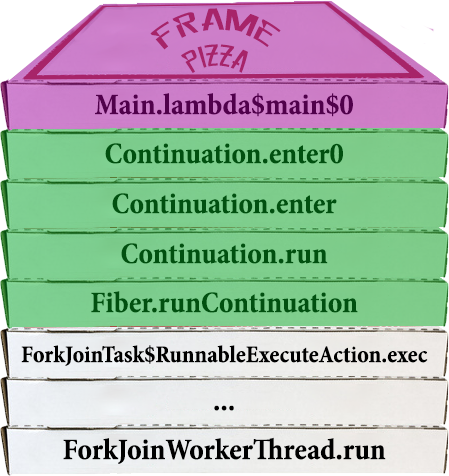
С точки зрения пользователя, мы здесь еще ничего не запустили.
Вот только первый фрейм юзерского кода появился на стеке, и он отмечен фиолетовым.
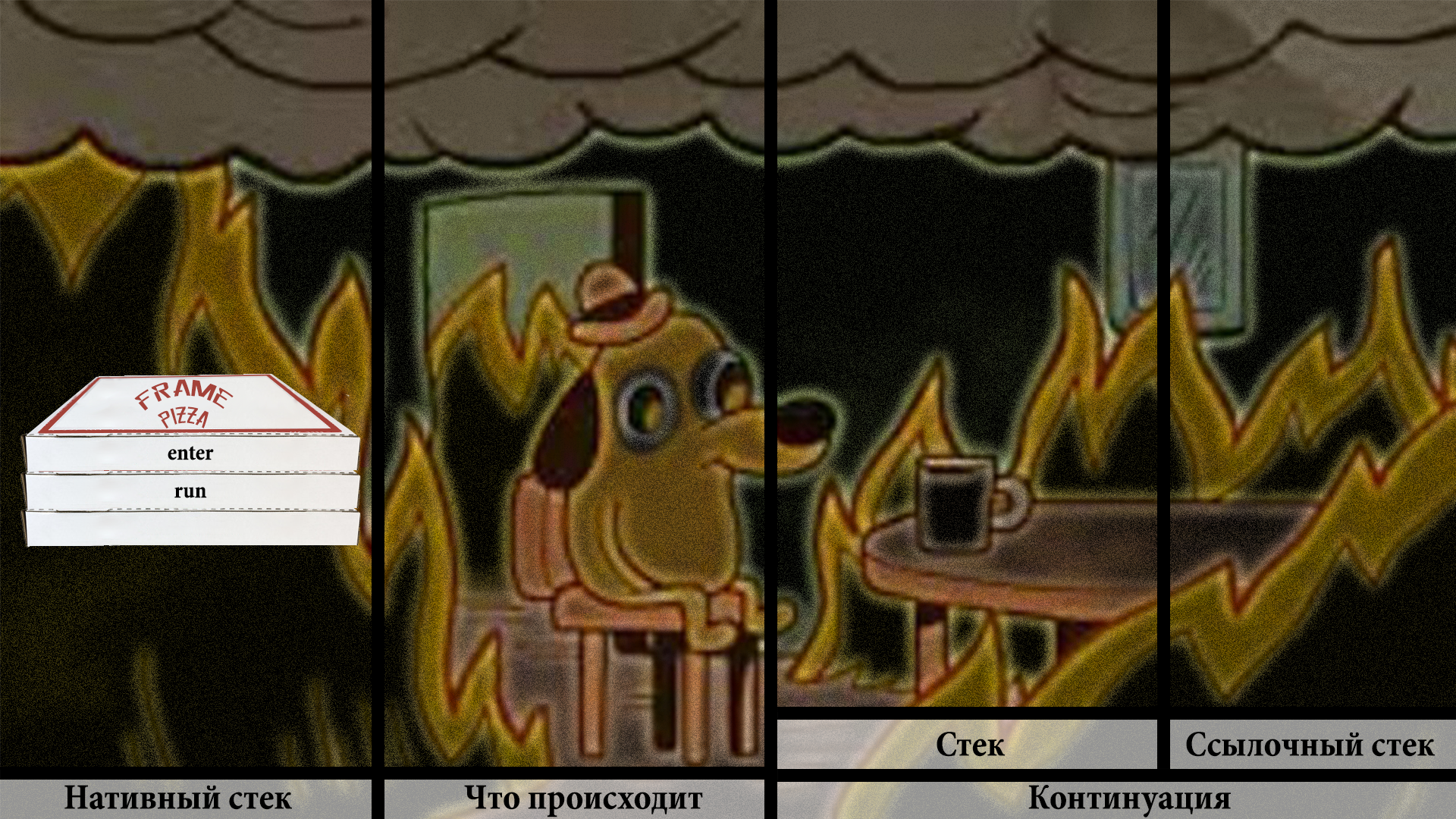
Дальше код выполняется-выполняется, в какой-то момент таск пытается захватить лок и заблочиться на нем, что приводит к автоматическому вытеснению.

Всё, что есть на стеке континуации, сохраняется в некое магическое место. И исчезает.

Как видим, поток возвращается в файбер, на инструкцию, которая идет следом за Continuation.run. А это — окончание кода файбера.
Таск файбера заканчивается, тред-носитель ждет новой работы.

Файбер запаркован, где-то лежит, континуация полностью вытеснена.
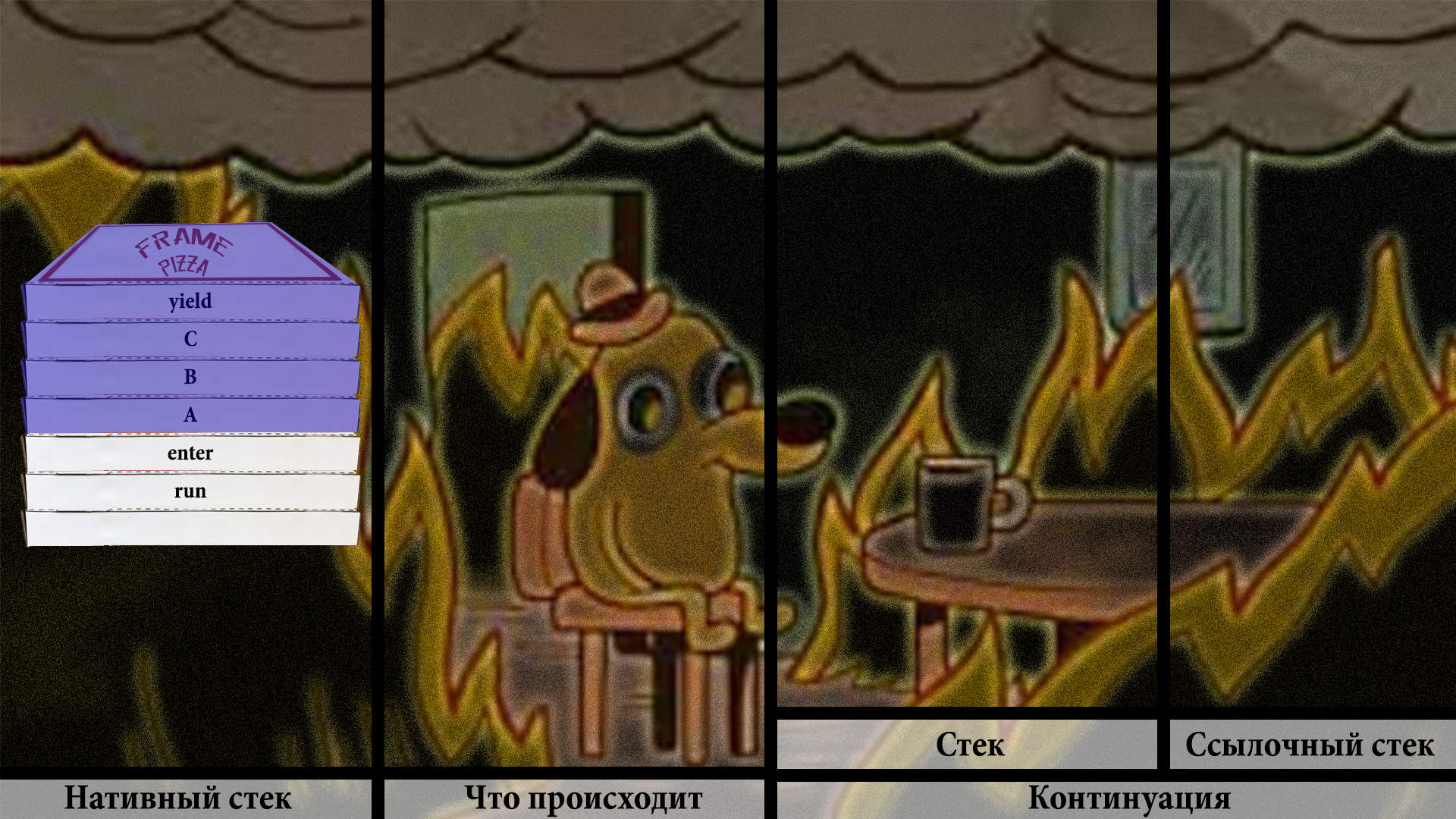
Рано или поздно наступает момент, когда тот, кто владеет локом, отпускает его.
Это приводит к тому, что файбер, который ждал отпускания лока, анпаркится. Таск этого файбера запускается снова.
- ReentrantLock.unlock
- LockSupport.unpark
- Fiber.unpark
- ForkJoinPool.execute
И мы быстро возвращаемся к стеку, который был недавно.
Причем тред-носитель может быть совершенно другой. И в этом смысл!
Снова запускаем континуацию.

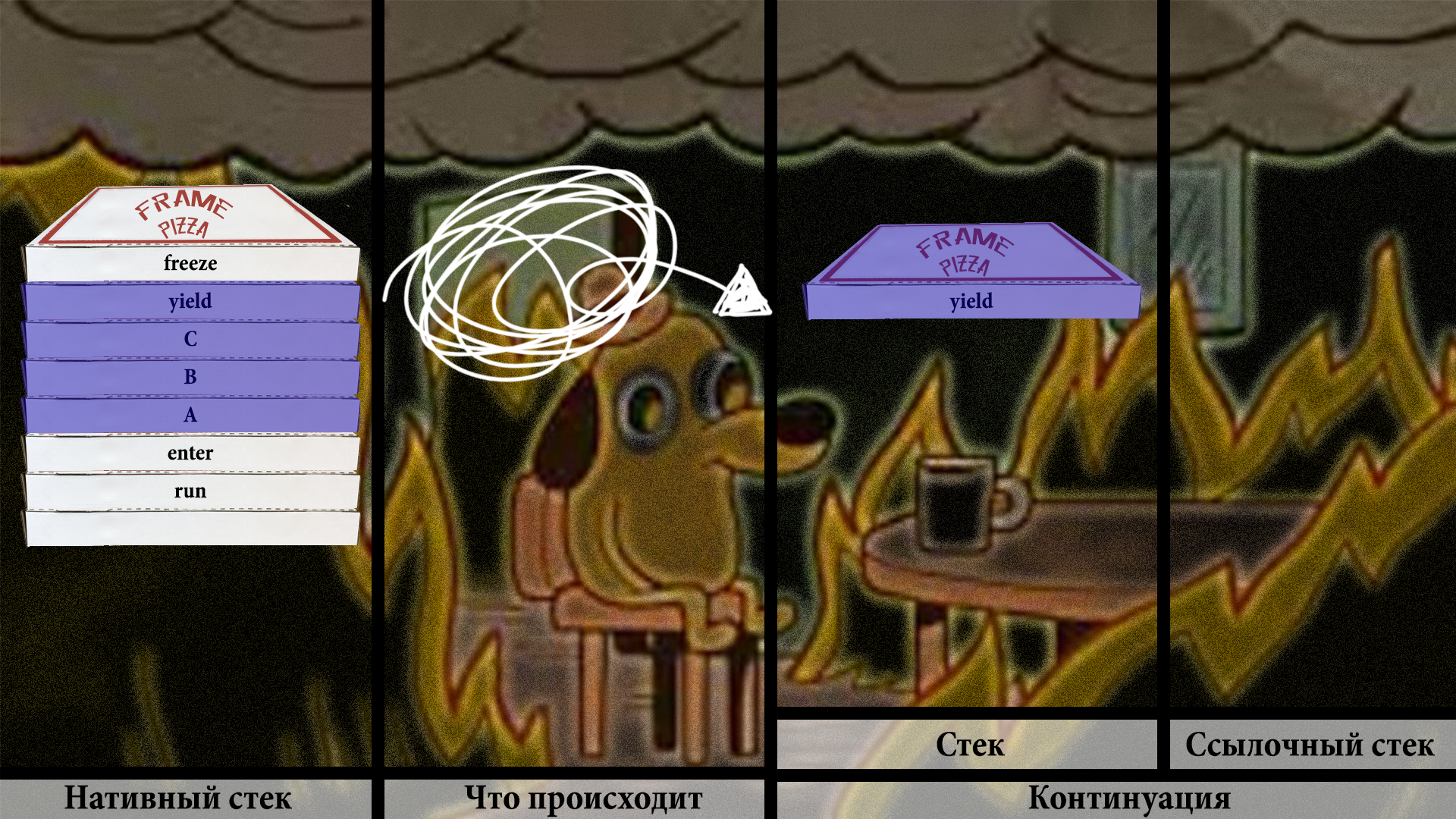
И тут происходит МАГИЯ!!! Стек восстанавливается, и выполнение продолжается с инструкции после Continuation.yield.

Мы вылезаем из только что отпаркованного лока и начинаем выполнять весь оставшийся в континуации код:

Таск пользователя завершается, и управление возвращается в таск файбера сразу же после инструкции continuation.run

При этом заканчивается и выполнение файбера, и мы снова оказываемся в режиме ожидания.
Следующий запуск файбера вновь инициирует весь описанный выше цикл перерождений.

Живые примеры
А кто вообще сказал, что все это работает? Это про пару микробенчмарков, написанных за вечер?
В качестве примера работы файберов оракловцы написали небольшой веб-сервер и накормили его запросами так, что он захлебнулся. Потом перевели на файберы. Сервер захлебываться перестал, и из этого сделали вывод, что файберы работают.
У меня нет точного кода этого сервера, но если этот пост наберет достаточно лайков и комментариев, я попробую самостоятельно написать пример и построить реальные графики.
Проблемы
Есть ли тут какие-то проблемы? Да, конечно! Вся история с файберами — это история о сплошных проблемах и трейдоффах.
Философские проблемы
- Нужно ли нам переизобрести треды?
- Должен ли весь существующий код нормально работать внутри файбера?
Текущий прототип выполняет с ограничениями. Которые, возможно, перейдут в релиз, хотя не хотелось бы. Всё-таки, OpenJDK — это штука, уважающая бесконечную совместимость.
В чем заключаются технические ограничения? Самых очевидных ограничений — 2 штуки.
Проблема раз — нельзя вытеснить нативные фреймы
PrivilegedAction<Void> pa = () -> {
readLock.lock(); // may park/yield
try {
//
} finally {
readLock.unlock();
}
return null;
}
AccessController.doPrivileged(pa); //native methodЗдесь doPrivileged зовет нативный метод.
Вы в файбере зовете doPrivileged, выпрыгиваете из VMки, у вас на стеке появляется нативный фрейм, после чего вы пытаетесь запарковаться на строчке readLock.lock(). И в этот момент тред-носитель окажется запиненным до того времени, пока его не распаркуют. То есть тред пропадает. В этом случае могут закончиться треды-носители, и вообще, это ломает всю идею файберов.
Способ это решить уже известен, и сейчас идут дискуссии по этому поводу.
Проблема два — synchronized-блоки
Это уже гораздо более серьезная фигня
synchronized (object) { //may park
object.wait(); //may park
}synchronized (object) { //may park
socket.getInputStream().read(); //may park
}В случае захвата монитора в файбере, треды-носители тоже пинятся.
Понятно, что в совершенно новом коде можно поменять мониторы на прямые блокировки, вместо wait+notify можно использовать condition objects, но что делать с легаси? Это проблема.
Thread API? Thread.currentThread()? Thread Locals?
В текущем прототипе для Thread и Fiber сделали один общий суперкласс под названием Strand.
Это позволяет перенести API в самом минимальном варианте.
Что делать дальше — как всегда в этом проекте, вопрос.
Что сейчас происходит с Thread API?
- Первое использование
Thread.currentThread()в файбере создает некий теневой тред, Shadow Thread; - с точки зрения системы, это "незапущенный" тред, и в нем нет никакой VMной метаинформации;
- ST старается эмулировать все, что может;
- но надо понимать, что в старом API куча мусора;
- более конкретно, Shadow Thread реализует Thread API для всего, кроме
stop,suspend,resumeи обработки непойманных исключений.
Что делать с Thread Locals?
- сейчас thread locals просто превращаются в fiber locals;
- с этим есть очень много проблем, все это обсуждается;
- особенно обсуждается набор способов использования;
- треды исторически использовали и правильно, и неправильно (те, кто используют неправильно, все равно на что-то надеются, и нельзя их совсем-то разочаровывать);
- в целом это создает целый спектр применений:
- Высокоуровневые: кэш коннекшенов или паролей в контейнере;
- Низкоуровневые: процессорные в системных библиотеках.
Сколько все это жрет

Thread:
- Стек: 1MB и 16KB на структуры данных ядра;
- На экземпляр треда: 2300 байтов, включая VMную метаинформацию.
Fiber:
- Стек континуации: от сотен байт до килобайт;
- На экземпляр файбера: 200-240 байтов.
Разница колоссальная!
И это именно то, что позволяет файберам запускаться миллионами.
Что может парковаться
Понятно, что самая магическая вещь — это автоматическая парковка при наступлении каких-то событий. Что сейчас поддерживается?
- Thread.sleep, join;
- java.util.concurrent и LockSupport.lock;
- IO: сетевое на сокетах (socket read, write, connect, accept), файлы, пайпы;
- Всё это недоделанное, но свет в туннеле виден.
Коммуникация между файберами
Еще один вопрос, который все задают: как конкуррентно обмениваться информацией между файберами.
- Текущий прототип запускает таски в
Runnable, можно переделать наCompletableFuture, если зачем-то нужно; - java.util.concurrent «просто работает». Можно шарить всё стандартным способом;
- возможно, появятся новые API для многопоточности, но это не точно;
- куча мелких вопросов вроде «должны ли файберы возвращать значения?»; всё обсуждается, их нет в прототипе.
Как реализованы континуации в прототипе?
На континуации накладываются очевидные требования: нужно использовать как можно меньше оперативной памяти, и нужно переключаться между ними как можно быстрей. Иначе не получится держать их миллионами. Основная задача тут — каким-то образом не делать полное копирование стека на каждый паркинг-анпаркинг. И такая схема есть! Попробуем объяснить это в картинках.
Самый крутой способ был бы, конечно, просто класть все стеки на джавовый хип и использовать их напрямую. Но это непонятно, как сейчас закодить, поэтому в прототипе используется копирование. Но копирование с небольшим, но важным хаком.
У нас есть два стула… в смысле, два стека. Два джавовых массива в хипе. Один — объектный массив, где мы будем хранить ссылки на объекты. Второй — примитивный (например, интовый), который будет обрабатывать всё остальное.
Сейчас мы находимся в состоянии, когда континуация собирается выполняться в самый первый раз.
run зовёт внутренний метод под названием enter:
И дальше выполняется пользовательский код, вплоть до первого вытеснения.
В этот момент выполняется вызов VM, который зовёт freeze. В этом прототипе это делается прямо физически — с помощью копирования.

