Казалось бы, тема избитая – про резервное копирование сказано и написано многое, поэтому нечего изобретать велосипед, просто бери и делай. Тем не менее, каждый раз, когда перед системным администратором web-проекта встает задача настроить бэкапы, для многих она повисает в воздухе большим вопросительным знаком. Как правильно собрать бэкап данных? Где хранить резервные копии? Как обеспечить необходимый уровень ретроспективы хранения копий? Как унифицировать процесс резервного копирования для целого зоопарка различного ПО?

Для себя мы впервые решали эту задачу в 2011. Тогда мы сели и написали свои скрипты резервного копирования. На протяжении многих лет мы пользовались только ими, и они успешно обеспечивали надежный процесс сбора и синхронизации бэкапов web-проектов наших клиентов. Бэкапы хранились в нашем либо каком-то другом внешнем хранилище, с возможностью тюнинга под конкретный проект.
Надо сказать, эти скрипты отработали своё по полной. Но чем дальше мы росли, тем больше у нас появлялось разношерстных проектов с разным ПО и внешними хранилищами, которые наши скрипты не поддерживали. Например, у нас не было поддержки Redis и “горячих” бэкапов MySQL и PostgreSQL, которые появились позже. Процесс бэкапов не мониторился, были только email-алерты.
Другой проблемой был процесс поддержки. За многие годы наши, некогда компактные, скрипты разрослись и превратились в огромного несуразного монстра. И когда мы собирались с силами и выпускали новую версию, отдельных усилий стоило выкатить обновление для той части клиентов, которые использовали предыдущую версию с какой-то кастомизацией.
В итоге в начале этого года мы приняли волевое решение: заменить наши старые скрипты бэкапов чем-то более современным. Поэтому сначала мы сели и выписали все хотелки к новому решению. Получилось примерно следующее:
- Бэкапить данные наиболее часто используемого в работе ПО:
- Файлы (дискретное и инкрементное копирование)
- MySQL (холодные/горячие бэкапы)
- PostgreSQL (холодные/горячие бэкапы)
- MongoDB
- Redis
- Хранить бэкапы в популярных хранилищах:
- Local
- FTP
- SSH
- SMB
- NFS
- WebDAV
- S3
- Получать алерты в случае возникновения каких-либо проблем в процессе резервного копирования
- Иметь единый конфигурационный файл, который позволит управлять бэкапами централизованно
- Добавлять поддержку нового ПО через подключение внешних модулей
- Указывать extra опции для сбора дампов
- Иметь возможность восстановить бэкапы штатными средствами
- Простота начального конфигурирования
Анализируем имеющиеся решения
Мы посмотрели open-source решения, которые уже существуют:
- Bacula и её форки, например, Bareos
- Amanda
- Borg
- Duplicaty
- Duplicity
- Rsnapshot
- Rdiff-backup
Но у каждого из них были свои недостатки. Например, Bacula перегружена ненужными нам функциями, начальное конфигурирование — достаточно трудоемкое занятие из-за большого количества ручной работы (например, для написания/поиска скриптов бэкапов БД), а для восстановления копий необходимо задействовать специальные утилиты и т.д.
В конце концов мы пришли к двум важным выводам:
- Ни одно из существующих решений в полной мере нам не подходило;
- Похоже, у нас у самих было достаточно опыта и безумия, чтобы взяться за написание своего решения.
Так мы и сделали.
Рождение nxs-backup
В качестве языка для реализации выбрали Python – он прост в написании и поддержке, гибок и удобен. Конфигурационные файлы было принято решение описывать в формате yaml.
Для удобства поддержки и добавления бэкапов нового ПО была выбрана модульная архитектура, где процесс сбора бэкапов каждого конкретного ПО (например, MySQL) описывается в отдельном модуле.
Поддержка файлов, БД и удалённых хранилищ
На текущий момент реализована поддержка следующих типов бэкапов файлов, БД и удалённых хранилищ:
БД:
- MySQL (горячие/холодные бэкапы)
- PostgreSQL (горячие/холодные бэкапы)
- Redis
- MongoDB
Файлы:
- Дискретное копирование
- Инкрементное копирование
Удалённые хранилища:
- Local
- S3
- SMB
- NFS
- FTP
- SSH
- WebDAV
Дискретное резервное копирование
Для разных задач подойдут либо дискретные, либо инкрементные бэкапы, поэтому реализовали оба типа. Можно задавать, какой способ использовать на уровне отдельных файлов и каталогов.
