
В начале осени завершился конкурс по написанию ботов Mini AI Cup #3 (aka Mad Cars), в котором участникам необходимо было сражаться на машинках. Участники много спорили о том, что будет работать и что не будет, высказывались и проверялись идеи от простых if’ов до обучения нейросетей, но топовые места заняли ребята с, так называемой, "симуляцией". Давайте попробуем разобраться с тем, что это такое, сравним решения за 1ое, 3е и 4ое места и порассуждаем на тему других возможных решений.
Дисклеймер
Статья была написана в соавторстве с Алексеем Дичковским (Commandos) и Владимиром Киселевым (Valdemar).
Для тех, кому хочется просто почитать про решения победителей, советую сразу начинать с пункта "Симуляция".
Постановка задачи
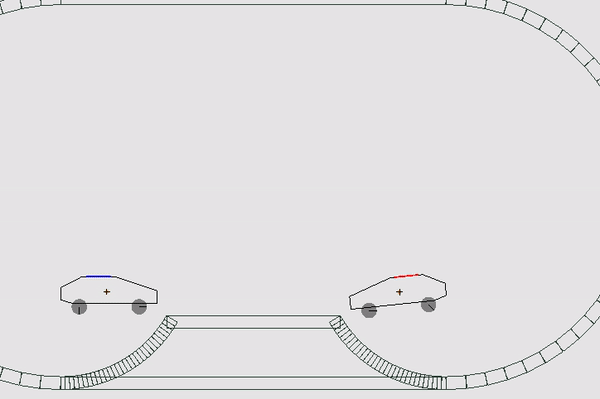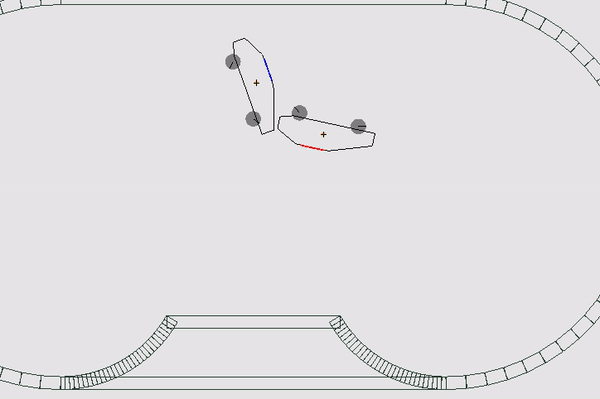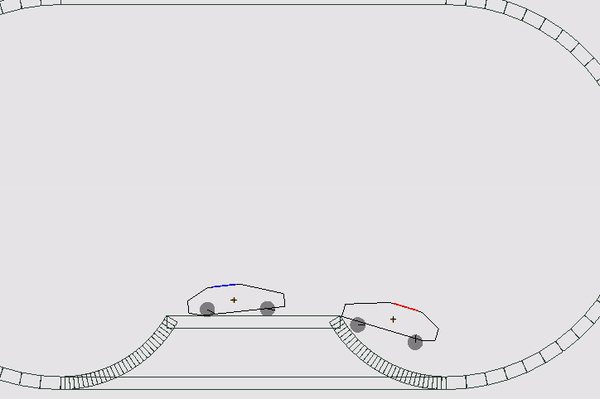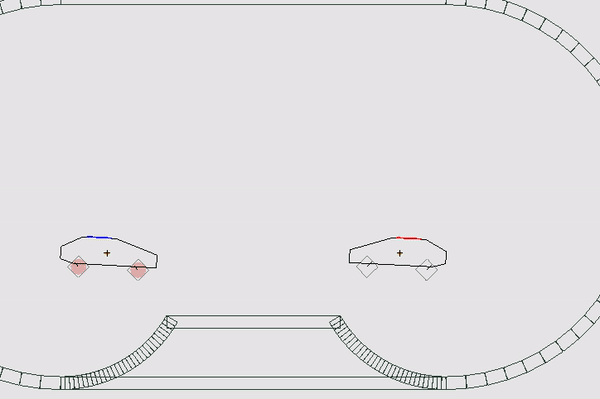
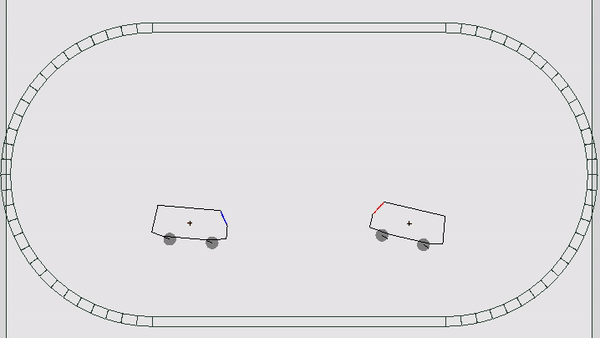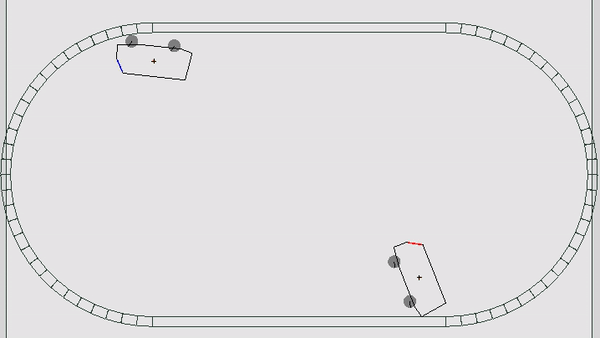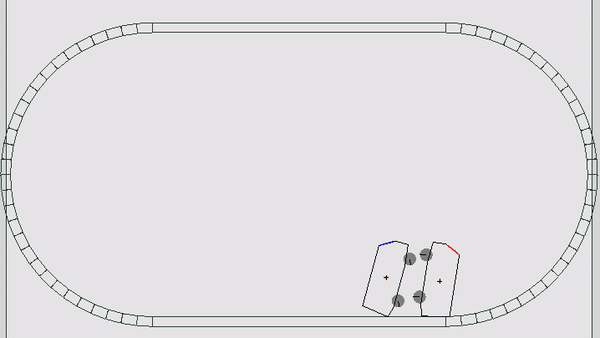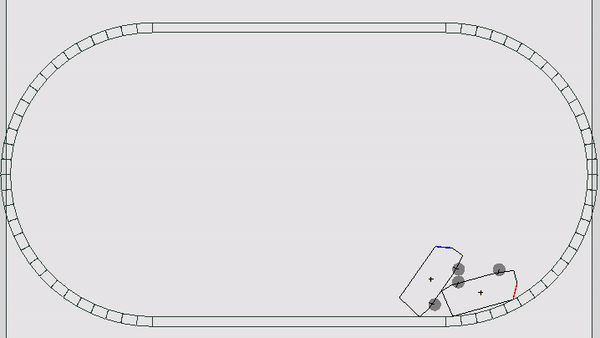
В этот раз механика мира сильно походила на мобильную игру Drive Ahead: игрокам давалась машина с расположенной на ней кнопкой; задача — нажать кнопку врага быстрее, чем это сделает он. Если за 600 игровых тиков никто не побеждает, карта начинает погружаться в кучу мусора, которая также может нажать на кнопку. Другими словами, нужно беречь свою кнопку от врагов, окружающего мира и кучи мусора (жизненно, да). Каждому игроку давалось по 5 жизней, игра шла от 5 до 9 раундов, пока у кого-то не заканчивались жизни. Каждый раунд проходил на случайной карте и машинках, одинаковых для обоих участников. Всего было 6 разных карт и 3 вида автомобилей — итого 18 различных комбинаций.
