Итак, что такое кластеризация с точки зрения нашего восприятия? Приведу пример, допустим, есть милое изображение с цветочками с дачи твоей бабушки.

Вопрос следующий: определить, сколько на данном фото участков, залитых приблизительно одним цветом. Ну это совсем не сложно: белые лепестки – раз, желтые центры – два (я не биолог, как они именуются, не знаю), зелень – три. Эти участки и называются кластерами. Кластер -объединение данных, имеющих общие признаки (цвет, положение и т.д.). Процесс определения и помещения каждой составляющей каких-либо данных в такие кластеры — участки и называется кластеризацией.
Есть много алгоритмов кластеризации, но самый простой из них — k – средних, о котором дальше и пойдет речь. K-средних – простой и эффективный алгоритм, который легко реализовать программным методом. Данные, которые мы будем распределять по кластерам — пиксели. Как известно, цветной пиксель имеет три составляющих — red, green и blue. Наложение этих составляющих и создает палитру существующих цветов.
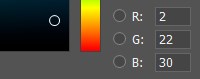
В памяти компьютера каждая составляющая цвета характеризуется числом от 0 до 255. То есть комбинируя различные значения красного, зеленого и синего, получаем палитру цветов на экране.
На примере пикселей мы и реализуем наш алгоритм. K-средних – итерационный алгоритм, то есть он даст правильный результат, после энного количества повторов некоторых математических вычислений.
Алгоритм
- Нужно наперед знать в сколько кластеров нужно распределить данные. Это является существенным минусом данного метода, но эта проблема решается улучшенными реализациями алгоритма, но это, как говорят, совсем другая история.
- Нужно выбрать начальные центры наших кластеров. Как? Да наугад. Зачем? Чтобы можно было привязывать каждый пиксель к центру кластера. Центр – это как Король, вокруг которого собираются его подданные — пиксели. Именно «расстояние» от центра до пикселя определяет, кому будет подчиняться каждый пиксель.
- Посчитаем расстояние от каждого центра до каждого пикселя. Это расстояние считается как евклидово расстояние между точками в пространстве, а в нашем случае — как расстояние между тремя составляющими цвета: Считаем расстояние от первого пикселя до каждого центра и определяем наименьшее расстояние между этим пикселем и центрами. Для центра расстояние, до которого является наименьшим, пересчитываем координаты, как среднее арифметическое между каждой составляющей пикселя – короля и пикселя — подданного. Наш центр смещается в пространстве соответственно подсчетам.
- После пересчета всех центров, мы распределяем пиксели по кластерам, сравнивая расстояние от каждого пикселя до центров. Пиксель помещается в кластер, к центру которого он расположен ближе, чем к остальным центрам.
- Все начинается сначала, до тех пор, пока пиксели остаются в одних и тех же кластерах. Часто такого может и не случится, так как при большом количестве данных центры будут перемещаться в малом радиусе, и пиксели по краям кластеров будут прыгать то в один, то в другой кластер. Для этого нужно определить максимальное число итераций.
Реализация
Реализовывать данный проект я буду на С++. Первый файл – «k_means.h», в нем я определил основные типы данных, константы, и основной класс для работы — «K_means».
