
Привет всем!
Продолжая проработку темы глубокого обучения, мы как-то раз хотели поговорить с вами о том, почему нейронным сетям повсюду мерещатся овцы. Эта тема рассмотрена в 9-й главе книги Франсуа Шолле.
Таким образом мы вышли на замечательные исследования компании «Positive Technologies», представленные на Хабре, а также на отличную работу двоих сотрудников MIT, считающих, что «вредоносное машинное обучение» — не только помеха и проблема, но и замечательный диагностический инструмент.
Далее — под катом.
В течение нескольких последних лет случаи вредоносного вмешательства привлекли серьезное внимание в сообществе специалистов по глубокому обучению. В этой статье мы хотели бы в общих чертах рассмотреть данный феномен и обсудить, как он вписывается в более широкий контекст надежности машинного обучения.
Вредоносные вмешательства: интригующий феномен
Чтобы очертить пространство нашей дискуссии, приведем несколько примеров такого вредоносного вмешательства. Думаем, что большинству исследователей, занятых МО, попадались подобные картинки:
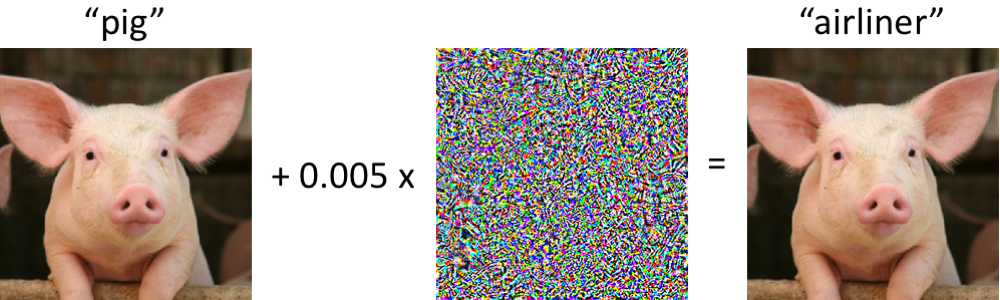
Слева изображен поросенок, верно классифицируемый современной сверточной нейронной сетью как поросенок. Стоит нам внести в картинку минимальные изменения (все пикселы находятся в диапазоне [0, 1], и каждый меняется не более чем на 0,005) – и теперь сеть с высокой достоверностью возвращает класс «авиалайнер». Такие атаки на обученные классификаторы известны как минимум с 2004 года (ссылка), а первые работы, касающиеся вредоносного вмешательства в классификаторы изображений относятся к 2006 году (ссылка). Затем этот феномен стал привлекать существенно больше внимания примерно с 2013 года, когда выяснилось, что нейронные сети уязвимы для атак такого рода (см. здесь и здесь). С тех пор многие исследователи предлагали варианты построения вредоносных примеров, а также способы повышения устойчивости классификаторов к таким патологическим возмущениям.
Однако, важно помнить, что совсем необязательно углубляться в нейронные сети, чтобы наблюдать такие вредоносные примеры.
Насколько устойчивы вредоносные примеры?
Возможно, ситуация, в которой компьютер путает поросенка с авиалайнером, поначалу может растревожить. Однако, следует отметить, что использованный при этом классификатор (сеть Inception-v3) не так хрупок, как может показаться на первый взгляд. Хотя, сеть и наверняка ошибается при попытке классифицировать искаженного поросенка, это происходит лишь в случае специально подобранных нарушений.
Сеть гораздо устойчивее к случайным возмущениям сопоставимой магнитуды. Поэтому, основной вопрос заключается в том, именно ли вредоносные возмущения вызывают хрупкость сетей. Если вредоносность как таковая критически зависит от контроля над каждым входным пикселом, то при классификации изображений в реалистичных условиях такие вредоносные образцы не кажутся серьезной проблемой.
