
На мой взгляд, стохастические исчисления — это один из тех великолепных разделов высшей математики (наряду с топологией и комплексным анализом), где формулы встречаются с поэзией; это место, где они обретают красоту, место где начинается простор для художественного творчества. Многие из тех, что прочли статью Винеровский хаос или Еще один способ подбросить монетку, даже если и мало, что поняли, всё же смогли оценить великолепие этой теории. Сегодня мы с вами продолжим наше математическое путешествие, мы погрузимся в мир случайных процессов, нетривиального интегрирования, финансовой математики и даже немного коснемся функционального программирования. Предупреждаю, держите наготове свои извилины, так как разговор у нас предстоит серьезный.

Кстати, если вам интересно прочитать в отдельной статье, как вдруг оказалось, что я добавил внизу опрос, где вы можете оставить свой голос.
Скрытая угроза фракталов
Представьте себе какую-нибудь простую функцию на некотором интервале . Представили? В стандартном математическом анализе мы привыкли к тому, что если размеры этого интервала достаточно долго уменьшать, то данная нам функция начинает вести себя довольно гладко, и мы можем приблизить её прямой, в крайнем случае, параболой. Все благодаря теореме о разложении функции, сформулированной английский ученым Бруком Тэйлором в 1715-м году: Этой теоремой искусно орудуют современные математики-инженеры, аппроксимируя всё подряд для своих численных вычислений. Но на фракталах такая схема даёт сбой.
К тому моменту как Бенуа Мандельброт придумал само понятие «фракталов», они уже сотню лет не давали спать многим мировым ученым. Одним из первых, кому фракталы подмочили репутацию, стал Андре-Мари Ампер. В 1806 году ученый выдвинул довольно убедительное «доказательство» того, что любую функцию можно разбить на интервалы из непрерывных функций, а те в свою очередь, благодаря непрерывности, должны иметь производную. И многие его современники-математики с ним согласились. Вообще, Ампера нельзя винить в этой, с виду довольно грубой, ошибке. Математики начала XIX века имели довольно расплывчатое определение таких ныне столь базовых концепций мат.анализа как непрерывность и дифференцируемость, и, как следствие, могли сильно ошибаться в своих доказательствах. Не исключением были даже такие именитые ученые как Гаусс, Фурье, Коши, Лежандр, Галуа, не говоря уже о куда менее известных математиках тех времен.
