В Grammarly основа нашего бизнеса — центральный языковой движок — написан на Common Lisp. Сейчас движок обрабатывает более чем тысячу предложений в секунду, масштабируется горизонтально и надежно служит нам в продакшене почти 3 года.
Мы заметили, что почти нет постов о развертывании Lisp софта в современной облачной инфраструктуре, поэтому мы решили, что поделиться нашим опытом будет хорошей идеей. Рантайм и среда программирования Lisp'а предоставляют несколько уникальных, немного непривычных, возможностей для поддержки продакшн систем (для нетерпеливых — они описаны в последней части).

Вопреки распространенному мнению, Lisp это невероятно практичный язык для создания продакшн систем. Вобще говоря, вокруг нас много Lisp-систем: когда вы ищите авиа-билет на Hipmunk или едете в метро в Лондоне, используются Lisp-программы.
Наши Lisp-сервисы концептуально представляют собой классическое ИИ-приложение, которое функционирует на огромной куче знаний, созданных лингвистами и исследователями. Его главный используемый ресурс это ЦПУ, и это один из крупнейших потребителей вычислительных ресурсов в нашей сети.
Система работает на обычных образах Линукс, развернутых в AWS. Мы используем SBCL для продакшена и CCL на большинстве машин разработчиков. Один из приятных моментов при использовании Lisp'а — вы имеете возможность выбора из нескольких развитых реализаций с различными плюсами и минусами: в нашем случае мы оптимизировали скорость работы на сервере и скорость компиляции при разработке (почему это критично для нас описано далее).

В Grammarly мы используем множество языков программирования для разработки наших сервисов: кроме языков для JVM и Javascript'а мы также пишем на Erlang, Python и Go. Должная инкапсуляция сервисов позволяет нам использовать тот язык или платформу, который лучше всего подходит для задачи. Такой подход имеет определенную цену в обслуживании, но мы ценим выбор и свободу больше, чем правила и шаблоны.
Мы также стараемся опираться на простые, не завязанные на языки, инфраструктурные утилиты. Такой подход освобождает нас от множества проблем при интеграции всего этого зоопарка технологий в нашей платформе. Например, statsd отличный пример невероятно простого и полезного сервиса, который очень легко использовать. Другой — Graylog2, он предоставляет шикарную спецификацию для логирования, и несмотря на то, что не было готовой библиотеки для работы с ним из CL, ее было очень легко собрать из того, что доступно в Lisp-экосистеме. Вот весь код, который нужен (и практически весь он просто слово в слово перевод спецификации):
Отсутствие библиотек в экосистеме — одна из частых претензий к Lisp'у. Как видите, 5 библиотек использованы только в этом примере для таких вещей как кодирование, сжатие, получение Unix-времени и сокет соединения.
Lisp-библиотеки действительно существуют, но, как и во всех интеграциях библиотек, мы сталкиваемся с проблемами. Для примера, чтобы подключить Jenkins CI, нам пришлось использовать xUnit и было не очень просто найти спецификации для него. К счастью, помог один вопрос на Stackoverflow — в итоге мы встроили его в свою собственную библиотеку тестирования should-test.
Еще один пример — использование HDF5 для обмена моделями машинного обучения: мы потратили некоторое время на адаптацию низкоуровневой библиотеки hdf5-cffi для наших реалий, но нам пришлось потратить намного больше времени на обновление наших AMI (Amazon Machine Image) для поддержки текущей версии C библиотеки.
Другой принцип, которому мы следуем в платформе Grammarly — это максимальная декомпозиция различных сервисов для обеспечения горизонтальной масштабируемости и функциональной независимости — про это пост моего коллеги. Таким образом нам не нужно взаимодействовать с базами данных в критических частях наших сервисов языкового ядра. Однако, мы используем MySQL, Postgres, Redis и Mongo для внутреннего хранилища, и мы успешно применяли CLSQL, postmodern, cl-redis и cl-mongo для доступа к ним из Lisp'а.
Мы используем Quicklisp для управления внешними зависимостями и простую систему упаковки исходного кода библиотеки с проектом для собственных библиотек и форков. Репозиторий Quicklisp содержит более 1000 Lisp-библиотек: не супер огромное число, но вполне достаточное для удовлетворения всех потребностей нашего продакшена.