Начинаем процесс последовательного копирования фреймов из нативного стека в джавовый хип.
Нужно обязательно проверить, держатся ли там мониторы или используется нативный код, или ещё что-то такое, что на самом деле не даст нам дальше работать.
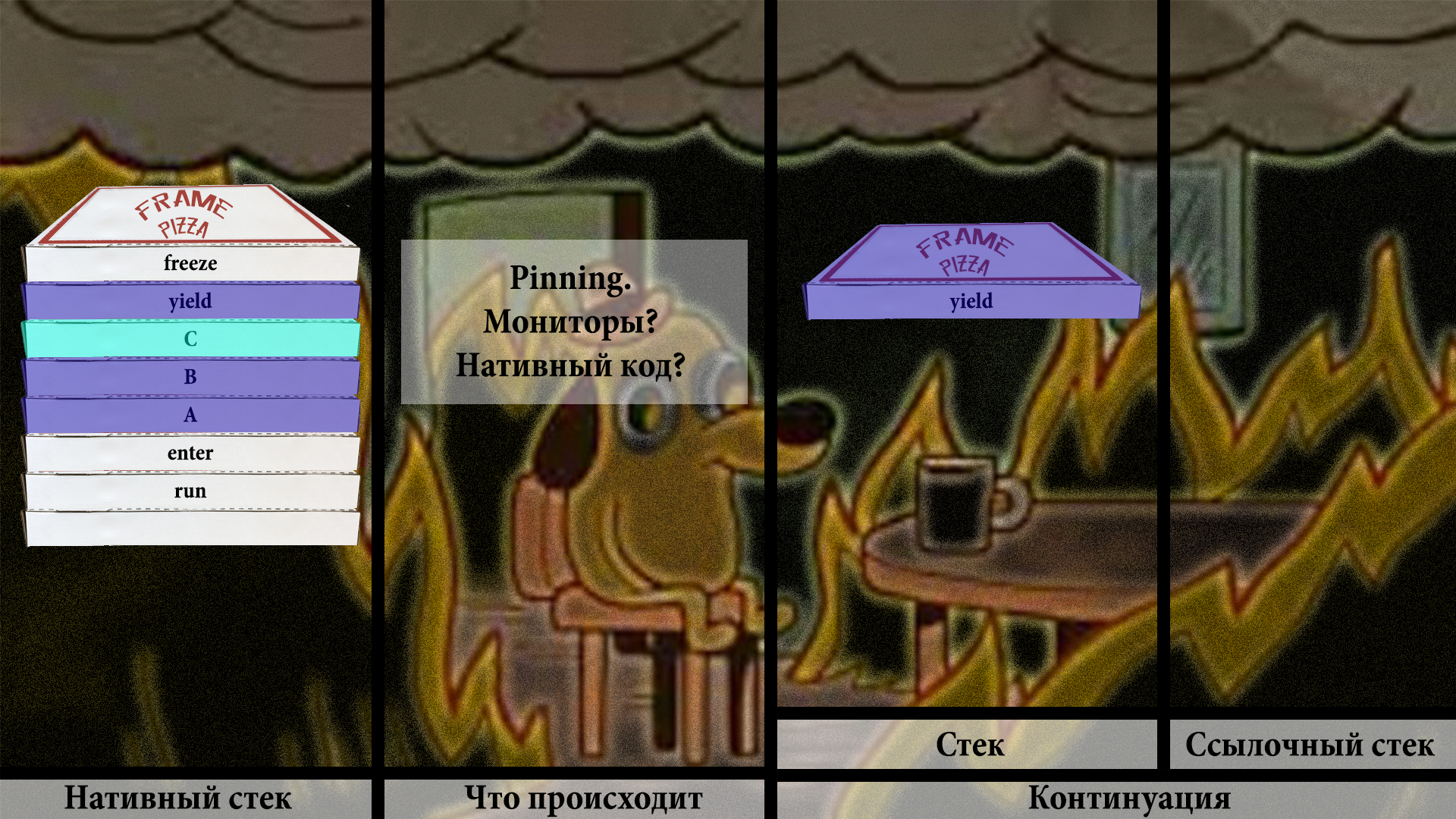
И если всё хорошо, мы копируем сначала в примитивный массив:

Потом вычленяем ссылки на объекты и сохраняем в объектный массив:
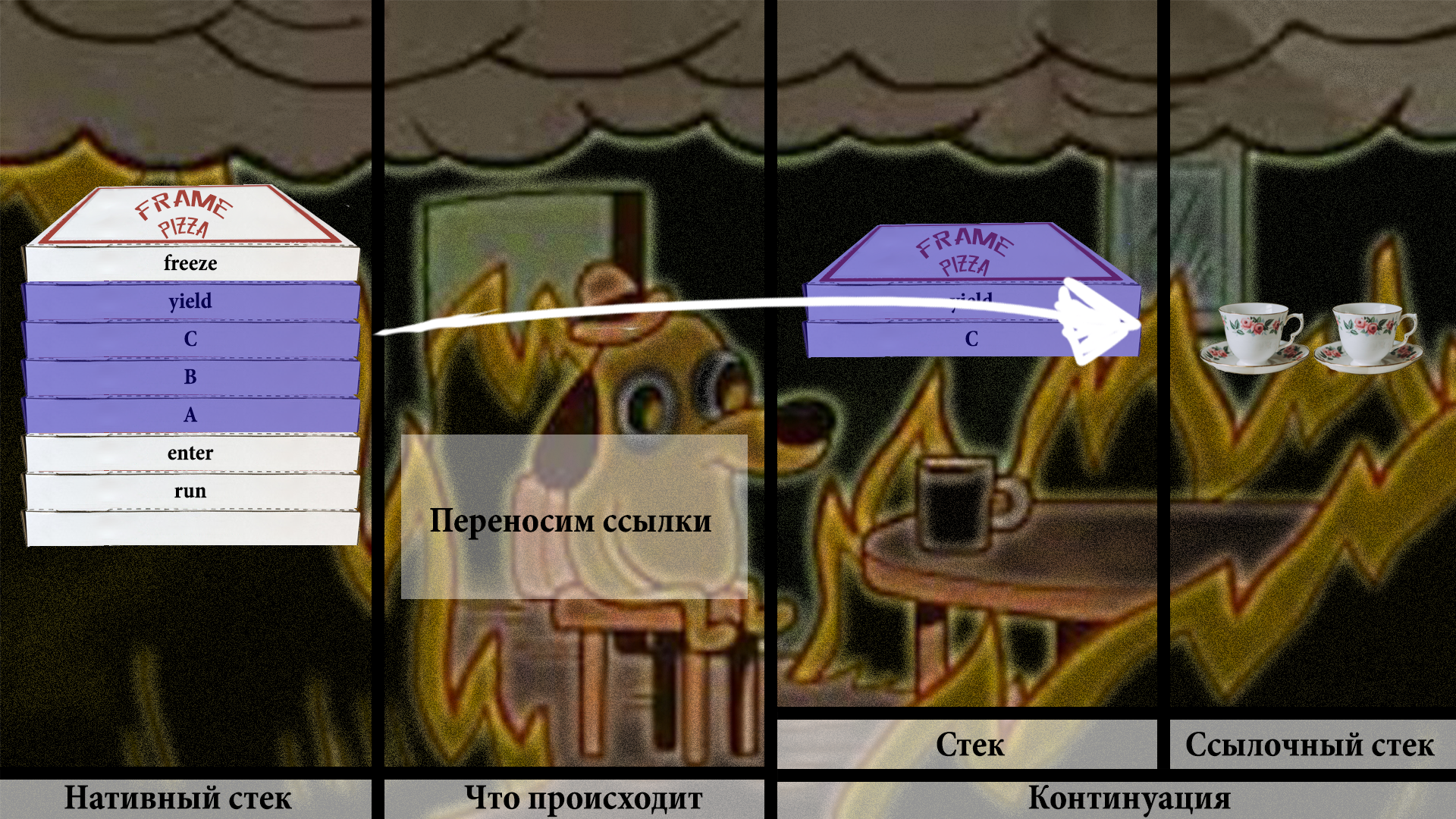
Собственно, два чая всем, кто дочитал до этого места!
Дальше мы продолжаем эту процедуру для всех остальных элементов нативного стека.