Каждый раунд разбит на тики. Тик — это один ход, как в шахматах. Разница только в том, что ходят оба игрока одновременно. Бывают соревнования, где все ходят по очереди, либо можно делать действие только раз в несколько ходов и выделять юнитов рамкой.
Каждый тик боту приходит состояние мира и дается возможность совершить 3 действия: ВЛЕВО, СТОП, ВПРАВО. Эти действия заставляют ехать машинку в каком-то из направлений, а если при этом она не касается колесами земли, то и придают небольшое вращение всему кузову (немного аркадной физики). После того, как оба соперника выбрали действие, запускается симуляция игрового мира, считается новое состояние и отсылается игрокам. В случае, если кому-то нажали на кнопку, то раунд завершается и запускается следующий. Все просто, но есть нюансы.
Более полные правила можно найти тут. А игры финала посмотреть тут.
Общее описание решения
Большинство соревнований по написанию ботов очень похожи: есть конечное число тиков (тут для одного раунда примерно 1500 максимум), есть конечное число возможных действий, нужно выбирать такую последовательность действий, чтобы быть лучше, чем твои противники. Чуть позже еще вернемся к тому, что значит "быть лучше", а пока разберемся с тем, как бороться с главной проблемой — огромным количеством вариантов действий: на старте у нас есть одно начальное состояние, затем каждая машинка может двигаться тремя разными способами, что дает нам 9 разных комбинаций для двух машинок, к 1500 ходу это будет уже 9^1500 различных комбинаций… Что чуть больше, чем хотелось бы, если мы планируем успеть перебрать их за время существования Вселенной.
Тут мы и подошли к тому, что такое симуляция. Это не какой-то алгоритм, а просто воссоздание правил игры с достаточной или полной точностью, чтобы можно было перебирать решения. Разумеется, мы будем перебирать не все решения, а только часть из них. Для этого будет использоваться алгоритм поиска — в дереве состояний игры мы ищем наилучшее для нас. Алгоритмов достаточно много (от минимакса до MCTS), каждый имеет свои нюансы. Лучше всего ознакомиться с тем, какие решения писали участники прошлых соревнований по ИИ. Это даст базовое понимание, в каких условиях алгоритмы работают, а в каких не очень. Много ссылочек для этого есть в специальном репозитории.
При выборе алгоритма следует учитывать:
- ограничение времени на 1 тик (тут я сильно просчитался в этом году, но смог остаться на 3м месте);
- количество игроков. Например, если игроков трое, то будет сложно использовать минимакс;
- точность симуляции, т.к. это может позволить переиспользовать старые вычисления;
- "ветвистость" дерева состояний (можно ли просчитать все возможные состояния хотя бы на 10 ходов вперед);
- здравый смысл — не стоит начинать писать MCTS, если соревнование длится 4 часа.
В данном соревновании на 1 тик давалось около 10-13мс (2 минуты на всю игру). За это время бот должен был считать данные, принять решение и отправить команду для движения. Этого хватало, чтобы просимулировать порядка 500-1000 ходов. Перебирать все состояния не получится. Самый простой алгоритм поиска может выглядеть как сравнение трех вариантов движения: "50 тиков едем влево", "50 тиков едем вправо", "50 тиков жмем стоп". И как бы просто это не звучало, это не сильно далеко от решения победителя.
Т.к. мы считаем только на 50 ходов вперед, что в большинстве случаев не досчитывает до конца игры, то нам нужна функция оценки, которая скажет, насколько хорошо и плохо состояние мира для нас. Чаще всего она построена на эвристиках и понимании, что важно для победы. Например, в конкурсе Russian AI Cup 2014 года были гоночки, но победить можно было и приехав последним, если набрать больше бонусных очков. Значит и функция оценки должна стимулировать сбор очков одновременно с быстрым движением по трассе. Оценка может быть посчитана только для последнего состояния симуляции (через 50 тиков) или как сумма оценок промежуточных состояний. Часто оценка "затухает" по времени, чтобы больше влияли состояния, которые произойдут раньше. Т.к. мы не можем наверняка предсказать врага, то и будущие варианты имеют меньшую вероятность случиться, не будем на них сильно полагаться. Также этот прием заставляет бота быстрее выполнять поставленные задачи, а не откладывать все на потом. Но стоит отметить и то, что бот будет меньше рисковать ради последующей выгоды.
Раз уж мы собрались предсказывать состояния мира в ответ на наши действия, то нам надо как-то моделировать поведение врагов. Тут нет ничего сложного и существуют пара распространённых вариантов:
- Заглушка или эвристика
Пишется простая логика поведения, где враг просто ничего не делает, либо выбирает действия на основе простых эвристик (например, можно использовать свои первые версии стратегии или просто повторять предыдущий ход соперника). - Использовать такой же алгоритм как для себя
Сначала пытаемся найти для врага лучшие действия (против своего лучшего набора действий с прошлого хода, либо против заглушки), а потом ищем лучшее действие уже для себя, используя поведение, которое нашли врагу. Тут бот будет пытаться противостоять хитрым врагам. Такая логика плохо работает на старте соревнования, т.к. многие боты еще весьма слабы, а ваше решение будет излишне осторожничать с ними. - Другое
Тот же минимакс перебирает все ходы игроков одновременно, и эвристики ему просто не понадобятся.
