Итак, 4 января в 7:15, протерев глаза от сна, обнаруживаю пачку сообщение в группе Telegram от Zabbix-сервера о том, что на одном из серверов виртуализации нагрузка по CPU повысилась:
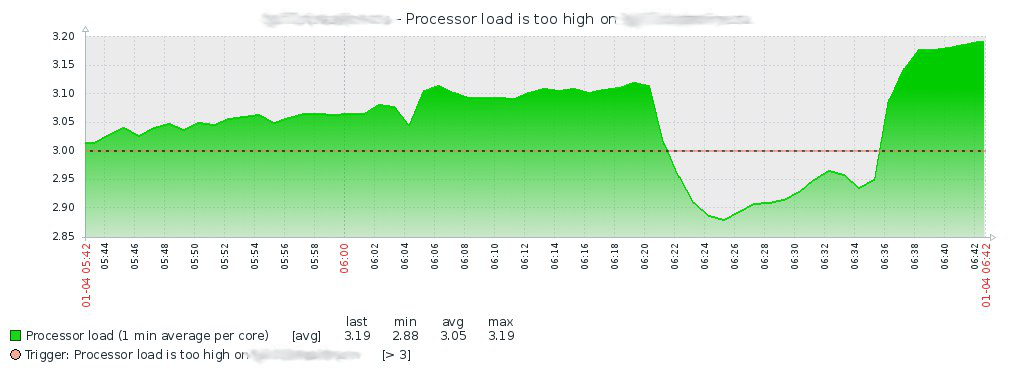
Посмотрев историю в Zabbix, лезу на сервер и смотрю в dmesg, где нахожу следующее:
[Чт янв 3 20:05:18 2019] qla2xxx [0000:21:00.1]-015b:10: Disabling adapter.
[Чт янв 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device
[Чт янв 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device
[Чт янв 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device
[Чт янв 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device
[Чт янв 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline deviceЛезу на хранилище на которое смотрит FC-адаптер QLogic, вижу что 1 января в 19:54 один из накопителей на хранилище был выведен из работы, подхвачен Spare-накопитель и 2 января в 9:11 закончился resilvering:

Подумал: возможно с хранилища или FC-коммутатора прилетело что-то, от чего у QLogic-адаптера взбеленился драйвер.
Создал задачу в трекере, перезапустил сервер, всё вновь заработало как должно, на первый взгляд.
На этом отложил дальнейшие действия до конца новогодних праздников.
С началом рабочей недели 9 января, начал разбирать причину сбоя.
Поскольку сообщение:
[Чт янв 3 20:05:18 2019] qla2xxx [0000:21:00.1]-015b:10: Disabling adapter.не слишком информативно, полез в исходники драйвера.
Судя по коду драйвера, сообщение выдаётся когда драйвер выгружается в связи с ошибкой на PCI (linux/drivers/scsi/qla2xxx/qla_os.c (ядро v4.15)):
qla2x00_disable_board_on_pci_error(struct work_struct *work)
{
struct qla_hw_data *ha = container_of(work, struct qla_hw_data,
board_disable);
struct pci_dev *pdev = ha->pdev;
scsi_qla_host_t *base_vha = pci_get_drvdata(ha->pdev);
/*
* if UNLOAD flag is already set, then continue unload,
* where it was set first.