Ура! Мы всё перекопировали в заначку в хипе. Можно спокойно прыгать в место вызова, не боясь, что мы чего-то потеряли. Всё в хипе.
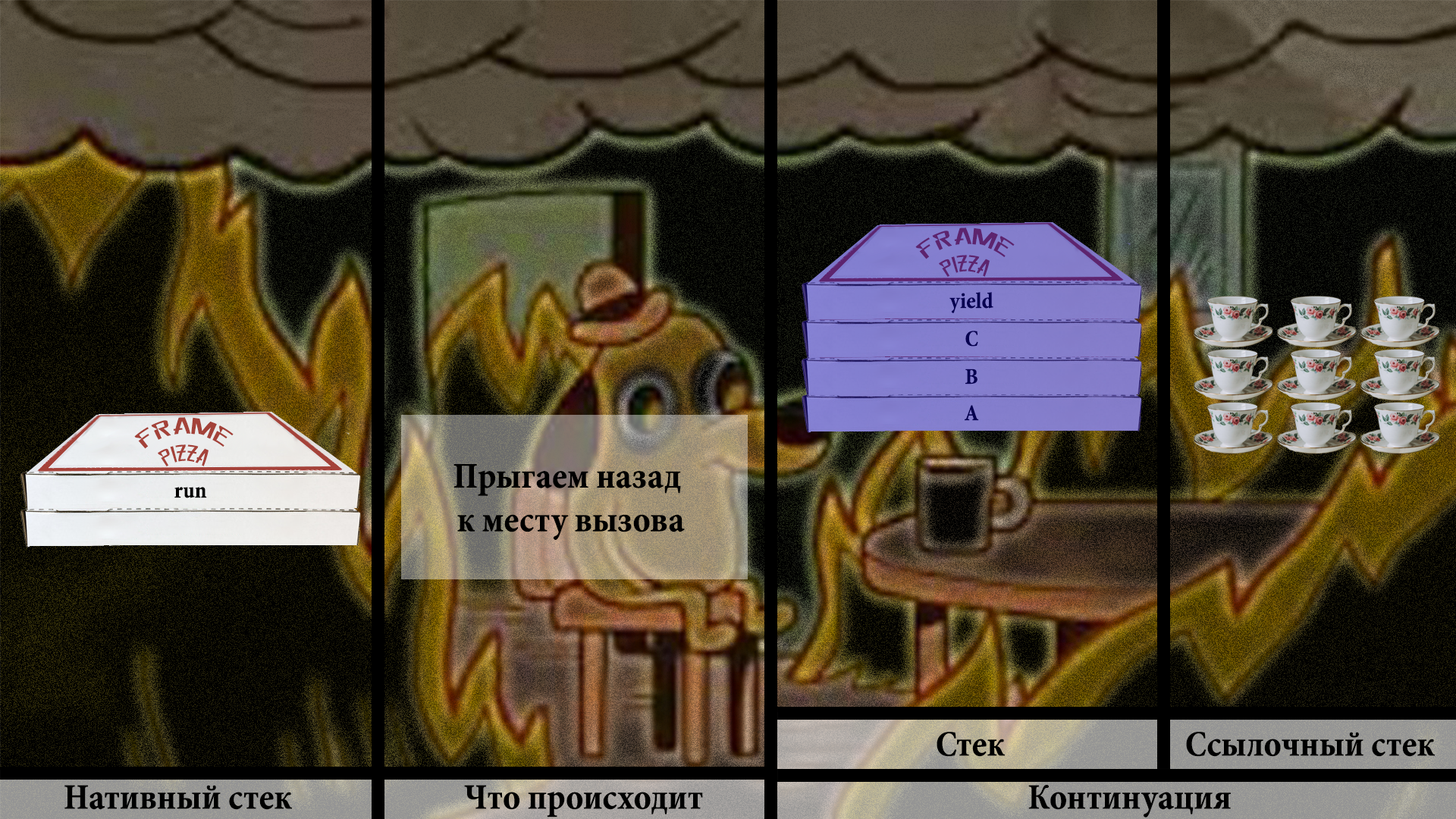
Теперь рано или поздно вызывающий код позовёт нашу континуацию снова. И она должна продолжиться с того места, где она была оставлена в прошлый раз. Это наша задача.
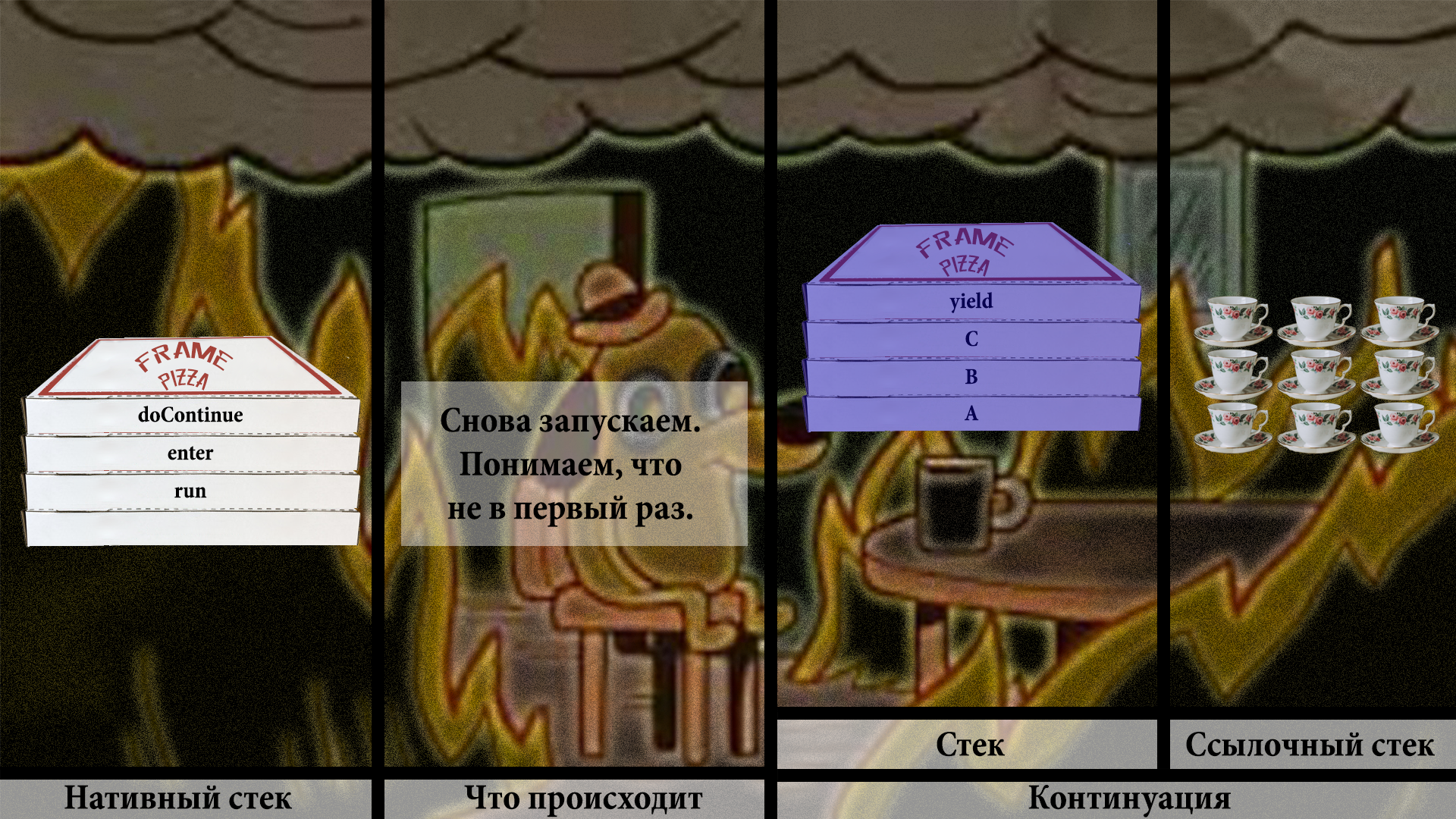
Проверка на то, запускалась ли континуация, говорит — да, запускалась. Значит, нужно позвать VM, почистить немного места на стеке и вызвать внутреннюю VM-ную функцию thaw. На русский «thaw» переводится как «оттаить», «разморозиться», что звучит вполне логично. Необходимо разморозить фреймы со стека континуации в наш основной нативный стек.
Не уверен, что разморозка чая выглядит достаточно наглядно. Плохая абстракция подобна котёнку с дверцей. Но нам и такая сгодится.
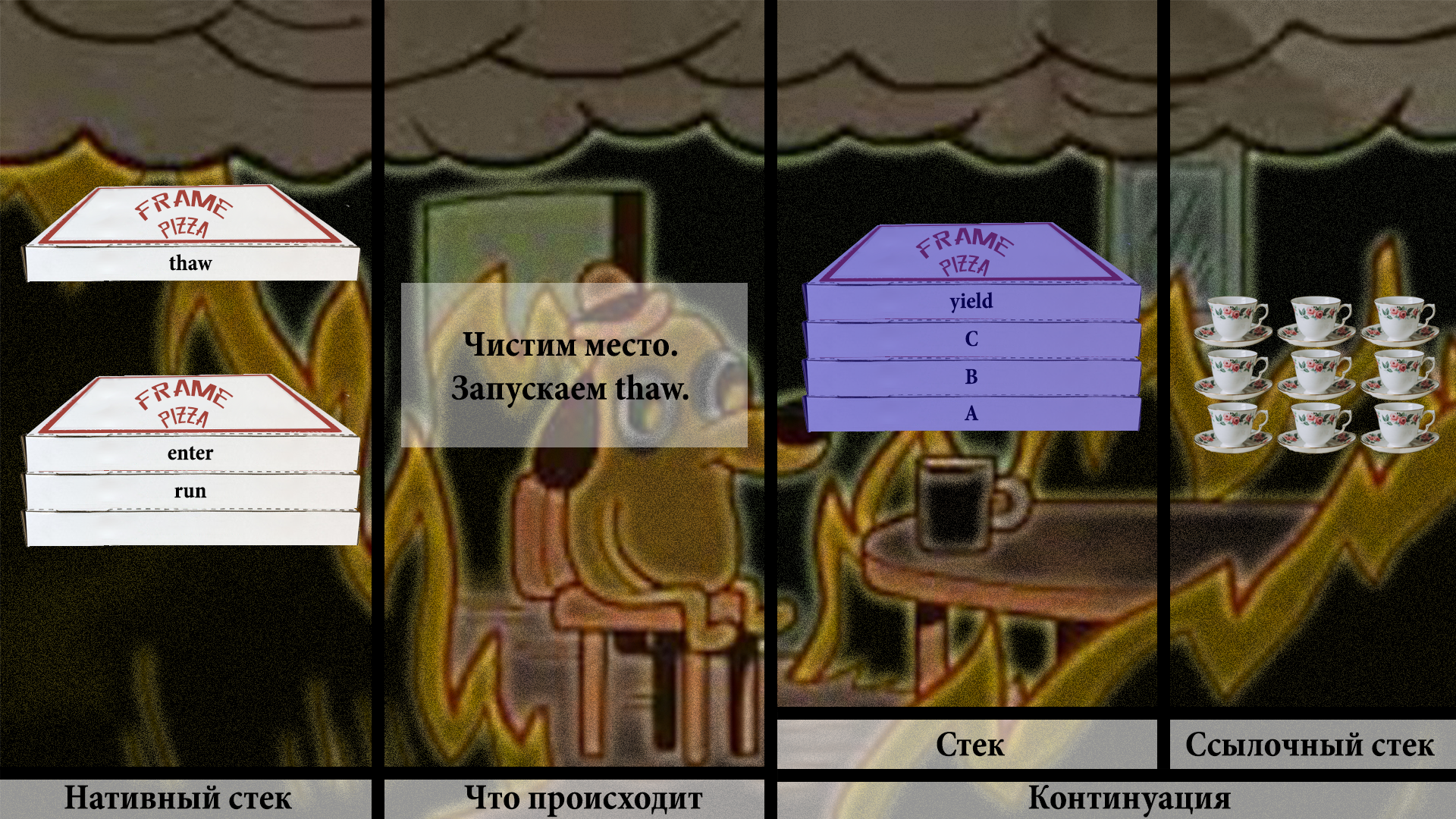
Производим вполне очевидные копирования.
Сначала с примитивного массива:
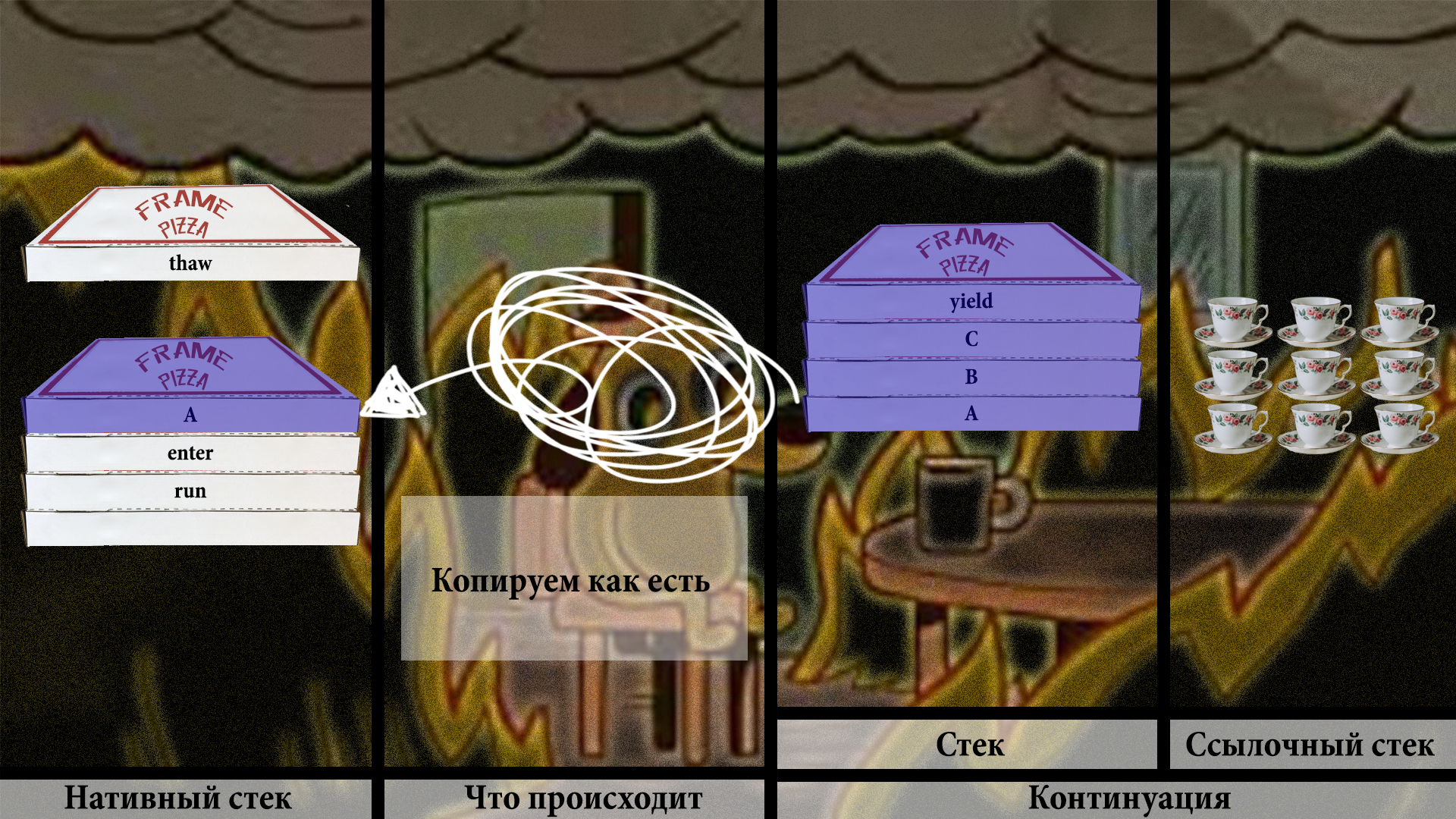
Потом со ссылочного:

Нужно немного попатчить скопированное, чтобы получить корректный стек:
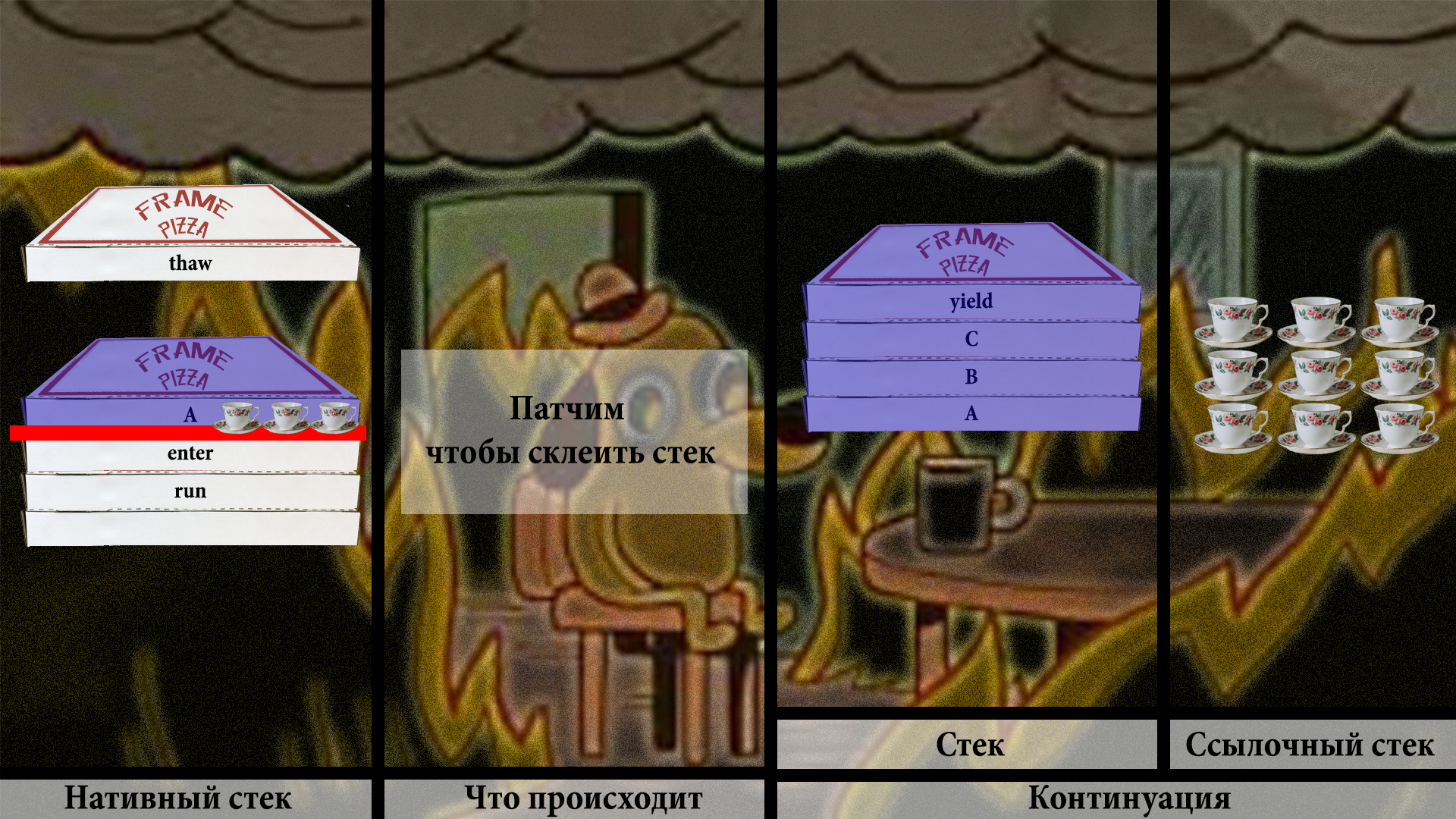
Повторяем непотребство для всех фреймов:
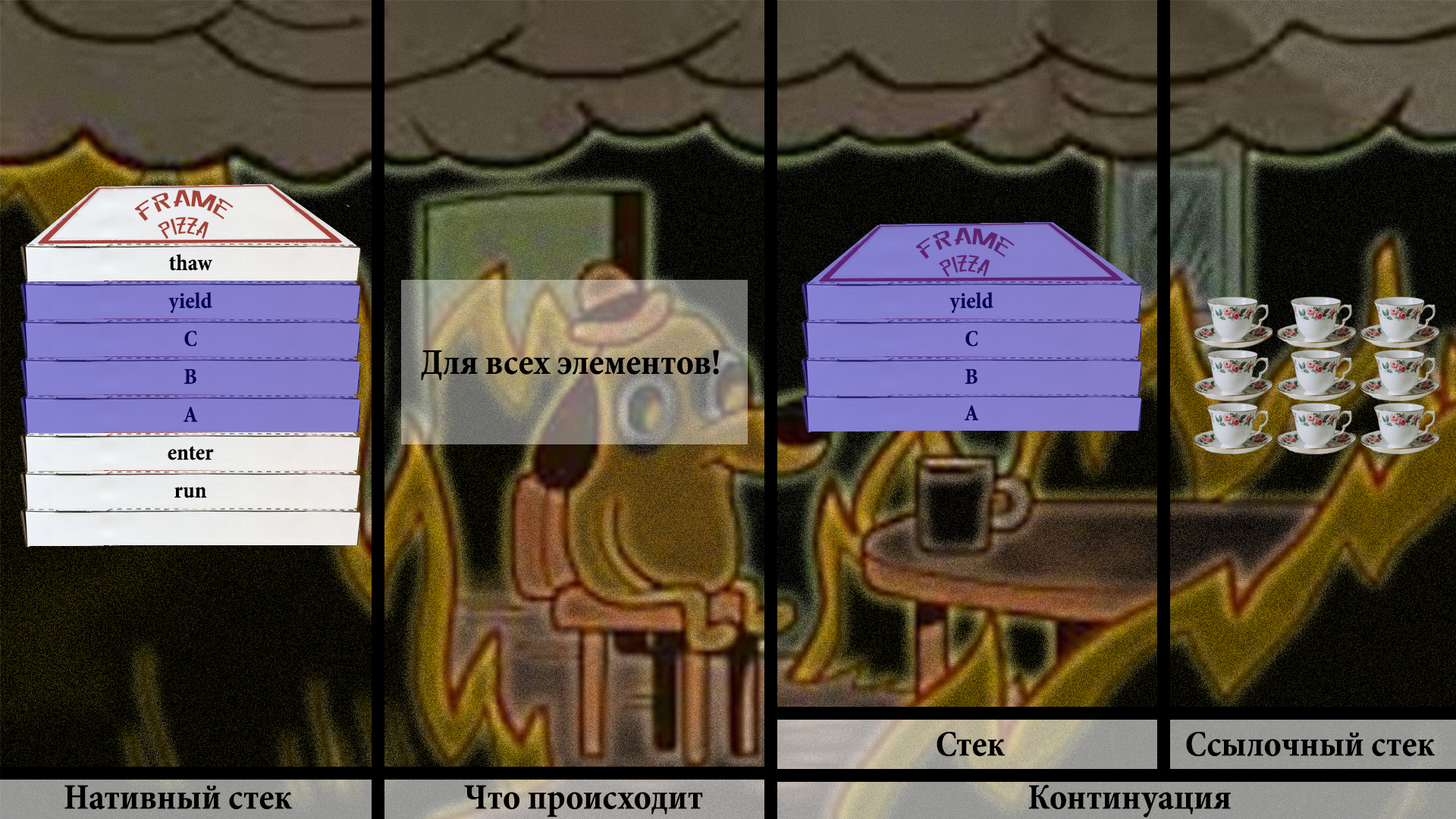
Теперь можно вернуться к yield и продолжить, как будто ничего и не происходило.