Для дискретных копий (как файлов, так и БД) можно задавать ретроспективу в формате дни/недели/месяцы.
Инкрементное резервное копирование
Инкрементные копии файлов делаются по следующей схеме:
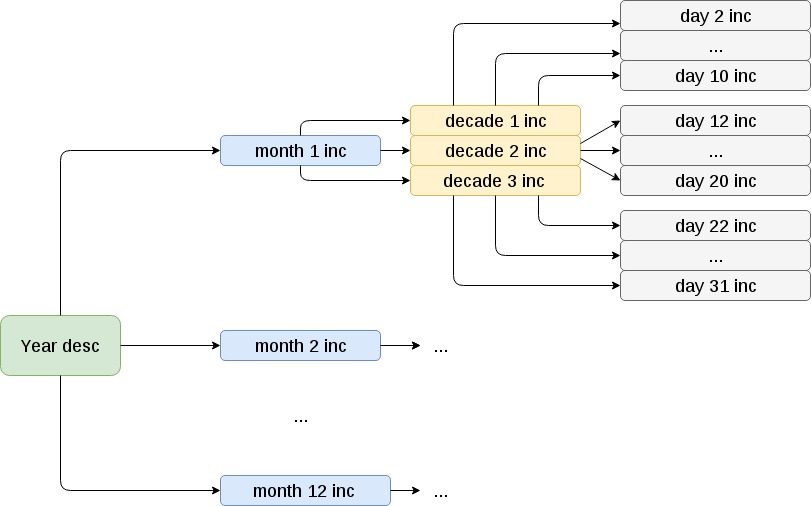
В начале года собирается полный бэкап. Далее в начале каждого месяца – инкрементная месячная копия относительно годичной. Внутри месячных – инкрементные декадные относительно месячной. Внутри каждой декадной – инкрементные дневные относительно декадной.
Стоит оговориться, что пока наблюдаются некоторые проблемы при работе с директориями, которые содержат большое количество поддиректорий (десятки тысяч). В таких случаях сбор копий значительно замедляется и может протекать более суток. Мы активно занимаемся устранением этого недочета.
Восстанавливаемся из инкрементных бэкапов
С восстановлением из дискретных бэкапов проблем нет – просто берём копию за нужную дату и разворачиваем обычным консольным tar. С инкрементными копиями немного сложнее. Чтобы восстановиться, например, на 24 июля 2018, нужно выполнить следующее:
- Развернуть годичный бэкап, пусть в нашем случае он отсчитывается от 1 января 2018 (на практике это может быть любая дата, в зависимости от того, когда было принято решение внедрить инкрементное резервное копирование)
- Накатить на него месячный бэкап за июль
- Накатить декадный бэкап за 21-ое июля
- Накатить дневной бэкап за 24 июля
При этом для выполнения 2-4 пунктов необходимо в команду tar добавить ключ -G, тем самым указав, что это инкрементный бэкап. Конечно, не самый быстрый процесс, но если учесть, что восстанавливаться из бэкапов приходиться не так уж часто и важна экономичность, такая схема получается вполне эффективной.
Исключения
Часто нужно исключить из бэкапов отдельные файлы или каталоги, например, каталоги с кешем. Это можно сделать, указав соответствующие правила-исключения:
- target:
- /var/www/*/data/
excludes:
- exclude1/exclude_file
- exclude2
- /var/www/exclude_3Ротация бэкапов
В наших старых скриптах ротация была реализована так, что старая копия удалялась только после того, как новая собиралась успешно. Это приводило к проблемам на проектах, где места под бэкапы в принципе выделено ровно под одну копию – свежая копия не могла там собраться по причине нехватки места.
В новой реализации мы решили поменять этот подход: сначала удалять старую и уже потом собирать новую копию. А процесс сбора бэкапов поставить на мониторинг, чтобы узнавать о возникновении каких-либо проблем.
