Создавая новый проект, мне приходилось использовать либо *.resx для WinForms, либо I2Localization для Unity, либо другие решения для локализации приложений. Все эти решения похожи тем, что приходится придумывать ключ-локализации, вставлять его в код и в словарь. Поначалу все хорошо, но со временем этот процесс начинает раздражать. Вместе с тем, смотря на ключ в коде не всегда понятно о чем речь.
О ситуации когда нужно добавить локализацию в большой проект где её вообще не было, я даже говорить не буду как это сложно.
Не знаю почему, но оказывается существует уже давно такое готовое решение как gnu/gettext. Расспрашивая своих знакомых и коллег (тех кто работает с .NET), большинство даже и не слышал о таком. Поэтому решил поделиться с этим удобным инструментом.
Принцип прост. Вы пишите код со строками на английском языке, запускаете утилиту, которая сканирует исходники и предоставляет вам возможность перевода. Никаких ключей придумывать не надо. Текст на английском и есть ключ.
Приступим
1) Устанавливаем пакет NGettext через Nu-get:
PM> Install-Package NGettext
NGettext – кроссплатформенная реализация GNU/Gettext для .NET.
2) Добавляем в свой проект дополнительный файл, который немного упростит синтаксис:
https://github.com/neris/NGettext/blob/master/doc/examples/T.cs
Также добавляем директорию в проект, где будут хранится переводы:
MyProj\Loc\ru-RU\LC_Messages