Тем не менее, в 1872 году гипотезу о существовании производных у непрерывных функций опроверг Карл Вейерштрасс, представив на обозрение первого в мире фрактального монстра, всюду непрерывного и нигде не дифференцируемого.
Вот, к примеру, как задается подобная функция:
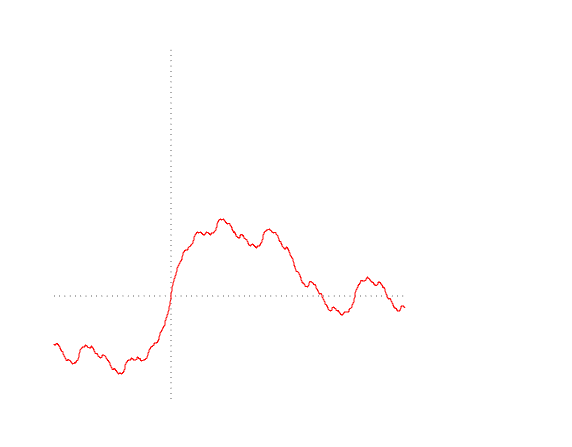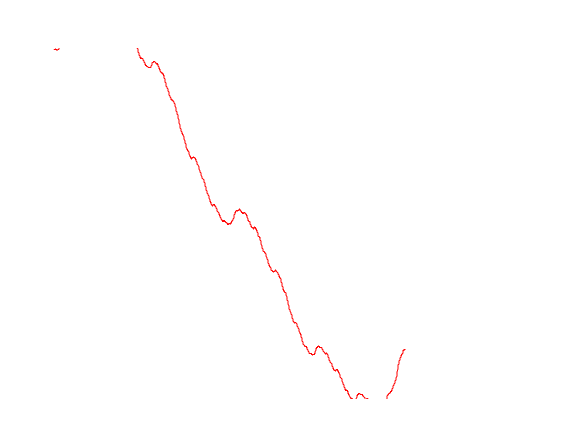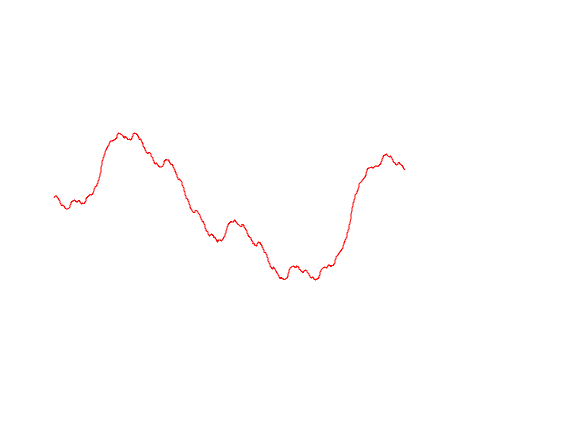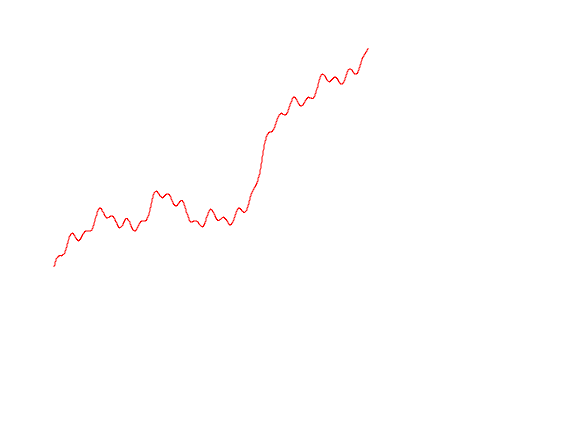
Таким же свойством обладает и Броуновское движение (кстати, почему-то не Брауновское, фамилия-то британская, всё же). Броуновское движение — это непрерывный случайный процесс , такой что все его приращения независимы и имеют нормальное распределение: Траектории Броуновского движения являются фрактальными функциями, они непрерывны всюду и всюду негладки. Но если функция Вейерштрасса являлась лишь контрпримером, пускай и одним из ярчайших за всю историю математического анализа, то Броуновское движение обещало стать фундаментом стохастической теории, и с ним надо было как-то научиться работать.
Бесконечная вариация Броуновского движения
Давайте снова представим себе функцию на интервале и разобьем этот интервал на множество из непересекающихся подынтервалов: Нам неважно как распределены точки , разбивающие этот интервал, куда более интересен размер максимального шага: Мы назовем величину вариацией (первого рода) функции (также именуемой общей вариацией). Если , то мы скажем, что обладает конечной вариацией. Например, вариация достаточно «гладкой» функции

будет конечной. В каком случае мы не столь уверены? Ну, например, конечной вариации не будет у функции возвращающей для всех рациональных и для всех иррациональных. Подобную логику можно расширить и на случайные функции. Пускай — это случайный процесс. Вариация для него задаётся аналогичным образом: Единственная разница — вариация тоже станет случайной (параметр можно для удобства опустить, но он здесь как бы намекает, что вариация от случайного процесса — это отображение из пространства случайных событий в ).
