Я работаю в команде платформы Одноклассников и сегодня расскажу про архитектуру, дизайн и детали реализации сервиса раздачи музыкальных треков.
Немного статистики
Сначала пару слов про ОК. Это гигантский сервис, которым пользуются больше 70 млн пользователей. Их обслуживают 7 тыс. машин в 4 дата-центрах. Недавно по трафику мы пробили отметку в 2 Тб/сек без учёта многочисленных CDN площадок. Мы выжимаем из нашего железа максимум, самые нагруженные сервисы обслуживают до 100 000 запросов в секунду с четырёхъядерной ноды. При этом практически все сервисы написаны на Java.
В ОК множество разделов, один из самых популярных — «Музыка». В нём пользователи могут загружать свои треки, покупать и скачивать музыку в разном качестве. В разделе есть замечательный каталог, система рекомендаций, радио и многое другое. Но главное предназначение сервиса, конечно же, — это проигрывание музыки.
Передачей данных в пользовательские плейеры и мобильные приложения занимается раздатчик музыки. Его можно выловить в веб-инспекторе, если посмотреть запросы к домену musicd.mycdn.me. API раздатчика предельно прост. Он отвечает на HTTP-запросы
GET и выдает запрашиваемый диапазон трека.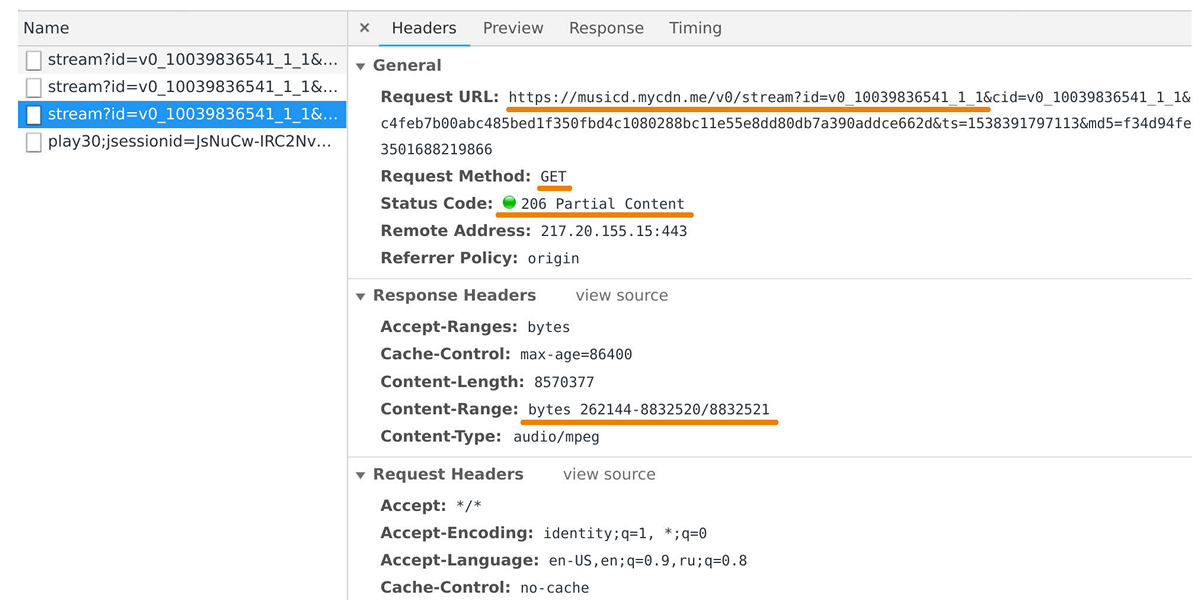
В пике нагрузка достигает 100 Гб/с через полмиллиона соединений. По сути, раздатчик музыки является кэширующим фронтендом перед нашим внутренним хранилищем треков, которое сделано на базе One Blob Storage и One Cold Storage и содержит петабайты данных.
Раз я заговорил о кэшировании, давайте посмотрим на статистику проигрываний. Мы видим ярко выраженный ТОП.
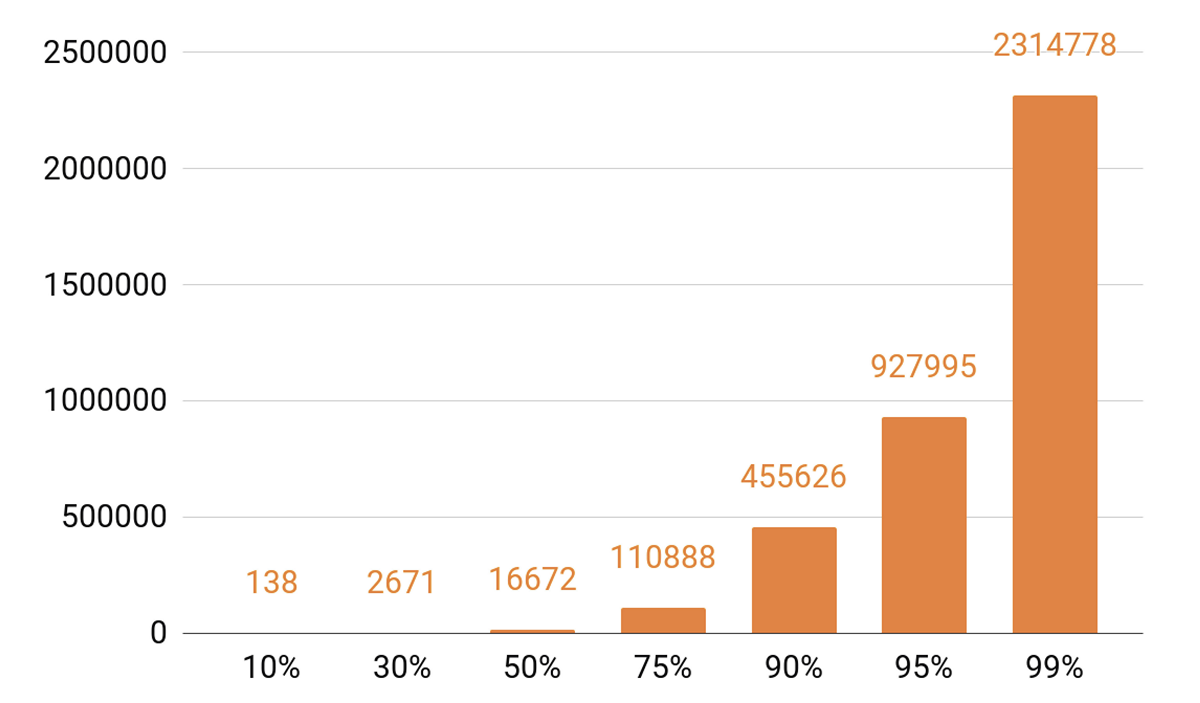
Примерно 140 треков покрывают 10% всех прослушиваний за день. Если мы хотим, чтобы наш кэширующий сервер имел cache hit хотя бы 90%, то нужно, чтобы в него помещалось полмиллиона треков. 95% — почти миллион треков.
Требования к раздатчику
Какие цели мы ставили перед собой при разработке очередной версии раздатчика?
