Наша цифровизация началась с создания двух центров и соответствующих им функциональных блоков.
Это «Функция цифровых технологий», в которую включены все продуктовые направления: цифровизация процессов, IIoT и продвинутая аналитика, а также центр управления данными, ставший самостоятельным направлением.

И вот как раз главная задача дата-офиса заключается в том, чтобы полноценно внедрить культуру принятия решений, основанных на данных (да, да, data-driven decision), а также в принципе упорядочить всё, что касается работы с данными: аналитика, обработка, хранение и отчетность. Особенность в том, что все наши цифровые инструменты должны будут не только активно использовать собственные данные, то есть те, которые генерируют сами (например, мобильные обходы, или датчики IIoT), но и внешние данные, с четким пониманием, где и зачем их нужно использовать.
Меня зовут Артем Данилов, я руководитель направления «Инфраструктура и технологии» в СИБУРе, в этом посте я расскажу, как и на чем мы строим большую систему обработки и хранения данных для всего СИБУРа. Для начала поговорим только о верхнеуровневой архитектуре и о том, как можно стать частью нашей команды.
Вот какие направления включает в себя работа в дата-офисе:
1. Работа с данными
Здесь трудятся ребята, которые активно занимаются инвентаризацией и каталогизацией наших данных. Они понимают, какие есть потребности у той или иной функции, могут определить, какого рода аналитика может понадобиться, какие метрики стоит отслеживать для принятия решений и как используются данные в определённой бизнес-области.
2. BI и визуализация данных
Направление тесно связано с первым и позволяет наглядно представить результат работы ребят из первой команды.
3. Направление контроля качества данных
Здесь внедряются инструменты контроля качества данных и проводится имплементация всей методологии такого контроля. Иными словами, ребята отсюда внедряют софт, пишут различные проверки и тесты, понимают, как происходят кросс-проверки между разными системами, отмечают функции тех сотрудников, которые отвечают за качество данных, а также налаживают общую методологию.
4. Управление НСИ
Мы — компания большая. У нас много разного рода справочников — и контрагенты, и материалы, и справочник предприятий… В общем, поверьте, справочников хватает с лихвой.
Когда компания что-то активно закупает для своей деятельности, у нее обычно есть специальные процессы заполнения этих справочников. В противном случае хаос достигнет такого уровня, что работать будет невозможно от слова «совсем». У нас такая система тоже есть (MDM).
Проблемы тут вот в чем. Допустим, в одном из региональных подразделений, которых у нас много, сидят сотрудники и вносят в систему данные. Вносят руками, со всеми вытекающими из такого способа последствиями. То есть им надо внести данные, проверить, что все доехало в систему в нужном виде, без дублей. При этом некоторые вещи, в случае заполнения каких-то реквизитов и обязательных полей, приходится вообще самостоятельно искать и гуглить. Например, есть у тебя ИНН компании, а тебе нужны остальные сведения — ты проверяешь через специальные сервисы и ЕГРЮЛ.
Все эти данные, конечно, уже где-то есть, поэтому было бы правильно их просто автоматически подтягивать.
Раньше в компании в принципе не было какой-то единой должности, четкой команды, которая бы этим занималась. Было множество разрозненных подразделений, вручную вносящих данные. Но таким структурам обычно сложно даже сформулировать, что именно и где именно в процессе работы с данными надо изменить, чтобы все было отлично. Поэтому мы пересматриваем формат и структуру управления НСИ.
5. Внедрение хранилища данных (узел данных)
Вот именно это мы и начали делать в рамках этого направления.
Давайте сразу определимся с терминами, а то используемые мной словосочетания могут пересекаться с какими-нибудь другими концепциями. Грубо говоря, узел данных = озеро данных + хранилище данных. Чуть дальше я раскрою это подробнее.
Архитектура
В первую очередь мы постарались прикинуть, с какими именно данными предстоит работать — какие тут есть системы, какие датчики. Поняли, что будут как потоковые данные (это то, что генерируют сами предприятия со всего своего оборудования, это IIoT и прочее) и классические системы, разные CRM, ERP и подобное.