Проблема в том, что полное копирование стека — это совершенно не то, что нам хотелось бы иметь. Оно очень тормозное. Всё это вычленение ссылок, проверки для пиннинга, оно не быстрое. И главное — всё это линейно зависит от размера стека! Словом, ад. Не надо так делать.
Вместо этого у нас есть другая идея — ленивое копирование.
Давайте откатимся к тому месту, где у нас уже есть замороженная континуация.
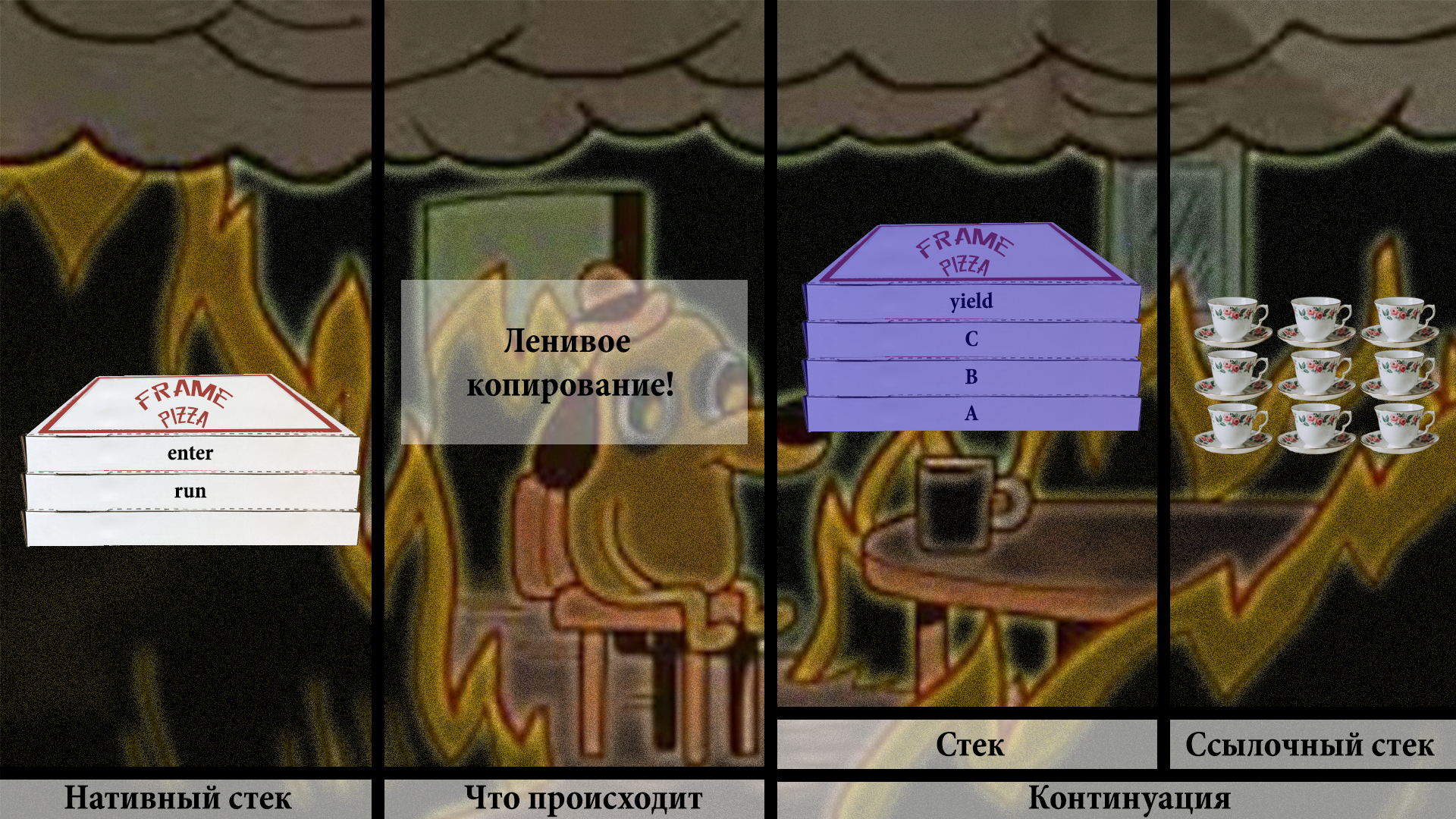
Мы продолжаем процесс так же, как и раньше:

Точно так же, как и раньше, чистим место на нативном стеке:
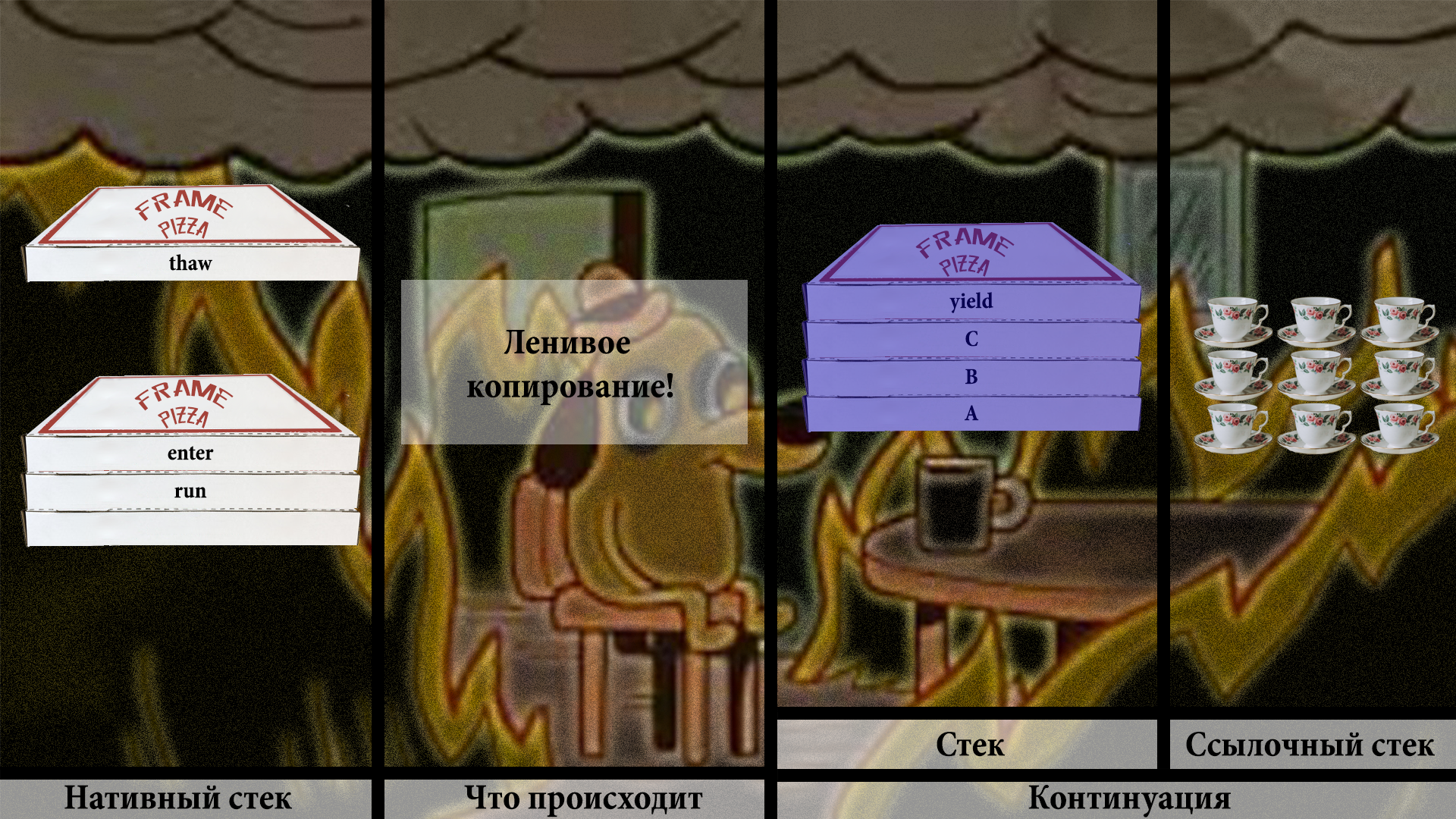
Но копируем не всё подряд, а только один или парочку фреймов:
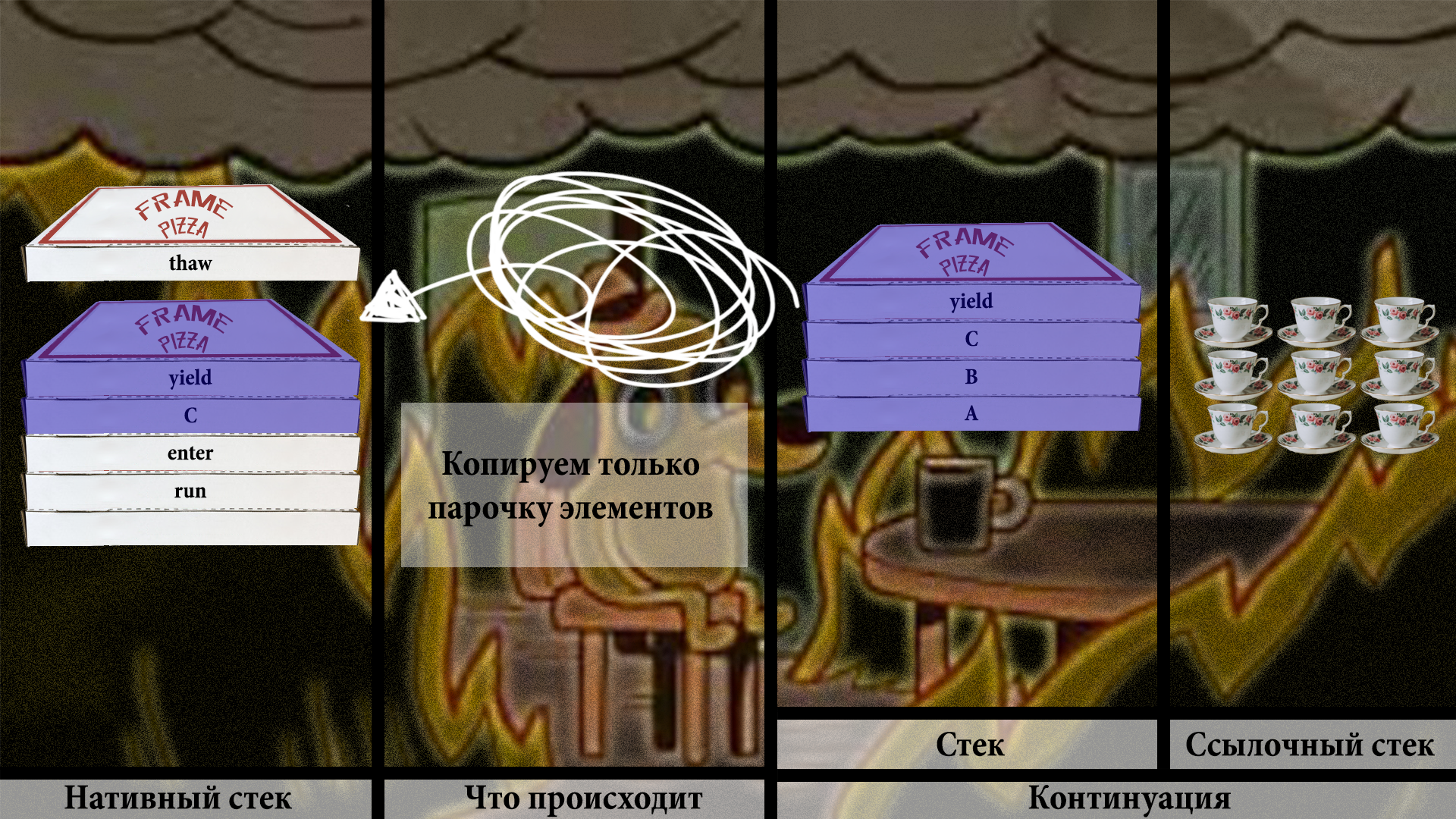
Теперь хак. Нужно пропатчить адрес возврата метода C, чтобы он указывал на некий return barrier:
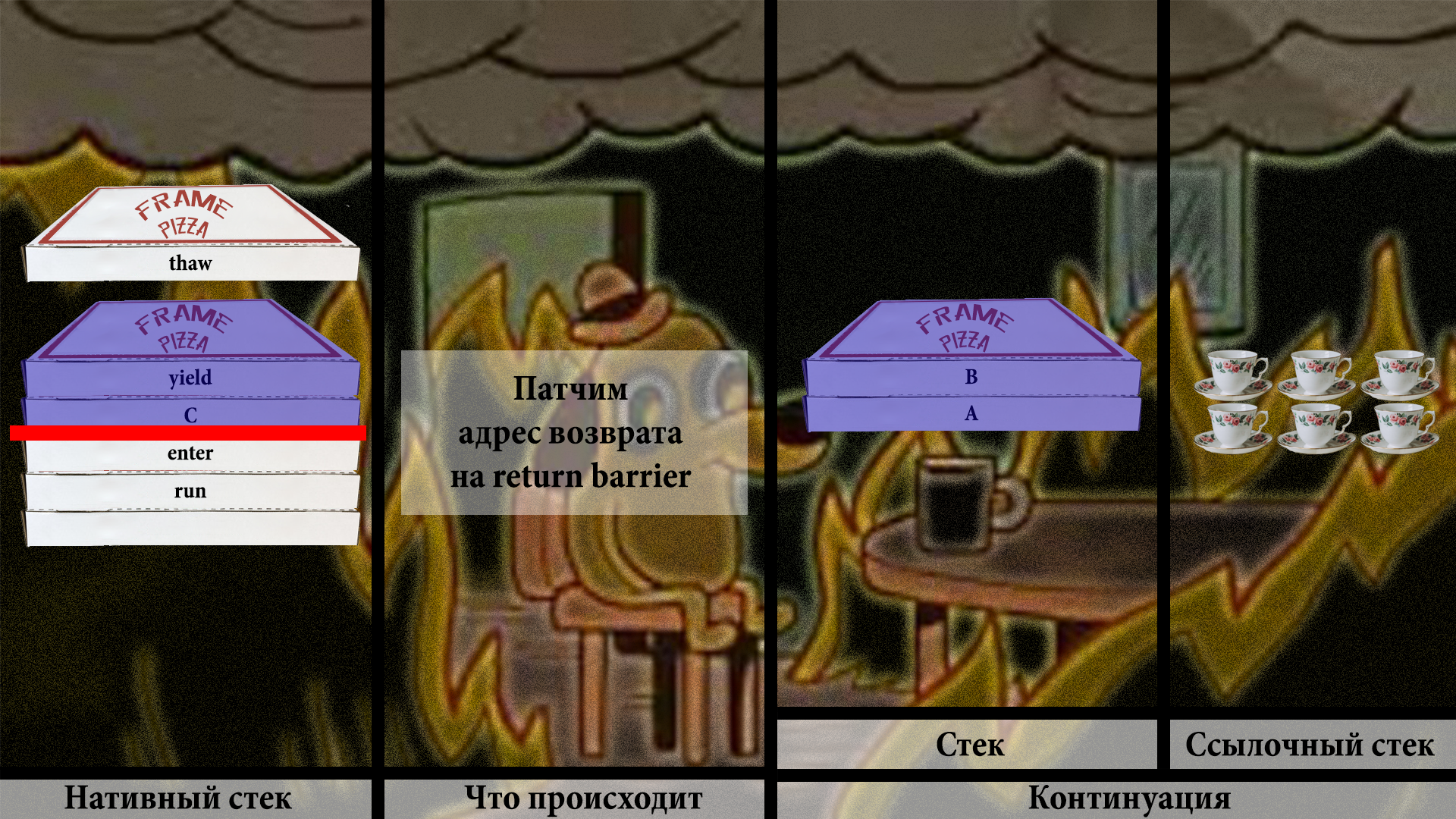
Теперь можно спокойно вернуться к yield:
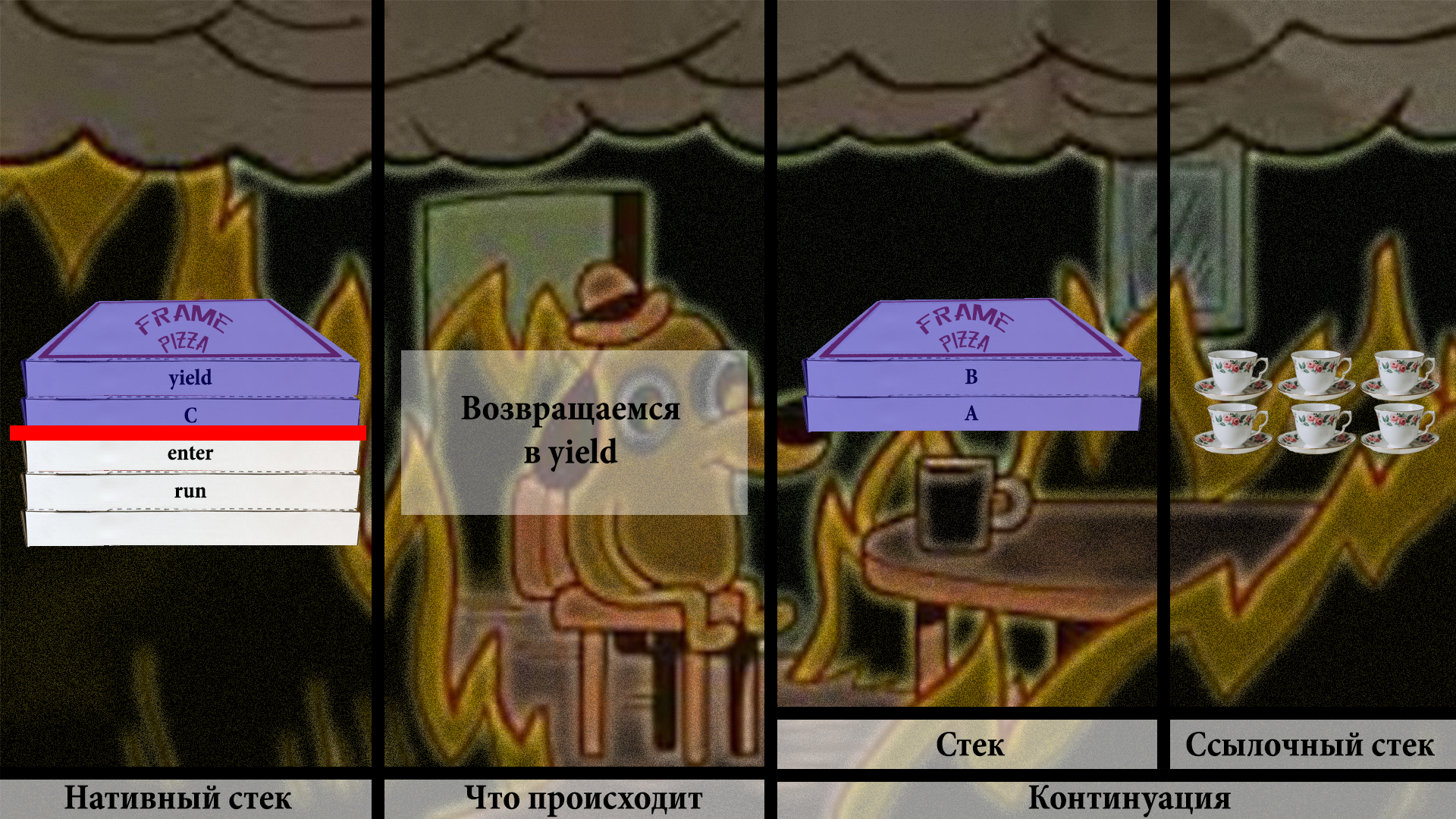
Что в свою очередь приведёт к вызову пользовательского кода в методе C:

