Мы в «Ростелекоме» стремимся развивать работу с Hadoop, так что уже попробовали и оценили преимущества Apache NiFi по сравнению с другими решениями. В этой статье я расскажу, чем нас привлек этот инструмент и как мы его используем.
Предыстория
Не так давно мы столкнулись с выбором решения для загрузки данных из внешних источников в кластер Hadoop. Продолжительное время для решения подобных задач у нас использовался Apache Flume. К Flume в целом не было никаких нареканий, кроме нескольких моментов, которые нас не устраивали.
Первое, что нам, как администраторам, не нравилось – это то, что написание конфига Flume для выполнения очередной тривиальной загрузки нельзя было доверить разработчику или аналитику, не погруженному в тонкости работы этого инструмента. Подключение каждого нового источника требовало обязательного вмешательства со стороны команды администраторов.
Вторым моментом были отказоустойчивость и масштабирование. Для тяжелых загрузок, например, по syslog, нужно было настраивать несколько агентов Flume и ставить перед ними балансировщик. Все это затем нужно было как-то мониторить и восстанавливать в случае сбоя.
В-третьих, Flume не позволял загружать данные из различных СУБД и работать с некоторыми другими протоколами «из коробки». Конечно, на просторах сети можно было найти способы заставить работать Flume с Oracle или с SFTP, но поддержка таких «велосипедов» — занятие совсем не из приятных. Для загрузки данных из того же Oracle приходилось брать на вооружение еще один инструмент — Apache Sqoop.
Откровенно говоря, я по своей натуре являюсь человеком ленивым, и мне совсем не хотелось поддерживать зоопарк решений. А еще не нравилось, что всю эту работу приходится выполнять самому.
Есть, разумеется, достаточно мощные решения на рынке ETL-инструментов, которые умеют работать с Hadoop. К ним можно отнести Informatica, IBM Datastage, SAS и Pentaho Data Integration. Это те, о которых чаще всего можно услышать от коллег по цеху и те, что первыми приходят на ум. К слову, у нас используется IBM DataStage для ETL на решениях класса Data Warehouse. Но так уж исторически сложилось, что использовать DataStage для загрузок в Hadoop наша команда не имела возможности. Опять же, нам не нужна была вся мощь решений такого уровня для выполнения достаточно простых преобразований и загрузок данных. Что нам требовалось, так это решение с хорошей динамикой развития, умеющее работать со множеством протоколов и обладающее удобным и понятным интерфейсом, с которым способен справиться не только администратор, разобравшийся во всех его тонкостях, но и разработчик с аналитиком, которые зачастую и являются для нас заказчиками самих данных.
Как вы могли понять из заголовка, мы решили перечисленные проблемы с помощью Apache NiFi.
Что такое Apache NiFi
Название NiFi происходит от «Niagara Files». Проект в течение восьми лет разрабатывался агентством национальной безопасности США, а в ноябре 2014 года его исходный код был открыт и передан Apache Software Foundation в рамках программы по передаче технологий (NSA Technology Transfer Program).
NiFi — это open source ETL/ELT-инструмент, который умеет работать со множеством систем, причем не только класса Big Data и Data Warehouse. Вот некоторые из них: HDFS, Hive, HBase, Solr, Cassandra, MongoDB, ElastcSearch, Kafka, RabbitMQ, Syslog, HTTPS, SFTP. Ознакомиться с полным списком можно в официальной документации.
Работа с конкретной СУБД реализуется за счет добавление соответствующего JDBC-драйвера. Есть API для написания своего модуля в качестве дополнительного приемника или преобразователя данных. Примеры можно найти здесь и здесь.
Основные возможности
В NiFi используется веб-интерфейс для создания DataFlow. С ним справится и аналитик, который совсем недавно начал работать с Hadoop, и разработчик, и бородатый админ. Последние двое могут взаимодействовать не только с «прямоугольниками и стрелочками», но и с REST API для сбора статистики, мониторинга и управления компонентами DataFlow.
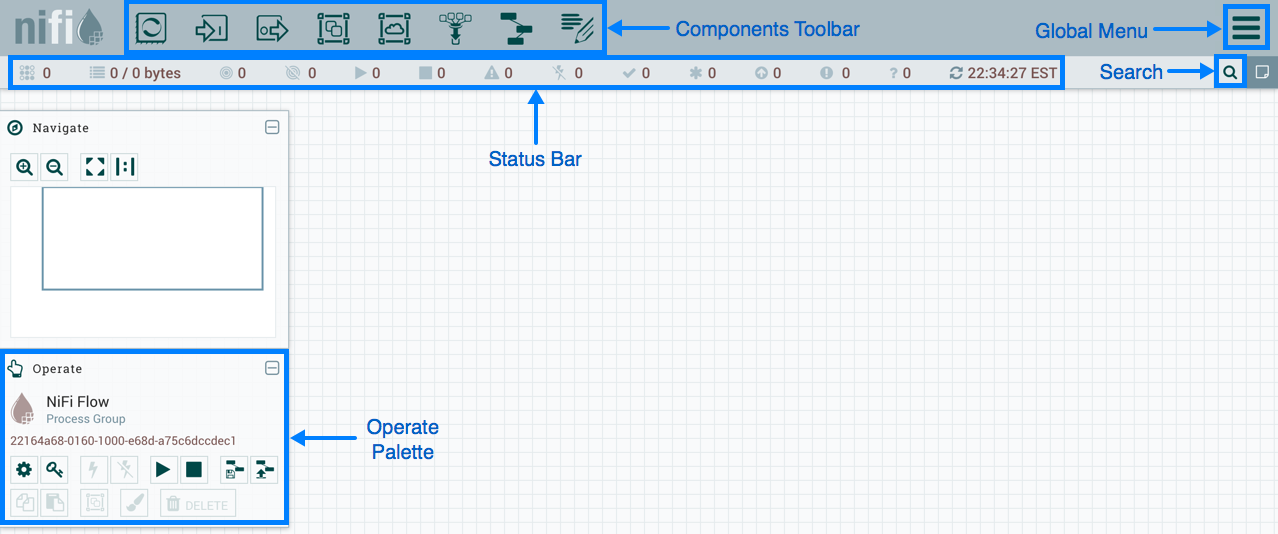
Веб-интерфейс управления NiFi
Ниже я покажу несколько примеров DataFlow для выполнения некоторых обыденных операций.