Мы хотели, чтобы одна нода могла держать 100 тыс. соединений. Причем это медленные клиентские соединения: куча браузеров и мобильных приложений через сети с варьирующей скоростью. При этом сервис, как и все наши системы, должен быть масштабируемым и отказоустойчивым.
В первую очередь нам нужно масштабировать пропускную способность кластера, чтобы поспевать за ростом популярности сервиса и уметь отдавать всё больше трафика. Также необходимо уметь масштабировать суммарную емкость кэша кластера, потому что от неё непосредственно зависит cache hit и доля запросов, которая будет попадать в хранилище треков.
Сегодня обязательно быть способным масштабировать любую распределенную систему горизонтально, то есть добавлять машины и дата-центры. Но мы хотели реализовать и вертикальное масштабирование. Наш типичный современный сервер содержит 56 ядер, 0,5—1 ТБ оперативной памяти, сетевой интерфейс на 10 или 40 Гбит и десяток SSD дисков.
Говоря о горизонтальной масштабируемости, возникает интересный эффект: когда у тебя тысячи серверов и десятки тысяч дисков, постоянно что-то ломается. Отказ дисков — это рутина, мы меняем их по 20—30 штук в неделю. И отказы серверов никого не удивляют, 2—3 машины в день идут под замену. Приходилось сталкиваться и с отказами дата-центров, например, в 2018 году таких отказов было три, и это, наверняка, не в последний раз.
К чему я это всё? Когда мы проектируем любые системы, то знаем, что они рано или поздно сломаются. Поэтому всегда тщательно прорабатываем сценарии отказов всех компонентов системы. Основной способ борьбы с отказами — резервирование с помощью репликации данных: на разных нодах хранится несколько копий данных.
Также мы резервируем пропускную способность сетей. Это важно, потому что при отказе какого-то компонента системы нельзя допустить, чтобы рост нагрузки на остальные компоненты обрушил систему.
Балансировка
Сначала нужно научиться балансировать пользовательские запросы между дата-центрами, причём делать это автоматически. Это на тот случай, если нужно провести сетевые работы, или если дата-центр отказал. Но балансировка нужна и внутри дата-центров. Причем распределять запросы между нодами мы хотим не рандомно, а с весами. Например, когда мы выкладываем новую версию сервиса и хотим новую ноду плавно ввести в ротацию. Также веса очень помогают при нагрузочном тестировании: мы повышаем вес и заводим на ноду гораздо бо?льшую нагрузку, чтобы понять пределы её возможностей. А когда нода отказывает под нагрузкой, мы оперативно обнуляем вес и выводим её из ротации, используя механизмы балансировки.
Как выглядит путь запроса от пользователя к ноде, которая вернет данные с учетом балансировки?
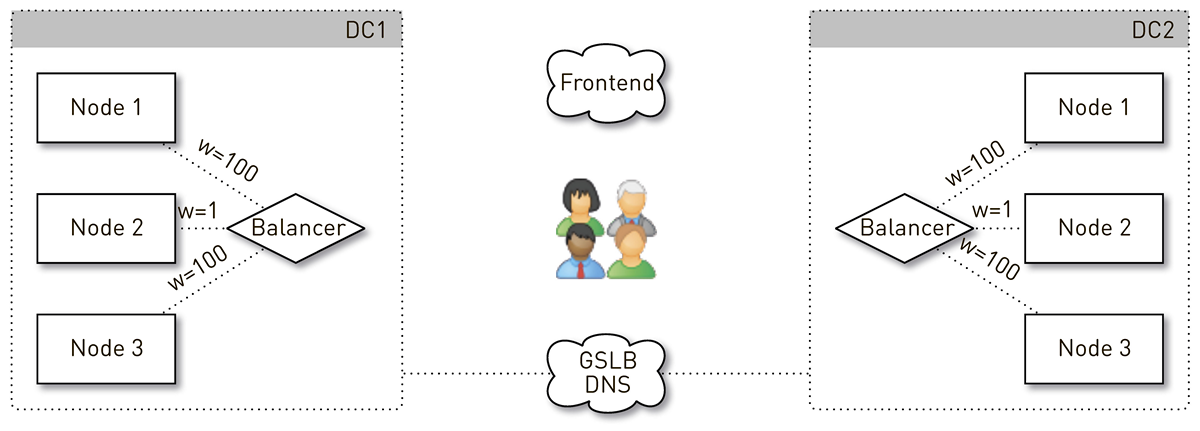
Пользователь заходит через сайт или мобильное приложение и получает URL трека:
musicd.mycdn.me/v0/stream?id=...Чтобы получить IP адрес из имени хоста в URL, клиент обращается к нашему GSLB DNS, который знает про все наши дата-центры и CDN-площадки. GSLB DNS отдает клиенту IP адрес балансировщика одного из дата-центров, и клиент устанавливает с ним соединение. Балансировщик знает про все ноды внутри дата-центров и их веса. Он от лица пользователя устанавливает соединение с одной из нод. Мы используем L4-балансировщики на базе NFWare. Нода отдает пользователю данные напрямую, минуя балансировщик. В сервисах, подобных раздатчику, исходящий трафик существенно превышает входящий.
Если возникает сбой дата-центра, GSLB DNS это обнаруживает и оперативно выводит его из ротации: перестаёт отдавать пользователям IP адрес балансировщика этого дата-центра. Если в дата-центре какая-то нода выходит из строя, то её вес обнуляется, а балансировщик внутри дата-центра перестает посылать на нее запросы.
Теперь рассмотрим балансировку треков по нодам внутри дата-центра. Будем считать дата-центры независимыми автономными единицами, каждый из них будет жить и работать, даже если все остальные погибли. Треки нужно балансировать по машинам равномерно, чтобы не было перекосов нагрузки, и реплицировать их на разные ноды. Если откажет одна нода, нагрузка должна распределиться поровну между оставшимися.
Эту задачу можно решить по-разному. Мы остановились на consistent hashing. Весь возможный диапазон хэшей идентификаторов треков заворачиваем в кольцо, и тогда каждый трек отображается в точку на этом кольце. Затем мы более или менее равномерно распределяем диапазоны кольца между нодами в кластере. Ноды, которые будут хранить трек, выбираются путем хэширования треков в точку на кольце и переходом по часовой стрелке.

Но у такой схемы есть недостаток: в случае отказа ноды N2, например, вся её нагрузка ляжет на следующую реплику по кольцу — N3. И если у неё нет двойного запаса по производительности — а такое экономически мало оправдано, — то, скорее всего, второй ноде тоже придется плохо. N3 с большой долей вероятности сложится, нагрузка перейдёт на N4 и так далее — возникнет каскадный отказ по всему кольцу.
Эту проблему можно решить, если увеличить количество реплик, но тогда уменьшается общая полезная ёмкость кластера в кольце. Поэтому мы делаем иначе. При том же количестве нод кольцо делится на значительно большее количество диапазонов, которые случайно разбросаны по кольцу. Реплики для трека выбираются по вышеописанному алгоритму.

В примере выше каждая нода отвечает за два диапазона. При сбое одной из нод вся её нагрузка ляжет не на следующую ноду по кольцу, а распределится между двумя другими нодами кластера.
