Примерно так же до 2018 года было устроено распознавание японских и китайских символов: в первую очередь с использованием растровых и признаковых классификаторов. Но с распознаванием иероглифов есть свои трудности:
- Огромное количество классов, которое нужно различать.
- Более сложное устройство символа в целом.

Сказать однозначно, сколько символов насчитывает китайская письменность, так же сложно, как точно посчитать, сколько слов в русском языке. Но наиболее часто в китайской письменности используются ~10 000 символов. Ими мы и ограничили число классов, используемых при распознавании.
Обе описанные выше проблемы также приводят и к тому, что для достижения высокого качества приходится использовать большое количество признаков и сами эти признаки вычисляются на изображениях символов дольше.
Чтобы эти проблемы не приводили к сильнейшим замедлениям во всей системе распознавания, приходилось использовать множество эвристик, в первую очередь направленных на то, чтобы быстро отсечь значительное количество иероглифов, на которые эта картинка точно не похожа. Это всё равно не до конца помогало, а нам хотелось вывести наши технологии на качественно новый уровень.
Мы стали исследовать применимость свёрточных нейронных сетей, чтобы поднять как качество, так и скорость распознавания иероглифов. Хотелось заменить весь блок распознавания отдельного символа для этих языков с помощью нейронных сетей. В этой статье мы расскажем, как нам в итоге это удалось.
Простой подход: одна свёрточная сеть для распознавания всех иероглифов
В общем-то использование свёрточных сетей для распознавания символов идея совсем не новая. Исторически их первый раз применили именно для этой задачи ещё в далёком 1998 году. Правда тогда это были не печатные иероглифы, а рукописные английские буквы и цифры.
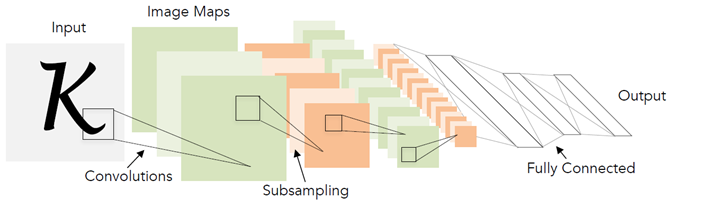
За 20 лет технологии в области глубокого обучения, конечно, сильно скакнули вперёд. В том числе появились более продвинутые архитектуры и новые подходы к обучению.
Архитектура, представленная на схеме выше (LeNet), на самом деле и на сегодняшний день очень хорошо подходит для таких простых задач как распознавание печатного текста. «Простой» я её называю по сравнению с другими задачами компьютерного зрения как, например, поиск и распознавание лиц.
Казалось бы – вот решение проще некуда. Берём нейронную сеть, выборку из размеченных иероглифов и обучаем её на задачу классификации. К сожалению, оказалось, что всё не так просто. Все возможные модификации LeNet для задачи классификации 10 000 иероглифов не давали достаточного качества (как минимум сравнимого с уже имеющейся у нас системой распознавания).
Для достижения требуемого качества приходилось рассматривать более глубокие и сложные архитектуры: WideResNet, SqueezeNet и т.д. С их помощью удалось достичь требуемой планки качества, но они давали сильную просадку по скорости работы – в 3-5 раз по сравнению с базовым алгоритмом на CPU.
Кто-нибудь может задаться вопросом: «В чём смысл измерять скорость работы сети на CPU, если она куда быстрее работает на графическом процессоре (GPU)»? Здесь стоит сделать ремарку относительно того, что для нас в первую очередь важна именно скорость работы алгоритма на CPU. Мы разрабатываем технологии для большой линейки продуктов распознавания в ABBYY. В наибольшем количестве сценариев распознавание производится на стороне клиента, и мы не можем заведомо предполагать, что у него есть GPU.
Так вот, в итоге мы пришли к следующей проблеме: одна нейронная сеть для распознавания всех символов в зависимости от выбора архитектуры работает или слишком плохо, или же слишком медленно.
Двухуровневая нейросетевая модель распознавания иероглифов
Пришлось искать другой путь. При этом отказываться от нейронных сетей не хотелось. Казалось, что самая большая проблема – это огромное число классов, из-за которых приходится строить сети сложной архитектуры. Поэтому мы решили, что не будем обучать сеть на большое число классов, то есть на весь алфавит, но будем вместо этого обучать много сетей на небольшое число классов (подмножества алфавита).
В общих деталях идеальная система представлялась следующим образом: алфавит разбивается на группы похожих символов. Сеть первого уровня классифицирует, к какой группе символов принадлежит данное изображение. Для каждой группы в свою очередь обучена сеть второго уровня, которая производит окончательную классификацию в рамках каждой группы.