В моем случае получается такая картина:

3) Добавляем пути в файл T.cs:
static T()
{
var localesDir = Path.Combine(Directory.GetCurrentDirectory(), "Loc");
_Catalog = new Catalog("Test", localesDir, new CultureInfo("ru-RU"));
}Упрощено. Для примера только русский. (Есть возможность считывать словари из самой сборки)
4) Пишем свой код с использованием локализации. Вместо “text” пишем T._(“text”)
namespace TestCode
{
static class Program
{
public static void Main(string[] args)
{
Console.WriteLine(T._("Hello, World!"));
Console.WriteLine(T._("Cat"));
Console.ReadKey();
}
}
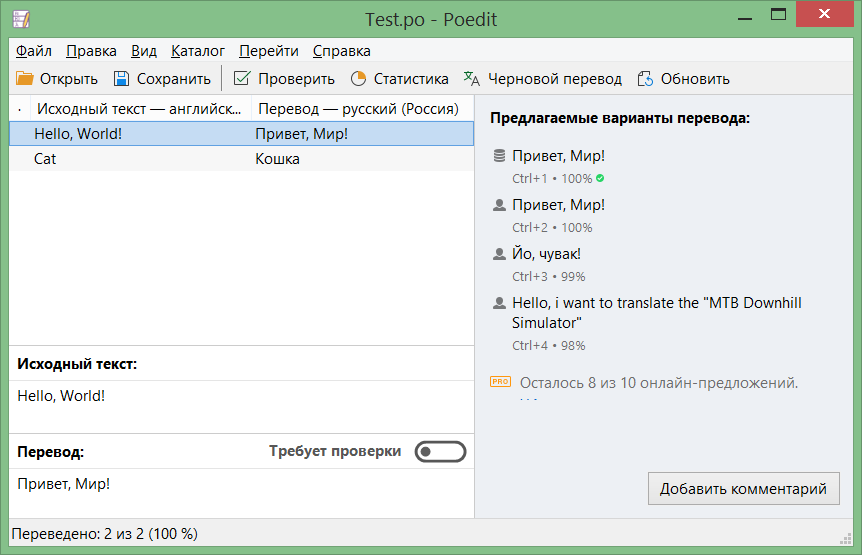
}5) Теперь нам необходимо перевести весь наш текст. Качаем PoEdit. Создаем файл перевода:
Файл > Создать > папка LC_MESSAGES > Test.po
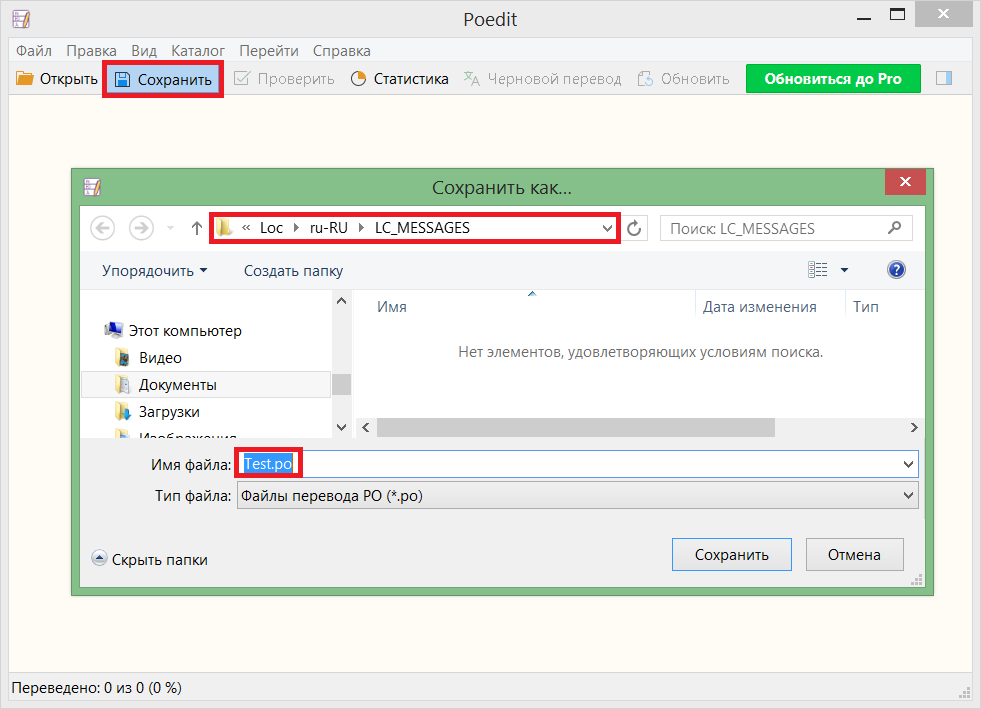
Указываем папку, в которой находятся наши исходники. Их программа будет сканировать:
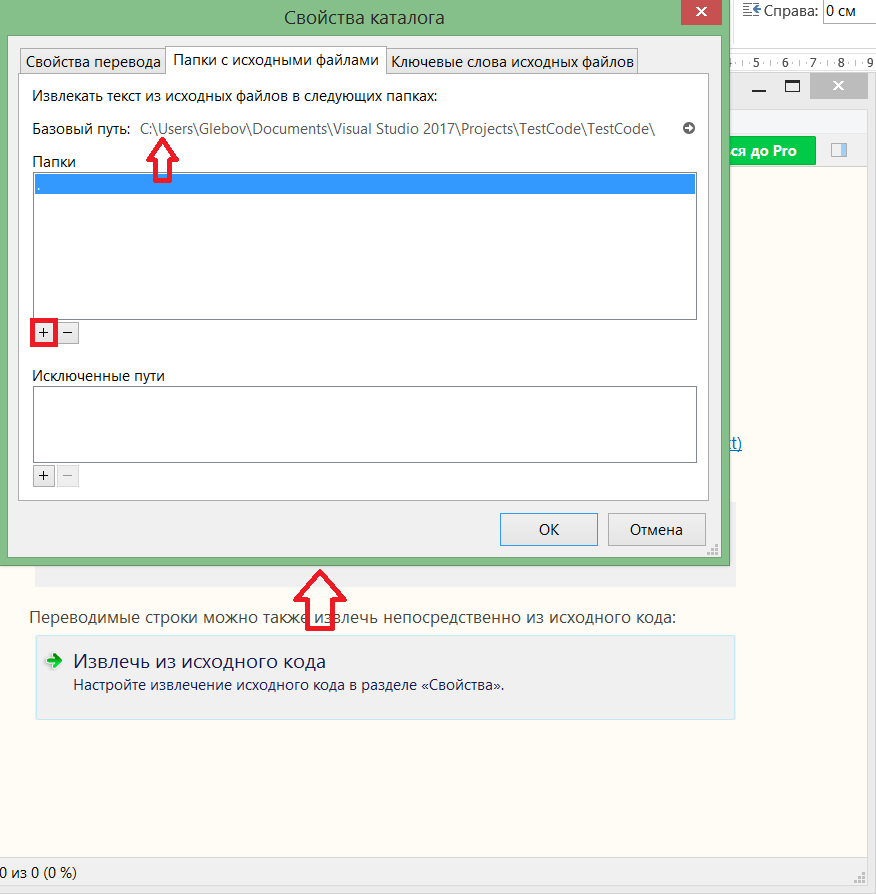
Так же необходимо указать ключевое слово, которое будет искать poEdit для перевода:
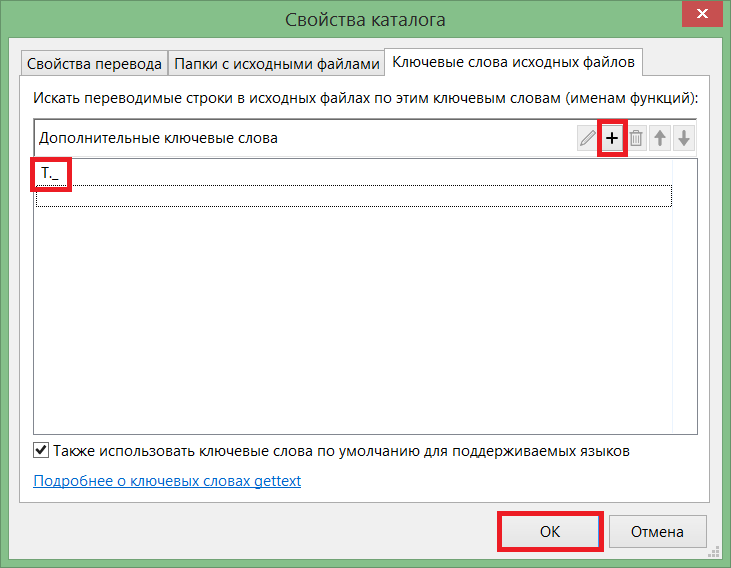
Добавляем нужный нам перевод и сохраняем.
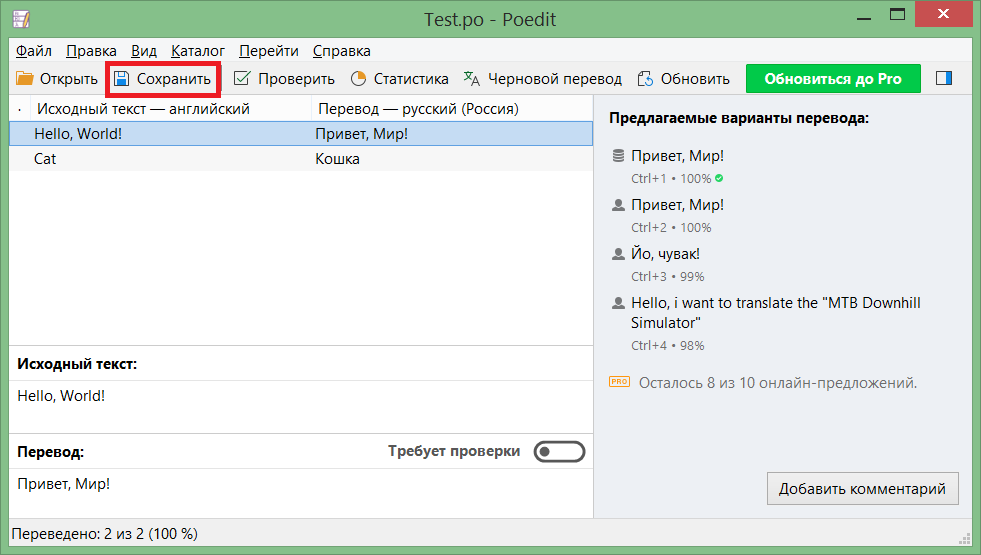
Добавляем файлы перевода в проект. Делаем их Copy always:
(Есть возможность встраивать их в саму сборку)

Готово. Запускаем:
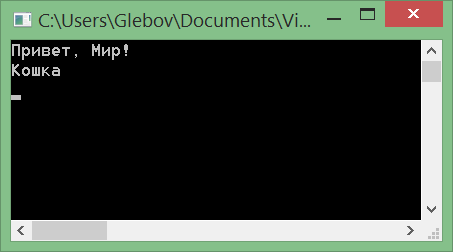
Настройка готова. Далее все просто. Пишите код – правите перевод