Вот, как будет выглядеть довольно простая реализация вариации на Хаскеле:
-- | 'totalVariation' calculates total variation of the sample process X(t)
totalVariation :: [Double] -- process trajectory X(t)
-> Double -- V(X(t))
totalVariation x@(_:tx) = sum $ zipWith (\x xm1 -> abs $ x - xm1) tx x
Где в реальном мире встречаются случайные процессы? Один из известнейших примеров сегодня — финансовые рынки, а именно движение цен на валюту, акции, опционы и различные ценные бумаги. Пускай — это стоимость акции Apple. В какой-то момент времени вы решили купить акций по цене , а через некоторый промежуток времени цена изменилась и стала равна . В результате у вас чистой прибыли/убытка, где . Вы решили докупить/продать часть акций и теперь вы держите на руках ценных бумаг. Через некоторое время ваш доход/потери составят , и т.д. В конце концов, вы заработаете/потеряете Все довольно просто, но вот загвоздка: процесс изменения цены на акцию может двигаться очень быстро, как и наш процесс её покупки/продажи (так называемый High Frequency Trading). Хотелось бы расширить эти вычисления на непрерывные процессы и представить наши доходы в виде интеграла наподобие Проблема в том, что мы пока не знаем каким образом брать интегралы по случайным процессам и их траекториям. Но мы помним по какому принципу определяется стандартный интеграл Лебега(-Стилтьеса). Обычно сначала нужно задать соответствующую меру. Возьмем неубывающий процесс , для простоты начинающийся с нуля: , и неотрицательную меру, соответствующую его приращениям Если функция ограниченная и измеримая (вспоминаем функциональный анализ) мы можем определить для неё интеграл на интервале в виде Для общего случая, если траектории случайного процесса не обладают монотонностью, мы можем разделить его на два неубывающих процесса: и тогда мы определим интеграл Лебега как Необходимое условие для существования такого интеграла — это существование . Действительно, если наш процесс состоит из разницы двух неубывающих процессов, то у него существует конечная вариация (во второй строке мы воспользовались неравенством треугольника): Кстати, это условие работает и в обратном направлении: если у нас есть процесс с конечной вариацией, то мы можем определить и . Монотонность и равенство легко доказываются.
Теперь мы с легкостью можем что-нибудь проинтегрировать. Возьмем траекторию какого-нибудь непрерывного случайного процесса и обзовём её . С помощью теоремы Лагранжа о среднем можно показать, что для непрерывной функции вариация будет равна . Если этот интеграл существует, то при упомянутых выше условиях ограниченности и измеримости мы сможем посчитать Это действительно несложно. А как насчет фракталов, траекторий типа монстра Вейерштрасса? Ведь для них не существует .

Итак вопрос: можно ли взять интеграл в смысле Лебега от Броуновского движения? Посчитаем вариацию, и если она будет конечной, то у нас не должно быть никаких проблем. Давайте зайдем со стороны так называемой квадратичной вариации: Чему, по-вашему, равен этот предел? Мы рассмотрим случайную величину и покажем, что её дисперсия равняется нулю: где стандартная нормально распределенная величина. В частности, так как все независимы и имеют распределение хи-квадрат со степенью 1, несложно подсчитать, что Следовательно, Иначе говоря, Запомните эту формулу! Она является фундаментом стохастического анализа, своеобразным местным аналогом центральной предельной теоремы, и все остальные теоремы явно и неявно крутятся вокруг неё.
Заметьте, что , однако методы подсчёта этих двух величин совсем разные. Дисперсия Броуновского движения считается усреднением всех его траекторий, учитывая их вероятности. Квадратичная вариация же берется из одной единственной случайной траектории, по которой произошло движение, и вероятности здесь роли не играют. В то время как дисперсия может быть посчитана только теоретически, так как требует усреднения всех реализаций, квадратичная реализация может быть посчитана явно (с достаточным значением дискретизации данных). Указанная выше формула интересна в частности тем, что по определению квадратичная вариация, как и вариация первого рода является случайной величиной. Однако, фича Броуновского движения в том, что его квадратичная вариация вырождается и принимает лишь одно единственное значение, соответствующее длине интервала, независимо от того, по какой траектории происходило движение.
