Сегодня мы расскажем читателям Хабра о том, как с помощью нейронных сетей нам удается повышать разрешение видео в режиме реального времени. Вы также узнаете, чем отличается теоретический подход к решению этой задачи от практического. Если вам не интересны технические детали, то можно смело пролистать пост – в конце вас ждут примеры нашей работы.

В интернете много видеоконтента в низком качестве и разрешении. Это могут быть фильмы, снятые десятки лет назад, или трансляции тв-каналов, которые по разным причинам проводятся не в лучшем качестве. Когда пользователи растягивают такое видео на весь экран, то изображение становится мутным и нечётким. Идеальным решением для старых фильмов было бы найти оригинал плёнки, отсканировать на современном оборудовании и отреставрировать вручную, но это не всегда возможно. С трансляциями всё ещё сложнее – их нужно обрабатывать в прямом эфире. В связи с этим наиболее приемлемыи? для нас вариант работы — увеличивать разрешение и вычищать артефакты, используя технологии компьютерного зрения.
В индустрии задачу увеличения картинок и видео без потери качества называют термином super-resolution. На эту тему уже написано множество статей, но реалии «боевого» применения оказались намного сложнее и интереснее. Коротко о главных проблемах, которые нам пришлось решать в собственной технологии DeepHD:
- Нужно уметь восстанавливать детали, которых не было на оригинальном видео ввиду его низкого разрешения и качества, “дорисовывать” их.
- Решения из области super-resolution восстанавливают детали, но они делают чёткими и детализованными не только объекты на видео, но и артефакты сжатия, что вызывает неприязнь у зрителей.
- Есть проблема со сбором обучающеи? выборки – требуется большое количество пар, в которых одно и то же видео присутствует и в низком разрешении и качестве, и в высоком. В реальности для плохого контента обычно нет качественнои? пары.
- Решение должно работать в реальном времени.
Выбор технологии
В последние годы использование нейронных сетей привело к значительным успехам в решении практически всех задач компьютерного зрения, и задача super-resolution не исключение. Наиболее перспективными нам показались решения на основе GAN (Generative Adversarial Networks, генеративные соперничающие сети). Они позволяют получить фотореалистичные изображения высокой чёткости, дополняя их недостающими деталями, например прорисовывая волосы и ресницы на изображениях людей.

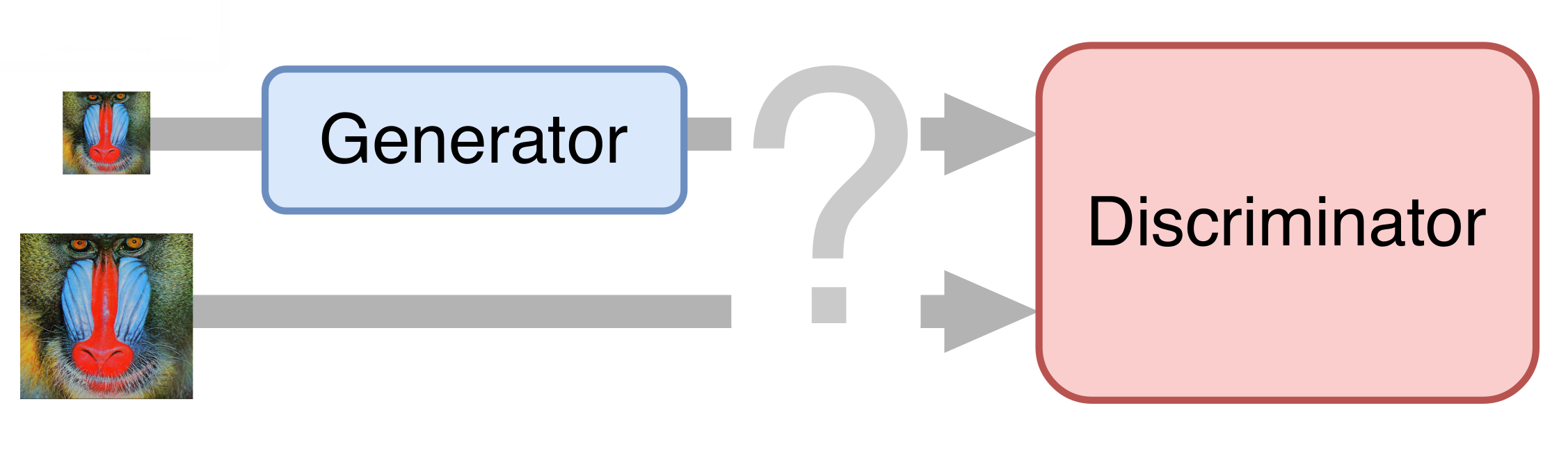
В самом простом случае нейронная сеть состоит из двух частей. Первая часть – генератор – принимает на вход изображение и возвращает увеличенное в два раза. Вторая часть – дискриминатор – получает на вход изображение, сгенерированные и “настоящие”, и пытается отличить друг от друга.
Подготовка обучающего множеств
Для обучения мы собрали несколько десятков роликов в UltraHD-качестве. Сначала мы уменьшили их до разрешения 1080p, получив тем самым эталонные примеры. Затем мы уменьшили эти ролики ещё вдвое, попутно сжав с разным битрейтом, чтобы получить что-то похожее на реальное видео в низком качестве. Полученные ролики мы разбили на кадры и в таком виде использовали для обучения нейронной сети.
Деблокинг
Конечно же, нам хотелось получить end-to-end-решение: обучать нейросеть генерировать видео высокого разрешения и качества сразу из оригинального. Однако GAN'ы оказались очень капризны и постоянно пытались уточнять артефакты сжатия, а не устранять их. Поэтому пришлось разбить процесс на несколько этапов. Первый – подавление артефактов сжатия видео, также известный как деблокинг.
Пример работы одного из методов деблокинга:

На этом этапе мы минимизировали среднеквадратичное отклонение между сгенерированным и исходным кадром. Тем самым мы хоть и увеличивали разрешение изображения, но не получали реального повышения разрешения за счёт регрессии к среднему: нейросеть, не зная, в каких конкретно пикселях проходит та или иная граница на изображении, была вынуждена усреднять несколько вариантов, получая размытый результат. Главное, чего мы добились на этом этапе – устранение артефактов сжатия видео, так что генеративной сети на следующем этапе нужно было только повысить чёткость и добавить недостающие мелкие детали, текстуры. После сотен экспериментов мы подобрали оптимальную по соотношению производительности и качества архитектуру, отдалённо напоминающую архитектуру DRCN:
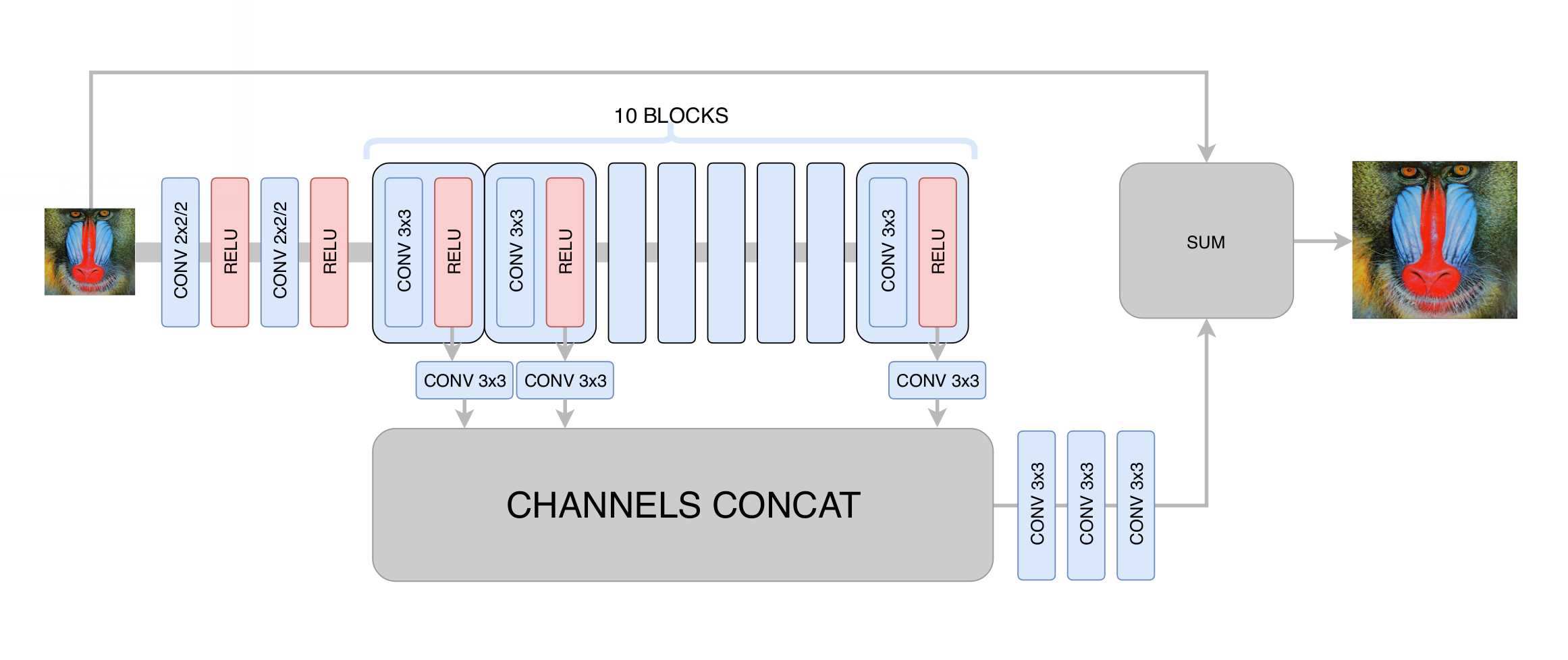
Основная идея такой архитектуры состоит в желании получить максимально глубокую архитектуру, при этом не получив проблем со сходимостью при её обучении. С одной стороны, каждый следующий свёрточный слой извлекает всё более сложные признаки входного изображения, что позволяет определять, что за объект находится в данной точке изображения и восстанавливать сложные и сильно повреждённые детали. С другой стороны, расстояние в графе нейронной сети от любого её слоя до выхода остаётся небольшим, благодаря чему улучшается сходимость нейросети и появляется возможность использовать большое количество слоёв.