Также можно найти готовые библиотеки для локализации интерфейсов:
> WPF
> Дополнительная информация об использовании NGettext
> Информация о GNU/Gettext
Комментарии (28)

lowercase
11.12.2018 14:51+2А как поведет себя либа с омонимами? Ну то есть, например, есть у меня в исходном тексте два места в которых слово draw используется. Но в одном оно означает рисовать, а в другом — тянуть карты. Она позволит нормально в обоих местах перевести или тут будет коллизия?
GLeBaTi Автор
11.12.2018 14:53-2Использовать разные ключи. (Например draw_pic, draw_map)
lowercase
11.12.2018 15:02А, то есть, текст, который указывается в
T._()— это сам ключ? Я подумал, что это одновременно, и ключ, и дефолтный текст.GLeBaTi Автор
11.12.2018 15:06Вы правильно подумали. Это дефолтный текст. Нужно ещё en_US создать для переводчика, т.к. у программиста скорее всего будут ошибки в тексте.
mayorovp
11.12.2018 15:22+1Как-то тут обошли вниманием кучу острых углов, которые могут испортить всю локализацию...
Первое — омонимы и просто многозначные слова, уже упомянутые выше. Добавлю сюда также просто любые слишком короткие строки.
Вот свежий пример из локализации Stack overflow: слово "about" может быть переведено как "о компании", "о сайте", "об участнике" и еще кучей разных способов. Просто потому что прямой перевод — просто предлог "о" — слишком мал для ссылки или заголовка.