Напишем код, считающий квадратичную вариацию реализации случайного процесса :
-- | 'quadraticVariation' calculates quadratic variation of the sample process X(t)
quadraticVariation :: [Double] -- process trajectory X(t)
-> Double -- [X(t)]
quadraticVariation x@(_:tx) = sum $ zipWith (\x xm1 -> (x - xm1) ^ 2) tx x
Итак, теперь мы готовы вернуться к подсчету интересующей нас вариации . Мы выяснили, что То есть, это ненулевая, но и не бесконечная величина. С другой стороны, она ограничена сверху максимальным шагом разбитого :
Мы знаем, что Броуновское движение — процесс непрерывный, а значит Однако, И, как следствие,
Н-да…

Интеграл Ито или Новая надежда
В 1827 году английский ботаник Роберт Браун, наблюдая пыльцевые зерна в воде через микроскоп, заметил, что частицы внутри их полости двигаются определенным образом; однако он тогда не смог определить механизмы, вызывавшие это движение. В 1905 году Альберт Эйнштейн опубликовал статью, в которой подробно объясняется, как движение, наблюдаемое Брауном, было результатом того, что пыльца перемещается отдельными молекулами воды. В 1923 году вундеркинд и «отец кибернетики» Норберт Винер написал статью о дифференцируемых пространствах, где подошел к этому движению со стороны математики, определил вероятностные меры в пространстве траекторий и, используя концепцию интегралов Лебега, заложил фундамент стохастического анализа. С тех пор в математическом сообществе Броуновское движение также именуется Винеровским процессом.
В 1938 году выпускник Токийского университета Киёси Ито начинает работать в Бюро по статистике, где в свободное время знакомится с работами основателя современной теории вероятности Андрея Колмогорова и французского ученого Поля Леви, изучающего на тот момент различные свойства Броуновского движения. Он пытается соединить воедино интуитивные видения Леви с точной логикой Колмогорова, и в 1942 году пишет работу «О стохастических процессах и бесконечно делимых законах распределения», в которой реконструирует с нуля концепцию стохастических интегралов и связанную с ней теорию стохастических дифференциальных уравнений, описывающих движения, вызванные случайными событиями.
Интеграл Ито для простых процессов
Ито разработал довольно простой способ построения интеграла. Для начала мы определим интеграл Ито для простого кусочно-постоянного процесса , а затем расширим это понятие на более сложные интегранды. Итак, пускай у нас снова есть разбиение . Мы считаем, что значения постоянны на каждом интервале

Представим, что — это стоимость какого-либо финансового инструмента в момент (Броуновское движение может принимать отрицательные значения, поэтому это не очень хорошая модель для движения цены, но сейчас мы это проигнорируем). Пускай также — это торговые дни (часы/секунды, не важно), а — это наши позиции (количество финансовых инструментов на руках). Мы считаем, что зависит только от информации, известной в момент . Под информацией я имею ввиду траекторию Броуновского движения до этого момента времени. Тогда наш доход будет составлять: Процесс называется интегралом Ито для простого процесса и мы будем его записывать в виде
У этого интеграла есть несколько интересных свойств. Первое и довольно очевидное: в начальный момент его математическое ожидание в любой точке равно нулю: Более того, интеграл Ито является мартингалом, но об этом позже.
Расчет второго момента/дисперсии уже требует дополнительных расчётов. Пускай для и . Тогда мы можем переписать интеграл Ито в виде Воспользовавшись тем, что и тем, что и независимы для мы можем рассчитать Равенство называется изометрией Ито.
И, наконец, квадратичная вариация. Давайте сначала посчитаем вариацию на каждом интервале , где значения постоянны, а потом сложим их все вместе. Возьмем разбиение интервала и рассмотрим Аналогично считается квадратичная вариация для интервала . Суммируя все эти кусочки, мы получаем
Теперь мы можем ясно видеть разницу между дисперсией и вариацией. Если процесс является детерминированным, то они совпадают. Но если мы решим менять нашу стратегию в зависимости от траектории, по которой прошло Броуновское движение, то и вариация начнет меняться, в то время как дисперсия всегда равна определенному значению.