При дискретном резервном копировании старой копией считается архив, который выходит за рамки заданной схемы хранения в формате дни/недели/месяцы. В случае инкрементного резервного копирования бэкапы по умолчанию хранятся год, а удаление старых копий происходит в начале каждого месяца, при этом старыми резервными копиями считаются архивы за тот же месяц прошлого года. Например, перед сбором месячного бэкапа 1 августа 2018 система проверит, есть ли бэкапы за август 2017, и если да, то удалит их. Это позволяет оптимально использовать дисковое пространство.
Логирование
В любом процессе, а в бэкапах особенно, важно держать руку на пульсе и иметь возможность узнавать, если что-то пошло не так. Система ведёт лог своей работы и фиксирует результат каждого шага: запуск/остановка средств, начало/конец выполнения определенного задания, результат сбора копии во временном каталоге, результат копирования/перемещения копии из временного каталога в постоянное место дислокации, результат ротации бэкапов и т.д..
События делятся на 2 уровня:
- Info: информационный уровень – полёт проходит нормально, очередной этап завершился успешно, в логе делается соответствующая запись информационного характера
- Error: уровень ошибки – что-то пошло не так, очередной этап завершился аварийно, в логе делается соответствующая запись об ошибке
E-mail нотификации
По окончанию сбора резервной копии система может рассылать email-уведомления.
Поддерживаются 2 списка получателей:
- Администраторы – те, кто обслуживают сервер. Они получают только нотификации об ошибках, нотификации об успешных операциях им не интересны
- Бизнес-пользователи – в нашем случае это клиенты, которые иногда хотят получать уведомления, чтобы удостовериться, что с бэкапами у них всё хорошо. Или, наоборот, не очень. Они могут выбирать – получать полный лог либо только лог с ошибками.
Структура конфигурационных файлов
Структура конфигурационных файлов выглядит следующим образом:
/etc/nxs-backup
+-- conf.d
¦ +-- desc_files_local.conf
¦ +-- external_clickhouse_local.conf
¦ +-- inc_files_smb.conf
¦ +-- mongodb_nfs.conf
¦ +-- mysql_s3.conf
¦ +-- mysql_xtradb_scp.conf
¦ +-- postgresql_ftp.conf
¦ +-- postgresql_hot_webdav.conf
¦ L-- redis_local_ftp.conf
L-- nxs-backup.confЗдесь /etc/nxs-backup/nxs-backup.conf – главный конфигурационный файл, в котором указываются глобальные настройки:
main:
server_name: SERVER_NAME
admin_mail: project-tech@nixys.ru
client_mail:
- ''
mail_from: backup@domain.ru
level_message: error
block_io_read: ''
block_io_write: ''
blkio_weight: ''
general_path_to_all_tmp_dir: /var/nxs-backup
cpu_shares: ''
log_file_name: /var/log/nxs-backup/nxs-backup.log
jobs: !include [conf.d/*.conf]Массив заданий (jobs) содержит список задач (job), которые представляют собой описание того, что именно бэкапить, где хранить и в каком количестве. Как правило, они выносятся в отдельные файлы (один файл на один job), которые подключаются через include в главном конфигурационном файле.
Также позаботились о том, чтобы максимально оптимизировать процесс подготовки этих файлов и написали простенький генератор. Поэтому администратору не нужно тратить время на поиск шаблона конфига для какого-то сервиса, например, MySQL, а достаточно просто запустить команду:
nxs-backup generate --storage local scp --type mysql --path /etc/nxs-backup/conf.d/mysql_local_scp.confНа выходе генерируется файл /etc/nxs-backup/conf.d/mysql_local_scp.conf:
- job: PROJECT-mysql
type: mysql
tmp_dir: /var/nxs-backup/databases/mysql/dump_tmp
sources:
- connect:
db_host: ''
db_port: ''
socket: ''
db_user: ''
db_password: ''
auth_file: ''
target:
- all
excludes:
- information_schema
- performance_schema
- mysql
- sys
gzip: no
is_slave: no
extra_keys: '--opt --add-drop-database --routines --comments --create-options --quote-names --order-by-primary --hex-blob'
storages:
- storage: local
enable: yes
backup_dir: /var/nxs-backup/databases/mysql/dump
store:
days: ''
weeks: ''
month: ''
- storage: scp
enable: yes
backup_dir: /var/nxs-backup/databases/mysql/dump
user: ''
host: ''
port: ''
password: ''
path_to_key: ''
store:
days: ''
weeks: ''
month: ''В котором остаётся только подставить несколько нужных значений.