Если реализовать все вышеописанные шаги, то, скорее всего, получится весьма неплохой бот, особенно если удастся подобрать хорошую функцию оценки. Но, просматривая свои бои, можно заметить, что в определенных ситуациях он ведет себя странно. Исправить функцию оценки под эти ситуации может быть сложно, либо велик риск сломать другую логику. Тут на помощь приходят костыли и if'ы. Да, последние дни соревнования часто сводятся к написанию костылей и if’ов, чтобы исправить недочеты в каких-то конкретных условиях. Лично я очень не люблю эту часть, но уже не раз замечал, что именно костыли в финале могут влиять на расположение мест в первой десятке, а значит один ненаписанный if может стоить вам призового места (мое сердечко болит, когда я пишу эти слова, я тоже люблю красивые алгоритмы и решения).
Q: Можно ли обойтись совсем без симуляции?
A: Да, можно использовать решения на эвристиках (деревья принятия решений, куча if'ов и т.п.). Есть хорошая статья с архитектурами ИИ на эвристиках.
Q: Насколько использование симуляции лучше подходов на эвристиках?
A: Все зависит от задачи. Например, тут некоторые сочетания карт и машин можно было жестко закодировать if'ами и всегда побеждать (или ничья). Однако часто симуляция находит решения, до которых сложно додуматься самому, либо сложно реализовать эвристиками. В данном конкурсе, когда ты переворачиваешь другую машинку, то решения на симуляциях ставили свое колесо на колесо врага, что отключало флаг "в воздухе", а значит враг не мог применять вращение кузова и повернуться обратно на колеса. Но решение не задумывалось о смысле этого, оно просто находило варианты, где враг быстрее упадет на крышу и нажмет свою кнопку.

Q: Нейронные сети и RL?
A: Как бы это не было популярно, в соревнованиях ботов такие решения редко показывают себя хорошо. Хоть нейросети и не нуждаются в симуляции, т.к. могут просто выдавать действие исходя из входных параметров текущего состояния, им все еще нужно как-то обучаться, а для этого часто приходится писать симулятор, чтобы гонять игры тысячами локально. Лично я верю, что у них есть потенциал. Быть может ими можно решать часть задачи, либо использовать в условиях очень ограниченного времени на ответ.
Примечание
По поводу конечного числа возможных действий стоит уточнить, что иногда разрешено "плавно" регулировать какой-то параметр. Например, не просто ехать вперед, а каким-то процентом мощности. В этом случае "конечности" числа выводов легко добиться просто используя несколько значений, например, 0%, 25%, 50%, 75% и 100%. Чаще всего хватает всего двух: "полностью включено" и "полностью выключено".
Симуляция
В данном соревновании использовали готовый движок chipmunk physics. Ожидания организаторов были в том, что он старый, проверенный временем и имеет много врапперов, чтобы каждый мог включить его в свое решение...
В суровой действительности движок выдавал каждый раз разные значения, что делало проблематичным его перезапуск для просчета вариантов ходов. Проблема решалась “в лоб” — писался свой аллокатор памяти на С и целиком копировался кусок памяти с состоянием мира. Такой аллокатор ставил крест на возможности писать решения на языках кроме С++ (на самом деле это было возможно, но очень трудозатратно и аллокатор все равно пришлось бы писать на С). Кроме того, на точность предсказания влиял порядок добавления элементов в игровой мир, что требовало очень точного копирования кода, который использовали организаторы для просчета игр. А вот он уже был на Python. Последним гвоздем в крышку гроба других языков программирования стало то, что движок старый и содержит много оптимизаций, которые невозможно точно воссоздать за время соревнования, чтобы получить свою урезанную версию симуляции физики.
В итоге, движок, который должен был дать всем участникам равные условия для симуляции ходов, стал самой сложной преградой для этого. Преодолеть ее смогли человек 10. Первые 7 мест лидерборда заняли исключительно ребята, сделавшие точную симуляцию, что может служить неким доказательством ее важности в таких конкурсах.
За исключением пары участников, которые смогли залезть во внутренности chipmunk’а и оптимизировать копирование его состояния, остальные имели примерно равную по производительности симуляцию (что делало соревнование немного более интересным, т.к. ты знаешь, что борьба идет за алгоритм решения, а не "кто больше просчитает ходов").
Алгоритм поиска и предсказание противника
С этого пункта начинается раздельное описание решений. Описание алгоритмов будет вестись от лица его автора.
Владимир Киселев (Valdemar) 4 место
Для поиска по пространству решений был использован случайный поиск (Monte Carlo). Алгоритм выглядит следующим образом:
- Инициализируем геном — последовательность действий (влево, вправо, стоп) на 60 тиков — случайными данными.
- Берем лучший найденный геном
- Случайным образом меняем одно из действий
- При помощи функции оценки получаем число — показатель того, насколько хорош новый геном
- Если получилось более удачное решение, то обновляем лучшее решение
- Повторяем заново с п.2
Мой симулятор выдавал ~100k симуляций мира за 1 секунду, учитывая что на тик есть в среднем ~12мс, получаем 1200 действий на тик. То есть за 1 тик успеваем пройти полный цикл около 20ти раз.
Для поиска оптимального решения такого количества итераций явно не хватало. Поэтому была реализована идея с “растягиванием” действий: вместо генома из 60 ходов будем оперировать цепочкой из 12 “растянутых” ходов — считаем, что каждое действие длится 5 тиков подряд.
Плюс: Повышение качества мутаций за счет уменьшения длины генома, также симуляция может быть запущена раз в 5 тиков и проверить 100 геномов вместо 20ти (для избежания падений по лимиту времени, в итоге остановился на 70).
Минус: растягивание действий может приводить к не оптимальным решениям (например качание на бампере, вместо стабильной стойки)
Следует отметить приемы, которые позволили значительно улучшить качество работы алгоритма:
- Случайную инициализацию проводим только на первом тике, все остальное время переиспользуем лучшее найденное решение со сдвигом на 1 ход (действие на 2й тик смещается на 1й и т.д., в конец добавляется случайное действие). Это значительно улучшает качество поиска, поскольку иначе алгоритм "забывает", что собирался делать на прошлом тике и бессмысленно дергается в разные стороны.
- В начале хода делаем более интенсивные изменения (меняем геном 2 или 3 раза вместо одного) в надежде выйти из локального максимума (подобие температуры в методе имитации отжига).
Интенсивность была подобрана вручную: первые 30 итераций делаем 3 мутации, следующие 10 по 2, потом по 1. - Очень важное значение имеет предсказание действий противника. В ущерб времени на поиск собственного решения запускаем случайный поиск со стороны противника, на 20 итераций, потом 50 для себя, используя информацию об оптимальных ходах противника.