Поняли, что данных в текущих системах будет не прямо чтобы совсем много по объему, но с внедрением цифровых инструментов и IIoT их станет очень много. А еще будут очень разнородные данные из классических учетных систем. Поэтому придумали архитектуру вот такого плана.

Далее подробнее по блокам.
Хранение
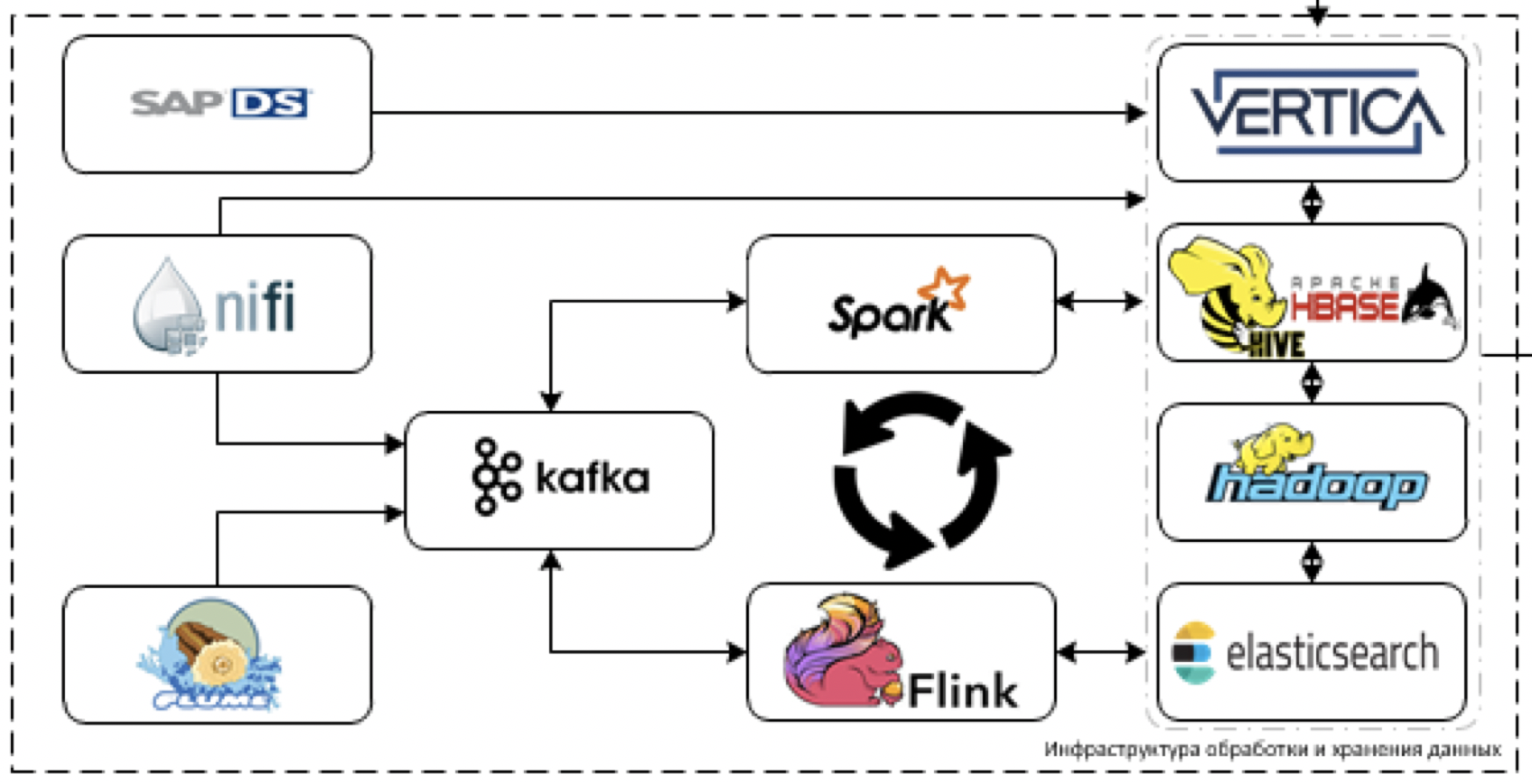
Это основное ядро нашей платформы. То, что используется для обработки и хранения данных. Задача — загружать данные более чем из 60 различных систем, когда они начнут их поставлять. То есть тут вообще все данные, которые могут пригодиться для принятия каких-то решений.