Разберём на примере. Пусть у нас на сервере в каталоге /var/www есть две площадки интернет-магазина на 1С-Битрикс (bitrix-1.ru, bitrix-2.ru), каждая из которых работает со своей БД в разных инстансах MySQL (3306 порт для bitrix_1_db и 3307 порт для bitrix_2_db).
Структура файлов типичного Битрикс-проекта примерно следующая:
+-- ...
+-- bitrix
¦ +-- ..
¦ +-- admin
¦ +-- backup
¦ +-- cache
¦ +-- ..
¦ +-- managed_cache
¦ +-- ..
¦ +-- stack_cache
¦ L-- ..
+-- upload
L-- ...Как правило, каталог upload весит много, и со временем только растёт, поэтому его бэкапим инкрементно. Все остальные каталоги — дискретно, за исключением каталогов с кешем и бэкапами, собираемых нативными средствами Bitrix. Пусть схема хранения бэкапов для этих двух площадок должна быть одинакова, при этом копии файлов нужно хранить как локально, так и на удаленном ftp-хранилище, а БД — только на удаленном smb-хранилище.
Итоговые конфигурационные файлы для такого сетапа будут иметь следующий вид:
- job: Bitrix-desc-files
type: desc_files
tmp_dir: /var/nxs-backup/files/desc/dump_tmp
sources:
- target:
- /var/www/*/
excludes:
- bitrix/backup
- bitrix/cache
- bitrix/managed_cache
- bitrix/stack_cache
- upload
gzip: yes
storages:
- storage: local
enable: yes
backup_dir: /var/nxs-backup/files/desc/dump
store:
days: 6
weeks: 4
month: 6
- storage: ftp
enable: yes
backup_dir: /nxs-backup/databases/mysql/dump
host: ftp_host
user: ftp_usr
password: ftp_usr_pass
store:
days: 6
weeks: 4
month: 6 - job: Bitrix-inc-files
type: inc_files
sources:
- target:
- /var/www/*/upload/
gzip: yes
storages:
- storage: ftp
enable: yes
backup_dir: /nxs-backup/files/inc
host: ftp_host
user: ftp_usr
password: ftp_usr_pass
- storage: local
enable: yes
backup_dir: /var/nxs-backup/files/inc - job: Bitrix-mysql
type: mysql
tmp_dir: /var/nxs-backup/databases/mysql/dump_tmp
sources:
- connect:
db_host: localhost
db_port: 3306
db_user: bitrux_usr_1
db_password: password_1
target:
- bitrix_1_db
excludes:
- information_schema
- performance_schema
- mysql
- sys
gzip: no
is_slave: no
extra_keys: '--opt --add-drop-database --routines --comments --create-options --quote-names --order-by-primary --hex-blob'
- connect:
db_host: localhost
db_port: 3307
db_user: bitrix_usr_2
db_password: password_2
target:
- bitrix_2_db
excludes:
- information_schema
- performance_schema
- mysql
- sys
gzip: yes
is_slave: no
extra_keys: '--opt --add-drop-database --routines --comments --create-options --quote-names --order-by-primary --hex-blob'
storages:
- storage: smb
enable: yes
backup_dir: /nxs-backup/databases/mysql/dump
host: smb_host
port: smb_port
share: smb_share_name
user: smb_usr
password: smb_usr_pass
store:
days: 6
weeks: 4
month: 6Параметры для запуска сбора бэкапов
В предыдущем примере мы подготовили конфигурационные файлы job для сбора бэкапов сразу всех элементов: файлов (дискретно и инкрементно), двух БД и их хранения на локальном и внешних (ftp, smb) хранилищах.
