Прим. перев.: Оригинальная статья написана представителями компании BlueData, основанной выходцами из VMware. Она специализируется на том, чтобы сделать доступнее (проще, быстрее, дешевле) развёртывание решений для Big Data-аналитики и машинного обучения в различных окружениях. Этому призвана способствовать и недавняя инициатива компании под названием BlueK8s, в которой авторы хотят собрать плеяду Open Source-инструментов «для деплоя stateful-приложений и управления ими в Kubernetes». Статья посвящена первому из них — KubeDirector, что, согласно замыслу авторов, помогает энтузиасту в области Big Data, не имеющему специальной подготовки в Kubernetes, разворачивать в K8s приложения типа Spark, Cassandra или Hadoop. Краткая инструкция о том, как это сделать, и приведена в статье. Однако учтите, что у проекта ранний статус готовности — pre-alpha.

KubeDirector — Open Source-проект, созданный для упрощения запуска кластеров из сложных масштабируемых stateful-приложений в Kubernetes. KubeDirector реализован с помощью фреймворка Custom Resource Definition (CRD), использует родные возможности расширения Kubernetes API и опирается на их философию. Такой подход обеспечивает прозрачную интеграцию с управлением пользователей и ресурсов в Kubernetes, а также с существующими клиентами и утилитами.
Анонсированный недавно проект KubeDirector — часть большей Open Source-инициативы для Kubernetes, названной BlueK8s. Теперь я рад объявить и о доступности раннего (pre-alpha) кода KubeDirector. В этой публикации будет показано, как он работает.
KubeDirector предлагает следующие возможности:
KubeDirector позволяет data scientists, привыкшим к распределённым приложениям с интенсивной обработкой данных, таким как Hadoop, Spark, Cassandra, TensorFlow, Caffe2 и т.п., запускать их в Kubernetes с минимальной кривой обучения и без необходимости в написании кода на Go. Когда эти приложения контролируются KubeDirector, они определяются простыми метаданными и связанным с ними набором конфигураций. Метаданные приложения определяются как ресурс
Чтобы разобраться в компонентах KubeDirector, склонируйте репозиторий на GitHub командой вроде следующей:
Определение
Конфигурация кластера приложения определяется как ресурс
Определение
Запускать кластеры Spark в Kubernetes вместе с KubeDirector просто.
Во-первых, убедитесь, что запущен Kubernetes (версии 1.9 или выше), — с помощью команды