Кольцо рассчитывается исходя из небольшого набора параметров алгоритмически и детерминировано на каждой ноде. То есть мы его не храним в каком-то конфиге. У нас в production этих диапазонов больше сотни тысяч, и в случае отказа любой из нод нагрузка распределяется абсолютно равномерно между всеми остальными живыми нодами.
Как выглядит отдача трека пользователю в такой системе с consistent hashing?
Пользователь через L4-балансировщик попадает на случайную ноду. Выбор ноды случаен, потому что балансировщик ничего не знает о топологии. Но зато о ней знает каждая реплика в кластере. Нода, получившая запрос, определяет, является ли она репликой для запрашиваемого трека. Если нет, то переключается в режим проксирования с одной из реплик, устанавливает с ней соединение, и та ищет данные в своем локальном хранилище. Если трека там нет, реплика подтягивает его из хранилища треков, сохраняет в локальное хранилище и отдает прокси, которая перенаправляет данные пользователю.

Если диск в реплике выйдет из строя, то данные из хранилища будут переданы пользователю напрямую. А если реплика выйдет из строя, то прокси ведь знает обо всех остальных репликах для данного трека, она установит соединение с другой живой репликой и получит данные с нее. Так мы гарантируем, что если пользователь запросил трек и жива хотя бы одна реплика, он получит ответ.
Как устроена нода

Нода представляет собой конвейер из набора стадий, через который проходит запрос пользователя. Сначала запрос попадает на внешний API (мы всё отдаём по HTTPS). Дальше выполняется валидация запроса — проверяются подписи. Затем конструируются теги IDv3, если это необходимо, например, при покупке трека. Запрос попадает на стадию роутинга, где на основе топологии кластера определяется, как будут отдаваться данные: либо текущая нода является репликой для данного трека, либо будем проксировать с другой ноды. Во втором случае нода через прокси-клиент устанавливает соединение с репликой по внутреннему HTTP API уже без проверок подписей. Реплика ищет данные в локальном хранилище, если находит трек, то отдаёт его со своего диска; а если не находит, то подтягивает из хранилища треков, кэширует и отдает.
Нагрузка на ноду
Прикинем, какую нагрузку должна держать одна нода в такой конфигурации. Пусть у нас три дата-центра по четыре ноды.

Весь сервис должен обслуживать 120 Гбит/с, то есть по 40 Гбит/с на дата-центр. Допустим, сетевики устроили манёвры или произошла авария, и осталось два дата-центра DC1 и DC3. Теперь каждый из них должен отдавать по 60 Гбит/с. Но тут разработчикам приспичило выкатить какой-то апдейт, в каждом дата-центре осталось по 3 живых ноды и каждая из них должна отдавать по 20 Гбит/с.
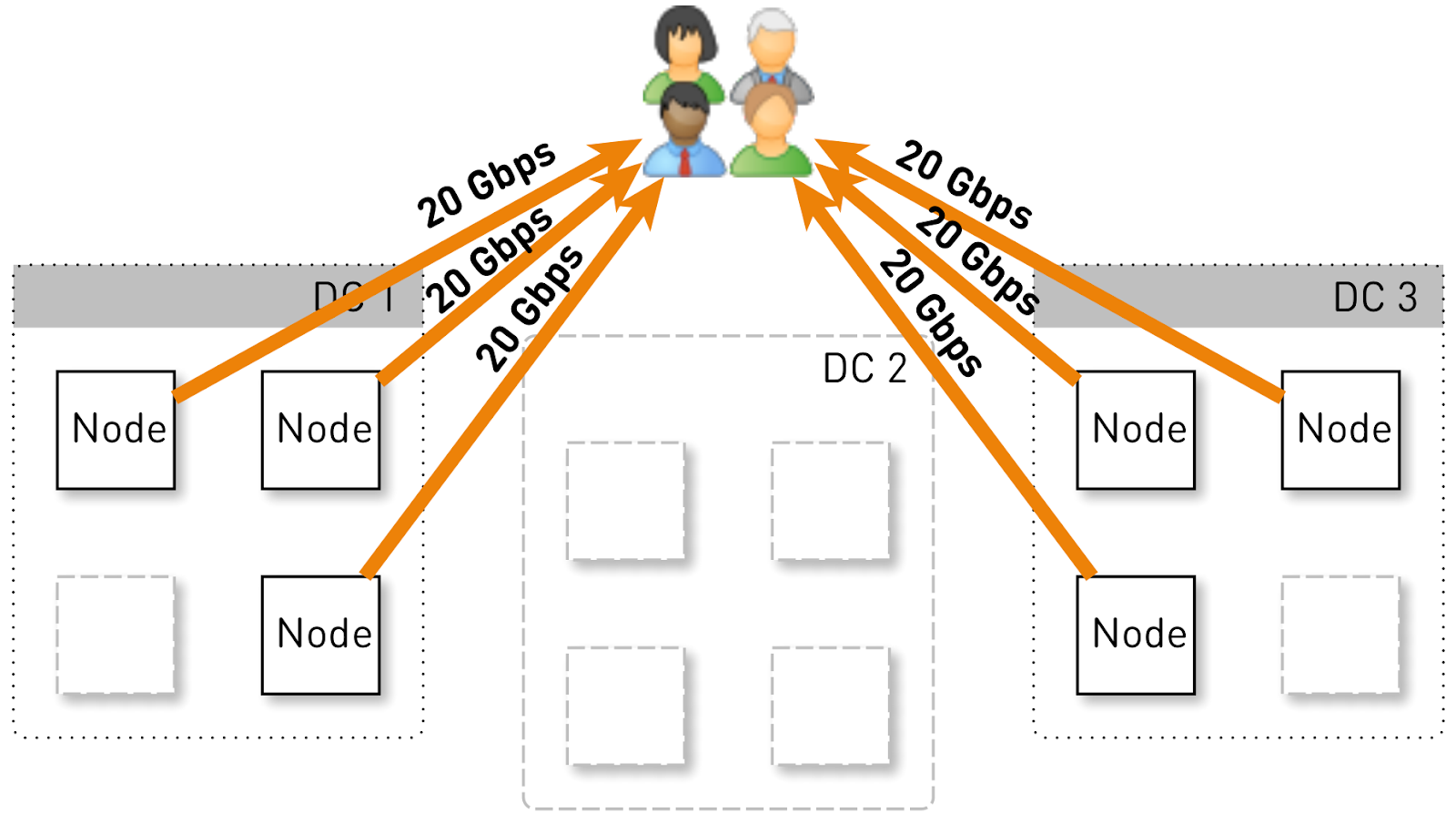
Но изначально в каждом дата-центре было 4 ноды. И если мы храним по две реплики в дата-центре, то с вероятностью 50% нода, которая получила запрос, не будет является репликой для запрошенного трека и станет проксировать данные. То есть половина трафика внутри дата-центра проксируется.