Для характеристики каждого пикселя создадим структуру, которая состоит из трех составляющих пикселя, для которых я выбрал тип double для более точных расчетов, а также определил некоторые константы для работы программы:
const int KK = 10; //количество кластеров
const int max_iterations = 100; //максимальное количество итераций
typedef struct {
double r;
double g;
double b;
} rgb;Сам класс K_means:
class K_means
{
private:
std::vector<rgb> pixcel;
int q_klaster;
int k_pixcel;
std::vector<rgb> centr;
void identify_centers();
inline double compute(rgb k1, rgb k2)
{
return sqrt(pow((k1.r - k2.r),2) + pow((k1.g - k2.g), 2) + pow((k1.b - k2.b), 2));
}
inline double compute_s(double a, double b) {
return (a + b) / 2;
};
public:
K_means() : q_klaster(0), k_pixcel(0) {};
K_means(int n, rgb *mas, int n_klaster);
K_means(int n_klaster, std::istream & os);
void clustering(std::ostream & os);
void print()const;
~K_means();
friend std::ostream & operator<<(std::ostream & os, const K_means & k);
};
Пробежимся по составляющим класса:
vectorpixcel — вектор для пикселей;
q_klaster – количество кластеров;
k_pixcel – количество пикселей;
vectorcentr – вектор для центров кластеризации, количество элементов в нем определяется q_klaster;
identify_centers() – метод для случайного выбора начальных центров среди входных пикселей;
compute() и compute_s() встроенные методы для расчета расстояния между пикселями и пересчета центров соответственно;
три конструктора: первый по умолчанию, второй — для инициализации пикселей из массива, третий — для инициализации пикселей из текстового файла (в моей реализации сначала файл случайно заполняется данными, и потом с этого файла считываются пиксели для работы программы, почему не напрямую в вектор – просто так нужно в моем случае);
clustering(std::ostream & os) – метод кластеризации;
метод и перегрузка оператора вывода для публикации результатов.
Реализация методов:
void K_means::identify_centers()
{
srand((unsigned)time(NULL));
rgb temp;
rgb *mas = new rgb[q_klaster];
for (int i = 0; i < q_klaster; i++) {
temp = pixcel[0 + rand() % k_pixcel];
for (int j = i; j < q_klaster; j++) {
if (temp.r != mas[j].r && temp.g != mas[j].g && temp.b != mas[j].b) {
mas[j] = temp;
}
else {
i--;
break;
}
}
}
for (int i = 0; i < q_klaster; i++) {
centr.push_back(mas[i]);
}
delete []mas;
}
Это метод для выбора начальных центров кластеризации и добавления их в вектор центров. Осуществляется проверка на повтор центров и замена их в этих случаях.
K_means::K_means(int n, rgb * mas, int n_klaster)
{
for (int i = 0; i < n; i++) {
pixcel.push_back(*(mas + i));
}
q_klaster = n_klaster;
k_pixcel = n;
identify_centers();
}
Реализация конструктора для инициализации пикселей из массива.
K_means::K_means(int n_klaster, std::istream & os) : q_klaster(n_klaster)
{
rgb temp;
while (os >> temp.r && os >> temp.g && os >> temp.b) {
pixcel.push_back(temp);
}
k_pixcel = pixcel.size();
identify_centers();
}
В этот конструктор мы передаем объект ввода для возможности ввода данных как из файла, так и из консоли.
void K_means::clustering(std::ostream & os)
{
os << "\n\nНачало кластеризации:" << std::endl;
/*В эти векторы мы будем помещать информацию о принадлежности каждого пикселя к определенному кластеру: в одном векторе будет информация о предыдущей итерации, а в другом - о текущей, и если они равны, то цикл заканчивается, так как каждый пиксель остался на своем месте.*/
std::vector<int> check_1(k_pixcel, -1);
std::vector<int> check_2(k_pixcel, -2);