Обучение генеративной сети
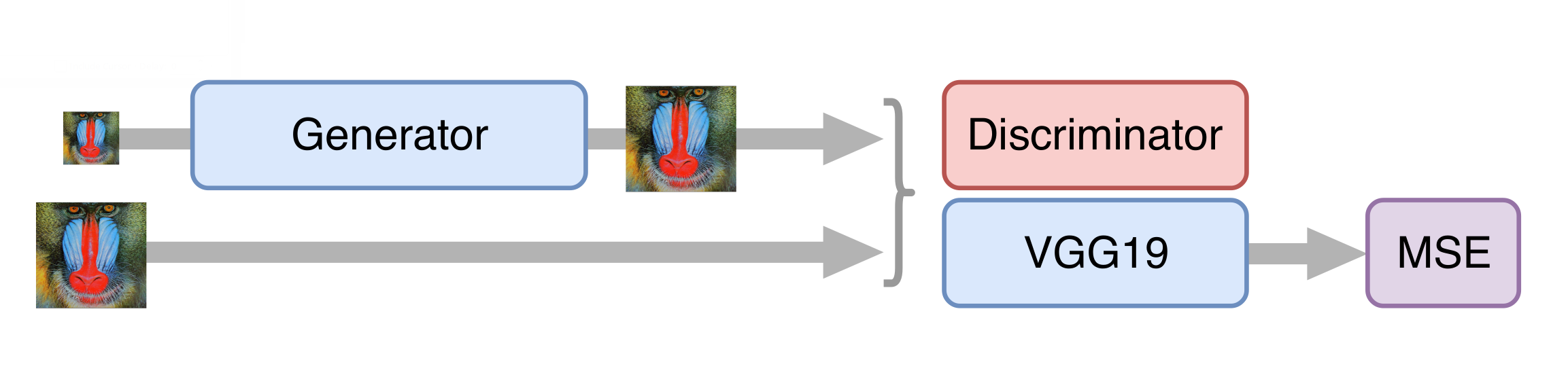
За основу нейронной сети для повышения разрешения мы взяли архитектуру SRGAN. Прежде чем обучать соревновательную сеть, нужно предобучить генератор – обучить его тем же способом, что и на этапе деблокинга. В противном случае в начале обучения генератор будет возвращать только шум, дискриминатор сразу начнёт «выигрывать» – легко научится отличать шум от реальных кадров, и никакого обучения не получится.

Далее обучаем GAN, но и тут есть свои нюансы. Нам важно, чтобы генератор создавал не только фотореалистичные кадры, но и сохранял имеющуюся на них информацию. Для этого к классической архитектуре GAN'а мы добавляем контентную функцию потерь (content loss). Она представляет собой несколько слоёв нейросети VGG19, обученной на стандартном датасете ImageNet. Эти слои преобразуют изображение в карту признаков, которая содержит информацию о содержимом изображения. Функция потерь минимизирует расстояние между такими картами, полученными из сгенерированного и исходного кадров. Также наличие такой функции потерь позволяет не испортить генератор на первых шагах обучения, когда дискриминатор ещё не обучен и выдает бесполезную информацию.
Ускорение нейросети
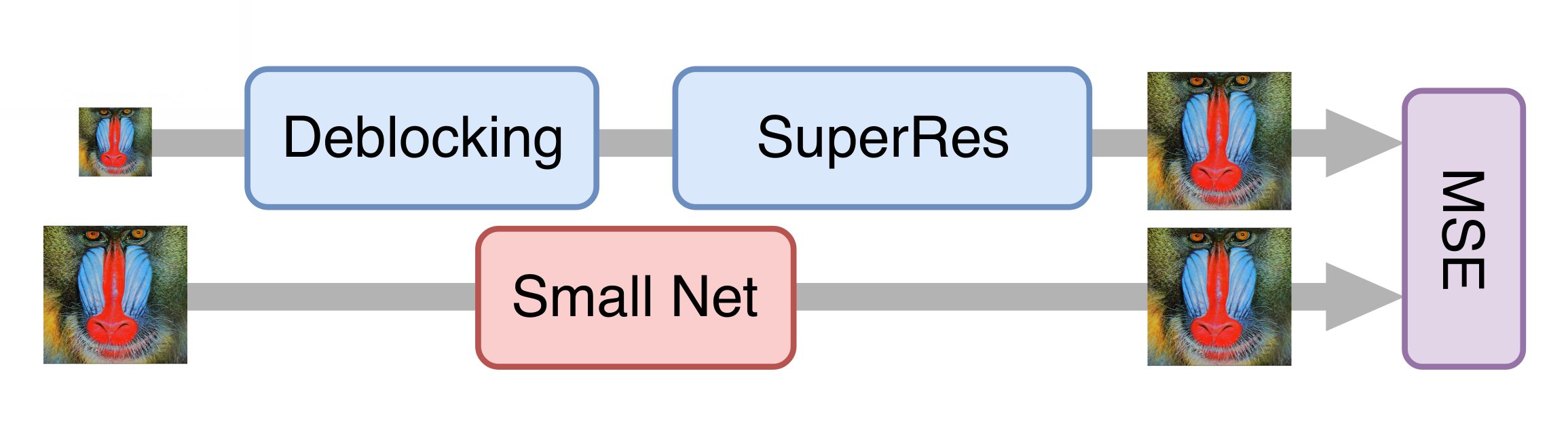
Всё шло хорошо, и после цепочки экспериментов мы получили неплохую модель, которую уже можно было применять к старым фильмам. Однако для обработки потокового видео она все ещё была слишком медленной. Оказалось, что просто уменьшить генератор без существенной потери качества итоговой модели нельзя. Тогда нам на помощь пришёл подход knowledge distillation («дистилляция» знаний). Этот метод предусматривает обучение более лёгкой модели таким образом, чтобы она повторяла результаты более тяжёлой. Мы взяли множество реальных видео в низком качестве, обработали их полученной на предыдущем шаге генеративной нейросетью и обучили более лёгкую сеть получать из тех же кадров такой же результат. За счёт этого приёма мы получили сеть, которая не очень сильно уступает по качеству исходной, но быстрее её в десятки раз: на обработку одного телеканала в разрешении 576p требуется одна карта NVIDIA Tesla V100.
