
«2048» через несколько недель исполняется 5 лет, а значит, пора написать что-нибудь, посвящённое этой замечательной игре.
Особенно познавательна тема самостоятельной игры искусственного интеллекта в головоломку. Способы реализации есть самые разные и сегодня разберём относительно лёгкий из них. А именно — научим компьютерный разум собирать степени двойки с помощью метода Монте-Карло.
Статья написана при поддержке компании EDISON Software, которая занимается разработкой мобильных приложений и предоставляет услуги по тестированию программного обеспечения.

Вдохновением к данному труду послужило обсуждение на stackoverflow, где умные ребята предложили действенные способы компьютерной игры. По всей видимости, наилучшим способом является метод минимакса с альфа-бета отсечением и через пару дней ему будет посвящена следующая публикация.
Казино-способ предложен пользователем stackoverflow
Метод Монте-Карло
Я заинтересовался идеей ИИ для этой игры, в которой нет жестко запрограммированного интеллекта (то есть отсутствуют эвристики, подсчет очков и т.п.). ИИ должен «знать» только правила игры и «разбираться» в игре. Это отличает его от большинства ИИ (таких, как в этой теме), поскольку игровой процесс, фактически, является грубой силой, управляемой функцией подсчета очков, отражающей человеческое понимание игры.
ИИ алгоритм
Я обнаружил простой, но удивительно хороший игровой алгоритм: чтобы определить следующий ход для данного состояния поля, ИИ разыгрывает в игру в оперативной памяти, делая случайные ходы до тех пор, пока игра не закончится поражением. Это делается несколько раз, при этом отслеживается конечный счет. Затем рассчитывается средний конечный балл с учётом начального хода. В качестве уже реально выбираемого хода выбирается тот начальный ход, который показал наибольший средний результат.
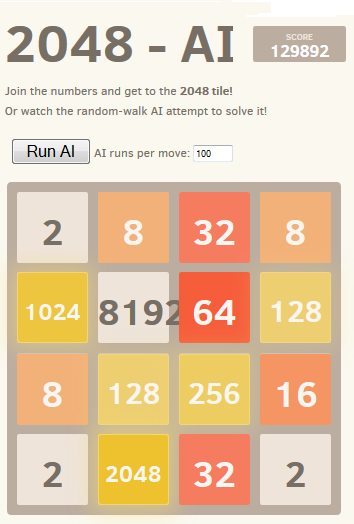
При 100 прогонах для каждого начального хода ИИ добирается до плитки 2048 в 80% случаев и плитки 4096 в 50% случаев. При использовании 10000 прогонов 2048 получается в 100% случаев, 70% — для 4096 и около 1% — для 8192.
Посмотреть в действии
Лучший достигнутый результат показан на скриншоте:
Интересным фактом для данного алгоритма является то, что хотя игры с произвольно осуществляемыми ходами ожидаемо довольно плохи, тем не менее выбор лучшего (или наименее плохого, если угодно) хода приводит к очень хорошему игровому процессу: типичная игра ИИ методом Монте-Карло может набрать 70000 очков за 3000 ходов, однако игры с произвольной игрой в памяти из любой заданной позиции дают в среднем 340 дополнительных очка примерно за 40 дополнительных ходов перед проигрышем. (Вы можете убедиться в этом сами, запустив ИИ и открыв консоль отладки.)
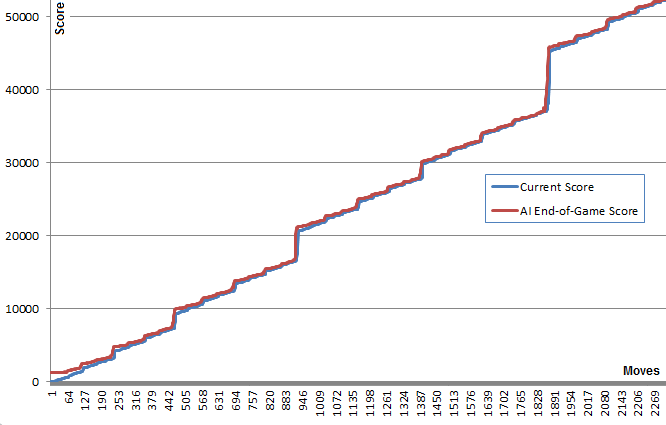
Данный график иллюстрирует эту концепцию: синяя линия показывает счет игры после каждого хода. Красная линия показывает лучший результат алгоритма, произвольно делающий ходы с данной позиции до конца игры. По сути, красные значения «подтягивают» синие вверх, поскольку они являются наилучшими предложениями алгоритма. Интересно, что красная линия чуть-чуть выше синей линии в каждой точке, но синяя линия сокращает разрыв все больше и больше.