int iter = 0;
/*Количество итераций.*/
while(true)
{
os << "\n\n---------------- Итерация №"
<< iter << " ----------------\n\n";
{
for (int j = 0; j < k_pixcel; j++) {
double *mas = new double[q_klaster];
/*Первая часть алгоритма: берем пиксель и находим расстояние от него до каждого центра. Данные помещаем в динамический массив размерностью, равной количеству кластеров.*/
for (int i = 0; i < q_klaster; i++) {
*(mas + i) = compute(pixcel[j], centr[i]);
os << "Расстояние от пикселя " << j << " к центру #"
<< i << ": " << *(mas + i) << std::endl;
}
/*Определяем минимальное расстояние и в m_k фиксируем номер центра для дальнейшего пересчета.*/
double min_dist = *mas;
int m_k = 0;
for (int i = 0; i < q_klaster; i++) {
if (min_dist > *(mas + i)) {
min_dist = *(mas + i);
m_k = i;
}
}
os << "Минимальное расстояние к центру #" << m_k << std::endl;
os << "Пересчитываем центр #" << m_k << ": ";
centr[m_k].r = compute_s(pixcel[j].r, centr[m_k].r);
centr[m_k].g = compute_s(pixcel[j].g, centr[m_k].g);
centr[m_k].b = compute_s(pixcel[j].b, centr[m_k].b);
os << centr[m_k].r << " " << centr[m_k].g
<< " " << centr[m_k].b << std::endl;
delete[] mas;
}
/*Классифицируем пиксели по кластерам.*/
int *mass = new int[k_pixcel];
os << "\nПроведем классификацию пикселей: "<< std::endl;
for (int k = 0; k < k_pixcel; k++) {
double *mas = new double[q_klaster];
/*Находим расстояние до каждого центра.*/
for (int i = 0; i < q_klaster; i++) {
*(mas + i) = compute(pixcel[k], centr[i]);
os << "Расстояние от пикселя №" << k << " к центру #"
<< i << ": " << *(mas + i) << std::endl;
}
/*Определяем минимальное расстояние.*/
double min_dist = *mas;
int m_k = 0;
for (int i = 0; i < q_klaster; i++) {
if (min_dist > *(mas + i)) {
min_dist = *(mas + i);
m_k = i;
}
}
mass[k] = m_k;
os << "Пиксель №" << k << " ближе всего к центру #" << m_k << std::endl;
}
/*Выводим информацию о принадлежности пикселей к кластерам и заполняем вектор для сравнения итераций.*/
os << "\nМассив соответствия пикселей и центров: \n";
for (int i = 0; i < k_pixcel; i++) {
os << mass[i] << " ";
check_1[i] = *(mass + i);
}
os << std::endl << std::endl;
os << "Результат кластеризации: " << std::endl;
int itr = KK + 1;
for (int i = 0; i < q_klaster; i++) {
os << "Кластер #" << i << std::endl;
for (int j = 0; j < k_pixcel; j++) {
if (mass[j] == i) {
os << pixcel[j].r << " " << pixcel[j].g
<< " " << pixcel[j].b << std::endl;
mass[j] = ++itr;
}
}
}
delete[] mass;
/*Выводим информацию о новых центрах.*/
os << "Новые центры: \n" ;
for (int i = 0; i < q_klaster; i++) {
os << centr[i].r << " " << centr[i].g
<< " " << centr[i].b << " - #" << i << std::endl;
}
}
/*Если наши векторы равны или количество итераций больше допустимого – прекращаем процесс.*/
iter++;
if (check_1 == check_2 || iter >= max_iterations) {
break;
}
check_2 = check_1;
}
os << "\n\nКонец кластеризации." << std::endl;
}
std::ostream & operator<<(std::ostream & os, const K_means & k)
{
os << "Начальные пиксели: " << std::endl;
for (int i = 0; i < k.k_pixcel; i++) {
os << k.pixcel[i].r << " " << k.pixcel[i].g
<< " " << k.pixcel[i].b << " - №" << i << std::endl;
}
os << std::endl << "Случайные начальные центры кластеризации: " << std::endl;
for (int i = 0; i < k.q_klaster; i++) {
os << k.centr[i].r << " " << k.centr[i].g << " "
<< k.centr[i].b << " - #" << i << std::endl;
}
os << "\nКоличество кластеров: " << k.q_klaster << std::endl;
os << "Количество пикселей: " << k.k_pixcel << std::endl;
return os;
}
Вывод начальных данных.