Недавние исследования свидетельствуют об ином: можно обеспечить устойчивость возмушений к различным канальным эффектам в конкретных физических сценариях. Например, вредоносные образцы можно напечатать на обычном офисном принтере, так что изображения на них, сфотографированные камерой смартфона, все равно классифицируются неправильно. Также можно изготовить стикеры, из-за которых нейронные сети неверно классифицируют различные реальные сцены (см., например, ссылка1, ссылка2 и ссылка3). Наконец, недавно исследователи напечатали на 3D-принтере черепашку, которую стандартная сеть Inception практически под любым углом обзора ошибочно считает винтовкой.
Подготовка атак, провоцирующих ошибочную классификацию
Как создать такие вредоносные возмущения? Подходов много, но оптимизация позволяет свести все эти различные методы к обобщенному представлению. Как известно, обучение классификатора зачастую формулируется как нахождение параметров модели
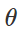 , позволяющих минимизировать эмпирическую функцию потерь для заданного множества примеров
, позволяющих минимизировать эмпирическую функцию потерь для заданного множества примеров  :
: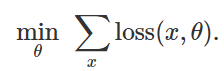
Поэтому, чтобы спровоцировать ошибочную классификацию для фиксированной модели
и “безвредного” ввода 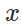 , естественно попытаться найти ограниченное возмущение
, естественно попытаться найти ограниченное возмущение  , такое, чтобы потери на
, такое, чтобы потери на  получились максимальными:
получились максимальными: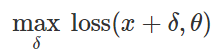
Если исходить из этой формулировки, многие методы создания вредоносного ввода можно считать различными оптимизационными алгоритмами (отдельные шаги градиента, проецируемый градиентный спуск, т.д.) для различных наборов ограничений (небольшое
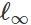 -нормальное возмущение, небольшие изменения пикселов, т.д.). Ряд примеров приведен в следующих статьях: ссылка1, ссылка2, ссылка3, ссылка4 и ссылка5.
-нормальное возмущение, небольшие изменения пикселов, т.д.). Ряд примеров приведен в следующих статьях: ссылка1, ссылка2, ссылка3, ссылка4 и ссылка5.Как было объяснено выше, многие успешные методы генерации вредоносных образцов работают с фиксированным целевым классификатором. Поэтому важен вопрос: а не воздействуют ли данные возмущения лишь на конкретную целевую модель? Что интересно – нет. При применении многих методов возмущения результирующие вредоносные образцы переносятся от классификатора к классификатору, обученных с разным набором исходных случайных значений (random seeds) или различных архитектур моделей. Более того, можно создать вредоносные образцы, обладающие лишь ограниченным доступом к целевой модели (иногда в таком случае говорят об «атаках по принципу черного ящика»). См., например, пять следующих статей: ссылка1, ссылка2, ссылка3, ссылка4 и ссылка5.
Не только картинки
Вредоносные образцы встречаются не только при классификации изображений. Похожие феномены известны при распознавании речи, в вопросно-ответных системах, при обучении с подкреплением и решении других задач. Как вы уже знаете, изучение вредоносных образцов продолжается более десяти лет:
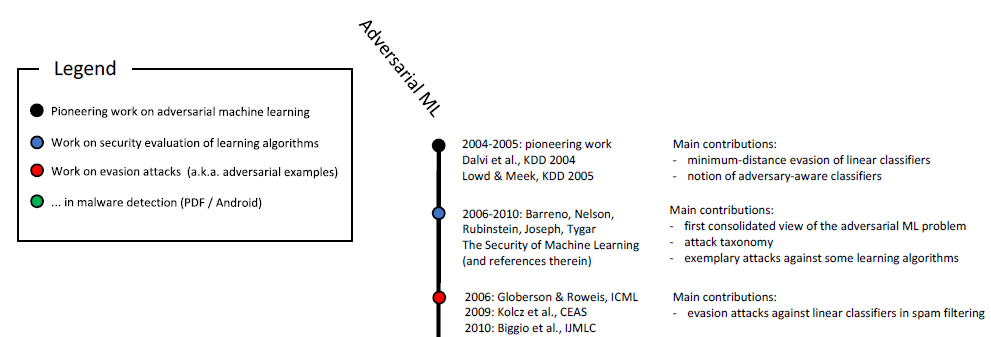
Хронологическая шкала вредоносного машинного обучения (начало). Полная шкала приведена на рис. 6 в этом исследовании.