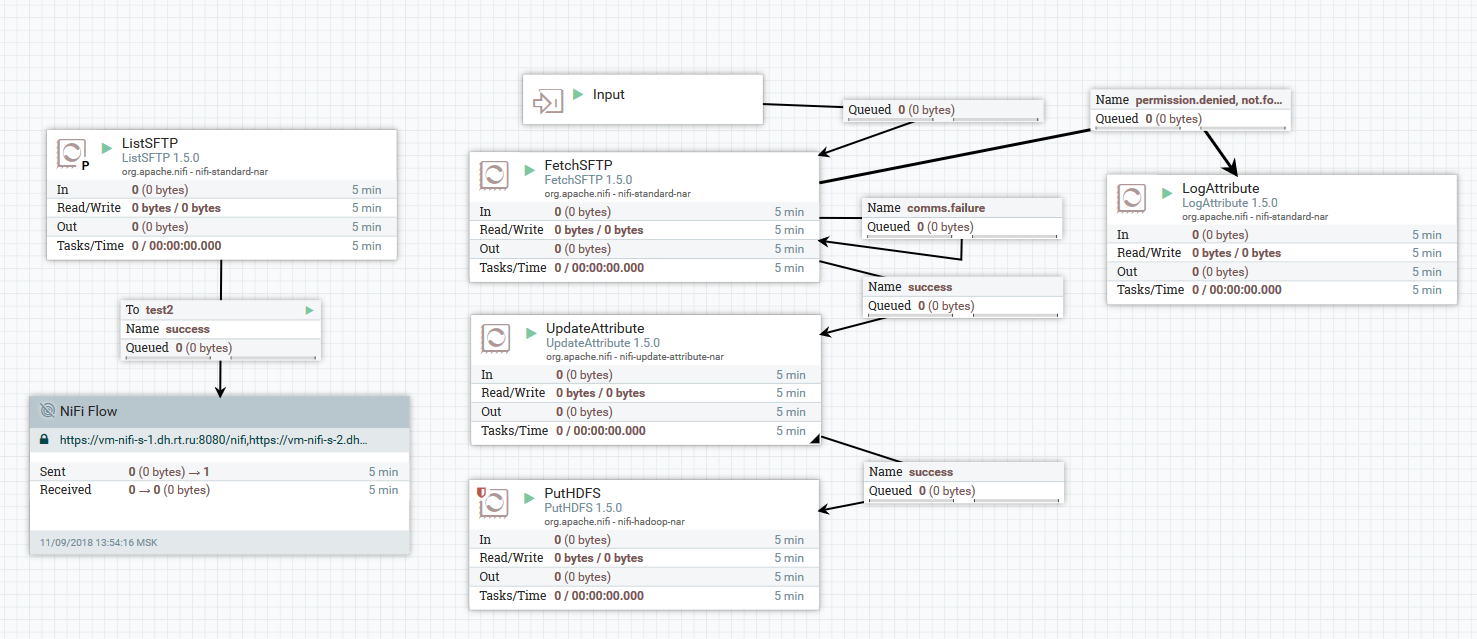
Пример загрузки файлов с SFTP-сервера в HDFS
В этом примере процессор «ListSFTP» делает листинг файлов на удаленном сервере. Результат этого листинга используется для параллельной загрузки файлов всеми нодами кластера процессором «FetchSFTP». После этого, каждому файлу добавляются атрибуты, полученные путем парсинга его имени, которые затем используются процессором «PutHDFS» при записи файла в конечную директорию.