Для развертывания в продакшене мы используем универсальный стек: приложение тестируется и собирается с помощью Jenkins, доставляется на сервера благодаря Rundeck и запускается там через Upstart как обычный Unix-процесс.
В целом, проблемы, с которыми мы сталкиваемся при интеграции Lisp-приложений в облачный мир, радикально не отличаются от тех, которые мы встречаем во множестве других технологий. Если вы хотите использовать Lisp в продакшене и испытывать удовольствие от написания Lisp-кода, нет ни одной реальной технической причины не делать этого!

Как бы ни была идеальна эта история, не все только про радуги и единорогов.
Мы создали эзотерическое приложение (даже по меркам Lisp-мира) и в процессе уперлись в некоторые ограничения платформы. Одной такой неожиданностью было исчерпание памяти во время компиляции. Мы очень сильно полагаемся на макросы, и самые большие из них раскрываются в тысячи строк низкоуровневого кода. Оказалось, что компилятор SBCL реализует множество оптимизаций, благодаря которым мы можем наслаждаться довольно быстрым сгенерированным кодом, но некоторые из них требуют экспоненциальных времени и памяти. К сожалению, нет способа выключить или отрегулировать их. Несмотря на это, существует известное общее решение, стиль call-with-*, которое позволяет немного пожертвовать эффективности ради лучшей модульности (что оказалось решающим в нашем случае) и отлаживаемости.
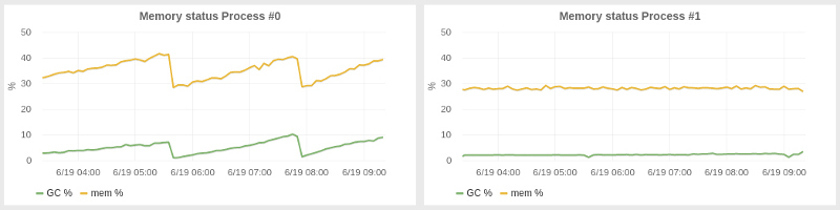
Регулировка сборщика мусора для уменьшения задержек и улучшения утилизации ресурсов в нашей системе оказалась менее неожиданной проблемой в отличие от приручения компилятора. SBCL предоставляет годный сборщик мусора, основанный на поколениях, хотя и не настолько изощренный как в JVM. Нам пришлось настраивать размеры поколений и оказалось, что лучшим вариантом было использование кучи увеличенного размера: наше приложение потребляет 2-4 гигабайта памяти, но мы запустили его с кучей на 25G, что автоматически привело к увеличению размера первого поколения. Еще одна настройка, которую нам пришлось сделать, гораздо менее очевидная, была запуском GC программно каждые N минут. С увеличенной кучей мы заметили постепенное наращивание использования памяти за периоды в десятки минут, из-за чего все больше времени тратилось на GC и уменьшалась производительность приложения. Наш подход с периодическим GC привел систему в более стабильное состояние с практически константным потреблением памяти. Слева видно, как выполняется система без наших настроек, а справа — эффект периодического GC.
Из всех этих трудностей, самым неприятным багом, что я встречал, был сетевой баг. Как обычно бывает в таких ситуациях, баг был не в приложении, а в нижележащей платформе (в этот раз — SBCL). И, более того, я напоролся на него дважды в двух разных сервисах, но в первый раз я не смог вычислить его, так что пришлось его обойти.
Когда мы только начинали запуск нашего сервиса на существенных нагрузках в продакшене, после некоторого времени нормального функционирования все сервера внезапно начинали замедляться и в конце концов становились недоступны. После длительного расследования с подозрением на входные данные, мы обнаружили, что проблема была в гонке в низкоуровневом сетевом коде SBCL, конкретно в способе вызова функции сокета — getprotobyname, которая не была потокобезопасной. Это была очень маловероятная гонка, так что она проявляла себя только в высоконагруженном сетевом сервисе, когда эта функция вызывалась десятки тысяч раз. Это выбивало один рабочий поток за другим, постепенно вводя систему в кому.