Кроме того, естественной средой для изучения вредоносных аспектов машинного обучения являются приложения, связанные с обеспечением безопасности. Если злоумышленник может обмануть классификатор и выдать вредоносный ввод (скажем, спам или вирус) за безвредный, то спам-детектор или антивирусный сканер, работающий на основе машинного обучения, окажется неэффективен. Следует подчеркнуть, что эти соображения – не чисто академические. Например, команда Google Safebrowsing еще в 2011 году опубликовала многолетнее исследование того, как злоумышленники пытались обходить их системы обнаружения вредоносного ПО. Также см. эту статью о вредоносных образцах в контексте фильтрации спама в почте GMail.
Не только безопасность
Все новейшие работы по изучению вредоносных образцов совершенно четко выдержаны в ключе обеспечения безопасности. Это обоснованная точка зрения, но мы считаем, что такие образцы должны рассматриваться и в более широком контексте.
Надежность
В первую очередь вредоносные образцы поднимают вопрос о надежности всей системы. Прежде, чем мы сможем осмысленно рассуждать о свойствах классификатора с точки зрения безопасности, мы должны убедиться, что механизм хорошо обеспечивает высокую точность классификации. В конце концов, если мы собираемся развертывать наши обученные модели в реальных сценариях, то необходимо, чтобы они демонстрировали высокую степень надежности при изменении распределения базовых данных – независимо от того, обусловлены ли эти изменения злонамеренным вмешательством или всего лишь естественными флуктуациями.
В таком контексте вредоносные образцы – это полезное диагностическое средство для оценки надежности систем машинного обучения. В частности, подход с учетом вредоносных образцов позволяет выйти за рамки стандартного протокола оценки, где обученный классификатор прогоняется по тщательно подобранному (и обычно статическому) тестовому набору.
Так можно прийти к поразительным выводам. Например, оказывается, что можно легко создавать вредоносные образцы, даже не прибегая к изощренным методам оптимизации. В недавней работе мы показываем, что ультрасовременные классификаторы изображений удивительно уязвимы для небольших патологических переходов или поворотов. (См. здесь и здесь другие работы на эту тему.)

Поэтому, даже если не придавать значения, скажем, возмущениям из разряда ????, все равно зачастую возникают проблемы с надежностью из-за вращений и переходов. В более широком смысле, необходимо понимать показатели надежности наших классификаторов, прежде, чем можно будет интегрировать их в более крупные системы как подлинно надежные компоненты.
Понятие о классификаторах
Чтобы понять, как работает обученный классификатор, необходимо найти примеры его явно удачных или неудачных операций. В данном случае вредоносные образцы иллюстрируют, что обученные нейронные сети зачастую не соответствуют нашему интуитивному представлению о том, что значит «выучить» конкретную концепцию. Это особенно важно в глубоком обучении, где часто заявляют о биологически правдоподобных алгоритмах и о сетях, чья успешность не уступает человеческой (см, напр., здесь, здесь или здесь). Вредоносные образцы отчетливо заставляют в этом усомниться сразу во множестве контекстов:
- При классификации изображений, если минимально изменить набор пикселов или немного повернуть картинку, это едва ли помешает человеку отнести его к верной категории. Тем не менее, такие изменения полностью вырубают самые современные классификаторы. Если поместить объекты в необычном месте (например, овец на дереве) также легко убедиться, что нейронная сеть интерпретирует сцену совсем не так как человек.
- Если подставить нужные слова в текстовый отрывок, можно серьезно запутать вопросно-ответную систему, хотя, с точки зрения человека смысл текста из-за таких вставок не изменится.