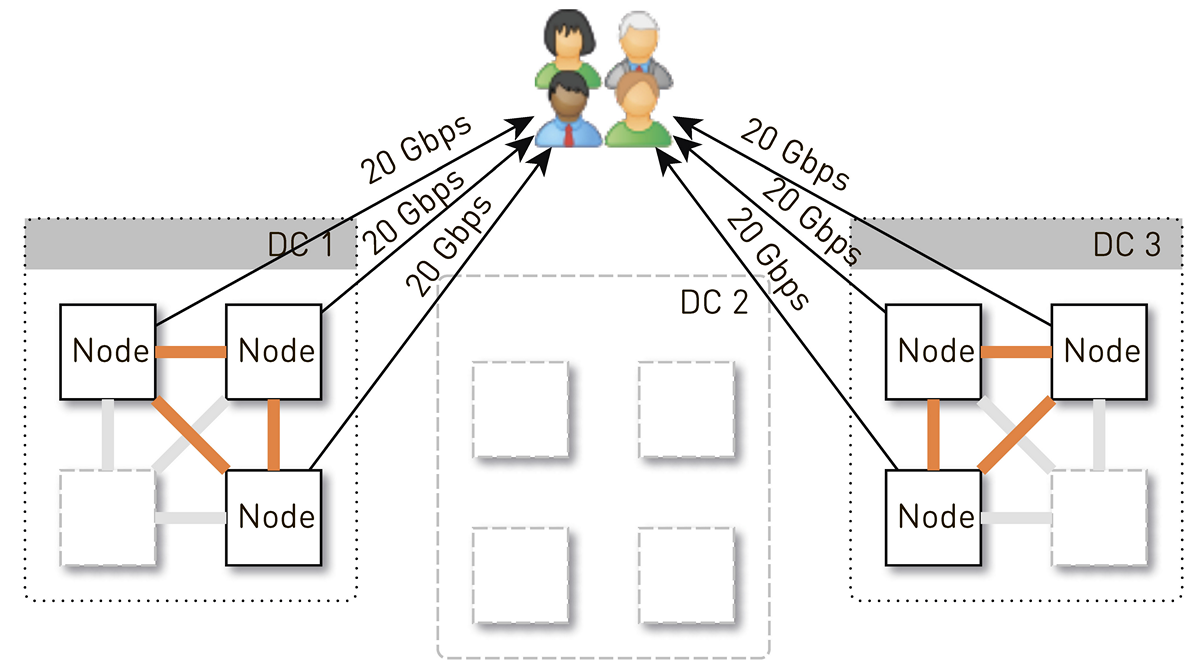
Итак, одна нода должна отдавать пользователям 20 Гбит/с. Из них 10 Гбит/с она тянет со своих соседей в дата-центре. Но схема симметричная: те же 10 Гбит/с нода отдает соседям в дата-центре. Получается, наружу от ноды идет 30 Гбит/с, из них 20 Гбит/с она должна обслужить сама, поскольку является репликой для запрашиваемых данных. Причём данные пойдут либо с дисков, либо из оперативной памяти, куда помещается около 50 тыс. «горячих» треков. С учетом нашей статистики проигрывания это позволяет снять 60-70% нагрузки с дисков, и останется около 8 Гбит/с. Этот поток вполне способен отдавать десяток SSD.
Хранение данных на ноде
Если каждый трек класть в отдельный файл, то накладные расходы на управление этими файлами будут огромными. Даже на перезапуск ноды и сканирование данных на дисках уйдут минуты, если не десятки минут.
В этой схеме есть и менее очевидные ограничения. Например, подгружать треки можно только с самого начала. А если пользователь запросил проигрывание с середины и произошёл промах кэша, то мы не сможем отдать ни одного байта, пока не догрузим данные до нужного места из хранилища треков. Более того, хранить треки мы можем тоже только целиком, даже если это гигантская аудиокнига, которую бросают слушать уже на третьей минуте. Она так и будет лежать мертвым грузом на диске, тратить дорогое место и снижать cache hit этой ноды.
Поэтому мы делаем совсем по-другому: дробим треки на блоки по 256 КБ, потому что это коррелирует с размером блока в SSD, и уже оперируем этими блоками. На диск в 1 ТБ помещается 4 млн блоков. Каждый диск в ноде — это независимое хранилище, и все блоки каждого трека распределяются по всем дискам.
Мы не сразу пришли к такой схеме, сначала все блоки одного трека лежали на одном диске. Но это привело к сильным перекосам нагрузки между дисками, так как если на один из дисков попал популярный трек, все запросы за его данными попадут на один диск. Чтобы такого не было, мы распределили блоки каждого трека по всем дискам, выровняв нагрузку.
Кроме того, не забываем, что у нас есть куча оперативной памяти, но самописный кэш мы решили не делать, поскольку у нас есть чудесный page cache в Linux.
Как хранить блоки на дисках?
Сначала решили завести один гигантский файл на XFS размером в диск и поместить в него все блоки. Потом возникла идея работать с блочным устройством напрямую. Мы реализовали оба варианта, сравнили их и получилось, что при прямой работе с блочным устройством запись в 1,5 раза быстрее, время ответа в 2-3 раза ниже, общая загрузка системы ниже в 2 раза.
Индекс
Но недостаточно уметь хранить блоки, необходимо поддерживать индекс из блоков музыкальных треков в блоки на диске.

Он получился достаточно компактным, одна запись индекса занимает всего 29 байт. Для хранилища размером 10 ТБ индекс занимает чуть больше 1 ГБ.
Здесь есть интересный момент. В каждой такой записи приходится хранить общий размер всего трека. Это классический пример денормализации. Причина в том, что по спецификации в HTTP range response мы должны возвращать общий размер ресурса, а также формировать заголовок Content-length. Если бы это не это, то всё было бы ещё компактнее.
К индексу мы сформулировали ряд требований: чтобы работал быстро (желательно, хранился в оперативной памяти), чтобы был компактным и не отнимал место у page cache. Ещё индекс должен быть персистентным. Если мы его потеряем, то потеряем информацию о том, в каком месте на диске хранится какой трек, а это равносильно очистке дисков. И вообще, хотелось бы, чтобы старые блоки, к которым давно не обращались, как-то вытеснялись, освобождая место для более популярных треков. Мы выбрали политику вытеснения LRU: блоки вытесняются раз в минуту, 1% блоков держим свободными. Конечно, индексная структура должна быть потокобезопасной, потому что у нас 100 тыс. соединений на ноду. Всем этим условиям идеально удовлетворяет
SharedMemoryFixedMap из нашей open source-библиотеки one-nio.Индекс мы поместили на
tmpfs, работает он быстро, но есть нюанс. Когда машина перезапускается, то теряется всё, что было на tmpfs, включая индекс. Кроме того, если из-за любимого sun.misc.Unsafe наш процесс рухнул, то непонятно, в каком состоянии остался индекс. Поэтому мы раз в час делаем его слепок. Но этого мало: раз у нас используется вытеснение блоков, приходится поддерживать WAL, в который мы пишем информацию о вытесненных блоках. Записи о блоках в слепках и WAL нужно как-то упорядочивать при восстановлении. Для этого мы используем поколение блока. Он играет роль глобального счетчика транзакции и инкрементируется каждый раз при изменении индекса. Давайте посмотрим на примере, как это работает.Возьмём индекс с тремя записями: два блока трека №1 и один блок трека №2.

