В этой статье я хочу рассказать о своем давнем увлечении — изучении и работе с far fields mic (mic array) — массивами микрофонов.
Статья будет интересна увлекающимся построением своих голосовых помощников, она ответит на некоторые вопросы людям, воспринимающим инженерное дело как искусство, а также желающим попробовать себя в роли Q (Это из Бондианы). Мой скромный рассказ, надеюсь возможно, поможет вам понять, почему умная колонка- помощник, сделанный строго по туториалу работает хорошо только при условии полного отсутствия шумов. И так плохо там, где они есть, например на кухне.
Много лет тому назад я увлекся программированием, писать код я начал просто потому, что мудрые учителя разрешали играть только в игры, написанные самостоятельно. Это было в году так 87 и это была Yamaha MSX. На эту тему тогда же был первый стартап. Все строго по мудрости: «Выбери себе работу по душе, и тебе не придётся работать ни одного дня в своей жизни» (Конфуций).
И вот прошли годы, и я по прежнему пишу код. Даже хобби с кодом — ну кроме катания на роликах, для разминки мозгов и "не забуду матан" это работа с Far Fields mic (Mic array). Зря что ли преподаватели время со мною тратили.
Что это такое и где применяется
В голосовом помощнике, который слушает вас, обычно присутствует массив микрофонов. Их мы находим и в системах видео-конференц-связи. При коллективном общении, львиная доля внимания уделяется речи, мы естественно, не постоянно при общении смотрим на говорящего, а говорить точно в микрофон или гарнитуру, это сковывает и неудобно.
Практически каждый, уважающий клиента, производитель мобильников использует в своих творениях от 2 и более микрофонов, (да, да за этими дырочками сверху, снизу, сзади сидят микрофоны). К примеру в iPhone 3G/3GS он был единственный, в четвертом поколении айфонов их было два, а в пятом насчитывалось уже три микрофона. В общем то, это тоже массив микрофонов. И все это для лучшей слышимости звука.
Но вернемся к нашим голосовым помощникам
Как же увеличить дальность слышания?
"нужны большие уши"
Простая идея: если для того, чтоб услышать того кто рядом, достаточно одного микрофона, то для того чтоб услышать издалека, нужно применить более дорогой микрофон с отражателем, похожий на ушки у лисичек-фенеков:

(Википедия)


 На самом деле -это не часть фурри-сьюта, а серьезный девайс для охотников и разведчиков.
На самом деле -это не часть фурри-сьюта, а серьезный девайс для охотников и разведчиков.

То же, только на резонаторных трубках

В среде обитания.
(Взято с https://forum.guns.ru)
Диаметр зеркала от 200мм до 1,5м
(больше такого см http://elektronicspy.narod.ru/next.html)
«Нужно больше микрофонов»
Или может, если поставить много дешевых микрофонов, то количество перейдет в качество и все получится? Зерг- раш только микрофонами.
Странно, но это работает и в реальной жизни. Правда с большим количеством матана, но работает. И расскажем мы про это в следующем разделе.
А как научиться слышать дальше без красивых рупоров?

Одна из проблем рупорных систем — это то что хорошо слышно то, что в фокусе. А вот если нужно услышать что то с другого направления, то нужно сделать "финт ушами" и физически перенацелить систему в другом направлении.
И про соотношение сигнал\шум у систем с микрофонными матрицами как то лучше по сравнению с обычным микрофоном.
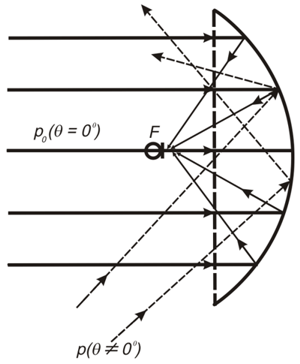
В массивах микрофонов, как и в их ближайших родственниках — ФАР (фазированных антенных решетках) ничего поворачивать не нужно. Подробнее в разделе про Beamforming. Легко видеть:

Несфокусированный микрофон (левая картинка) записывает все звуки со всех направлений, а не только тот, что нужно.
Откуда же большая дальность? На правой картинке, микрофон внимательно слушает только один источник. Как бы сфокусировавшись, получает сигнал только избранного источника, а не кашу из возможных источников шумов, а чистый сигнал просто усилить (сделать громче), не применяя сложных техник шумоподавления. Примерно как рупор, но на матановой тяге.
Что же не так с шумоподавлением?