Интеграл Ито для сложных процессов
Теперь мы готовы расширить понятие интеграла Ито на более сложные процессы. Пускай у нас есть функция , которая может непрерывно измениться во времени и даже иметь разрывы. Единственные предположения, которые мы хотим сохранить — это квадратичная интегрируемость процесса: и адаптируемость, т.е. на момент , когда мы знаем значение , мы уже должны знать также значение . В реальном мире мы не можем сначала узнать стоимость акций на завтра, а затем в них вложиться.
Для того, чтобы определить мы аппроксимируем простыми процессами. На графике ниже показано, как это можно сделать.
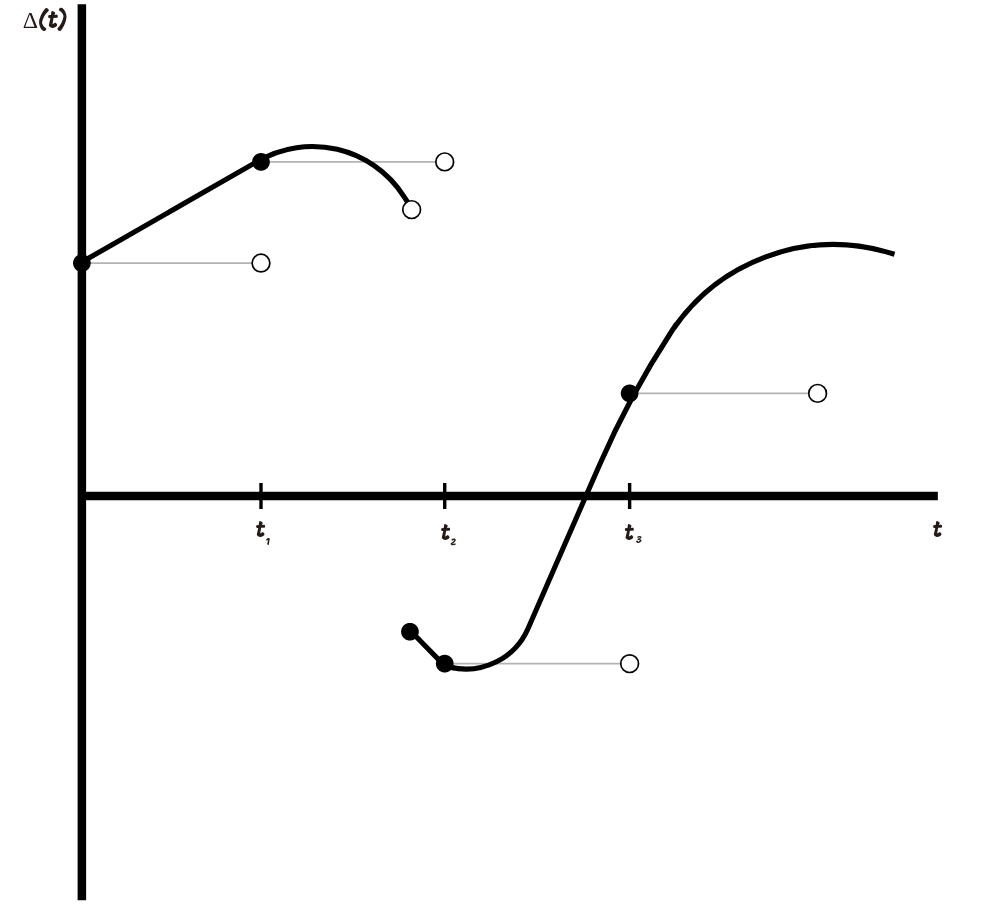
Аппроксимация происходит следующим образом: мы выбираем разбиение , затем создаем простой процесс, чьи значения равны для каждого и не изменяются на отрезке . Чем меньше становится максимальный шаг нашего разбиения, тем ближе становится аппроксимирующий простой процесс к нашему интегранду.
В общем случае, возможно выбрать последовательность простых процессов , такую что она будет сходиться к . Под сходимостью мы имеем ввиду Для каждого процесса интеграл Ито уже определен и мы определяем интеграл Ито для непрерывно изменяющегося процесса как предел: Интеграл Ито в общем случае обладает следующими свойствами:
- Его траектории непрерывны
- Он адаптирован. Логично, ведь в каждый момент времени мы должны знать наше значение дохода.
- Он линеен:
- Он мартингал, но об этом ближе к концу статьи.
- Сохраняется изометрия Ито: .
- Его квадратичная вариация:
Небольшая ремарка: для тех, кто хочет более подробно изучить конструирование интеграла Ито или вообще увлекается финансовой математикой, очень советую книгу Steven Shreve «Stochastic Calculus for Finance. Volume II».
Покодим?
Для последующих рассуждений мы будем обозначать интеграл Ито в несколько ином виде: для некоторого . Таким образом, мы подготавливаем себя к мысли о том, что интеграл Ито — это отображение, действующее из пространства квадратично интегрируемых функций в вероятностное пространство случайных процессов. Так например, можно перейти от старой нотации к новой:
В предыдущей статье мы реализовали Гауссовский процесс: . Мы знаем, что Гауссовский процесс — это отображение из гильбертова пространства в вероятностное, что по сути является обобщенным случаем интеграла Ито, отображения из пространства функций в пространство случайных процессов. Действительно,
data L2Map = L2Map {norm_l2 :: Double -> Double}
type ItoIntegral = Seed -- ?, random state
-> Int -- n, sample size
-> Double -- T, end of the time interval
-> L2Map -- h, L2-function
-> [Double] -- list of values sampled from Ito integral
-- | 'itoIntegral'' trajectory of Ito integral on the time interval [0, T]
itoIntegral' :: ItoIntegral
itoIntegral' seed n endT h = 0 : (toList $ gp !! 0)
where gp = gaussianProcess seed 1 (n-1) (\(i, j) -> norm_l2 h $ fromIntegral (min i j + 1) * t)
t = endT / fromIntegral n
Функция itoIntegral' принимает на вход seed — параметр для генератора случайных величин, n — размерность выходного вектора, endT — параметр и функцию h из класса L2Map, для которой определена функция norm_l2, возвращающая норму интегранда: . На выходе itoIntegral выдает реализацию интеграла Ито на интервале с частотой дискретизации, соответствующей параметру n. Естественно, подобный способ реализации интеграла Ито — это в некотором смысле overkill, но он позволяет настроиться на функциональное мышление, столь необходимое для дальнейших рассуждений. Мы запишем более быструю реализацию, не требующую работы с гигантскими матрицами.
-- | 'mapOverInterval' map function f over the interval [0, T]
mapOverInterval :: (Fractional a) => Int -- n, size of the output list
-> a -- T, end of the time interval
-> (a -> b) -- f, function that maps from fractional numbers to some abstract space
-> [b] -- list of values f(t), t \in [0, T]
mapOverInterval n endT fn = [fn $ (endT * fromIntegral i) / fromIntegral (n - 1) | i <- [0..(n-1)]]
-- | 'itoIntegral' faster implementation of itoIntegral' function
itoIntegral :: ItoIntegral
itoIntegral seed 0 _ _ = []
itoIntegral seed n endT h = scanl (+) 0 increments
where increments = toList $ (sigmas hnorms) * gaussianVector
gaussianVector = flatten $ gaussianSample seed (n-1) (vector [0]) (H.sym $ matrix 1 [1])
sigmas s@(_:ts) = fromList $ zipWith (\x y -> sqrt(x-y)) ts s
hnorms = mapOverInterval n endT $ norm_l2 h
Теперь с помощью этой функции, мы можем реализовать, например, обыкновенное Броуновское движение: . Функция h будет функцией, у которой норма norm_l2 будет , тождественной функцией.
l2_1 = L2Map {norm_l2 = id}
-- | 'brownianMotion' trajectory of Brownian motion a.k.a. Wiener process on the time interval [0, T]
brownianMotion :: Seed -- ?, random state
-> Int -- n, sample size
-> Double -- T, end of the time interval
-> [Double] -- list of values sampled from Brownian motion
brownianMotion seed n endT = itoIntegral seed n endT l2_1
Попробуем нарисовать различные варианты траекторий Броуновского движения
import Graphics.Plot
let endT = 1
let n = 500
let b1 = brownianMotion 1 n endT
let b2 = brownianMotion 2 n endT
let b3 = brownianMotion 3 n endT
mplot [linspace n (0, lastT), b1, b2, b3]

Самое время перепроверить наши предыдущие вычисления. Давайте посчитаем вариацию траектории Броуновского движения на интервале .