Пробуждается поток создания слепков и итерируется по этому индексу: первый и второй кортежи попадают в слепок. Затем к индексу обращается поток вытеснения, понимает, что к седьмому блоку давно не обращались, и решает использовать его для чего-то другого. Процесс вытесняет блок и пишет запись в WAL. Добирается до 9 блока, видит, что к нему тоже давно не обращались, и так же помечает его вытесненным. Тут к системе обращается пользователь и происходит промах кэша — запрошен трек, которого у нас нет. Сохраняем блок этого трека в наше хранилище, перезаписав 9 блок. При этом инкрементируется generation и становится равным 22. Далее активируется процесс создания слепка, который не доделал свою работу, доходит до последней записи и пишет её в слепок. В итоге у нас в индексе есть две живые записи, слепок и WAL.
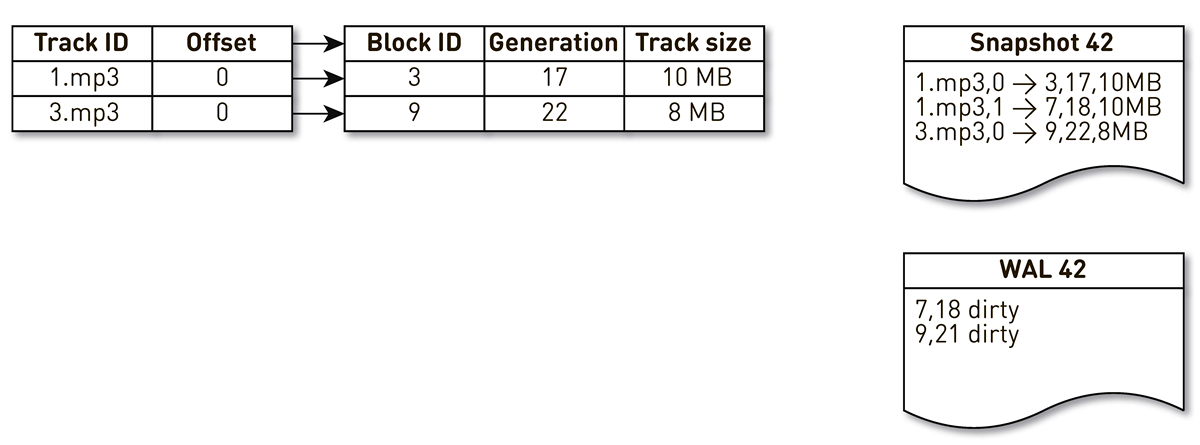
Когда текущая нода упадёт, то она будет восстанавливать исходное состояние индекса следующим образом. Вначале сканируем WAL и строим карту грязных блоков. Карта хранит отображение из номера блока в тот generation, когда этот блок вытеснили.
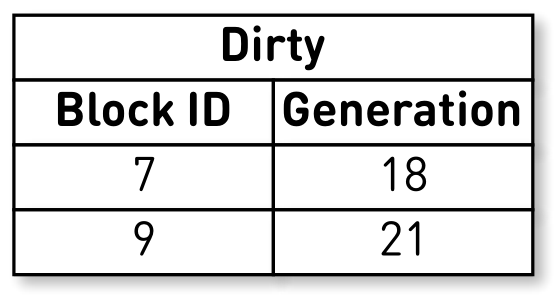
После этого начинаем итерироваться по слепку, используя карту как фильтр. Смотрим на первую запись слепка, она касается блока №3. Он не упоминается среди грязных, значит, он жив и попадает в индекс. Добираемся до блока №7 с восемнадцатым поколением, но карта грязных блоков говорит нам, что как раз в 18 поколении блок был вытеснен. Поэтому в индекс он не попадает. Доходим до последней записи, которая описывает содержимое 9 блока с 22 поколением. Этот блок упоминается в карте грязных блоков, но его вытеснили раньше. Значит, он переиспользован под новые данные и попадает в индекс. Цель достигнута.
Оптимизации
Но и это ещё не всё, спускаемся глубже.
Начнем с page cache. Мы рассчитывали на него изначально, но когда начали проводить нагрузочное тестирование первой версии, выяснилось, что page cache hit rate не достигает 20%. Предположили, что проблема в read ahead: мы храним не файлы, а блоки, при этом обслуживаем кучу соединений, а в такой конфигурации эффективно работа с диском происходит случайным образом. Мы почти никогда не читаем ничего последовательно. К счастью, в Linux есть вызов
posix_fadvise, который позволяет указать ядру, как мы собираемся работать с файловым дескриптором — в частности можно сказать, что нам не нужен read ahead, передав флажок POSIX_FADV_RANDOM. Этот системный вызов доступен через one-nio. В эксплуатации у нас cache hit составляет 70-80%. Количество физических чтений с дисков уменьшилось больше чем в 2 раза, задержка ответа по HTTP снизилась на 20%.Пошли дальше. У сервиса немаленький размер heap. Чтобы облегчить жизнь TLB-кэшам процессора, решили включить Huge Pages для нашего Java-процесса. В результате получили заметный профит для времени сборки мусора (GC Time/Safepoint Total Time на 20-30% ниже), загрузка ядер стала более равномерной, но на графиках HTTP latency никакого эффекта не заметили.
Инцидент
Вскоре после запуска сервиса произошёл единственный (пока что) инцидент.
Однажды вечером после окончания рабочего дня в поддержку посыпались жалобы на проигрывание музыки. Пользователи писали, что включают свой любимый трек, но каждые несколько секунд слышат непонятную музыку других времен и народов, а плеер им говорит, что это играет их любимый трек. Довольно быстро сузили круг поиска до одной машины, которая отдавала что-то странное. По логам выяснили, что её недавно перезапускали. Если упростить, то у нас было два диска и индексы, которые описывали содержимое блоков. Один индекс говорит, что четвертый блок трека Daft Punk лежит в блоке №2 диска sdc, а нулевой блок трека Стаса Михайлова лежит в нулевом блоке диска sdd.

Оказалось, что после перезагрузки машины имена дисков поменялись местами со всеми вытекающими последствиями. Эта проблема в Linux общеизвестна: если в сервере несколько дисковых контроллеров, то порядок именования дисков не гарантируется.