Оценка качества решений
Пожалуй, самый сложный момент при работе с генеративными сетями – это оценка качества полученных моделей. Здесь нет понятной функции ошибки, как, например, при решении задачи классификации. Вместо этого мы знаем только точность дискриминатора, которая никак не отражает интересующее нас качество генератора (хорошо знакомый с этой сферой читатель мог бы предложить использовать метрику Вассерштайна, но, к сожалению, у нас она давала заметно более плохой результат).
Решить эту проблему нам помогли люди. Мы показывали пользователям сервиса Яндекс.Толока пары изображений, одно из которых было исходным, а другое – обработанным нейросетью, либо оба были обработанными разными версиями наших решений. За вознаграждение пользователи выбирали более качественное видео из пары, так мы получали статистически значимое сравнение версий даже при сложно различимых глазом изменениях. Наши итоговые модели одерживают победу в более чем 70% случаев, что достаточно много, учитывая, что пользователи тратят на оценку пары видео всего несколько секунд.
Интересным результатом также стал тот факт, что видео в разрешении 576p, увеличенное технологией DeepHD до 720p, выигрывает у такого же оригинального видео с разрешением 720p в 60% случаев – т.е. обработка не только повышает разрешение видео, но и улучшает его визуальное восприятие.
Примеры
Весной мы испытали технологию DeepHD на нескольких старых фильмах, посмотреть которые можно на КиноПоиске: «Радуга» Марка Донского (1943), «Летят журавли» Михаила Калатозова (1957), «Дорогой мой человек» Иосифа Хейфица (1958), «Судьба человека» Сергея Бондарчука (1959), «Иваново детство» Андрея Тарковского (1962), «Отец солдата» Резо Чхеидзе (1964) и «Танго нашего детства» Альберта Мкртчяна (1985).

Разница между версиями до и после обработки особенно заметна, если вглядываться в детали: изучать мимику героев на крупных планах, рассматривать фактуру одежды или рисунок ткани. Удалось компенсировать и некоторые недостатки оцифровки: например, убрать пересветы на лицах или сделать более заметными предметы, размещённые в тени.
Позднее технология DeepHD стала использоваться для улучшения качества трансляций некоторых каналов в сервисе Яндекс.Эфир. Распознать такой контент легко по метке dHD.
Теперь на Яндексе в улучшенном качестве можно посмотреть «Снежную королеву», «Бременских музыкантов», «Золотую антилопу» и другие популярные мультики киностудии «Союзмультфильм». Несколько примеров в динамике можно увидеть в ролике:
Для требовательных к качеству изображения зрителей разница будет особенно заметной: изображение стало более резким, лучше видны листья деревьев, снежинки, звёзды на ночном небе над джунглями и другие мелкие детали.
Дальше – больше.
Полезные ссылки
Jiwon Kim, Jung Kwon Lee, Kyoung Mu Lee Deeply-Recursive Convolutional Network for Image Super-Resolution [arXiv:1511.04491].
Christian Ledig et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network [arXiv:1609.04802].
Mehdi S. M. Sajjadi, Bernhard Scholkopf, Michael Hirsch EnhanceNet: Single Image Super-Resolution Through Automated Texture Synthesis [arXiv:1612.07919].
Комментарии (158)

MoscowBrownBear
25.09.2018 10:29+2Просто великолепно! Есть возможность пропустить свое видео через этот инструмент?
bdmoiseev Автор
25.09.2018 13:15Спасибо! Пока, к сожалению, нет — пока что это только внутренний инструмент. Прежде чем делать технологию публичной, хочется ещё побороться за качество и производительность.
Javian
25.09.2018 14:23Если мультфильм, то к virtualdub был в начале 2000-х неплохой плагин Cartoon с похожим результатом.
MoscowBrownBear
25.09.2018 15:05я хотел пропустить через него хоме видео, снятое на первые телефоны, которое сейчас лежит в облаке
Javian
25.09.2018 20:11Как отметил ниже SADKO, следует обратить внимание на MSU фильтры — очень хорошие результаты:
www.compression.ru/video/deblocking/index.html
www.compression.ru/video/deblocking/smartdeblocking.html
SADKO
25.09.2018 15:30Много чего было и есть, так-что я искренне не понимаю чем тут Яндекс хвастается, какой-такой супер результат получен, тем более что это отнюдь не первая, дурацкая попытка сделать нейрошарпилку, и результат не разу не удивительный для тех кто в теме…
… и мультфильмы в примерах ой, как не случайны, сравнили-бы результат с тем-же банальным warpsharp-ом по мотивам которого и апскейл можно сделать…
Про всякие поделки сумрачных отаку и MSU Cartoon Restore я вообще молчу, и автор статьи молчит, хотя понятие имеет, ведь на сайт MSUшной лабы он ходил как минимум за примерами деблока…
bdmoiseev Автор
25.09.2018 16:43+1В общем-то вы во многом правы, нам ещё явно есть что улучшать. Мультфильмы, я думаю, действительно можно обработать и ручными методами достаточно неплохо, если внимательно подобрать фильтры. Другое дело, что намного полезней иметь универсальное решение, которое «из коробки» работает и на мультфильмах, и на фильмах, и на телепрограммах, без каких-либо дополнительных ручных действий, подбора степени шарпенинга и т.п.
За MSU Cartoon Restore — спасибо, мы действительно не знали про них, хотя и не совсем честно сравниваться с их решением: оно работает только на мультфильмах и требует ручного выставления параметров.
А пример деблокинга — кадр из видео foreman, широко используемого для демонстрации методов обработки видео по всему миру. Вот целое видео, если интересно: www.youtube.com/watch?v=0cdM-7_xUXMDaemon_Hell
25.09.2018 18:10А не пробовали добавить conditioning вектор для разного типа контента? Хотя бы банально — анимация/кино.
bdmoiseev Автор
25.09.2018 18:26Не пробовали, но мне кажется, что даже одного кадра более чем достаточно для того, чтобы отличить анимацию от кино, и если такой conditioning действительно полезен, то нейросеть сама справится его выучить на основе входной картинки.
SADKO
25.09.2018 18:36Да, но есть нюансы обучения и структуры что-бы это стало реальностью…
… пока судя по видосикам, ваша сеть ведёт себя не лучше предшественников
Однако здесь я согласен с вашим подходом.
AWSVladimir
25.09.2018 20:17+3Посмотрел ваши демо-ролики.
Почему не убрали дрожание кадра?
Выровняли бы видеоряд первым этапом, потом бы обрабатывали это видео.
С одной стороны DeppHD, вроде топовые технологии, с другой видео на компьютере как на пленочном проекторе.
Да и сжатие значительно увеличится при стабилизации изображения.alexdoesh
25.09.2018 23:47Вот это, кстати, очень простая и хорошая идея. Однозначный win для текущей задачи, так как «ламповость» все равно теряется, то почему бы и нет.
3Dvideo
26.09.2018 15:11Посмотрел ваши демо-ролики.
Однозначно. Можно попробовать прогнать бесплатный MSU Deflicker: www.compression.ru/video/deflicker/index_en.html
Почему не убрали дрожание кадра?
Там местами видео однозначно сильно полегчает )
SADKO
25.09.2018 18:33Последовательностей, было много разных, но не в последнюю очередь благодаря регулярным публикациям MSUшников она стала, таки стандартной :-)
Про универсальность, не надо лукавить, все примитивные алгоритмы обладают ей, можно зашить туда безопасные значения, а можно их динамически вычислять разными способами, что в коммерческих видеопроцессорах и делается…
И вот тут, ваша жесткая структура тупо проиграет корейскому телевизору, который умеет измерить превышение некоторых критичных для человеческого глаза параметров, и подкорректировать свои настройки, до социально приемлемых.
А ваша структура, как и прочие аналоги, лишь генерализует нечто среднестатистическое (дай-то бох :-) и с этой колокольни перескажет пользовательские данные. Но пользователи разные, настроения у них разные, и разные истории показывают им авторы, разным языком.
Есть Норштейновский Ёжик, а есть Соник или Губка Боб, понимаете?
А всё ещё сложнее, есть например Гамбол!
Про кино я и не заикаюсь вообще, люди про него тут написали и я могу лишь подписаться.EviGL
25.09.2018 19:59+2Корейского телевизора нет, есть смартфон Sony со встроенной улучшалкой изображения. На вид работает неплохо.