Теперь представим, что C хочет вернуться к коду, который его вызвал. Но его вызывальщик — это B, и он не на стеке! Поэтому, когда он попытается вернуться, он пройдёт по адресу возврата, и этот адрес теперь — return barrier. И, ну вы понимаете, это снова потянет за собой вызов thaw:

А thaw нам разморозит следующий фрейм на стеке континуации, и это B:
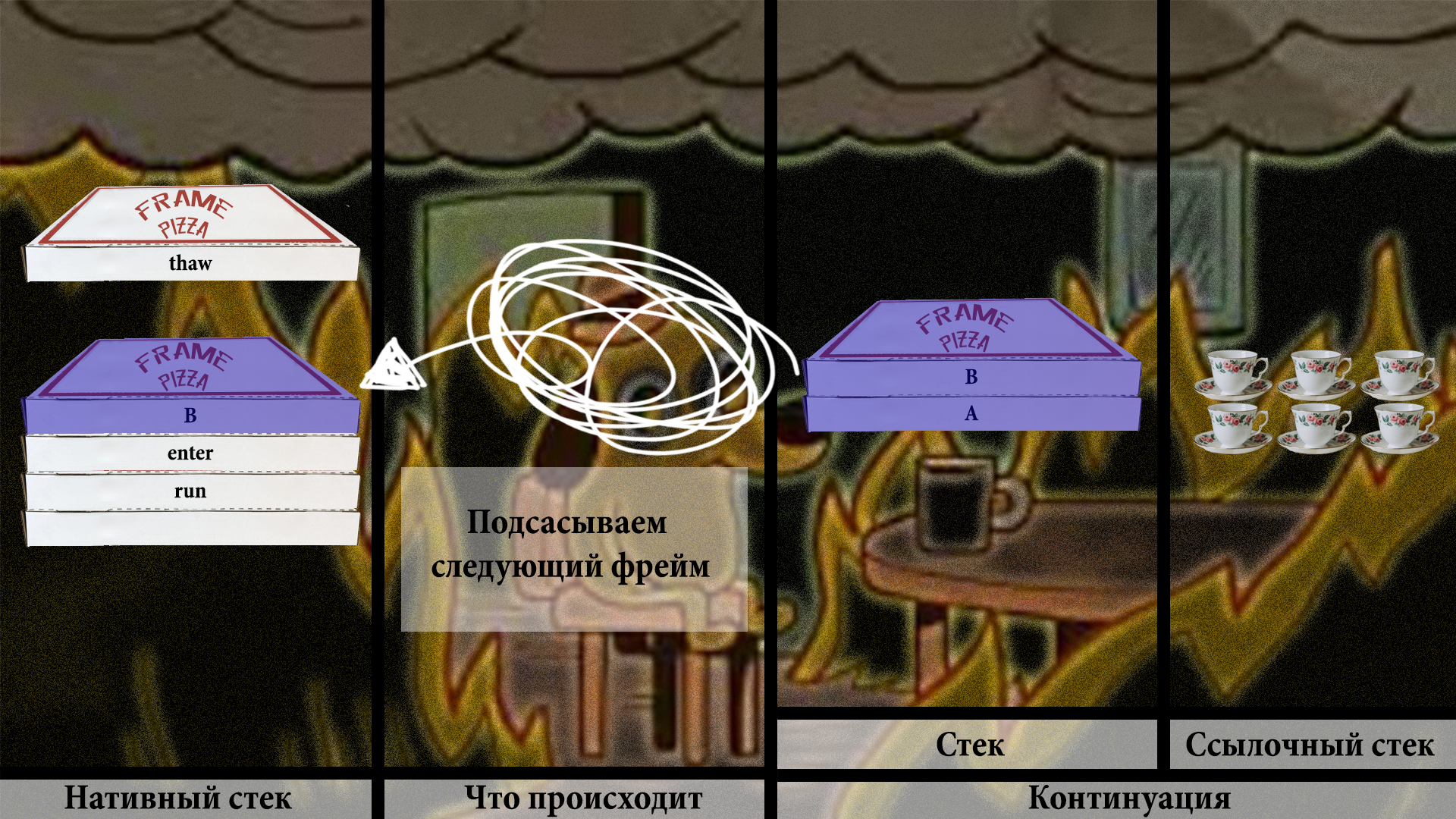
По сути, мы скопировали его лениво, по запросу.
Дальше мы сбрасываем B со стека континуации и снова устанавливаем барьер (барьер нужно ставить, потому что на стеке континуации кой-чего осталось). И так раз за разом.
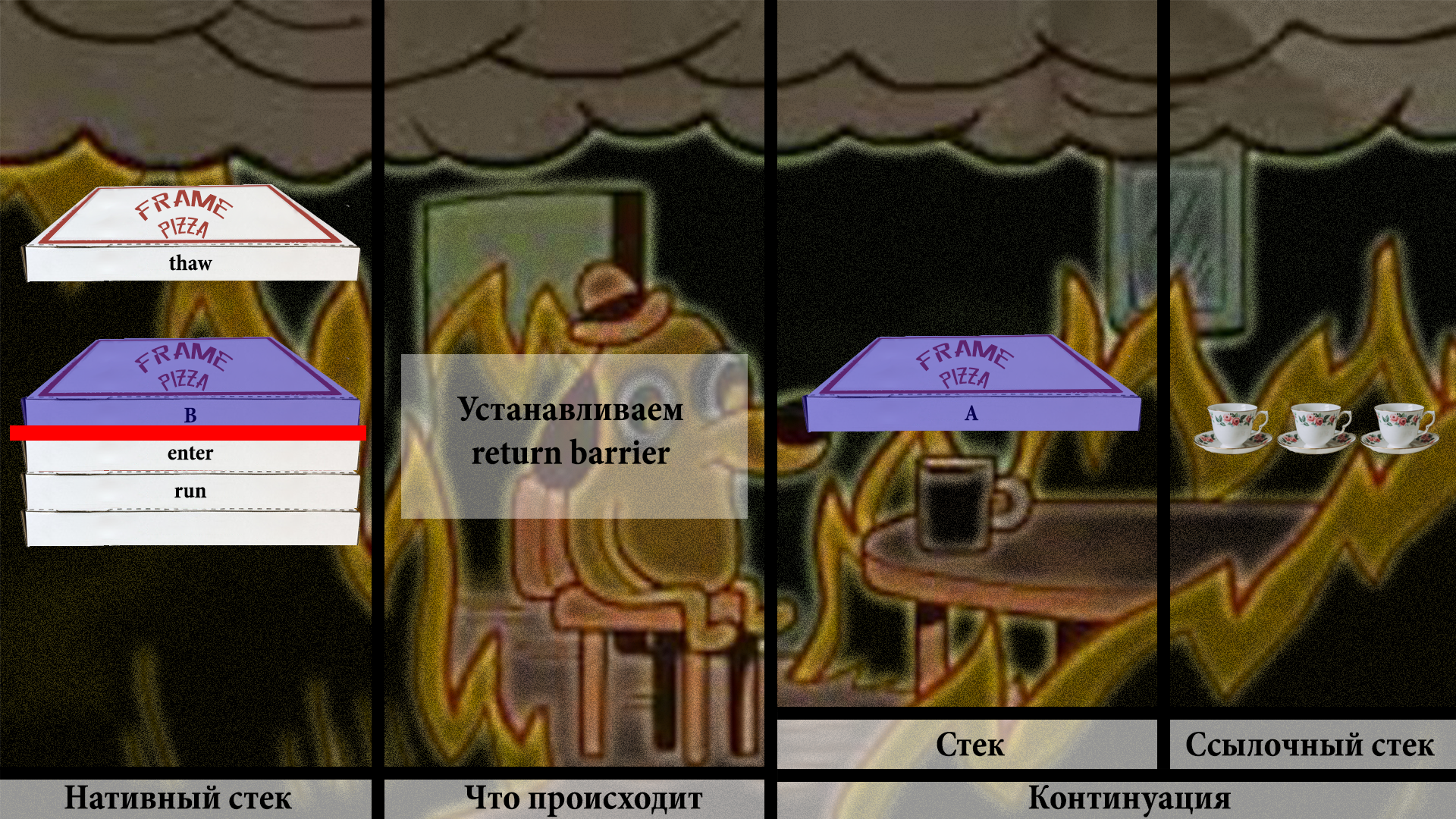
Но представим, что B не собирается возвращаться к вызывающему коду, а вначале зовёт какой-то другой метод D. И этот новый метод тоже хочет вытесниться.

В этом случае, когда придёт время делать freeze, нам нужно будет скопировать в стек континуации только верхушку нативного стека:

Таким образом, количество совершаемой работы не зависит линейно от размера стека. Оно линейно зависит только от количества тех фреймов, которые мы реально использовали в работе.
Что осталось?
Некоторые фичи разработчики держат в уме, но в прототип они не попали.
- Сериализация и клонирование. Возможность продолжить на другой машине, в другое время, и т.п.
- JVM TI и отладка, как будто бы они обычные треды. Если вы заблокировались на чтении сокета, то вы не увидите красивого прыжка из yield, в прототипе тред просто заблокируется, как и любой другой обычный тред.
- К хвостовой рекурсии даже не прикасались.
Следующие шаги:
- Сделать человеческий API;
- Добавить все недостающие фичи;
- Улучшить производительность.
Где взять
Прототип выполнен в виде бранча в репозитории OpenJDK. Cкачать прототип можно здесь, переключившись на бранч fibers.
Делается это так:
$ hg clone http://hg.openjdk.java.net/loom/loom
$ cd loom
$ hg update -r fibers
$ sh configure
$ make imagesКак вы понимаете, всё это запустит сборку всего чертового OpenJDK. Поэтому, во-первых, ближайшие полчаса вашей жизни придется заняться чем-то другим, пока всё это собирается.

Во-вторых, нужно иметь нормально настроенный компьютер с C++ тулчейном и GNUшными либами. Я намекаю, что всячески не рекомендуется делать это на Windows. Серьезно, даже со скачиванием VirtualBox и установкой новой Ubuntu туда вы потратите на порядки меньше времени, чем пытаясь осознать очередную негуманоидную ошибку при билде из Cygwin или msys64. Это тот момент, когда msys заходит даже хуже, чем Cygwin.
Хотя это, конечно, все ложь, я просто задолбался писать вам инструкции по сборке.
Если собираетесь чего-то менять в исходнике, рекомендую включить mercurial extension под названием fsmonitor. Прочитать, что это такое, можно командой hg help -e fsmonitor.
Для включения нужно добавить в ~/.hgrc такую строчку:
[fsmonitor]
mode = onМногие каким-то невообразимым образом умудряются испортить скачанный репозиторий в течение первых минут использования. Поэтому рекомендую на всякий случай сразу же после скачивания всю папочку скопировать куда-нибудь, cp -R ./loom ./loom-backup.
Как обычно, меняем место на жестком диске на возможные потерянные часы жизни. Думаю, что среднестатистический Java-разработчик получает достаточно много бабла, чтобы правильно расставить приоритеты в этом вопросе.
sh configure иногда будет просить что-то сделать. Например, если у вас свежеустановленная Ubuntu, то оно попросит установить Autoconf (sudo apt-get install autoconf). Это — одна из прелестей сборки OpenJDK на свежей Ubuntu, многие проблемы тебе уже рассказали, как решить. В Windows настолько же хороших подсказок не будет, если будут вообще.
Посмотреть, в чем разница между бранчами, можно командой hg diff --stat -r default:fibers.
В целом, подробный разбор увиденного в диффе заслуживает совершенно отдельной философской статьи, отдельного выпуска подкаста, и сейчас это обсуждать бессмысленно.
Заключение
Файбер в английском языке означает «волокно, нить». Отсюда слово «микрофибра», например. «Loom» — это «ткацкий станок». В Project Loom мы будем ткать свой код как полотно из файберов.
Но даже с этими нововведениями современное многопоточное программирование выглядит допотопно, потому что требует кучи дополнительных усилий и осознанности. То, что теперь мы можем запускать «треды» сразу миллионами, не означает, что думать вообще не надо — думать надо, но, к счастью, — сильно меньше.
Символично, что именно те, кто ткал на ручных ткацких станках в первой четверти XIX века бросились ломать автоматику, которая была тогда создана для дешевого производства чулок.

А у нас дешевое производство тредов. По-моему, аналогия прозрачна.
Надеюсь, однажды всё это будет заменено на ещё более простые и дешевые по отношению к мыслетопливу разработчиков механизмы. Всё это будет делать Искусственный Интеллект внутри IDE и так далее.
А в данный момент можно будет насладиться не только файберами, но и сочным бугуртом Свидетелей святой Конкарренси, которые расскажут нам, что всё это «не нужно», «тормозит», «вручную понятней» и так далее.
А что вы по этому поводу думаете? Напишите в комментариях. Порадуйте старого человека.
Спасибо.
Комментарии (139)

