
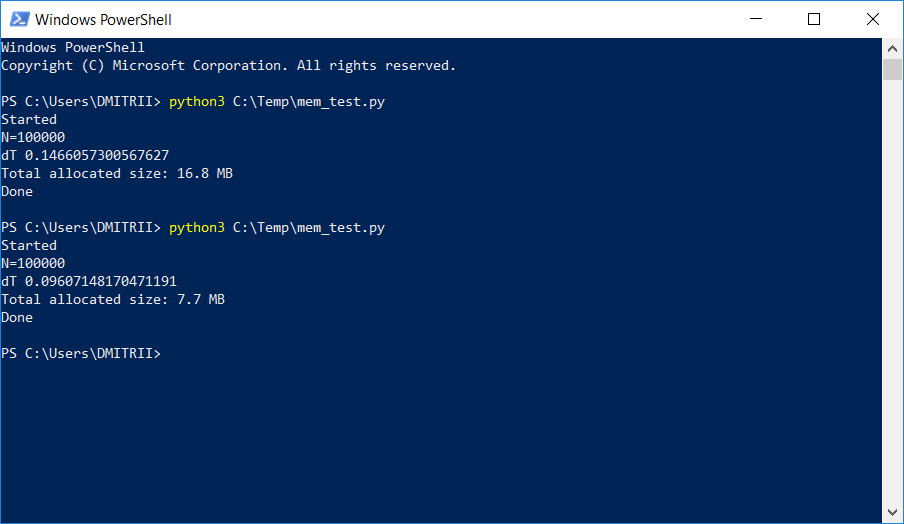
В одном проекте, где необходимо было хранить и обрабатывать довольно большой динамический список, тестировщики стали жаловаться на нехватку памяти. Простой способ, как «малой кровью» исправить проблему, добавив лишь одну строку кода, описан ниже. Результат на картинке:
Как это работает, продолжение под катом.
Рассмотрим простой «учебный» пример — создадим класс DataItem, содержащий
class DataItem(object):
def __init__(self, name, age, address):
self.name = name
self.age = age
self.address = address
«Детский» вопрос — сколько такой объект занимает в памяти?
Попробуем решение в лоб:
d1 = DataItem("Alex", 42, "-")
print ("sys.getsizeof(d1):", sys.getsizeof(d1))Получаем ответ 56 байт. Вроде немного, вполне устраивает.
Однако, проверяем на другом объекте, в котором данных больше:
d2 = DataItem("Boris", 24, "In the middle of nowhere")
print ("sys.getsizeof(d2):", sys.getsizeof(d2))Ответ — снова 56. На этом моменте понимаем, что что-то здесь не то, и не все так просто, как кажется на первый взгляд.
Интуиция нас не подводит, и все действительно не так просто. Python — это очень гибкий язык с динамической типизацией, и для своей работы он хранит
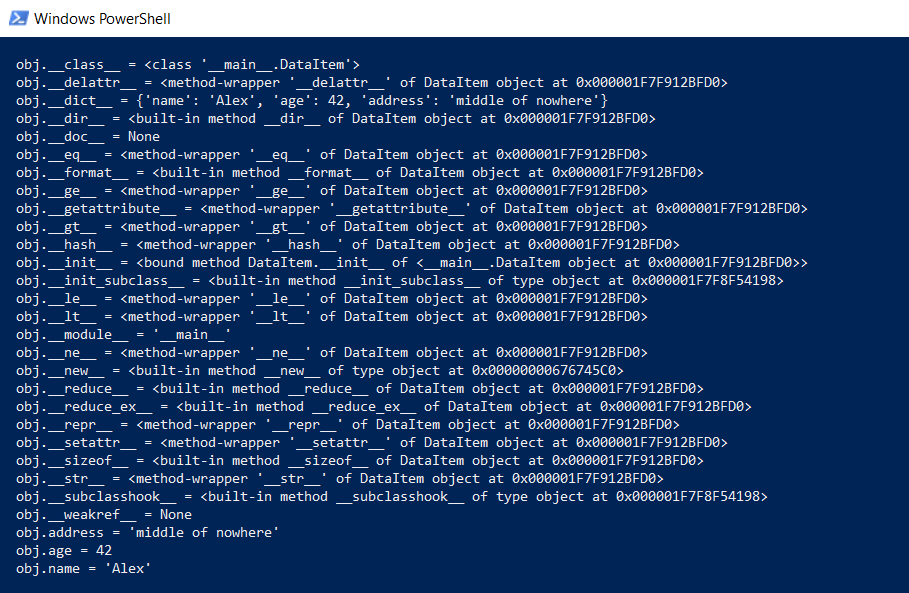
Однако вернемся к нашему классу DataItem и «детскому» вопросу. Сколько занимает такой класс в памяти? Для начала, выведем целиком все содержимое класса на более низком уровне:
def dump(obj):
for attr in dir(obj):
print(" obj.%s = %r" % (attr, getattr(obj, attr)))Эта функция покажет то, что скрыто «под капотом», чтобы все функции Python (типизация, наследование и прочие плюшки) могли функционировать.
