- версии систем и приложений, которые теперь поддерживает решение
- работу с облачными инфраструктурами
- улучшения в резервном копировании
- улучшения в восстановлении
- новое в поддержке vSphere и Hyper-V
А также узнаем об улучшениях в работе с виртуальными машинами под управлением Linux, о новых плагинах и других фичах.

Итак, добро пожаловать под кат.
Поддержка Windows Server 2019, Hyper-V 2019, новейших приложений и платформ
Microsoft Windows Server 2019 поддерживается в качестве:
- гостевой ОС для защищаемых виртуальных машин
- сервера для установки Veeam Backup & Replication и его удаленных компонентов
- машины, которую можно бэкапить с помощью Veeam Agent for Microsoft Windows
Аналогичная поддержка реализована и для Microsoft Windows 10 October 2018 Update.
Поддержана новая версия гипервизора Microsoft Windows Server Hyper-V 2019, включая поддержку ВМ с virtual hardware версии 9.0.
Для популярных систем и приложений Microsoft Active Directory 2019, Exchange 2019 и SharePoint 2019 поддерживается бэкап с учетом работы приложений (application-aware processing) и восстановление объектов приложений с помощью инструментов Veeam Explorer.
Для ВМ с гостевой ОС Windows реализована поддержка Oracle Database 18c — также с учетом работы приложения, включая бэкап журналов и возможность восстановления на выбранную точку.
Кроме того, теперь поддерживаются VMware vSphere 6.7 U1 ESXi, vCenter Server и vCenter Server Appliance (VCSA), а также VMware vCloud Director 9.5.
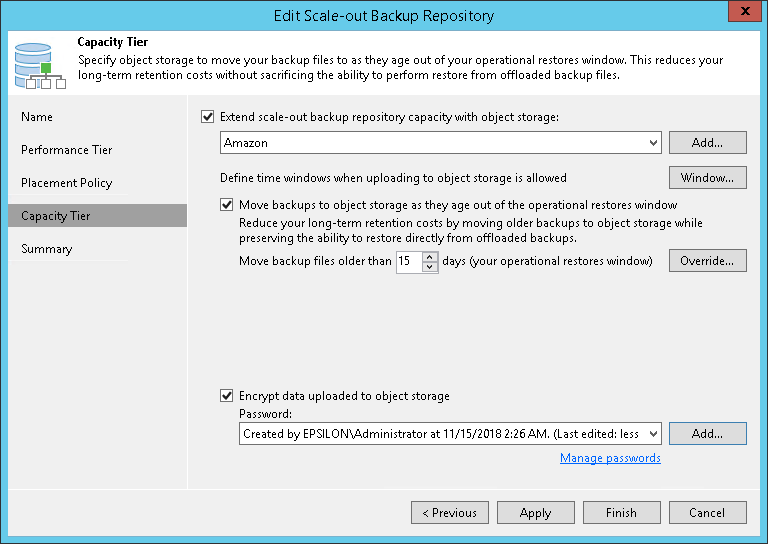
Гибкие возможности для хранения резервных копий с помощью Capacity Tier
Capacity Tier — это новый подход к хранению резервных копий в масштабируемом репозитории (scale-out backup repository, SOBR) с возможностью автоматизированной загрузки данных в облачное хранилище.
С помощью Capacity Tier и политик хранения можно организовать эффективную многоуровневую систему хранения, при которой “на расстоянии вытянутой руки” (то есть в достаточно оперативном хранилище) будут лежать свеженькие бэкапы на случай оперативного восстановления. По истечении установленного срока они перейдут в разряд “второй свежести” и автоматически уедут на удаленную площадку — в данном случае в облако.
Для работы Capacity Tier требуются:
- один или несколько SOBR-репозиториев, содержащих 1 или более репозиториев-extent-ов
- один облачный репозиторий (т.н. хранилище объектов — object storage repository)
Поддерживаются облачные S3 Compatible, Amazon S3, Microsoft Azure Blob Storage, IBM Cloud Object Storage.
Если если вы планируете использовать эту функциональность, вам нужно будет:
- Настроить репозитории резервных копий для использования в качестве extent-ов SOBR-репозитория.