Пример вывода
255 140 50 — №0
100 70 1 — №1
150 20 200 — №2
251 141 51 — №3
104 69 3 — №4
153 22 210 — №5
252 138 54 — №6
101 74 4 — №7
Случайные начальные центры кластеризации:
150 20 200 — #0
104 69 3 — #1
100 70 1 — #2
Количество кластеров: 3
Количество пикселей: 8
Начало кластеризации:
Итерация №0
Расстояние от пикселя 0 к центру #0: 218.918
Расстояние от пикселя 0 к центру #1: 173.352
Расстояние от пикселя 0 к центру #2: 176.992
Минимальное расстояние к центру #1
Пересчитываем центр #1: 179.5 104.5 26.5
Расстояние от пикселя 1 к центру #0: 211.189
Расстояние от пикселя 1 к центру #1: 90.3369
Расстояние от пикселя 1 к центру #2: 0
Минимальное расстояние к центру #2
Пересчитываем центр #2: 100 70 1
Расстояние от пикселя 2 к центру #0: 0
Расстояние от пикселя 2 к центру #1: 195.225
Расстояние от пикселя 2 к центру #2: 211.189
Минимальное расстояние к центру #0
Пересчитываем центр #0: 150 20 200
Расстояние от пикселя 3 к центру #0: 216.894
Расстояние от пикселя 3 к центру #1: 83.933
Расстояние от пикселя 3 к центру #2: 174.19
Минимальное расстояние к центру #1
Пересчитываем центр #1: 215.25 122.75 38.75
Расстояние от пикселя 4 к центру #0: 208.149
Расстояние от пикселя 4 к центру #1: 128.622
Расстояние от пикселя 4 к центру #2: 4.58258
Минимальное расстояние к центру #2
Пересчитываем центр #2: 102 69.5 2
Расстояние от пикселя 5 к центру #0: 10.6301
Расстояние от пикселя 5 к центру #1: 208.212
Расстояние от пикселя 5 к центру #2: 219.366
Минимальное расстояние к центру #0
Пересчитываем центр #0: 151.5 21 205
Расстояние от пикселя 6 к центру #0: 215.848
Расстояние от пикселя 6 к центру #1: 42.6109
Расстояние от пикселя 6 к центру #2: 172.905
Минимальное расстояние к центру #1
Пересчитываем центр #1: 233.625 130.375 46.375
Расстояние от пикселя 7 к центру #0: 213.916
Расстояние от пикселя 7 к центру #1: 150.21
Расстояние от пикселя 7 к центру #2: 5.02494
Минимальное расстояние к центру #2
Пересчитываем центр #2: 101.5 71.75 3
Проведем классификацию пикселей:
Расстояние от пикселя №0 к центру #0: 221.129
Расстояние от пикселя №0 к центру #1: 23.7207
Расстояние от пикселя №0 к центру #2: 174.44
Пиксель №0 ближе всего к центру #1
Расстояние от пикселя №1 к центру #0: 216.031
Расстояние от пикселя №1 к центру #1: 153.492
Расстояние от пикселя №1 к центру #2: 3.05164
Пиксель №1 ближе всего к центру #2
Расстояние от пикселя №2 к центру #0: 5.31507
Расстояние от пикселя №2 к центру #1: 206.825
Расстояние от пикселя №2 к центру #2: 209.378
Пиксель №2 ближе всего к центру #0
Расстояние от пикселя №3 к центру #0: 219.126
Расстояние от пикселя №3 к центру #1: 20.8847
Расстояние от пикселя №3 к центру #2: 171.609
Пиксель №3 ближе всего к центру #1
Расстояние от пикселя №4 к центру #0: 212.989
Расстояние от пикселя №4 к центру #1: 149.836
Расстояние от пикселя №4 к центру #2: 3.71652
Пиксель №4 ближе всего к центру #2
Расстояние от пикселя №5 к центру #0: 5.31507
Расстояние от пикселя №5 к центру #1: 212.176
Расстояние от пикселя №5 к центру #2: 219.035
Пиксель №5 ближе всего к центру #0
Расстояние от пикселя №6 к центру #0: 215.848
Расстояние от пикселя №6 к центру #1: 21.3054
Расстояние от пикселя №6 к центру #2: 172.164
Пиксель №6 ближе всего к центру #1
Расстояние от пикселя №7 к центру #0: 213.916
Расстояние от пикселя №7 к центру #1: 150.21
Расстояние от пикселя №7 к центру #2: 2.51247
Пиксель №7 ближе всего к центру #2
Массив соответствия пикселей и центров:
1 2 0 1 2 0 1 2
Результат кластеризации:
Кластер #0
150 20 200
153 22 210
Кластер #1
255 140 50
251 141 51
252 138 54
Кластер #2
100 70 1