Начнём с извлечения и обработки данных. Для этих целей мы планируем использовать ETL-инструмент NiFi для потоковых и пакетных данных, а также инструменты для стриминговой обработки: Flume для первичного приема данных и их декодирования, Kafka для буферизации, Flink и Spark Streaming как основные инструменты обработки потоков данных.
Наиболее сложно работать с системами стэка SAP. Извлекать из SAP данные придётся с помощью отдельного ETL-инструмента — SAP Data Services.
В качестве инструментов хранения мы планируем использовать платформу Cloudera Hadoop (сам HDFS, HBASE, Hive, Impala), аналитическую СУБД Vertica и, для отдельных кейсов, elasticsearch.
В принципе, мы используем самый современный стэк. Да, нас можно попробовать закидать помидорами и поусмехаться над тем, что мы называем самым современным стэком, но на самом деле — так и есть.
Мы не ограничены legacy-разработкой, но при этом не можем использовать bleeding edge в промышленном решении из-за явной enterprise ориентированности нашей платформы. Поэтому, может, мы и не тащим Horton, а ограничиваемся Clouder’ой, там, где можно, мы обязательно пытаемся затащить более новый инструмент.

Для контроля качества данных используется SAS Data Quality, а Airflow для управления всем этим добром. Мониторинг всей платформы делаем через стек ELK. Визуализацию по большей части планируем делать на Tableau, какие-то совсем статичные отчеты на SAP BO.
Уже сейчас понимаем, что часть задач невозможно реализовать через стандартные BI-решения, так как требуется совсем изощренная визуализация в реальном времени с множеством картонных контролов. Поэтому будем писать свой фреймворк визуализации, который можно было бы встраивать в разрабатываемые цифровые продукты.
Про цифровую платформу
Если посмотреть чуть шире, то сейчас мы с коллегами из функции цифровых технологий строим единую цифровую платформу, задача которой — быстрая разработка собственных приложений.
Озеро данных — один из элементов этой платформы.
В рамках этой активности мы понимаем, что нам потребуется реализовать удобный интерфейс доступа к аналитическим данным. Поэтому в планах реализовать Data API и объектную модель производства для более удобного доступа к производственным данным.
Что еще делаем и кто нам нужен
Кроме хранения и обработки данных на нашей платформе будет работать всё машинное обучение, а также IIoT-фреймворк. Озеро будет выступать и как источник данных для обучения и работы моделей, и как мощности для работы моделей. Уже сейчас готов ML-фреймворк, который будет работать поверх платформы.

Прямо сейчас в команде есть я, пара архитекторов и 6 разработчиков, поэтому мы активно ищем новых людей (мне нужны архитекторы данных и дата-инженеры), которые помогут нам с развитием платформы. Ковыряться в легаси не придётся (легаси тут только на входе от систем), стэк свежий.
Вот где будут тонкости — так это в интеграциях. Связывать старое с новым, да так, чтобы оно все нормально работало и решало задачи — это вызов. Кроме этого, надо будет придумывать, прорабатывать и навешивать кучу самых разных метрик.
Сбор данных проводится из всех основных систем — 1С, SAP и куча всего остального. На основе собранных тут данных будет строиться вся аналитика, вся предиктивка, вся цифровая отчетность.
Если совсем коротко, ты мы хотим сделать так, чтобы работать с данными стало по-настоящему круто. Вот, например, маркетинг и продажи — у них есть люди, которые собирают всю статистику руками. То есть сидят и из 5 разных систем выкачивают разрозненные данные в разных форматах, загружают их из 5 разных программ, потом выгружают себе в эксель все это считать. Потом сводят информацию в единые экселевские таблицы, как-то пытаются делать визуализацию.
В общем, времени уходит вагон на все это. Подобные проблемы мы и хотим решить нашей платформой. А в следующих постах подробно расскажем о том, как мы связывали элементы между собой и настраивали корректную работу системы.