- В этой статье на тщательно подобранных текстовых примерах показаны границы возможностей переводчика Google Translate.
Во всех трех случаях вредоносные примеры помогают испытать на прочность наши современные модели и подчеркивают, в каких ситуациях эти модели действуют совершенно не так, как поступал бы человек.
Безопасность
Наконец, вредоносные образцы действительно представляют опасность в тех сферах, где машинное обучение уже достигает определенной точности на «безвредном» материале. Всего несколько лет назад такие задачи как классификация изображений выполнялись еще очень плохо, поэтому проблема безопасности в данном случае казалась вторичной. В конце концов, степень безопасности системы с машинным обучением становится существенна лишь тогда, когда эта система начинает достаточно качественно обрабатывать «безвредный» ввод. В противном случае мы все равно не можем доверять ее прогнозам.
Теперь в различных предметных областях точность таких классификаторов существенно повысилась, и развертывание их в ситуациях, где критичны соображения безопасности – всего лишь вопрос времени. Если мы хотим ответственно к этому подойти, то важно исследовать их свойства именно в контексте безопасности. Но к вопросу безопасности нужен целостный подход. Подделать некоторые признаки (например, набор пикселов) гораздо легче, чем, например, другие сенсорные модальности, или категориальные признаки, или метаданные. В конце концов, при обеспечении безопасности лучше всего полагаться именно на такие признаки, которые сложно или даже практически невозможно изменить.
Итоги (подводить пока рано?)
Несмотря на впечатляющий прогресс в машинном обучении, который мы наблюдали в последние годы, необходимо учитывать пределы возможностей тех инструментов, что есть у нас в распоряжении. Проблемы самые разнообразные (напр., связанные с честностью, приватностью или эффектами обратной связи), причем, максимальную озабоченность вызывает надежность. Человеческое восприятие и познание устойчивы к разнообразнейшим фоновым помехам окружающей среды. Однако, вредоносные образцы демонстрируют, что нейронные сети до сих пор очень далеки от сопоставимой устойчивости.
Итак, мы уверены в важности изучения вредоносных примеров. Их применимость в машинном обучении далеко не ограничивается вопросами безопасности, а может послужить диагностическим эталоном для оценки обученных моделей. Подход с использованием вредоносных образцов выгодно отличается от стандартных оценочных процедур и статических тестов тем, что позволяет выявить потенциально неочевидные изъяны. Если мы хотим разобраться в надежности современного машинного обучения, то новейшие достижения важно исследовать и с точки зрения злоумышленника (правильно подобрав вредоносные образцы).
Пока наши классификаторы сбоят даже при минимальных изменениях между учебным и тестовым распределением, мы не сможем достичь удовлетворительной гарантированной надежности. В конце концов, мы стремимся создавать такие модели, которые не просто будут надежны, но и будут согласовываться с нашими интуитивными представлениями о том, что такое «изучить» задачу. Тогда они будут безопасны, надежны и удобны для развертывания в самых разных средах.
Комментарии (11)

DrZlodberg
11.11.2018 10:10Если злоумышленник может обмануть классификатор и выдать вредоносный ввод (скажем, спам или вирус) за безвредный, то спам-детектор или антивирусный сканер, работающий на основе машинного обучения, окажется неэффективен.
На яндексовую почту периодически приходит любопытный спам. Он не только отправлен не на мой адрес и даже не на домен яндекса, там в заголовке мой адрес вообще не упоминается нигде и ни в каком виде (я честно старался найти). Они там случаем не загнали в продакшн антиспамный аи? Вроде какие-то новости про такие перспективы были…
third112
S_A
TLDR: нейросети могут всё, но поставить исходную задачу может быть сложнее, чем решить.