roman901
11.09.2018 16:21+1На самом деле уже начинаешь путаться в этих fibers, asyncio, корутины, etc…
Никак не могу найти хорошего материала, когда какую технологию использовать и как.
Я правильно понимаю — если читаешь много или пишешь в сеть/файл — лучше использовать fibers/async/coroutines + пул потоков (к примеру, как делает Netty + Executors.newFixedThreadsPool()); если же обрабатываешь много данных (к примеру, эмуляция игрового мира), то лучше разбить всё по обычным потокам?
Был бы безумно рад, если б кто кинулся какой-нибудь книжкой-умной статьёй :)olegchir Автор
11.09.2018 16:25Может быть, Рома elizarov Елизаров ответит :) У меня более обобщенный подход — надо изучать и пилить интересные штуки, а чего это и зачем — кому надо сам придумает применение.
roman901
11.09.2018 16:30+1У меня схожий подход, проблема лишь в том, что иногда приходится делать что-то для продакшна, и возникают вопросы по технологиям :)
Цитируя StackOverflow:
A Fiber is a lightweight thread that uses cooperative multitasking instead of preemptive multitasking. A running fiber must explicitly «yield» to allow another fiber to run, which makes their implementation much easier than kernel or user threads.
A Coroutine is a component that generalizes a subroutine to allow multiple entry points for suspending and resuming execution at certain locations. Unlike subroutines, coroutines can exit by calling other coroutines, which may later return to the point where they were invoked in the original coroutine.
A Green Thread is a thread that is scheduled by a virtual machine (VM) instead of natively by the underlying operating system. Green threads emulate multithreaded environments without relying on any native OS capabilities, and they are managed in user space instead of kernel space, enabling them to work in environments that do not have native thread support.
Я правильно понимаю, получается, что корутина прерывается только в момент await, а fiber — в момент, когда этот самый fiber говорит «я уже доделал»? Из статьи не особо понятно, чем этот подход отличается от конкретно корутин :)olegchir Автор
11.09.2018 16:35Отличаются — названием? Оракл — это такая особая компания, которая даёт привычным вещам свои собственные имена. Иногда они действительно значительно более простые и запоминающиеся, чем стандартная терминология. Не всем хотелось бы трогать руками склизкий холодный зигохистоморфный препроморфизм
roman901
11.09.2018 17:11+1Мне бы понять чем файбер от корутины с точки зрения прикладного подхода отличаются :) Понятно, что это не для perfomance-dependent вычислений, но есть ли какая-то особая разница между ними, к примеру, в обработке подключений клиента? Или по-факту одно и тоже, но по разному выглядящее?
olegchir Автор
11.09.2018 17:15Если ты обобщенном смысле (не про названия в java и kotlin), то основная разница в наличии или отсуствии планировщика. У файбера планировщик занимается переключением контекстов, у корутины никакого планировщика нет, и этим должен заниматься ты сам в ручном режиме, в создающем-вызывающем-уничтожающем корутину коде. И корутина может быть вообще никак не связана с тредами, а быть сильно связана с вызывающим кодом. Это просто нужно для разных способов использования. Но наверное, это очень сильно вопрос терминологии и используемой технологии — сейчас придут люди и скажут, что всё я вру.
mayorovp
12.09.2018 09:04Отличие в том, что сопрограммы («корутины») обычно не имеют своего стека вызовов. Это ровно одна подпрограмма которая посреди своей работы может приостановиться. Если одна сопрограмма вызывает другую, то вызывающая сопрограмма должна выбирать будет ли она приостанавливаться при приостановке вызываемой, и если будет — это нужно еще как-то реализовать.
Волокно (fiber) же — это легковесный поток. У него есть свой стек, и приостановиться он может на любом уровне вложенности. Достоинства волокон — при поддержке стандартной библиотеки их можно сделать полностью прозрачными для программиста (неотличимыми от потоков). Недостатки волокон — без таковой поддержки они получатся половинчатыми, плюс для них нужно выделять стек (последний недостаток как раз пытаются тут устранить хитрым копированием).
loltrol
12.09.2018 12:45+1Очень просто:
- много IO, мало вычислений — lightweigh треды
- много вычислений, мало IO — обычные треды
- очень много вычислений — смотреть в сторону горизонтального масштабирования
Но в реальном мире простого не бывает, поэтому зависит от ситуации :)
HandleX
11.09.2018 19:11+6Smalltalk, 80-e. Green Threads, Continuations «из коробки»...
olegchir Автор
11.09.2018 20:17Интересно, что какого-то дикого безумного запроса на эту фичу не было. Люди не кричали от боли, не бросались на разработчиков жавы «где наши файберы, умираем без файберов». Как набралась критическая масса — так сразу и запилили, и года не прошло.
HandleX
12.09.2018 00:57Процессы в Smalltalk-VM суть ваши файберы сразу, иных механизмов многозадачности там нет. Компы в то время были большие, программы маленькие, и потоки — легковесные ;)
sshikov
11.09.2018 20:20+2Меня вот что смущает. Идея continuations — она совсем не нова, и растет кажется из лиспа(ов), т.е. лет ей дай боже.
Если просто погуглить + java + continuations, то вы на первой же странице увидите, кроме Loom, еще парочку проектов, один из которых был сделан аж в 2007. И что-то никто особо не впечатлился. Вопрос — а почему, собственно, в этот раз должно взлететь? В чем разница-то, если в этом проекте работы осталось начать да кончить?olegchir Автор
11.09.2018 20:38О каком проекте идет речь, можно ссылочку?
Сейчас в Kotlin сделали корутины и впечатлились… ну, можно сказать, все кто может использовать Kotlin. Впечатлились все. В golang есть горутины — и это одна из топовых причин, зачем вообще юзать голанг.
Что касается языка Java. Нормально без хаков в рантайме этого никак не сделать, и все кто делал — получали что-то наполовину нерабочее. В том же котлине вообще не подразумевается, что есть какой-то 20-летний легаси, который надо заставить работать без изменений и пересборки. В той же алибабе это хак виртуалки, причём прямолинейный и дорогой, и они жутко мучаясь поддерживают форки, насколько понимаю.
Здесь же это официальный проект компании Оракл, которая выделила на это лучших инженеров и бабло. Его на фуллтайм ведёт человек, который уже однажды сделал Квазар и имеет успешный опыт. Плюс поставлены вполне конкретные задачи — сделать не как попало, а сохранить главную отличительную фишку платформы Java — совместимость с legacy кодом. Все несовместимости в API, все корнер-кейсы — к этому относятся не как к мелочи, а как к важнейшим аспектам вопроса.
Плюс в целом, дозрела культура разработчиков. Пришло глобальное понимание о нужности таких штук.sshikov
11.09.2018 21:00rifers.org/blogs/gbevin/2005/9/23/announcing_rifecontinuations
Ну вот скажем пост от 2005 года.
>Нормально без хаков в рантайме этого никак не сделать, и все кто делал — получали что-то наполовину нерабочее.
Я боюсь, что и с хаками это нормально сделать сложно. Не так чтобы работало, а так, чтобы было совместимо с легаси.
>Здесь же это официальный проект компании Оракл, которая выделила на это лучших инженеров и бабло. Его на фуллтайм ведёт человек, который уже однажды сделал Квазар и имеет успешный опыт.
Ну, к сожалению в общем виде деньги еще ничего не гарантируют. Опыт — это чуть лучше, но это ограниченный опыт одного человека. Или даже группы.
>и в большой картине всего это, скорее, достижение.
Ну да, и? Но я вот впервые от вас слышу про квазар, что как минимум говорит о том, что по популярности ему пока далеко даже до котлина. Поймите меня верно, я только за то, чтобы встроить continuations, но меня смущает тот факт, что оракл запилил уже 10 версию JDK, а народ при этом массово сидит скажем на 8, и никуда, заметьте, мигрировать не спешит. И этот народ — например все, кто на хадупе, ага. Далеко не самые глупые люди. То есть, их способности в целом, как компании, прогнозировать нужность тех или иных фич — они далеки от идеала, не потому, что они там глупые, а потому что задача уж очень сложная — сохранить совместимость, и угодить всем.olegchir Автор
11.09.2018 21:21+1сохранить совместимость, и угодить всем.
да, поэтому этой задачей и занимаются лучшие в мире разработчики из компаний Oracle, RedHat, IBM, и других разработчиков OpenJDK. Они сделали Java 8 такой, что на неё очень скоро переползли все. И да, когда появлялась Восьмерка, точно так же ныли: "да мы ещё на Шестёрке, куда столько версий"
я тоже когда-то жил в каком-то узком мирке, наполненном людьми ленивыми и очень боязливыми, уставшими от жизни. Понимаю, о чем вы. К несчастью, эти выгоревшие люди имели большие тайтлы вроде "самый главный старший архитектор всего" или "директор директоров по управлению управлением". И они рассказывали эти унылые душные басни о том, что Java 6 это наше всё, а с Hibernate x.x.y на x.x.(y+1) переходить — это капец какое предприятие. Проблема не в технологиях (которые на самом деле дают большие возможности делать крутые вещи — например, файберы экономят огромное количество денег), проблема вот в таких людях
и вот знаете что, я в 2018 у меня всё замечательно, а половина этих нытиков или обанкротилась или ушла на пенсию и теперь пасёт гусей
так что, наверное, я не самый верный человек для того, чтобы обсуждать как всё плохо, и что ваше большое начальство рассказало о том, что вы вечно будете на Java 8. Чемодан — вокзал — современная клёвая компания, которая сможет воспользоваться преимуществами новейших разработок в JDK, всё что могу посоветовать :-)
а на JDK 10 переходить действительно не стоит. Сейчас JDK будут обновляться либо раз в полгода (для обычных компаний), либо раз в 3 года LTS (для совсем кровавых замшелых ынтерпрайзов). И тем и другим сейчас нужно переходить на JDK 11, это новая точка отсчёта для всех
sshikov
11.09.2018 21:27>так что, наверное, я не самый верный человек для того, чтобы обсуждать как всё плохо, и что ваше большое начальство рассказало о том, что вы вечно будете на Java 8.
Расскажите это авторам хадупа. И не надо выдумывать всякую фигню про начальство, если вы просто не в курсе — это не зазорно, уж поверьте.olegchir Автор
11.09.2018 21:55Зачем им это рассказывать, они уже давно портировали его на jdk9, а сейчас полным ходом переходят на jdk11, судя по их же джире.
sshikov
12.09.2018 19:34Давно портировали? Гм.
Fix Java 9 incompatibilies in Hadoop
Status:OPEN
Resolution: Unresolved
Affects Version/s:3.0.0-alpha1
Fix Version/s: None
Component/s: None
Environment:Java 9
Вы хоть открыли ту ссылку, которую давали?olegchir Автор
12.09.2018 20:19Сейчас в OpenJDK незакрытых багов из основного списка — двадцать тысяч, из них три с половиной тысячи относятся к стабильной версии — JDK 8 (конечно, ни одной P1, 13 штук P2, но уже 751 P3 и тысячи по мелочи).
Это вы еще не видели, сколько их в JDK 11!
Наличие открытых багов не является причиной для неиспользования.
sshikov
12.09.2018 20:55Умением читать jira как раз и отличается практикующий программист от евангелиста :)
То что вы прислали — это не баг, это Task по устранению несовместимости. И она не сделана (как и связанные задачи, кстати). Более того, судя по пустым Fix Versions — ее даже не планировали пока сделать, т.е. не известно, в какой версии она будет готова.
Я уже молчу про то, что Affects Version/s: 3.0.0-alpha1 — т.е. если даже и начнут исправлять — то вероятно исправят в третьей ветке, которая промышленным кластерам в ближайшее время не светит.
На основной странице документации явно написано, что протестированные версии JDK — это 7 и 8, с явным указанием конкретных билдов. Ровно тоже самое пишут на сайте Cloudera.
Я непосредственно являюсь хадуп разработчиком, и для нас никакой поддержки Java 9 пока нет, и не предвидится. Моя личная оценка — пройдет еще года два минимум (наш пром кластер, как и остальные, пока работает на версии 2.6 хадупа, в планах в лучшем случае миграция на 2.8), и в первую очередь потому, что это нафиг никому тут не нужно, ибо никакого профита даже не обещает.olegchir Автор
12.09.2018 21:16Я действительно не в курсе вашей ситуации, возможно там все действительно так серьезно.
У меня никогда в жизни особых проблем с этим не возникало. В смысле, я постоянно сижу на альфа-версиях всего, и да — очень часто бывает что в Spring после апдейта отваливаются нужные фичи и приходится чинить их дрожащими руками долгими одинокими ночами. Но в этом и есть кайф от жизни лично для меня — быть на острие bleeding edge и быть в первых рядах early adopters всего.
Даже вот эта статья, глядите — она о фиче, которая появится может через год, а может через два. Как только она будет работать в сколько-нибудь удобоваримом виде, я мгновенно попытаюсь заиспользовать ее где-нибудь на практике :)
Если бы я был разработчиком на всем этом хадуповом деле, в свое свободное нерабочее время я попробовал бы запустить это на JDK 11 и посомтреть, что отвалится. Потом найти соответствующие тикеты в джире (или зарепортить их, если их еще нет), и потом попроовать последовательно их исправить, пользуясь помощью разработчиков мейнлайна. Потом можно будет прийти на конференцию и рассказать об этом всем. Вполне может оказаться, что там и проблем-то не так много как кажется вначале.
OpenSource — это о том, что если не работает — пойди и сам сделай. Если нет документации к Project Loom — пойди и напиши ее сам на Хабру. Если нет описания патчей — пойди и прочитай дифф между default и fibers и оформи ее в виде статьи на хабр. Если что-то не работает на JDK 11 — пойди и переведи это на JDK 11 сам. Любая другая позиция лично для меня воспринимается как нытье :-)sshikov
12.09.2018 21:32+1Это нормальный взгляд на жизнь, не имею ничего против. Просто он не единственный.
>Любая другая позиция лично для меня воспринимается как нытье :-)
Ну вот у нас даже есть начальник, у которого позиция примерно такая как у вас. Я его энтузиазм даже вполне понимаю, вот только есть еще и бизнес, которому интересны его задачи. И да, можно подумать, что обычные бизнес-задачи — не интересные. Как бы не так (хотя конечно, бывают всякие)!
А перевод хадупа на java 11? Какой в этом бизнес смысл? Если он и есть — он очень сильно опосредованный. Во всяком случае для такой экосистемы, как хадуп, где и без Java найдется десятки продуктов, которые заслуживают того, чтобы обновиться на новую версию: собственно Hadoop/HDFS, Hive, Spark, HBase, Oozie, Sentry, ну и так далее по списку.
sshikov
12.09.2018 19:51А вторая ссылка вообще ведет на tomee. К хадупу это никаким боком не относится, так что про версию 11 все так же непонятно, как и было.