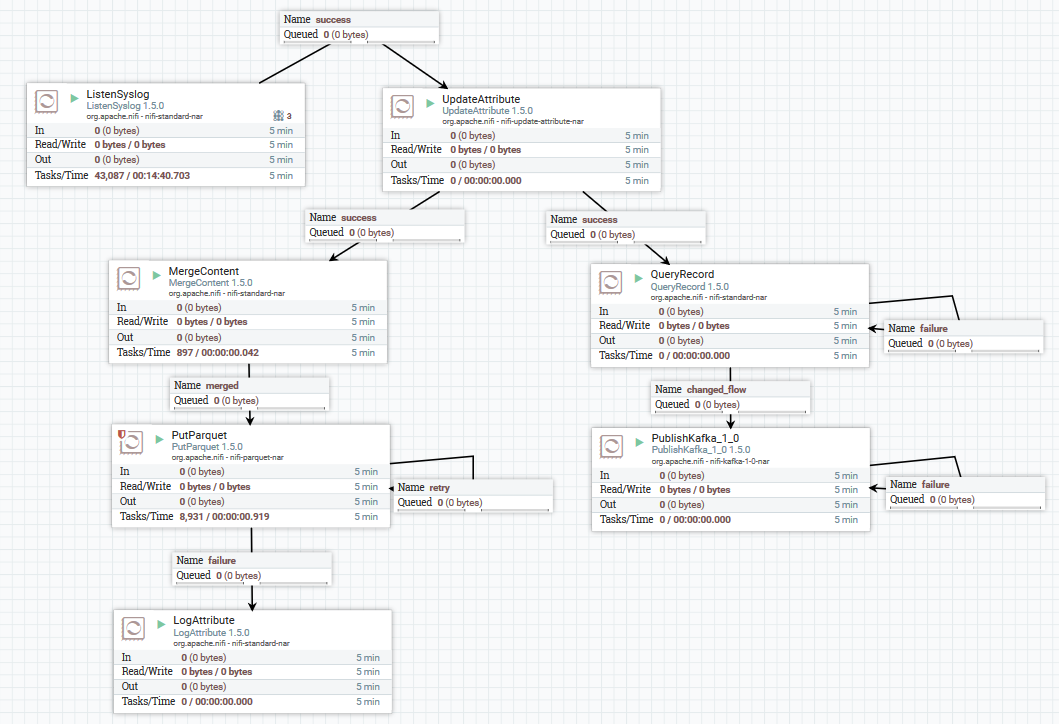
Пример загрузки данных по syslog в Kafka и HDFS
Здесь с помощью процессора «ListenSyslog» мы получаем входной поток сообщений. После этого каждой группе сообщений добавляются атрибуты о времени их поступления в NiFi и название схемы в Avro Schema Registry. Далее первая ветвь направляется на вход процессору «QueryRecord», который на основе указанной схемы читает данные и выполняет их парсинг с помощью SQL, а затем отправляет их в Kafka. Вторая ветвь направляется процессору «MergeContent», который агрегирует данные в течение 10 минут, после чего отдает их следующему процессору для преобразования в формат Parquet и записи в HDFS.
Вот пример того, как еще можно оформить DataFlow:
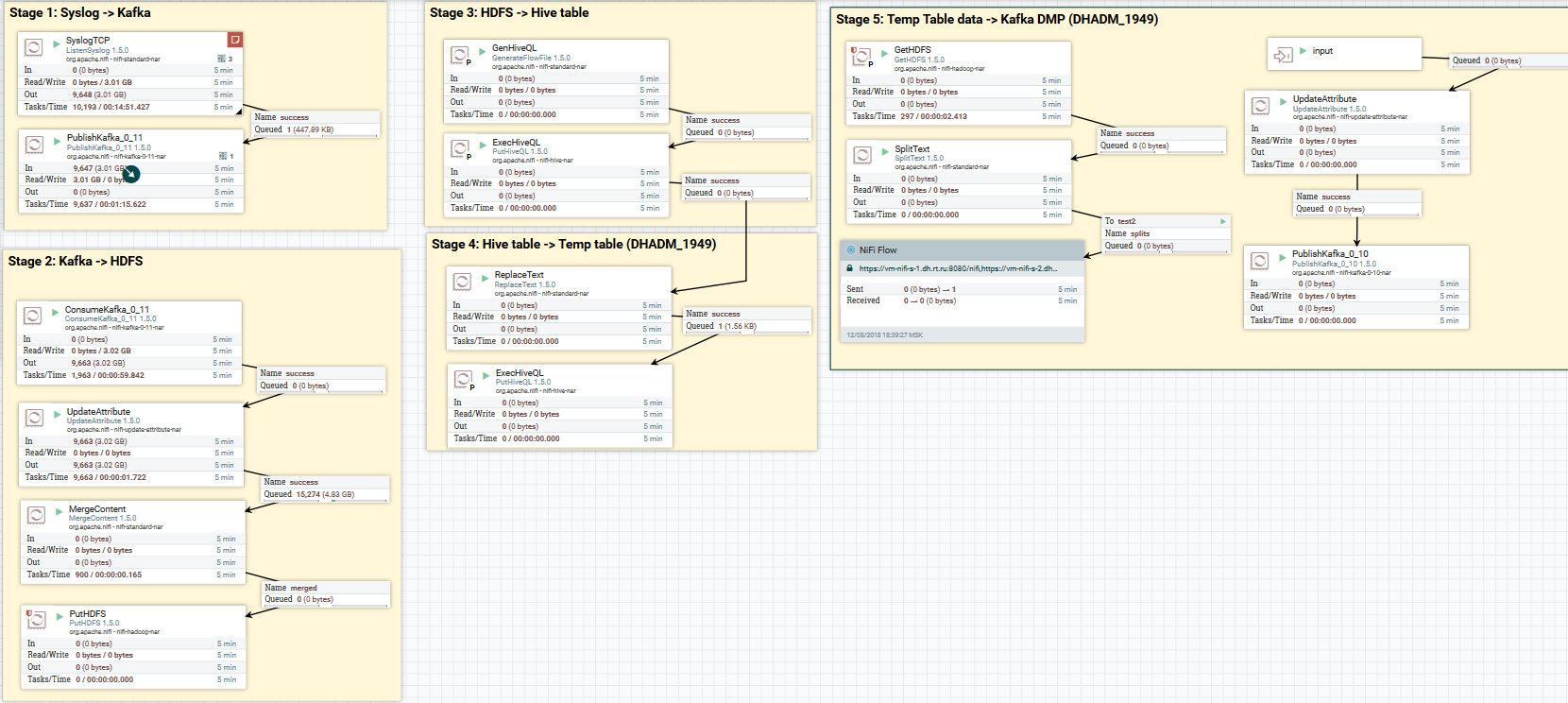
Загрузка данных по syslog в Kafka и HDFS. Очистка данных в Hive
Теперь о преобразовании данных. NiFi позволяет парсить данные регуляркой, выполнять по ним SQL, фильтровать и добавлять поля, конвертировать один формат данных в другой. Еще в нем есть собственный язык выражений, богатый различными операторами и встроенными функциями. С его помощью можно добавлять переменные и атрибуты к данным, сравнивать и вычислять значения, использовать их в дальнейшем при формировании различных параметров, таких как путь для записи в HDFS или SQL-запрос в Hive. Подробнее можно прочитать тут.
