
{kind=link}
В начале 2016 года логи у наших администраторов и разработчиков были, что называется, «на кончиках пальцев», то есть инженер для работы с ними подключался с помощью SSH к хосту, где располагался интересующий его сервис, расчехлял универсальный набор из tail/grep/sed/awk и надеялся, что нужные данные удастся найти именно на этом хосте.

{kind=link}
Был у нас и отдельный сервер, куда по NFS монтировались все каталоги с логами со всех серверов, и который иногда надолго задумывался от того, что на нем делали с логами все желающие. Ну а tmux с несколькими панелями c запущенным tail на какие-нибудь активно обновляющиеся логи выглядел для сторонних наблюдателей весьма впечатляюще на большом мониторе и создавал волнительную атмосферу причастности к таинствам продакшена.
Всё это даже работало, но ровно до тех пор, пока не требовалось быстро обработать большой объем данных, а требовалось это чаще всего в моменты, когда в проде уже что-нибудь свалилось.
Иногда на расследование инцидентов требовалось совсем уж неприличное время. Его значительная часть уходила на ручную агрегацию логов, запуск
Словом, всё это было весьма медленно, навевало уныние и недвусмысленно намекало на то, что пора бы озаботиться централизованным хранением логов.
Если честно, никакого сложного процесса отбора кандидатов на роль технологического стека, который бы нам это обеспечил, тогда не было: связка ELK на тот момент уже была популярна, обладала хорошей документацией, в интернете по всем компонентам имелось большое количество статей. Решение было незамедлительным: нужно пробовать.

{kind=link}
Самую первую инсталляцию стека сделали после просмотра вебинара «Logstash: 0-60 in 60» на трёх виртуальных машинах, на каждой из которых запустили по экземпляру Elasticsearch, Logstash и Kibana.
Дальше мы столкнулись с некоторыми проблемами с доставкой логов с конечных хостов на серверы Logstash. Дело в том, что в то время Filebeat (штатное решение стека для доставки логов из текстовых файлов) гораздо хуже работал с большими и быстро обновляемыми файлами, регулярно протекал в RAM и в нашем случае в целом не справлялся со своей задачей.
К этому добавлялась необходимость найти способ доставлять логи серверов приложений с машин под управлением IBM AIX: основная часть приложений у нас тогда запускалась в WebSphere Application Server, работавшем именно под этой ОС. Filebeat написан на Go, более-менее работоспособного компилятора Go для AIX в 2016 году не существовало, а использовать Logstash в качестве агента для доставки очень не хотелось.
Мы протестировали несколько агентов для доставки логов: Filebeat, logstash-forwarder-java, log-courier, python-beaver и NXLog. От агентов мы ожидали высокой производительности, низкого потребления системных ресурсов, легкой интеграции с Logstash и возможности выполнять базовые манипуляции с данными силами агента (например, сборку многострочных событий).
Про сборку многострочных (multiline) событий стоит сказать отдельно. Эффективно ее можно выполнять только на стороне агента, который читает конкретный файл. Несмотря на то, что Logstash когда-то имел multiline-фильтр, а сейчас обладает multiline-кодеком, все наши попытки совместить балансировку событий по нескольким серверам Logstash с обработкой multiline на них же провалились. Такая конфигурация делает эффективную балансировку событий практически невозможной, поэтому для нас чуть ли не самым важным фактором при выборе агентов была поддержка multiline.
Победители распределились так: log-courier для машин с Linux, NXLog для машин с AIX. С такой конфигурацией мы и прожили почти год без особых проблем: логи доставлялись, агенты не падали (ну почти), все были довольны.
В октябре 2016 года была выпущена пятая версия компонентов Elastic Stack, в том числе и Beats 5.0. В этой версии над всеми агентами Beats была проделана большая работа, и мы смогли заменить log-courier (у которого к тому времени обнаружились свои проблемы) на Filebeat, который мы и используем до сих пор.