transcengopher
12.09.2018 00:17+1Мигрировать с Java 8 сейчас очень больно, ведь модули — это немалое переосмысление сборки рантайма, а кроме модулей в Java 9 почти ничего и нет (вот кому надо было это «почти ничего» — те закусили пулю и перешли, у остальных «и так работает»).
Вместе с тем, много инструментов разработки с серьёзным отставанием реагировали на обновление версии языка, и отставанию сильно помогло упомянутое выше переосмысление. Ну там было… и проблемы с производительностью, и с потреблением памяти, и даже весьма мистическое предупреждение "(Recovered) Internal inconsistency during lambda shape analysis" — всё на коде, написанном весьма даже по JLS, и вроде даже людьми сдавшими OCP-8. Сейчас-то они[инструменты] уже, может, и догнали, а только хайп ушёл на спад. В итоге вот и приходится сгонять народ с Java 8 драконовскими датами end of life.
Ну, это моё видение ситуации.sshikov
12.09.2018 19:55Мое видение еще проще: я не занимаюсь скажем мобильной разработкой, а для серверных продуктов не видел никогда и не вижу никаких применений для jigsaw. Все случаи, когда было нужно модульность, прекрасно и давно покрыты OSGI.
При этом OSGI делает практически все тоже самое, но на более позднем этапе — в runtime. В итоге изменения, которые требуются в сторонних модулях, сводятся как правило к нулю. Никакой перекомпиляции, пересборки и прочее вообще не нужно.olegchir Автор
12.09.2018 20:40jigsaw сделана в первую очередь для разработчиков JDK. Если бы вы были разработчиком JDK, вы бы такого не написали. OSGi в контексте разработки JDK особого смысла не имеет, хотя бы потому, что несовместима с AOT-компиляцией и вообще не про то
вам как пользователю jigsaw нужен опосредованно. Благодаря нему джава не умрет в ближайшие пять лет, а просуществует еще следующие 10 лет. А там будет еще какой-нибудь большой рефакторинг, а через очередные 10 лет — еще и еще, что позволит джаве жить условно вечно
sshikov
12.09.2018 21:24>Если бы вы были разработчиком JDK, вы бы такого не написали.
Хм. Может им еще скинуться на бедность?
Это разработчикам JDK еще нужно подтвердить, что их решения были правильны.
Что такого нового было еще в Java 9 и 10, чтобы на них вообще имело смысл переходить? Хоть что-то уровня lambda или stream из 8-ки назовете, такое чтобы must have? Грааль? Не тянет, при всей интересности. Новый GC? Тоже не тянет. Релизы раз в полгода? Так это решает их проблемы, а не наши.
Более того, даже если оракл забросит всю разработку прямо завтра — java ни при каких условиях не умрет через 5 лет, да и через 10 тоже. Просто мы «вечно» будем жить на какой-нибудь ibm j9 (которая к слову v8).
P.S. Лично я давно зарекся делать хоть какие-то прогнозы в IT на сроки больше 5 лет. Не сбывается.olegchir Автор
12.09.2018 21:26Новые релизы решают ваши проблемы — они чинят баги (которых напомню — двадцать тысяч только открытых), и понемножку добавляют новые фичи. Мой прогноз следующий: те кто привыкнут обновляться раз в полгода на каждую новую версию — будут в шоколаде, все остальные будут ныть, ничего не понимать, а каждый переход на новый LTS будет полным адом и светопреставлением. В результате на шестимесячные обновления перейдут все, кроме кровавых ынтерпрайзов и отчаянных садомазохистов. Не нужно задумываться, зачем мигрировать на новую версию — это просто НАДО, все уже решили за тебя.
sshikov
13.09.2018 19:35Ну вообще-то нет. Я не помню, чтобы кто-то с багами вот так работал. Скажем, в моем личном списке багов 8-ки на сегодня ровно одна штука — падает javac на сборке одного из сторонних проектов (вроде java unrar). И это относится к сборке 144 (рекомендованной клоудерой для хадупа). Но поскольку собрать я спокойно могу сборкой 171, я это и сделал, таким образом, багов в JDK 8 для меня на сегодня не существует.
Поэтому обновления на новые версии, для проектов в проме, а тем более 24*7, обычно в моей окрестности выглядят так — обновления безопасности накатываем срочно (причем с этим безопасники сами прибегают), остальные — читаем release notes и смотрим, что нас затронуло. Если ничего — то не накатываем вообще, ибо нефиг тратить свое время, и ловить возможные новые баги. Лучше уж жить со старыми, известными.
Такой режим, как вы предлагаете, наверное может себе позволить кто-то вроде гугля, у которого куча серверов, часть из которых может безболезненно отвалиться в любой момент, и на них можно протестировать все что угодно, потому что никто не заметит.
transcengopher
12.09.2018 22:27Почему бы благородному дону не сделать OSGi поверх jigsaw? Ведь сами же и сказали — OSGi делает часть проверок позже, чем jigsaw. Следовательно, если среда OSGi может доказать, что проект построен поверх jigsaw, часть собственных проверок она имеет право превратить в «arg0->true», и под это дело немного разгрузить runtime.
Вот и нашлась одна из причин, а дальше — главным образом, весы с контрпримерами, и вопросы о цене интегрирования.sshikov
13.09.2018 19:18>Почему бы благородному дону не сделать OSGi поверх jigsaw?
Не вижу особого смысла.
>часть собственных проверок она имеет право превратить в «arg0->true», и под это дело немного разгрузить runtime
Не уверен. Собственные проверки — это по большей части чтение метаданных бандла, чтобы понять, какие пакеты экспортируются и импортируются. До 9 это было только в METADATA.MF. Насколько я знаю, например karaf уже поддерживает Java 9. И в моем понимании эта поддержка должна бы включать чтение данных о модулях jigsaw, и преобразование их неким образом в совместимую метаинформацию, чтобы опять же решить, что импортировать и экспортировать. Но все это все равно будет делаться при деплое бандла. Где тут может быть разгрузка, если бандлы деплоятся, стартуют, и пр. исключительно в рантайме?
В принципе, авторы декларируют работоспособность карафа под JDK 9, но что в нее входит — я не в курсе. Изначально поддержка может состоять в том, чтобы караф просто нормально стартовал под 9-кой, а поддержка бандлов, собранных 9-кой и содержащих модулей — это отдельная проблема, и я не знаю, ни решена ли она, ни планировали ли вообще ее решать.
Ну и кстати, мы вот у себя широко используем всяческий OpenSource, и при этом сидим плотно на JDK 8. По-идее, если бы среди оного попадалось что-то, собранное 9-кой, мы бы это заметили. Но что-то я ни про что такое не слышал. Что как бы намекает на популярность (а точнее, на ее отсутствие).
Ну и кстати, дискуссия в блоге котлина:
discuss.kotlinlang.org/t/kotlin-support-for-java-9-and-java-10/8054/2
что-то никто особо не рвется активно поддерживать.
dernasherbrezon
11.09.2018 21:05+1Своеобразно написано конечно. Из статьи я понял что лексс это как то относится к java concurrency и стек это почему то коробки с пиццей.
А вот проблему я так и не понял. На бэкэнде eve online написанном на питоне запустили 2000 тредов и все стало тормозить? Ну так не запускайте 2000 тредов на питоне. На Java стали тормозить 1млн запущенных тредов? Ну так не запускайте и думайте что делаете.
olegchir Автор
11.09.2018 21:12Не запускайте треды — и что? Что вместо этого-то? Это единственный ныне существующий удобный примитив для написания такого рода задач. Более того, вся экосистема Java уже заточена именно под треды. Именно поэтому такое внимание уделяется разработке именно совместимого решения, а не какого угодно.
Вместо предложения "не запускайте треды" теперь появляется куда лучшее предложение — запускайте! Все сколько есть! Миллионами! Счастье всем и почти даром.
dernasherbrezon
11.09.2018 21:36Плохое предложение. Вы же понимаете, что:
- придет junior
- прочитает этот совет
- назапускает тредов.
- в любом случае упрется в ограничения ресурсов
- скажет, "Java — тормозит!"
ИМХО количество тредов — не самая актуальная проблема. Надо просто подумать и съоптимизировать код. Есть гораздо более сложные проблемы, которые пока вообще не имеют решения в java. Например, было бы круто, если бы jit научился оптимизировать скалярные операции. Или компилировать в VHDL.
olegchir Автор
11.09.2018 21:53Нет, не понимаю. Именно так пусть и делает — запускает файберы, когда в этом есть необходимость. Фича это позволяет. Она как раз и занимается той оптимизацией, которую бы делал вручную человек — и которую ему теперь делать совершенно не нужно.
Ну точней, прямо сейчас — фича не позволяет, потому что это ранний прототип, и его не точили на высокий перфоманс. Сейчас оттачивается философия и API. Но на релизе всё будет ок.dernasherbrezon
11.09.2018 22:00Магии не бывает. Если условный junior не подумал про использование ресурсов, то никакими технологиями это не исправить. Проблема просто будет спрятана: его приложение будет падать не на 1000 тредах, а на 1млн.
Кстати, а что будет с context switching/cpu contention, если запустить 1млн файберов?
olegchir Автор
11.09.2018 22:15Раньше нужно было запускать второй инстанс на амазоне после 1000 потоков, а сейчас — после миллиона. Хммм, как же это скажется на доходах компании, у которой огромный кусок бюджета уходит на облака, даже не знаю…
dernasherbrezon
11.09.2018 22:50+1Не совсем мой пример. Скорее так: раньше они масштабировали приложение через неделю из за утечки потоков, а теперь начинают масштабировать через 2 недели.
varanio
12.09.2018 07:47О ресурсах все равно джуну придется думать.
Ты можешь конечно запустить 100500 легких тредов, но при этом если ты помимо чего-то простого будешь там какие-то условные интегралы считать (т.е. то, что требует какое-то время на вычисления), то на 16-ядерной машине ты сможешь запустить только 16 таких тредов, все остальные 100500 тредов, даже самые простые, тупо будут ждать, когда отпустит.
Разве не так?
По крайней мере в go и nodejs именноCyberSoft
12.09.2018 08:58Конечно, ядер от этого не добавится. Смысл-то в утилизации цпу (+ копеечный оверхед по памяти): 16 ядер всегда выполняют какие-то файберы. Хотя честно, не вижу разницы с обычными потоками в этом смысле, все также засыпают на локах, IO и отдают ядра другим потокам.
Bonart
12.09.2018 10:25Разница простая — принудительного переключения нет, но само переключение очень быстрое.
Можно писать неблокирующий код, читающий из сокета по байтику, но такой же простой, как и блокирующий.
fzn7
12.09.2018 09:34+1Откуда святая уверенность, что не хватает потоков? В Еве проблема была с обработкой симуляции мира. Это когда все ваши потоки уже отработали, приняли команды и выстроились в очередь. Все они должны быть обработаны в строгом порядке, повреждения должны быть нанесены последовательно, невозможные команды на каждом шаге симуляции отбрасываются. Распарралелить эту задачу не получится, поэтому можете хоть обмазаться миллионом потоков, оно будет также
Ryppka
12.09.2018 00:01+1EvE Online == stalkless python, нет там проблемы запустить 2000 тредов…
olegchir Автор
12.09.2018 00:17Прочитал, что это. Аххахаха. Похоже, я привёл самый неудачный пример из существующих.
Понятно, почему у них там всё так хорошо.
HDDimon
11.09.2018 23:42+1Олег, спасибо за статью. А правильно понял что основное отличие от акторов реализованных в erlang и Scala — это возможность нормального разделения общих ресурсов?
time2rfc
12.09.2018 00:04+1Можете подсказать, что вы имеете ввиду когда говорите о разделении ресурсов ?
dos65
12.09.2018 01:52+1Ну в каком-то смысле да, если общий ресурс тут выделяемое процессорное время на актор.
При разработке на аkka, из-за безальтернативновного выбора между тредами или тредами на jvm, все равно нужно учитывать, что процессинг сообщений не должен блокировать тред, иначе будет бобо всем остальным акторам.
olegchir Автор
12.09.2018 13:04Я пошел к коллегам по редакции ScalaNews и попросил прокомментировать :-) Выше ответ dos65 :) Сам я вопроса не очень понял — связь между эрлангом и скалой конечно есть, но конкретно в Java это делается просто чтобы общий ресурс в виде нативных тредов не простаивал. Чтобы сделать более общий вывод нужно хорошо знать эрланг и скалу, а я на них говнокодил недостаточно много.
HDDimon
12.09.2018 15:25+1По классическим работам Хевита(https://en.wikipedia.org/wiki/Carl_Hewitt) акторы не разделяют ничего общего, общение производиться за счет отсылки сообщений.
За счет этого довольно легко запустить огромное количество акторов, а блокирующие нужно выносить отдельно. Файберы же по сути потоки на стеройдах, которые могут иметь общее состояние. Вопрос был об этом.
yannmar
11.09.2018 23:53+2>Ещё я иногда буду использовать слово «вытеснение» вместо английского варианта «yield». Просто слово «yield» — оно какое-то уж совсем мерзковатое. Поэтому будет «вытеснение».
yield — это уступить дорогу, буквально. В частности такой надписью на асфальте дублируют соответствующий дорожный знак-морковку. Применительно к тредам он значит ровно тоже самое: указывает одному треду притормозить и дать проехать другому треду.olegchir Автор
12.09.2018 00:01по-русски то как это сказать. Я вот придумал «самовытеснение», или «вытеснение» чтобы было короче. Пошёл и самовыпилился. Если говорить «уступать», то сразу же возникают вопросы — «уступать кому», «уступать что», оно как-то ненадёжно звучит :(
замечание абсолютно верное, что делать — непонятно. Если сейчас придумать вариант лучше, то можно его использовать в следующих статьях.yannmar
12.09.2018 00:09+1Можно наверное просто «уступить дорогу» и использовать, вполне себе устоявшееся выражение, как мне кажется.
olegchir Автор
12.09.2018 00:14и постоянно говорить «уступить дорогу», «уступить дорогу», «уступить дорогу». Длинно. Лишние повторения. Срабатывает нюх на пахнущий код: если одно и то же повторяется несколько раз, пора отрефакторить это в отдельную функцию. В данном случае — в отдельное слово. Какое?
вот что у английского yield не отнимешь — оно короткое и понятное (для них). Его не стрёмно повторять. Попробуй найди слово ещё короче. А то же слово «вытесниться» — это просто капец какая длинная неповоротливая фигня, пока выговоришь — можно поесть и поспать несколько разyannmar
12.09.2018 00:24+1Ну вот повезло им, что слово у них короткое, но понятное-то оно потому, что является отсылкой к дорожному движению.
relgames
12.09.2018 00:30+1О, async/await на стероидах. Сыровато, конечно.
Сейчас CompletableFuture и всякие Reactive на коне.
Akka без проблем держит миллионы "потоков". Spring MVC новый тоже подтянулся.
В общем, можно сделать троллейбус из буханки хлеба. Но зачем?.. Пусть евангелисты фигнёй страдают. Инженерам работать надо.
olegchir Автор
12.09.2018 00:45Там же в самом верху картинка была с двумя стульями. Если коротко, то асинхронный код (даже если он спрятан за сахаром) — очень сложный для чтения, очень сложный даже для написания, у него очень неприятная отладка и инструменты для нее плохие — короче, дорогой в разработке и поддержке.
Что ещё важней, асинхронщину никто на самом деле не любит. Никто не любит, когда ему приносят больше проблем, если можно меньше проблем. Но в данный момент «меньше» проблем нельзя, потому что существуют конкретные бизнес-запросы на этот счёт
Когда-то реализацией такой мечты были треды. Тебе не надо разбираться, как там это всё работает в операционной системе, C++, ассемблере итп — ты просто берешь Java, фигачишь тред, и всё отлично. Ты пишешь всё в виде линейного императивного кода и можешь почти полностью игнорировать тот факт, что на самом деле никакой линейности не существует
Единственный минус тредов в том, что они слишком большие. Малая гранулярность. Ты захотел сделать какую-то мелочь, а нужно тащить целый тред. И да, можно по тредам всё вручную распихивать, но это неудобно.
И вот на помощь приходят файберы, которые снова позволяют писать обычный линейный код и притвориться, что всё выполняется строго последовательно.
Ещё интересно, что на релизе, весь тулинг тоже будет притворяться вместе с тобой. Это просто и удобно.CyberSoft
12.09.2018 09:00+1Почему это «вручную распихивать по потокам»? А тред пул экзекьютеры разве не эту задачу выполняют?
olegchir Автор
12.09.2018 12:51тредпул экзекьюторы решают задачу запуска — задачу приостановки они не решают. Нужно писать это руками. А тут предполагается, что все это будет уже за тебя сделано разработчиками Лума, и оно будет иметь универсальный интерфейс, а не твои мегакостыли
Artyomcool
12.09.2018 14:29Это и есть распихивать вручную. Приходится руками обеспечивать свое собственное переключение контекстов и обмен данных между задачами.
CyberSoft
12.09.2018 20:43Что-то не понял. Берём ThreadPoolExecutor, настраиваем и начинаем давать ему Runnable в execute. Где ручное распихивание, перключение контекстов? Обмен данными, если нужен, надо будет и в файберах организовывать.
Artyomcool
12.09.2018 21:26+1Для этого, во-первых, нужно сначала аккуратно побить задачи на Runnable, во-вторых, что-то сделать с блокирующими вызовами. Большинство задач выглядят как прочитать немножко данных, возможно, из разных источников, что-то с ними сделать и куда-то записать результаты, возможно, в несколько мест. В случае сегодняшнего Executor API на Thread'ах нельзя сделать это одновременно с перформансом асинхронного API (при котором придется обеспечивать обмен данными, зачастую весьма нетривиально) и с удобством синхронного API.
transcengopher
12.09.2018 22:31+1Но то же самое нужно будет делать и для Fiber'ов.
Вряд ли Main станет Fiber'ом из-за обратной несовместимости, а перевод экосистемы на Continuation опять же потребует аккуратного дробления. Но в добавок ещё и с ограничением на блокировку.
(или нет? насколько увеличится толщина методов в java.io если они будут повсеместно проверять, запущены ли они в Fiber'ах?)Artyomcool
12.09.2018 22:57+1Блокирование на большинстве IO-операций и reentrant lock'ах будут «отдавать» текущий тред на корм другим Fiber'ам. Даже уже написанный код. И да, Main не станет Fiber'ом. Однако запустить Fiber на ForkJoinPool'е так же просто, как и запустить Runnable. При этом его не потребуется аккратно разбивать на части — внутри может выполнятся «как бы последовательный» код, в том числе легаси, в том числе уже скомпилированный до нас. Т.е. запускаем миллион Fiber'ов (вместо Runnable) и они перестают блокировать друг друга ожиданиями IO и прочими lock'ами. Упираемся дальше фактически в CPU, что много лучше, чем упираться в конфигурацию ThreadPool'а.
transcengopher
13.09.2018 15:26Но постойте? Если блокирование на io всё равно отдаёт ресурсы файберам, для чего нужно было городить разделение Thread|Fiber? Ведь это фактически уже значит, что любой тред становится, эффективно говоря, своеобразным файбером уже благодаря этому факту. Я тут уже в нескольких ветках пытаюсь этот на этот вопрос найти ответ.
И я, кстати, не согласен, что в CPU упираться лучше. Что если я не хочу в него упираться — кто мне оставит такую опцию в настройках? Хорошо настроенный пул уже будет упираться в CPU, а так это получается опять магия, как с Common FJ-pool в Stream, разве что (может быть) с меньшим количеством дедлоков. Или с большим, если не повезёт, учитывая в что в FJ не будет миллионов конкурирующих задач.mayorovp
13.09.2018 16:56Как я понял, блокирование на io всё равно отдаёт файберам только если сейчас выполняется другой файбер.
Danik-ik
13.09.2018 17:00А мне кажется, что никакие проблемы с блокировками тут не решаются никак. Просто простаивающий поток, предоставленный ОС, переиспользуется другой задачей, а не консервируется до возобновления текущей. Всё. Совсем всё.
time2rfc
12.09.2018 13:23+1Есть третий стул. https://www.youtube.com/watch?v=dWyGM3MnN0A
Не пропаганды ради, другой точки зрения для.
DGolubets
12.09.2018 18:57+1Асинхронный код не сложен для чтения если используется функциональное программирование. Просто люди из последних сил цепляются за динозавра\ не хотят учить новое.
olegchir Автор
12.09.2018 18:59К сожалению, функциональное прогарммирование в практике Java не используется почти никак. В своей массе, у большинства разработчиков. Ну и да, язык-то у нас ни разу не Haskell, он не шибко помогает писать чистый код, архитектуру портов-адаптеров с кругом чистоты, и вот это все. Даже в F# есть полу нерешаемые проблемы!
Я наверное скоро выложу интервью с Венкатом (который тоже будет на Joker 2018!), он про это немножко говорил. Как написатель книжки про функциональное программирование в Java он кой чего в этом понимает)sshikov
12.09.2018 19:41+1>К сожалению, функциональное прогарммирование в практике Java не используется почти никак.
Вот не надо обобщать на всех.
DGolubets
12.09.2018 19:56+1Ну оно и понятно, ведь Java изначально ООП язык, да еще с многолетним багажем. А вот почему народ с нее не хочет переходить на Scala мне остается непонятным. И это при том, переход плавный и экосистема та же — не то что Haskell учить.
CyberSoft
12.09.2018 20:32К сожалению, функциональное прогарммирование в практике Java не используется почти никак
Stream API это разве не адаптированная функциональщина? А им ой как пользуются, что даже доклад о "переиспользовании" в прошлом году был у вас.