Второе — локализуемые сообщения никогда нельзя собирать конкатенацией. Только
string.Format, и переводить надо форматную строку целиком.
Третье — надо не забывать про согласование с числительными и оставлять переводчику достаточно инструментов для этих целей.
vp1000
11.12.2018 17:07Сам уже много лет пользуюсь локализацией gettext + poEdit для Windows приложений. Хоть и не .net.
1. Это не проблема. Всегда считаем что есть перевод с английского на английский и другие необходимые языки. Короткие слова и омонимы просто писать в виде развернутого ключа. Например «About company» а в переводе уже указывать нужный вариант.
2. Это действительно может быть проблемой. Сборку строк нужно производить не командой не format, а например записью в поток std::stringstream частей, каждая из которых переводится отдельно.
3. Вот переводчики самая большая проблема. Они не могу понять как пользоваться poEdit. Что нельзя нарушать форматирование строк. Что можно менять, а что нельзя. Приходится садиться и править текст вместе с переводчиком, а потом тестировать результат и править еще раз.
Изменения в коде править легко. poEdit подсвечивает все изменения и может предлагать варианты из готового словаря.mayorovp
11.12.2018 17:14+2Сборку строк нужно производить не командой не format, а например записью в поток std::stringstream частей, каждая из которых переводится отдельно.