Результат впечатляет:
Сколько это все занимает целиком? На github нашлась функция, подсчитывающая реальный объем данных, рекурсивно вызывая getsizeof для всех объектов.
def get_size(obj, seen=None):
# From https://goshippo.com/blog/measure-real-size-any-python-object/
# Recursively finds size of objects
size = sys.getsizeof(obj)
if seen is None:
seen = set()
obj_id = id(obj)
if obj_id in seen:
return 0
# Important mark as seen *before* entering recursion to gracefully handle
# self-referential objects
seen.add(obj_id)
if isinstance(obj, dict):
size += sum([get_size(v, seen) for v in obj.values()])
size += sum([get_size(k, seen) for k in obj.keys()])
elif hasattr(obj, '__dict__'):
size += get_size(obj.__dict__, seen)
elif hasattr(obj, '__iter__') and not isinstance(obj, (str, bytes, bytearray)):
size += sum([get_size(i, seen) for i in obj])
return size
Пробуем ее:
d1 = DataItem("Alex", 42, "-")
print ("get_size(d1):", get_size(d1))
d2 = DataItem("Boris", 24, "In the middle of nowhere")
print ("get_size(d2):", get_size(d2))Получаем 460 и 484 байта соответственно, что больше похоже на правду.
Имея эту функцию, можно провести ряд экспериментов. Например интересно, сколько места займут данные, если структуры DataItem положить в список. Функция get_size([d1]) возвращает 532 байта — видимо, это «те самые» 460 + некоторые накладные расходы. А вот get_size([d1, d2]) вернет 863 байта — меньше, чем 460 + 484 по отдельности. Еще интереснее результат для get_size([d1, d2, d1]) — мы получаем 871 байт, лишь чуть больше, т.е. Python достаточно «умен» чтобы не выделять память под один и тот же объект второй раз.
Теперь мы переходим ко второй части вопроса — можно ли уменьшить расход памяти? Да, можно. Python это интерпретатор, и мы в любой момент можем расширить наш класс, например добавить новое поле:
d1 = DataItem("Alex", 42, "-")
print ("get_size(d1):", get_size(d1))
d1.weight = 66
print ("get_size(d1):", get_size(d1))Это замечательно, но если нам не нужна эта функциональность, мы можем принудительно указать интерпретатору список объектов класса с помощью директивы __slots__:
class DataItem(object):
__slots__ = ['name', 'age', 'address']
def __init__(self, name, age, address):
self.name = name
self.age = age
self.address = address
Более подробно прочитать можно в документации (RTFM), в которой написано что "__slots__ allow us to explicitly declare data members (like properties) and deny the creation of __dict__ and __weakref__. The space saved over using __dict__ can be significant".
Проверяем: да, действительно significant, get_size(d1) возвращает… 64 байта вместо 460, т.е. в 7 раз меньше. Как бонус, создаются объекты примерно на 20% быстре (см. первый скриншот статьи).
Увы, при реальном использовании такого большого выигрыша в памяти не будет за счет других накладных расходов. Создадим массив на 100000 простым добавлением элементов, и посмотрим расход памяти:
data = []
for p in range(100000):
data.append(DataItem("Alex", 42, "middle of nowhere"))
snapshot = tracemalloc.take_snapshot()
top_stats = snapshot.statistics('lineno')
total = sum(stat.size for stat in top_stats)
print("Total allocated size: %.1f MB" % (total / (1024*1024)))
Имеем 16.8 Мбайт без __slots__ и 6.9 Мб с ним. Не в 7 раз конечно, но и так вполне неплохо, учитывая что изменение кода было минимальным.