*/
if (test_bit(UNLOADING, &base_vha->dpc_flags))
return;
ql_log(ql_log_warn, base_vha, 0x015b,
"Disabling adapter.\n");Начал копать дальше, полез в BMC, гляжу в Event Log:
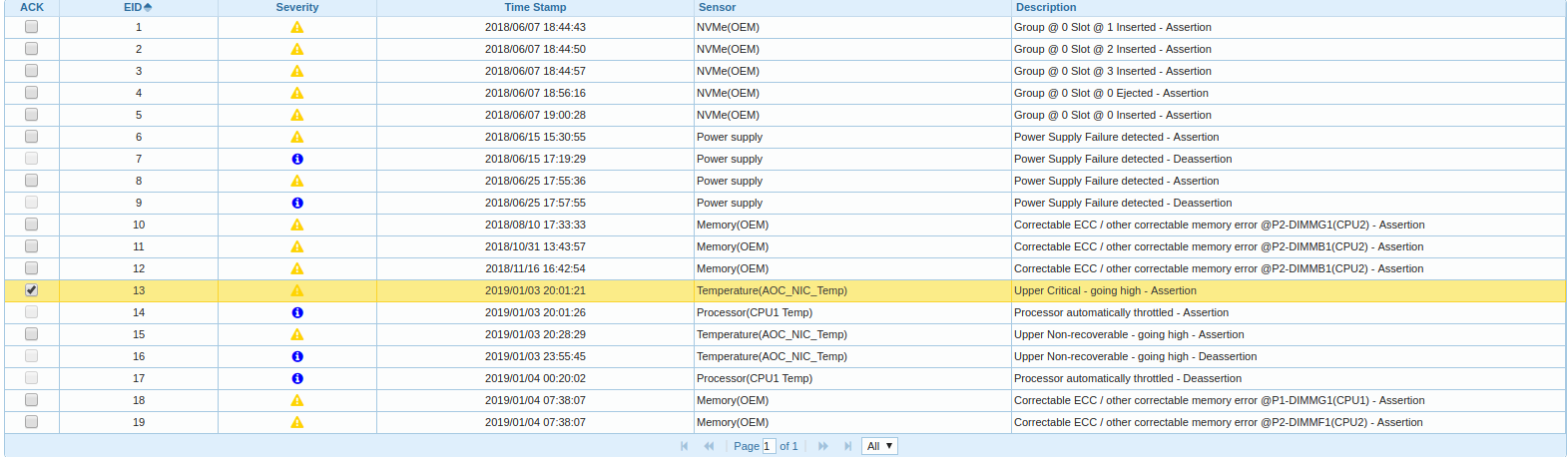
Оказывается один из двух CPU ноды в платформе греется и троттлит и время сообщения о выгрузке драйвера FC-адаптера коррелирует с временем начала троттлинга.
Тут стоит сделать ремарку, что серверная платформа у нас вот такая https://www.supermicro.com/Aplus/system/2U/2123/AS-2123BT-HNC0R.cfm с двумя EPYC 7601 на каждую ноду:
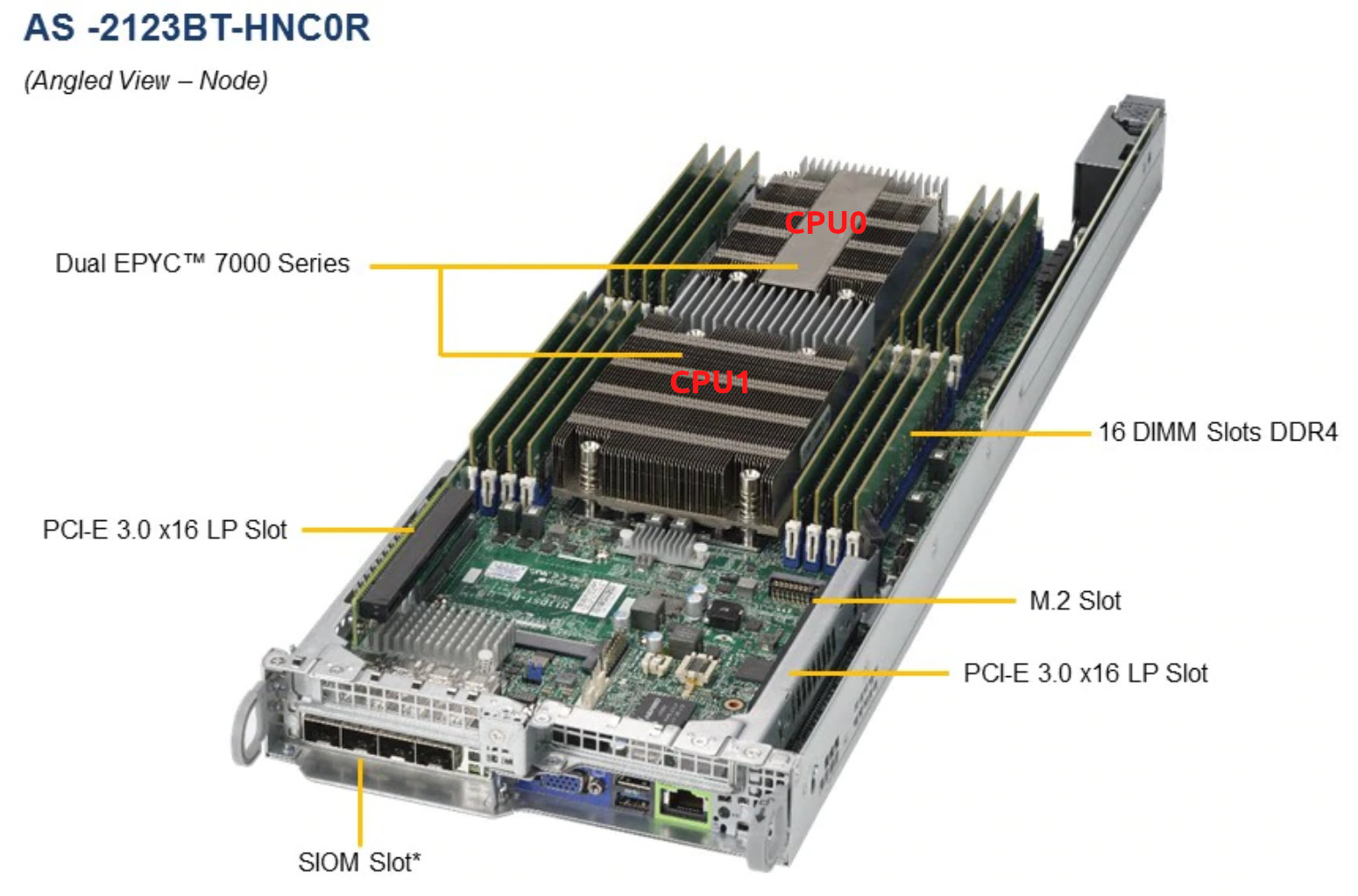
Двинул в ЦОД, вынули ноду из сервера, сменили термопасту, воткнули обратно, а всё равно греется.
Заметили, что поток воздуха в одной части сервера не так силён, как в другой. Немного нагрузив все ноды с помощью stress-ng, стало понятно, что процессоры нод в правой части платформы не обдуваются должным образом и температура вторых CPU в двух нодах очень быстро достигает критической.
Попробовав поменять параметры обдува в BMC, выяснилось, что они не оказывают действия:
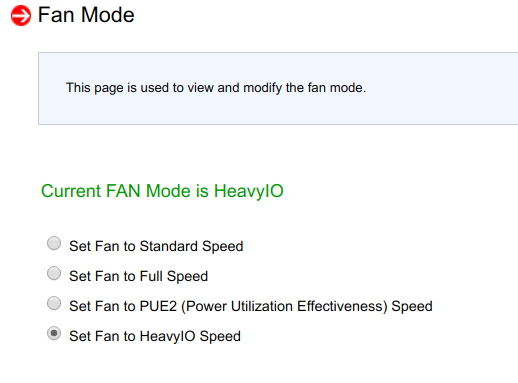
Перезапуск BMC так же не возымел действия.
Заглянув в "Sensor Readings" я увидел, что на одной ноде из 53 сенсоров, определяются только 4, а на другой ноде только 6:
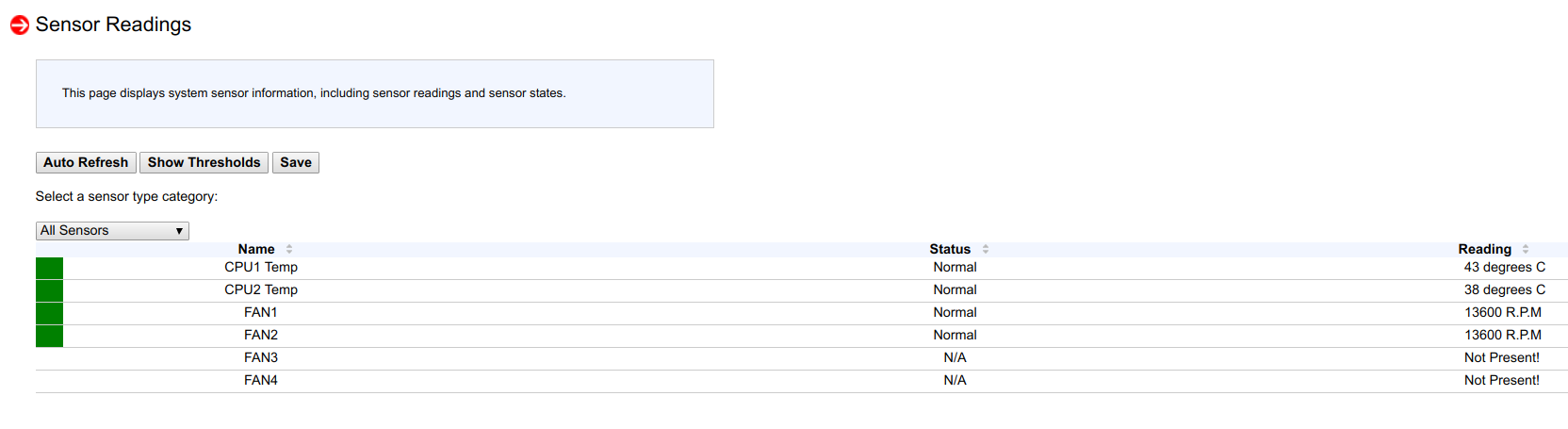
И вот тогда, я вспомнил, что прошивая с месяц-два назад новую версию BIOS и новый BMC в ноды, на двух нодах я не сделал сброс конфигурации BMC на заводские параметры (что-бы проверить один частный случай настройки).
После сброса BMC на заводские параметры все 53 сенсора вновь обнаружились, управление скоростью вращения вентиляторов вновь заработало, процессоры перестали греться.
То, что причиной выгрузки драйвера QLogic является перегрев процессора — не точно, но других близких корреляций я не обнаружил.
Выводы:
- после прошивки BMC даже если всё работает на первый взгляд нормально, всё же стоит сбросить настройки на заводские;
- конечно же температуру и сообщения об ошибках ядра надо ставить под мониторинг и это естественно в планах, но не всё сразу.
Комментарии (9)

Golex
21.01.2019 18:37Напомнили очень давнюю историю, когда серверные платформы Intel (да и на младших HP пролиантах я встречал такое поведение) после обновления BIOS ревели вентиляторами безостановочно, пока не обновишь и прошивку BMC. frusdr она тогда называлась. Многие админы ловились не прочтя описания в readme, кто производителя ругал, кто считал что так должно быть — всё равно в серверной шумно.
Я надеялся что культура разработки прошивок с тех пор изменилась. Оказывается бывает по разному.
derwin
22.01.2019 08:14на HP (вроде бы g4) требовалось для мажорной прошивки BMC переключить джампер на матплате в нужное положение. Потом вернуть.

BigD
22.01.2019 10:20А Zabbix из коробки умеет в Telegram отправлять сообщения?

RNZ Автор
22.01.2019 17:16Увы нет. Я использовал это github.com/ableev/Zabbix-in-Telegram, настраивается достаточно просто и в группе t.me/ZbxTg народ отзывчивый
Aquahawk
Интересно что даже производители видеокарт часто включают продув на 70-80% пока не запустится драйвер и не начнёт контролировать температуру, имменно чтобы при отсутствии драйвера ничего не перегрелось. Т.е. имхо производитель сервера(материнки и софта к ней) должен позаботиться о том, чтобы сервер обнаружив существенные проблемы с чтением температуры перешёл в fail safe режим и дул пропеллерами аки боинг на взлёте.
amarao
Вообще, все приличные сервера делают так же. Обычно это звучит так: УУУУУУУуууууууу шшшшш при включении. А вот насчёт поведения при отсутствии сенсоров — это да. Хотя мне кажется, уважающий себя сервер должен был просто зарепортить проблему в sel, а если всё плохо — встать. Лучше вставший сервер, чем тротлящий.
RNZ Автор
Ну я думаю, что проблем с чтением температуры CPU в BMC не было, по крайней мере BCM её показывал такой-же как lm-sensors.
И вращались вентиляторы тоже с приемлемой скоростью (~10k оборотов) для idle или небольшой нагрузки, но под значимой нагрузкой этого был недостаточно.
Так же, я связываю это с тем, что отключил C-States, т. к. постоянно валились сообщения:
Кстати, в этой платформе, каждые две ноды обдуваются парой вентиляторов (80x80x38 mm, 16.5K RPM, Non-hot-swappable):