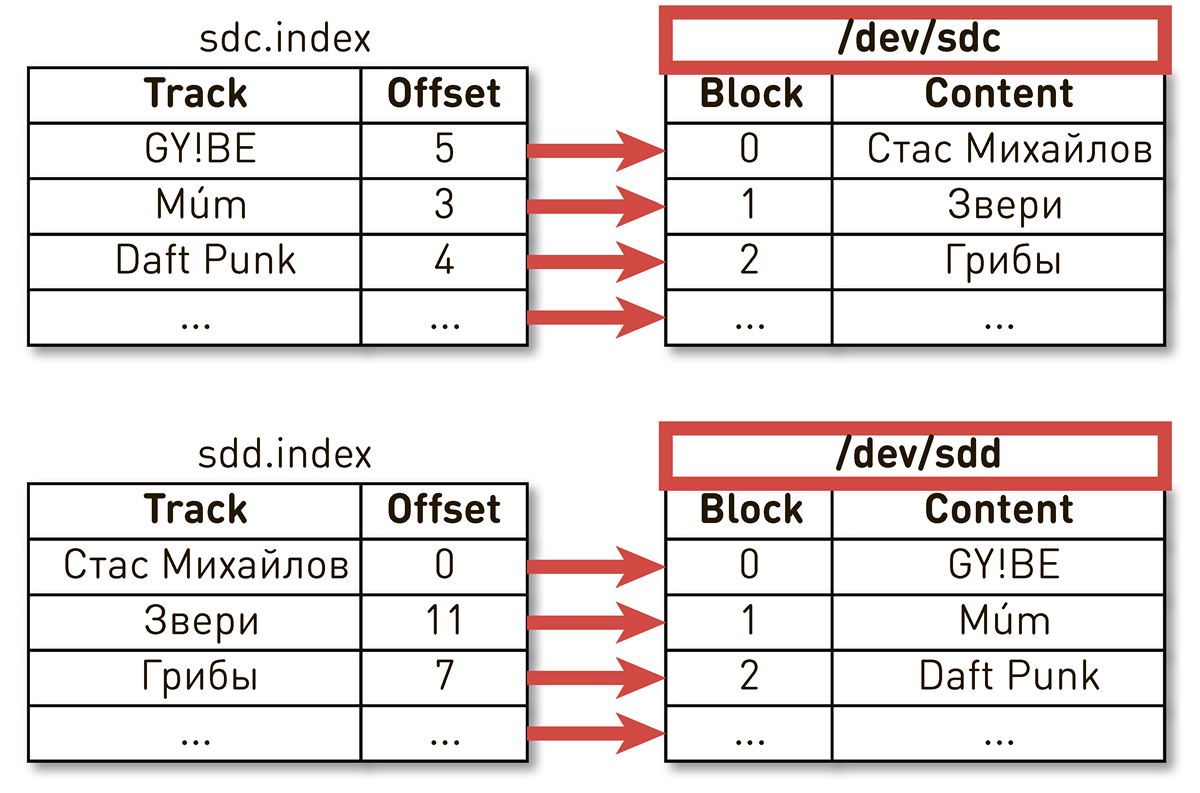
Фикс оказался простым. Для дисков существуют несколько разных видов персистентных ID. Мы используем WWN на основе серийных номеров дисков и идентифицируем с их помощью индексы, снэпшоты и WAL. Это не исключает самого перемешивания дисков, но как бы они не перемешивались, мапинг индексов на диске не нарушится и мы всегда будем отдавать корректные данные.
Анализ инцидентов
Анализ проблем в подобных распределённых системах затруднён, потому что пользовательский запрос проходит через множество стадий и пересекает границы нод. В случае с CDN всё становится ещё сложнее, потому что для CDN апстримом является домашний дата-центр. Таких хопов может быть довольно много. Причём в системе обслуживаются сотни тысяч пользовательских соединений. Понять, на какой стадии возникает проблема с обработкой запроса конкретного пользователя, довольно сложно.
Мы упрощаем себе жизнь так. На входе в систему все запросы помечаем тегом по аналогии с Open Tracing и Zipkin. Тег включает в себя идентификатор пользователя, запроса и запрошенного трека. Этот тег внутри конвейера передаётся со всеми данными и запросами, относящимися к текущему соединению, а между нодами передаётся в виде HTTP-заголовка и восстанавливается принимающей стороной. Когда нам нужно разобраться с проблемой, мы включаем отладку, журналируем тег, находим все записи, касающиеся определенного пользователя или трека, агрегируем и выясняем, как обрабатывался запрос на всём пути через кластер.
Отправка данных
Рассмотрим типичную схему отправки данных с диска в сокет. Вроде, ничего сложного: выделяем буфер, читаем с диска в буфер, отправляем буфер в сокет.
ByteBuffer buffer = ByteBuffer.allocate(size);
int count = fileChannel.read(buffer, position);
if (count <= 0) {
// ...
}
buffer.flip();
socketChannel.write(buffer);Одна из проблем этого подхода заключается в том, что здесь спрятано два скрытых копирования данных:
- при чтении из файла с помощью
FileChannel.read()происходит копирование из kernel space в user space; - а когда мы отправляем данные из буфера в сокет с помощью
SocketChannel.write(), происходит копирование из user space в kernel space.
К счастью, в Linux есть вызов
sendfile(), который позволяет попросить ядро отправить данные из файла в сокет с определенного смещения напрямую, минуя копирование в user space. И конечно, этот вызов доступен через one-nio. Мы на нагрузочных тестах заводили пользовательский трафик на одну ноду и заставляли проксировать с соседней ноды, которая отдавала данные только через sendfile() — загрузка процессора на 10 Гбит/с при использовании sendfile() была близка к 0.Но в случае с user-space SSL-сокетами мы не можем воспользоваться
sendfile() и нам не остается ничего другого, кроме как отправлять данные из файла через буфер. И здесь нас ждет еще один сюрприз. Если покопаться в исходниках SocketChannel и FileChannel, или воспользоваться Async Profiler и попрофилировать систему в процессе отдачи данных таким способом, то рано или поздно вы доберетесь до класса sun.nio.ch.IOUtil, к которому сводятся все вызовы read() и write() на этих каналах. Там спрятан такой код.ByteBuffer bb = Util.getTemporaryDirectBuffer(dst.remaining());
try {
int n = readIntoNativeBuffer(fd, bb, position, nd);
bb.flip();
if (n > 0)
dst.put(bb);
return n;
} finally {
Util.offerFirstTemporaryDirectBuffer(bb);
}Это пул нативных буферов. Когда вы читаете из файла в heap
ByteBuffer, то сначала стандартная библиотека берет буфер из этого пула, читает в него данные, потом копирует в ваш heap ByteBuffer, и возвращает нативный буфер обратно в пул. При записи в сокет происходит то же самое.Спорная схема. Здесь на помощь снова приходит one-nio. Создаем аллокатор
MallocMT — по сути, это пул памяти. Если у нас SSL и мы вынуждены отправлять данные через буфер, то выделяем буфер вне Java heap, оборачиваем его в ByteBuffer, читаем без лишних копирований из FileChannel в этот буфер и пишем в сокет. А затем возвращаем буфер в аллокатор.final Allocator allocator = new MallocMT(size, concurrency);
int write(Socket socket) {
if (socket.getSslContext() != null) {
long address = allocator.malloc(size);
ByteBuffer buf = DirectMemory.wrap(address, size);
int available = channel.read(buf, offset);
socket.writeRaw(address, available, flags);
100 000 соединений на ноду
Но успешность системы не гарантируется продуманностью реализации на нижних уровнях. Здесь есть еще одна проблема. Конвейер на каждой ноде обслуживает до 100 тыс. одновременных соединений. Как организовать вычисления в такой системе?
Первое, что приходит в голову — создаем поток исполнения для каждого клиента или соединения и в нём выполняем стадии конвейера одну за другой. При необходимости блокируемся, затем идем дальше. Но при такой схеме затраты на контекстные переключения и стеки потоков будут чрезмерными, поскольку речь идёт о раздатчике и потоков получается очень много. Поэтому мы пошли иным путём.