При переходе на версию 5.0 мы стали собирать не только логи, но и некоторые метрики: Packetbeat у нас начал кое-где использоваться как альтернатива записи логов HTTP-запросов в файлы, а Metricbeat собирал системные метрики и метрики некоторых сервисов.
К этому моменту работа наших инженеров с логами стала гораздо проще: теперь не нужно было знать, на какой сервер идти, чтобы посмотреть интересующий тебя лог, обмен найденной информацией упростился до простой передачи ссылки на Kibana в чатах или почте, а отчеты, которые раньше строились за несколько часов, стали создаваться за несколько секунд. Нельзя сказать, что это был просто вопрос комфорта: изменения мы заметили и в качестве нашей работы, в количестве и качестве закрытых задач, в скорости реагирования на проблемы на наших стендах.
В какой-то момент мы начали использовать утилиту ElastAlert от компании Yelp для рассылки алертов инженерам. А потом подумали: почему бы не интегрировать ее с нашим Zabbix, чтобы все алерты имели стандартный формат и отправлялись централизованно? Решение нашлось довольно быстро: ElastAlert позволяет вместо отправки, собственно, оповещений выполнять любые команды, что мы и использовали.
Сейчас наши правила ElastAlert при срабатывании выполняют bash-скрипт на несколько строк, которому в аргументах передают необходимые данные из события, вызвавшего срабатывание правила, а из скрипта, в свою очередь, вызывается zabbix_sender, который и отправляет данные в Zabbix для нужного узла.
Так как вся информация о том, кто и где сгенерировал событие, в Elasticsearch всегда есть, никаких сложностей с интеграцией не возникло. Например, у нас и раньше существовал механизм автоматического обнаружения серверов приложений WAS, а в событиях, которые они генерируют, всегда записывается имя сервера, кластера, ячейки и т.д. Это позволило нам использовать в правилах ElastAlert опцию query_key, чтобы условия правил обрабатывались для каждого сервера отдельно. Скрипту с zabbix_sender затем уходят точные «координаты» сервера и данные отправляются в Zabbix для соответствующего узла.
Еще одно решение, которое нам очень нравится и которое стало возможным благодаря централизованному сбору логов, – это скрипт для автоматического заведения тасков в JIRA: раз в сутки он выгребает все ошибки из логов и, если по ним еще нет тасков, заводит их. При этом из разных индексов по уникальному ID запроса в таск подтягивается вся информация, которая может пригодиться при расследовании. В результате получается эдакая стандартная заготовка с необходимым минимумом информации, которую потом инженеры могут дополнять при необходимости.
Разумеется, перед нами вставал вопрос мониторинга самого стека. Частично это реализовано с помощью Zabbix, частично с помощью все того же ElastAlert, а основные performance-метрики по Elasticsearch, Logstash и Kibana мы получаем с помощью штатного мониторинга, встроенного в стек (компонент Monitoring в X-Pack). Также на самих серверах с сервисами стека у нас установлена netdata от Firehol. Она бывает полезна, когда нужно посмотреть, что происходит с конкретной нодой прямо сейчас, в реальном времени и с высоким разрешением.
Когда-то в ней была немного поломан модуль для мониторинга Elasticsearch, мы это обнаружили, починили, добавили всяких полезных метрик и сделали пулл-реквест. Так что теперь netdata умеет мониторить последние версии Elasticsearch, включая базовые метрики JVM, показатели производительности индексации, поиска, статистику по логу транзакций, сегментам индексов и так далее. Netdata нам нравится, и нам приятно, что мы смогли сделать небольшой вклад в неё.
Сегодня, спустя почти три года, наш Elastic Stack выглядит примерно таким образом:
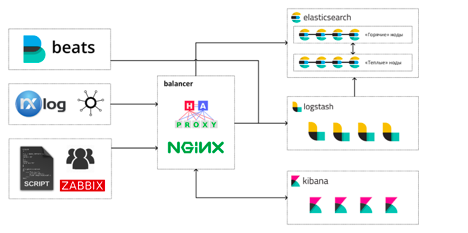
Инженеры работают со стеком тремя основными способами:
- просмотр и анализ логов и метрик в Kibana;
- дашборды в Grafana и Kibana;
- прямые запросы к Elasticsearch с использованием SQL или встроенного query DSL.