Я нахожу довольно удивительным, что алгоритм на самом деле необязательно предвидит хороший игровой процесс, и тем не менее выбирает ходы, которые его (хороший процесс) производят.
Позже я обнаружил, что этот метод может быть классифицирован как алгоритм поиска по дереву Монте-Карло.
Имплементация и ссылки
Сначала я создал версию на JavaScript, которую можно увидеть в действии здесь. Эта версия способна запустить 100 прогонов за приемлемое время. Откройте консоль для дополнительной информации. (исходники)
Позже, чтобы поиграться, я использовал высокооптимизированную инфраструктуру @nneonneo и реализовал свою версию на C++. Эта версия допускает до 100000 пробежек за ход и даже 1000000, если Вы готовы подождать. Инструкция по сборке прилагается. Всё работает в консоли, а также имеет пульт дистанционного управления для воспроизведения в веб-версии. (исходники)
Результаты
Удивительно, но увеличение количества прогонов кардинально не улучшает игровой процесс. Кажется, что у этой стратегии есть предел в 80000 пунктов с плиткой 4096 и всеми меньшими результатами, очень близкими к достижению плитки 8192. Увеличение количества прогонов со 100 до 100000 увеличивает шансы на достижение этого лимита (с 5% до 40%), но не преодолевает его.
Выполнение 10000 прогонов с временным увеличением до 1000000 вблизи критических позиций позволило преодолеть этот барьер менее чем в 1% случаев с достижением максимального количества набранных очков 129892 и плитки 8192.
Улучшения и оптимизации
После реализации этого алгоритма я попробовал много улучшений, включая использование минимальных или максимальных оценок или комбинации минимальных, максимальных и средних значений. Я также пытался использовать глубину: вместо того, чтобы пытаться выполнить K прогонов за ход, я пробовал K ходов за список ходов заданной длины (например, «вверх, вверх, влево») и выбирал первый ход из списка ходов с лучшим выигрышем.
Позже я реализовал дерево подсчета очков, которое учитывало условную вероятность того, что он сможет выполнить ход после заданного списка ходов.
Однако ни одна из этих идей не показала реального преимущества перед простой первой идеей. Я оставил закомментироанный код для этих идей в исходниках C++.
Я добавил механизм «Глубокий поиск», который временно увеличивал число прогонов до 1000000, когда любой из прогонов сумел случайно достичь следующей наивысшей плитки. Это привело к улучшению по временным показателям.
Мне было бы интересно узнать, есть ли у кого-нибудь другие идеи по улучшению, которые поддерживают независимость ИИ от предметной области?
Варианты и клоны 2048
Ради интереса, я также реализовал ИИ в виде букмарклета, подключив его к элементам управления игры. Это позволяет работать как с оригинальной игрой, так и со многими ее вариациями.
Это возможно благодаря доменно-независимой природе ИИ. Некоторые из вариантов довольно оригинальны, такие как гексагональный клон.
| На этом перевод завершён, но не только ради него затеяна данная публикация. До коликов захотелось самому проверить различные идеи для ИИ в 2048. С этой целью реализовал игру в Excel, написав приложение с макросами. Сама по себя реализация на VBA подвигом не является — погуглив, можно быстро обнаружить с дюжину различных эксцельных поделок. А вот не только состряпать 2048 в виде электронных таблиц, но и реализовать компьютерную самостоятельную игру — этого мне пока на глаза не попадалось. |
2048.xlsm
Само Excel-приложение можно скачать с гугл-диска.
Картинка кликабельна — откроется полноформатное изображение.