104 69 3
101 74 4
Новые центры:
151.5 21 205 — #0
233.625 130.375 46.375 — #1
101.5 71.75 3 — #2
Итерация №1
Расстояние от пикселя 0 к центру #0: 221.129
Расстояние от пикселя 0 к центру #1: 23.7207
Расстояние от пикселя 0 к центру #2: 174.44
Минимальное расстояние к центру #1
Пересчитываем центр #1: 244.313 135.188 48.1875
Расстояние от пикселя 1 к центру #0: 216.031
Расстояние от пикселя 1 к центру #1: 165.234
Расстояние от пикселя 1 к центру #2: 3.05164
Минимальное расстояние к центру #2
Пересчитываем центр #2: 100.75 70.875 2
Расстояние от пикселя 2 к центру #0: 5.31507
Расстояние от пикселя 2 к центру #1: 212.627
Расстояние от пикселя 2 к центру #2: 210.28
Минимальное расстояние к центру #0
Пересчитываем центр #0: 150.75 20.5 202.5
Расстояние от пикселя 3 к центру #0: 217.997
Расстояние от пикселя 3 к центру #1: 9.29613
Расстояние от пикселя 3 к центру #2: 172.898
Минимальное расстояние к центру #1
Пересчитываем центр #1: 247.656 138.094 49.5938
Расстояние от пикселя 4 к центру #0: 210.566
Расстояние от пикселя 4 к центру #1: 166.078
Расстояние от пикселя 4 к центру #2: 3.88306
Минимальное расстояние к центру #2
Пересчитываем центр #2: 102.375 69.9375 2.5
Расстояние от пикселя 5 к центру #0: 7.97261
Расстояние от пикселя 5 к центру #1: 219.471
Расстояние от пикселя 5 к центру #2: 218.9
Минимальное расстояние к центру #0
Пересчитываем центр #0: 151.875 21.25 206.25
Расстояние от пикселя 6 к центру #0: 216.415
Расстояние от пикселя 6 к центру #1: 6.18805
Расстояние от пикселя 6 к центру #2: 172.257
Минимальное расстояние к центру #1
Пересчитываем центр #1: 249.828 138.047 51.7969
Расстояние от пикселя 7 к центру #0: 215.118
Расстояние от пикселя 7 к центру #1: 168.927
Расстояние от пикселя 7 к центру #2: 4.54363
Минимальное расстояние к центру #2
Пересчитываем центр #2: 101.688 71.9688 3.25
Проведем классификацию пикселей:
Расстояние от пикселя №0 к центру #0: 221.699
Расстояние от пикселя №0 к центру #1: 5.81307
Расстояние от пикселя №0 к центру #2: 174.122
Пиксель №0 ближе всего к центру #1
Расстояние от пикселя №1 к центру #0: 217.244
Расстояние от пикселя №1 к центру #1: 172.218
Расстояние от пикселя №1 к центру #2: 3.43309
Пиксель №1 ближе всего к центру #2
Расстояние от пикселя №2 к центру #0: 6.64384
Расстояние от пикселя №2 к центру #1: 214.161
Расстояние от пикселя №2 к центру #2: 209.154
Пиксель №2 ближе всего к центру #0
Расстояние от пикселя №3 к центру #0: 219.701
Расстояние от пикселя №3 к центру #1: 3.27555
Расстояние от пикселя №3 к центру #2: 171.288
Пиксель №3 ближе всего к центру #1
Расстояние от пикселя №4 к центру #0: 214.202
Расстояние от пикселя №4 к центру #1: 168.566
Расстояние от пикселя №4 к центру #2: 3.77142
Пиксель №4 ближе всего к центру #2
Расстояние от пикселя №5 к центру #0: 3.9863
Расстояние от пикселя №5 к центру #1: 218.794
Расстояние от пикселя №5 к центру #2: 218.805
Пиксель №5 ближе всего к центру #0
Расстояние от пикселя №6 к центру #0: 216.415
Расстояние от пикселя №6 к центру #1: 3.09403
Расстояние от пикселя №6 к центру #2: 171.842
Пиксель №6 ближе всего к центру #1
Расстояние от пикселя №7 к центру #0: 215.118
Расстояние от пикселя №7 к центру #1: 168.927
Расстояние от пикселя №7 к центру #2: 2.27181
Пиксель №7 ближе всего к центру #2
Массив соответствия пикселей и центров:
1 2 0 1 2 0 1 2
Результат кластеризации:
Кластер #0
150 20 200
153 22 210
Кластер #1
255 140 50
251 141 51
252 138 54
Кластер #2
100 70 1
104 69 3
101 74 4
Новые центры:
151.875 21.25 206.25 — #0
249.828 138.047 51.7969 — #1
101.688 71.9688 3.25 — #2
Конец кластеризации.