Лучшее решение противника также переиспользуется на следующем ходу со смещением. При этом во время поиска решения врага, в качестве моих предполагаемых действий используется геном с прошлого хода.
Во время конкурса активно использовал инструменты для локальной разработки, которые позволили быстро находить баги и сосредоточиться на слабых местах стратегии:
- локальная арена — запуск множества матчей против предыдущей версии;
- визуализатор для дебага поведения;
- скрипт для сбора статистики по матчам с сайта — позволяет понять на каких картах и машинах чаще всего происходят поражения.
mortido:
Считать раз в 5 тиков выглядит рискованно, особенно, если противник сильно отходит от предсказанных тобою вариантов. С другой стороны, в данном игровом мире за 5 тиков не так много и происходило.
Также в своем решении я, все-таки, добавлял случайные комбинации каждый тик, но точно не скажу как это сказалось на решении.
Commandos:
Менять по пару действий при таком кол-ве симуляций выглядит не очень осмысленно, ведь за одно действие изменений происходит очень мало. А вот при растягивании одного действия на 5 тиков смысла, кажется, становится больше.
Ещё мне не нравится сама идея — берём лучший набор и пытаемся править где-то у него в начале. Мне кажется нелогичным, что изменение первых тиков оставят последующие хотя бы относительно адекватными.
Александр Киселев (mortido) 3 место
Вооружившись статьями победителей других конкурсов я решил использовать генетический алгоритм. Получилось, правда, что-то похожее на случайный поиск или даже имитацию отжига, но об этом чуть позже.
Закодируем решение массивом из 40 чисел, где -1, 0 и 1 соответствуют движению ВЛЕВО, СТОП и ВПРАВО.
Вначале каждого раунда я считал сколько времени я уже потратил за всю игру, считал новый лимит времени исходя из того, сколько максимально еще будет раундов, а каждый раунд я полагал длительностью 1200 тиков. Т.о. изначально я старался тратить не больше 11мс на ход, но мог немного "разгуляться" под конец, если предыдущие раунды были быстрее 1200 тиков.
Valdemar:
Интересно, что у меня эта фишка ухудшила игру. Оказалось, что лучше всегда тратить 20-30мс, чем сначала 11, а под конец 60
Треть этого времени я искал лучший ход противника, остальное уходило на расчет собственного решения. При поиске хода для врага мое поведение моделировалось как лучшее с прошлого хода, сдвинутое на 1 тик. Т.е. как будто я продолжаю действовать согласно плану, составленному в прошлый тик, а он пытается мне противостоять.
Сам поиск решения был одинаковый и для себя и для соперника:
- Берем решение с прошлого хода и сдвигаем на 1 ход (который мы уже сделали)
- Докидываем в популяцию случайных решений, пока не заполним ее всю
- Симулируем все решения и выставляем фитнесс с помощью функции оценки. Лучшее запоминаем.
- Пока есть время для расчетов
- Хинт, всегда добавлять в популяцию 1 мутацию текущего лучшего решения, запомнить его, если оно лучше
- Пока есть место в новой популяции и не превышено время для расчетов (можно выйти на полу заполненной популяции)
- Берем двух разных особей и оставляем с лучшим фитнесом — мама
- Берем двух разных особей и оставляем с лучшим фитнесом — папа (не должен совпадать с мамой)
- Скрещиваем их
- Мутируем, если
RND < Вероятность Мутации - Симулируем решение и запоминаем его, если оно лучшее
В результате нам вернется последовательность действий, которая считается оптимальной. Первый ход в ней и отправляется как действие бота. К сожалению, в моем плане был серьезный недостаток, т.к. количество симуляций, которые можно сделать за тик, было очень небольшое (в т.ч. и из-за долгой оценочной функции), то на сервере соревнования 4 пункт выполнялся всего 1 раз, а для врага и вовсе не выполнялся полностью. Это делало алгоритм больше похожим на случайный поиск или имитацию отжига (т.к. мы успевали мутировать 1 раз решение с прошлого хода). Менять что-то было уже поздно, да и 3е место удержать удалось.
Важным является реализация алгоритмов скрещивания, мутации и генерации начальных случайных решений, т.к. от этого зависит то, какие решения будут проверятся, а полный рандом не так хорош, как может показаться на первый взгляд (он будет работать, но потребуется гораздо больше вариантов перебрать).
В итоговой версии генерация случайных решений происходила отрезками, что исключало "дрыгающиеся" на одном месте решения:
- Выбиралась случайная команда
- Для всей длины решения (40 ходов)
- Записываем текущую команду в ячейку
- С вероятностью 10% меняем текущую команду на случайную
По похожей технологии происходила и мутация — случайный отрезок решения заменялся на случайную команду. Скрещивание же происходило выбором точки, до которой бралось решение от 1 родителя, а после от 2-го.
Мне понравилось, что мы используем все доступное нам время, для поиска лучшего решения. При этом не страшно, если решение не самое лучшее — мы сможем улучшить его на следующем тике, т.к. оптимизация получается "размазанной" по времени. Также мы всегда пытаемся предугадать, как враг нам испортит жизнь и противостоять этому. Разумеется факт, что часть задумки не работала из-за лимита времени, сильно портит радужную картину. Сейчас я бы не стал реализовывать эту идею в таких условиях, а склонился бы к варианту случайного поиска или имитации отжига
Valdemar:
Генетика из 1го поколения больше напоминает случайный поиск, думаю, применение твоих методов рандомизации без скрещивания повысило бы производительность и выдало лучший результат.
Commandos:
Про ограничение времени — с нашим кол-вом симуляций я про генетику даже не задумывался бы.
И мне всё же очень не нравится цикличность — выбрали лучшее для врага, затем выбрали лучшее для себя. Кажется на следующем ходу от врага будут найдены контрмеры, как и контрмеры на контрмеры… Но это актуально только в случае, если у нас много больше времени для рассчётов. Можем случайно получить "дрыгающиеся на одном месте решения”. Хотя в нашем случае хорошо было найти хоть что-то.
Алексей Дичковский (Commandos) 1 место
Для себя я перебирал всего два действия (двухуровневое дерево перебора), которые повторялись n и m тиков соответственно. То есть всего 3^2=9 комбинаций. В общей сложности глубина просчета была m + n и в финальной версии равнялась 40 тикам.
Пример решения:
|----------- n раз -----------|---------- m раз --------|
| ВЛЕВО ВЛЕВО ... ВЛЕВО ВЛЕВО | СТОП СТОП ... СТОП СТОП |Для каждой ветки своих действий симулировал три варианта действия соперника: соперник либо всегда едет вправо, либо влево, либо стоит. Выбирал худший для себя исход (по аналогии с минимаксом).