- Настроить облачный репозиторий.
- Настроить масштабируемый SOBR-репозиторий и добавить в него репозитории-extent-ы.
- Настроить привязку облачного репозитория к SOBR и задать политику хранения данных и загрузки их в облако — это и будет конфигурация вашего Capacity Tier.
- Создать задание резервного копирования, которое будет сохранять бэкапы в SOBR-репозиторий.
С пунктом 1 все довольно очевидно (для тех, кто подзабыл, есть документация на русском языке). Переходим к пункту 2.
Облачное хранилище как элемент инфраструктуры Veeam Backup
Про настройку облачного репозитория (aka хранилища объектов) подробно написано здесь (пока что на английском). Если коротко, то нужно сделать следующее:
- В представлении Backup Infrastructure выбираем в панели слева узел Backup Repositories и в верхнем меню кликаем на пункт Add Repository.
- Выбираем, какое облачное хранилище будем настраивать:
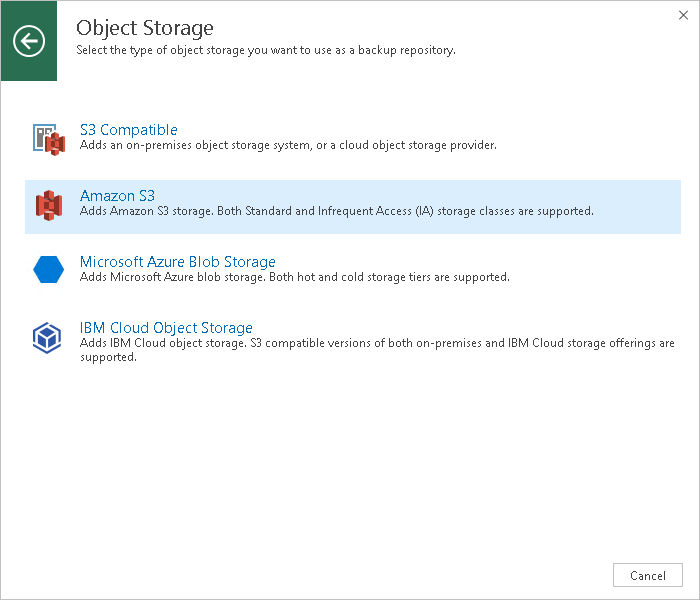
- Далее проходим по шагам мастера (для примера я рассмотрю Amazon S3)
Примечание: Поддерживаются хранилища класса Standard и Infrequent Access.
- Сначала вводим имя и краткое описание нашего нового хранилища.
- Затем указываем учетную запись для доступа к Amazon S3 — выбираем существующую из списка либо кликаем Add и вводим новую. Из списка регионов размещения дата-центров Data center region выбираем нужный регион.
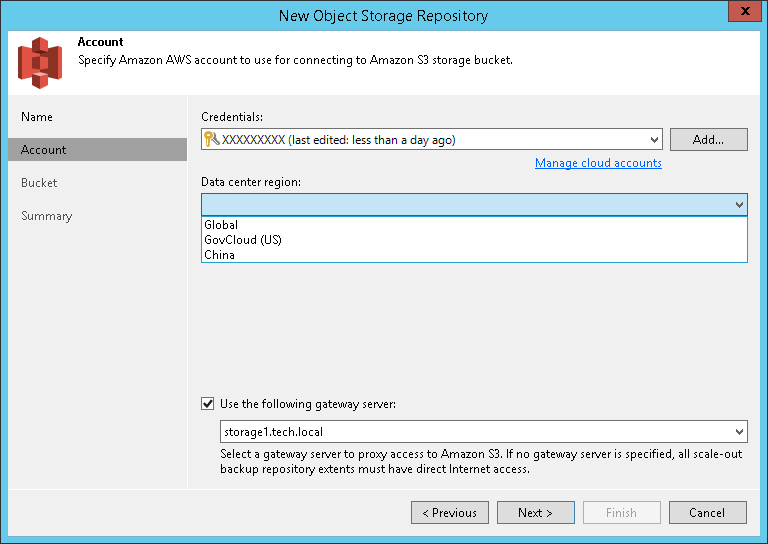
Подсказка: Для указания учетных записей, используемых при работе с облачными компонентами, разработан Cloud Credentials Manager.