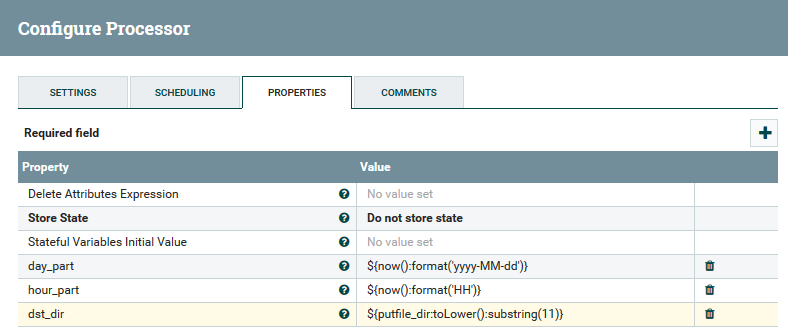
Пример использования переменных и функций в процессоре UpdateAttribute
Пользователь может отслеживать полный путь следования данных, наблюдать за изменением их содержимого и атрибутов.
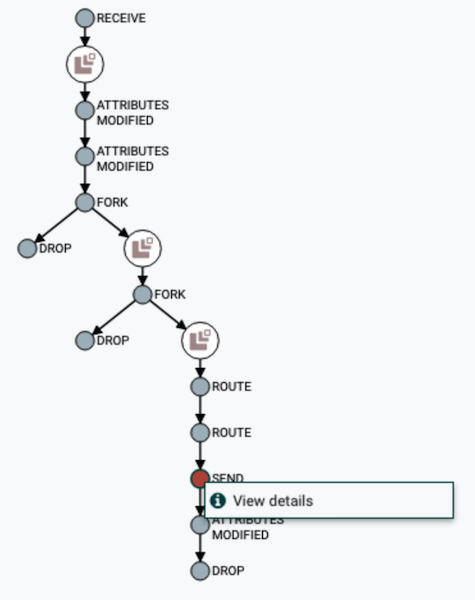
Визуализация цепочки DataFlow
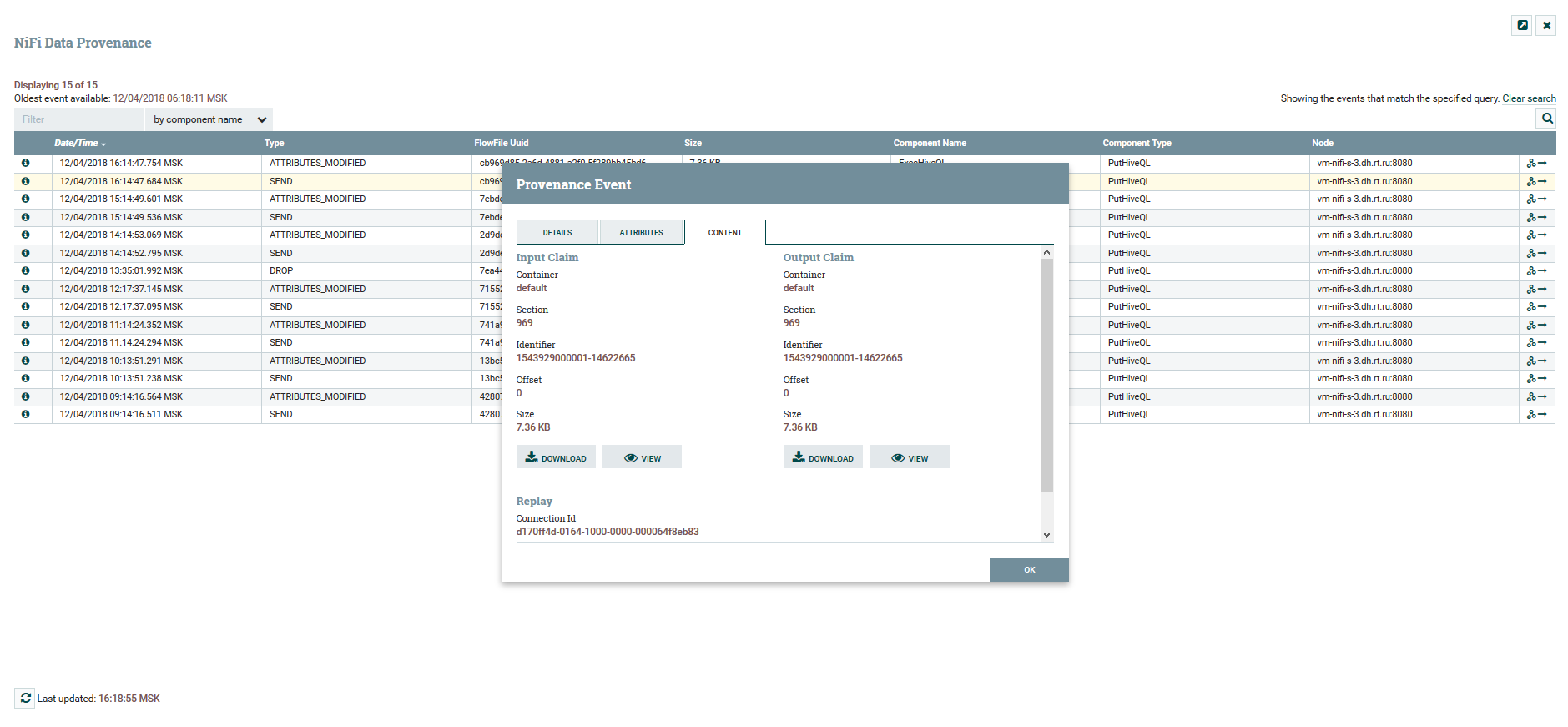
Просмотр содержимого и атрибутов данных
Для версионирования DataFlow есть отдельный сервис NiFi Registry. Настроив его, вы получаете возможность управлять изменениями. Можно запушить локальные изменения, откатиться назад или загрузить любую предыдущую версию.

Меню Version Control
В NiFi можно управлять доступом к веб-интерфейсу и разделением прав пользователей. На текущий момент поддерживаются следующие механизмы аутентификации:
- На основе сертификатов
- На основе имени пользователя и пароля посредством LDAP и Kerberos
- Через Apache Knox
- Через OpenID Connect
Одновременное использование сразу нескольких механизмов не поддерживается. Для авторизации пользователей в системе используются FileUserGroupProvider и LdapUserGroupProvider. Подробнее про это можно прочитать здесь.
Как я уже говорил, NiFi умеет работать в режиме кластера. Это обеспечивает отказоустойчивость и дает возможность горизонтально масштабировать нагрузку. Статично зафиксированной мастер-ноды нет. Вместо этого Apache Zookeeper выбирает одну ноду в качестве координатора и одну в качестве primary. Координатор получает от других нод информацию об их состоянии и отвечает за их подключение и отключение от кластера.
Primary-нода служит для запуска изолированных процессоров, которые не должны запускаться на всех нодах одновременно.
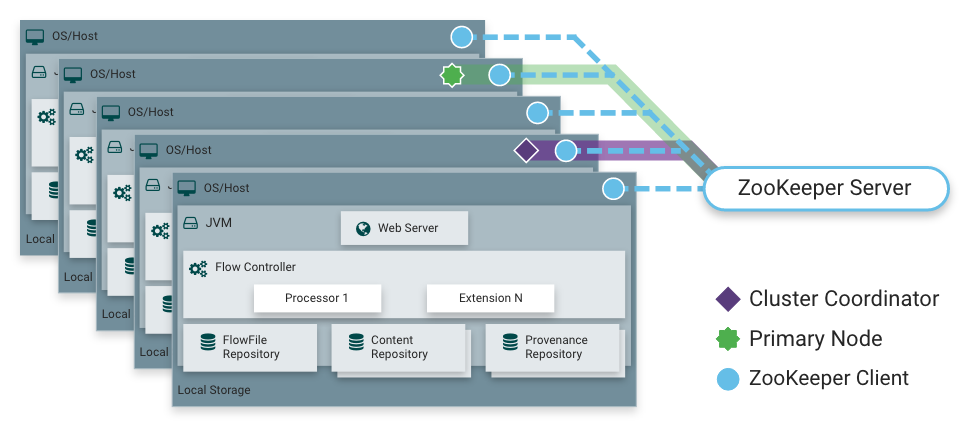
Работа NiFi в кластере
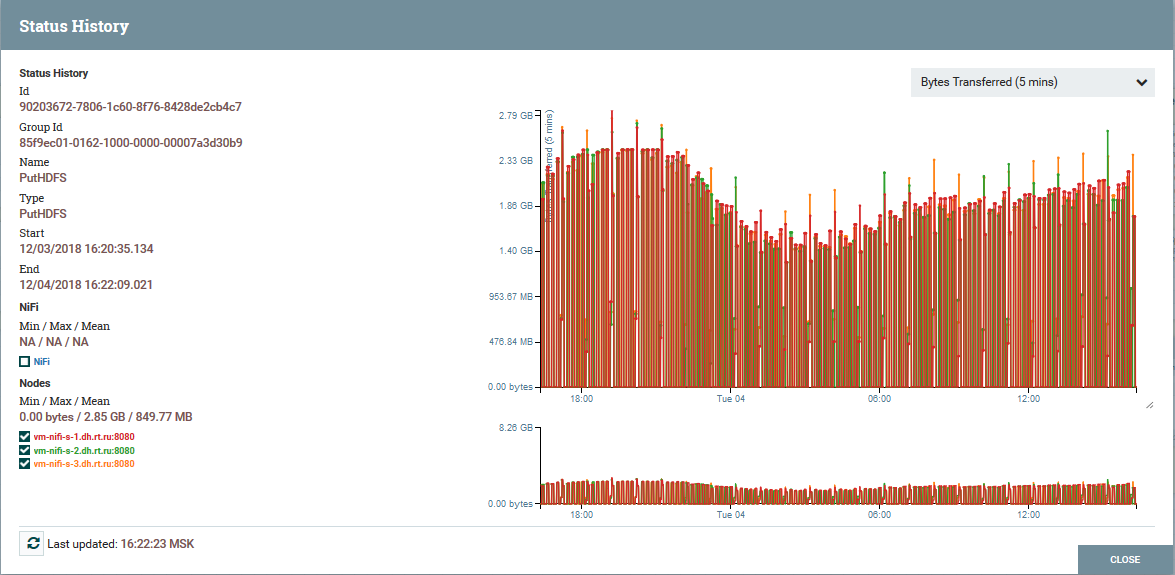
Распределение нагрузки по нодам кластера на примере процессора PutHDFS
Краткое описание архитектуры и компонентов NiFi

Архитектура NiFi-инстанса
NiFi опирается на концепцию «Flow Based Programming» (FBP). Вот основные понятия и компоненты, с которыми сталкивается каждый его пользователь:
FlowFile — сущность, представляющая собой объект с содержимым от нуля и более байт и соответствующих ему атрибутов. Это могут быть как сами данные (например, поток Kafka сообщений), так и результат работы процессора (PutSQL, например), который не содержит данных как таковых, а лишь атрибуты сгенерированные в результате выполнения запроса. Атрибуты представляют собой метаданные FlowFile.
FlowFile Processor — это именно та сущность, которая выполняет основную работу в NiFi. Процессор, как правило, имеет одну или несколько функций по работе с FlowFile: создание, чтение/запись и изменение содержимого, чтение/запись/изменение атрибутов, маршрутизация. Например, процессор «ListenSyslog» принимает данные по syslog-протоколу, на выходе создавая FlowFile’ы с атрибутами syslog.version, syslog.hostname, syslog.sender и другими. Процессор «RouteOnAttribute» читает атрибуты входного FlowFile и принимает решение о его перенаправлении в соответствующее подключение с другим процессором в зависимости от значений атрибутов.
Connection — обеспечивает подключение и передачу FlowFile между различными процессорами и некоторыми другими сущностями NiFi. Connection помещает FlowFile в очередь, после чего передает его далее по цепочке. Можно настроить, как FlowFile’ы выбираются из очереди, их время жизни, максимальное количество и максимальный размер всех объектов в очереди.
Process Group — набор процессоров, их подключений и прочих элементов DataFlow. Представляет собой механизм организации множества компонентов в одну логическую структуру. Позволяет упростить понимание DataFlow. Для получения и отправки данных из Process Groups используются Input/Output Ports. Подробнее об их использовании можно прочитать здесь.
FlowFile Repository — это то место, в котором NiFi хранит всю известную ему информацию о каждом существующем в данный момент FlowFile в системе.
Content Repository — репозиторий, в котором находится содержимое всех FlowFile, т.е. сами передаваемые данные.
Provenance Repository — содержит историю о каждом FlowFile. Каждый раз, когда с FlowFile происходит какое-либо событие (создание, изменение и т.д.), соответствующая информация заносится в этот репозиторий.