Также была сделана коллекция из сочетаний n и m, и для каждого следующего хода бралась следующая пара из коллекции. Благодаря этому каждый ход искались новые варианты, что давало большой буст стратегии.
Алгоритм на каждом шаге игры работал следующим образом:
- Получаем оценку для набора действий, который был найден на предыдущем тике (на самом первом шаге раунда это минус бесконечность, без дополнительных проверок):
- Берём набор действий, признанный лучшим на предыдущем шаге, убираем первый тик, который прошёл с того момента.
- Для простоты сравнения оценок нужно сделать так, чтобы длина совпадала с длиной решений, которые будем перебирать. Для этого необходимо добавить один тик в цепочку моих действий справа. Я решил вместо простого добавления одного тика перебрать все варианты моих действий для последних двух тиков. После данного этапа набор действий выглядел как выбранный лучший на предыдущем тике, у которого отброшены первый и последний ходы, а в конец добавлено два новых, которые были получены полным перебором.
- Данный набор действий оценивался по трём вариантам поведения противника. Худшая оценка запоминалась; по итогам оценки варианты поведения противника сортировались (в будущем в дереве в первую очередь проверялся худший для нас вариант).
- Строим дерево проверок по следующему значению n и m из коллекции. Проверка действий соперника проходит в порядке, полученном в конце п.1, от худшего к лучшему для меня, в листе запоминается минимум из оценок для этого набора действий. Если этот минимум на каком-то этапе (чаще всего после первой проверки) оказывается меньше, чем худшая оценка для базового набора действий — текущий набор действий точно не может быть лучшим, последующие симуляции с ним не проводятся;
- После всех симуляций смотрим на максимальное значение функции оценки в листьях дерева поиска. Если оно больше, чем оценка базового набора — заменяем базовый набор на новый найденный. Чаще всего оставался тот, который был найден на предыдущем шаге (и незначительно улучшен дополнительным перебором последних двух тиков).
Valdemar:
Удивлен, что перебор возможных направлений с глубиной 2 дал такой хороший результат. Видимо дьявол в деталях. Идея с лесом деревьев с разными параметрами очень интересная, похожего раньше не встречал.
mortido:
Здорово! Перебираются разные варианты, выглядит как хорошее распределение времени на вычисления. Выглядит простым в реализации. Не уверен, что глубины 2 хватит в других соревнованиях, где за 40-60 тиков можно выполнить более сложный план действий. Также нравится, что для каждого своего хода проверяется до 3х разных ходов противника.
n + m == const ?
В итоге да. Когда n + m != const, то даже аккуратно нормированная по количеству ходов оценка ни к чему хорошему не приводила. При опасности бот выбирал дерево покороче, что логично. И из-за этого получалось хуже.
Функция оценки
Владимир Киселев (Valdemar) 4 место
Сразу стоит сказать, что в моей оценочной активно использовалась нормализация. Значения, получаемые от симулятора (угол наклона машины, скорость, расстояние и т.д.) переводились в диапазон [0..1].
Это позволило удобно компоновать различные показатели и добиться тонкой настройки поведения. Например были реализованы сценарии типа: старайся ехать побыстрее, но только если угол наклона не слишком большой.
Не берусь судить насколько эта фишка повлияла на успех стратегии в целом, но точно можно сказать, что она помогла во время отладки: в лог выводились составные слагаемые оценочной, что позволяло быстро понять почему бот ведет себя определенным образом.
Итак, в оценочной учитывались:
- угол наклона машины — нормализовался диапазон от 70 до 180 градусов (здесь и далее: значения не входящие в диапазон обрезаются до соответствующей границы).
Для обычной багги также давался дополнительный бонус, если враг наклонен и находится в воздухе. - расстояния между центрами машин в диапазоне 0..500
- угловая скорость — диапазон [2pi, pi/4] отображался в [0, 1]
- близость к кнопке — по формуле учитывается расстояние, угол между точкой и центром кнопки (чтобы поощрять нацеливание в центр), угол машины (бонус не дается, если мы приближаемся со стороны днища, потому что оттуда кнопку все равно не нажать)
- определение тарана — случай, когда мы едем в сторону противника, он повернут к нам днищем, и наш капот нацелен на точку чуть ниже его переднего колеса.
Бонус особенно хорош для обычных багги, позволяет определять, когда мы можем с разгона перевернуть противника. - скорость — до определенной степени поощряем движение. Позволяет не стоять на месте и в целом играть активнее.
- разность между минимальной по Y координатой кнопок — актуально при приближении дедлайна.
- большой штраф если мы проиграли и большой бонус за победу
Угол наклона, близость к кнопке и таран считались 2 раза для меня и противника и давали либо бонус либо штраф, соответственно.
Все составляющие умножались на различные коэффициенты в зависимости от типа машины.
В случае обычной багги пара карт были учтены вручную:
- на “острове” разрешался только разгон в сторону противника, иначе велика вероятность упасть с платформы
- на “острове с ямой” давался огромный бонус за нахождение на стартовой площадке, поскольку статистика показала, что спуск в яму часто приводит к поражениям.
mortido:
Быстрее чем у меня, т.к. я делал много запросов к движку, а они оказались очень медленными.
Commandos:
В целом суть похожа на мою, разница в деталях и количестве костылей. Возможно местами в чём-то лучше
Александр Киселев (mortido) 3 место
Большую часть параметров для оценочной функции я брал, используя запросы к физическому движку chipmunk. Эти запросы позволяли находить разные расстояния до ближайших объектов или пересечения объекта и луча. Хотя движок и оптимизировал их, используя свои внутренние структуры и кэши, большое количество обращений к нему, в конечном счете, сильно затормозило симуляцию. Многие компоненты оценочной функции пришлось исключить перед финалом.
Изначально я делал одну оценочную функцию и только после написания скрипта для сбора статистики боёв я разделил ее на 3 части и наговнокодил добавил несколько фиксов.