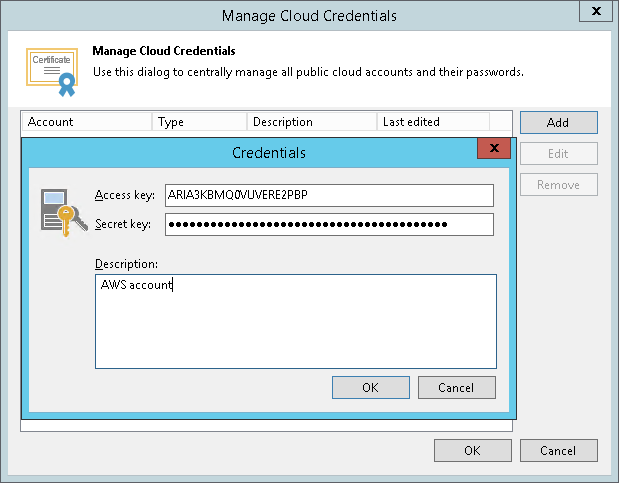
- При необходимости регулирования интернет-трафика через шлюз (gateway) можно выбрать опцию Use gateway server и указать нужный шлюз.
- Указываем настройки нового хранилища: нужный bucket, папку, куда будут складываться наши бэкапы, ограничение на общий объем места (опционально) и класс хранения (опционально).
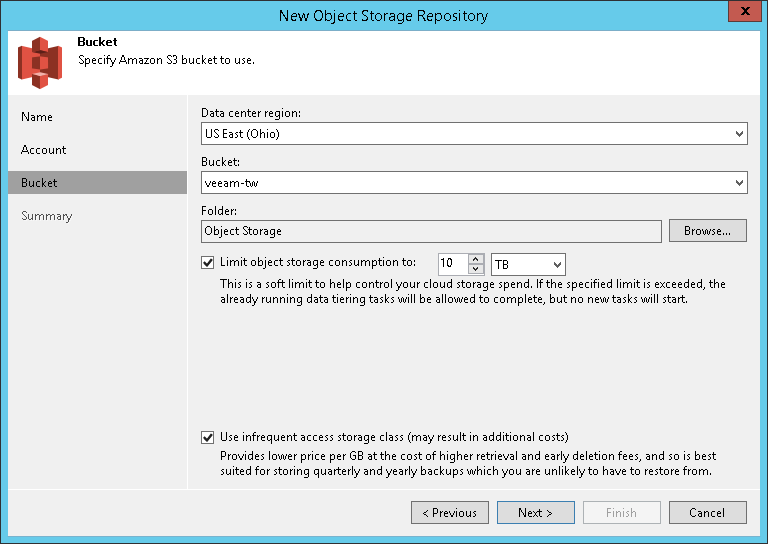
Важно! Одной папке можно поставить в соответствие только одно хранилище объектов! Ни в коем случае нельзя конфигурировать несколько таких хранилищ, “смотрящих” на одну и ту же папку. - На заключительном шаге проверяем все настройки и жмем Finish.
Настройка загрузки бэкапов в облачное хранилище
Теперь настраиваем SOBR-репозиторий соответствующим образом:
- В представлении Backup Infrastructure выбираем в панели слева узел Backup Repositories и в верхнем меню кликаем на пункт Add Scale-out Repository.
- На шаге мастера Performance Tier указываем для него extent-ы и говорим, как складывать бэкапы в них:
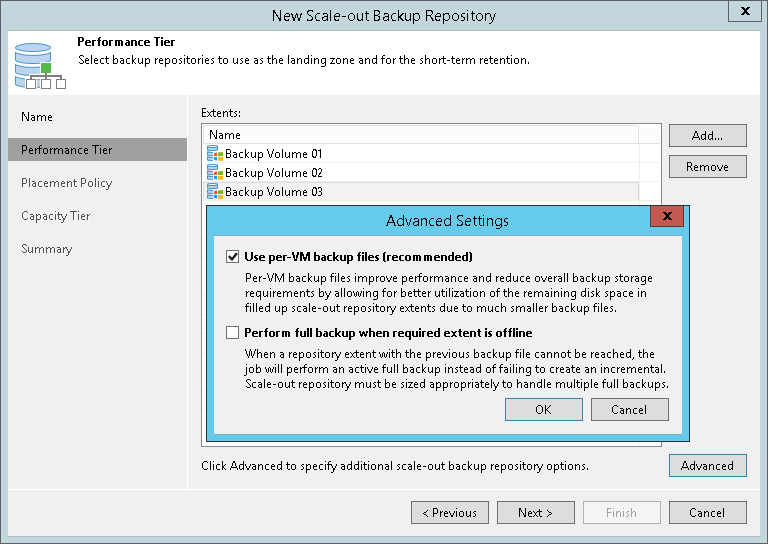
- На шаге Capacity Tier:
- выбираем опицию Extend scale-out backup repository capacity with object storage (расширить емкость репозитория, задействовав хранилище объектов) и указываем, какое именно облачное хранилище объектов задействовать. Можно выбрать из списка или запустить мастер создания, нажав Add.
- говорим, в какие дни-часы можно выполнять загрузку в облако — для этого нажимаем кнопку Window (окно загрузки).
- настраиваем политику хранения — указываем, через сколько дней хранения в SOBR-репозитории данные станут “второй свежести”, и их можно будет перенести в облако — в нашем примере это 15 дней.
- можно включить шифрование данных при загрузке в облако — для этого выберите опцию Encrypt data uploaded to object storage и укажите, какой из паролей, хранящихся в Credentials Manager, надо использовать. Шифрование выполняется с использованием AES 256-bit.
По умолчанию, данные собираются с extent-ов и переносятся в хранилище объектов с помощью особого типа задания - SOBR Offload job. Оно работает в фоновом режиме, именуется по названию SOBR-репозитория с суффиксом Offload (например, Amazon Offload) и каждые 4 часа выполняет следующие операции:
- Проверяет, соответствуют ли цепочки бэкапов, хранящиеся в extent-ах, критериям переноса в хранилище объектов.
- Собирает прошедшие проверку цепочки и отправляет их по-блочно в хранилище объектов.
- Записывает результаты работы своей сессии в базу, чтобы администратор смог просмотреть их при необходимости.
Схема переноса данных и структуры хранения их в облаке показана на рисунке ниже:

Важно! Для создания такой многоуровневой системы хранения вам потребуется лицензия на редакцию не ниже Enterprise.
Бэкапы, сохраненные в облако, разумеется, можно использовать для восстановления непосредственно из места хранения. Причем можно также и сгрузить их из облака на землю и восстановить с помощью даже бесплатного Veeam Backup Community Edition.
Новое в работе с облачным инфраструктурами
Для работы с Amazon
- Восстановление из бэкапов напрямую в AWS — поддерживается для ВМ с гостевой ОС Windows или Linux, также для физических машин. Все это можно восстанавливать в виртуальные машины в AWS EC2 VM, включая Amazon Government Cloud и Amazon China.
- Работает встроенное преобразование UEFI2BIOS.
Для работы с Microsoft Azure
- Реализована поддержка Azure Government Cloud и подписок Azure CSP.
- Есть возможность выбрать группу network security group при восстановлении в ВМ Azure IaaS.
- При входе в облако с использованием учетной записи Azure теперь можно указывать пользователя Azure Active Directory.
Новое в поддержке работы приложений
- Для работы приложений на виртуальных машинах vSphere реализована поддержка Kerberos-аутентификации. Это позволит отключать NTLM в сетевых настройках гостевой ОС для предотвращения атак, использующих передачу хэша, что весьма актуально для инфраструктур с не самым высоким уровнем контроля.
- Модуль резервного копирования журналов транзакций SQL и Oracle теперь использует в качестве вспомогательного местоположения при бэкапе журналов не системный диск С, где частенько не хватает места, а том с максимальным свободным пространством. На Linux-ВМ будет использоваться директория /var/tmp или /tmp, также в зависимости от свободного места.