Осталось всё это дело запустить. Запуск производится командой:
nxs-backup start $JOB_NAME -c $PATH_TO_MAIN_CONFIGПри этом есть несколько зарезервированных имен job:
- files — выполнение в произвольном порядке всех job с типами desc_files, inc_files (то есть, по сути забэкапить только файлы)
- databases — выполнение в произвольном порядке всех job с типами mysql, mysql_xtradb, postgresql, postgresql_hot, mongodb, redis (то есть, забэкапить только БД)
- external — выполнение в произвольном порядке всех job с типом external (запуск только дополнительных пользовательских скриптов, подробнее об этом ниже)
- all — имитация поочередного запуска команды с job files, databases, external (значение по умолчанию)
Поскольку нам необходимо на выходе получить бэкапы данных как файлов, так и БД по состоянию на одно и тоже время (или с минимальной разницей), то рекомендуется осуществлять запуск nxs-backup с job all, что обеспечит последовательное выполнение описанных job (Bitrix-desc-files, Bitrix-inc_files, Bitrix-mysql).
То есть, важный момент – бэкапы будут собираться не параллельно, а последовательно, один за другим, с минимальной разницей во времени. Более того — само ПО при очередном запуске проверяет наличие уже запущенного процесса в системе и в случае его обнаружения автоматически завершит свою работу с соответствующей пометкой в журнале. Такой подход значительно снижает нагрузку на систему. Минус – бэкапы отдельных элементов собираются не одномоментно, а с некоторой разницей во времени. Но пока наша практика показывает, что это не критично.
Внешние модули
Как было сказано выше, благодаря модульной архитектуре, возможности системы можно расширять с помощью дополнительных пользовательских модулей, которые взаимодействуют с системой через специальный интерфейс. Цель – иметь в будущем возможность добавлять поддержку бэкапов нового ПО без необходимости переписывать nxs-backup.
- job: TEST-external
type: external
dump_cmd: ''
storages:
….Особое внимание необходимо уделить ключу dump_cmd, где в качестве значения указывается полная команда для запуска внешнего скрипта. При этом по завершению выполнения данной команды ожидается, что:
- Будет собран готовый архив данных ПО
- В stdout будут отправлены данные в формате json, вида:
{ "full_path": "ABS_PATH_TO_ARCHIVE", "basename": "BASENAME_ARCHIVE", "extension": "EXTERNSION_OF_ARCHIVE", "gzip": true/false }
- При этом ключи basename, extension, gzip необходимы исключительно для формирования конечного имени бэкапа.
- В случае успешного завершения работы скрипта код возврата должен быть 0 и любой другой в случае возникновения каких-либо проблем.
Например, пусть у нас есть скрипт для создания snapshot etcd /etc/nxs-backup-ext/etcd.py:
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
import json
import os
import subprocess
import sys
import tarfile
def archive(snapshot_path):
abs_tmp_path = '%s.tar' %(snapshot_path)
with tarfile.open(abs_tmp_path, 'w:') as tar:
tar.add(snapshot_path)
os.unlink(snapshot_path)
return abs_tmp_path
def exec_cmd(cmdline):
data_dict = {}
current_process = subprocess.Popen([cmdline], stdout=subprocess.PIPE,
stderr=subprocess.PIPE, shell=True,
executable='/bin/bash')
data = current_process.communicate()
data_dict['stdout'] = data[0][0:-1].decode('utf-8')
data_dict['stderr'] = data[1][0:-1].decode('utf-8')
data_dict['code'] = current_process.returncode
return data_dict
def main():
snapshot_path = "/var/backups/snapshot.db"
dump_cmd = "ETCDCTL_API=3 etcdctl --cacert=/etc/ssl/etcd/ssl/ca.pem --cert=/etc/ssl/etcd/ssl/member-node1.pem"+ " --key=/etc/ssl/etcd/ssl/member-node1-key.pem --endpoints 'https://127.0.0.1:2379' snapshot save %s" %snapshot_path
command = exec_cmd(dump_cmd)
result_code = command['code']
if result_code:
sys.stderr.write(command['stderr'])
else:
try:
new_path = archive(snapshot_path)
except tarfile.TarError as e:
sys.exit(1)
else:
result_dict = {
"full_path": new_path,
"basename": "etcd",
"extension": "tar",
"gzip": False
}
print(json.dumps(result_dict))
sys.exit(result_code)
if __name__ == '__main__':
main()Конфиг для запуска этого скрипта выглядит следующим образом:
- job: etcd-external
type: external
dump_cmd: '/etc/nxs-backup-ext/etcd.py'
storages:
- storage: local
enable: yes
backup_dir: /var/nxs-backup/external/dump
store:
days: 6
weeks: 4
month: 6При этом программа при запуске job etcd-external:
- Запустит на выполнение скрипт /etc/nxs-backup-ext/etcd.py без параметров
- После завершения работы скрипта проверит код завершения и наличие необходимых данных в stdout
- Если все проверки прошли успешно, дальше задействуется тот же механизм, что и при работе уже встроенных модулей, где в качестве tmp_path выступает значение ключа full_path. Если нет — завершит выполнение данного задания с соответствующей отметкой в журнале.