Кстати, кроме архитекторов и дата-инженеров в этой команде мы будем рады видеть:
Комментарии (25)

dmitrievanthony
21.01.2019 17:31А как используется Ignite ML Framework в этой системе? Немного неожиданно его видеть не в области хранения и обработки данных.

Izayda Автор
22.01.2019 12:51+1Думаю тут есть некая путаница. Мы сделали свой кастомный ML фреймворк, работающий на игнайте, который совпал по названию с Ignite ML Framework :) И поместили в раздел к ML инструментам, тк пока планируем его использовать только для машинки.
По факту, это фреймворк управления жизенным циклом моделей (ci\cd, исполнение, мониторинг), который использует часть нашей инфраструктуры для своей работы (Elastic, HDFS, YARN). В то же время источником данных для обучения и работы моделей выступает наша платформа.
Коллеги обещают сделать отдельную статью про этот фреймворк.chiefy
22.01.2019 12:55Да, путаница действительно возникла потому что у Ignite есть собственный модуль ML. Вот и показалось что речь о нем)
chiefy
22.01.2019 13:02И кстати об Ignite ML, во встроенном фреймворке есть возможность импорта и инференса моделей. Это свежий функционал и возможно Вы его пропустили. Нет ли планов по использованию этого встроенного фреймворка?
Izayda Автор
22.01.2019 14:43Все-таки Ignite ML framework больше про алгоритмы, а наш фреймворк больше про жизненный цикл и управление моделями.
Мы внимательно следим за развитием Ignite ML framework. Возможно в будущем будем его использовать под нашим движком в качестве одного из способов исполнения алгоритмов.chiefy
22.01.2019 14:50А что именно Вы имеете ввиду под «жизненным циклом»? В данный момент во фреймворке есть поддерка как тренировки моделей самого Ignite, так и импорт, поддержка и хранение сторонних моделей (TensorFlow, XGBoost и Spark MLib, хотя последние две вещи будут в релизе 2.8, но уже есть в мастер бранче).
Izayda Автор
23.01.2019 17:03Создание, миграции моделей между разными средами, исполнение моделей и их мониторинг.
Многие вещи так или иначе уже есть в Ignite ML Framework, многие постепенно появляются, но на текущий момент целиком переехать на него не можем.
AplatonoVV
21.01.2019 17:31+1Спасибо за статью. А не могли бы вы подробней рассказать о том как используется Ignite ML в вашем решении?
pe4albka
21.01.2019 17:31Почему в качестве ХД решили вертику использовать?
Izayda Автор
22.01.2019 12:59+1Отвечу немного шире.
Мы специально сразу добавили в архитектуру реляционную MPP базу по следующим причинам:
- Для хранения агрегатов, небольшого горизонта детальных данных и витрин данных
- Как инструмент с меньшим порогом входа для пользователей. Многие знают только SQL.
- Как более простую подложку для BI инструментов
Почему именно Вертика (в основном выбирали между GreenPlum, ClickHouse и Exasol):
- GreenPlum отмели, тк не очень подходит по нагрузке, отсутвию транзакций. И есть мучительный опыт с ним.
- ClickHouse сыроват и пока может решать весь набор требуемых задач.
- Exasol — пока очень дорогой, требовательный к железу, проприетарная ОС, мало инфы и внедрений в России. Т.к. мы все равно немного Enterprise, решили не рисковать.
- Опять же низкий порог входа. У Вертики прекрасный оптимизатор, который спокойно переваривает самые глупые запросы.
- Есть базовые интеграции с используемым стеком (c Hadoop, Kafka, Spark).
- В команде большая экспертиза по Вертике. Есть опыт двух больших внедрений.
TimonKK
22.01.2019 22:09Можете сказать размер данных в Вертике? И денормализуете ли данные? И не смотрели ли MariaDB Column Store? Мы всё никак не выберем, ClickHouse — быстрый, но крикой SQL. Остальные стоят денег
Izayda Автор
23.01.2019 17:05Первоначально оценили данные в 50ТБ. Думаю, что за 1 год заполним.
Про нормализацию:
Витрины будем делать денормализованными. Детальный слой планируем строить на смеси DataVault и AnchorModelling.