Web Server — предоставляет веб-интерфейс и REST API.
Заключение
С помощью NiFi «Ростелеком» смог улучшить механизм доставки данных в Data Lake на Hadoop. В целом, весь процесс стал удобнее и надежнее. Сегодня я могу с уверенностью сказать, что NiFi отлично подходит для выполнения загрузок в Hadoop. Проблем в его эксплуатации у нас не возникает.
К слову, NiFi входит в дистрибутив Hortonworks Data Flow и активно развивается самим Hortonworks. А еще у него есть интересный подпроект Apache MiNiFi, который позволяет собирать данные с различных устройств и интегрировать их в DataFlow внутри NiFi.
Дополнительная информация о NiFi
- Официальная страница документации проекта
- Собрание интересных статей о NiFi от одного из участников проекта
- Блог о NiFi одного из разработчиков
- Статьи на портале Hortonworks
Пожалуй, на этом все. Спасибо всем за внимание. Пишите в комментариях, если у вас есть вопросы. С удовольствием на них отвечу.
Комментарии (24)

dmitry_dvm
06.12.2018 12:57Так это из-за этого у вас так чудовищно тормозит ЛК? Вчера не подгружались ни счета на оплату, ни проведенные платежи, ни информация о тарифе.
Что это за дерьмо, ребята?На загрузку этой формы уходит МИНУТА!

r3former Автор
06.12.2018 13:11Мне кажется, Вы не ту статью выбрали для Вашего комментария. NiFi используется в Ростелеком для загрузок данных в Hadoop, а сам Hadoop никоим образом не связан с работой интернет/IPTV/мобильной связи и веб-ресурсов Ростелеком. Hadoop для построения рекомендательных моделей, машинного обучения и всякой разной аналитики. По работе ЛК рекомендую Вам обратиться в техподдержку компании.
dmitry_dvm
06.12.2018 14:20А вы к ним в техподдержку обращались? Сначала прорваться через их сверхразум на входе, потом подождать полчаса, пока кто-нибудь соизволит ответить. У меня есть на что это время потратить. Конечно, мой камент здесь офтоп, но другого способа докричаться до их отделов разработки я не знаю.
tvr
06.12.2018 13:35На загрузку этой формы уходит МИНУТА!