Вот фикс, на котором мы остановились, к сожалению, его нельзя использовать в более широком контексте как библиотеку. (Баг был отправлен к команде SBCL и был исправлен, но мы все еще используем этот хак, на всякий случай :)

Системы Common Lisp реализуют множество идей легендарных Lisp-машин. Одна из наиболее выдающихся — это интерактивное окружение SLIME. Пока индустрия ожидает созревания LightTable и ему подобных инструментов, Lisp-программисты тихонько наслаждаются такими возможностями в SLIME много лет. Узрите мощь этой до зубов вооруженной и функционирующей боевой станции в действии.
Но SLIME это не просто подход Lisp'а к IDE. Будучи клиент-серверным приложением, оно позволяет запускать свой бэкенд на удаленной машине и подключаться к ней из вашего локального Emacs (или Vim, если у вас нет выбора, с SLIMV). Программисты Java могут подумать о JConsole, но тут вы не скованы предопределенным набором операций и можете производить любую интроспекцию или изменение, какое только захотите. Мы бы не смогли отловить гонку в функции сокета без этих возможностей.
Более того, удаленная консоль — это не единственная полезная утилита предоставляемая SLIME. Как и множество IDE она может переходить в исходный код функций, но в отличие от Java или Python, у меня на машине есть исходный код SBCL, так что я часто просматриваю исходные коды реализации, и это очень сильно помогает в изучении того, что происходит «под капотом». Для случая с сокетным багом это также было важной частью процесса отладки.
Наконец, еще одна супер полезная утилита для интроспекции и дебага, которой мы пользуемся — TRACE. Она полностью изменила мой подход к отладке программ, теперь вместо нудного выполнения кода по шагам я могу проанализировать всю картину в целом. Этот инструмент также помог нам локализовать наш баг с сокетами.
С trace вы указываете функцию для трассировки, выполняете код, и Lisp печатает все вызовы этой функции и ее аргументы и все результаты которые она возвращает. Это что-то похожее на трейс стека, но вам не нужен полный стек и вы динамически получаете поток трассировок, без остановки приложения. trace это как print на стероидах, который позволяет быстро проникнуть во внутренности кода любой сложности и отслеживать сложные пути выполнения хода программы. Ее единственный недостаток — нельзя трейсить макросы.
Вот фрагмент трейса, который я сделал буквально сегодня, чтобы убедиться, что JSON-запрос к одному из наших сервисов формируется корректно и возвращает нужный результат:
Так, для отладки нашего ужасного сокетного бага мне пришлось закопаться глубоко в сетевой код SBCL и изучить вызываемые функции, затем подключиться по SLIME к умирающему серверу и пробовать трейсить эти функции одну за другой. И когда я получил вызов, который не вернулся — это было оно. В итоге, после выяснение в мануале того, что функция не является потокобезопасной и встречи нескольких упоминаний про это в комментариях исходного кода SBCL, я убедился в своей гипотезе.
Эта статья про то, что Lisp показал себя удивительно надежной платформой для одного из наших самых критичных проектов. Он вполне соответствует общим требованиями современной облачной инфраструктуры, и несмотря на то, что этот стек не очень широко известен и популярен, он имеет свои сильные стороны — вам нужно только научиться использовать их. Что уж говорить про мощь Lisp-подхода к решению сложных задач, за который мы его так любим. Но это уже совершенно другая история…
Прим. переводчика:
Я вдвойне рад что про использование Common Lisp в продакшене пишут, и даже пишут люди из СНГ, ведь у нас практики работы с этим стеком практически нет. Надеюсь после прочтения данной статьи кто-то обратит внимание на эту сильно недооцененную технологию.
Мы заметили, что почти нет постов о развертывании Lisp софта в современной облачной инфраструктуре, поэтому мы решили, что поделиться нашим опытом будет хорошей идеей. Рантайм и среда программирования Lisp'а предоставляют несколько уникальных, немного непривычных, возможностей для поддержки продакшн систем (для нетерпеливых — они описаны в последней части).
Wut Lisp?!!
Вопреки распространенному мнению, Lisp это невероятно практичный язык для создания продакшн систем. Вобще говоря, вокруг нас много Lisp-систем: когда вы ищите авиа-билет на Hipmunk или едете в метро в Лондоне, используются Lisp-программы.