Поддержка и обновление
Процесс разработки и поддержки новой системы бэкапов реализован у нас по всем канонам CI/CD. Больше никаких обновлений и правок скриптов на боевых серверах. Все изменения проходят через наш центральный git-репозиторий в Gitlab, где в pipeline прописана сборка новых версий deb/rpm-пакетов, которые затем загружаются в наши deb/rpm репозитории. И уже после этого через менеджер пакетов доставляются на конечные сервера клиентов.
Как скачать nxs-backup?
Мы сделали nxs-backup open-source проектом. Любой желающий может скачать и пользоваться им для организации процесса бекапа в своих проектах, а также дорабатывать под свои нужды, писать внешние модули.
Исходный код nxs-backup можно скачать с Github-репозитория по этой ссылке. Там же находится инструкция по установке и настройке.
Также мы подготовили Docker-образ и выложили его на DockerHub.
Если в процессе настройки или использования возникнут вопросы, напишите нам. Мы поможем разобраться и доработаем инструкцию.
Заключение
В ближайших планах у нас реализовать следующий функционал:
- Интеграцию с мониторингом
- Шифрование резервных копий
- Web-интерфейс для управления настройками бэкапов
- Разворачивание бэкапов средствами nxs-backup
- И многое другое
Комментарии (21)

polearnik
01.10.2018 10:45+1возможно невнимательно читал Но зачем бэкапить веб сайты если они есть в системе контроля версий? Нужно ранить загруженные файлы и снимки баз данных.
victoremelian Автор
01.10.2018 14:24Здравствуйте!
Я с Вами абсолютно согласен, что в случае использования на проекте системы контроля версий необходимость в бэкапе кода отпадает. Но дело в том, что на нашем обслуживании есть некоторое количество проектов, которые по каким-то причинам не используют VCS и работают с кодом исключительно по ftp/ssh.
Поэтому мы рассматриваем обобщённый вариант, который можно будет адаптировать под конкретный случай.

fessmage
01.10.2018 13:31В списке рассмотренных решений не увидел, поэтому упомяну то что использу: restic, restic/rest-server и rclone.
Restic обеспечивает отличное хранение снапшотами и дедупликацию, удаление лишних снапшотов в соответствии с политикой хранения, проверку целостности данных. Плюс встроенное шифрование и эффективность, позволяющая полностью загрузить дисковую подсистему/сеть.
Rclone же позволяет restic-у бекапиться на облачные файловые хранилища.victoremelian Автор
01.10.2018 14:46Rclone мы успешно применяем в нашей работе для синхронизации копий в наше собственное облачное хранилище, а что касается restic — то ранее нам не приходилось с ним сталкиваться. Обязательно изучим его возможности и посмотрим какие идеи или наработки можно использовать для нашего инструмента.
Спасибо за информацию!
zapimir
02.10.2018 00:55У вас небольшая путаница с терминологией. Холодный бэкап БД — это когда для бэкапа останавливают сервер БД и тупо копируют файлы данных. В вашем же случае и mysqldump, и XtraBackup — это горячий бэкап. Они отличаются по другому признаку. Первый делает логический бэкап (человекопонятный), просто набор SQL-запросов, который человек может легко исправить, если нужно. Вторая же тулза делает физический (бинарный) бэкап, т.е. по сути это ближе к холодному бэкапу, так как физически копируются файлы базы данных (но без остановки сервера), и человек его вручную не отредактирует.