У применения сложного шумоподавление уйма недостатков — значит, уйдет часть сигнала, вместе с частью сигнала изменится звук, и на слух это выглядит как характерное окрашивание звука шумодавом и как результат неразборчивость. Эта неразборчивость видна русскоговорящим, которые хотят услышать от собеседника вот эти шипящие. Ну и как дополнительно — в результате шумоподавления слушающий не слышит вообще никаких опознавательных сигналов, связывающих его с собеседником (дыхания, сопения и других шумов, сопровождающих живую речь). Это создаёт некоторые проблемы, ведь в разговорной речи вот это все слышно, и как раз помогает оценивать состояние и отношение к вам собеседника. Отсутствие их (шумов) пока мы слышим голос вызывает неприятные ощущения и снижает уровень восприятия, понимания ну и идентификации. Ну а если вас слушает голосовой помощник — шумоподавление затрудняет распознавание как ключевой фразы, так и речи после. Правда есть лайфхак — распознавалку нужно обучать на выборке, записанной с учетом искажений от именно используемого шумопонижения.
Те, кому знакомы слова cocktail party problem могут пока сходить на кофе или коктейль, и провести натурный эксперимент, те у кого настроение почитать, продолжают дальше.

Кратко о матане, на котором оно работает:
DOA Estimation (определение направления на источник звука) и формирование луча (beamforming)
Буду краток: делается это с помощью белой, серой или темной магии (зависит от предпочитаемой темы в IDE) и матана.
Наиболее простой и легкий для понимания способ -delay & sum (DAS and FDAS) — лучеформирование на базе задержки и суммирования.
Для визуалов:
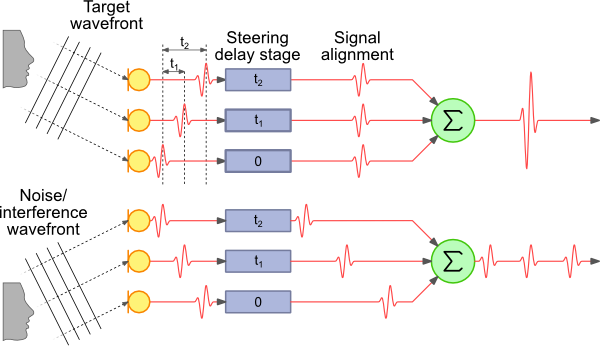
(Взято с http://www.labbookpages.co.uk/audio/beamforming/delaySum.html)
Лайфхак: Не забываем про разную длину волн и для каждой частоты рассчитываем свою разницу фаз tn
Примерная диаграмма направленности будет выглядеть как то так
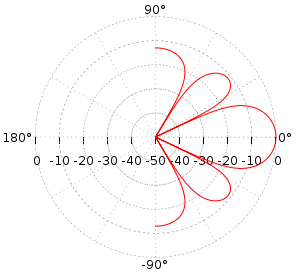
Не забывшие как раскуривать матан могут причаститься к JIO-RLS (Joint Iterative Subspace Adaptive reduced-rank least squares). Очень напоминает по вкусу градиентный спуск, знаете ли.

Итак резюмируем: обычными методами добится сравнимого с матричным микрофоном качества сложно. После применения определения направления на источник, и как результат этого, слышим только тот источник, что нужен, избавляемся от шумов и реверберации среды, даже той, которая слабо различима на слух (эффект Хааса).
Голосовой помощник — как это выглядит изнутри
Итак как выглядит схема обработки звука у матерого голосового помощника:

Сигнал с массива микрофонов поступает на устройство, в котором мы формируем луч на источник звука (beamforming), тем самым убирая помехи. Потом звук этого луча начинаем распознавать, обычно для качественного распознавания ресурсов устройства недостаточно, и чаще всего сигнал уходит для распознавания в облако (На выбор Microsoft, Google, Amazon).
Внимательный читатель заметит: А на картинке с описанием есть какой то квадратик Нот word, а почему не сразу распознавание, как обещали?
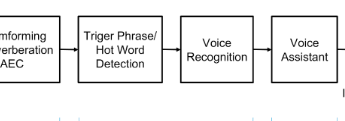
Зачем на схеме нарисован этот наверное лишний квадратик?
А потому что постоянно транслировать сигнал изо всех источников шумов в интернет для прослушивания распознавания никаких ресурсов не хватит. Поэтому распознавать начинаем, только когда поняли, что от нас этого таки точно хотят — и для этого сказали специальное заклинание — ок гугл, сири или алекса, ну или кортану позвали. А классификатор Нот word — чаще всего нейронка и работает прямо на устройстве. В построении классификатора есть тоже много интересного, но сегодня не об этом.