Суммарно на всё это выделены такие ресурсы: 146 CPU, 484GB RAM, под хранилище данных Elasticsearch выделено 17TB.
Всего у нас в составе Elastic Stack сейчас трудятся 13 виртуальных машин: 4 машины под «горячие» ноды Elasticsearch, 4 – под «тёплые», 4 машины с Logstash и одна машина-балансировщик. На каждой горячей ноде Elasticsearch запущено по экземпляру Kibana. Так сложилось с самого начала, и пока что у нас не было необходимости перемещать Kibana на отдельные машины.
А вот решение вынести Logstash на отдельные машины оказалось, наверное, одним из самых правильных и результативных за время эксплуатации стека: высокая конкуренция за процессорное время между JVM Elasticsearch и Logstash приводила к не очень приятным спецэффектам во время всплесков нагрузки. Больше всех страдали сборщики мусора.

{kind=link}
Мы храним в кластере данные за последние 30 дней: сейчас это около 12 млрд. событий. В сутки «горячие» ноды записывают на диск 400-500ГБ новых данных с максимальной степенью сжатия (включая данные шардов-реплик). Наш кластер Elasticsearch имеет архитектуру hot/warm, но перешли мы на неё сравнительно недавно, поэтому на «тёплых» нодах пока что хранится меньше данных, чем на «горячих».
Наша типичная нагрузка для рабочего времени:
- индексация – в среднем 13000 rps с пиками до 30000 (без учета индексации в шарды-реплики);
- поиск – 5200 rps.
Мы стараемся поддерживать запас по использованию CPU в 40-50% на горячих нодах Elasticsearch, чтобы без проблем переживать внезапные всплески количества индексируемых событий и тяжелые запросы от Kibana/Grafana или внешних систем мониторинга. Около 50% RAM на хостах с нодами Elasticsearch всегда доступно для page cache и off-heap нужд JVM.
За время, прошедшее с запуска первого кластера, мы успели для себя определить некоторые положительные и отрицательные стороны Elastic Stack как средства агрегации логов и поисково-аналитической платформы.
Что нам особенно нравится в стеке:
- Единая экосистема хорошо интегрированных друг с другом продуктов, в которой есть практически всё необходимое. Beats когда-то были не очень хороши, но сейчас претензий к ним у нас никаких нет.
- Logstash, при всей его монструозности, очень гибкий и мощный препроцессор и позволяет делать с сырыми данными очень многое (а если чего-то не позволяет, всегда можно написать сниппет на Ruby).
- Elasticsearch с плагинами (а с недавних пор и «из коробки») поддерживает SQL в качестве языка запросов, что упрощает его интеграцию с другим софтом и людьми, которым SQL как язык запросов ближе.
- Качественная документация, которая позволяет быстро вводить новых сотрудников на проекте в курс дела. Эксплуатация стека, таким образом, не становится делом одного человека, обладающего каким-то специфическим опытом и «тайными знаниями».
- Отсутствие необходимости заранее знать о структуре получаемых данных многое для начала их сбора: можно начать агрегировать события как есть, а затем, по мере появления понимания, какую полезную информацию можно из них извлечь, менять подход к их обработке, не теряя «обратную совместимость». В стеке для этого есть много удобных инструментов: алиасы полей в индексах, scripted fields и т. д.

{kind=link}
Что нам не нравится:
- Компоненты X-Pack распространяются только по модели подписок и никак иначе: если из Gold, к примеру, только поддержка RBAC или PDF-отчетов, то платить придется за всё, что в Gold есть. Это особенно расстраивает, когда, например, из Platinum нужен только Graph, а в довесок приобрести предлагается Machine Learning и ещё пачку другой функциональности, которая вам, может быть, не очень-то и нужна. Наши попытки около года назад пообщаться с отделом продаж Elastic насчёт лицензирования отдельных компонентов X-Pack ни к чему не привели, но, возможно, с тех пор что-то изменилось.