Да и параметр mysql_xtradb как-то не очень подходит. Так как, есть такой движок таблиц с названием xtradb (в форке MySQL от Percona), и можно подумать, что это только для него. В то время, как в XtraBackup нет буквы «D».victoremelian Автор
02.10.2018 08:41Формально Вы правы, но в данном случае, употребляя термины «холодный» и «горячий» бэкапы БД, целью было подчеркнуть, что в первом случае (при использовании mysqldump) во время сбора дампа могут наблюдаться проблемы в работе проекта, связанные с блокировками, в то время как во втором случае (xtrabackup) вероятность этого события стремится к нулю, т.е. с точки зрения клиента это сопоставимо с остановкой/непрерывной работой СУБД.
Что касается замечания относительно типа mysql_xtradb — я с Вами соглашусь, в ближайшее время внесем необходимые изменения в наименование типа.
Спасибо за ценные замечания!zapimir
02.10.2018 16:37Ну, понимаете, холодный и горячий бэкап это устоявшиеся термины, а не просто красивые слова. Так что стоит придерживаться общепринятой терминологии, тем более, если тулзу делаете не только для себя.
Тем более mysqldump именно горячий бэкап, он работает исключительно при работающем сервере, так как, в процессе просто выполняются SQL-запросы. А тормоза с проектом, будут практически в любом случае при бэкапе, так как серверу нужно перелопатить большой объем данных, к тому же еще и сжать их, да и для таблиц MyISAM в любом случае блокировка делается.
Можно назвать logical и physical (или dump/sql и binary/raw). А то без заглядывания в доки никогда бы не догадался, что cold это создание SQL-дампа.
Ну и раз делаете свой репозиторий, возможно неплохо было бы включить в комплект mydumper, чтобы он шёл из коробки.victoremelian Автор
03.10.2018 14:27Согласен с Вами и чтобы у всех было единое представление о возможностях ПО, термины «горячий» и «холодный» бэкап в ближайшее время будут заменены на logical и physical. Что касается включения в комплект mydumper, то мы обязательно рассмотрим такой вариант.
Спасибо за предложение!
thelost1295
02.10.2018 08:42Скажите, а почему в списке open-source имеющихся систем нет BackupPC?
victoremelian Автор
02.10.2018 08:45Статья не призвана сделать обзор всех имеющихся open-source систем резервного копирования и в ней представлено только то ПО, которые мы изучили в поисках лучшего решения для наших задач. BackupPC не был озвучен нами потому, что ранее мы не сталкивались с этим продуктом и не изучали его возможности.
При беглом ознакомлении с документацией уже можно сказать, что данное ПО нам бы не подошло хотя бы потому, что у него нет нативной поддержки бэкапов БД.
MrFrizzy
02.10.2018 15:57Я тут «имел удовольствие» бэкапить 1.5 тб фотографий в 3-х уровневой структуре с помощью Borg — из-за того, что он хранит бэкап в бинарных файлах единым массивом, листинг потом мог занимать часы, а восстановление сотни файлов пару дней — столько же, сколько сам бэкап изначально совершался. Хуже того, сама обратная связь на ошибки или отсутствие файлов была такой же медленной.
Я так понимаю, это проблема всех решений, кто хранит бэкап в виде снимков.