Дико бесит, что эта улучшалка туда вбита проприетарными алгоритмами и привязана к железу. То есть я сделал фото, смотрю — оно красивое. Делюсь им с друзьями — на их экранах оно страшное. Смысл?
Так что "корейский телевизор", но который можно быстро применить к файлу и результат будет доступен везде — это уже хороший продукт, имеющий право на жизнь.
3Dvideo
26.09.2018 15:14Последовательностей, было много разных, но не в последнюю очередь благодаря регулярным публикациям MSUшников она стала, таки стандартной :-)
Еще раз спасибо, но мы только на русском разве что популяризировали foreman-а ), а так все, кто сжатием занимается давно с этим мужиком знакомы так же плотно, как сжимавшие картинки с леной )
Про универсальность, не надо лукавить, все примитивные алгоритмы обладают ей, можно зашить туда безопасные значения, а можно их динамически вычислять разными способами, что в коммерческих видеопроцессорах и делается…
Однозначно так!
3Dvideo
26.09.2018 15:08За MSU Cartoon Restore — спасибо, мы действительно не знали про них, хотя и не совсем честно сравниваться с их решением: оно работает только на мультфильмах и требует ручного выставления параметров.
Побойтесь бога, в простом режиме там параметры минимальны:
Сравнивать скорее некорректно, поскольку это будет сравнение свободно доступного бесплатного плагина под бесплатную программу и закрытой коммерческой технологии. Опять же — MSU Cartoon Restore работает быстрее реального времени и почти не требует памяти, а у вас скорее всего другая история ). Но тем не менее сравнить в качестве стартовой точки можно.
А что мы известны в основном за рубежом, это увы…
Кстати! Что вы заканчивали? Это не вы часом?
graphics.cs.msu.ru/ru/node/861 )))
3Dvideo
26.09.2018 15:00Про всякие поделки сумрачных отаку и MSU Cartoon Restore я вообще молчу, и автор статьи молчит, хотя понятие имеет, ведь на сайт MSUшной лабы он ходил как минимум за примерами деблока…
Спасибо за добрые слова в наш адрес! ) Очень приятно!
Справедливости ради — примеры простого деблокинга действительно похожи с теми, что у нас на www.compression.ru/video/deblocking, но автор картинку брал, похоже, тут en.wikipedia.org/wiki/File:Deblock1.JPG
ValdikSS
25.09.2018 17:08+2Vapoursynth + Waifu2x/Waifu2x-caffe + AWarpSharp + какой-нибудь анти-алиасинг (в мультике с раками видно лесенки) + другие плагины по желанию.
muon
28.09.2018 07:52+1А вообще жуткенько.
Берём старые семейные видеозаписи, прогоняем через эту мясорубку, и вуаля — мы помним людей не такими, какими они были, а такими, какими их представила себе нейросеть.
Привет, «Чёрное зеркало».
inferrna
25.09.2018 10:35+1Если бы ещё убрали мерцающие шумы во временном пространстве, стало бы совсем хорошо (можно и без нейронки обойтись ffmpeg.org/ffmpeg-filters.html#hqdn3d-1). Да и повышать чёткость у очищенных кадров проще.
SADKO
25.09.2018 15:46Они работают со сжатым\пережатым видео, и там как правило кодировщики во времени уже поработали, причём с нюансами…
… хотя глубокой сети на вход 3D матрицу дать, может-бы что интересного и вышло бы, хотя опять же, нужно сравнивать с тупыми свёртками, и более сложными алгоритмами движения3Dvideo
26.09.2018 15:28Заявляется повышение разрешения, т.е. то, что называют Super Resolution (и у нас несколько поколений MSU Super Resolution тоже было), но по сути это скорее восстановление и именно после сжатия (вы совершенно справедливо пишите).
Проблема с восстановлением в том, что разные кодеки ухудшают картинку по-разному, причем чем они новее, тем более сложные модели нужно строить, чтобы восстановить поток. Т.е. это возможно (и простой поиск compressed video restoration выдает массу вариантов, начиная от бесплатных и заканчивая вполне коммерческими), но там все очень нетривиально.
Кстати — именно с нейросетями вполне возможно, что получится относительно «просто» смоделировать современные сложные кодеки и таки построить «универсальное» восстановление. Но очень вероятно, что в ближайшее время наилучшие результаты будут, если просто смотреть на кодек, проверять, что артефакты ему соответствуют (ибо транскодеры весьма популярны) и брать модель, обученную на восстановление потоков этого стандарта. Это совершенно реальная тема.
Но правда и спекулировать на таком подходе проще всего ), т.е. обучиться на конкретном стандарте и потом показать, как на нем сеть все хорошо затаскивает )))
bdmoiseev Автор
25.09.2018 17:06+1Спасибо за идею! Я попробовал, но пока с виду эффект получается своеобразным, на кадрах появляются следы предыдущих кадров, что выглядит не очень здорово. Попробуем ещё покрутить параметры.
vmm86
25.09.2018 10:49-1Недавно подумалось о том, что теоретически можно создать технологию машинного обучения, когда путём сравнения HD-видео c его SD-копиями разного размера и качества (например, разные форматы издания одного и от того же фильма) алгоритм пытался бы «воссоздать» видео низкого качества до требуемых параметров размера/качества картинки. Было бы замечательно, если бы подобная технология стала доступна для обработки произвольных видеофайлов, например, низкокачественных оцифровок старых VHS или киноплёнок в домашней коллекции.
DaMaNic
25.09.2018 12:48Когда то у меня была идея — берется несколько источников плохого качества, но с разными экспозициями/настройками, у которых потеряны разные детали — где то хорошая четкость но потеряны светлые детали, где то плохая четкость но потеряны темные детали, где то вообще низкое качество картинки но высокая плавность. И натравливать алгоритм на то чтобы свести их вместе, максимально вытягивая информацию их всех источников в одну восстановленную запись
DjOnline
25.09.2018 13:54+1Изобрёл HDR фото, там так и делается.
DaMaNic
25.09.2018 14:02+1Не совсем. Алгоритм должен не брать два или более изображений одного и того же вида с разной эспозицией, а сначала подбирать кадры, делать для них 3D преобразование, чтобы они наложились друг на друга (и не факт что кадр с одного видео будет найден на другом — легко источники могут иметь разную частоту кадров = необходимость интерполяции кадров), далее нормализовать яркости/цветности, которые могут иметь сложные зависимости (у разных изображений один угол может быть чернее другого, а третий отдавать фиолетовым), далее анализировать картинку на предмет наличия на одной того, чего нет на другой, используя как опорные точки уже найденные зависимости между изображениями, и собственно отсеяв с изображений шум, выводить результат. Тогда я уж изобрел HDR фото, наложенный на алгоритм формирования панорам, при условии что склейка идет не с одной точки одной камерой разных изображений, а одного изображения с разных углов и источников, и проведением сквозного анализа через множество кадров, чтобы формировалось видео, т.е. на все вышеуказанное накладываются векторы движения.
DjOnline
25.09.2018 14:24В будущем лет через 100 возможно так и будет, полная 3D реконструкция пространства из видео, с текстурами из тысяч соседних кадров, что позволит получать любую чёткость, устранять дрожание камеры, двигая камеру плавно как на кране.
DaMaNic
25.09.2018 14:40Уже
habr.com/post/146157 — уже в трехмере
total3d.ru/cinema/93899 — уже в стерео, думаю половина вопросов решалась вручную, а половина с помощью разработанных алгоритмов…
Но не об этом мое было желание ) не трехмерная реконструкция (хотя именно она была бы идеальным решением), а что то типа SVP, когда наличие двух кадров позволяет получить третий. Только у SVP это разница во времени, а у меня разница в пространстве/яркости/углу поворота.
DrZlodberg
26.09.2018 11:38Кстати а HDR так генерить никто не пробовал? А то все автоматические решения которые я видел работают так себе. Реально качественная картинка получается только ручной работой :(
Хотя я давно не следил за темой, может сейчас стало получше.
HOMPAIN
25.09.2018 11:25Как вы добились плавности перехода между кадрами? Ведь если ваша сеть работает с отдельным кадром, то в одном кадре она дорисует волосы одним способом, а на соседнем совсем по другому и в итоге они будут мерцать при воспроизведении.
bdmoiseev Автор
25.09.2018 13:29По факту такой проблемы не возникает, причин этому несколько. Во-первых, сеть добавляет только мелкие детали, которые всегда привязаны к крупным, которые движутся плавно. Во-вторых, важная стадия — деблокинг, на которой устраняются привнесённые алгоритмами сжатия артефакты, в результате все сгенерированные детали привязаны к контенту изображений, а не к квадратикам алгоритма сжатия, за счет чего результат получается более гладким.