Нет, нельзя так делать! Никакого "переводится отдельно"! У переводчика должна быть возможность задать формат для подставляемых значений, переставить части местами, или даже продублировать любую из них. Ничего из этого
std::stringstreamне дает.
3.Вот переводчики самая большая проблема. Они не могу понять как пользоваться poEdit. Что нельзя нарушать форматирование строк.Или вы не предоставили достаточных инструментов, из-за чего переводчикам теперь приходится подбирать структуру предложения под шаблон?
ingumsky
11.12.2018 17:25+2Вот переводчики самая большая проблема. Они не могу понять как пользоваться poEdit. Что нельзя нарушать форматирование строк. Что можно менять, а что нельзя. Приходится садиться и править текст вместе с переводчиком, а потом тестировать результат и править еще раз.
Не надо наговаривать на переводчиков. Если ваши переводчики не умеют пользоваться инструментом, с помощью которого вы хотите делать свою локализацию, это ваша проблема как заказчика — вероятно, вы пожалели денег на квалифицированных специалистов и/или не уделили внимание тому, соответствуют ли подрядчики вашим требованиям. Если вы сознательно берёте людей, зная, что они не владеют инструментом/технологией, которую вы используете, ваша задача — их научить и ответить на все их вопросы. В противном случае вы сам себе злобный буратино.vp1000
12.12.2018 10:01-1И не наговариваю. Переводчики на необходимые в работе языки у нас штатные сотрудники. Для выполнения наших задач от них требуется главным образом знание терминологии в конкретной технической области. Из-за загруженности переводчиков работой, им не до изучения новых технологий локализации, работа с которыми составляет 1% от их основной деятельности. Поэтому и приходится заниматься переводом совместно с переводчиком.
ingumsky
12.12.2018 14:25+1У вас противоречие — переводчики загружены вашей работой, но у них нет времени научиться использованию вашей технологии локализации. Так не бывает. Тем более, что gettext — распространённая технология, не требующая особой подготовки. Либо у вас переводчики — совсем не фонтан, либо вы «не умеете их готовить». Хорошие переводчики — прекрасно обучаемые специалисты, владеющие большим спектром технологий и разнообразным ПО, причём им неважно, какое именно ПО использует заказчик — перестроиться не составит проблемы. Многие способны частично автоматизировать свою работу, написав для этого скрипты и т.п. Это я вам говорю, как человек, который работает в области перевода и локализации 15 лет.
PS Минус не мой.vp1000
12.12.2018 17:26Переводчики загружены не моей работой, а работой компании. Переводом контрактов, переписки с заказчиками, тех. документации и пр. Локализация ПО для них разовая и не основная работа. Из за этого и проблемы.
ingumsky
13.12.2018 00:00ОК, так понятнее. Тогда, если позволите, мой совет:
Организуйте правильно работу с локализацией, займитесь этим всерьёз. Есть ощущение, что сейчас вы разгребаете проблемы, вызванные неправильной организацией. Я не знаю точно, как процесс организован у вас, поэтому рекомендации будут достаточно общими — давайте на перевод законченные строки, желательно с контекстом, чтобы переводчик смог понять и передать всё правильно. Не старайтесь добиться «атомарных значений» фрагментов — чем крупнее фрагмент для перевода, тем более точным и соответствующим оригиналу будет перевод. Не забывайте о том, что в разных языках могут быть различные правила грамматики (дополнительные времена, падежи, словоформы, формы множественного числа и части речи) и разные правила типографики, поэтому, с одной стороны, обеспечьте переводчику возможность «манёвра», с другой, оставьте порядок следования слов на усмотрение переводчика. Ну и, разумеется, не забывайте о том, что в разных языках одна и та же фраза может значительно отличаться по длине, поэтому должен быть запас по ограничению символов.
Johan
11.12.2018 19:54+2- Боюсь, вам не удастся угадать все случаи, когда одно и то же английское слово переводится по разному в зависимости от контекста. К тому же, использование развёрнутого ключа, в моём понимании, уже стремится к тем самым идентификаторам, от которых хотел избавиться автор.