Теперь о недостатках. Активация __slots__ запрещает создание всех элементов, включая и __dict__, значит к примеру, не будет работать такой код перевода структуры в json:
def toJSON(self):
return json.dumps(self.__dict__)
Но это просто исправить, достаточно сгенерировать свой dict программно, перебрав все элементы в цикле:
def toJSON(self):
data = dict()
for var in self.__slots__:
data[var] = getattr(self, var)
return json.dumps(data)
Также невозможно будет динамически добавлять новые переменные в класс, но в моем случае этого и не требовалось.
И последний тест на сегодня. Интересно посмотреть, сколько памяти занимает программа целиком. Добавим в конец программы бесконечный цикл, чтобы она не закрывалась, и посмотрим расход памяти в диспетчере задач Windows.
Без __slots__:
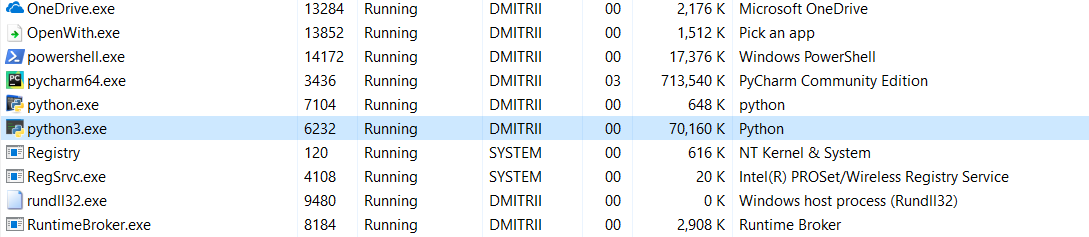
16.8Мб каким-то чудом превратилось (правка — объяснение чуда ниже) в 70Мб (программисты Си надеюсь еще не вернулись к экрану?).
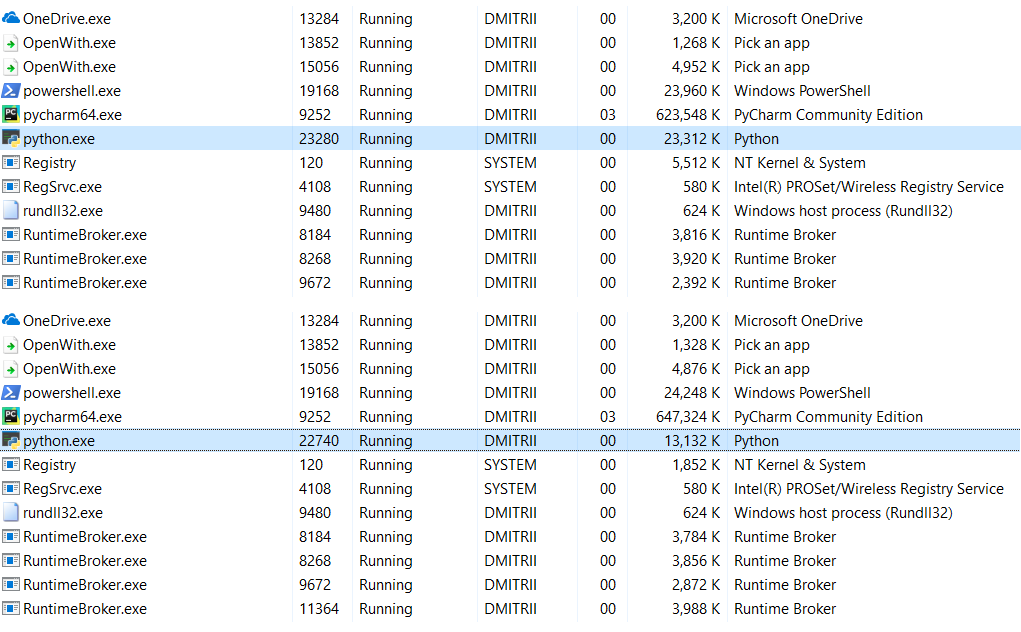
С включенным __slots__:

6.9Мб превратились в 27Мб… ну, все-таки память мы сэкономили, 27Мб вместо 70 это не так уж плохо для результата добавления одной строчки кода.
Правка: в комментариях (спасибо robert_ayrapetyan за проделанный тест) подсказали, что много дополнительной памяти занимает использование отладочной библиотеки tracemalloc. Видимо, она добавляет дополнительные элементы к каждому создаваемому объекту. Если отключить ее, суммарный расход памяти будет гораздо меньше, на скриншоте показаны 2 варианта:
Что делать, если нужно сэкономить еще больше памяти? Это возможно с использованием библиотеки numpy, позволяющей создавать структуры в Си-стиле, но в моем случае это потребовало бы более глубокой доработки кода, да и первого способа оказалось вполне достаточно.
Странно, что использование __slots__ ни разу не разбиралось подробно на Хабре, надеюсь, эта статья немного восполнит данный пробел.
Вместо заключения.
Может показаться, что данная статья является антирекламой Python, но это совсем не так. Python — очень надежный (чтобы «уронить» программу на Python надо очень сильно постараться), легко читабельный и удобный для написания кода язык. Эти плюсы во многих случаях перевешивают минусы, ну а если нужна максимальная производительность и эффективность, можно использовать библиотеки вроде numpy, написанные на С++, которые работают с данными вполне быстро и эффективно.
Всем спасибо за внимание, и хорошего кода :)
Комментарии (54)

robert_ayrapetyan
27.10.2018 00:36+2> 16.8Мб каким-то чудом превратилось в 70Мб
Так это память интерпретатора, не имеет отношения к вашему коду.DmitrySpb79 Автор
27.10.2018 09:30Вероятно да, но как видно из результатов, включение/выключение slots на память интерпретатора ощутимо влияет тоже.
robert_ayrapetyan
27.10.2018 18:32В статье этого как раз и не видно, мб пропустил. Вы меряете свои структуры и выводите размеры в коде, а потом сразу бац — скриншот из менеджера задач. Покажите какой был размер, занимаемый процессом до\после. А потом еще и «пустым» запущенным процессом интерпритатора, чтобы знать его собственный размер.
DmitrySpb79 Автор
27.10.2018 19:41Там 2 скриншота из менеджера задач, которые отличаются только slots. Полагаю что его наличие или отсутствие сильно влияет на внутреннюю структуру интерпретатора, как именно хз, не вникал.
Более точные измерения есть чуть выше внутри, где я использовал tracemalloc.take_snapshot, для них скриншот не приведен, просто цифры даны в тексте.robert_ayrapetyan
28.10.2018 02:05+1Хм, вот что удалось намерять мне. Во-первых, tracemalloc генерит большой оверхед (это к чуду превращения 17Мб в 70Мб), надо от него избавляться.
1. Выделения памяти пустым скриптом (фактически это память, необходимая самому интерпретатору, чтобы просто запуститься):
dtrace -n 'syscall::mmap:entry { @ = sum(arg1); }' -c "python empty.py"
35950592 (34MB)
2. Создаем скрипт по мотивам вашей логики, без доп. оверхеда:
test.py
class DataItem(object): # __slots__ = ['name', 'age', 'address'] def __init__(self, name, age, address): self.name = name self.age = age self.address = address data = [] def foo(): for p in range(100000): data.append(DataItem("Alex", 42, "middle of nowhere")) foo()
2.1. Без слотов:
dtrace -n 'syscall::mmap:entry { @ = sum(arg1); }' -c "python test.py"
53514240 (51MB)
2.2. Со слотами:
dtrace -n 'syscall::mmap:entry { @ = sum(arg1); }' -c "python test.py"
42766336 (40MB)
Если вычесть память самого питоновского движка (34MB), получим соотв. 17 и 6 МБ под сами структуры (почти то же самое, что намерили вы).
Интересно, что зависимость не линейная (это уже паттерны выделения памяти ОС): увеличив повторения цикла в 10 раз (1 млн. повторений), получим
182Мб и 291Мб соответственно, еще в 10 раз (10 млн. повторений) получим 1494Мб и 2835Мб, т.е. заголовок статьи можно поменять на «от 1.5 до 2.5 раз».
Andy_U
27.10.2018 00:57+2На всякий случай, большая часть атрибутов из первой картинки — это атрибуты класса. Добавьте в функцию dump вывод id(attr), вызовите ее второй раз с аргументом DataItem и увидите, что почти все адреса совпадают. Соответственно и функцию подсчета нужно модифицировать, чтобы она эти общие для всех инстансов атрибуты не учитывала.
tmnhy
27.10.2018 01:08+2>>> from pympler import asizeof >>> asizeof.asized(d1, detail=1).format() <DataItem object at 0x7fde39dc8ba8> size=480 flat=56 __dict__ size=424 flat=112 __class__ size=0 flat=0
Но, да, как пример обход атрибутов — наверное, для понимания полезнее.
etho0
27.10.2018 05:34+1Первую четверть статьи молился что бы было что-то интересное, а не slots. И неверно называть это решением на одну строку кода. В проекте может быть миллион классов, могут быть классы где аттрибуты динамические, да основные затраты вообще могут идти на типы которые нельзя отредактировать толком.
P.S.использование __slots__ ни разу не разбиралось подробно на Хабре
Может я чего-то не понимаю но это все что угодно кроме подробного разбора, скорее что-то типо не большого ревьюDmitrySpb79 Автор
27.10.2018 09:24Судя по названию про «одну строчку кода», можно было догадаться про slots, да ;)
Естественно, в реальном проекте экономия будет меньше, ну думаю это и так очевидно.
Xalium
27.10.2018 06:16Просто для примера, sys.getsizeof("") вернет 33 — да, целых 33 байта на пустую строку! А sys.getsizeof(1) вернет 24 — 24 байта для целого числа
Это какая ОС/версия питон?
Win 7 x64, Python 2.7.15
sys.getsizeof("") # 21 sys.getsizeof(целое_число) # от 12 и выше sys.getsizeof(dict()) # 140
Win 7 x64, Python 3.6.6
sys.getsizeof("") # 25 sys.getsizeof(целое_число) # от 14 и выше sys.getsizeof(dict()) # 136Yahweh
27.10.2018 10:13Да ладно у автора еще нормально, бывает и хуже
import sys v = sys.version.replace("\n", "| ") print(f'version: {v}') print(f'string: {sys.getsizeof("")}') print(f'number: {sys.getsizeof(11)}') print(f'dict: {sys.getsizeof({})}')
Out
version: 3.6.5 (default, Apr 1 2018, 05:46:30) | [GCC 7.3.0] string: 49 number: 28 dict: 240
tmnhy
27.10.2018 09:24iOS/Linux developer
Но, почему PowerShell и 10?DmitrySpb79 Автор
27.10.2018 09:27Ставить Linux дома я все же не готов :)
Ну и Python вполне кроссплатформенная штука, вышеприведенный код работает везде, от Винды до Raspberry Pi или OSX.
menstenebris
27.10.2018 12:56-1Интересно было бы сравнить еще с data class которыйэ добавили в
3.7. Может это синтаксический сахар. А может и нет
NaName
27.10.2018 13:22Python. К вершинам мастерства. стр. 293. Там много чего интересного написано, про что не было статей на хабре.
Dessloch
27.10.2018 16:51не программист, просто для интереса делаю так:
import sys class DataItem(object): def __init__(self, name, age, address): self.name = name self.age = age self.address = address d1 = DataItem("Alex", 42, "-") print ("sys.getsizeof(d1):", sys.getsizeof(d1)) class DataItem1(object): __slots__ = ['name', 'age', 'address'] def __init__(self, name, age, address): self.name = name self.age = age self.address = address d2 = DataItem1("Alex", 42, "-") print ("sys.getsizeof(d2):", sys.getsizeof(d2))
('sys.getsizeof(d1):', 64)
('sys.getsizeof(d2):', 72)
ЧЯДНТ?
P.S.
python -V Python 2.7.15rc1 Ubuntu 18.04.1 LTS
jackynautiyal
27.10.2018 19:26It is also not necessary to read what is written in general in any book. Along the hook, take Lutz, Beasley, Summerfil — each one is spelled out clearly, accessiblely and clearly.
Although how the memory consumption is affected by the slots in the real code, it would be interesting to read the real problem solver. Only if this real code is not tailored specifically for slots, such as a huge number of objects of the same class. RichestsoftDmitrySpb79 Автор
27.10.2018 19:35This was already discussed in the first comments thread. Many people are using Python for fun or for their hobby projects or as a helper tool for other projects, and they are not aware of using slots or dict. This article is mostly for beginners.
I also described briefly my real task in the first thread as well (you can use google translate to read it:).
Miron11
27.10.2018 20:15"(программистов на Си прошу отойти от экрана и дальше не читать, дабы не утратить веру в прекрасное)"
— поздно, инфаркт — валидол — скорая.
Садист!!!Borjomy
28.10.2018 01:39Поддерживаю. Я конечно понимаю, что с питоном все плохо… Но настолько! Пробовал пользоваться. Наткнулся на потрясающе низкую скорость выполнения. Теперь и это. Ребята, прекрасно, конечно, что вам удобно вести разработку на таком языке, где думать особо не надо. Только вот пользователю этими программами пользоваться. А потом думаешь, а что это элементарная программа так тормозит и память жрет? Знаете программистский апопкалипсис? Это когда всех питонщиков посадят на C.
DmitrySpb79 Автор
28.10.2018 09:53На самом деле, не все так плохо.
Питон это интерпретатор, и естественно, он работает медленнее. Но его библиотеки написаны как раз на Си, и при их грамотном использовании, код лишь чуть уступает по скорости. Еще к питону можно и свои С-библиотеки подключать, да много чего там есть.
На самом деле, Python обманчиво простой язык, с низким порогом входа, но писать на нем эффективные программы далеко не так просто, и требует понимания не меньшего, чем для С-программистов.
Cykooz
28.10.2018 13:33Вы же наверное понимаете почему в питоне целое число занимает 24 байта и более? Вот простейший для питона код, который объясняет это (** — это возведение в степень):
print(10**5000 + 23**1200 — 67**150)
Для питона такие большие ЦЕЛЫЕ числа — не проблема. Поэтому они занимают столько много места.
Интересно сколько времени займёт написать на C аналогичный пример?Borjomy
28.10.2018 21:21Для начала, расскажите, в каких областях техники оперируют такими степенями. В жизни вы НИКОГДА с такими числами не столкнетесь. И считанные программисты хоть раз в жизни с этим сталкиваются. Это такой сферический конь в вакууме. Для остальных с головой достаточно типа Double. Если совсем невмоготу, то есть Extended, который поддерживает указанный вами диапазон от 3.37 x 10**-4932 до 1.18 x 10**4932 и занимает 16 байт в памяти. Поэтому питон никакого сверхестественного диапазона чисел не обеспечивает. Все его библиотеки написаны на C. Но озвучу здесь маленькую догадку, откуда взялся размер 24 байта. Наиболее вероятно, что переменные хранятся в банальном типе Variant. Это наиболее подходящий способ хранения переменных для такого языка.
Arlekcangp
28.10.2018 22:15но питон написан на си… Т е его писали программисты на си… Сразу возникает вопрос — как они не померли и зачем сделали это? Это были садомазохисты видимо...
tmnhy
27.10.2018 20:55Засирателям кармы и минусаторам посвящается, вот так материал на эту тему выглядит с претензией на полноту:
barabanus
28.10.2018 23:00Немного смешно читать про оптимизацию Python программ средствами самого Python. 1000 объектов теперь занимают не 100МБ, а 50МБ. Вау! При том, что на C/C++ эти же 1000 объектов уместяться в 64к.
А вообще, писать ускоряющие С/С++/Cython библиотеки для Python — это мой хлеб. И первое, что дает прирост в десятки, а иногда и сотни раз — отказ от использования питоновских объектов и питоновского же менеджера памяти. Больше всего мне нравится, когда в конце разработки клиент замеряет скорость работы и у него округляются глаза. Вычисления зависели, скажем, как O(n) и клиент начинал уже придумывать, как ему уменьшить «n», чтобы вложиться во временной интервал. А после ускорения оказывалось, что даже самый большой «n» клиента вписывается с запасом в одну миллисекунду.
Python хорош для прототипирования. Для Computer Vision или Machine Learning хорошо пробовать много разных вещей и Python тут раскрывается во всей красе. Но если надо запилить свой математический алгоритм, то это неподходящий инструмент.
KvanTTT
29.10.2018 00:51Находится в хабе «высокая производительность». Нужно в «обычная произвоидительность» или «не низкая».
tmnhy
Вы забыли в конце резюмировать «ваш К.О.».
Когда речь заходит про «питон и оптимизацию», первым делом приводят пример _slots_ и вторым пунктом — namedtuple (попробуйте и ещё одну статью
ни о чёмнапишите).DmitrySpb79 Автор
Самому попробовать всегда интереснее, чем где-то прочитать, так что ничего плохого не вижу.
YaakovTooth
Не обязательно сообщать всему миру, что кто-то научился ходить, а кто-то уже в детский садик пошёл.
DmitrySpb79 Автор
Сайт читают не только профи, и не все знают про slots и dict. Нет ничего плохого если кто-то научится чему-то новому из этой (или любой другой) статьи.
YaakovTooth
Действительно — то, что написано в документации ярко, просто, прямо и понятно читать не надо. Так же не надо читать то, что написано вообще в любой книге. Навсидку, возьмём Лутца, Бизли, Саммерфила — у каждого это прописано чётко, доступно и понятно.
С другой стороны, выкладывали же мануалы по установке модулей для вордпрессе, сайт же читают не только профи, всё правильно.
«Power on IBM/PC for dummies».
DmitrySpb79 Автор
Да, вы не поверите, но бывают и статьи для начинающих. Ваш К.О. ;)
YaakovTooth
Я вам более отличный способ экономии памяти нашёл.
DmitrySpb79 Автор
Кстати была мысль в некоторых местах использовать dict вместо класса, но уж больно страдает читабельность кода имхо.
YaakovTooth
Cheatability здесь не при чём, здесь плохой дизайн; надо переделывать.
Yahweh
Я думаю в коде того кто не знает про slots и dict бутылочным горлышком будет далеко не slots, а более банальные вещи.
Хотя как на потребление памяти влияет slots в реальном коде, решаящем реальную задачу было бы интересно почитать. Только если этот реальный код не подогнан специально под slots, типа огромного количества объектов одного класа.
DmitrySpb79 Автор
В моем случае ничего сверх-интересного не было, но slots все же пригодился. Надо было хранить информацию о кадрах с IP-камер (timestamp, размер, и пр), которые приходили 2 раза в секунду. Массив динамический, кадры то приходят новые, то удаляются, так что numpy array тут был бы неудобен. Все это еще и на девайсе типа Raspberry Pi, так что памяти не сильно много.
В итоге, после нескольких дней работы девайса без остановки, память просто выжралась вся, хотя объектов было не так уж много.
YaakovTooth
Очевидно, что причина не в слотсах. И решать нужно проблему, а не лечить симптомы, когда уже всё сдохло.
DmitrySpb79 Автор
Массив кадров нужно было хранить в памяти, т.к. он нужен для их обработки, выборка потом делается по timestamps. Можно гипотетически на диск скидывать, но тогда SD-карта (которая вместо диска) быстро помрет.
Как вариант, использовать массивы numpy, тоже думал об этом, но пока не так критично чтобы это переписывать.
YaakovTooth
Вы вместо пересказа любого учебника по питонам в посте — лучше бы задачу озвучили, это куда как интереснее и продуктивнее. :)
DmitrySpb79 Автор
Задача в целом простая, я чуть ниже ответил, хранение изображений с IP-камер в «облаке», для этого есть автономный девайс типа Raspberry Pi который все это хранит и обрабатывает. Т.к. девайс простой, есть ограничения на количество циклов записи на карту, ну и на память в целом (PS: переписать все на Си не предлагать;).
Source
Перепишите на Nim xD
DmitrySpb79 Автор
Была мысль на Go переписать :)
Source
Ну не, тогда уж лучше на Си )))
Yahweh
Я думаю YaakovTooth и не только хочет сказать что slots может только отсрочить проблему на какое-то время, а потом добавится ктоме timestamp еще несколько полей и проблему все равно прийдется решать более основательно.
DmitrySpb79 Автор
Да, согласен разумеется, бесконечной памяти никто и нигде не обещал.
Yahweh
Конечно никто тут кроме вас не знает вашу задачу и ее ограничения.
Но так на вскидку: неужели все эти кадры надо в памяти хранить, а не прочитал > обработал > при необходимости записал куда-то > выкинул из памяти > побежал дальше.
DmitrySpb79 Автор
Там в общем, так и было — информация о кадрах хранится в памяти, затем если интернет есть, все это уходит на сервер в Azure, кадр удаляется. Но если по какой-то причине интернета нет, массив начинает заполняться и расти.
Ситуацию «интернета нет месяц» я все же не рассматриваю как нереальную, так что данной оптимизации в принципе было достаточно.