И на самом деле схема выглядит вот так:
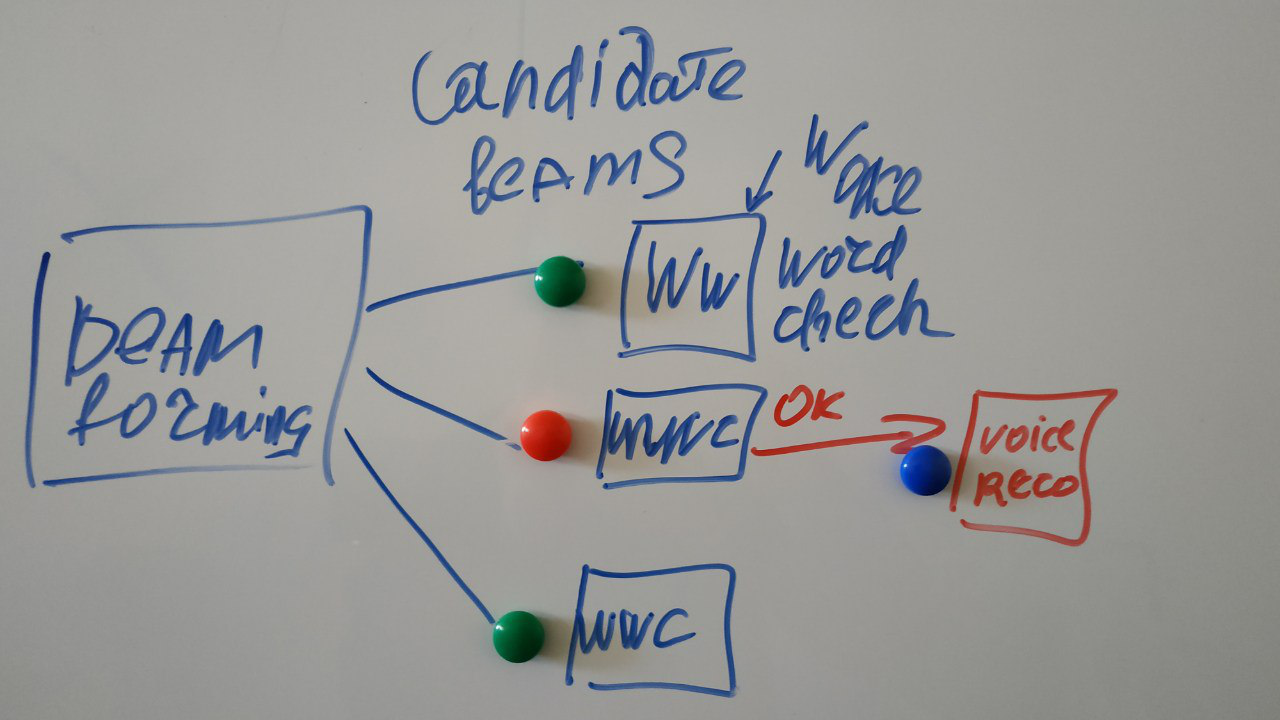
(каракули мои)
Может быть сформировано несколько лучей на разные источники сигнала, и ищем специальное слово мы в каждом из них. Но дальше обрабатывать будем того, кто сказал нужное слово.
Дальнейший этап- распознавание в облаке, многократно освещен в интернете, по нему множество туториалов.
Как вы можете приобщится к этому празднику матана
Проще всего купить dev board. Обзор существующих девбордов: один из наиболее полных — по ссылке.
Наиболее дружелюбные для начинающих:
https://www.seeedstudio.com/ReSpeaker-4-Mic-Array-for-Raspberry-Pi-p-2941.html
https://www.seeedstudio.com/ReSpeaker-Mic-Array-v2-0-p-3053.html
основан на XMOS XVF-3000.
Сделана так как мне нравится — FPGA с открытым интерфейсом управляет микрофонами матрицы, общение с ней по SDA.
Мои подвиги по скрещиванию Android Things и Mic Array:
К этой плате (Voice) конечно есть немало примеров, но вот мне как раз удобно использовать ее под Things.
Доводы за Things:
Можно построить гибкий и мощный инструмент:
- удобно что можно с экраном использовать как отдельный прибор
- можно использовать как headless устройство, т.е сделать передачу по сети (создать апи для передачи на другое устройство)
- удобная отладка
- много библиотек в том числе для передачи по сети;
- инструментов для анализа — много.
- а если показалось мало, то возможно подключение Сишных библиотек
Например я использую:
- анализ звуковых файлов,
- HRTF,
- Тренировка\построение классификаторов.
Да и потом если придется портировать/переписывать код в какой нибудь эмбед, то как то проще это делать с Java кода.
К сожалению, пример от авторов платы для Things был немного неработоспособен, поэтому я сделал свой демо-проект (естественно — я же ж могу).
Вкратце о чем там — всю черную магию по быстрому опросу микрофонов, FFT делаем на C++, а визуализацию, анализ, сетевое взаимодействие — на Java.