Этот пример спланирован наперед, пиксели выбраны специально для демонстрации. Программе достаточно двух итераций, чтобы сгруппировать данные в три кластера. Посмотрев на центры двух последних итераций, можно заметить, что они практически остались на месте.
Интереснее случаи при рандомной генерации пикселей. Сгенерировав 50 точек, которые нужно поделить на 10 кластеров, я получил 5 итераций. Сгенерировав 50 точек, которые нужно поделить на 3 кластера, я получил все 100 максимально допустимых итераций. Можно заметить, что чем больше кластеров, тем легче программе найти наиболее схожие пиксели и объединить их в меньшие группы, и наоборот — если кластеров мало, а точек много, часто алгоритм завершается только от превышения максимально допустимого количества итераций, так как некоторые пиксели постоянно прыгают из одного кластера в другой. Тем не менее, основная масса все равно определяются в свои кластеры окончательно.
Ну а теперь давайте проверим результат кластеризации. Взяв результат некоторых кластеров из примера 50 точек на 10 кластеров, я вбил результат этих данных в Illustrator и вот что получилось:
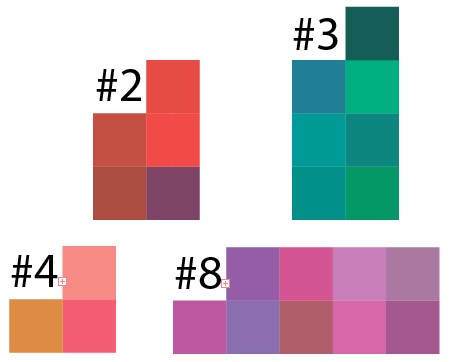
Видно, что в каждом кластере преобладают какие-либо оттенки цвета, и тут нужно понимать, что пиксели были выбраны случайно, аналогом такого изображения в реальной жизни является какая-то картина, на которую случайно набрызгали всех красок и выделить участки схожих цветов сложно.
Допустим, у нас есть такое фото. Остров мы можем определить, как один кластер, но при увеличении мы видим, что он состоит из разных оттенков зеленого.

А это 8 кластер, но в уменьшенном варианте, результат аналогичен:

Полную версию программы можно посмотреть на моем GitHub.
Комментарии (16)

Sdima1357
25.10.2018 21:08K — means довольно быстрый как метод сегментации (кластеризации), но не стабильный из-за случайной выборки затравок :(. Это легко увидеть обработав им видео-последовательность. Правильная выборка затравок и количества сегментов — это отдельная и очень сложная задача.
Mean shift «en.wikipedia.org/wiki/Mean_shift» медленней, но стабильней и проще параметризуется.
Ryppka
25.10.2018 21:37А зачем Вы на C++ писали на C? Вот такая конструкция в C++ смотрится откровенно странно:
typedef struct { double r; double g; double b; } rgb;
На мой вкус она и на C так.., но это уже, конечно, дело вкуса.dankor1498 Автор
25.10.2018 21:47-1Просто в универе сейчас Си учим, а С++ сам изучаю, вот и комбинирую что знаю))) Думаю на саму суть это не влияет.
Ryppka
25.10.2018 22:18Влияет. И в C, и в C++ Вы создали нечто с именем, известным только компилятору, а потом задали для этого нечто алиас. Гляньте в отладчике, лучше не в самом умном, но точном: там будет что-то наподобие struct Anonymous (если писали на C) или какая-то случайная комбинация символов. В C такая практика довольно распространена, поскольку иначе нужно объявлять как struct some_name, что не всегда удобно. Поэтому делают typedef. Но даже в этом случае лучше не экономить нажатия на клавиши и прописывать явный «тэг» структуры.