LynXzp
27.09.2018 23:55Немного возникает, но не в мелких деталях, посмотрите как начинает мерцать фон:
Заголовок спойлераHOMPAIN
25.09.2018 11:28Текстуры которые домешивает сеть у вас хранятся отдельно или они получаются непосредственно в самой сети по мере обучения и от неё не отделимы?
bdmoiseev Автор
25.09.2018 13:32Непосредственно в самой сети — по сути сеть «запоминает», как должны выглядеть те или иные текстуры и объекты из обучающей выборки, и переносит эти знания на целевой домен.
Xazzzi
25.09.2018 11:30А пробовали продолжать улучшать изображение, подавая на вход к примеру четверти от выхода прошлой итерации?
Заголовок спойлера
Invision
25.09.2018 12:41Опередили меня с этой картинкой :)
Но подход реально классный, и статья отличная
AngReload
25.09.2018 15:43Как вы загрузили WebP в HabraStorage?
Xazzzi
25.09.2018 15:58Просто вставил картинку по внешней ссылке, а хабрастор её скачал и заменил в моем комменте.
dmitryredkin
25.09.2018 16:13Хабрасторадж мог бы и перекодировать в jpg для обладателей не-webkit браузеров…
Ca5per
25.09.2018 11:57+1Технология крутая, надеюсь когда-нибудь она появиться в виде программы для домашнего использования, как для фотографий, так и для видео.

pbo
25.09.2018 12:41Спасибо за статью, очень познавательно.
Нашёл небольшую опечатку или повтор: «Наши итоговые модели одерживают победу в более чем 70% случаев. Наши итоговые модели одерживают победу в более чем 70% случаев, что достаточно много....»
Rikkitik
25.09.2018 12:59Настораживает момент «сделать более заметными предметы, спрятанные в тени». Они ведь наверняка специально были приглушены, иначе просто подсветили бы. Ваша система нарушает режиссёрское построение кадра, разбивку на задний и передний планы. Например, в «исправленном» чёрно-белом кадре с солдатом гораздо темнее стали стальные конструкции на заднем плане, они вырвались вперёд, да и сам свет в кадре из мягкого и рассеянного стал жёстким. Увеличение чёткости деталей заднего плана тоже никогда не на пользу. Глубина резкости кадра — один из инструментов операторской работы, а вы этот аспект просто уничтожаете.
maedv
25.09.2018 13:25+1Поддерживаю. Идея правильная, но нужно быть очень аккуратным.
В последнем видео на 0:55 рак стал неестественно чётким, пропала мягкость 2d-рисунка.dmitryredkin
25.09.2018 13:39-1В чем конкретно неестественость рака?
SADKO
25.09.2018 16:00+1Звоном на краях, в прочем если внимательно приглядеться к «оригиналу», в нём уже есть этот звон, яндекс просто его раздул, ну а что ему ещё оставалось делать…
dmitryredkin
25.09.2018 16:16Объясните, плиз, куда смотреть. Пять раз пересматривал, никакого звона не вижу.
SADKO
25.09.2018 16:36+1Белый ореол вдоль чёрной контурной линии, на желтой заливке, особенно заметно на пересечении контурных линий под острыми углами…
… в исходнике это заметно как аномальное увеличение\уменьшение люмы в тех же местах, оно не так заметно для не тренированного глаза, но именно за него цепляются все шарпилки, от простых свёрток, до глубоких уродцев.3Dvideo
26.09.2018 15:29+1Плюсую!
Думаю, что именно поэтому не было примера восстановления фильма ), там подобные артефакты должны возникать намного чаще. При том что и текущий пример, очевидно, был выбран из лучших.
achekalin
25.09.2018 13:08Помнится, была старая аксиома, что из отсутствия информации сделать ее наличие просто так не получится — нужно добавить информацию, иначе это все будет «гадание». Более того, обработка — это обычно даже потеря информации.
Помните, как на Марсе сфинкса разлядывали: взяли нечеткий снимок, и после обработки на компьютере что-то углядели, причем, чем больше обрабатывали компом, тем более «сфинксовым» был лик. Но больше информации от этого, увы, не стало, просто картинку подогнали так, чтобы человеку было нескучно смотреть на фото:

Улучшение видео — штука хорошая, но в лучшем случае вы вносите в картинку то, что ваш алгоритм «придумал», а не то, что автор видео хотел или мог бы снять, правильно?AndrewSu
25.09.2018 13:32Здесь источником информации является обучающая выборка. Для улучшения фильмов этого вполне достаточно. А для «уникальных» данных сеть додумает «как в кино». Для некоторых областей результат будет неприменим.
achekalin
25.09.2018 15:22+1Т.е. она возьмет, предположим, человека, и дорисует его до среднестатического человека, так? Или возьмет клип Джексона, и нарисует ему кожу того же цвета, как в другом клипе, другого года (а цвет у Майкла отличался, я про это), потому что так «обучена»?
Может, просто взять качественный исходник?Hardcoin
25.09.2018 17:23Просто? Можно мне просто качественный исходник Метрополиса 27-го года? Заранее спасибо.
AndrewSu
25.09.2018 19:41Может, вообще другое лицо дорисовать, смотря, как обучение проводить.
Дело скорее в отсутствии качественного исходника.achekalin
25.09.2018 19:45+1Exactly so. Если нет информации, то можно ее попробовать заменить похожей, но что получится — непонятно. Кому-то кожу без татухи заменит на кожу с татухой, кому-то лицо грустное — на лицо плачущее. Лицо черно белое, размытое, но Чарли Чаплина — на лицо резкое, высокого качества, в цвете, но — совсем другого актера. Итог будет прилично сделанным, но это будет уже не оригинал.
Машина сделает работу хорошо, главное, чтобы улучшение было нужным.
MIKEk8
25.09.2018 16:13Эта аксиома — не аксиома. Если есть закономерность(формула), то информацию можно получить.
x(n+1) = x(n) + 1
И взяв изначальное значение, мы получаем сколь угодно большую последовательность. И ни какого гадания здесь нет.
Если-бы эта аксиома была верна, то не существовало алгоритмов сжатия без потерь.SADKO
25.09.2018 16:47+1… фигня то в том, что формула реальности на столько хитро деланная, что по результатам измерений с долей шумов и ограниченной точностью мы можем лишь приблизительно прикинуть некоторые её члены, но никак не все, и чем больше потеряно, тем больше возрастает неопределённость…
См. ниже шкалу е%%чxиx шакалов3Dvideo
26.09.2018 15:32Именно поэтому применение 3D подходов (когда идет протягивание объекта во времени, о чем вы выше поминали) на сжатых потоках может дать реальный ощутимый прирост качества. Но и сложность алгоритма при этом кардинально возрастет. И протягивать во времени до сих пор никто на сильно пожатом видео хорошо не умеет. Т.е. целая пачка фундаметнальных проблем, которые с налета не порешаешь. Хотя всем хочется результат! )
SADKO
26.09.2018 18:00Ну, не знаю кому хочется, ИМХО всех всё устраивает, сейчас конечно пошла волна 4к, и опять можно по конкурировать на тему, кто растянет HD краше, но у 4k на маленьких в сравнении с киношным экраном есть своя, простая, специфика :-) потягаться с таким тупым подходом конечно можно, но получить прямо таки визуальное преимущество, которое-бы клиент реально разглядел на полках магазина, это вряд ли…
… и того, ощутимого выхлопа в продажах, который был от работы с аналоговым, эфирным ТВ, уже не будет, да и если начать вспоминать то время, там тоже всё было не так просто, ибо пипл как известно, хавает, а именно массовые модели делают большую часть профита…
Что до 3D, то есть две большие разницы, работаем-ли мы с исходными данными и избыточной частотой кадров, и\или пытаемся процессить пережатку, где никаких уточняющих данных уже нет в принципе, и бороться можно разве-что за устранение артефактов и\или привидение оных в смотрибельный вид…
Однако, по хорошему, эта работа должна делаться внутри самих декодеров, ибо повторно вычислять то что уже вычислено, это знаете, да вы и сами знаете…3Dvideo
27.09.2018 21:22+1Ну, не знаю кому хочется, ИМХО всех всё устраивает, сейчас конечно пошла волна 4к
Именно! Продуктам компаний нужно чем-то отличаться в лучшую сторону от аналогов. Нужны красивые истории, если что-то где-то наглядно становится лучше — это радует всех. )
но получить прямо таки визуальное преимущество, которое-бы клиент реально разглядел на полках магазина, это вряд ли…
Вы забываете про рост диагоналей. Пипл покупает числа и диагональ 65 дюймов больше, чем 56, я уж 145 или 170 — так вообще! ))) И (внезапно) на таком размере «мыло» привычных алгоритмов ресэмплинга начинает конкретно напрягать пипл, который раньше хавал.
Что до 3D, то есть две большие разницы, работаем-ли мы с исходными данными и избыточной частотой кадров, и\или пытаемся процессить пережатку
Однозначно!
Однако, по хорошему, эта работа должна делаться внутри самих декодеров, ибо повторно вычислять то что уже вычислено, это знаете, да вы и сами знаете…
Очень хорошо знаю )
Там все не так просто, увы. Во-первых, как только возникает IPBBB, т.е. большое количество B-кадров, восстановить реальное движение становится той еще задачей. А во-вторых, очень сильно мешает то, что на выбор моушн вектора в кодеке влияет его вес, в итоге уже на средних битрейтах (которые легко возникают в трансляциях при любом резком движении) в поток часто идет вектор просто повторяющий соседа, вместо реального. И использовать такие при процессинге, а тем более восстановлении — плодить характерные артефакты (когда часть слаботекстурного фона прилипает к контрастному объекту, например). И «починить» это оказывается по вычислительной сложности сравнимо с построением карты движения с нуля.
От того счастье так легко и не наступает. )
achekalin
25.09.2018 19:50Скорее речь о том, что у вас (пусть даже в looseless) сжат звук, скажем, стерео, а вы (пусть и с нейронками, с чем-то еще), но говорите, что после обработки получили звук аж 7.1. Понятно, что looseless, но понятно, что еще на лишние каналы можно только аппроксимировать. Или, в контексте поста, заменить похожими, но фрагментами других записей.
А если вы выведете формулу, по которой можно дорисовать нерезкий кусок картинки — так вы будете великим, человеком, который весь мир описал одной формулой. *смайлик*
Кстати, в вашей формуле информации ровно немного: тип зависимости и коэффициенты, а вовсе не вся таблица при всех значениях n. Вот эту информацию мы и имеем, но, если я вам скажу, скажем, что есть формула
x(n+1) = x(n) + A
и вы, не имея данных, догадаетесь о значении A, вот тут и появится новая, лишняя, исходно не дававшаяся информация.
haoNoQ
25.09.2018 23:07-1А сжатия без потерь и не существует. Не существует алгоритма, который сожмёт любую последовательность байтов так, что она станет от этого короче, и сможет потом любой результат сжатия однозначно разжать. Есть лишь иллюзия сжатия без потерь, которая возникает, когда какой-нибудь алгоритм сильно сжимает последовательности байтов очень специального вида (скажем, "осмысленные"), и при этом чуть портит все остальные.
muon
26.09.2018 02:55Не существует алгоритма, который сожмёт любую последовательность байтов так, что она станет от этого короче, и сможет потом любой результат сжатия однозначно разжать.
LZMA, LZO, LZ4?..
Про «любую» и белый шум занудствовать не будем.haoNoQ
26.09.2018 03:38Это не занудство, это вполне себе ответ по существу на занудство собеседника. MIKEk8 утверждает что когда мы разжимаем LZMA-архив, мы создаём информацию. А я указываю, что если подсунуть архиватору любую достаточно содержательную последовательность байтов, то он задохнётся и ничего не сожмёт. И произойдёт это как раз именно потому, что информация в полезном для практики смысле — именно в том смысле, в котором она в данном разговоре употребляется (информация о том, что изображено на картинке) — при разжатии не появляется, а при сжатии, соответственно, не исчезает, но просто переводится с одного языка на другой. И указываю я на это как можно более резко, применяя приём под названием "парадокс" для привлечения внимания собеседника к именно тому, что требуется.
muon
26.09.2018 04:51Не существует алгоритма, который сожмёт любую последовательность байтов
Конечно, мы не создаём информацию. Информации в несжатом файле столько же, сколько и в сжатом.
<...>
мы создаём информацию
Но последовательность байт почти всегда можно сжать, а потом разжать, этот процесс не имеет отношения к уничтожению и порождению информации. Байт — это не всегда 8 бит информации, поэтому архиватор может вместить ту же информацию в меньшее количество байт.
если подсунуть архиватору любую достаточно содержательную последовательность байтов, то он задохнётся и ничего не сожмёт.
Картинка в bmp — вполне осмысленная последовательность байт. Или текст в txt. Отлично жмутся.haoNoQ
26.09.2018 05:24Ок, да, использовать слово "содержательный" в значении "содержащий много информации", в котором оно почти противоположно слову "осмысленный", было не очень.
В остальном мне нечего добавить, я рад что мы поняли друг друга, три раза пересказав одну и ту же мысль своими словами.
bdmoiseev Автор
25.09.2018 17:34Вы правы, из отсутствия информации сделать её наличие нельзя. Но можно перенести информацию оттуда, где она есть. Подобный подход применяется, например, при обучении классификаторов: сначала обучают модель на какой-нибудь большой базе (например, ImageNet), а потом уже на маленькой базе обучают целевой классификатор.
Точно так же и тут: нейросеть «запоминает», как выглядят волосы, и дорисовывает исходя из этого знания. В этом и основная разница методов, основанных на машинном обучении, и простым шарпенингом: без знания о том, как вглядят волосы или глаза, нельзя реалистично их восстановить, см. пример с лицом из статьи. При этом отмечу, что content loss «отвечает» за то, чтобы содержимое кадров не изменилось, в результате нейросеть меняет только высокочастотные детали, не трогая ничего важного.achekalin
25.09.2018 19:55Ну да, на больше части задач реставрации это отлично подходит: у нас есть дворец 500-летней давности, в нем была лепнина, но ее вид утрачен. Мы ищем лепнину такого возраста и такого стиля, как остальной дворец, и делаем по подобию — туристы во дворце все равно будут рады увидеть общий вид отделки, и уж это явно лучше, чем отсутствие лепнины в каких-то частях здания.
Но здесь мы ищем не исходник, а именно нечто подобное. Для видеохостинга это как бы глупо: если речь о некачественных роликах, то ценность их такова, что улучшай — не улучшай.
aleksey001
26.09.2018 08:21ваша сеть покадрово проводит работу? в видео можно много информации получить если анализировать пачку кадров, те же волоски на 1 кадре не понятно где сколько, но если есть движение, то сравнив пачку кадров можно гораздо больше информации получить. такая технология есть например в астрофотографии, из кучи размытых картинок получается четкое детальное изображение. т.е. как мне видится ИИ должен определить из чего состоит кадр и кто куда движется, затем на пачке кадров каждый элемент сопоставить и виртуально обездвижить, затем пачку кадров условно неподвижных объектов проанализировать. и без фантазий ИИ получится четкость.
3Dvideo
26.09.2018 16:02Вы правы, из отсутствия информации сделать её наличие нельзя. Но можно перенести информацию оттуда, где она есть. Подобный подход применяется, например, при обучении классификаторов
В видео подобный подход также можно применять к соседним кадрам. Такие алгоритмы появились порядка 20 лет назад и их все проще и проще делать практическими.
Главное достоинство по сравнению с вашим подходом — это именно восстановление, а не попытка найти что-то похожее. На практике это проявляется в меньшем проценте заметных артефактов.
lxsmkv
25.09.2018 23:11+2Когда человек смотрит на размытую картинку и узнает в ней что-то, он тоже «додумывает». Причем так же в зависимости от зрителя с разным результатом. Можно пользоваться своей, аналоговой, «додумывалкой», а можно цифровой!
Приведенный вами пример со снимками планеты, это, в отличии от чисто развлекательного, ненаучного материала, тот случай, когда детали играют существенную роль. Тут, конечно, надо просто быть ответственным и понимать в каких областях можно применять такие методы, а в каких это будет недопустимо.
anprs
25.09.2018 13:26+6А не пробовали прогнать через DeepHD всю шкалу шакалов?

Точнее, каждый отдельный элемент. И сравнить результат :)ManWithGun
25.09.2018 16:20Поддерживаю. Хочется посмотреть на результат обработки. Натравите на картинку ИИ, пожалуйста. :-)
Hilbert
25.09.2018 20:20+7Шкала-то ненастоящая!

Mad__Max
26.09.2018 02:21Правильная шкала должна быть не «или» как у вас на картинке а «и» — некачественное обычно видео подразумевает И артефакты сжатия И низкое разрешение (что на вашей картинке обозвано «пикселизаций» — это просто понижение разрешения).
zer0hex
25.09.2018 13:45+3Мне не нравится, что цвета так заметно меняются. Не для всех видов контента подойдет.
uryevich
25.09.2018 13:45+2Да, очень здорово, результат впечатляет!
Но вот если оценивать тональность изображения в Ч/Б фильмах, то помимо повышения детализации и прорисовки фактуры заметно, что некоторые участки становятся ощутимо темнее. В некоторых случаях (пока сужу только по неподвижным изображениям), это выглядит недостаточно естественно. Просто снимал на Ч/Б фотоплёнку достаточно долго и сужу о результате по своему опыту. Мне кажется, дополнительная обработка или настройка алгоритмов всё-таки нужна.
zigrus
25.09.2018 13:57где посмотреть примеры?
ни google ни сам яндекс не выдает ничего по deephd
то что то для взрослых, то мультик deep
ссылки на кинопоиск выдают страничку без видео
пример который показан тут, отрывок из маугли дрожит. с этим что то можно сделать?uryevich
25.09.2018 14:17Нажимайте ссылку из статьи на кинопоиск и находите на странице оранжевую кнопку «Бесплатно». Там настройки качества доступны.
artyums
25.09.2018 14:22+1В статье есть примеры фильмов на Кинопоиске (под обложкой кнопка Смотреть), в селекторе качества надо выбрать «dHD».
Под спойлером, например, два кадра примерно одного момента из фильма «Дорогой мой человек» (второй раз взял из первого результата с YouTube).
Кадры тутDelphiCowboy
25.09.2018 14:16Очень круто!
Такой бы плагин да к старым играм нарисованным от руки в 320x200VGA!Wizard_of_light
25.09.2018 16:49Для Дума и Еретика есть doomsday engine.
ValdikSS
25.09.2018 17:20Для старых игр придумана уйма апскейлинг-алгоритмов: en.wikipedia.org/wiki/Pixel-art_scaling_algorithms
DjOnline
25.09.2018 14:34Яндекс, отлично!
Все ждут теперь этот инструмент в свободном доступе.
В идеале надо ещё сделать шаг — определять автоматически реальное разрешение видео, и предварительно сжимать до него. Или это уже есть? Например если камера выдаёт чёткость сравнимую с 540p на 720p материале, то сжимать предварительно до 540p.
Кстати, пример с OceanTV плохой, там материал вообще идёт без деитерлейсинга, и в итоге каша получается. Видел это сегодня в 13:33, если нужны таймкоды.
perfect_genius
25.09.2018 14:58+3Почему нет сравнения с аналогами или обычными фильтрами повышения резкости?
bdmoiseev Автор
25.09.2018 17:51Потому что существующие решения решают более узкую задачу. Например, академические решения задачи super resolution хоть и повышют разрешения, но непригодны для решения поставленной задачи, т.к. артефакты сжатия видео начинают сильно бросаться в глаза. Обычные фильтры повышают резкость, но не увеличивают детализацию, и опять-таки делают более явными дефекты видео. Так что сравнение будет заведомо нечестным, т.к. мы решаем практическую, а не академическую задачу.
Просто для примера — вот относительно новая реализация super resolution: github.com/fperazzi/proSR. На реальных изображениях интернета, даже при условии предобработки всех изображений нашим деблокингом, по оценкам из Толоки DeepHD выигрывает в 67% случаев.ValdikSS
25.09.2018 18:08В таком случае, разумно сделать сравнение с типичным конвейером фильтров видеообработки. Насколько у вас все автоматизировано? Наверняка, у вас не полностью универсальный автоматизированный алгоритм, и все же требует настройки для каждого конкретного случая.
В мультике с раками у вас сильный антиалиасинг, с шакалами — либо минимальный, либо отсутствует.
Также интересны сравнения скорости. Мой типичный конвейер для PAL DVD-видео (720?576) обрабатывает примерно 4-8 кадров в секунду на 4-ядерном процессоре 4-летней давности.
Вы пишете:
на обработку одного телеканала в разрешении 576p требуется одна карта NVIDIA Tesla V100
Что подразумевается под телеканалом? 60 полукадров?
NVIDIA Tesla V100 стоит 600+ тысяч рублей, на эти деньги можно купить два двухсокетных сервера с 10-ядерными процессорами.bdmoiseev Автор
25.09.2018 18:24У нас полностью универсальный автоматизированный алгоритм, все примеры из статьи (и цветные, и чёрно-белые фильмы, и мультфильмы) обрабатывались одним и тем же кодом аналогом цикла for внутри вычислительной платформы Нирвана. По сути это просто нейросетевая модель, которая на вход покадрово принимает видео и выдаёт видео в два раза больше, никаких специальных настроек там нет.
Что подразумевается под телеканалом? 60 полукадров?
25 полных кадров в секунду.ValdikSS
25.09.2018 18:34Вы вообще не делаете никакой настройки и предварительной обработки? Что будет, если на выход алгоритму подать видео с телекино или обычным интерлейсом, например? Цвет тоже полностью автоматически меняется, без ручной настройки?
bdmoiseev Автор
25.09.2018 22:41Да, вообще никакой. Про телекино не знаю, а интерлейс выглядит не очень хорошо (не сильно лучше, чем видео без обработки, на что уже выше указывали в комментариях), но для трансляций в интернете обычно всё равно приходится делать деинтерлейс и обрабатывать уже progressive-сигнал. Цвета тоже полностью автоматически меняются (так сетка научилась).
Мы очень ленивые люди, поэтому всё автоматизировано :)dab512
26.09.2018 07:45Интересно, почему сеть дескриминатор не отсеивала варианты с цветокоррекцией не соответствующей оригиналу?
Ведь в идеале если увеличенное сеткой изображение уменьшить, то оно должно совпадать с тем, которое было исходным (изменения должны вноситься только на тех частотах которых нет в исходном изображении).
3Dvideo
26.09.2018 15:41+1Мы очень ленивые люди, поэтому всё автоматизировано :)
Вам стоит поинтересоваться, как обрабатывает видео гугл при заливке на YouTube, например. Вы заведомо проиграете им по качеству при ленивом подходе. Ведь когда вы зарелизитесь и вас можно будет сравнить — кто-нибудь это обязательно сделает. И будут вас сравнивать не с академическими аналогами или бесплатными фильтрами, а с доступными бесплатно коммерческими системами. И как вы будете оправдываться? )
3Dvideo
26.09.2018 15:39Потому что существующие решения решают более узкую задачу. Например, академические решения задачи super resolution хоть и повышют разрешения, но непригодны для решения поставленной задачи,
На данный момент ваше решение выглядит не очень далеко ушедшим от академических решений. Но даже не в этом дело, а том, что вообще video restoration люди вполне себе профессионально занимаются уже порядка 25 лет и есть коммерческие программные пакеты, наборы плагинов под популярные редакторы видео и т.п.
Вы ведь не хотите сказать, что никто до вас не решал такую задачу? )
Nice-L
25.09.2018 16:22Жаль не успел поучаствовать в Толоке. Интересно было бы. Знаете, какие нибудь дни рождения детей, снятые на плохие камеры, восстановленные этим алгоритмом будут дарить счастье. Наверное уже готовите функционал по преобразованию видео «по кнопке» из загруженных в Яндекс.Диск?
phoenixweiss
25.09.2018 17:30Удалось побывать как раз на презентации DeepHD на YaC 2018 — эта штука поразила больше всего. Действительно в кой это веке машинное обучение настолько близко и понятно фокусируется на вполне осязаемой цели и настолько грамотно её решает. Молодцы!
smer44
25.09.2018 21:14блин забивают гвозди микроскопом. Простейшая обработка в GIMP:
— shrapen + softlight, layer visibility ~ 50%
— + bump map на оригинальный слой

хуже, но это в руках нуба.
Если написать спец. алгоритм векторизации по краям, будет не хуже всяких диплернинговbdmoiseev Автор
25.09.2018 22:45-1Если говорить про такие мультфильмы с не самыми качественными исходниками — да, возможно для каждого мультфильма и можно подобрать подходяшие фильтры вручную, хоть такой подход и плохо масштабируется. Однако лица вот так, например, всё же не вытянуть:
advan20092
26.09.2018 08:22Я сильно сомневаюсь что это реальный результат обработки, а не художественная интерпретация работы алгоритма.
Rikkitik
26.09.2018 10:05Увеличьте и посмотрите, какая там белая кайма на правой фотке вокруг очков, будто их в фотошопе приклеили. Особенно неестественно смотрится в районе переносицы. На двухслойные пластиковые очки с белой изнанкой не похоже, у них была бы видна подложка не по всему контуру, а только с одной стороны.
krainov
26.09.2018 11:22Это очки с двойным пластиком (модель RX 5150 2034). Внутри он прозрачный.
Rikkitik
26.09.2018 11:41Я архитектор, и занимаюсь рисованием объектов сложной формы с натуры уже более 20 лет. Такая конструкция должна давать белую полосу-толщину или справа, или слева от носа, или сверху, или снизу от самой нижней дуги оправы. Вот на этой фотке в более резком ракурсе более понятно, о чём я:
Другой ракурс
krainov
26.09.2018 11:44Простите, но на фотографии я, и это мои очки. Так получилось.
Rikkitik
26.09.2018 13:00Тогда пролейте свет на вопрос, это правая фотка исправлена или левая ухудшена.
krainov
26.09.2018 13:30Правая получена из левой.
Rikkitik
26.09.2018 15:18Выложите оригинал, пожалуйста, очень хочется проверить, артефакт эти полосы по всему периметру или нет.
krainov
26.09.2018 16:12У меня нет оригинала :(
Это для како-то интервью снимали, и оригинал утерян.
Но вы можете дать свою фотку и мы попробуем на ней.
А потом вы опубликуете оригинал.Rikkitik
26.09.2018 17:13У меня очки другие, не такой сильный контраст с кожей не даст белой обводки. Кстати, тут выше упоминали рака из мультика, у него тоже бело-жёлтый контур вдоль чёрных линий пошёл.
3Dvideo
26.09.2018 15:57Я сильно сомневаюсь что это реальный результат обработки, а не художественная интерпретация работы алгоритма.
Это вы зря, в статьях на тему можно намного более впечатляющие картинки найти:

На тему еще 10 лет назад уже книжки выходили:
www.amazon.com/3-D-Shape-Estimation-Image-Restoration/dp/1849965595
Другое дело, что новые подходы намного универсальнее и практичнее.advan20092
27.09.2018 08:16Это совсем другой тип размытия и алгоритмы для исправления таких вещей действительно давно известны.
3Dvideo
27.09.2018 21:06Конечно другой. Пусть меня поправят, но выше также пример сети, обученной на лицах приводят как пример для задачи увеличения разрешения сжимавшихся файлов, т.е. несколько другая задача. Хоть и близкая. )
3Dvideo
26.09.2018 15:47Ну Александр Крайнов ведь хорошо знает (и даже лекции читает) о том, какие «чудеса» можно показывать с нейросетями и какие там проблемы под капотом. В частности, насколько легко подбором тренировочной выборки получить нужный результат.
Вы можете этот же алгоритм предъявить на первой сотне картинок такого запроса:
yandex.ru/images/search?text=лицо )))
dim2r
26.09.2018 19:29Верится с большим трудом, что так можно вывести картинку из блура.
Я попробовал через частотное разложение в фотошопе — результат близко не стоял.red75prim
26.09.2018 22:34Нейросеть всё-таки использует кучу данных из обучающей выборки, чтобы "нафантазировать" детали. Но по поводу картинки из этого комментария у меня тоже сомнения — не видно артефактов апскейлинга. Или фотография была в обучающей выборке и сеть переобучилась, или кто-то перепутал и запостил оригинальную фотографию.
RuK
26.09.2018 04:49Яндекс всегда был одним из лидеров индустрии — так держать!
(до сих пор один из «почт» на вашем сервисе)
Tertium
26.09.2018 12:18С видео круто, а подскажите, есть ли что-то толковое и юзабельное для апскейла картинок на локальном компе? Вот фото с бородой и бровями хорошо апскейлили, аж завидно.
FadeToBlack
26.09.2018 12:36Мне кажется странным, что говорили о фильмах, а показали в качестве примера мультфильм. К тому же, такой результат работы алгоритма можно было элементарными фильтрами из фотошопа получить. Отрывки указанных фильмов — в студию!
bdmoiseev Автор
26.09.2018 15:08В конце статьи ещё есть примеры старых чёрно-белых фильмов, а больше можно посмотреть по запросу «фильмы в deephd» на Яндекс.Видео.
FadeToBlack
27.09.2018 12:05нашел вот это yandex.ru/blog/company/oldfilms
И это действительно впечатляет.3Dvideo
27.09.2018 21:34Да, намного лучше примеры. И, главное, на разных реальных текстурах. Удивительно, что они не были использованы в статье, ибо намного нагляднее.
ribble_rabble
27.09.2018 23:13Вот тут ещё с мультиками примеры можно посмотреть: https://yandex.ru/blog/company/soyuzmultfilm
FadeToBlack
28.09.2018 05:30Пример с мультиками не показательный. Там можно применять любые уже известные алгоритмы сглаживания / увеличения четкости / векторизации. Убивать нейросети на мультики вообще не целесообразно, разве что по типу призмы сконвертить стиль одного мультика в другой.
NihilSherrKhaine
26.09.2018 18:17Было бы крайне интересно узнать, что из себя представляет smaller networks при дистиляции знаний. По крайней мере концептуально, является ли это тем же самым решением в уменьшенных масштабах или более тривиальная модель?
bdmoiseev Автор
26.09.2018 18:18Архитектурно это практически та же сеть, что применяется на этапе деблокинга.
shurricken
27.09.2018 10:43Вчера где-то увидел новость про мультфильмы, и невнимательно глянул на заголовки колонок кадров. Рассматривал и думал, что оригиналы — это как раз улучшенные версии.
Вот честно, как обывателю мне не совершенно не ясна польза от таких технологий.
Вот фото превращения смазанной футболки в четкую, приведенное выше, гораздо эффектнее.
Обычные стандартные пункты меню разных программ, типа «автолевел», «шарп», «автоматическое улучшение цвета» и тд, зрительно зачастую лучший эффект дают.
Насчет математики круто наверно. Но вот игра нейросетевого шахматного монстра впечатлила зримее.
kibergus
27.09.2018 22:05Любить российские мультфильмы в HD можно только из России. Есть планы тткрыть их на весь мир?




MMik
Хорошая работа. Спасибо. А что со звуком? Что-то пытались улучшить, и какие были результаты? На старых записях очень часто звук глухой, есть шумы, звук может звучать как-бы в отдалении.
bdmoiseev Автор
Спасибо за добрые слова!
Про звук много думаем, но это существенно сложнее. Для того, чтобы обучить такую нейросеть, нужно воспроизвести те деффекты, которые есть на реальном контенте низкого качества. В случае видео достаточно понизить разрешение, добавить блура и сжать одним из популярных кодеков, и результат уже получается неплохим. В случае звука нужно воспроизводить шумы и дефекты, которые возникали при записи на старые микрофоны и последующей записи на плёнку, что сложнее. Можно попробовать не воспроизводить эти шумы, а воспользоваться технологиями вроде CycleGAN, но мы пока что ещё не пробовали.
nightwolf_du
Дурацкое предложение — для микрофонных эффектов качественно воспроизводить на нормальном оборудовании, а слушать старым микрофоном — их еще достаточно на руси, по всяким районным домам культуры много этой аппаратуры.
С процессом записи на пленку сложнее.
Daemon_Hell
А чего сложного, пленочные магнитофоны тоже в наличии есть. В некоторых студиях на них до сих пор пишут (для того самого звука)
Panblch
Замечательно! А когда можно будет классику японской анимации так же улучшить?)