- Довольно частые релизы, в которых каким-нибудь образом (каждый раз новым) ломают обратную совместимость. Приходится очень внимательно читать чейнжлог и готовиться к обновлениям заранее. Каждый раз нужно выбирать: остаться на старой версии, которая работает стабильно или попробовать обновиться ради новых фич и прироста производительности.
В целом же мы очень довольны нашим выбором, сделанным в 2016 году, и планируем переносить опыт эксплуатации Elastic Stack на другие наши проекты: инструменты, предоставляемые стеком, очень плотно вошли в наш рабочий процесс и отказаться от них сейчас было бы очень сложно.
Комментарии (13)

meforyou
13.11.2018 17:23+2Спасибо за статью. Можете подробнее рассказать про конфигурации нод elasticsearch (jvm.options, elasticsearch.yml, маппинг индексов)?
Сколько у Вас мастер нод, дата нод?
Используете ли Вы координатор?
Какой объем индексации с учетом реплик?
Использовали ли Вы Kibana Canvas?
Ну и с какими проблемами сталкиваетесь :)kirillbuev Автор
13.11.2018 19:09+1В кластере Elasticsearch у нас всего 8 нод: 4 горячих, 4 тёплых.
Горячие ноды одновременно выполняют роль мастеров и координирующих нод, для защиты от split-brain параметрdiscovery.zen.minimum_master_nodes:равен трём. Тёплые ноды имеют только рольdataи не могут становиться мастерами или координировать запросы.
Каждой виртуальной машине с горячей нодой выделено 20 vCPU и 64GB RAM, для тёплых — 8 vCPU, 32GB RAM.
Размер heap у всех горячих нод 31GB, у тёплых — 16GB. Основная часть оставшейся памяти используется под page cache, это хорошо помогает быстрее обслуживать пачки запросов к одним и тем же данным.
Машины c Logstash имеют следующую конфигурацию: 8 vCPU, 24GB RAM.
Тредпулы Elasticsearch настроены так: размер пулов
write(bulkв более старых версиях) иmanagementпо количеству CPU, размерsearchпо количеству CPU x 8. Ну а размеры очередей для пулов были подобраны таким образом: понемногу увеличивали их, пока очереди не перестали переполняться во время пиковой нагрузки и умножили этот размер на два.
Никаких проблем из-за того, что у нас нет выделенных мастер-нод или координаторов, мы не замечали. Вероятно, у нас недостаточный объем данных, чтобы их ощутить.
Кстати об объеме: с учетом репликации (1 реплика на шард) у нас в самые нагруженные периоды рабочего дня (09:00 — 12:00, 14:00 — 16:00) скорость индексации в среднем держится на уровне 25000 событий/сек., с редкими пиками до 60000 событий/сек. Кластер может пропустить через себя в среднем 100000 событий/сек. со 100% нагрузкой.
Прямо сейчас в кластере 751 индекс, 13 463 335 957 документов (без учета реплик) и 11.42TB данных (с учетом реплик).
В шаблонах для индексов у нас ничего особенного нет: маппинги для полей делаем, когда точно знаем, какие в них будут данные, в остальных случаях используем дефолтный маппинг из шаблона, который поставляется с Logstash — строки в поля типа
text, плюс поле.raw с типомkeyword. Данные храним с кодекомbest_compression, структурированный текст из логов хорошо жмётся. Используем токенизатор типаpattern, который разбивает строки на токены по всем символам, кроме[A-Za-z0-9А-Яа-я_\.-]: по понятным причинам дефолтный токенизатор для обычного текста плохо подходит для логов.
Canvas не пробовали, но хотим. Ждем выхода версии, в которой он будет встроен в поставку по умолчанию.