Вот часть компонентов, которые я смог вспомнить на данный момент (не думаю, что точное указание принципиально важно, главное основная идея):
- штраф за смерть. Он самый большой и после нее симуляция дальше не идет, просто считается, что мы умираем в каждом последующем тике (так бот будет стараться отложить смерть на потом, чтобы суммарный штраф был меньше);
- бонус за убийство врага, симуляция продолжается дальше — это помогает с промахами по кнопке врага, когда неправильно предсказано его движение; основная причина таких промахов в том, что мы используем только 1 поведение врага;
- бонус за скорость;
- разность высот нижних точек кнопки (чем ближе к дедлайну матча, тем сильнее);
- расстояние от кнопки до любого препятствия (мне со знаком “+”, противнику со знаком “-”);
-расстояние от кнопки до противника (мне со знаком “+”, противнику со знаком “-”); немного спорный параметр, он позволял позиционировать машину так, чтобы свою кнопку держать в безопасности, но это часто ставило машину на дыбы и ее переворачивали;
лучи под 30 градусов от плоскости кнопки, чтобы смотреть расстояние по ним до карты, это немного помогало не переворачиваться (но это не точно); - остальные хаки, в основном для защиты от переворотов и правильного позиционирования.
Стоит отметить, что при сложении компонент одни затухали по времени, а другие имели больший коэффициент ближе к концу (например, выгоднее оказаться выше в последний тик и слегка спуститься для разгона сейчас, чем жадно подниматься в текущем)
Valdemar:
Идея давать больший коэффициент ближе к концу достаточно зыбкая. Можно попасть в ситуацию, когда бот будет думать “сейчас я постою, но через тик начну разгоняться, чтобы получить побольше бонус” и так несколько тиков подряд, пока внезапно не изменится обстановка (противник сделал непредсказуемый ход и т.д.) и ситуация станет сильно хуже.
Такое было, он до последнего стоял, чтобы прямо на волоске от смерти начать взлетать. С этим были сложности.
Commandos:
Не очень понятно, зачем продолжать симуляцию, если враг “умер”… Возможно это костыль для автобусного дедлайна? Идею про повышение бонуса за высоту машинки под конец симуляции можно было бы попробовать, может и “взлетела” бы.
Алексей Дичковский (Commandos) 1 место
Основная функция оценки делалась под SquaredWheelsBuggy, как под самую интересную с т.з. игры машинку, с которой могут происходит самые разные ситуации. Оценочная функция для простого Buggy отличалась только тем, что в неё был добавлен бонус за касание колеса соперника, чтобы противник не мог влиять на свою угловую скорость (и часто в такой ситуации просто беспомощно падал на крышу/кнопку).
Кратко:
- штраф за смерть;
- штраф за угол относительно земли; если мы имеем большую скорость и движемся вверх — коэффициент, с которым работал этот штраф, менялся от 1 до 0; т.о. при быстром наборе высоты угол машинки не учитывался;
- штраф за угол относительно соперника. Не очень то хотелось находиться кнопкой к сопернику; также этот угол считался со сдвигом положения соперника на 10 тиков вперёд при текущих скоростях (поэтому машинка чуть раньше заканчивала задавать бесполезный угол в надежде защититься от соперника);
- штраф за близость колёс и некоторых контрольных точек соперника до моей кнопки (своя оптимизированная реализация без запросов к движку игру, не учитывала квадратность колёс);
- бонус за скорость машинки (считал, что лучше побегать по карте в надежде на ошибку соперника);
- небольшой штраф за расстояние до соперника — чуть-чуть чаще двигались к сопернику, чем от него;
- штраф/бонус за разницу высот с соперником; в основном точкой отсчёта считался центр масс, для автобуса в более новой реализации — нижняя точка кнопки; новая реализация оценочной для автобуса отличалась слабо и играла не на всех картах.
Пункты 1-5 считались зеркально для меня и соперника, с разным знаком. В пункте 2 для соперника не учитывался “коэффициент набора высоты”.
Valdemar:
Думаю до этого дошли многие, кто хотя бы пару дней посидел над оценочной. Вся магия в алгоритме поиска и коэффициентах, с которыми суммируются все эти пункты.
mortido:
Интересная идея с углом к противнику, учитывая его положение через 10 тиков.
Костыли и IF'ы
Владимир Киселев (Valdemar) 4 место
Периодический сбор статистики по матчам показал, что определенные карты на автобусах и багги всегда проигрываются стратегиям на if’ах. Внимание на это я стал обращать примерно за 3 дня до начала финала, к тому моменту идеи для улучшения оценочной уже закончились, а близость призового места не позволяла опустить руки и идти отдыхать. Поэтому, рядом с алгоритмом случайного поиска были добавлены эвристики, которые брали на себя контроль в определенных комбинациях машина-карта.
Важный момент: в начале каждого тика производилась проверка, которая говорила насколько “безопасно” включать эвристику — если противник быстро к нам приближается, или делает что-то непонятное, или по неизвестным причинам наша машина оказалась в неожиданном положении (например летит вниз, хотя должна стоять) — управление берет симуляция.
На откуп ифам были отданы:
- Стойка на бампере для автобуса. Поскольку растягивание действий давало небольшие раскачивания, которые иногда приводили к поражению от линии дедлайна.
- Движение в стойке для автобуса — актуально для карты с ямой, путем колебаний с разной амплитудой можно было ездить на бампере и как минимум гарантировать ничью на этой карте.
- Хардкод начальных тиков. Актуально для багги на карте “остров с ямой” и для автобуса на большинстве карт.
При помощи визуализатора были вычислены действия, которые позволяли стратегиям на ифах занимать оптимальное положение, после чего эти действия были бессовестно скопированы к себе.
Такой подход является хрупким и работает только если противник не будет к нам приближаться и толкать, но на этот случай включалась симуляция, поэтому в сумме работало достаточно хорошо.
Во время работы эвристик большую помощь оказал симулятор, который предоставлял дополнительную информацию: скорость движения и угловую скорость. После конкурса выяснилось, что там где я использовал эти данные, участники на if’ах использовали тригонометрию и хитрые вычисления.
mortido:
Потиковый хардкод меня сильно огорчил, когда я первый раз об этом узнал. Сейчас эта идея не кажется такой уж и плохой в данном соревновании.
Commandos:
Суровая реальность if’ов. Заткнуть дыры там, где льётся от решения, покрывающего большую часть ситуаций… Я всё же больше старался положить скрипты на оценочную функцию, но это занимало порядком времени, а результат был местами странный.
Александр Киселев (mortido) 3 место
Это писалось с большой болью в сердце и попытками всячески замаскировать костыли под какую-нибудь логику.
Первым делом были разделены 3 оценочные функции. Каждая для своей машинки. Две из них были практически одинаковыми и отличались коэффициентами. Для “Буханки”, которой выгоднее было не сражаться и просто забраться повыше и стоять в оборонительной позе была написана своя функция. Туда шли даже потенциальные поля для пары карт, которые позволяли ей заезжать на высоту, либо запрыгивать на холмик.
Я не использовал жесткий хардкод ходов по тикам для карт, где можно было скопировать “лучшее” решение у других. Я лил эту пакость в оценочную функцию. Где в зависимости от карты, машинки и тика могли стоять немного разные задачи, например, минимизировать расстояние переднего колес до какой-то конкретной точки. А дальше генетический алгоритм пытался решить эту задачу. Работало это гораздо хуже хардкода, а настраивать и дебажить было практически невозможно, т.к. рандом вносил много проблем.
В спорах после соревнования, где я очень ругал захардкоженные тики, я высказывал, что мог смириться с ними, если бы эти тики были найдены локально тем же алгоритмом поиска, только с огромным запасом времени на вычисление. После я проверил этот вариант… Генетический алгоритм не смог найти даже близко хорошие ходы. В общем если что-то можно сделать просто и это работает — надо делать, принципиальность зачастую только мешает (но я и за здоровую долю любопытства, чтобы проверить и другие варианты).
Valdemar:
Про потенциальные поля интересно, даже не думал их использовать. Идея добавлять аналог потикового хардкода в поиск видится совсем неправильной. Если мы говорим про принципиальность и эстетическую “красоту” решения, то такой подход еще хуже явных if’ов. А то, что генетический алгоритм не смог найти хорошие ходы совсем неудивительно — на поиск этих ходов участники с эвристиками потратили несколько дней или даже недель.
Думаю можно было еще собирать ходы противника из реплеев игр, где ты проиграл и добавлять их + их мутации в качестве стартовой популяции. Правда, звучит как много потраченного времени и кода.
Commandos:
В данном случае… Если хочешь, чтобы что-то было сделано — сделай это сам, а не проси оценочную сделать так, как ты хочешь. Хотя я тоже много времени убил на то, чтобы сделать желаемое через оценочную, но по итогу она была не очень осмысленной и потиковый хардкод был бы проще и надёжней.
Алексей Дичковский (Commandos) 1 место
Хардкодить я начал за две недели до конца соревнований. И хардкода набралось огромное количество (больше, чем в любом другом соревновании, что я писал ранее). В основном весь хардкод был в подборе коэффициентов (и добавочных компонентов) для сочетаний карта/машинка.
Например на карте pill carcass map для обоих багги сильно возрастал бонус за скорость, если я нахожусь снизу при надвигающемся дедлайне, а также дополнительно начислял очки за нахождение поближе к центру верхней перекладины (как и бонус за сталкивание подальше от центра перекладины соперника). Очень похожий бонус был на island map, где от нас только и требовалось, что перевернуть или столкнуть противника.
Также из хорошо отработавших хардкодов была езда на заднем бампере на карте island hole для buggy. Для этого сочетания машинки/карты обычная функция оценки отключалась до момента, пока моя стратегия не решит, что соперник пошёл в атаку (находится слишком близко). Если же такая ситуация имела место — включалась стандартная функция оценки. Также похожая, и тоже не идеальная имплементация была на той же карте, но уже для автобуса. А для SquaredWheelBuggy на этой карте был предусмотрен штраф за слишком высокую скорость вверх. Иногда физика срабатывала так, что багги просто улетал в космос, функция оценки это находила и считала, что так будет лучше. Скорость большая, мы выше соперника… А вот до момента, когда мы в любом случае умрём, досчитать не хватало дальности симуляции.
На одной карте (Pill map, Bus) старт вообще был сделан потиковым хардкодом и не показывался до самого последнего дня соревнования во избежание копирования, которое было нетрудно сделать в этом соревновании (по итогу на таком сочетании карты/машинки имею 100% побед).
Также для автобуса была очень удачно заскриптована карта pill hubble map. Скрипт мог отрабатывать как корректно, так и не очень (во всех примерах первый раунд), но мне он очень нравился. Ну и статистика говорит в его пользу.
Для тех же автобусов по итогу было две разных оценочных функций на разных картах — было лень тестировать на всех и тестировал только там, где требовались исправления...
Описанные моменты не охватывают всю ширину костылизации, но позволяют понять её глубину. Но в основном это всё же замена весов у разных частей оценочной функции и добавления компонентов, зависящих от определённой карты. Благо поддержка таких костылей была заложена в архитектуру изначально (хотя и немного подправлялась по факту).
Valdemar:
Специфика игры такова, что хардкод действий на некоторых картах позволяет играть идеально — как минимум добиться ничьи при помощи пары условий. Хардкод выглядит ужасно, но при этом невероятно эффективен.
mortido:
Хорошо залатал дыры в стратегии, пока я пытался написать “идеальную” оценочную функцию.
Эмоции
Valdemar:
Начало контеста было довольно скучным. Создание симулятора требовало много усилий и опытные участники начинали высказывать мнения, что ничего интересного мы не увидим. Затем начались вечера (и даже немного ночи) постоянных доработок и стало гораздо веселее.
Я участвую в таких соревнованиях ради эмоций и удовольствия от общения в кругу таких же любителей игрового ИИ. Этакие “фанатики”, которые после рабочего дня за компьютером, приходят домой и дорабатывают бота в ущерб домашним делам и, иногда, сну :)
Впечатления великолепные, спасибо mailru за то, что они организуют такие конкурсы.
mortido:
Соревнования ботов для меня всегда приносят кучу эмоций: когда ты смотришь как твой бот начинает побеждать всех и ты полночи просто смотришь бои, а потом утром приходят крутые ребята и ломают ему лицо… Очень нравятся моменты, где твоя стратегия начинает находить решения, до которых ты бы не додумался (например как тут с колесом и переворотом). Или когда тебе кидают реплей, где твой бот убил 3 союзников по команде, а ты делаешь вид, что это случайно… хотя это было немного другое соревнование.
Commandos:
Как-то странно я провёл это соревнование, слишком рано начал впиливать костыли. И, пожалуй, немного не так, как стоило. Хотя с другой стороны… Костылями тут очень много погоды и сделалось. Но по итогу это сказалось на оценочной функции — она была не сильно продуманная, за что я чуть не поплатился.
Интеграция с чипманком убивала — дотошное копирование движка из питона в С++. На этот раз это была половина успеха. После написания симулятора долго не мог решить, с какой стороны подойти к написанию бота. Потом увидел в топ 1 мортидои пошёл ломать его боту лицои решил написать хоть что-нибудь.
Итак
Надеемся, статья получилась интересной и нам удалось раскрыть схожесть и разнообразие решений. В ходе описания решений, у авторов произошло много споров и дискуссий на тему оптимальности тех или иных подходов. Часть обсуждений были добавлены в статью, но если у вас остались вопросы, то их можно задать тут или в офф чате соревнования.