Ну так это, снежинки, ёлочные украшения, всё для создания новогоднего настроения и атмосферы у клиента, а вам всё не так, всё не нравится.dmitry_dvm
06.12.2018 14:35Причем снежинка, как и вся статика грузятся быстро. А вот нужная инфа либо минуту, либо вообще не.

barloc
06.12.2018 20:14Статья неплохая. И если бы не знал всех потрохов найфая в работе даже сошло бы :)
Но:
Первое, что нам, как администраторам, не нравилось – это то, что написание конфига Flume для выполнения очередной тривиальной загрузки нельзя было доверить разработчику или аналитику, не погруженному в тонкости работы этого инструмента.
Это все сохраняется и для найфая. Вернее как, бестпрактис и стандартные шаблоны выстраданы квалифицированной командой дев+опс, но никак не первым встречным, который в первый раз увидел найфай. Он просто уронит сервер, а вместе с ним и все остальные таски на нем. Ведь у найфай нет изоляции заданий, все крутится вместе.
Вторым моментом были отказоустойчивость и масштабирование. Для тяжелых загрузок, например, по syslog, нужно было настраивать несколько агентов Flume и ставить перед ними балансировщик. Все это затем нужно было как-то мониторить и восстанавливать в случае сбоя.
Ситуация с балансировщиком остается и в случае найфая. Если у вас эндпойнт внутри кластера, то кто же будет клиентов перенаправлять на него в случае падения/обслуживания ноды?
И масштабирование у найфая весьма специфичное, только через РПГ, которые не работают внутри ПГ.
В-третьих, Flume не позволял загружать данные из различных СУБД и работать с некоторыми другими протоколами «из коробки». Конечно, на просторах сети можно было найти способы заставить работать Flume с Oracle или с SFTP, но поддержка таких «велосипедов» — занятие совсем не из приятных. Для загрузки данных из того же Oracle приходилось брать на вооружение еще один инструмент — Apache Sqoop.
Процессоров куча, а в итоге нет-нет да и предется расчехлять скрипты на груви. И не дай бог влезть в житон, более багованной штуки еще не встречал.
А так приятно видеть, что найфай набирает обороты. Не так активно конечно, как эйрфлоу, но все же. Особенно отрадно видеть сетевых ребят в первом ряду (есть у вас коллеги с ним).
Ну и добро пожаловать в чатик в телеге: @nifiusersr3former Автор
06.12.2018 20:43Спасибо за комментарий! Приятно, что нашлись те, с кем можно поделиться опытом. Приглашение в тг-канал принял, уже там)
Немного поспорю с Вами:
Это все сохраняется и для найфая. Вернее как, бестпрактис и стандартные шаблоны выстраданы квалифицированной командой дев+опс, но никак не первым встречным, который в первый раз увидел найфай. Он просто уронит сервер, а вместе с ним и все остальные таски на нем. Ведь у найфай нет изоляции заданий, все крутится вместе
Согласен, но создать темплейты в nifi на все случаи жизни и описать бестпрактисы на вики, чтобы «новичок» смог сделать простые загрузки самостоятельно — это куда проще, чем объяснять flume/sqoop, линукс и написание скриптов на bash/python. Так то и про промышленные ETL-системы можно сказать, что бестпрактисы сложных задач выстраданы и человек «с улицы» все поломает.
Ситуация с балансировщиком остается и в случае найфая. Если у вас эндпойнт внутри кластера, то кто же будет клиентов перенаправлять на него в случае падения/обслуживания ноды?
И масштабирование у найфая весьма специфичное, только через РПГ, которые не работают внутри ПГ.
1. Если процессор предоставляет именно эндпоинт, то балансировщик нужен как и в случае flume. Если мы говорим про загрузку данных из kafka/hdfs/чего угодно, то все это как правило масштабируется в nifi.
2. РПГ уже не нужен для балансировки для случая, когда трафик идет с primary node. Это пофиксили в версии 1.8 и теперь балансировка работает на уровне connection, пруф. Про то, что РПГ не работают внутри ПГ — не очень понял. У меня в ПГ работает РПГ сейчас, что не так я делаю?barloc
07.12.2018 08:09Согласен, но создать темплейты в nifi на все случаи жизни и описать бестпрактисы на вики, чтобы «новичок» смог сделать простые загрузки самостоятельно — это куда проще, чем объяснять flume/sqoop, линукс и написание скриптов на bash/python.
И тут мы приходим к Apache Kylo :)
Многое, конечно, зависит от. Я наблюдал как опытный девопс делал первый етл на Nifi и получилось достаточно плохо. Оно работало, но без погружения именно в тонкости nifi — работало плохо и завешивало все серверы кластера.
И все равно внутри обмазано житонами, кафками и всякими секьюрными штуками, чтобы разобраться в которых нужна опсовская практика :)
Если мы говорим про загрузку данных из kafka/hdfs/чего угодно, то все это как правило масштабируется в nifi.
Не понял слова масштабируется в этом контексте. У меня опыт версии 1.2 — но масштабирования там особо нет, или все на примари, или РПГ.