Серьезные проблемы за всё время эксплуатации были связаны в основном с багами в компонентах стека. После перехода на 5.0 обнаружился серьезный баг в Elasticsearch, который приводил к кратковременному выпадению случайных нод из кластера в случайное время. Мы его зарепортили и Elastic очень быстро его починили. После перехода на 6.0 у нас воспроизвелся баг, который приводил к быстрому переполнению management тредпула в определенных условиях. Все точно так же быстро решилось после отправки баг-репорта.
Мы начали с версии 2.2 и я могу сказать, что с тех пор стек очень сильно изменился в лучшую сторону: как с точки зрения стабильности работы, так и с точки зрения функциональности. То есть, ELK времен Elasticsearch 2.2 и Elastic Stack 6.4 это почти два разных продукта.
bravosierrasierra
13.11.2018 19:42Есть ли какой-то компонент в X-Pack, без которого вам бы была не мила жизнь со стеком ELK?
kirillbuev Автор
13.11.2018 20:05+1Чтобы прямо не мила — нет, мы жили без него долгое время и начали им пользоваться только когда он вошел в комплект по умолчанию и для его установки перестал требоваться полный рестарт кластера.
То есть мы его не устанавливали, а просто не стали удалять.
Из всех компонентов X-Pack нам наиболее интересны Security и Graph, если бы их можно было приобрести отдельно, мы были бы весьма рады. Сейчас мы периодически используем kbn_network, но он довольно ограничен по сравнению с Graph. В качестве замены Security используем правила на Nginx (список разрешенных HTTP-методов, запрет доступа к определенным API, индексам и т. д.).
Компоненты Monitoring и Reporting в Kibana (выгрузки в CSV) — приятное дополнение, но их отсутствие не приведет к отказу от стека в целом.
lioncub
14.11.2018 07:56+1nxlog — не плохой продукт. Но, не знаю как сейчас, на linux хосте мог вызвать полное зависание системы из-за переполнении буферов. Именно им собирал, там же обрабатывал с windows и linux логи, отправлял тоже на nxlog и складывал всё в mysql базу.
Появляются ли множество событий в jira при жёсткой перезагрузке сервера? Были таки случаи?kirillbuev Автор
14.11.2018 09:05+1NXLog мы используем только из-за наличия AIXовых машин сейчас.
Продукт неплохой, он производительный и позволяет делать с логами многое на стороне агента, разгружая таким образом препроцессоры.
Но у нас с ним есть одна проблема, которую победить до сих пор не удалось.
У NXLog есть внутренний лимит на длину обрабатываемой строки. Пока он не достигнут — все работает замечательно. Но у нас специфика сервисов, логи которых мы собираем, такая, что в логе внезапно может оказаться строка, скажем, на 50МБ. Или даже 100. Если такая строка встречается, нам нужно ее либо обрезать до вменяемой длины, либо дропнуть. Проблема в том, что для того, чтобы что-то сделать с событием, NXLog всё равно нужно обработать строку и, если она не влезает в его лимит, иногда происходят странные вещи:
- Перестает работать xm_multiline модуль — событие "рассыпается" на отдельные строки.
- В некоторых случаях после получения такой строки NXLog просто перестает обрабатывать записи из лога, но при этом, как правило, не падает (а иногда и падает).
- Иногда получение такой строки приводит к утечке NXLog в память.
С Filebeat, к примеру, такой проблемы никогда не было, там тоже есть (настраиваемый) лимит на максимальный размер события, но большие строки он обрабатывает корректно.
Пока что мы это обходим мониторингом запущенности процессов NXLog и "контролем качества" для логов приложений, чтобы в принципе не допускать попадание таких больших строк туда.
Если кто-то знает, как решить эту проблему с NXLog, мы были бы очень благодарны за наводку, в каком направлении копать.lioncub
14.11.2018 09:36Может попробовать обрезать до лимита: substr()
kirillbuev Автор
14.11.2018 10:33А мы так и делаем:
if size ($raw_event) > N {$message = substr(...);}. Это работает почти во всех случаях, но на очень длинных строках nxlog все равно иногда впадает в кому и приходится перезапускать его сервис. К счастью, сейчас это происходит гораздо реже, чем раньше.