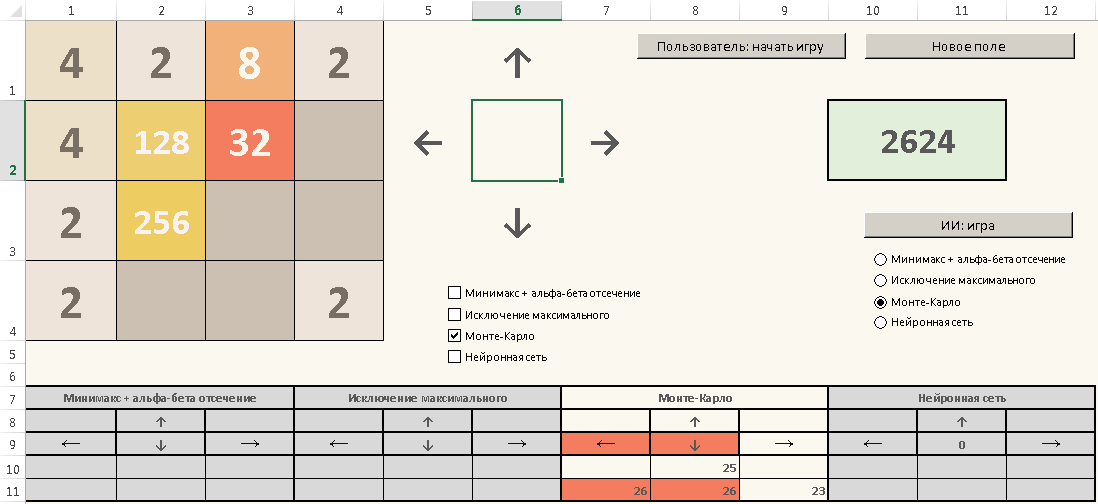
Кратко по интерфейсу и функционалу приложения.
Чтобы начать играть, нужно нажать на кнопку "Пользователь: начать игру". При повторных нажатиях на эту кнопку надпись меняется с "Пользователь: начать игру" на "Пользователь: завершить игру" и обратно, то есть в любой момент можно останавливать игру и затем запускать её снова. При остановке игры можно вручную поменять расклад на поле, улучшив или ухудшив свою позицию в целях тестирования или проверки каких-то идей.
Во время непосредственно игры можно делать ходы двумя способами:
- Клавиатурно: просто нажимая клавиши «вверх», «вниз», «влево», «вправо».
- С помощью мыши: щёлкая по клеткам с большими стрелочками, указывающими на нужное направление.
Кнопка "Новое поле" очищает игровое поле и на нём в случайном порядке размещает «двойку» и «четвёрку».
Самое интересное — метод Монте-Карло удалось реализовать, именно в том виде, в каком его предложил чувак со stackoverflow. На каждой позиции компьютер в памяти перебирает случайные ответвления для каждого первого хода («вверх», «вниз», «влево», «вправо») до тех пор пока это не приведёт к проигрышу. Статистически самое выгодное направление подсвечивается красным цветом в специальной таблице внизу. Можно использовать как подсказку, если видите что Ваша собственная игра заходит в тупик и нужно как-то спасаться. ;)
Над таблицей находятся чекбоксы с вариантами анализа. На данный момент решён только Монте-Карло, остальные будут добавлены в ближайшие дни (по итогам чего будут ещё хабрастатьи с обновлением excel-приложения и пояснениями по теории).
Также есть кнопка "ИИ: игра". Щёлкнув по ней, компьютерный помошник сделает один ход в соответствии с методом Монте-Карло или каким-то другим, который выбран в группе переключателей (минимакс и нейронная сеть будут в этом списке работать чуть позже).
safari2012
35584 получилось в браузере
valemak Автор
Не так интересен общий счёт как максимальная плитка.
maxzhurkin
И вот тут никак не удаётся добраться до 32768 :(
valemak Автор
Методом Монте-Карло, судя по всему, даже вдвое меньшая плитка 16k недостижима.
Вручную некоторые маньяки (в том числе и с хабра) достигали и более высоких результатов чем 32k, выкладывая плиточки змейкой. Но я даже боюсь подумать сколько часов нужно убить на это. Лично у меня рекорд 4096, дальше я скучаю и бросаю игру.
Если же речи об ИИ, то с помощью minimax и expectimax можно достигать максимально возможных результатов. Эти способы тоже разберём в ближайшее время.
voted
В опции игры когда 1 последний ход можно было отменить — я руками набирал плитку 131072, но с 7й попытки вроде (если бы можно было отменять несколько то и 1й всегда можно), месяц на 8й примерно :)
valemak Автор
А сколько времени уходит на один сеанс подобного марафона?
Vantela
По моему опыту примерно месяц катания на метро:)
Тоже делал когда то максимальную плитку.
valemak Автор
Хочу уточнить — это каждый день, при поездке на работу и обратно приходилось начинать заново каждый раз? И как-то раз — хоп — удалось собрать максимум?
Или же Вы действовали обдуманно и не спеша, приостанавливая игру когда прибываете к месту назначения и затем с этой позиции продолжая играть в следующей поездке? И таким образом, одна-единственная игра длилась почти месяц?
Vantela
Нет, нет! Конечно, прогресс сохранялся.
Месяц это по протяженности. А само время игры как именно игры — гораздо меньше.
Но оценить в часах очень сложно. Все таки, иногда я не играл, а дремал или играл в другие игры или читал.
На самом деле если чуть потренироваться, думаю за пол дня можно сделать максимальную плитку. Но добить максимум очков как у voted это сильно сложнее.
Еще нюанс — возникают плитки 2 или 4. Так вот если в неправильный момент возникли плитки 2 и 4 (вместо двух четверок!), то максимальное количество очков не получается. Поэтому без UNDO никак. Или же начинать сначала.
alexey_c
Это «с продолжением».
Посчитайте для примера, если взять тупо ход в секунду, сколько их уйдёт на набор хотя бы плитки 64К.
Реально несколько дней в транспорте.
Я добирался до состояния («змейкой») [64К, 16К, 8К, 4К, 2К, 512, 256, 64, 32, 16, 8] с пустыми клетками, это примерно 1,35 млн. очков. Но дальше — перешел на езду за рулём и на 2048 забил.
Играю методом заполнения «змейкой», с ходами только в трёх направлениях.
voted
На эту конкретно попытку ушло месяца 2 или 3, по 1-3 часа в день игры, прогресс сохранялся, в это время я за утренним кофе ленту FB не просматривал, играл в транспорте (игра не требует инета), когда ждал в каких то очередях, ну и само собой вместо чтения в туалете :)
Germanjon
Почему-то за три прогона ИИ ни разу не воспользовался оптимальной стратегией — загнать максимальную плитку в один из углов и выстраивать остальные змейкой
valemak Автор
Потому что в данном случае эта стратегия не запрограммирована.
Монте-Карло вообще «недальновидный» метод. Его философия — нахапать побольше очков здесь и сейчас, не заботясь о том, что с увеличением значения максимальной плитки в произвольном месте поля — схлопывать всё сложнее и сложнее. Поэтому и достигается планка 4096, выше которой в Монте-Карло прыгнуть почти никогда нельзя.
Метод минимакса, который будет разобран в следующей хабрастатье действует уже стратегически, держа самую жирную плитку в углу и стагивая к ней плитки поменьше с обеих сторон. Это ещё не пресловутая «змейка», но уже нечто похожее на неё.
А потом мы дойдём до expectimax, которому хоть и не указывается прямо собирать «змейкой», но который интуитивно выходит именно на неё. Этот метод способен собрать максимально возможное количество на поле.
Можно сказать, что мы разберём эти методы ИИ в порядке возрастания их интеллектуальности — от самого топорного (Монте-Карло — это почти брутфорс) к наиболее изощрённому.
maxim_0_o
Почему-то после прочтения захотелось попробовать реализовать нечто похожее, но на генетических алгоритмах. Но что-то мне подсказывает, что через минут 15 это желание пройдет :)
valemak Автор
Энтузиазм может сойти на нет, если будете с нуля писать 2048 а уже потом писать обучение. Если сэкономите силы и не допустите преждевременного перегорания — т.е. найдёте и разберетесь уже в какой-либо готовой реализации 2048 и сразу приступите к своему алгоритму, то есть вероятность что запала хватит довести дело до конца.