Планы на будущее развитие
Источник планов ну и заодно вдохновения: ODAS.
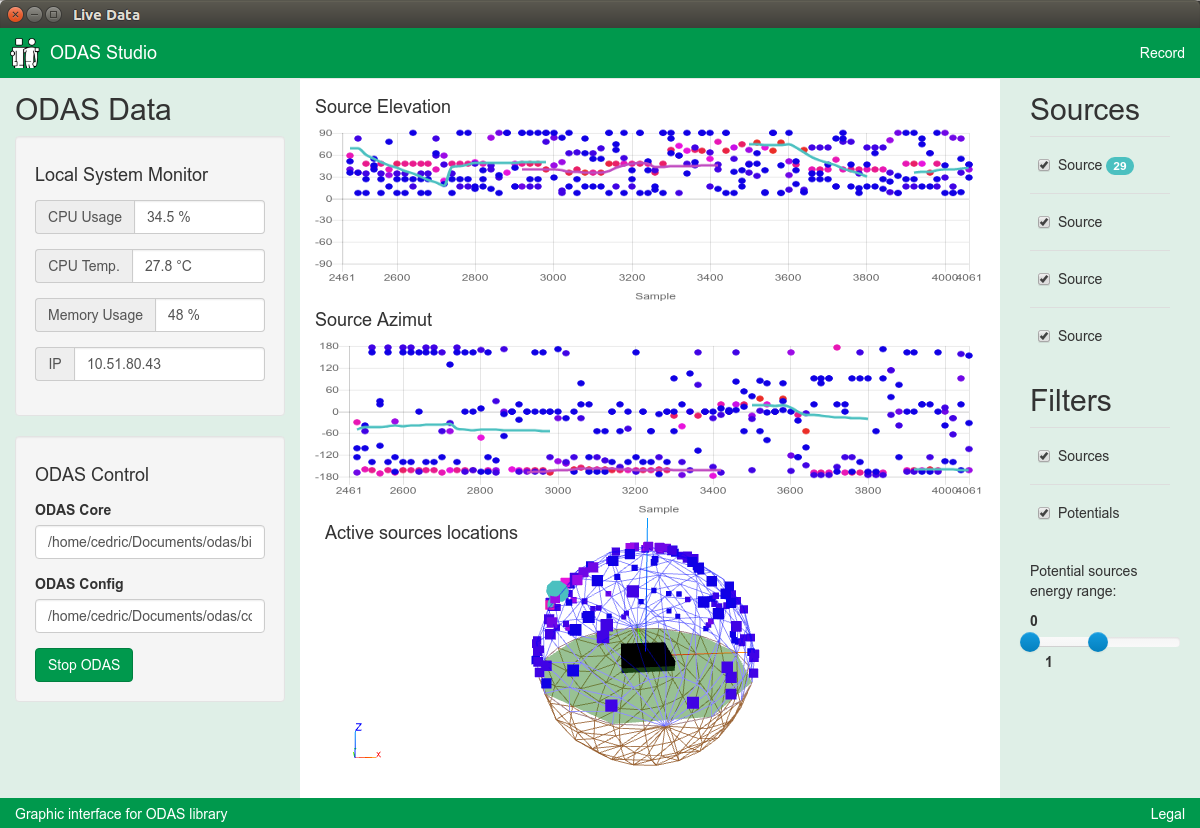
Вот хочу сделать то же, только на Things и без глюков.
- Потому что ODAS немного неудобен при использовании.
- Мне нужен нормальный инструмент для работы
- Потому что могу и мне нравится эта тема
- Использованные аппаратно программные средства отвечают сложности задачи.
Мои планы строятся на базе этого (моего же) репозитория.
И напоминаю
"Если вам есть что дополнить или критиковать, не стесняйтесь писать об этом в комментариях, ибо одна голова хуже двух, две хуже чем три, а n-1 хуже чем n" nikitasius
Комментарии (31)

buldo
26.11.2018 19:52А вы случайно не знаете доступные на рынке готовые микрофоны для конференций, построенные по такому принципу? В идеале хотелось бы, чтобы один такой микрофон покрывал полусферу радиусом метра 4.
Nick_Maverick Автор
26.11.2018 21:04К сожалению, страшно далек я от продаж, и не знаю, что там сейчас в моде.
Да и вопрос выбора сложнее чем кажется. Вопрос о деталях скрыт в слове «покрывал»:
слушать нужно один источник, или многоканальный, да и нужно ли отслеживать перемещения источника.