Вот здесь у Filebeat неоспоримое преимущество — с ним об этих вещах не нужно думать вообще: лимит на размер события "просто работает".
kirillbuev Автор
14.11.2018 09:25+1Что касается тасков в JIRA — скрипт, который их заводит, запускается раз в сутки, имеет лимиты и исключения. То есть, если жесткий перезапуск сервера привел к разовому всплеску ошибок, «лишних» тасков не заведется.
К тому же есть у нас еще один механизм, который позволяет сократить количество тасков: для каждой заводимой задачи считается «отпечаток», который представляет собой SHA256 от строки «ячейка-кластер-исключение-класс-метод». Этот хеш записывается в таск и при следующем запуске скрипта при обнаружении ошибок сначала делается поиск по открытым таскам, чтобы определить, нет ли у нас уже задач про них. Если есть — туда просто добавляется комментарий с актуальной диагностической информацией из лога. Таким образом, «автозадачи» в JIRA у нас всегда автоматически актуализируются.
yayashitoya
14.11.2018 08:47ELK стандарт де-факто, да.
Но интересны и альтернативы (не столь жрущие как системы на Java), для менее жирных систем. Бо странно иметь систему сбора логов в разы более ресурсоемкую, чем основной софт.
Внимание, вопрос:
Есть ли какие-нибудь альтернативы ELK, более скромные по затратам ресурсов? Пусть и с меньшим количеством возможностей.kirillbuev Автор
14.11.2018 10:27+1Ну, в нашем случае выделенные под стек ресурсы даже не приближаются к общему объему, выделенному под проект, поэтому для нас такой вопрос был неактуален. Для нас была важна функциональность, отсутствие необходимости платить за объем обрабатываемых данных и наличие большого сообщества у продукта.
Тут еще есть такой момент: если вам в основном нужно собирать метрики или большой объем сильно структурированных данных, то лучше, наверное, посмотреть в сторону чего-то вроде TICK stack от Influxdata или ClickHouse от Yandex. Elasticsearch поддерживает довольно эффективное хранение метрик (колоночное хранилище, поддержка rollup), но это скорее на случай, если вы уже собираете в него логи и рядом с ними есть еще немного метрик, которые тоже хотелось бы снимать и собирать.
Альтернативы для Beats/Logstash есть (fluentd, тот же nxlog, Heka (Hindsight), ...) Но если нужно собирать логи в разном формате из разных источников и с разной структурой, то, как правило, нужен и полнотекстовый поиск по ним, а значит понадобится какой-нибудь поисковый движок. Из популярных это Elasticsearch, Apache Solr (тот же Lucene внутри), Sphinx. Elasticsearch обладает преимуществом: так как Elastic активно продвигает весь стек как универсальное средство для сбора и аналитики событий/метрик, в Elasticsearch активно пилятся фичи, которые его превращают из поискового движка общего назначения в поисково-аналитическую платформу.
azmar
Спасибо за наводку на elastalert, видимо пришло время заменить самописную ruby-простыню на него
Скажите, а какие протоколы используются при передаче логов в logstash (которые не из beats), и как происходит балансировка и гарантированная доставка?
kirillbuev Автор
Да, ElastAlert мы очень рекомендуем, его легко развернуть и у него есть все необходимые виды правил: простое соответствие фильтру, изменение количества событий или значения в определенном поле и т. д. И способов оповещения тоже умеет много, можно обойтись только им самим, если алерты нужно слать в почту или что-нибудь вроде Slack/Gitter/PagerDuty.
Протоколы у нас используются кроме beats такие:
В целом, мы стремимся к тому, чтобы заменить весь этот зоопарк агентами Beats, процесс идет, но не очень быстро. Основной фактор, который удерживает от перехода на Beats полностью — наличие AIX. Компилятор gccgo под AIX с определенной версии собирает агенты Beats и они даже запускаются, но в реализации netpoll есть недостаток, который приводит к высокой утилизации CPU при определенных условиях.