1. Им действительно всегда будут мерешиться овцы. Известен случай (из книги «Верховный алгоритм», научпоп, но рекомендую к чтению на досуге), что одна нейросеть очень хорошо обучилась распознавать танки. А когда подсунули лошадь, она тоже решила что танк, потому что все танки были светлыми фотками, и фото с лошадью тоже. Т.е. вариант такой — нейросети могут сколько угодно хорошо работать даже на отложенном датасете, но она не в состоянии генерализовать знание настолько, насколько человек имеет его априорно от рождения (та же устойчивость к вращениям). По сути, из этого вытекала бы слабость мат. аппарата нейросетей в человекопривычных задачах.
2. Как ни странно, но нейросети как матаппарат — аппроксимируют любые функции. Следовательно, либо исходный датасет просто так себе (это универсальный ответ, но из разряда второго из трёх конвертов на работе), либо функция (архитектура и прочее) подобраны слабые.
Я лично склоняюсь к варианту, что нейросети не врут. Просто они живут в мире без тех априори, в котором мы живем, и даже если мы устраним проблему с поворотами — каким-нибудь предварительным преобразованием (пришло в голову isomap, но это не точно) или архитектурой, то вылезет еще что-нибудь, неучтенное в математике вопроса.
Теоретический ответ есть в упомянутой книге, но алгоритма на нем, если не считать Conditional Random Fields им в некотором роде, я что-то в либах даже не видел, не говоря уж продакшн.
А в целом пока что практический выход — верить Байесу, а не классификаторам.
third112
Человек априорно от рождения знает, что такое танк и лошадь? Думаю, нет. ИМХО новорожденный и сеть до обучения имеют одинаковый нуль знаний. Но человек учится гораздо лучше сети. Это заставляет предположить, что их устройства принципиально разные.
М.б. математика у сети и у человека разные? — два разных алгоритма м.б. основаны на разных мат. принципах. BTW интересно отметить, что шахматист не думает по альфа-бета алгоритму, которые использует ПО компьютерных шахмат. Но ни один хороший шахматист не может объяснить, как он думает, настолько подробно, чтобы реализовать это объяснение в ПО.
S_A
Шахматы уже давно не по альфа-бета алгоритму работают. Также, как и гроссмейстеры, мыслят фрагментами. Как и (сверточные) нейросети. Человек от рождения отличает танк от лошади на фото, при поворотах изображения тоже, в отличие от некоторых сетей.
Если человек смог описать, сам различает, обратная индукция сработает.
third112
S_A
Модели танков и породы лошадей отличают специально обученные люди :) я их тоже не очень отличаю.
Я говорю о том, что сетка или даже любой другой алгоритм — не мозг, а продолжение мозга. Будет это кувалда или скальпель — зависит от архитектуры и от данных.
DelphiCowboy
Проблема в том, что сети обучают на неподвижных фото, а не на видео, в результате:
— реальный танк — это подвижный 3D-объект,
— но для нейросети — это неподвижный набор цветных пятен на плоскости.
S_A
Ну человек-то отличает же фото, он может не знает танком ли это называется, но с лошадью не спутает. Видео кстати тоже набор пятен :) И время — одно из априори для человека, память у него сортирует картинки автоматом. Сети нужна архитектура для этого.
Дело в постановке задачи все же. Разделяемые визуально множества может разделить и нейросеть, только разделяющее преобразование очень сложно подобрать.
DelphiCowboy
Человек — увидев картинку, сразу пытается выстроить у себя в голове 3D-модель.
Нейросеть занимающаяся распознаванием — этого не делает, в чём и ошибка!
Нужно два слоя:
— первый слой строит 3D-модель из плоской картинки
— второй слой пытается распознать эту 3D-модель.
S_A
Соглашусь в том плане, что человек если и не 3D-модель строит, то как минимум ближе-дальше на фотках различает. Светом, тенями и так далее. Сети с осветлением справляются, а вот содержать в себе ту же модель Фонга, восстановить нормали они теоретически могут, но не делают. И все равно, проблема с переворачиванием останется скорее всего, там в другом проблема.