Картинка кликабельна
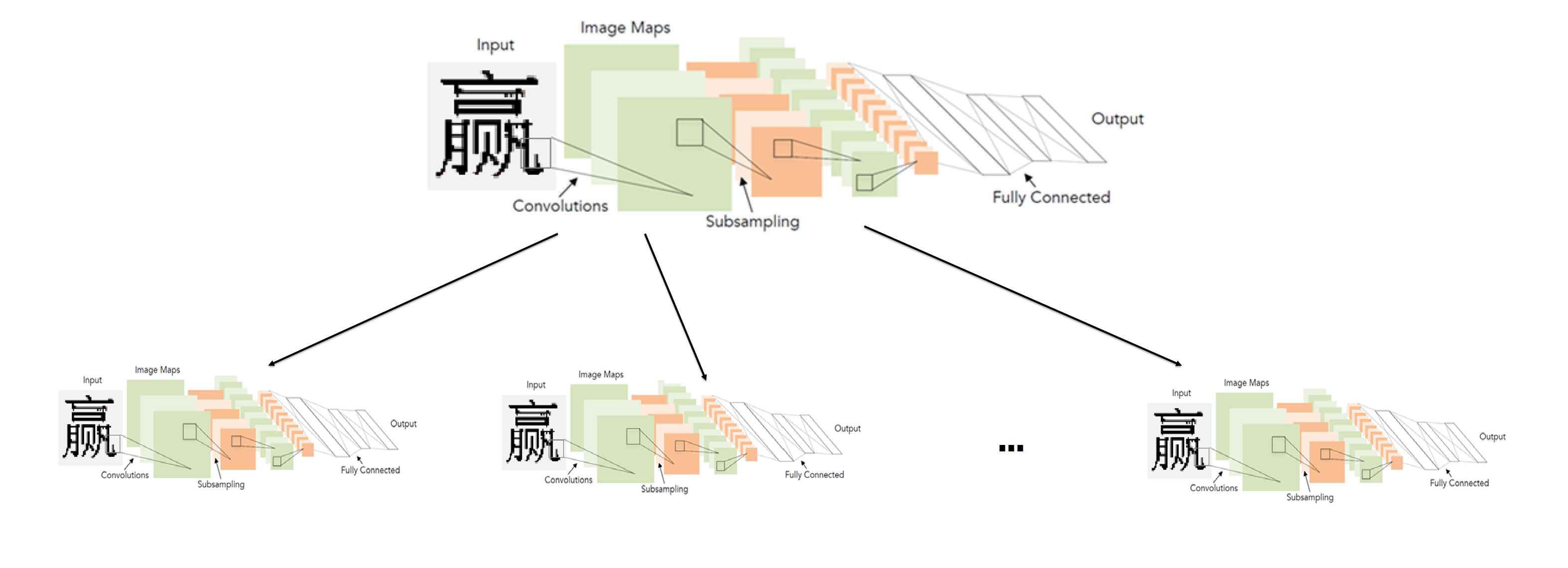
Таким образом, итоговую классификацию мы производим запуском двух сетей: первая определяет, какую сеть второго уровня запускать, а вторая уже производит конечную классификацию.
Собственно, принципиальный момент здесь состоит в том, как же разделить символы на группы таким образом, чтобы сеть первого уровня можно было бы сделать точной и быстрой.
Построение классификатора первого уровня
Чтобы понять какие символы сети отличать проще, а какие сложнее, проще всего посмотреть на то, какие признаки выделяются для тех или иных символов. Для этого мы взяли сеть-классификатор, обученную различать все символы алфавита с хорошим качеством и посмотрели на статистику активаций предпоследнего слоя этой сети – стали смотреть на итоговые признаковые представления, которые сеть получает для всех символов.
При этом мы знали, что картинка там должна получаться примерно следующей:
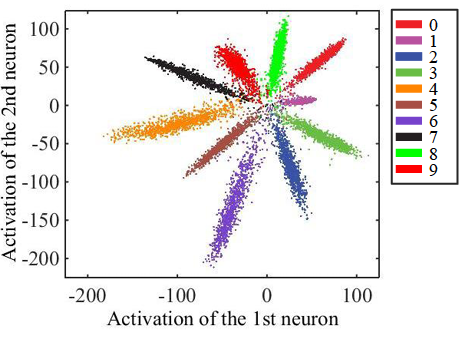
Это простой пример для случая классификации выборки рукописных цифр (MNIST) на 10 классов. На предпоследнем скрытом слое, идущем до классификации, всего 2 нейрона, благодаря чему статистику их активаций легко отобразить на плоскости. Каждая точка на графике соответствует какому-то примеру из тестовой выборки. Цвет точки соответствует определённому классу.
В нашем случае размерность признакового пространства была больше, чем в примере – 128. Мы прогнали группу изображений из тестовой выборки и получили для каждого изображения вектор признаков. После этого нормализовали их (поделили на длину). Из картинки выше очевидно, почему это стоит сделать. Нормализованные вектора мы кластеризовали методом KMeans. Получили разбиение выборки на группы похожих (с точки зрения сети) изображений.
Но нам в конечном итоге нужно было получить разбиение алфавита на группы, а не разбиение тестовой выборки. Но первое из второго получить несложно: достаточно каждую метку класса отнести к тому кластеру, в который попало больше всего изображений данного класса. В большинстве ситуаций, конечно же, весь класс и вовсе будет оказываться внутри одного кластера.
Ну вот и всё, мы получили разбиение всего алфавита на группы похожих символов. Дальше остаётся выбрать простую архитектуру и обучить классификатор различать эти группы.
Вот пример случайных 6 групп, которые получены в результате разбиения всего исходного алфавита на 500 кластеров:

Построение классификаторов второго уровня
Дальше нужно определиться с тем, на какие целевые множества символов будут учиться классификаторы второго уровня. Вроде бы ответ очевиден – это должны быть полученные на предыдущем шаге группы символов. Это будет работать, но не всегда с хорошим качеством.
Дело в том, что классификатор первого уровня в любом случае допускает ошибки и их можно частично нивелировать построением множеств второго уровня следующим образом:
- Фиксируем некоторую отдельную выборку изображений символов (не участвующую ни в обучении, ни в тестировании);
- Прогоняем эту выборку через обученный классификатор первого уровня, помечая каждое изображение меткой этого классификатора (метка группы);
- Для каждого символа рассматриваем все возможные группы, к которым изображения этого символа отнёс классификатор первого уровня;
- Добавляем этот символ во все группы до тех пор, пока не будет достигнута требуемая степень покрытия T_acc;
- Итоговые группы символов считаем целевыми множествами второго уровня, на которые будут обучаться классификаторы.
Например, изображения символа «А» были отнесены классификатором первого уровня 980 раз к 5-й группе, 19 раз ко 2-й группе и 1 раз к 6-ой группе. Всего у нас 1000 изображений этого символа.
Тогда мы можем добавить символ «А» в 5-ю группу и получить покрытие этого символа в 98%. Можем отнести его к 5-ой и 2-ой группе и получить покрытие 99.9%. А можем отнести сразу к группам (5, 2, 6) и получить покрытие 100%.
По сути T_acc задаёт некоторый баланс между скоростью и качеством. Чем он выше – тем выше будет итоговое качество классификации, но тем больше будут целевые множества второго уровня и потенциально сложнее устроена классификация на втором уровне.
Практика показывает, что даже при T_acc=1 увеличение размера множеств в результате описанной выше процедуры пополнения не такое уж и значительное – в среднем где-то в 2 раза. Очевидно, что это будет напрямую будет зависеть от качества обученного классификатора первого уровня.
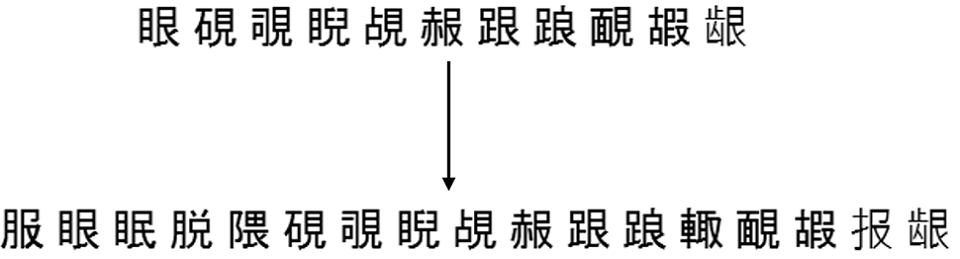
Вот пример того, как это пополнение работает для одного из множеств из того же разбиения на 500 групп, которое было выше:
Результаты встраивания модели
Обученные двухуровневые модели уже наконец-то работали быстрее и лучше используемых ранее классификаторов. На деле её было не так-то просто «подружить» с тем же графом линейного деления (ГЛД). Для этого пришлось отдельно научить модель отличать символы от априорного мусора и ошибок сегментации строки (возвращать в этих ситуациях низкую уверенность).
Итоговый результат встраивания в полный алгоритм распознавания документа ниже (получен на коллекции китайских и японских документов), скорость указана для полного алгоритма:
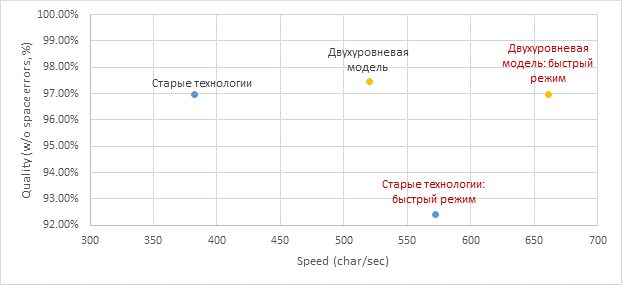
Мы подняли качество и ускорились как в обычном, так и в быстром режиме, переведя при этом всё символьное распознавание на нейронные сети.
Немного про End-to-End распознавание
На сегодняшний день большая часть публично известных OCR-систем (тот же Tesseract от Google) использует End-to-End архитектуры нейронных сетей для распознавания строк или их фрагментов целиком. Мы же здесь использовали нейронные сети именно как замену модуля распознавания отдельного символа. Это неспроста.
Дело в том, что сегментация строки на символы в печатном китайском и японском не является большой проблемой в силу моноширинной печати. В связи с этим использование End-to-End распознавания для этих языков не сильно улучшает качество, но при этом значительно медленнее (по крайней мере на CPU). Да и вообще, как в контексте End-to-End использовать предложенный двухуровневый подход – непонятно.
Есть же наоборот языки, для которых линейное деление на символы является ключевой проблемой. Явные примеры – арабский, хинди. Для арабского, например, End-to-End решения уже активно у нас исследуются. Но это уже совсем другая история.
Алексей Журавлев, руководитель OCR New Technologies Group
Комментарии (11)

RobertLis
06.02.2019 13:51+1Вы не пробовали CapsNet для End-to-End?
В иероглифах важно взаимное расположение небольшого количества стандартных элементов, а сильная сторона CapsNet вроде бы как раз в умении выделять подобные вещи. То есть они могут хорошо решить задачу факторизации иероглифа.
Или это тоже тупик?
AlekseyZhuravlev Автор
06.02.2019 14:16+1Капсульные сети в задачах распознавания пока не пробовали. В теории действительно может хорошо работать для иероглифов, но экспериментов пока не было, так что точно сказать не могу. Не думаю, что это тупик, но в научном сообществе применения CapsNets для End-to-End OCR нигде не видел.
ericgrig
07.02.2019 00:56Алексей, спасибо за подробное изложение вашего подхода к распознаванию китайских иероглифов с помощью нейронных сетей. Я, когда-то интересовался этой задачей. Хочу спросить: «Есть ли возможность воспользоваться данными растровых изображений всех 10 000 иероглифов для целей обучения?». Хотелось бы восстановить алгоритм и пропустить через него. Может удастся чем-то помочь.
AlekseyZhuravlev Автор
07.02.2019 11:34Спасибо, рады стараться. Ваш вопрос не совсем понял. В нашем подходе по факту используются для обучения растровые данные (картинки) всех доступных изображений иероглифов. Или вы имеете ввиду данные, полученным синтетическим рендерингом из шрифтов?
Nashev
А не пробовали заточить сети на распознавание составляющих иероглифы элементов по отдельности, и затем другую сеть на распознавание иероглифов по сочетаниям и положениям элементов?
AlekseyZhuravlev Автор
Да, такой подход мы называем факторизацией, мы его тоже пробовали. Он очень хорошо работает для корейской письменности, там собственно он и используется. Для китайского качество пока получается ниже, чем у двухуровневой модели, но мы планируем продолжать исследования в этом направлении.
Nashev
Если честно, мне кажется этот подход и для латиницы с кириллицей должен прекрасно срабатывать. Особенно, если отслеживать не только наличие элементов, их положение, но и их способы их связанности друг с другом — отступы, засечки, промежутки, сдвиги и т.п…
AlekseyZhuravlev Автор
Да, может заработать. Здесь главный вопрос в том, каким образом такую сложную информацию закодировать в выходах нейронной сети, чтобы она при этом хорошо обучилась.
Для корейского с факторизацией всё просто и интуитивно, т.к. составляющих элементов достаточно мало, и их позиции в символе строго фиксированы. В итоге можно просто сделать у сети 4 выхода небольшого размера, которые кодируют символ.
Для китайского уже становится сложнее, потому что составляющих элементов сильно больше, как и возможных комбинаций их взаимного расположения.
С европейскими языками, кстати, скорее всего будет проще, чем с китайским, тут вопрос эксперимента. Другой вопрос будет ли от этого какая-то практическая польза, ибо алфавит там уже небольшой и распознаётся хорошо и быстро одной простенькой нейросетью.
Nashev
Я пока не разобрался, в каком формате выводятся из сетей, определяющих лица, положение найденного лица на фотографии? Но почему-то уверен, что примерно в этом же формате можно их передавать сетке, оценивающей сочетание элементов.
AlekseyZhuravlev Автор
Там обычно предсказывают 3 числа, соответствующие углам поворота в пространстве (Yaw, pitch, roll) и обучают на это задачу регрессии. В символах тоже можно подумать в направлении регрессии и кодирования взаимного расположения элементов через неё, вполне возможно что заработает.
Nashev
Это ж Вы не про позицию, а про ракурс. А я про позицию…