SADKO
27.11.2018 22:48В конференц системах и вообще, там где требуется качество, такие подходы не в ходу, по той причине, что чисто электронные шумы микрофонов замечательно складываются между собой, а диаграмма направленности акустической ФАР на разных частотах различна и завязана на расстояния между её элементами, так что по факту не всё так радужно…
Обычно используется несколько направленных микрофонов (под разными углами в одном корпусе с микрофоном с круговой направленностью), и приоритетная динамическая обработка. Для подавления эха и акустической обратной связи, используется цифровая обработка в которой иногда используют сигнал с микрофона круговой направленности.
Смотрите что предлагают Shure, Beyerdynamic.
a7v
27.11.2018 22:06Здравствуйте! Спасибо за статью. Может быть изучали вопрос и сравнивали отладочные платы, а лучше аналог фронтенд по критерию наименьшей групповой задержки? Сможете что-нибудь посоветовать для системы активного шумоподавления (не наушники, а в пространстве)? Интересует минимальная групповая задержка при частотах дискретизации 8 или 16 кГц. Понятно, что задержку можно еще сократить передискретизацией с максмимальной частоты дискретизации до нужных 8 или 16 кГц полифазным фильтром.
Nick_Maverick Автор
27.11.2018 22:12сравнивали отладочные платы
Только теоретически, бабло и возможность доставки понимаете ли.
системы активного шумоподавления (не наушники, а в пространстве)