Наши Lisp-сервисы концептуально представляют собой классическое ИИ-приложение, которое функционирует на огромной куче знаний, созданных лингвистами и исследователями. Его главный используемый ресурс это ЦПУ, и это один из крупнейших потребителей вычислительных ресурсов в нашей сети.
Система работает на обычных образах Линукс, развернутых в AWS. Мы используем SBCL для продакшена и CCL на большинстве машин разработчиков. Один из приятных моментов при использовании Lisp'а — вы имеете возможность выбора из нескольких развитых реализаций с различными плюсами и минусами: в нашем случае мы оптимизировали скорость работы на сервере и скорость компиляции при разработке (почему это критично для нас описано далее).
A stranger in a strange land
В Grammarly мы используем множество языков программирования для разработки наших сервисов: кроме языков для JVM и Javascript'а мы также пишем на Erlang, Python и Go. Должная инкапсуляция сервисов позволяет нам использовать тот язык или платформу, который лучше всего подходит для задачи. Такой подход имеет определенную цену в обслуживании, но мы ценим выбор и свободу больше, чем правила и шаблоны.
Мы также стараемся опираться на простые, не завязанные на языки, инфраструктурные утилиты. Такой подход освобождает нас от множества проблем при интеграции всего этого зоопарка технологий в нашей платформе. Например, statsd отличный пример невероятно простого и полезного сервиса, который очень легко использовать. Другой — Graylog2, он предоставляет шикарную спецификацию для логирования, и несмотря на то, что не было готовой библиотеки для работы с ним из CL, ее было очень легко собрать из того, что доступно в Lisp-экосистеме. Вот весь код, который нужен (и практически весь он просто слово в слово перевод спецификации):
(defun graylog (message &key level backtrace file line-no)
(let ((msg (salza2:compress-data
(babel:string-to-octets
(json:encode-json-to-string #{
:version "1.0"
:facility "lisp"
:host *hostname*
:|short_message| message
:|full_message| backtrace
:timestamp (local-time:timestamp-to-unix (local-time:now))
:level level
:file file
:line line-no
})
:encoding :utf-8)
'salza2:zlib-compressor)))
(usocket:socket-send (usocket:socket-connect
*graylog-host* *graylog-port*
:protocol :datagram :element-type '(unsigned-byte 8))
msg (length msg))))
Отсутствие библиотек в экосистеме — одна из частых претензий к Lisp'у. Как видите, 5 библиотек использованы только в этом примере для таких вещей как кодирование, сжатие, получение Unix-времени и сокет соединения.
Lisp-библиотеки действительно существуют, но, как и во всех интеграциях библиотек, мы сталкиваемся с проблемами. Для примера, чтобы подключить Jenkins CI, нам пришлось использовать xUnit и было не очень просто найти спецификации для него. К счастью, помог один вопрос на Stackoverflow — в итоге мы встроили его в свою собственную библиотеку тестирования should-test.
Еще один пример — использование HDF5 для обмена моделями машинного обучения: мы потратили некоторое время на адаптацию низкоуровневой библиотеки hdf5-cffi для наших реалий, но нам пришлось потратить намного больше времени на обновление наших AMI (Amazon Machine Image) для поддержки текущей версии C библиотеки.
Другой принцип, которому мы следуем в платформе Grammarly — это максимальная декомпозиция различных сервисов для обеспечения горизонтальной масштабируемости и функциональной независимости — про это пост моего коллеги. Таким образом нам не нужно взаимодействовать с базами данных в критических частях наших сервисов языкового ядра. Однако, мы используем MySQL, Postgres, Redis и Mongo для внутреннего хранилища, и мы успешно применяли CLSQL, postmodern, cl-redis и cl-mongo для доступа к ним из Lisp'а.
Мы используем Quicklisp для управления внешними зависимостями и простую систему упаковки исходного кода библиотеки с проектом для собственных библиотек и форков. Репозиторий Quicklisp содержит более 1000 Lisp-библиотек: не супер огромное число, но вполне достаточное для удовлетворения всех потребностей нашего продакшена.
Для развертывания в продакшене мы используем универсальный стек: приложение тестируется и собирается с помощью Jenkins, доставляется на сервера благодаря Rundeck и запускается там через Upstart как обычный Unix-процесс.
В целом, проблемы, с которыми мы сталкиваемся при интеграции Lisp-приложений в облачный мир, радикально не отличаются от тех, которые мы встречаем во множестве других технологий. Если вы хотите использовать Lisp в продакшене и испытывать удовольствие от написания Lisp-кода, нет ни одной реальной технической причины не делать этого!
The hardest bug I've ever debugged
Как бы ни была идеальна эта история, не все только про радуги и единорогов.
Мы создали эзотерическое приложение (даже по меркам Lisp-мира) и в процессе уперлись в некоторые ограничения платформы. Одной такой неожиданностью было исчерпание памяти во время компиляции. Мы очень сильно полагаемся на макросы, и самые большие из них раскрываются в тысячи строк низкоуровневого кода. Оказалось, что компилятор SBCL реализует множество оптимизаций, благодаря которым мы можем наслаждаться довольно быстрым сгенерированным кодом, но некоторые из них требуют экспоненциальных времени и памяти. К сожалению, нет способа выключить или отрегулировать их. Несмотря на это, существует известное общее решение, стиль call-with-*, которое позволяет немного пожертвовать эффективности ради лучшей модульности (что оказалось решающим в нашем случае) и отлаживаемости.
Регулировка сборщика мусора для уменьшения задержек и улучшения утилизации ресурсов в нашей системе оказалась менее неожиданной проблемой в отличие от приручения компилятора. SBCL предоставляет годный сборщик мусора, основанный на поколениях, хотя и не настолько изощренный как в JVM. Нам пришлось настраивать размеры поколений и оказалось, что лучшим вариантом было использование кучи увеличенного размера: наше приложение потребляет 2-4 гигабайта памяти, но мы запустили его с кучей на 25G, что автоматически привело к увеличению размера первого поколения. Еще одна настройка, которую нам пришлось сделать, гораздо менее очевидная, была запуском GC программно каждые N минут. С увеличенной кучей мы заметили постепенное наращивание использования памяти за периоды в десятки минут, из-за чего все больше времени тратилось на GC и уменьшалась производительность приложения. Наш подход с периодическим GC привел систему в более стабильное состояние с практически константным потреблением памяти. Слева видно, как выполняется система без наших настроек, а справа — эффект периодического GC.
Из всех этих трудностей, самым неприятным багом, что я встречал, был сетевой баг. Как обычно бывает в таких ситуациях, баг был не в приложении, а в нижележащей платформе (в этот раз — SBCL). И, более того, я напоролся на него дважды в двух разных сервисах, но в первый раз я не смог вычислить его, так что пришлось его обойти.
Когда мы только начинали запуск нашего сервиса на существенных нагрузках в продакшене, после некоторого времени нормального функционирования все сервера внезапно начинали замедляться и в конце концов становились недоступны. После длительного расследования с подозрением на входные данные, мы обнаружили, что проблема была в гонке в низкоуровневом сетевом коде SBCL, конкретно в способе вызова функции сокета — getprotobyname, которая не была потокобезопасной. Это была очень маловероятная гонка, так что она проявляла себя только в высоконагруженном сетевом сервисе, когда эта функция вызывалась десятки тысяч раз. Это выбивало один рабочий поток за другим, постепенно вводя систему в кому.
Вот фикс, на котором мы остановились, к сожалению, его нельзя использовать в более широком контексте как библиотеку. (Баг был отправлен к команде SBCL и был исправлен, но мы все еще используем этот хак, на всякий случай :)
#+unix
(defun sb-bsd-sockets:get-protocol-by-name (name)
(case (mkeyw name)
(:tcp 6)
(:udp 17)))
Back to the future
Системы Common Lisp реализуют множество идей легендарных Lisp-машин. Одна из наиболее выдающихся — это интерактивное окружение SLIME. Пока индустрия ожидает созревания LightTable и ему подобных инструментов, Lisp-программисты тихонько наслаждаются такими возможностями в SLIME много лет. Узрите мощь этой до зубов вооруженной и функционирующей боевой станции в действии.