Как у вашей утилиты обстоят дела с таким кейсом? :)
Сильно сложно проверить существование и восстановить несколько файлов из инкрементального архива?MrFrizzy
02.10.2018 16:00upd: и продолжается ли бэкап при обрыве связи, например, сессия ssh дропнулась, или бэкап просто заканчивается с ошибкой?
victoremelian Автор
03.10.2018 14:37К сожалению, пока нам не удалось протестировать утилиту на таком объеме данных. Но поскольку как дискретные, так и инкрементные копии хранятся в формате tar, то каких-либо проблем с получением листинга и восстановлением конкретного файла из архива возникнуть не должно. Например, получить листинг файлов в архиве можно командой:
tar -tf <path_to_tarfile>
Извлечь конкретный файл из архива:
tar -xf <path_to_tarfile> [<file_1_in_archive> <file_2_in_archive> ..]MrFrizzy
03.10.2018 15:13Ну то есть это пока никак не автоматизировано :)
Все-таки найти файл в нескольких инкрементальных архивах и распаковать его по сети не то же самое, что извлечь один файл из одного архива на локалхосте :)victoremelian Автор
03.10.2018 15:49upd: и продолжается ли бэкап при обрыве связи, например, сессия ssh дропнулась, или бэкап просто заканчивается с ошибкой?
Если Вас имеете в виду, что будет в случае, если во время работы утилиты оборвется связь с удаленным storage, в который должен быть загружен файл, то стоит пояснить следующее — за исключением инкрементных копий файлов бэкап всегда сначала собирается локально во временной директории. Затем, архив поочередно копируется на все удаленные storage, после чего локально перемещается в постоянное место дислокации или удаляется (в зависимости от того, используется ли локальный storage).
Поэтому, если по какой-либо причине во время копирования файла на удаленный storage с ним была потеряна связь, то утилита должна сообщить о проблемах (сделать соответствующую пометку в лог-файле) и приступить к работе со следующим хранилищем, в том числе и локальным.
При ответе на Ваш вопрос мы обнаружили баг в коде, при котором утилита аварийно завершает свою работу, в случае обрыва связи во время передачи файла на какое-либо удаленное хранилище. В ближайшее время этот баг будет устранен, спасибо за интересный вопрос!
Ну то есть это пока никак не автоматизировано :)
Да, пока процесс распаковки архива никак не автоматизирован. Этот функционал будет реализован в следующем релизе.
zapimir
04.10.2018 04:21о каких-либо проблем с получением листинга и восстановлением конкретного файла из архива возникнуть не должно.
Это как раз сомнительно, так как tar файлы не содержат в себе листинга файлов, и чтобы получить листинг файлов нужно прочитать весь файл. В случае если файл где-то в удаленном хранилище, то его для простого листинга нужно весь скачать, и если речь хотя бы о архиве в сотни мегабайт, то процесс будет весьма не быстрым (не говоря о бэкапах в гигабайты).
Sovetnikov
03.10.2018 09:05Интересная утилита, но про настройку хранилища S3 ничего нет в документации.
В документации отмечено, что пользователю надо самостоятельно настраивать s3fs, напишите хотя бы вкратце что и как. Особенно интересно как подключиться не к AWS серверам S3, а к сторонним.
Разберёмся конечно, но как-то «волшебство» утилиты начинает биться об реальность :)
И я так понимаю, что нельзя настроить внешний SMTP аккаунт для отправки E-mail оповещений?
И что за формат конфигурационных файлов? Это yml?victoremelian Автор
03.10.2018 16:02Интересная утилита, но про настройку хранилища S3 ничего нет в документации.
В документации отмечено, что пользователю надо самостоятельно настраивать s3fs, напишите хотя бы вкратце что и как. Особенно интересно как подключиться не к AWS серверам S3, а к сторонним.Спасибо за ценное замечание, в ближайшее время дополним документацию по настройке s3. Что касается подключения к пользовательским серверам через s3 REST API интерфейс, то сама утилита s3fs поддерживает такую возможность, однако nxs-backup на текуший момент может работать только с AWS. Поскольку это, действительно, может оказаться полезной фичей — мы реализуем данный функционал в nxs-backup.
И я так понимаю, что нельзя настроить внешний SMTP аккаунт для отправки E-mail оповещений?
На текущий момент отправка почты осуществляется через системный sendmail, который уже можно настроить под свои нужды. В ближайших планах дать возможность рулить настройками почты через nxs-backup.
И что за формат конфигурационных файлов? Это yml?
Да, именно так.
Sovetnikov
03.10.2018 16:39Про сторонние S3 очень даже полезная фича в свете импортозамещения :)
А s3fs в docker ровно работает?
flasher007
Неплохо, пошел пробовать)