Шот система телепатии дала сбой. Уточните, шумы собрались прям в определенной области давить? Если да, то это романтично называется «материализация фантома». И это тема прям не ответа на коммент, а чуть поширше.
Nick_Maverick Автор
27.11.2018 12:12групповая задержка
рецепт MEMS микрофоны. И высокие частоты дискретизации. И обработка, чтоб получить желаемый, а не такой как получился на картинке, эффект, на частоте гдет от 44100
a7v
27.11.2018 22:36Да, в шумы в определенной области пространства. Уже слегка давит, но только гармонические (как раз из-за большой групповой задержки в предусилителях, АЦП, ЦАП и т.д.). А хочется подвинуть шумодав поближе к источнику и давить не только гармоники, а что-нибудь еще в нижней части спектра. Вот, например, наша симуляция.
Кольцо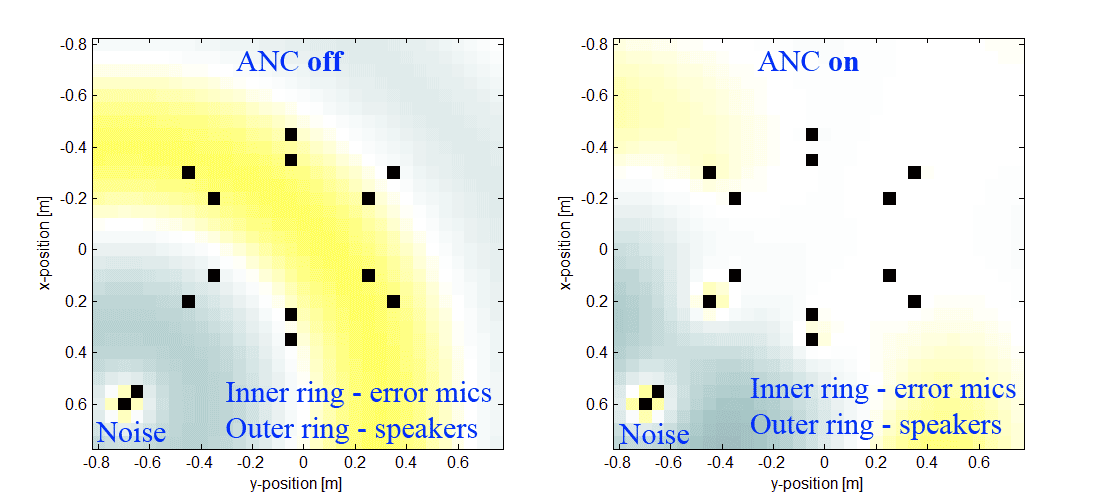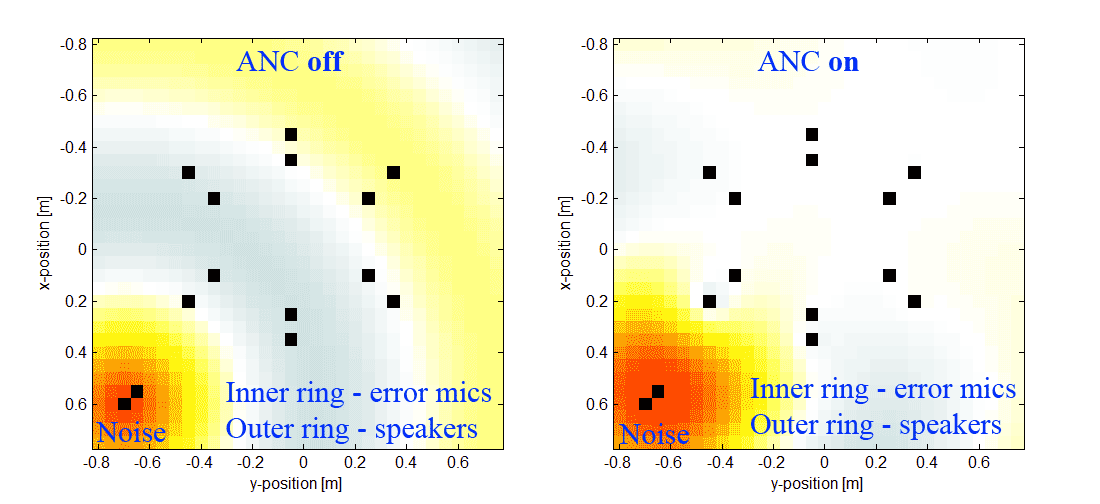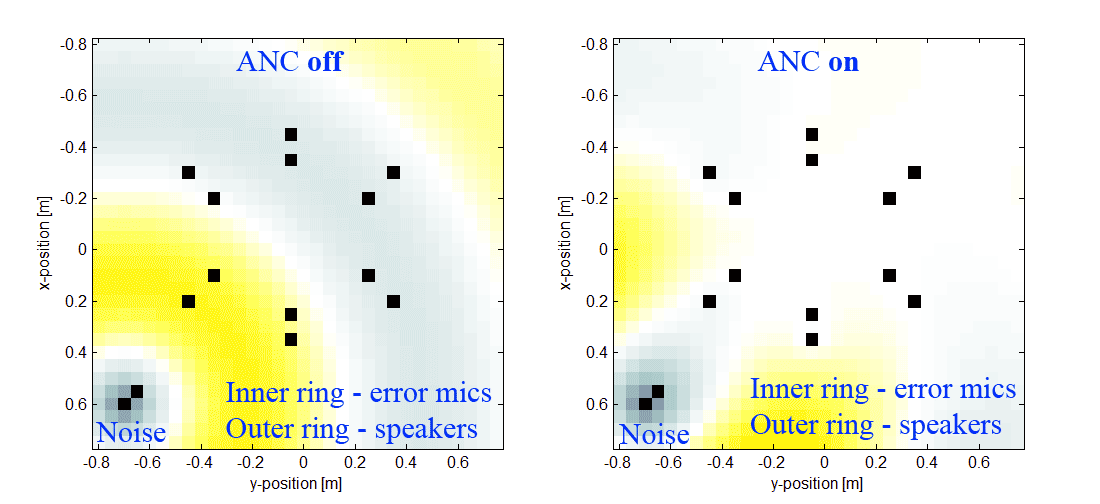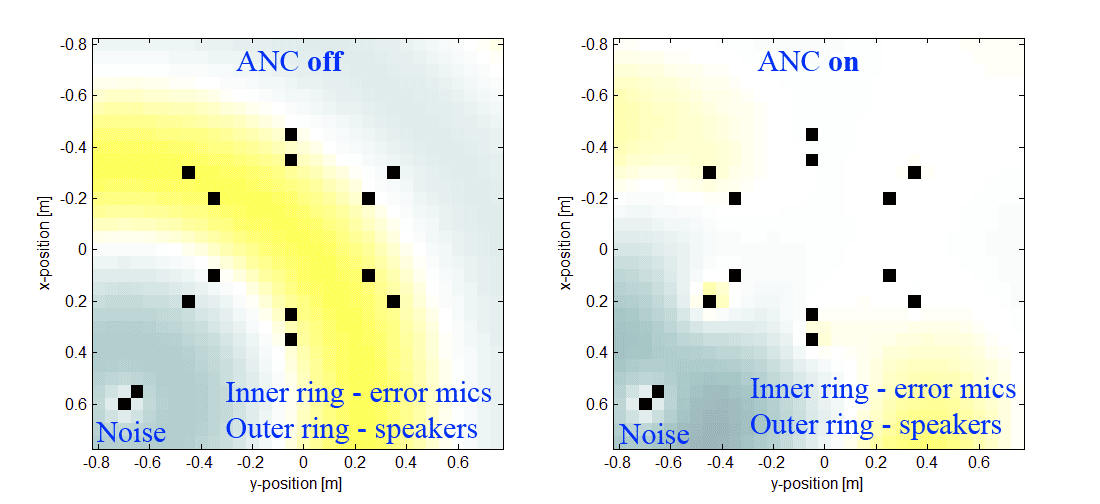

SADKO
27.11.2018 23:02Да, тут только так и надо, ибо здесь вообще другая опера…
И нюансы воспроизведения сигнала, особенно на НЧ, фигня в том что типичный конструктор узч полагает что ему достаточно просто усилить сигнал с минимальными искажениями, наивный, полагает что дельта напряжения на выходе усилителя, даст нам дельту давления, и она её конечно даст, но лишь в некоторых случаях, и точную лишь приблизительно…Nick_Maverick Автор
26.11.2018 23:19Ничего страшного в приблизительности, адаптивность и обратная связь рулит. Linkwitz transform подстраиваемый reinforcement learning как то так.