Но SLIME это не просто подход Lisp'а к IDE. Будучи клиент-серверным приложением, оно позволяет запускать свой бэкенд на удаленной машине и подключаться к ней из вашего локального Emacs (или Vim, если у вас нет выбора, с SLIMV). Программисты Java могут подумать о JConsole, но тут вы не скованы предопределенным набором операций и можете производить любую интроспекцию или изменение, какое только захотите. Мы бы не смогли отловить гонку в функции сокета без этих возможностей.
Более того, удаленная консоль — это не единственная полезная утилита предоставляемая SLIME. Как и множество IDE она может переходить в исходный код функций, но в отличие от Java или Python, у меня на машине есть исходный код SBCL, так что я часто просматриваю исходные коды реализации, и это очень сильно помогает в изучении того, что происходит «под капотом». Для случая с сокетным багом это также было важной частью процесса отладки.
Наконец, еще одна супер полезная утилита для интроспекции и дебага, которой мы пользуемся — TRACE. Она полностью изменила мой подход к отладке программ, теперь вместо нудного выполнения кода по шагам я могу проанализировать всю картину в целом. Этот инструмент также помог нам локализовать наш баг с сокетами.
С trace вы указываете функцию для трассировки, выполняете код, и Lisp печатает все вызовы этой функции и ее аргументы и все результаты которые она возвращает. Это что-то похожее на трейс стека, но вам не нужен полный стек и вы динамически получаете поток трассировок, без остановки приложения. trace это как print на стероидах, который позволяет быстро проникнуть во внутренности кода любой сложности и отслеживать сложные пути выполнения хода программы. Ее единственный недостаток — нельзя трейсить макросы.
Вот фрагмент трейса, который я сделал буквально сегодня, чтобы убедиться, что JSON-запрос к одному из наших сервисов формируется корректно и возвращает нужный результат:
0: (GET-DEPS
("you think that's bad, hehe, i remember once i had an old 100MHZ dell unit i was using as a server in my room"))
1: (JSON:ENCODE-JSON-TO-STRING
#<HASH-TABLE :TEST EQL :COUNT 2 {1037DD9383}>)
2: (JSON:ENCODE-JSON-TO-STRING "action")
2: JSON:ENCODE-JSON-TO-STRING returned "\"action\""
2: (JSON:ENCODE-JSON-TO-STRING "sentences")
2: JSON:ENCODE-JSON-TO-STRING returned "\"sentences\""
1: JSON:ENCODE-JSON-TO-STRING returned
"{\"action\":\"deps\",\"sentences\":[\"you think that's bad, hehe, i remember once i had an old 100MHZ dell unit i was using as a server in my room\"]}"
0: GET-DEPS returned
((("nsubj" 1 0) ("ccomp" 9 1) ("nsubj" 3 2) ("ccomp" 1 3) ("acomp" 3 4)
("punct" 9 5) ("intj" 9 6) ("punct" 9 7) ("nsubj" 9 8) ("root" -1 9)
("advmod" 9 10) ("nsubj" 12 11) ("ccomp" 9 12) ("det" 17 13)
("amod" 17 14) ("nn" 16 15) ("nn" 17 16) ("dobj" 12 17)
("nsubj" 20 18) ("aux" 20 19) ("rcmod" 17 20) ("prep" 20 21)
("det" 23 22) ("pobj" 21 23) ("prep" 23 24)
("poss" 26 25) ("pobj" 24 26)))
((<you 0,3> <think 4,9> <that 10,14> <'s 14,16> <bad 17,20> <, 20,21>
<hehe 22,26> <, 26,27> <i 28,29> <remember 30,38> <once 39,43>
<i 44,45> <had 46,49> <an 50,52> <old 53,56> <100MHZ 57,63>
<dell 64,68> <unit 69,73> <i 74,75> <was 76,79> <using 80,85>
<as 86,88> <a 89,90> <server 91,97> <in 98,100> <my 101,103>
<room 104,108>))
Так, для отладки нашего ужасного сокетного бага мне пришлось закопаться глубоко в сетевой код SBCL и изучить вызываемые функции, затем подключиться по SLIME к умирающему серверу и пробовать трейсить эти функции одну за другой. И когда я получил вызов, который не вернулся — это было оно. В итоге, после выяснение в мануале того, что функция не является потокобезопасной и встречи нескольких упоминаний про это в комментариях исходного кода SBCL, я убедился в своей гипотезе.