Разверните сервис KubeDirector и примеры определений ресурсов
В результате запустится под с KubeDirector:
Просмотрите список установленных в KubeDirector приложений, выполнив
Теперь можно запустить кластер Spark 2.2.1 с помощью файла-примера для
В списке запущенных сервисов тоже появился Spark:
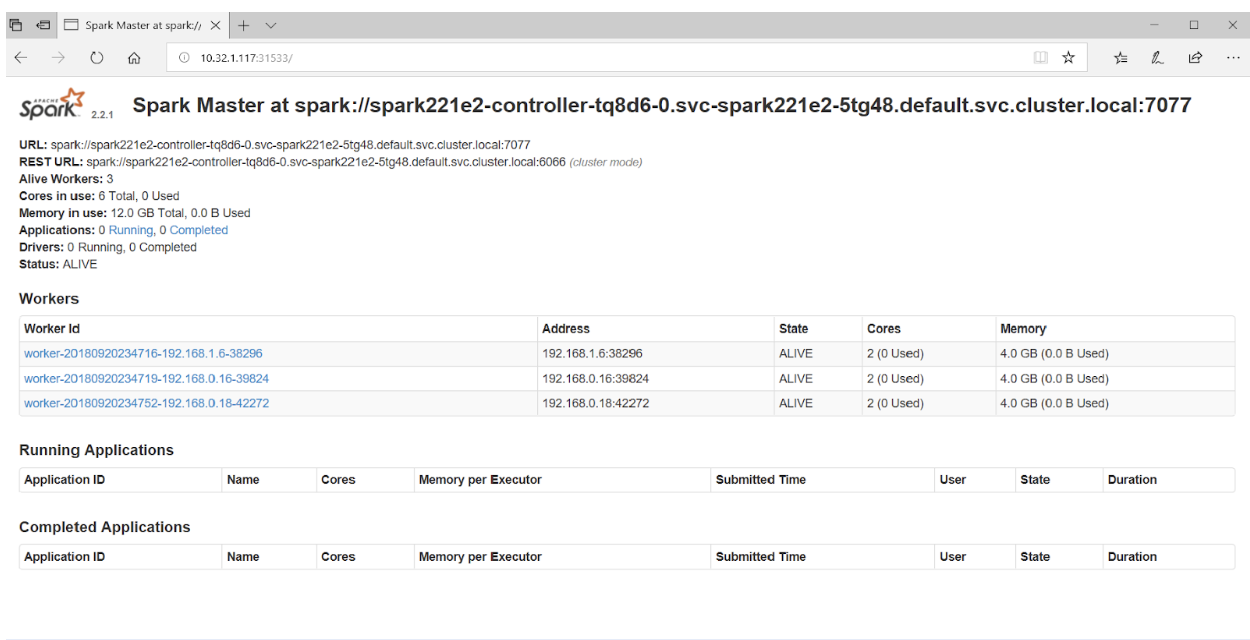
Если в браузере обратиться к порту 31533, можно увидеть Spark Master UI:
Вот и всё! В примере выше мы помимо кластера Spark развернули ещё и Jupyter Notebook.
Для запуска другого приложения (например, Cassandra) просто укажите другой файл с
Проверьте, что кластер Cassandra стартовал:
Теперь в Kubernetes запущены кластер Spark (с Jupyter Notebook) и кластер Cassandra. Список сервисов можно увидеть командой
Если вы заинтересовались проектом KubeDirector, стоит так же обратить внимание на его wiki. К сожалению, найти публичный roadmap не удалось, однако issues в GitHub проливают свет на ход развития проекта и взгляды его главных разработчиков. Кроме того, для заинтересованных в KubeDirector авторы приводят ссылки на Slack-чат и Twitter.
Читайте также в нашем блоге:
KubeDirector — Open Source-проект, созданный для упрощения запуска кластеров из сложных масштабируемых stateful-приложений в Kubernetes. KubeDirector реализован с помощью фреймворка Custom Resource Definition (CRD), использует родные возможности расширения Kubernetes API и опирается на их философию. Такой подход обеспечивает прозрачную интеграцию с управлением пользователей и ресурсов в Kubernetes, а также с существующими клиентами и утилитами.
Анонсированный недавно проект KubeDirector — часть большей Open Source-инициативы для Kubernetes, названной BlueK8s. Теперь я рад объявить и о доступности раннего (pre-alpha) кода KubeDirector. В этой публикации будет показано, как он работает.
KubeDirector предлагает следующие возможности:
- Отсутствие необходимости в модификации кода для запуска в Kubernetes stateful-приложений не из категории cloud native. Другими словами, пропадает потребность в декомпозиции уже существующих приложений для их соответствия паттерну микросервисной архитектуры.
- Родная поддержка хранения специфичной для приложения конфигурации и состояния (state).
- Не зависящий от приложений паттерн деплоя, минимизирующий время запуска новых stateful-приложений в Kubernetes.
KubeDirector позволяет data scientists, привыкшим к распределённым приложениям с интенсивной обработкой данных, таким как Hadoop, Spark, Cassandra, TensorFlow, Caffe2 и т.п., запускать их в Kubernetes с минимальной кривой обучения и без необходимости в написании кода на Go. Когда эти приложения контролируются KubeDirector, они определяются простыми метаданными и связанным с ними набором конфигураций. Метаданные приложения определяются как ресурс
KubeDirectorApp.Чтобы разобраться в компонентах KubeDirector, склонируйте репозиторий на GitHub командой вроде следующей:
git clone http://<userid>@github.com/bluek8s/kubedirector.Определение
KubeDirectorApp для приложения Spark 2.2.1 расположено в файле kubedirector/deploy/example_catalog/cr-app-spark221e2.json: ~> cat kubedirector/deploy/example_catalog/cr-app-spark221e2.json {
"apiVersion": "kubedirector.bluedata.io/v1alpha1",
"kind": "KubeDirectorApp",
"metadata": {
"name" : "spark221e2"
},
"spec" : {
"systemctlMounts": true,
"config": {
"node_services": [
{
"service_ids": [
"ssh",
"spark",
"spark_master",
"spark_worker"
],
…Конфигурация кластера приложения определяется как ресурс
KubeDirectorCluster.Определение
KubeDirectorCluster для примера с кластером Spark 2.2.1 доступно в kubedirector/deploy/example_clusters/cr-cluster-spark221.e1.yaml:~> cat kubedirector/deploy/example_clusters/cr-cluster-spark221.e1.yamlapiVersion: "kubedirector.bluedata.io/v1alpha1"
kind: "KubeDirectorCluster"
metadata:
name: "spark221e2"
spec:
app: spark221e2
roles:
- name: controller
replicas: 1
resources:
requests:
memory: "4Gi"
cpu: "2"
limits:
memory: "4Gi"
cpu: "2"
- name: worker
replicas: 2
resources:
requests:
memory: "4Gi"
cpu: "2"
limits:
memory: "4Gi"
cpu: "2"
- name: jupyter
…Запуск Spark в Kubernetes с KubeDirector
Запускать кластеры Spark в Kubernetes вместе с KubeDirector просто.
Во-первых, убедитесь, что запущен Kubernetes (версии 1.9 или выше), — с помощью команды
kubectl version:~> kubectl version
Client Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.3", GitCommit:"a4529464e4629c21224b3d52edfe0ea91b072862", GitTreeState:"clean", BuildDate:"2018-09-09T18:02:47Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.3", GitCommit:"a4529464e4629c21224b3d52edfe0ea91b072862", GitTreeState:"clean", BuildDate:"2018-09-09T17:53:03Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"}Разверните сервис KubeDirector и примеры определений ресурсов
KubeDirectorApp с помощью следующих команд:cd kubedirector
make deployВ результате запустится под с KubeDirector:
~> kubectl get pods
NAME READY STATUS RESTARTS AGE
kubedirector-58cf59869-qd9hb 1/1 Running 0 1m Просмотрите список установленных в KubeDirector приложений, выполнив
kubectl get KubeDirectorApp:~> kubectl get KubeDirectorApp
NAME AGE
cassandra311 30m
spark211up 30m
spark221e2 30mТеперь можно запустить кластер Spark 2.2.1 с помощью файла-примера для
KubeDirectorCluster и команды kubectl create -f deploy/example_clusters/cr-cluster-spark211up.yaml. Проверьте, что он стартовал:~> kubectl get pods
NAME READY STATUS RESTARTS AGE
kubedirector-58cf59869-djdwl 1/1 Running 0 19m
spark221e2-controller-zbg4d-0 1/1 Running 0 23m
spark221e2-jupyter-2km7q-0 1/1 Running 0 23m
spark221e2-worker-4gzbz-0 1/1 Running 0 23m
spark221e2-worker-4gzbz-1 1/1 Running 0 23mВ списке запущенных сервисов тоже появился Spark:
~> kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubedirector ClusterIP 10.98.234.194 <none> 60000/TCP 1d
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d
svc-spark221e2-5tg48 ClusterIP None <none> 8888/TCP 21s
svc-spark221e2-controller-tq8d6-0 NodePort 10.104.181.123 <none> 22:30534/TCP,8080:31533/TCP,7077:32506/TCP,8081:32099/TCP 20s
svc-spark221e2-jupyter-6989v-0 NodePort 10.105.227.249 <none> 22:30632/TCP,8888:30355/TCP 20s
svc-spark221e2-worker-d9892-0 NodePort 10.107.131.165 <none> 22:30358/TCP,8081:32144/TCP 20s
svc-spark221e2-worker-d9892-1 NodePort 10.110.88.221 <none> 22:30294/TCP,8081:31436/TCP 20sЕсли в браузере обратиться к порту 31533, можно увидеть Spark Master UI:
Вот и всё! В примере выше мы помимо кластера Spark развернули ещё и Jupyter Notebook.
Для запуска другого приложения (например, Cassandra) просто укажите другой файл с
KubeDirectorApp:kubectl create -f deploy/example_clusters/cr-cluster-cassandra311.yamlПроверьте, что кластер Cassandra стартовал:
~> kubectl get pods
NAME READY STATUS RESTARTS AGE
cassandra311-seed-v24r6-0 1/1 Running 0 1m
cassandra311-seed-v24r6-1 1/1 Running 0 1m
cassandra311-worker-rqrhl-0 1/1 Running 0 1m
cassandra311-worker-rqrhl-1 1/1 Running 0 1m
kubedirector-58cf59869-djdwl 1/1 Running 0 1d
spark221e2-controller-tq8d6-0 1/1 Running 0 22m
spark221e2-jupyter-6989v-0 1/1 Running 0 22m
spark221e2-worker-d9892-0 1/1 Running 0 22m
spark221e2-worker-d9892-1 1/1 Running 0 22mТеперь в Kubernetes запущены кластер Spark (с Jupyter Notebook) и кластер Cassandra. Список сервисов можно увидеть командой
kubectl get service:~> kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubedirector ClusterIP 10.98.234.194 <none> 60000/TCP 1d
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d
svc-cassandra311-seed-v24r6-0 NodePort 10.96.94.204 <none> 22:31131/TCP,9042:30739/TCP 3m
svc-cassandra311-seed-v24r6-1 NodePort 10.106.144.52 <none> 22:30373/TCP,9042:32662/TCP 3m
svc-cassandra311-vhh29 ClusterIP None <none> 8888/TCP 3m
svc-cassandra311-worker-rqrhl-0 NodePort 10.109.61.194 <none> 22:31832/TCP,9042:31962/TCP 3m
svc-cassandra311-worker-rqrhl-1 NodePort 10.97.147.131 <none> 22:31454/TCP,9042:31170/TCP 3m
svc-spark221e2-5tg48 ClusterIP None <none> 8888/TCP 24m
svc-spark221e2-controller-tq8d6-0 NodePort 10.104.181.123 <none> 22:30534/TCP,8080:31533/TCP,7077:32506/TCP,8081:32099/TCP 24m
svc-spark221e2-jupyter-6989v-0 NodePort 10.105.227.249 <none> 22:30632/TCP,8888:30355/TCP 24m
svc-spark221e2-worker-d9892-0 NodePort 10.107.131.165 <none> 22:30358/TCP,8081:32144/TCP 24m
svc-spark221e2-worker-d9892-1 NodePort 10.110.88.221 <none> 22:30294/TCP,8081:31436/TCP 24mP.S. от переводчика
Если вы заинтересовались проектом KubeDirector, стоит так же обратить внимание на его wiki. К сожалению, найти публичный roadmap не удалось, однако issues в GitHub проливают свет на ход развития проекта и взгляды его главных разработчиков. Кроме того, для заинтересованных в KubeDirector авторы приводят ссылки на Slack-чат и Twitter.
Читайте также в нашем блоге:
- «Операторы для Kubernetes: как запускать stateful-приложения»;
- «Rook — „самообслуживаемое“ хранилище данных для Kubernetes»;
- «Kubernetes tips & tricks: ускоряем bootstrap больших баз данных»;
- «Полезные утилиты при работе с Kubernetes»;
- «Полезные команды и советы при работе с Kubernetes через консольную утилиту kubectl»;
- «Знакомимся с альфа-версией снапшотов томов в Kubernetes»;
- «Представляем loghouse — Open Source-систему для работы с логами в Kubernetes».
gecube
Что-то я не уверен, что из этого выйдет прям продакшн решение. Полагаю, что останется на уровне minikube/minishift (т.е. поиграться), но если удастся обойти негативнвые особенности платформы k8s, то все только будут в выигрыше