
(картинка с официального сайта)
Buildbot, как несложно догадаться из названия, является инструментом для непрерывной интеграции (continuous integration system, ci). Про него уже было несколько статей на хабре, но, с моей точки зрения, из них не очень понятны преимущества сего инструмента. Кроме того, в них почти нет примеров, из-за чего трудно увидеть всю мощь программы. В своей статье я постараюсь восполнить эти недостатки, расскажу про внутренне устройство Buildbot'a и приведу примеры нескольких нестандартных сценариев.
Общие слова
В настоящее время есть огромное множество систем непрерывной интеграции и когда речь заходит об одной из них, то появляются вполне логичные вопросы в духе «А зачем она нужна, если уже есть <program_name> и все ей пользуются?». Постараюсь ответить на такой вопрос о Buildbot'e. Часть информации будет дублироваться с уже существующими статьями, часть описана в официальной документации, но это необходимо для последовательности повествования.
Основное отличие от других систем непрерывной интеграции состоит в том, что Buildbot является питоновским фреймворком для написания ci, а не решением из коробки. Это означает, что для подключения какого-либо проекта к Buildbot'у вы должны сначала написать отдельную программу на питоне с использованием Buildbot-фреймворка, реализующую необходимую вашему проекту функциональность по непрерывной интеграции. Такой подход обеспечивает огромную гибкость, позволяя реализовывать хитрые сценарии тестирования, которые невозможны для решений из коробки в силу архитектурных ограничений.
Далее, Buildbot не является сервисом, а потому вы должны честно развернуть его на своей инфраструктуре. Здесь я отмечу то, что фреймворк весьма лоялен к ресурсам системы. Это конечно не С или С++, но у своих Java конкурентов питон выигрывает. Вот, например, сравнение потребления памяти с GoCD (и да, несмотря на название, это система на джаве):
Buildbot:
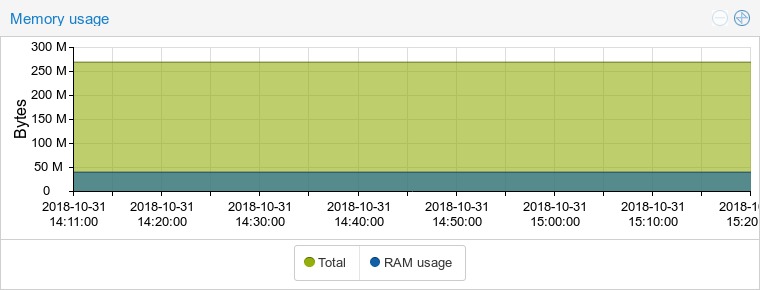
GoCD:

Самостоятельное развертывание и написание отдельной программы для тестирования могут нагонять тоску при мысли о первоначальной настройке. Тем не менее, написание сценариев сильно упрощается за счет огромного количества встроенных классов. Эти классы покрывают множество стандартных операций, будь то получение изменений из гитхабовского репозитория или сборка проекта CMake'ом. Как результат, стандартные сценарии для небольших проектов будут не сложнее YML-файлов для какого-нибудь travis-ci. Про развертывание я писать не буду, это подробно освещено в существующих статьях и ничего сложного там тоже нет.
Следующей особенностью Buildbot'a я отмечу то, что по умолчанию логика тестирования реализуется на стороне ci-сервера. Это идет в разрез с популярным нынче подходом «pipeline as a code», при котором логика тестирования описывается в файле (вроде .travis.yml), лежащим в репозитории вместе с исходным кодом проекта, а ci-сервер лишь считывает этот файл и выполняет то, что в нем сказано. Повторюсь, что это лишь поведение по умолчанию. Возможности Buildbot-фреймворка позволяют реализовать описанный подход с хранением сценария тестирования в репозитории. Есть даже готовое решение — bb-travis, которое старается взять лучшее от Buildbot'a и travis-ci. Кроме того, дальше в этой статье я опишу как реализовать что-то похожее на такое поведение самому.