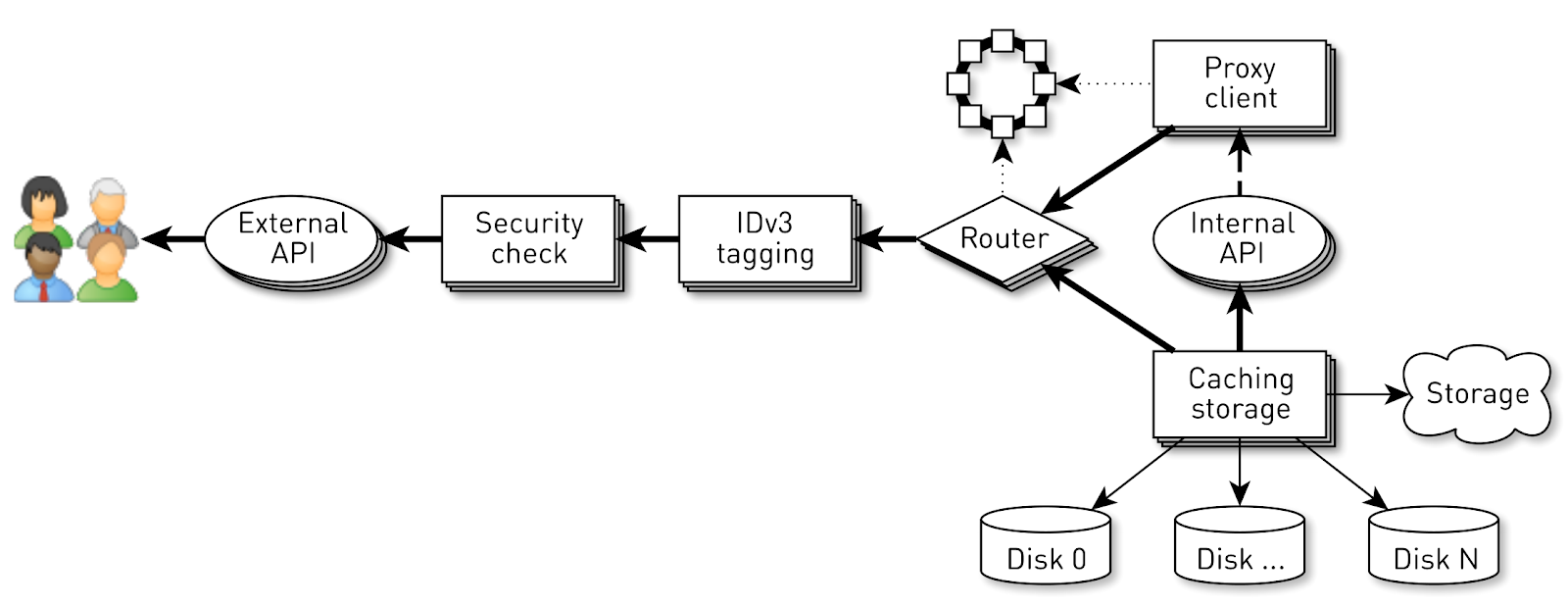
Для каждого соединения создается логический конвейер, который состоит из стадий, асинхронно взаимодействующих друг с другом. Каждая стадия имеет свою очередь, которая хранит входящие запросы. Для исполнения стадий используются небольшие общие пулы потоков. Если нужно обработать сообщение из очереди запросов, мы берем поток из пула, обрабатываем сообщение и возвращаем поток в пул. При такой схеме данные пушатся от хранилища к клиенту.
Но и такая схема не без изъянов. Бэкенды работают гораздо быстрее пользовательских соединений. Когда данные проходят через конвейер, они скапливаются в самой медленной стадии, т.е. на этапе записи блоков в сокет соединения с клиентом. Рано или поздно это приведет к коллапсу системы. Если попытаться ограничить очереди на этих стадиях, то всё мгновенно застопорится, потому что будут заблокированы конвейеры в цепочке к сокету пользователя. А поскольку они используют общие пулы потоков, то заблокируют в них все потоки. Нужен back pressure.
Для этого мы воспользовались реактивными стримами. Суть подхода в том, что subscriber управляет скоростью прихода данных от publisher с помощью demand. Demand означает, сколько еще данных готов обработать subscriber вместе с предыдущими demand, которые он уже просигнализировал. Publisher имеет право отправить данные, но только не превышая суммарный накопленный на данный момент demand за вычетом уже отправленных данных.
Таким образом система динамически переключается между режимами push и pull. В push режиме subscriber работает быстрее, чем publisher, то есть у publisher всегда есть неудовлетворённый demand от subscriber, но нет данных. Как только появляются данные, он тут же их отправляет subscriber-у. Режим pull возникает, когда publisher быстрее, чем subscriber. То есть publisher и рад бы отправить данные, только demand нулевой. Как только subscriber сообщает, что готов еще немного обработать, publisher ему сразу отправляет порцию данных в рамках demand.
Наш конвейер превращается в реактивный стрим. Каждая стадия превращается в publisher для предыдущей стадии и subscriber для следующей.
Интерфейс реактивных стримов выглядит предельно просто.
Publisher позволяет подписать Subscriber, а тот должен лишь реализовать четыре обработчика:interface Publisher<T> {
void subscribe(Subscriber<? super T> s);
}
interface Subscriber<T> {
void onSubscribe(Subscription s);
void onNext(T t);
void onError(Throwable t);
void onComplete();
}
interface Subscription {
void request(long n);
void cancel();
}Subscription позволяет сигнализировать demand и отменять подписку. Проще некуда.В качестве элемента данных мы передаем не массивы байтов, а такую абстракцию, как chunk. Мы это делаем, чтобы не затягивать в heap данные, если это возможно. Chunk — это ссылка на данные с очень ограниченным интерфейсом, который позволяет лишь прочитать данные в
ByteBuffer, записать в сокет или в файл.interface Chunk {
int read(ByteBuffer dst);
int write(Socket socket);
void write(FileChannel channel, long offset);
}Существует множество реализаций чанков:
- Самая популярная, которая используется в случае cache hit и при отдаче данных с диска, это реализация поверх
RandomAccessFile. Чанк содержит только ссылку на файл, смещение в этом файле и размер данных. Он идёт через весь конвейер, достигает сокета пользовательского соединения и там превращается в вызовsendfile(). То есть память вообще не потребляется. - В случае cache miss применяется другая реализация: мы блок за блоком извлекаем трек из нашего хранилища и сохраняем на диск. Чанк содержит ссылку на сокет, — по сути, клиентское соединение в хранилище треков, — позицию в стриме и размер данных.
- Наконец, в случае проксирования всё-таки приходится помещать полученный блок в heap. Здесь чанк выступает в роли обёртки вокруг
ByteBuffer.