В C++ такое объявление поддерживается для совместимости с C, но режет глаза. Незачем всем объявлять, что Вы не совсем понимаете, что делаете))))
Pochemuk
25.10.2018 23:08А зачем для сравнения расстояний от пикселей до центров использовать расстояние, а не квадрат расстояния?
Извлечение корня квадратного будет в данном случае лишней операцией.dankor1498 Автор
26.10.2018 08:42Спасибо за вопрос, взял формулу по аналогии формулы расстояния между двумя точками в пространстве, где корень присутствует.
Deosis
26.10.2018 09:39+1Корень нужен, чтобы выполнялось неравенство треугольника.
До тех пор, пока расстояния не складываются без корня можно обойтись.
Pochemuk
26.10.2018 11:41В свое время, лет так 25 назад занимался из любви к искусству кластеризацией цветов изображений. А все потому, что видеокарточка была VGA с максимальной глубиной цвета 8-bit, а фотографии 15-bit, 16-bit и 24-bit уже появлялись.
Какие я только методы кластеризации не перепробовал. И плоские и иерархические.
Неплохой результат давал метод квантования цветового пространства.
Суть его примерно такая:
1. Для всего множества пикселей находится такая ось в цветовом пространстве RGB, сумма квадратов расстояний от которой до цветовых координат пикселей является наименьшей.
2. Пиксели проецируются на эту ось. Просто каждому пикселю присваивается координата проекции.
3. Массив пикселей сортируется по координате проекции.
4. Отсортированный массив разбивается на два подмассива, таких что сумма квадратов отклонений проекций от центра тяжести соответствующего подмассива была минимальна.
5. Разбиение повторяется рекурсивно для каждого подмассива, пока число разбиений не станет равным заданному.
6. В каждом кластере все цвета заменяются на координаты центра тяжести кластера.
Метод достаточно хороший в плане приближения цветов. Но очень-очень долгий.
Можно существенно его упростить. Не находить на каждом шаге проективную ось, а выбрать одну из осей R, G, B. Например такую, максимальный разброс оттенков по которой является наибольшим. И провести медианное разбиение (с учетом весов — количества пикселей каждого оттенка).
Так будет существенно быстрее, но несколько уступать в точности цветопередачи.
Хотя, последующий дайзеринг нивелирует эту погрешность.old_gamer
26.10.2018 16:10видеокарточка была VGA с максимальной глубиной цвета 8-bit, а фотографии 15-bit, 16-bit и 24-bit уже появлялись.
8 бит же палитра у нее была, а цветовое пространство 18 бит, по 6 на цвет.Pochemuk
26.10.2018 16:31+1Ну да, прошу прощения за неточность. Конечно, 8 бит — размер индекса палитры. Т.е. цветов можно было вывести много, но одновременно — не более 256. А в Windows 3.x — не более 236, т.к. 20 индексов были зарезервированы под палитру самой Винды. Их тоже можно было заменить, но это приводило к тому, что шрифты, рамки, шапки окон — все меняло цвет. И работать было невозможно.
Но их можно было тоже включить в общую палитру без замены цветов. Но это уже чуть усложняло алгоритм оптимизации палитры. Хотя, она при этом становилась более адекватной, т.к. системные цвета лежали на границах цветового куба, т.е. хорошо подхватывали цвета, которые выбивались из кластеров в сторону границ.
Framework
Поправьте если я ошибаюсь, но на сколько я помню, то в университете этот метод классификации используется часто и даже не локально на каком-то одном предмете, не могло же только мне повезти. И заявление о недостатке литературы какое-то странное, ввиду этого.
dankor1498 Автор
У меня была цель описать именно пример работы с пикселями, ибо курсач такой). И я искал именно примеры кластеризации пикселей, и тут уже немного посложнее найти. Может кому и понадобится, вот и написал свой опыт. А так сам алгоритм довольно популярен среди данных разного типа.
Framework
Вот об этом и нужно писать, а не о том что недостаточно литературы.
Да, и чем пиксели на изображении так специфичны? Для ирисов метод как-то иначе работать будет?