Prelude> totalVariation (brownianMotion 1 100 1)
8.167687948236862
Prelude> totalVariation (brownianMotion 1 10000 1)
80.5450335433388
Prelude> totalVariation (brownianMotion 1 1000000 1)
798.2689137110999
Мы можем наблюдать, что при увеличении точности вариация принимает все большие и большие значения, в то время как квадратичная вариация стремится к :
Prelude> quadraticVariation (brownianMotion 1 100 1)
0.9984487348804609
Prelude> quadraticVariation (brownianMotion 1 10000 1)
1.0136583395467458
Prelude> quadraticVariation (brownianMotion 1 1000000 1)
1.0010717246843375
Попробуйте позапускать вычисления вариаций для произвольных интегралов Ито, чтобы убедиться в том, что вне зависимости от траектории движения.
Мартингалы
Есть такой класс случайных процессов — мартингалы. Для того, чтобы был мартингалом, необходимо выполнение трех условий:
- Он адаптирован
- почти всюду конечно:
- Условное математическое ожидание будущего значения равняется его последнему известному значению:
Броуновское движение — мартингал. Выполнение первого условия очевидно, выполнение второго условия следует из свойств нормального распределения. Третье условие также легко проверяется: Интеграл Ито тоже мартингал (оставим доказательство в качестве упражнения). О чем это нам говорит? Вернемся к финансовой математике и представим, что стоимость на выбранные нами акции — это Броуновское движение (предположение довольно наивное, но все же представим), а — это наша стратегия, количество акций в нашем портфеле. Процесс может быть случайным: мы не всегда знаем сильно заранее сколько акций мы захотим сохранить, будем исходить из движения цены . Но главное, чтобы этот процесс был адаптирован, то есть на момент мы точно знаем, сколько акций у нас лежит. Мы не можем вернуться в прошлое и поменять это значение. Так вот, так как интеграл Ито — это мартингал, то абсолютно неважно какой мы выберем стратегию , в среднем выигрыш от нашей торговли всегда будет уходить в ноль.
Есть еще одна интересная теорема, так называемая теорема о представлении мартингала: если у нас есть мартингал , чьи значения определяются Броуновским движением, то есть единственный процесс, вносящий неопределенность в значения , — это , то этот мартингал можно представить в виде притом процесс единственен. В дальнейшем, когда мы увеличим количество интегралов и даже расширим их на неадаптированные процессы, эта теорема нам очень поможет.
А на сегодня всё.

Комментарии (4)

S_A
25.12.2018 17:19Если расскажете, как восстановить параметры случайных процессов по известным данным — цене такой статье вот не будет.
sgn
26.12.2018 00:19Про лемму Ито-Дёблинга надо определенно писать хотя бы ради истории жизни самого Дёблинга и его неизвестной прорывной работы, которая хранилась в запечатанном конверте 60 лет после его смерти.
en.wikipedia.org/wiki/Wolfgang_Doeblin
Hedgehogues
26.12.2018 02:22У меня много вопросов. Я начну с одного, простого. А потом, если Вам не лень, быть может, Вы ответите на остальные. Правильно ли я понял, что вариация первого рода — это сумма Дарбу? Отсюда, фактически, если мы покажем, что правый и левый предел совпадают, то мы покажем, что верхняя и нижняя суммы Дарбу совпадают.
P.s. правда, в сумма Дарбу фигурируют inf, sup. Но, кажется, что это примерно эквивалентные вещи. Думаю, что это можно показать.
Tsvetik
Так как же все-таки взять интеграл от функции Вейерштрасса?