Отдельное спасибо Дмитрию и Mail.Ru Group за организацию конкурса.
Бонус
Исходники Valdemar
Исходники mortido
Кладезь статей по теме




Комментарии (19)

Fluttercom
20.11.2018 16:35Когда там уже не-мини cup? Будет в этом году?
lamik
20.11.2018 17:05+1Да, с движком получилось не очень. Без знания C/C++ я за время чемпионата успел реализовать точную симуляцию с аллокатором, но к тому моменту оставалась пара дней до конца и я не успел написать стратегию.
В итоге времени потратил немало, но так ничего и не залил.
Спасибо за статью, интересно.
И за опыт в C++ спасибо. Давно пора было познакомиться с этим чудесным миром Segfault-ов :)
Occama
20.11.2018 18:32Протыкал по ссылке три рандомных матча, в первом оба участника стояли на месте (но один каким-то образом всё же выиграл 1:0, видимо, всё же симметрия нарушилась немного и он под мусором утонул позднее), ещё в двух матчах уже на 5:0 выигрывал тот, кто не двигался, его оппонент прекрасно справлялся с суицидом самостоятельно. Может, я чего не понимаю и там можно отфильтровать вменяемые матчи? =)
DragoonXen
20.11.2018 18:52Наверное игры в песочнице. Там всякие могут быть.
Вариант открыть игры финала
aicups.ru/round/8/?rp=1#ranked-games
или прям рейтинговые игры из профилей топ участников
Voenniy
21.11.2018 10:04Спасибо за статью, спасибо организаторам за сам турнир.
Замечу что когда анонсировали этот турнир (в августе) то было много пессимистичных комментариев о том, что в конкурс лучше не соваться, там одни «монстры» и подобное.
Да, первая 5ка (а может и 10ка) лидеров — это те, кто уже не первый раз участвуют в подобных соревнованиях и имеют достаточный опыт. Но! Все они сидят телеграмм-канале соревнования и активно помогают, отвечая на вопросы от других участников.
Лично я впервые участвовал в подобном, писал решение на Go, на чистых IF-ах без симуляций и занял почетное 12-е место. Было очень интересно, даже не ожидал что так захватит.
Так что всем рекомендую участвовать в следующих турнирах!
ilyaknirim
21.11.2018 19:41С каждым разом растёт не только качество соревнований, но и количество интересных подходов, и… объём статей) Очень приятно было почитать! спасибо большое. Я припрятал свой мешок if-ов до новых минираиков, но с удовольствием наблюдал за гиперактивностью в чате. Было весело и очень интересно, поэтому отдельное спасибо организатору соревнования!!!
m0rtido Автор
21.11.2018 19:45Обьем получился и правда большим. После завершения соревнования, оказалось, что топовые стратегии имеют как общие, так и отличительные черты, которые было интересно сравнивать и обсуждать. В обсуждениях было выявленно много нюансов и интересных подробностей (и много чего еще не попало в текст...). Именно тогда появилась идея сделать статью сразу с несколькими решениями и коментариями топов по тем или иным "фичам".
tongohiti
22.11.2018 01:38Спасибо за статью! Такой формат очень даже неплох! Успехов в следующих контестах!
Geotyper
Это больше про суть соревнований, когда все в равном состоянии/ а так кто-то из 1000 участников конкурса научился копировать память движка и далее симуляция/ это уже не про соревнования тема/ а про то как я дырку в заборе нашел/ а вы не смогли… Что интересно организаторы выложили исходники движка на Си на сервер соревнований/ хотя другие языки были без расширения просто бибилиотеки поддержки. А так молодцы ребята/ но действительно питонисты, джависты и остальные в проигрышном состоянии. Но это вопрос больше к организаторам/ если конкурс то лучше более равный для участников. А касательно машинного обучения/ три вида машин/ шесть карт/ 18 вариантов начального состояния/ для мини конкурса многовато. Сама статья и подход через генетику к решению безусловно хороши!
sannikovdmitry
Саша, мы кидали доку на портирование движка на другие языки :( Все равно возникали трудности? Но стоит признать, что выбор этого физ движка был не особо удачным.
kswaldemar
Проблема в том, что chipmunk не умеет копировать свое состояние, а без этого в симуляции никак. В C++ выкрутились через подмену аллокатора памяти и копирование блоба. В других языках такое реализовать гораздо сложнее, если вообще реально.
DragoonXen
Нереально, в си в любом случае пришлось бы чуть влезть.
Впрочем кинули небольшой хелпер для СИ не совсем организаторы, его сделали участники. Причём сразу два хелпера.
Geotyper
Хороший движок/ изучил его за соревнования и даже научился состояние мира копировать/ но без дампа оперативной памяти/ этот секрет наверное из рук в руки передавали. И дух соревнований был конечно и приятно было участвовать. Три подхода испробовал и в топ попал на ифах которые сделал дня за три до конца/ но равные условия важны/ хотя конечно с++ и питон в симуляции как самолет и черепаха )
DragoonXen
Так на питоне шансов просимулировать не было, а без движка она есть, но всё равно питон почему-то побеждает только если ифами)
И никаких секретов из рук в руки. Не думаю, что таковыми можно считать сообщения в офчате, что «можно использовать аллокаторы» (от участников, конечно же). А по факту это у меня заняло ~ 30 строк кода и целый вечер, учитывая, что я первый раз писал аллокатор (да и С++ не тот язык, где мне комфортно)
А вот копирование исходников локал раннера из питона в С++ у меня заняло больше, чем половину недели. И тут бы все языки были бы более-менее равны (а питон даже ровнее, исходники ЛР то на нём)
kswaldemar
Копировать память научился не один участник. В чате телеграмма можно было получить подсказки, как добиться идеальной симуляции (без кода, разумеется). Те кто не хотели этим заниматься придумывали эвристики и прокладывали альтернативный путь в топ.
На мой взгляд соревновательная часть оставалась до самого конца.
Про другие языки — это правда, C++ в этот раз оказался в сильно выигрышном положении из за специфики движка. В оправдание организаторов можно сказать, что заранее это было узнать довольно сложно, все проявилось только после недели копания в коде чипмунка.
m0rtido Автор
С языками действительно вышел фейл, как я понимаю, задумка была наоборот их выровнять в шансах. А получилось… так как получилось.
Лично я на С++ писал в первый раз и за две недели до конкурса только начинал читать про то как инициализировать переменные и обьявлять функции. Как-то так :)
Буду надеятся, что и организаторы и участники вынесут что-то полезное для себя из статьи и нас ждут интересные задачки и честные зарубы на нескольких ЯП.