Несмотря на всю простоту этого API, по спецификации он должен быть потокозащищённым, а большинство методов должны быть неблокирующими. Мы выбрали путь в духе Typed Actor Model, навеянный примерами из официального репозитория реактивных стримов. Чтобы сделать вызовы методов неблокирующими, мы при вызове метода берем все параметры, заворачиваем в сообщение, кладем в очередь на исполнение и возвращаем управление. Сообщения из очереди обрабатываются строго последовательно.
Никакой синхронизации, код простой и понятный.
Состояние описывается всего тремя полями. У каждого publisher или subscriber есть почтовый ящик, где скапливаются входящие сообщения, а также executor, который делится между всеми стадиями этого типа.
Вызовы превращаются в сообщения:
Метод
Метод
Метод
AtomicBoolean обеспечивает happens before между последовательными пробуждениями.// Incoming messages
final Queue<M> mailbox;
// Message processing works here
final Executor executor;
// To ensure HB relationship between runs
final AtomicBoolean on = new AtomicBoolean();Вызовы превращаются в сообщения:
@Override
void request(final long n) {
enqueue(new Request(n));
}
void enqueue(final M message) {
mailbox.offer(message);
tryScheduleToExecute();
}Метод
tryScheduleToExecute():if (on.compareAndSet(false, true)) {
try {
executor.execute(this);
} catch (Exception e) {
...
}
}Метод
run():if (on.get())
try {
dequeueAndProcess();
} finally {
on.set(false);
if (!messages.isEmpty()) {
tryScheduleToExecute();
}
}
}Метод
dequeueAndProcess():M message;
while ((message = mailbox.poll()) != null) {
// Pattern match
if (message instanceof Request) {
doRequest(((Request) message).n);
} else {
…
}
}Мы получили полностью неблокирующую реализацию. Код простой и последовательный, без
volatile, Atomic*, contention и прочего. Во всей нашей системе для обслуживания 100 000 соединений существует всего 200 потоков.В итоге
В production у нас 12 машин, при этом имеется более чем двукратный запас по пропускной способности. Каждая машина в обычном режиме отдаёт до 10 Гбит/с через сотни тысяч соединений. Мы обеспечили масштабируемость и отказоустойчивость. Всё написано на Java и one-nio.
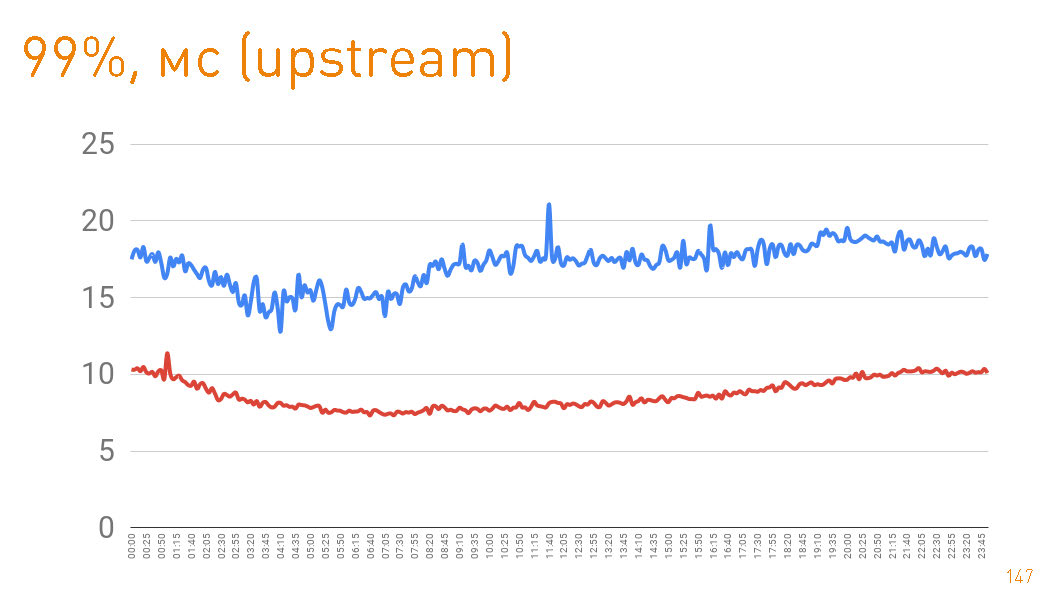
Это график до первого байта, отданного пользователю со стороны сервера. 99-перцентиль меньше 20 мс. Синий график — это отдача пользователю HTTPS-данных. Красный график — это отдача данных с реплики к прокси через
sendfile() по HTTP.На самом деле cache hit в production 97%, поэтому графики описывают latency нашего хранилища треков, из которого мы подтягиваем данные в случае промахов кэша, что тоже неплохо, учитывая петабайты данных.
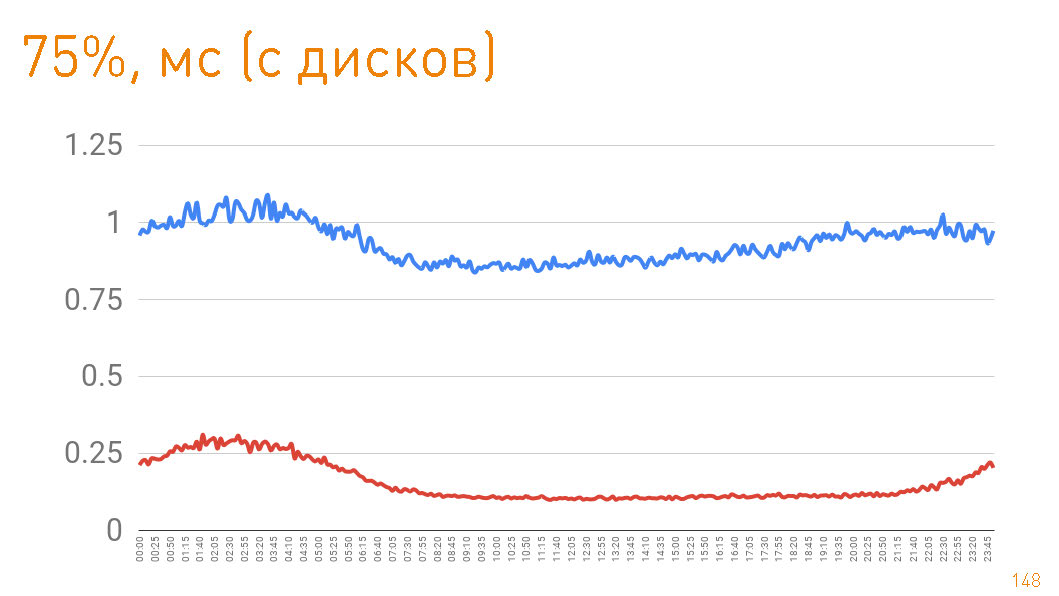
Если взглянуть на 75-перцентиль при отдаче с дисков, то пользователю первый байт улетает через 1 мс. Реплики внутри кластера общаются с ещё большей скоростью — отвечают за 300 мкс. Т.е. 0.7 мс — это стоимость проксирования.
В данной статье мы хотели продемонстрировать, как мы строим масштабируемые высоконагруженные системы, обладающие одновременно и высоким быстродействием, и отличной отказоустойчивостью. Надеемся, у нас это получилось.