Эта статья про то, что Lisp показал себя удивительно надежной платформой для одного из наших самых критичных проектов. Он вполне соответствует общим требованиями современной облачной инфраструктуры, и несмотря на то, что этот стек не очень широко известен и популярен, он имеет свои сильные стороны — вам нужно только научиться использовать их. Что уж говорить про мощь Lisp-подхода к решению сложных задач, за который мы его так любим. Но это уже совершенно другая история…
Прим. переводчика:
Я вдвойне рад что про использование Common Lisp в продакшене пишут, и даже пишут люди из СНГ, ведь у нас практики работы с этим стеком практически нет. Надеюсь после прочтения данной статьи кто-то обратит внимание на эту сильно недооцененную технологию.
Комментарии (10)

phozzy
11.07.2015 07:10как я понимаю, для clojure это все тоже применимо?

loz Автор
11.07.2015 11:05+1Частично, в комментариях к оригинальному посту есть обсуждение clojure в данном контексте. Например, там обсуждается что в Common Lisp возможности интроспекции намного лучше и вобще он более динамичный (например пакеты лучше чем неймспейсы), CLOS отличная объектная система, система сигналов так же очень мощная и полезная, есть доступ к ридер-макросам, и язык не привязан к окружающей платформе (в смысле ограничений которые переносятся в язык).
Так же там есть комментарии по поводу TRACE в clojure, у которой есть определенные ограничения.

SirEdvin
Я правильно понимаю, что у автора на машине нет исходного кода Java или Python?
Они были им специально удалены или как такое получилось?
Если же речь идет о методах и классах, которые реализуются для каждой платформы отдельно и поставляются через линкеры, то разве в Lisp не так же?
loz Автор
Тут имеется ввиду что с помощью SLIME можно перемещаться по исходному коду самого SBCL, в принципе IDE для джавы тоже умеют перемещаться по ее коду, другое дело что SBCL, например, сам написан на коммон лиспе поэтому перемещаться можно куда угодно)
>Если же речь идет о методах и классах, которые реализуются для каждой платформы отдельно и поставляются через линкеры, то разве в Lisp не так же?
Не совсем понял, какие методы и классы для каждой платформы?
SirEdvin
Спасибо большое за пояснения.
>Не совсем понял, какие методы и классы для каждой платформы?
Я имел ввиду реализацию того, что требует низкоуровнего доступа или того, что было отдано на откуп компилятору/интерпретатору.
Как, например, native методы в Java (из класса System):
Или пустышки в Python (из класса float):
loz Автор
Это реализуется в коммон лиспе с помощью так называемых readtime conditionals. Говоря простым языком — есть глобальный список *features* в котором хранятся названия фич присутствующих в текущем окружении, на которые может полагаться код. Во время чтения кода программы ридер обращает внимание на макросы чтения #+ и #-, которые соответственно определяют условия наличия или отсутствия нужных фич.
Вот отличный пример, в библиотеке Babel: github.com/cl-babel/babel/blob/master/src/strings.lisp#L138 тут после объявления макроса и сточки документации идет код, специфичный для разных реализаций лиспа, типа
То есть, в этом примере, если у нас в *features* нет :SBCL, то форма идущая за первым условием просто будет пропущена во время чтения и не создаст каких-либо проверок и оверхеда в рантайме.
Эти флаги (sbcl, cmu, scl и тд) как раз находятся в списке *features* и изначально добавляются туда реализацией. Так же видно, что их можно комбинировать различными способами.
Библиотеки так же добавляют собственные флаги, таким образом, код других библиотек или код пользователя может так же опираться на их наличие или отсутствие.
Вот например список флагов в SBCL 1.1.14 на моей машине без каких-либо библиотек:
Из самых общих видно :LINUX, :UNIX, :X86_64, :LITTLE-ENDIAN — по ним библиотеки процессов/потоков, работы с сетью, файлами, вобщем всем платформо-зависимым определяют на что они могут расчитывать, какие системные вызовы использовать, как передавать аргументы в нативный код и тд.
Это дает возможность (и пользователи коммон лиспа во всю этим пользуются) писать максимально платформо-независимый код, при этом используя все возможности конкретной платформы, не подгоняя их под какой-то общий минимум.