РПГ уже не нужен для балансировки для случая, когда трафик идет с primary node. Это пофиксили в версии 1.8 и теперь балансировка работает на уровне connection, пруф.
А вот это круто. Как раз готовимся к миграции на 1.8. Значимый бонус, если это так.r3former Автор
07.12.2018 10:07Не понял слова масштабируется в этом контексте. У меня опыт версии 1.2 — но масштабирования там особо нет, или все на примари, или РПГ.
Kafka всеми нодами забирается без проблем, там же консамер группы. А hdfs/sftp, если говорить про чтение, с primary-ноды, потом через РПГ все разлетается на другие ноды. Если про запись говорить, то это из коробки работает, считай что пишется в несколько потоков в дестинейшн.barloc
07.12.2018 11:06Kafka всеми нодами забирается без проблем, там же консамер группы. А hdfs/sftp, если говорить про чтение, с primary-ноды, потом через РПГ все разлетается на другие ноды. Если про запись говорить, то это из коробки работает, считай что пишется в несколько потоков в дестинейшн.
Понятно, я то надеялся какой-то интересный механизм впилили, а все осталось примерно по разному :)
r3former Автор
07.12.2018 10:47За Kylo отдельное спасибо. Интересный проект и совсем молодой в этой индустрии. Я так понял, что он работает поверх NiFi и включает его в себя.
barloc
07.12.2018 11:08Нашлепка поверх найфая, которую можно отдать пользователям и в которую ты забиваешь как раз свои шаблоны и бестпрактис.
То есть позволяет ее дать малоопытным пользователям или ДС, которые сами смогут строить свои флоу. И при этом будет не так страшно, как на продовом кластере найфая.
В чатике дата инженеров есть Антон из Терадаты, у него хороший опыт с kylo.
Wayfarer15
06.12.2018 20:59И ни слова о том, что процессоры для NiFi можно самим написать. Правда документалки по этому делу маловато. Т.е. она как бы есть, но когда начинаешь реально делать, то оказывается, что многие моменты просто не описаны. Например, нужен ли AtomicReference для объектов и как правильно его сделать, чтобы все копии процесса по кластерам использовали только один объект, а не создавали его заново и т.п.
r3former Автор
06.12.2018 21:32В статье об этом есть информация:
Работа с конкретной СУБД реализуется за счет добавление соответствующего JDBC-драйвера. Есть API для написания своего модуля в качестве дополнительного приемника или преобразователя данных. Примеры можно найти здесь и здесь.
Предположу, что место для этого абзаца получилось не самым лучшим, и Вы не заметили. Подробно эту тему я не раскрывал, так как это все же краткий обзор. Информации местами действительно не хватает, но многие вещи описаны на портале Hortonworks и в mailing lists.Wayfarer15
06.12.2018 21:37Я видел эти «здесь и здесь». Для очень простого процессора это пойдёт, для сложного прихдится копаться в документации, но она, как я уже упомянул, оставляет желать лучшего по некоторым специфическим вопросам.
PS. У меня процессоры для HL7 и FHIR — конвертация из одного формата в другой, валидация, динамические аттрибуты и прочее подобное.
barloc
07.12.2018 08:12Ради интереса подскажтие, большой выигрыш в скорости по сравнению с скриптованием внутри ExecuteScript скажем на груви?
С документацией полный швах, по апи скриптов раньше было 3 заметки на сайте хортона и все.
sshikov
06.12.2018 21:46>мне совсем не хотелось поддерживать зоопарк решений
Хм. Не вижу в sqoop ничего сложного. Если у вас много баз данных — то это вполне себе несложное решение (со своими ограничениями, разумеется).r3former Автор
06.12.2018 21:51Речь не про сложность sqoop, а про совокупность решений. NiFi заменяет flume + sqoop + скрипты. Ведь куда приятнее работать с однородной инфраструктурой, а не когда у Вас на каждый чих отдельное решение.
sshikov
06.12.2018 21:55Да это понятно, но это все все равно до определенного момента. Нам уж как информатику хвалили, как универсальное решение, но постепенно народ нахлебался, и понял, что как только ты выходишь за пределы, которые авторы предусмотрели — так практически сразу и ку-ку. В этом смысле более узкоспециализированные инструменты были и будут лучше, и собрать решение из них можно более подходящее для себя (хотя возможно и большими усилиями).
P.S. Ни в коем случае не имел в виду агитировать за Sqoop. Он сам не без недостатков.r3former Автор
06.12.2018 22:15Вы не первый, от кого слышу такой отзыв про informatica) С NiFi у нас хронология несколько иная. Сначала долго тестировали и игрались, а уже потом начали переносить все продакшн-флоу на него. И ожидания от NiFi совершенно не те были, что от informatica. Для нас NiFi — это больше EL, чем ETL. Поэтому пока довольны.
zQQrra
r3former Когда разбирался с NiFi так и не понял, можно ли там делать что-то типа «проектов»/«разных рабочих областей». Когда в рабочей области становится много различных DataFlow еще и не связанных между собой, навигация между ними неудобна.
Как вы с этим боретесь? Или я что то не доглядел?
r3former Автор
Все делается на уровне process groups. Разные проекты выделяются в отдельные PGs, внутри которых подпроекты и задачи в свою очередь разделяются на другие PGs. Разделение прав делается также на уровне PGs.