SADKO
26.11.2018 23:39Обратные связи действительно рулят! А вот на практическую реализацию reinforcement learning я бы посмотрел :-)
Серьёзно, я начал играться в эти игры в начале нулевых, ну очень соблазнительно было поиграться с фар (хотя-бы оффлайн), когда есть возможность качественной многоканальной записи…
… записываешь фоны для кино, а потом синхронизируешь с движением камеры, или какой-нибудь фестиваль барочной музыки в старинном соборе, можно и ревер задавить и микрофоны расставить постфактум, а уж подавление акустических шумов в коридоре казалось вообще детской забавой, казалось…Nick_Maverick Автор
26.11.2018 23:47А вот на практическую реализацию reinforcement learning я бы посмотрел
Ну в общем то как раз пишу, чтоб показать )
Nick_Maverick Автор
26.11.2018 23:28Да, и задержка на лицо, и конфигурация излучателей неоптимальна. Про задержку — это как раз то, почему я выбрал свой девбоард — на нем fcpga есть.
А насчет желания отойти от опытов на девборде и про сделать свою железку — я как раз работаю на фирме по производству железок. Так что немного в теме. Можем обсудить, может подскажу чего.
Про картинки — для понимания и советов надо подробней про использованый вами девборд, излучатели. О кстати и видос показать можно. Если тайна — то в личку.a7v
26.11.2018 23:51Вот видосик, но подавление происходит только на низкой частоте, причем только гармонической составляющей. Поэтому разница будет заметна если слушать в наушниках.
Активное шумоподавление дома
SADKO
26.11.2018 23:22Примерная диаграмма направленности будет выглядеть как то так
Так оно выглядит на какой-то конкретной, достаточно высокой частоте!
Там далее по ссылке, более правдивые картиночки, с учётом апературы и количества микрофончиков, при самом тупом их расположении. Но и тут ложка дёгдя, про рост электронных шумов с ростом числа микрофонов ни гу-гу, а частотное разрешение на графиках линейно, а не логарифмично как принято в звуковых измерениях, и принято не просто так, ибо слуховые анализаторы у человеков имеют совсем не линейное разрешение по частоте, и у меня есть сильные подозрения что это умышленно, ибо на низких частотах, всё совсем не весело :-)
… вот и получается, что борьба-то не за что, на самом деле, традиционные схемы построения направленных микрофонов ни чем не хуже, а только лучше по шумам и искажениям, ибо физику не обманешь, хочешь хорошую направленность бери большую апературу, хочешь линейности ачх (а здесь об это вообще не упоминается), располагай элементы с умом, и вообще всё придумано до нас, на самом делеNick_Maverick Автор
26.11.2018 23:41хочешь линейности ачх
У меня вообще про методы формирования луча вскользь, так как писал в популярном стиле, но про методы формирования луча, отличные от DAS такие как JIO-RLS, вроде ж упомянул.SADKO
27.11.2018 00:45И это хорошо, я как раз в нечто подобное игрался не в шутку, но с выводами вроде:
обычными методами добится сравнимого с матричным микрофоном качества сложно
Многие производители оборудования и просьюмеры (в том числе пользователи и конструкторы спец.средств) не согласятся, даже если чисто за сигнал\шум говорить, ведь и с одного микрофона можно стационарный шум съесть…
Но хорошо яичко ко христову дню, для мобильных девайсов где звук перед передачей жестоко оптимизируют и пожмут, для распознования где направление может иметь значение, но опять-же, по уму надо работать с «акустическим полем» а не симулировать направленный микрофон…Nick_Maverick Автор
27.11.2018 12:07Но можно. Вопрос в затратах на R&D. Ну и в наличии спецов для этого самого R&D.
и с одного микрофона можно стационарный шум съесть
Можно. Но у каждого «сьесть» есть своя цена. А с акустическим полем работать, имея n распределенных микрофонов, с известными характеристиками, с высокой частотой дискретизации как то проще. Да, и с достаточными вычислительными ресурсами.
electronus
27.11.2018 06:20А можно поподробнее о девайсах для охотников? Как называются? Можно ли сделать самому?
Nick_Maverick Автор
27.11.2018 11:54под фото ссылка forum.guns.ru/forum_light_message/14/698118.html
там еще много всякого интересного.
Из из не самоделок стрелковых — WALKER`S Alpha 360 Quad.
Может со временем что то свое застартаплю
Mobile1
27.11.2018 08:14А что если попробовать совершенно другой подход к этой проблеме?
У меня есть Alexa Echo и действительно, когда включен телевизор кодовое слово колонка может определить и активизироваться, а вот потом, когда она начинает делать анализ в облаке на фоне шумов она перестает что-то понимать, несмотря на наличие 8 микрофонов и всяких хитрых методов обработки.
В таком случае приходится или кричать или фоновый звук уменьшать.
И мне кажется что просто математикой эту проблему не решить.
Так вот, бредовая идея — вместо того чтобы затачиваться в обработку, в физику и в матан, не проще ли взять и раскидать по комнате еще несколько дополнительных микрофонов и анализировать инфу с них для эффективного шумоподавления и определения источника голосовых команд?
Сейчас есть недорогие сенсоры с микрофоном и с вайфай на борту.
Вообще все это напоминает ситуацию с Wi-Fi в части детекции слабого сигнала от клиента.
По моему и термин beamforming впервые появился именно у производителей вайфай железок и в принципе он должен был решить похожую проблему — «услышать» слабый сигнал от смартфона.
Но такую проблему лучше решает в Wi-Fi или меш сеть или WDS, т.е. тупо увеличиваем покрытие количеством точек и все это работает лучше beamforminga.
Здесь можно сделать тоже самое — разбросать микрофоны с вай-фай/блютус по комнате, которые бы слали все на центральную станцию и обрабатывать все соответствующим алгоритмом.Nick_Maverick Автор
27.11.2018 11:58взять и раскидать по комнате еще несколько дополнительных микрофонов
Практикую такой подход. Распределенная сеть микрофонов. Кстати доп микрофоны — те же matrix voice только модификация с ESP32Mobile1
27.11.2018 13:07Посмотрел цены — 65$ такая плата стоит, а к ней еще надо питание, корпус и т.д.
Проще купить несколько Alexa Dot за 45$.
Т.е. чисто для разработчиков и энтузиастов DIY.
encyclopedist
27.11.2018 13:30По моему и термин beamforming впервые появился именно у производителей вайфай железок
Этот термин появился в радиолокации и эхолокации лет наверное 60 назад.
bellerofonte
27.11.2018 13:30Хорошая статья, надо еще. Мне, вот например, интересна тема on-device hotword-spotting. Недавно сунулся изучать вопрос, а оказалось, что годных библиотек для этого в свободном доступе мало (особенно для js), да и те так себе. по сути есть только более-менее годный Snowboy, но у него очень много ложных срабатываний, если а) ключевое слово короткое; б) не на английском; в) мало сэмплов для тренировки (т.е. собственное слово, сэмплы которого были записаны макс. от 2-3 человек).
Чем пользуется автор и что у него есть рассказать по этому вопросу?Nick_Maverick Автор
27.11.2018 13:42+1Своим велосипедом. Но мне до снеговика пока далеко.
но у него очень много ложных срабатываний
у снеговика отличная логика. Таки на малом количестве семплов лучше и не будет.
А выбор ключевого слова — тот еще квест. И он кстати во многом обеспечивает качество распознавания.bellerofonte
27.11.2018 13:56а свей велосипед из чего? имею ввиду
- язык (Python/JavaScript/C++)
- тип нейросети
- библиотека для работы с нейросетями
Wicron
27.11.2018 17:56Знатная хайповая статья нарисовалась. Автор, возьми ODAS и прикрути к массивам из статьи, затем прикрути к алексе и сравни качество распознавания речи с устройством Echo. Напиши новую статью, возможно уверенности в своих комментариях и в том, что ты понимаешь станет меньше. Гипотеза о том, что много микрофонов это хорошо — это страшный бред. Научное абстрагирование по графикам может привести к иному выводу.
Что касается парадигмы DOA и beamformer. Соотнести грамотно ширину бимформера и ошибку по определению направления так, чтобы попадать туда, куда нужно — основное противоречие. Начать статью я бы посоветовал с разъяснения и сравнения подходов и аппаратных решений, разделив их на Near Field, Far Field. Хочу отметить, что есть решения их 2х микрофонов, которые решают задачу качественнее, чем те массивы, которые вы в статье описываете и даете на них ссылки. Без решения задачи создания системы распознавания речи работа с аппаратными решениями лишена полностью смысла, а в плане качестве разочарует даже при попытке это проанализировать на слух.
Sdima1357
Nick_Maverick Автор
Разницу фаз. Спасибо, исправил