olegchir Автор
12.09.2018 20:45Как вы в стримах на момент компиляции сможете обеспечить, чтобы все используемые в стримах функции были чистыми, а все данные — немутабельными?
Artyomcool
12.09.2018 22:52+1Есть ощущение, что многие люди забывают о том, что функциональщина — это про чистоту и иммутабельность, а не про лямбды и чейны.
Scf
12.09.2018 00:55+1Всё придумано до нас — это называется "кооперативная многозадачность" — https://en.wikipedia.org/wiki/Cooperative_multitasking
Разработчикам ОС проще, у них есть прямой доступ к стеку и аппаратная поддержка переключения контекстов.
olegchir Автор
12.09.2018 01:24Да, я где-то там в дебрях статьи ссылаюсь на эту статью :) Но вопрос не в кооперативной многозадачности как таковой, а в том, как бы её так впилить во вполне конкретную Hotspot JVM, чтобы никто не пострадал (в особенности легаси код).
Scf
12.09.2018 01:02+1Решение для написания асинхронного кода в промышленных масштабах уже придумано — Future/Promise. Конечно, это сложнее, чем синхронный код, но значичельно проще коллбэков а-ля node.js или изменяемого состояния + события а-ля Netty.
Проблем с интеграцией с синхронным кодом тоже нет — просто нужно помнить, что параллелизация синхронного кода ограничена количеством потоков в тредпуле.
olegchir Автор
12.09.2018 12:01+1Здесь не решается задача написания асинхронного кода. Тут решается прямо противоположное — из предположения что мы пишем нормальный линейный код, как сделать, чтобы он не тормозил. Дальше замечаем, что код обычно тратит треды на всевозможное IO и прочие блокировки (для огромной части аудитории их задачи IO-bound, или даже database-bound, например для ынтерпрайзных веб-разработчиков). Поэтому идея в том, чтобы код не жрал треды в то время, когда ждет ту же базу данных. И дальше все это — просто генерализация этой мысли на более общие конструкции в масштабах всей виртуальной машины в целом. В частности, поддержку этой фичи магическим образом получит легаси код, который висит на все том же файловом апи из ждк, в которую и впиливается поддержка файберов под капотом.
transcengopher
12.09.2018 18:10+1Но если «получит магическим образом», то почему нужен класс Fiber? Чем провинился Thread? Метаданными?
Пойду-ка статью перечитаю, что ли.olegchir Автор
12.09.2018 18:50+1Потому что полной совместимости, скорей всего, достичь не получится. Файбер похож на тред, но это во многом не тред, и совместимость там должна работать только в том смысле, что если легаси код запустить в файбере, то он скорей всего не поломается.
Останутся маленькие заусенцы, которые могут какой-то легаси код превратить в фарш. И даже если API отработает идеально, то все равно изменится паттерн нагрузки, и в какой-то ситуации быстрее может оказаться не обязательно — лучше.
Если человек применил файберы осознанно и у него появились заусенцы — это по крайней мере ожидаемо. Если сломается то, что бинарно без изменений работало двадцать лет — это похоже на катастрофу. Для юзера это будет выглядеть дико.Artyomcool
12.09.2018 21:55+1ThreadLocal'ы почти наверняка сломаются. Ведь невозможно узнать, для какой именно цели они были использованы: то ли какая-нибудь хитрая оптимизация, то ли «защита» от конкурентного доступа, то ли вообще что-то в голову ударило из разряда «а не запилить ли мне тут ThreadLocal? круто же будет».
transcengopher
12.09.2018 22:07[Перечитал(правда, по диагонали)]
Всё равно не особо понятно, и главным образом благодаря заявленной магии. Например обговаривается явное разделение мониторов по типу владельца — Fiber|Thread. А зачем конкретно делить? Нет, я в принципе-то понимаю, что выбор должен быть сознательным, но делить-то зачем?
Предположим, нечто заставляет системный примитив парковаться. Почему Fiber при этом может отдать мощности другому Continuation, а Thread, внезапно, не может? Разница такого порядка должна быть видна, разве что, на уровне достаточно глубоко системных процессов. Исключение, которое я могу придумать — это что кто-то (мир духу их) сохраняет ссылки на экземпляры Thread, дабы потом из другого Thread сравнить с другой ссылку по "==", и для Fiber нет механизмов, позволяющих вернуть тот же экземпляр ShadowThread? В чём-то другом? Какой предполагаемый механизм поломки? Если это просто «мы не знаем, но бывает всякий код», то возможно следует провести более подробное исследование узких мест, и всё-таки хакнуть сам Thread?
В итоге я, конечно, пророню скупую слезу по необходимости иметь в java.base растущее количество примитивов, делающих одно и то же, но с перламутровыми, а потом с и медными, пуговицами (ведь глупо сомневаться что ещё через N лет не придумают новые подходы ещё более эффективной параллелизации), но обратная совместимость есть фактор поддержания продаваемости, и придётся мириться.olegchir Автор
12.09.2018 22:22Ну так уже не всё Thread API работает. Не работает stop, suspend, resume — и вряд ли начнут. Непонятно что делать с ThreadLocal. Thread.currentThread указывает на непонятные постоянно меняющиеся значения. Непонятно что делать с нативным кодом, синхронизованными блоками, wait/notify, и еще кучей вещей. Пресслер говорит, что вот именно это они сейчас стараются как-то починить хотя бы на уровне философии. Вот в Котлине это на уровне философии починено так: а вы не юзайте просто currentThread() или будьте готовы к этому поведению. Но легаси код на Java к нему не готов.
Еще интересней, что совершенно не все фичи используются по назначению, и легко может оказаться так, что создатель программы заложился на какой-то сайд-эффект, который работает с тредами, но совершенно сломается с файберами. Какие-нибудь ситуации когда по какой-то сложнодоказуемой причине что-то успевает быстрей чего-то другого, и это обычно работает (без всякой гарантии от стандартов vm и я языка), но любой чих ломает эту логику к черту. Файберы весь такой код поломают.transcengopher
12.09.2018 22:41+1Thread.currentThread указывает на непонятные постоянно меняющиеся значения
Почему это? Если он возвращает ShadowThread, то для конкретного Continuation'a должен возвращать один и тот же экземпляр, из чего-то вроде ContinuationLocal. Сюда же идут имя треда и всё подобное.
Вот что делать с ThreadLocal действительно неясно — я ведь сам уже столкнулся с ситуацией, когда мой неверно придуманный r/o кэш был помещён в ThreadLocal, из-за чего запросы разных пользователей получили возможность не читать самостоятельно из базы некоторые значения (без нарушения инкапсуляции сессии; правда, в реальности ускорения получено не было, так как контекст нового пользователя с большой вероятностью просто вытеснял из кэша старьё, и 90-95% данных таки приходится подгружать). В моём-то случае это неверное понимание, что я творил, а если кто-то на это на самом деле полагается для чего-то критичного?
Artyomcool
12.09.2018 23:01+1Нельзя бездумно возвращать тот же самый shadow thread в currentThread. Можно поломать какой-нибудь хитрый happens-before в чужой логике оптимизаций, где будет currentThread == previousThread -> optimized branch; else -> common branch.
mayorovp
13.09.2018 13:42+1Достаточно потребовать чтобы засыпание Continuation было happens-before его пробуждения, и подобная поломка станет невозможной.
Artyomcool
13.09.2018 13:58Действительно, как-то не подумал. Конечно, еще останется проблема с нативным кодом, использующем понимание Java Thread = OS Thread. Ну и в целом, в неведомом коде может быть куча логики вокруг currentThread, какие-нибудь свои велосипедные ThreadLocal'ы.
transcengopher
13.09.2018 15:36Велосипедных ThreadLocal'ов как раз пожалуй опасаться не нужно, если экземпляр ShadowThread всё же будет тот же самый.
Другое понимание намного опаснее, так как это как раз и есть о чём я уже говорил — расчёт на то, что некий произвольный код действительно будет находить в ThreadLocal значения, оставленные там предыдущей (никак не связанной, кроме как через внешний дизайн, не выраженный в коде) задачей, а вот этого, думаю, мы как раз и не можем строго гарантировать.
a_e_tsvetkov
12.09.2018 10:07Я конечно извиняюсь, но почему бы просто не починить имеющиеся треды вместо создания новой фичи?
Что мешает вернутся к тем благословенным временам когда в яве небыло нативных тредов смахнуть пыль с шедулера и научить его работать не с одним нативным тредом, а с фиксированным количеством. Это снизит расходы памяти на нативные структуры.
В этих ваших файберах стек сократили с мегабайта до килобайта. Видимо за счет динамической аллокации. Если заимплементить динамическую аллокацию в тредах это сломает нативные фреймы точно так же как и в континуациях. Чинить надо так же как в континуациях :)a_e_tsvetkov
12.09.2018 12:16+1Кстати есть довольно простое решение проблемы с нативными вызовами.
Нужно на каждый такой вызов заводить отдельный стек. Фокус в том что он может быть существенно меньшего размера.
Есть правда еще одна беда. Что делать если нативные вызовы блокируются?
Но тут никакие файберы не помогут и можно тупо добавлять нативных тредов в таком случае.Artyomcool
12.09.2018 21:57А что если Java код с ожиданием был вызван из нативного? We need to go deeper.jpg
a_e_tsvetkov
13.09.2018 05:17Не вижу проблемы. Просто продолжаем использовать Java стек с того места из которого вызвали нативный метод. Для ясности вставить dummy фрейм с пометкой «если вы вернулись сюда, то на самом деле вам нужно вернутся в нативный код».
Artyomcool
13.09.2018 12:07Нативный код может не ожидать переноса стека по памяти.
mayorovp
13.09.2018 13:44Так потому и предлагается заводить под него отдельный стек, который не будет нуждаться в переносе.
a_e_tsvetkov
13.09.2018 14:55А его и не надо переносить. Его специально в отдельном месте хранить надо и запинивать при использовании.
Xandrmoro
12.09.2018 12:20+1Не пишу и, надеюсь, никогда не буду писать на джаве, но подача настолько великолепна, что прочитал целиком.
Двух котят с дверцами автору.olegchir Автор
12.09.2018 20:49Спасибо! Цель в том, чтобы в хабе Java всегда было что почитать из научно-популярного. Оно все будет про джаву в целом, но можно и просто так повтыкать. Еще что-то подобное будет про .NET, если я на него время найду
sved
12.09.2018 12:32+1Интересно, а если реальная необходимость в создании миллиона фибров?
Для распределения сложной вычислительной задачи по ядрам прекрасно нативные потоки справляются.
Если же речь идёт о миллионе соединений, то можно использовать неблокирующее API. В этом случае сложность написания асинхронного кода не так критична, ибо обработчики событий не могут быть сложными (ведь их же миллионы, они не могут долго выполняться).olegchir Автор
12.09.2018 12:39Это для того, чтобы люди могли фигачить файберы каждый раз, когда им хочется. Чтобы не нужно было трястись за каждую копейку, ой а имею ли я право тут потратить столько ресурсов и сделать тред. Надо — делай! Хоть каждую строчку в файбер зворачивай, с чистой душой и совестью.
svr_91
12.09.2018 17:18+1А что если человек сделает файбер с огромными вычислениями? Как я понимаю, основной смысл файберов, это чтобы их приостонавливали (и желательно почаще), а если кто-то шибко умный запустит while(true); то все точно также сломается
olegchir Автор
12.09.2018 18:56Он единолично захватит на себя тред, да. Но даже если у тебя жесткосвязанный цикл без вызова внешних функций, ты как автор этого цикла наверняка сможешь руками вызвать yield когда надо, типа каждый десятый проход. Или даже — каждый первый, а планировщик уже сам разберется, стоит ли пользоваться этим yield-ом или дать тебе выполниться дальше. У того же golang совершенно точно такие же ограничения на сильносвязанный код, но гошники прям кипятком писают от того, какие горутины хорошие.
Artyomcool
12.09.2018 21:59+1А уже есть публичное апи для yield? Или пока в мечтах?
olegchir Автор
12.09.2018 22:12Ну там есть функция yield без параметров) «Публичного» там нет ничего, это ранний прототип, который изменяется со скоростью света.
sved
12.09.2018 18:15+1Файберы делают поведение программы менее предсказуемым.
Непонятно сколько памяти будет выделяться под хранение локальных переменных.
Кроме того, непонятно что делать с escape анализом, где объекты для оптимизации создаются прямо в стеке вместо кучи.
Далее, континуейшен может выполниться на другом ядре, а значит надо заново заполнять кэш ядра. Напомню, что одно из преимуществ work stealing-a это локальность данных, когда отфоркнутая задача будет скорее всего выполняться на том же ядре, а значит не надо гонять данные туда-сюда.
В целом интересная абстракция. Однако непросто найти прям реальный пример практического применения. Обычно там где надо создать миллион потоков повышенные требования к ресурсам, а фибры это слишком большой оверхед.
olegchir Автор
12.09.2018 18:57Непонятно с точки зрения разработчика технологии файберов или пользователя-прикладника? Пользователю то что — он просто фигачит файберы и в ус не дует.
sved
12.09.2018 19:52+1если следовать вашей логике то пользователь точно также может фигачить потоки и в ус не дуть
olegchir Автор
12.09.2018 20:48Не может. Во-первых, через десять тысяч потоков все начнет тормозить (особенно в шиндовсе). Во-вторых (если вы внимательно читали статью), один поток занимает примерно 1 мегабайт памяти, и миллион потоков (даже если б они не тормозили) занял бы терабайт оперативки. У вас есть терабайт оперативки? Пусть даже на проде, а не на личном ноутбуке?
Artyomcool
12.09.2018 22:01+1Тем не менее, в большинстве случаев, средневзятому пользователю пары тысяч потоков вполне хватит. (нисколько не хочу умалять потребность в кооперативной многозадачности)
olegchir Автор
12.09.2018 22:11Сейас к потокам относятся как к некой священной корове. Их считают, их вызывают аккуратно, над ними думают. Существует вообще такая идея как «тредов хватит или не хватит». Наличие файберов позволит заворачивать в файбер чуть ли не каждую строчку :-) Кто знает, сколько при этом файберов наплодится?
transcengopher
12.09.2018 22:46+1Ситуация с parallelStream(), как мне кажется, немало народа (меня в том числе) заставила задуматься, так ли хорошо это когда любой чих может на самом деле произойти в тридевятом треде, а мне вернётся только результат.
Artyomcool
12.09.2018 22:46+1Ну все-таки каждая строчка перебор, кажется, что переключение контекстов файберов хоть и дешевле тредов, но не бесплатно. Думать головой, к сожалению, все еще придется.
olegchir Автор
12.09.2018 23:13Это наверное оффтоп, но мне кажется что есть вполне насущная проблема: если сейчас наслушаться Шипилева и начать говнокодить многопоточно, то как нефиг делать можно получить программу, которая будет *медленней* чем последовательная версия, ну потому что ты просто не понимаешь что творишь. И вот файберы могут помочь тем людям, кто уже готовы к написанию более интересного кода, но еще не готовы к тому чтобы удалиться в высокие горы и медетировать в пещере над тонкостями джава мемори модели. Желания испоганить что-то будет меньше, если все и так работает.
Artyomcool
12.09.2018 23:19+1Кажется, совсем не обязательно наслушиваться Шипилева, чтобы начать говнокодить сразу в несколько потоков. И как раз эта категория разработчиков вполне может сделать медленнее на файберах, чем просто линейно. Но да, быстрее, чем на тредах)
eugenex15
12.09.2018 22:02+1Те самые фиберы?
Фиберы
Третий сервис-пак для Microsoft Windows NT 3.51 принесла в операционную систему новые сервисы под названием фиберы. Они были добавлены в Win32, чтобы облегчить портирование приложений из UNIX в WinNT. Были написаны эти однотредные серверные юниксовые приложения, которые могли иметь «доступ ко многим клиентам за раз».eugenex15
12.09.2018 22:11+1vxlab.info/wasm/article.php-article=1021008.htm
Wasm.ru Треды и фиберы /27.08.2002/
woworks
olegchir Автор
Я недавно променял запись в трудовой с «IT-специалиста» на «специалиста по коммуникациям», теперь штормит немного :-)
Есть предчувствие, что так очень легко нарваться на лекцию jbaruch, касающуюся введения в профессию и чистоты морального облика хаброавтора. Особенно учитывая, что сегодня интервью с программным комитетом devoops, и он там будет. Немного боязно даже.
igor_suhorukov
Фуу, такое чувство что общаешься исключительно со школьниками средних классов. «Хардкор» в подаче для самых маленьких?)
Не предчувствуйте, с Барухом вы как бы из одной лодки и конфликта интересов быть не должно!
olegchir Автор
Ну я сам школьник средних классов — люблю потреблять именно вот такой контент. Как думаешь, что я сейчас смотрю в перерыве между работой? "Макса 100500" на фоне леопардового ковра. Сорянчик. Делал как для себя :-)
igor_suhorukov
Надеюсь что не на полной ставке по трудовой оформлен, иначе нарушение ТК!)
Будет потом как в меме про журналиста и ученого… «Хабр окупировали школьники»
olegchir Автор
Так они его и оккупировали. Собственно, статьи про кишки OpenJDK для того и нужны, чтобы постараться повернуть колесо в положительную сторону: больше качественного контента про программирование — больше адекватных людей — которые генерят еще больше качественного контента. Каждый боец нужен и важен на фронте.
igor_suhorukov
Мне тут больше экспертов и профессионалов встречается, так что спорное утверждение про аудиторию.
Про цели можно поспорить, лишь пытаюсь донести мысль что такая подача контента фокусирует ваши усилия на тех кого описали. Кто во что верит, тому и такая целевая аудитория.
olegchir Автор
Относиться плохо к школьникам — плохо.
Уровня развития школьника вполне должно хватать, чтобы мочь программировать на Java или даже C++ вполне осмысленные вещи.
И очень-очень скоро все эти школьники станут нашими коллегами, нашими начальниками, нашими товарищами.
Пусть привлекает. Если они сюда набегут — это будет праздник, обсуждение файберов пойдет куда живее
igor_suhorukov
Конечно пусть процветает словоблудство) Предлагаю хаб java для «маленьких». Обращаться к аудитории «чувак» «бро». Не рекомендовать читать монографию Ахо, а исключительно посещать курсы и конференции работодателей.
Это как практикующих медиков учить по «Стоматология для чайников».
olegchir Автор
«Чувак» я уже использую (называю так почти всех людей), а вот «бро» — это отличная идея. Мои любимые стримеры на твиче так говорят. Тоже буду так делать, спасибо!
igor_suhorukov
Как-бы в капиталистическом обществе живем, роялти что-ли платите за PR идею!)
А если без юмора, поскольку твои работодатели спокойно относятся к этому «прыщавому» сленгу, клянчанью лайков, мемам на каждом слайде и платят зарплату за такой маркетинг и PR. То можно сделать выводы, что ради увеличения прибыли, взяли партийный курс на развлечение и завлечение людей далеких от официальной целевой аудитории конференции — геймеров, школьников и их родителей. Запасаюсь попкорном и наблюдаю в стороне…
olegchir Автор
Хочешь сюрприз? Я на эту статью потратил свои личные выходные, и никто мне ничего за неё не заплатил. О чём, кстати, сказано в дисклеймере к статье.
У меня очень серьезные консёрны на тему, что если я буду ещё и стримить с приличной периодичностью, то учитывая работу — когда мне спать? Подготовка видосиков требует поразительно много усилий. Похоже, спать придется перестать.
Я сам геймер, вечерами постоянно играю в Overwatch (и хочу попробовать Quake Champions, а вот PUBG и батл рояли вообще не переношу) и время от времени устраиваю уютные стримы на своем Фейсбуке, вечерами после работы залипаю в Твиче, IRL тусуюсь в стримерской тусовке. Даже с летсплейщиками. Для меня именно такой формат наиболее понятен и приятен.
Поэтому когда выдалось время сделать нечто для души, а не по работе, я стал делать именно то, что стал бы смотреть сам. А теперь сорянчик, надо шлёпать — пересмотреть, чего там Дрю записал за эту пару дней.
igor_suhorukov
Респект! Не горюйте, вернется премией за KPI после сезона конференций. Материал стоящий, но подан сомнительно.
Еще есть минимум пара-тройка способов как сэкономить время на полезную и интересующую вас работу, но думаю сами догадаетесь.
По поводу остальной информации — она лишняя для меня, вместе со всем этим «сально-прыщавым» сленгом) Могу только посочувствовать вам и вашим родным по этому поводу. Но в принципе, все написанное вами подтверждает мои предположения о стратегии работодателей.
time2rfc
Я тоже не смог долго читать, количество вопросов подразумевает что кто-то смог.
Стиль изложения в некотором смысле вкусовщина.
23derevo
а ты не завидуй. Зависть — смертный грех!
igor_suhorukov
Конечно, так удобнее давить мнение джависта) Говоришь «критика=зависть» и конец дискуссии!
23derevo
Ты перешел на личности в разговоре с моим коллегой. Теперь получай!
igor_suhorukov
Обратитесь в профсоюз! Можете как организация завести аккаунты для родных и друзей коллеги)
Уверяю, тут нет перехода на личности. IMHO констатация фактов и фидбэк к статье.