- Переводы частей отдельно, возможно, и являются причиной проблем с переводчиками. Языки не всегда подчиняются законам, которые кажутся логичными. Законченный текст должен переводится целиком без всяких склеек.
gdt
12.12.2018 03:21+1Вам, наверное, никогда не приходилось иметь дела с арабским языком.
vp1000
12.12.2018 10:06Пока не приходилось ни с арабским ни с китайским. Целевые языки заранее известны. Пытаюсь адаптировать фразы в в приложении для универсального использования во всех языках. Пока получалось. Хотя я согласен со всеми комментаторами указывающими на недостатки моего подхода.
gdt
12.12.2018 10:12Проблема арабского языка — в написании справа налево. А когда в дело вступает форматирование (я имею ввиду подстановку цифр, дат, денежных значений и т. д.) — становится совсем невесело.
Лично я не против вашего подхода, но на мой взгляд он менее универсальный, конечно это не смертельно, если вы не планируете расширять список используемых языков.vp1000
12.12.2018 10:36Оборудование, в состав которого входит обсуждаемое ПО, поставлялось в том числе и в ОАЭ с английским языком интерфейса. Требований по локализации заказчик не выдвигал. Поэтому с этими проблемами и не столкнулся.
immaculate
12.12.2018 04:25В gettext (вообще, не знаю насчет данной конкретной реализации) естественно есть инструменты для согласования числительных (ngettext) и для добавления контекста к строке для переводчика. В более развитых редакторах, чем упоминаемый poedit, есть также дополнительные средства, в частности, к строкам можно прикреплять скриншоты приложения, чтобы переводчики видели, где именно используется строка.
alex1t
12.12.2018 12:27+2Тоже работаем с NGetText. В принципе всё устраивает. Работа с числительными там кстати есть — формат gettext это поддерживает. В коде вместе с текстом передается число (n) — для которого мы хотим получить форму. В целевом языке перевода (*.po-файле) задаётся правило для числительных, которое по сути по формуле вычисляет «категорию» числительной формы. Например в английском — всего две категории (day/days), а в русском уже 3 (2 дня/ 5 дней/ 21 день). В файле перевода соответственно и пишутся по 3 варианта фразы с разными словоформами множественного числа + одна словоформа единственного числа
Leopotam
Что произойдет со старой записью, когда поменяется английский текст-ключ в исходниках? Просто все потеряется и нужно будет заново выполнять локализацию? А если там просто фикс синтаксиса?
GLeBaTi Автор
Каждый ключ в *.po-файле ссылается на конкретный файл.
gettext генерирует новый *.po-файл и делает какой-то умный merge со старым.
Я пробовал менять несколько букв, изменять положение строки и т.п. Весь перевод остался, просто подсвечиваются измененные перед сохранением.
Leopotam
Т.е. неконтролируемая магия. Ясно-понятно. Проще по-старинке — через гуглодоки, ключи и без явной зависимости от внешнего софта и бинарных форматов.
GLeBaTi Автор
Контролируемая. Вам в редакторе подсветятся все изменения. Это как git merge делать.
На среднем проекте у меня пока не возникало проблем. Интересно было бы услышать мнение людей использующих gettext в больших проектах
yajohn
Да, потеряется, но не все, а только один перевод. Костыль — псевдоперевод с английского на английский. Что иногда оправдано само по себе, поскольку исходники пишет программист, а переводит — профессиональный переводчик.
immaculate
Такие строки никуда не исчезают, а помечаются утилитами gettext флагом fuzzy. Потом можно отредактировать строку с учетом изменений, и снять флаг fuzzy.
В нормальных инструментах для перевода (poEdit не пользовался около 10-12 лет, так что не помню, есть ли в нем это) есть еще память переводов, глоссарий, подсказки, и многое другое.
Например, сейчас пользуюсь Weblate для перевода нескольких проектов. Изумительная вещь, и переводчикам ничего объяснять не приходится.