Buildbot по-умолчанию собирает каждый коммит при пуше. Это может показаться какой-то мелкой ненужной фичей, но для меня это, наоборот, стало одним из главных преимуществ. Многие популярные решения из коробки (travis-ci, gitlab-ci) такую возможность вообще не предоставляют, работая лишь с последним коммитом на ветке. Представьте, что во время разработки вам часто приходится cherry-pick'ать коммиты. Будет неприятно взять нерабочий коммит, который не проверялся системой сборки из-за того, что был запушен вместе с пачкой коммитов сверху. Конечно, в Buildbot'e сборку только последнего коммита тоже можно сделать, причем делается это установкой всего одного параметра.
Фреймворк обладает достаточно хорошей документацией, в которой все подробно описывается от общей архитектуры до руководств по расширению встроенных классов. Тем не менее, даже несмотря на такую документацию, некоторые вещи вам может придется смотреть в исходом коде. Он полностью открыт под лицензией GPL v2 и легко читаем. Из минусов — документация доступна только на английском языке, на русском в сети информации совсем немного. Инструмент появился не вчера, с его помощью собирается сам питон, Wireshark, LLVM и множество других известных проектов. Выходят обновления, проект поддерживается множеством разработчиков, поэтому можно говорить о надежности и стабильности.
(главная страница Python Buildbot)
Теормин
Эта часть по сути является вольным переводом главы официальной документации, посвященной архитектуре фреймворка. Здесь показывается полная цепочка действий от получения изменений ci-системой до отправки уведомлений о результате пользователям. Итак, вы внесли изменения в исходный код проекта и отправили их в удаленный репозиторий. То что произойдет далее схематично показано на картинке:

(картинка из официальной документации)
Первым делом Buildbot должен как-то узнать о том, что в репозитории произошли изменения. Основных способов здесь два — вебхуки и поллинг, хотя никто не запрещает придумать что-то более изощренное. В первом случае в Buildbot'e за это отвечают классы-наследники BaseHookHandler. Есть много готовых решений, например, GitHubHandler или GitoriusHandler. Ключевой метод в этих классах — getChanges(). Его логика предельно проста: он должен преобразовать HTTP-запрос в список объектов-изменений (changes).
Для второго случая нужны классы-наследники PollingChangeSource. Опять же, есть готовые решения, например GitPoller или HgPoller. Ключевой метод — poll(). Он вызывается с определенной частотой и должен каким-то образом создавать список изменений в репозитории. В случае гита это может быть вызов git fetch и сравнение с предыдущим сохраненным состоянием. Если встроенных возможностей не хватает, то достаточно создать свой класс-наследник и перегрузить метод. Пример использования поллинга:
c['change_source'] = [changes.GitPoller(
repourl = 'git@git.example.com:project',
project = 'My Project',
branches = True, # получаем изменения со всех веток
pollInterval = 60
)]Вебхук использовать еще проще, главное не забыть настроить его на стороне git-сервера. В конфигурационном файле это всего одна строчка:
c['www']['change_hook_dialects'] = { 'github': {} }Следующим шагом объекты-изменения поступают на вход объектам-планировщикам (schedulers). Примеры встроенных планировщиков: AnyBranchScheduler, NightlyScheduler, ForceScheduler и т.д. Каждый планировщик получает на вход все объекты-изменения, но выбирает только те из них, которые проходят фильтр. Фильтр передается планировщику в конструкторе через аргумент change_filter. На выходе планировщики создают запросы на сборку (build requests). Планировщик выбирает сборщики на основании аргумента builders.
У некоторых планировщиков есть хитрый аргумент, именуемый treeStableTimer. Работает он следующим образом: при получении изменения планировщик не создает сразу новый запрос на сборку, а запускает таймер. Если приходят новые изменения, а таймер не истек, то старое изменение заменяется на новое, а таймер обновляется. Когда таймер заканчивается, планировщик создает всего лишь один запрос на сборку из последнего сохраненного изменения.
Таким образом реализуется логика сборки только последнего коммита при пуше. Пример настройки планировщика:
c['schedulers'] = [schedulers.AnyBranchScheduler(
name = 'My Scheduler',
treeStableTimer = None,
change_filter = util.ChangeFilter(project = 'My Project'),
builderNames = ['My Builder']
)]Запросы на сборку, как бы странно это ни звучало, поступают на вход сборщикам (builders). Задача сборщика — запустить сборку на доступном «работнике» (worker). Worker — это окружение для сборки, например, stretch64 или ubuntu1804x64. Список worker'ов передается через аргумент workers. Все worker'ы в списке должны быть одинаковыми (т.е. названия-то естественно разные, но окружение внутри одинаковое), поскольку сборщик волен выбрать любой из доступных. Задание нескольких значений здесь служит для балансировки нагрузки, а не для сборки в разных окружениях. Через аргумент factory сборщик получает последовательность шагов для сборки проекта. Про это я подробно распишу далее.
Пример настройки сборщика:
c['builders'] = [util.BuilderConfig(
name = 'My Builder',
workernames = ['stretch32'],
factory = factory
)]Итак, проект собрался. Последний шаг Buildbot'a — уведомление о сборке. За это отвечают классы-докладчики (reporters). Классический пример — класс MailNotifier, который отправляет электронное письмо с результатами сборки. Пример подключения MailNotifier:
c['services'] = [reporters.MailNotifier(
fromaddr = 'buildbot@example.com',
relayhost = 'mail.example.com',
smtpPort = 25,
extraRecipients = ['devel@example.com'],
sendToInterestedUsers = False
)]Что ж, пора переходить к полноценным примерам. Замечу, что сам Buildbot написан с помощью фреймворка Twisted, а потому знакомство с ним существенно облегчит написание и понимание сценариев Buildbot'a. Мальчиком для битья у нас будет проект с названием Pet Project. Пусть он написан на C++, собирается с помощью CMake, а исходный код лежит в git-репозитории. Мы даже не поленились и написали для него тесты, которые запускаются командой ctest. Совсем недавно мы прочитали эту статью и поняли, что хотим применить свежеполученные знания к своему проекту.
Пример первый: чтоб работало
Собственно, конфигурационный файл:
from buildbot.plugins import *
# shortcut
c = BuildmasterConfig = {}
# create workers
c['workers'] = [worker.Worker('stretch32', 'example_password')]
# general settings
c['title'] = 'Buildbot: test'
c['titleURL'] = 'https://buildbot.example.com/'
c['buildbotURL'] = 'https://buildbot.example.com/'
# setup database
c['db'] = { 'db_url': 'sqlite:///state.sqlite' }
# port to communicate with workers
c['protocols'] = { 'pb': { 'port': 9989 } }
# make buildbot developers a little bit happier
c['buildbotNetUsageData'] = 'basic'
# webserver setup
c['www'] = dict(plugins = dict(waterfall_view={}, console_view={}, grid_view={}))
c['www']['authz'] = util.Authz(
allowRules = [util.AnyEndpointMatcher(role = 'admins')],
roleMatchers = [util.RolesFromUsername(roles = ['admins'], usernames = ['root'])]
)
c['www']['auth'] = util.UserPasswordAuth([('root', 'root_password')])
# mail notification
c['services'] = [reporters.MailNotifier(
fromaddr = 'buildbot@example.com',
relayhost = 'mail.example.com',
smtpPort = 25,
extraRecipients = ['devel@example.com'],
sendToInterestedUsers = False
)]
c['change_source'] = [changes.GitPoller(
repourl = 'git@git.example.com:pet-project',
project = 'Pet Project',
branches = True,
pollInterval = 60
)]
c['schedulers'] = [schedulers.AnyBranchScheduler(
name = 'Pet Project Scheduler',
treeStableTimer = None,
change_filter = util.ChangeFilter(project = 'Pet Project'),
builderNames = ['Pet Project Builder']
)]
factory = util.BuildFactory()
factory.addStep(steps.Git(
repourl = util.Property('repository'),
workdir = 'sources',
haltOnFailure = True,
submodules = True,
progress = True)
)
factory.addStep(steps.ShellSequence(
name = 'create builddir',
haltOnFailure = True,
hideStepIf = lambda results, s: results == util.SUCCESS,
commands = [
util.ShellArg(command = ['rm', '-rf', 'build']),
util.ShellArg(command = ['mkdir', 'build'])
])
)
factory.addStep(steps.CMake(
workdir = 'build',
path = '../sources',
haltOnFailure = True)
)
factory.addStep(steps.Compile(
name = 'build project',
workdir = 'build',
haltOnFailure = True,
warnOnWarnings = True,
command = ['make'])
)
factory.addStep(steps.ShellCommand(
name = 'run tests',
workdir = 'build',
haltOnFailure = True,
command = ['ctest'])
)
c['builders'] = [util.BuilderConfig(
name = 'Pet Project Builder',
workernames = ['stretch32'],
factory = factory
)]Написав эти строки мы получим автоматическую сборку при пуше в репозиторий, красивую веб-морду, уведомления по email и прочие атрибуты любой уважающей себя ci. Большая часть тут должна быть понятна: настройки планировщиков, сборщиков и других объектов сделаны аналогично приведенным ранее примерам, значение большинства параметров интуитивно понятно. Подробно я остановлюсь только на создании фабрики, что и обещал сделать раньше.
Фабрика состоит из шагов (build steps), которые Buildbot должен выполнить для проекта. Как и в случае с другими классами, есть много готовых решений. Наша фабрика состоит из пяти шагов. Как правило, на первом шаге нужно получить актуальное состояние репозитория, и здесь мы не будем делать исключение. Для этого мы используем стандартный класс Git:
factory = util.BuildFactory()
factory.addStep(steps.Git(
repourl = util.Property('repository'),
workdir = 'sources',
haltOnFailure = True,
submodules = True,
progress = True)
)Далее, нам нужно создать директорию, в которой будет производиться сборка проекта — сделаем полноценный out of source build. Перед этим надо не забыть удалить директорию, если она уже существует. Таким образом, нам нужно выполнить две команды. В этом нам поможет класс ShellSequence:
factory.addStep(steps.ShellSequence(
name = 'create builddir',
haltOnFailure = True,
hideStepIf = lambda results, s: results == util.SUCCESS,
commands = [
util.ShellArg(command = ['rm', '-rf', 'build']),
util.ShellArg(command = ['mkdir', 'build'])
])
)Теперь необходимо запустить CMake. Для этого логично воспользоваться одним их двух классов — ShellCommand или CMake. Мы воспользуемся последним, но различия здесь минимальны: он является простенькой оберткой над первым классом, позволяя немного удобнее передавать специфичные для CMake аргументы.
factory.addStep(steps.CMake(
workdir = 'build',
path = '../sources',
haltOnFailure = True)
)Время компилировать проект. Как и в предыдущем случае, можно воспользоваться ShellCommand. Аналогично, есть класс Compile, который является оберткой над ShellCommand. Тем не менее, это уже более хитрая обертка: класс Compile отслеживает предупреждения при компиляции и аккуратно показывает их в отдельном логе. Именно поэтому мы воспользуемся классом Compile:
factory.addStep(steps.Compile(
name = 'build project',
workdir = 'build',
haltOnFailure = True,
warnOnWarnings = True,
command = ['make'])
)Напоследок, запустим наши тесты. Тут мы воспользуемся упомянутым ранее классом ShellCommand:
factory.addStep(steps.ShellCommand(
name = 'run tests',
workdir = 'build',
haltOnFailure = True,
command = ['ctest'])
)Пример второй: pipeline as a code
Здесь я покажу, как реализовать бюджетный вариант хранения логики тестирования вместе с исходным кодом проекта, а не в конфигурационном файле ci-сервера. Для этого положим в репозиторий с кодом файл .buildbot, в котором каждая строка состоит из слов, первое из которых интерпретируются как директория для выполнения команды, а оставшиеся как команда со своими аргументами. Для нашего Pet Project файл .buildbot будет выглядеть следующим образом:
. rm -rf build
. mkdir build
build cmake ../sources
build make
build ctestТеперь нам надо модифицировать конфигурационный файл Buildbot'a. Для анализа .buildbot файла нам придется написать класс собственного шага. Этот шаг будет читать файл .buildbot, после чего для каждой строки добавлять шаг ShellCommand с нужными аргументами. Для динамического добавления шагов мы воспользуемся методом build.addStepsAfterCurrentStep(). Выглядит совсем не страшно:
class AnalyseStep(ShellMixin, BuildStep):
def __init__(self, workdir, **kwargs):
kwargs = self.setupShellMixin(kwargs, prohibitArgs = ['command',
'workdir', 'want_stdout'])
BuildStep.__init__(self, **kwargs)
self.workdir = workdir
@defer.inlineCallbacks
def run(self):
self.stdio_log = yield self.addLog('stdio')
cmd = RemoteShellCommand(
command = ['cat', '.buildbot'],
workdir = self.workdir,
want_stdout = True,
want_stderr = True,
collectStdout = True
)
cmd.useLog(self.stdio_log)
yield self.runCommand(cmd)
if cmd.didFail():
defer.returnValue(util.FAILURE)
results = []
for row in cmd.stdout.splitlines():
lst = row.split()
dirname = lst.pop(0)
results.append(steps.ShellCommand(
name = lst[0],
command = lst,
workdir = dirname
)
)
self.build.addStepsAfterCurrentStep(results)
defer.returnValue(util.SUCCESS)Благодаря такому подходу фабрика для сборщика стала проще и универсальнее:
factory = util.BuildFactory()
factory.addStep(steps.Git(
repourl = util.Property('repository'),
workdir = 'sources',
haltOnFailure = True,
submodules = True,
progress = True,
mode = 'incremental')
)
factory.addStep(AnalyseStep(
name = 'Analyse .buildbot file',
workdir = 'sources',
haltOnFailure = True,
hideStepIf = lambda results, s: results == util.SUCCESS)
)Пример третий: worker as a code
Теперь представим, что нам рядом с кодом проекта нужно определять не последовательность команд, а окружение для сборки. По сути, определяем мы worker. .buildbot файл может выглядеть примерно так:
{
"workers": ["stretch32", "wheezy32"]
}Конфигурационный файл Buildbot'a в этом случае усложнится, ведь мы хотим, чтобы сборки на разных окружениях были связаны между собой (при ошибке хотя бы в одном окружении, весь коммит считался нерабочим). Решить проблему нам поможет двухуровневость. У нас будет локальный worker, который анализирует .buildbot файл и запускает сборки на нужных worker'ах. Сначала, как и в предыдущем примере, напишем свой шаг для анализа .buildbot файла. Для запуска сборки на конкретном worker'е используется связка из шага Trigger и специального вида планировщиков TriggerableScheduler. Наш шаг стал немного сложнее, но вполне умопостижим:
class AnalyseStep(ShellMixin, BuildStep):
def __init__(self, workdir, **kwargs):
kwargs = self.setupShellMixin(kwargs, prohibitArgs = ['command',
'workdir', 'want_stdout'])
BuildStep.__init__(self, **kwargs)
self.workdir = workdir
@defer.inlineCallbacks
def _getWorkerList(self):
cmd = RemoteShellCommand(
command = ['cat', '.buildbot'],
workdir = self.workdir,
want_stdout = True,
want_stderr = True,
collectStdout = True
)
cmd.useLog(self.stdio_log)
yield self.runCommand(cmd)
if cmd.didFail():
defer.returnValue([])
# parse JSON
try:
payload = json.loads(cmd.stdout)
workers = payload.get('workers', [])
except json.decoder.JSONDecodeError as e:
raise ValueError('Error loading JSON from .buildbot file: {}'
.format(str(e)))
defer.returnValue(workers)
@defer.inlineCallbacks
def run(self):
self.stdio_log = yield self.addLog('stdio')
try:
workers = yield self._getWorkerList()
except ValueError as e:
yield self.stdio_log.addStdout(str(e))
defer.returnValue(util.FAILURE)
results = []
for worker in workers:
results.append(steps.Trigger(
name = 'check on worker "{}"'.format(worker),
schedulerNames = ['Pet Project ({}) Scheduler'.format(worker)],
waitForFinish = True,
haltOnFailure = True,
warnOnWarnings = True,
updateSourceStamp = False,
alwaysUseLatest = False
)
)
self.build.addStepsAfterCurrentStep(results)
defer.returnValue(util.SUCCESS)Использовать этот шаг мы будем на локальном worker'е. Обратите внимание, что нашему сборщику «Pet Project Builder» мы установили тег. С помощью него мы можем фильтровать MailNotifier, сообщая ему, что письма нужно отправлять только для определенных сборщиков. Если такой фильтрации не сделать, то при сборке коммита на двух окружениях нам будет приходить три письма.
factory = util.BuildFactory()
factory.addStep(steps.Git(
repourl = util.Property('repository'),
workdir = 'sources',
haltOnFailure = True,
submodules = True,
progress = True,
mode = 'incremental')
)
factory.addStep(AnalyseStep(
name = 'Analyse .buildbot file',
workdir = 'sources',
haltOnFailure = True,
hideStepIf = lambda results, s: results == util.SUCCESS)
)
c['builders'] = [util.BuilderConfig(
name = 'Pet Project Builder',
tags = ['generic_builder'],
workernames = ['local'],
factory = factory
)]Нам осталось добавить сборщики и те самые Triggerable Schedulers для всех наших реальных worker'ов:
for worker in allWorkers:
c['schedulers'].append(schedulers.Triggerable(
name = 'Pet Project ({}) Scheduler'.format(worker),
builderNames = ['Pet Project ({}) Builder'.format(worker)])
)
c['builders'].append(util.BuilderConfig(
name = 'Pet Project ({}) Builder'.format(worker),
workernames = [worker],
factory = specific_factory)
)
(страница сборки нашего проекта в двух окружениях)
Пример четвертый: одно письмо на несколько коммитов
Если воспользоваться любым из приведенных выше примеров, то можно заметить одну неприятную особенность. Поскольку на каждый коммит создается одно письмо, то при пуше ветки с 20 новыми коммитами мы получим 20 писем. Избежать этого, как и в предыдущем примере, нам поможет двухуровневость. Также нам понадобится модифицировать класс для получения изменений. Вместо создания множества объектов-изменений мы будем создавать только один такой объект, в свойствах которого передается список всех коммитов. На скорую руку это можно сделать так:
class MultiGitHubHandler(GitHubHandler):
def getChanges(self, request):
new_changes = GitHubHandler.getChanges(self, request)
if not new_changes:
return ([], 'git')
change = new_changes[-1]
change['revision'] = '{}..{}'.format(
new_changes[0]['revision'], new_changes[-1]['revision'])
commits = [c['revision'] for c in new_changes]
change['properties']['commits'] = commits
return ([change], 'git')
c['www']['change_hook_dialects'] = {
'base': {
'custom_class': MultiGitHubHandler
}
}Для работы с таким необычным объектом-изменением нам понадобится свой специальный шаг, который динамически создает шаги, собирающие конкретный коммит:
class GenerateCommitSteps(BuildStep):
def run(self):
commits = self.getProperty('commits')
results = []
for commit in commits:
results.append(steps.Trigger(
name = 'Checking commit {}'.format(commit),
schedulerNames = ['Pet Project Commits Scheduler'],
waitForFinish = True,
haltOnFailure = True,
warnOnWarnings = True,
sourceStamp = {
'branch': util.Property('branch'),
'revision': commit,
'codebase': util.Property('codebase'),
'repository': util.Property('repository'),
'project': util.Property('project')
}
)
)
self.build.addStepsAfterCurrentStep(results)
return util.SUCCESSДобавим наш общий сборщик, который занимается только запуском сборок отдельных коммитов. Его следует отметить тегом, чтобы затем фильтровать отправку писем по этому самому тегу.
c['schedulers'] = [schedulers.AnyBranchScheduler(
name = 'Pet Project Branches Scheduler',
treeStableTimer = None,
change_filter = util.ChangeFilter(project = 'Pet Project'),
builderNames = ['Pet Project Branches Builder']
)]
branches_factory = util.BuildFactory()
branches_factory.addStep(GenerateCommitSteps(
name = 'Generate commit steps',
haltOnFailure = True,
hideStepIf = lambda results, s: results == util.SUCCESS)
)
c['builders'] = [util.BuilderConfig(
name = 'Pet Project Branches Builder',
tags = ['branch_builder'],
workernames = ['local'],
factory = branches_factory
)]Осталось добавить только сборщик для отдельных коммитов. Этот сборщик мы как раз не отмечаем тегом, а потому письма для него создаваться не будут.
c['schedulers'].append(schedulers.Triggerable(
name = 'Pet Project Commits Scheduler',
builderNames = ['Pet Project Commits Builder'])
)
c['builders'].append(util.BuilderConfig(
name = 'Pet Project Commits Builder',
workernames = ['stretch32'],
factory = specific_factory)
)Финальные слова
Эта статья никоим образом не заменяет чтение официальной документации, поэтому если вы заинтересовались Buildbot'ом, то вашим следующим шагом должно стать ее чтение. Полные версии конфигурационных файлов всех приведенных примеров доступны на гитхабе. Связанные ссылки, из которых и была взята большая часть материалов для статьи:
Комментарии (22)

vasyan
10.02.2019 20:16Так и не понял, зачем оно надо, если есть Teamcity, где можно мышкой натыкать конфигурацию, есть плагины и куча инфы на stackoverflow. Чтобы настроить CI для среднего проекта вообще мозг включать не надо, можно следовать гайдам.
PodnimatelPingvinov Автор
10.02.2019 22:10Тут справедливы все те же размышления, что я привел в ветке выше касательно дженкинса. Конкретно про TeamCity — это все же не полностью бесплатный продукт, а билдбот — тру open source.
Про настройку для среднего проекта — у любой уважающей себя ci есть раздел наподобие «getting started», если ему следовать, то задумываться почти не надо. Билдбот тут не исключение. Для себя я не считаю настройку мышкой через интерфейс проще написания конфигурационного файла, а прочитав документацию еще и хорошо понимаю, что там происходит на самом деле.
acmnu
11.02.2019 09:43Так и не понял, зачем оно надо, если есть Teamcity, где можно мышкой натыкать конфигурацию
Посмотрю я как вы будет натыкивать скажем 1к джобов.
sshikov
11.02.2019 10:19Кстати, чистая правда. Данный конкретный продукт на меня не произвел впечатление, но сам подход в виде написания скриптов — он вполне имеет право на жизнь. Скажем, дженкинсовский CLI достаточно примитивен, и зачастую хочется большего. А неудобно.
acmnu
11.02.2019 11:07Ну, на самом деле, в TC неплохая автоматизация. Точнее, скорее прототипирование на Kotlin, по типу Jenkins DSL, что были модны до Pipelines и JJB.
acmnu
11.02.2019 11:11Я пробовал внедрить BuildBot и столкнулся главным образ с то же проблемой, что и Pipelines — заточенность на один юз кейс: есть репа, с кодом — его нужно собрать. Мне бы хотелось видеть более универсальную платформу, которая занимается не только сборкой, но доставкой, отслеживаением артефактов и т.д. Строить такую вещь на BuildBot, как и на чистом Jenkins неудобно.
sshikov
12.02.2019 12:51У меня было похожее. Только немного другие кейсы — есть скажем JIRA, там есть баги и задачи, нужно создавать потоки сборки того, что попадет в релиз. Тоже было очень неудобно.
Extravert34
12.02.2019 02:11Инструмент появился не вчера, с его помощью собирается сам питон, Wireshark, LLVM и множество других известных проектов
К сожалению, большинство крупных проектов до сих пор сидят на старой версии 0.8. И уходить похоже не собираются
sshikov
>но у своих Java конкурентов
Но при этом ни Jenkins, ни Teamcity даже не упомянуты. Что у них выигрывает по потреблению памяти — вполне верю (хотя много лет уже не сталкивался с тем, чтобы CI не хватало памяти), а вот по функциональности — как-то сомнительно.
Можно писать пайплайны на питоне? Ну это не факт что преимущество по сравнению с возможностью писать их же на груви. Оба — универсальные широко известные языки общего назначения, и те примеры, что вы показываете, они вполне соответствуют по сложности тому, что я вижу каждый день на Jenkins.
То что можно выбрать инструмент, который программируется на любимом языке — это скорее всего хорошо, но для объективности более детально сравнить с Jenkins наверное не помешало бы.
PodnimatelPingvinov Автор
Я и не говорю что по функциональности выигрывает. Надо очень сильно постараться (если вообще возможно), найти то, что можно сделать в Jenkins'e, но нельзя в билдботе и наоборот. Сравнение таких мощных инструментов — весьма дискуссионная штука. Тут скорее на первый план выходят какие-то личные предпочтения, от языка до внешнего вида веб-интерфейса. Иногда тот или иной инструмент используется по историческим причинам. Я не был обременен легаси, а потому выбрал билдбот вместо дженкинса по 2 причинам: мне больше нравится питон и была важна ресурсозатратность. Если разработка основного проекта идет на джаве и есть мощный сервак, то разработчику скорее всего примешивать туда питон будет ни к чему и он выберет дженкинс.
sshikov
Да это в общем была и не претензия, просто вы как-то забыли про пару самых известных пожалуй инструментов, что было странно.
acmnu
Если бы там был чистый груви, то вопросов не было бы, а так, это язык на базе груви запускаемый в песочнице, под которую нет sdk. Вопросы отладки не проработаны.
Да и груви, по сути популярен только среди Java тусовки и найти девопса на рынке, которые это знает и любит тяжко. Мой опыт собеседований говорит, что процентов 80 народа используют Jenkins как cron, запускающий скрипты на Python или Ansible. Pipelines знают единицы.
sshikov
Я и сказал, что это относительное преимущество. У вас много пишущих на питоне — вам это хорошо. У нас как раз Java тусовка — и нам груви более чем хорош.
P.S. Pipelines тривиальны. Просто примените внушение, и пусть не отлынивают от работы ;)
Про песочницу с отладку — согласен. Особенно доставляет, когда админы решат по каким-то своим соображениям безопасности запретить часть методов.
acmnu
Да? А вы пробовали использовать shared_lib? Особенно не выключая безопасность. Если да, то напишите статью об этом. Лично я буду премного благодарен.
sshikov
> А вы пробовали использовать shared_lib? Особенно не выключая безопасность.
Пробовал. Нам безопасность никто и не дает отключать, она включена, причем в режиме параноика (на мой взгляд) — допустим, пайплайн не может сканировать файловую систему, независимо от того, в какой мы папке — внутри workspace, или где-то еще. При этом скажем maven build вполне может это делать.
Суть моего заявления в том, что они тривиальны для освоения. А что они во всем удобны — я не говорил. shared_lib тоже самое.
acmnu
Я имел ввиду, что я не знаю варианта нормально разрабатывать что-то под shared lib, поскольку не sdk, не эмулятора не наблюдается — приходится деплоить изменение в Jenkins на каждый чих, что мягко говоря не тривиально.
sshikov
Так я согласен. Речь о том, что сами по себе shared lib — довольно простая штука. Но писать их — не слишком удобно, и не только потому, что их отладить автономно нельзя, но и потому скажем, что одна библиотека — один репозиторий. А почему собственно так? У меня вот репозитории заводят админы — и что, я сижу в рамках одной shared lib?
SirEdvin
Последний раз, когда я пользовался jenkins, у них не работал цикл forEach в груви. Было очень классно, конечно, но суррогатные языки — это путь в никуда
sshikov
Он назвал тебя желтым земляным червяком! :)
У всех работал, а у вас почему-то не работал. groovy на сегодня 15 лет от роду, в то что там баги бывают — так это наверняка, что баги в дженкинсе бывают — тоже без сомнения. Но при этом и тот и другой настолько распространены, что в длительное существование бага «не работает forEach» я поверить не могу.
SirEdvin
Как насчет где-то двух лет? Пруф и там есть ссылка на issues.
Проблему уже описали выше — groovy в дженкинсе это не groovy, это квазиязык, который похож на groovy.
sshikov
Не, тут вы ошибаетесь. Это обычный груви, просто ограниченный в правах. Язык pipeline — это DSL на базе груви, то что вы пишете внутри — это тело closures, ничего более. И это кстати хорошо видно в стеках, которые приводятся по вашим ссылкам. Ровно также работают всякие билдеры (MarkupBuilder к примеру).
Да, там все сложнее, чем в простом груви. Но на самом деле, такого рода DSL на питоне вы вообще не сделаете скорее всего.