Columnstore, если честно, даже не рассматривали как возможный вариант. Не помню точно что повлияло, но она даже в short-list не вошла.
Сейчас полистали. По обзорам и отзывам в интернете, этому проекту ещё предстоит развиваться. Но текущая документация как-то скудно описывает и архитектуру, и возможности по оптимизации хранения под определённые запросы. Например, управление сегментацией, pruning при чтении…
Иначе говоря, если бы встал вопрос сейчас, мы тоже бы не заинтересовались.TimonKK
23.01.2019 17:33Я делал тестовый стенд на AnchorModelling, с помощью Spark данные нормализовал — получилось прикольно. Но ClickHouse и Columnstore не вывезли разворачивание по разным причинам. Потому пока остановились на ClickHouse и просто широкой таблице. А MemSQL не видели?
Izayda Автор
23.01.2019 17:53AnchorModelling тяжело ложится что на ClickHouse, что на Columnstore. В DataVault меньше джойнов, должно быстрее летать. В любом случае надо смотреть на частоту изменения модели данных и ее размеры в целом.
MemSQL не видели, спасибо, исследуем!

Yo1
22.01.2019 09:00странный подход. flume и kafka, spark и flink. нафига толкать в проект прямые аналоги? с ML тоже ощущение что натолкали все за что глаза зацепились. и spark ml и тензор и ignite ml с боку прилажен. причем судя по диаграмме план тащить данные из вертики в ml либы, хотя наиболее оптимально было бы на хадуп кластере внутри spark датафрейма дергать ml.
Izayda Автор
22.01.2019 13:16+1По Flume и Kafka — в целом да, в кафку сейчас можно любую функциональность запихнуть. Но с точки зрения эксплуатации и последующей разработки, мы их разделили, чтобы максимально упростить процесс изменений и контроля.
По Spark и Flink — если нам нужен микробатчинг или батчинг, то будем использовать Spark. Если нужна обработка в «реальном времени» — будем использовать Flink. Они все-таки немного разные, будем подбирать по задаче.
По ML — затолкнули все, что используют наши сайнтисты.
AntonAK83
22.01.2019 11:12Сбор данных проводится из всех основных систем — 1С, SAP и куча всего остального. На основе собранных тут данных будет строиться вся аналитика, вся предиктивка, вся цифровая отчетность.
Вероятно еще данные берете из MES-системы СИБУР-а. Там одна из баз это БД Historian(Proficy Historian).
Я как-раз занимаюсь сейчас передачей данных в Historian с помощью коллекторов. Так вот у GE IP(Intelligent Platforms) есть множество вариантов работы с big daga. Есть такая платформа как Predix Platform, можете ее еще рассмотреть как вариант.Izayda Автор
22.01.2019 13:26+1Спасибо за инфу! Задача такая есть. Решение Predix смотрели (их private cloud), думаем над использованием его подсистемы для переноса архивных данные Historian'а в Hadoop.
AntonAK83
23.01.2019 06:41Historian HD provides big data capabilities on a Hadoop platform. Historian Analysis provides visualization of key equipment and process information in S95 model context. CSense analyzes and troubleshoots asset- and process-performance issues.
Я думаю что с Hadoop platform проблем не возникнет. Csense конечно бы прикрутить еще можно, но Predix его скора вытеснит.Izayda Автор
23.01.2019 17:06Csense сейчас используем для некоторых задач, но весь поток будем через Historian API забирать. С их Hadoop Platform есть одна проблема — он стоит приличное количество денег и только только появился.
StrangeBelk
24.01.2019 10:47А чем обусловлен выбор именно Tableu? Не рассматривали вариант PowerBI? В прошлом году анализировал возможное решение по BI, и с точки зрения критериев оценки (стоимость владения, требования входа), хотя в общем по функционалу решения ± одинаковые, за исключением того, что PowerBI поддерживает R и в скором времени, на скок знаю, будет поддержка Python.
HDDimon
Привет, спасибо за сайтью. А как вы мониторите потоки данных в таком зоопарке? Как быстро узнаете и узнаете ли что какой-то из потоков отвалился?
Izayda Автор
Если честно, пока никак не мониторим.
Но планируем мониторить следующим образом по предыдущему опыту: