Эта с виду простая задача до сих пор находится в списке нерешенных проблем вычислительной геометрии. Причем ситуация даже не касается точек в многомерных пространствах, тем более искривленных, проблемой является уже самый простой вариант — когда все точки имеют целочисленные координаты и локализованы на одной линии.
За прошедшие почти полвека с тех пор, как эта задача была осознана математиками как вызов (Shamos, 1975), были получены некоторые результаты. Рассмотрим два случая возможных для одномерной задачи:
- точки расположены на прямой (turnpike проблема)
- точки расположены на окружности (beltway проблема)
Эти два случая получили разные названия не просто так — требуются различные усилия, чтобы их решить. И действительно, первая задача была решена достаточно быстро (за 15 лет) и построен backtracking алгоритм, восстанавливающий решение в среднем за квадратичное время , где — число точек (Skiena, 1990); для второй задачи этого сделать не удалось до сих пор, и лучший предложенный алгоритм имеет экспоненциальную вычислительную сложность (Lemke, 2003). На картинке ниже приведена оценка того, как долго будет работать ваш компьютер, чтобы получить решение для множества с разным числом точек.

То есть, за психологически приемлемое время (~10 сек) можно восстановить множество объемом до 10 тысяч точек в turnpike случае и только ~10 точек для beltway случая, что совершенно никуда не годится для практических приложений.
Небольшое уточнение. Считается, что turnpike проблема решена с точки зрения использования в практике, то есть для подавляющего большинства встречаемых данных. При этом игнорируются возражения чистых математиков на то, что существуют специальные наборы данных для которых время получения решения экспоненциально (Zhang, 1982). В противоположность turnpike, beltway проблема с ее экспоненциальным алгоритмом никак не может считаться решенной практически.
Важность решение beltway проблемы с точки зрения биоинформатики
В конце 20 века был обнаружен новый путь синтеза биомолекул, названный нерибосомальным путем синтеза. Главное его отличие от классического пути синтеза в том, что конечный результат синтеза вообще не закодирован в ДНК. Вместо этого, в ДНК записан только код «инструментов» (множества различных синтетаз), которые могут собирать эти объекты. Таким образом, биомашинная инженерия существенно обогащается, и клетке вместо одного типа сборщика (рибосомы), выполняющего работы только с 20 стандартными деталями (стандартные аминокислоты, также называемые протеиногенными) появляются множество других типов сборщиков, которые могут работать с более чем 500 стандартными и нестандартными деталями (непротеиногенные аминокислоты и различные их модификации). И эти сборщики могут не просто соединять детали в цепочки, но и получать весьма замысловатые конструкции — циклические, ветвящиеся, а также конструкции со многими циклами и ветвлением. Все это существенно повышает арсенал клетки на разные случаи ее жизни. Биологическая активность таких конструкций высока, специфичность (избирательность действия) тоже, разнообразие свойств — не ограничено. Класс этих продуктов клетки в англоязычной литературе имеет название NRPs (non-ribosomal products, или non-ribosomal peptides). Биологи надеются, что именно среди таких продуктов метаболизма клетки можно найти новые фармакологические препараты, обладающие высокой эффективностью и за счет специфичности не имеющие побочных эффектов.
Вопрос состоит только в том, а как и где искать NRPs? Они весьма эффективны, следовательно клетке совершенно незачем продуцировать их в большом количестве, и концентрации их ничтожны. Значит химические методы извлечения с их низкой точностью ~1% и огромными затратами по реактивам и времени бесполезны. Далее. Они не кодированы в ДНК, значит все базы данных, что накоплены при расшифровке генома, и все методы биоинформатики и геномики также бесполезны. Единственным способом что-то найти остаются физические методы, а, именно, масс-спектроскопия. Тем более, что уровень обнаружения вещества у современных спектрометров настолько высок, что позволяет найти ничтожные количества, всего >~ 800 молекул (атто-молярный диапазон, или концентрации ).
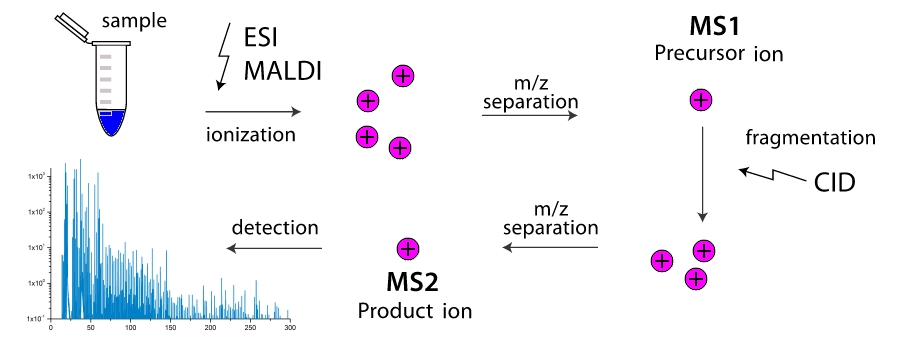 "
" А как работает масс-спектрометр? В рабочей камере прибора происходит разрушение молекул на фрагменты (чаще путем их столкновений друг с другом, реже за счет внешнего воздействия). Эти фрагменты ионизуются, а затем разгоняются и разделяются во внешнем электромагнитном поле. Разделение происходит либо по времени достижения детектора, либо по углу разворота в магнитном поле, ведь больше масса фрагмента и ниже его заряд, тем более неповоротливым он является. Таким образом, масс-спектрометр как бы «взвешивает» массы фрагментов. Причем, «взвешивание» можно сделать многоэтапным, многократно отфильтровывая фрагменты с одной массой (точнее с одним значением ) и прогоняя их через фрагментацию с дальнейшим разделением. Двухэтапные масс-спектрометры широко распространены и называются тандемными, многоэтапные — крайне редки, и просто обозначаются как , где — число этапов. А вот тут то и появляется задача, как зная только массы всевозможных фрагментов какой либо молекулы узнать ее структуру? Вот мы и пришли к turnpike и beltway проблемам, для линейных и циклических пептидов, соответственно.
Поясню более детально, как задача восстановления структуры биомолекулы сводится к указанным проблемам на примере циклического пептида.
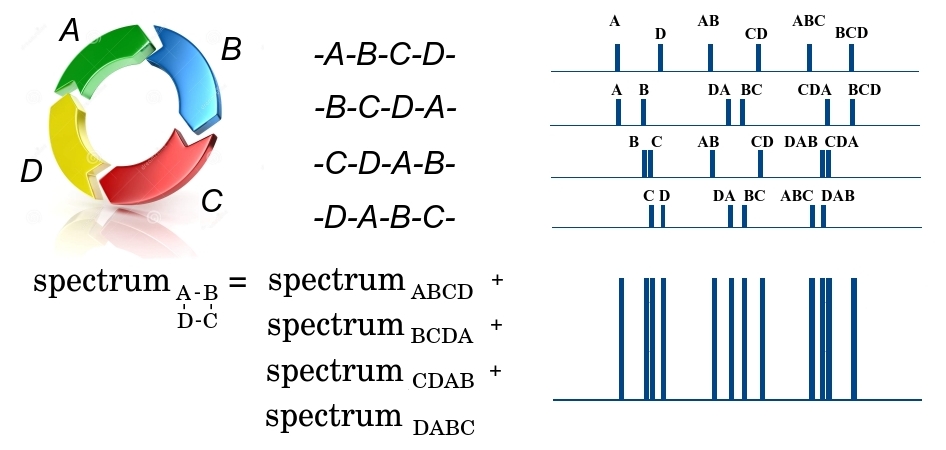
Циклический пептид ABCD на первом этапе фрагментации может быть разорван в 4-х местах, либо по связи D-A, либо по A-B, B-C или C-D, образуя 4 возможных линейных пептида — либо ABCD, BCDA, CDAB или DABC. Поскольку через спектрометр проходит огромное число одинаковых пептидов, то на выходе будем иметь фрагменты всех 4-х типов. Причем заметим, что все фрагменты имеют одинаковую массу, и не могут быть разделены на первом этапе. На втором этапе, линейный фрагмент ABCD может быть разорван в трех местах, образуя более мелкие фрагменты с разной массой A и BCD, AB и CD, ABC и D, и формируя соответствующий масс-спектр. В этом спектре по оси x откладывается масса фрагмента, а по оси y — число мелких фрагментов с данной массой. Аналогично формируются спектры для остальных трех линейных фрагментов BCDA, CDAB и DABC. Так как все 4 крупных фрагмента прошли на второй этап, то все их спектры складываются. Итого, на выходе получается некоторое множество масс , где — некоторая масса, а — кратность ее повторения. При этом мы не знаем, к какому фрагменту относится эта масса и уникален ли этот фрагмент, поскольку различные фрагменты могут иметь одну массу. Чем далее связи в пептиде находятся друг от друга, тем большая масса фрагмента пептида находится между ними. То есть, задача восстановления порядка элементов в циклическом пептиде сводится к beltway проблеме, в которой элементами множества являются связи в пептиде, а элементами множества — массы фрагментов между связями.
Предчувствие возможности существования алгоритма с полиномиальным временем решения beltway проблемы
Из своего опыта и из общения с людьми, кто пытался или реально что-то сделал для решения этой проблемы, я заметил, что подавляющее большинство людей пытаются решить ее либо в общем случае, либо для целочисленных данных в узком диапазоне, вроде такого (1, 50). Оба варианта обречены на неудачу. Для общего случая было доказано, что полное число решений для beltway проблемы в одномерном случае ограничено значениями (Lemke, 2003) что означает наличие экспоненциального числа решений в асимптотике . Очевидно, что если число решений растет по экспоненте, то и время их получения медленней расти не может. То есть для общего случая получить полиномиальное время решение невозможно. Что же касается целочисленных данных в узком диапазоне, то здесь все можно проверить экспериментально, поскольку не слишком сложно написать код, который ищет решение методом полного перебора. Для небольших такой код будет считать не очень долго. Результаты испытания такого кода покажут, что при таких условиях на данные полное число различных решений для любого множества уже при малых также растет крайне резко.
Узнав о этих фактах можно смириться и махнуть рукой на эту задачу. Допускаю, что это является одной из причин по которой beltway проблема до сих пор считается нерешенной. Однако лазейки все же существуют. Вспомним, что экспоненциальная функция ведет себя очень интересно. Сначала она растет страшно медленно, поднимаясь от 0 до 1 за бесконечно большой промежуток от до 0, затем ее рост все более и более ускоряется. Однако, чем меньше значение , тем больше должно быть значение , чтобы результат функции перешагнул некоторое заданное значение . В качестве такого значения удобно выбрать число , до него решение единственное, после него решений много. Вопрос. А проверял ли кто-нибудь зависимость числа решений от того, какие данные попадают на вход? Да, проверял. Есть замечательная phD диссертация хорватской женщины математика Тамары Дакис (Dakic, 2000), в которой она определила каким условиям должны удовлетворять входные данные, чтобы проблема решалась в полиномиальное время. Наиболее важные из них — единственность решения и отсутствие дублирования во множестве входных данных . Уровень ее phD диссертации очень высок. Очень жаль, что эта студентка ограничилась только turnpike проблемой, убежден, что обрати она свой интерес к beltway проблеме та давно была бы решена.
Получение алгоритма с полиномиальным временем решения beltway проблемы
Обнаружить данные для которых возможно построить нужный алгоритм удалось случайно. Потребовались дополнительные идеи. Основная идея возникла из наблюдения (см. выше), что спектр циклического пептида является суммой спектров всех линейных пептидов, которые образуются при однократных разрывах кольца. Поскольку последовательность аминокислот в пептиде может быть восстановлена из любого такого линейного пептида, то полное число линий в спектре существенно (в раз, где — число аминокислот в пептиде) избыточно. Вопрос заключается только в том, какие линии нужно исключить из спектра, чтобы не потерять возможность восстановления последовательности. Поскольку математически обе задачи (восстановления последовательности циклического пептида из масс-спектра и beltway проблема) изоморфны, то так же можно прореживать множество .
Операции прореживания были построены с использованием локальных симметрий множества (Fomin, 2016a).
- Симметризация. Первая операция заключается в том, чтобы выбрать произвольный элемент множества и удалить из все элементы, кроме тех, которые имеют симметричные пары относительно точек и , где — длина окружности (напомню, что в beltway случае все точки расположены на окружности).
- Конволюция по частичному решению. Вторая операция использует наличие догадки о решении, то есть знание отдельных точек, которые принадлежат решению, так называемое частичное решение. Здесь из множества также удаляются все элементы, кроме тех, которые удовлетворяют условию — если мы измерим расстояния от проверяемой точки до всех точек частичного решения, то все полученные значения имеются в . Уточню, что если хотя бы одно из полученных расстояний отсутствует в , то точка игнорируется.
Были доказаны теоремы, что обе операции прореживают множество , но в нем все равно останется достаточно элементов для восстановления решения . С использованием этих операция был построен и реализован на c++ алгоритм для решения beltway проблемы (Fomin, 2016b). Алгоритм мало отличается от классического backtracking алгоритма (то есть пытаемся строить решение путем перебора возможных вариантов и делаем возвраты, если при построении получили ошибку). Отличие заключается только в том, что для счет сужения множества опробовать нам становится существенно меньше вариантов.
Вот пример, как резко сужается множество при прореживании.

Вычислительные эксперименты выполнялись для случайно генерированных циклических пептидов длиной от 10 до 1000 аминокислот (ось ординат в логарифмическом масштабе). По оси абсцисс также в логарифмическом масштабе отложено число элементов в прореженных разными операциям множествах в единицах . Такое представление абсолютно непривычно, потому расшифрую, как это читается на примере. Смотрим левую диаграмму. Пусть пептид имеет длину . Для него число элементов во множестве равно (это точка на верхней пунктирной прямой ). После удаления из множества повторяющихся элементов, число элементов в уменьшается до (кружки с крестиками). После симметризации число элементов падает до (черные кружки), а после конволюции по частичному решению до (крестики). Итого, общий объем множества сокращается всего в 20 раз. Для пептида такой же длины, но на правой диаграмме, сокращение происходит от до , то есть в 100 раз.
Заметим, что генерация тестовых примеров для левой диаграммы выполняется таким образом, чтобы уровень дублирования в был в диапазоне от 0.1 до 0.3, а для правой — менее 0.1. Уровень дублирования определяется как , где — число уникальных элементов во множестве . Такое определение дает естественный результат: при отсутствии дубликатов во множестве его мощность равна и , при максимально возможном дублировании и . Как сделать обеспечить разный уровень дублирования, скажу чуть позже. По диаграммам видно, что чем меньше уровень дублирования, тем сильнее прореживается , при число элементов в прореженном вообще достигает своего предела , поскольку в прореженном множестве меньше чем элементов получить невозможно (операции сохраняют достаточно элементов, чтобы получить решение, в котором элементов). Факт сужения мощности множества до нижнего предела очень важен, именно он приводит к кардинальным изменениям в вычислительной сложности получения решения.
После вставка операций прореживания в backtracking алгоритм и в решении beltway проблемы выявился полный аналог того, о чем говорила Тамара Дакис относительно turnpike проблемы. Напомню. Она говорила, что для turnpike проблемы возможно получить решение за полиномиальное время, если решение единственно и отсутствует дублирование в . Оказалось, что не обязательно нужно полное отсутствие дублирования (вряд ли оно возможно для реальных данных), достаточно, что его уровень будет достаточно малым. На рисунке ниже показано, сколько времени требуется для получения решения beltway проблемы в зависимости от длины пептида и уровня дублирования в .

На рисунке обе оси абсцисс и ординат даны в логарифмическом масштабе. Это позволяет четко увидеть является ли зависимость времени счета от длины последовательности экспоненциальной (прямая линия) или полиномиальной (log-форма кривой). Как видно на диаграммах, при низком уровне дублирования (правая диаграмма) решение получается в полиномиальное время. Ну а если быть более точным, то решение получается за квадратичное время. Это происходит, когда операции прореживания снижают мощность множества до нижнего предела , в нем остается мало точек, возвраты при переборе вариантов становятся единичными, и по сути алгоритм перестает перебирать варианты, а просто конструирует решение из того, что осталось.
P.S. Ну и раскрою последний секрет относительно генерации множеств в разным уровнем дублирования. Это связано с разной точностью представления данных. Если данные генерятся с низкой точностью (например округляя до целых чисел), то уровень дублирования становится высоким, более 0.3. Если данные генерить с хорошей точностью, например, до 3 знака после запятой, то уровень дублирования резко снижается, менее 0.1. И отсюда следует последнее наиболее важное замечание.
Для реальных данных, в условиях постоянно увеличивающейся точности измерений, beltway проблема становится разрешима в реальном времени.
Литература.
1. Dakic, T. (2000). On the Turnpike Problem. PhD thesis, Simon Fraser University.
2. Fomin. E. (2016a) A Simple Approach to the Reconstruction of a Set of Points from the Multiset of n^2 Pairwise Distances in n^2 Steps for the Sequencing Problem: I. Theory. J Comput Biol. 2016, 23(9):769-75.
3. Fomin. E. (2016b) A Simple Approach to the Reconstruction of a Set of Points from the Multiset of n^2 Pairwise Distances in n^2 Steps for the Sequencing Problem: II. Algorithm. J Comput Biol. 2016, 23(12):934-942.
4. Lemke, P., Skiena, S., and Smith, W. (2003). Reconstructing Sets From Interpoint Distances. Discrete and Computational Geometry Algorithms and Combinatorics, 25:597–631.
5. Skiena, S., Smith, W., and Lemke, P. (1990). Reconstructing sets from interpoint distances. In Proceedings of the Sixth ACM Symposium on Computational Geometry, pages 332–339. Berkeley, CA
6. Zhang, Z. 1982. An exponential example for a partial digest mapping algorithm. J. Comp. Biol. 1, 235–240.
Комментарии (10)

strcpy
26.10.2018 04:19Гомотопию пробовали? Dimension reduction?
kpoxa2l Автор
26.10.2018 07:03Гомотопию не пробовал, нет идей как это сделать. Однако отображение из дискретного пространства точек множества на непрерывное сделал. При этом удалось обобщить метод и получить красивые формулы, но самое главное удалось решить проблему в случае наличия большого шума в спектрах.
Dimension reduction? Не пробовал. Причины в ответе на комментарий uchitel.strcpy
26.10.2018 07:34С гомотопией идея такая: берется задача с известным решением, дальше условие плавно переводится к задаче с неизвестным решением. Из постановки задачи не очень понятно, целые X или нет.
kpoxa2l Автор
26.10.2018 07:14Спасибо за отклики. К сожалению, в течении недели не смогу отвечать на комментарии. Приглашаю посетить конференцию Постгеном 2018 в Казанском федеральном университете, (естественно, у кого есть возможность). На хабре пока выставлена только половина от доклада.
DaylightIsBurning
26.10.2018 16:15+1Возможно ли в полиномиальное время восстановить координаты множества точек, если известно множество всех парных расстояний между ними?
Имеется ввиду, что расстояния даны без привязки к номеру точки? То есть мы не знаем, какой паре точек какое расстояние соответствует?
uchitel
А нельзя разбросать точки в случайном порядке, измерить расстояние между ними, сопоставить с реальными расстояниями и потом просто «подогнать»?
kpoxa2l Автор
Можно, получится аналог метода многомерного шкалирования. Но я не пробовал, предполагаю, что подгонка постоянно будет скатываться в локальные минимумы.
strcpy
Из локальных минимумов можно выходить.
uchitel
Возможно эти минимумы должны асимптотически приближаться к глобальному минимуму. Должен же быть какой то градиент.
Хочется попробовать, но как всегда есть куча других дел. Попробуйте описать задачу и свое решение более детально. Чувствуется, что для вас многие вещи очевидны, но для читателя это может звучать как, как «Авада Кедабра!» из Гари Поттера.