- При бэкапе журналов Oracle redo logs будет выполняться их анализ с тем, чтобы сохранить гарантированные точки восстановления Guaranteed Restore Points (являются частью встроенной фичи Oracle Flashback).
- Добавлена поддержка Oracle Data Guard.
Улучшенное резервное копирование
- Максимальный поддерживаемый размер диска и файла резервной копии увеличился более чем в 10 раз: при размере блока в 1 МБ для файла .VBK максимальный размер диска в бэкапе теперь может составить 120 ТБ, а максимальный размер всего файла резервной копии — 1 ПБ. (Подтверждено тестированием 100 ТБ для обоих значений.)
- Для бэкапов без шифрования объем метаданных снижен на 10 МБ.
- Оптимизирована производительность процессов инициализации и завершения задания резервного копирования; как результат, бэкапы небольших ВМ будут идти почти вдвое быстрее.
- Переработан модуль, ответственный за публикацию контента образа ВМ, что дало значительное ускорение восстановления на уровне файлов и на уровне объектов.
- Настройки Preferred Networks (предпочтительные сети) теперь будут распространяться и на акселераторы WAN.
Новое в восстановлении
Новая возможность восстановления ВМ целиком называется Staged Restore — поэтапное восстановление. В этом режиме ВМ восстанавливается из нужного бэкапа сначала в «песочнице» (которая теперь носит название DataLab), на гостевой ОС при этом можно запустить свой скрипт для внесения изменений в содержимое базы данных, настройки ОС или приложений. ВМ с уже выполненными изменениями затем можно перенести в производственную инфраструктуру. Это может пригодиться, например, чтобы загодя установить нужные приложения, включить или отключить настройки, удалить персональные данные, и пр.
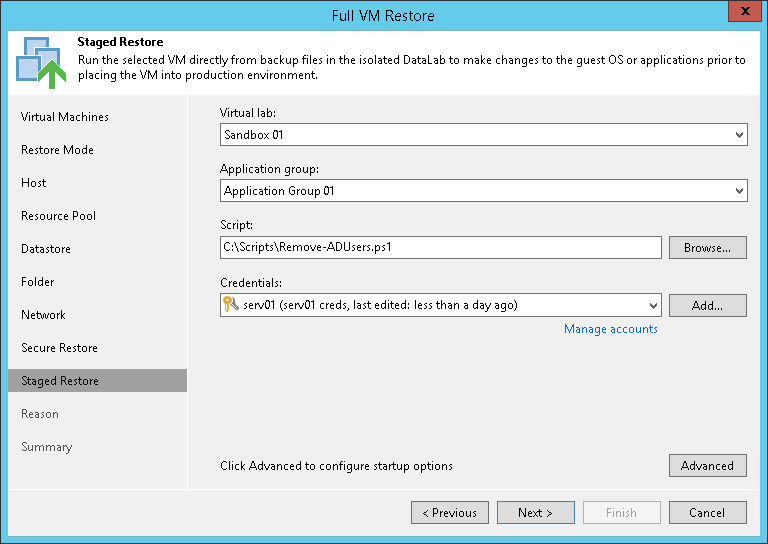
Подробнее можно почитать тут (на англ.языке).
Примечание: Требуется лицензия не ниже Enterprise.
Также появилась возможность Secure Restore — безопасное восстановление (работает почти для всех разновидностей восстановления). Теперь можно до начала процесса восстановления проверить файлы гостевой системы ВМ (непосредственно в резервной копии) на предмет наличия вирусов, троянов и т.п. — для этого диски ВМ монтируются к mount-серверу, ассоциированному с репозиторием, и запускается процедура сканирования с помощью антивируса, установленного на этом mount-сервере. (При этом необязательно, чтобы на mount-сервере и на самой ВМ был один и тот же антивирус.)
«Из коробки» поддерживаются Microsoft Windows Defender, Symantec Protection Engine и ESET NOD32; можно указать и другой антивирус, если он поддерживает работу через командную строку.
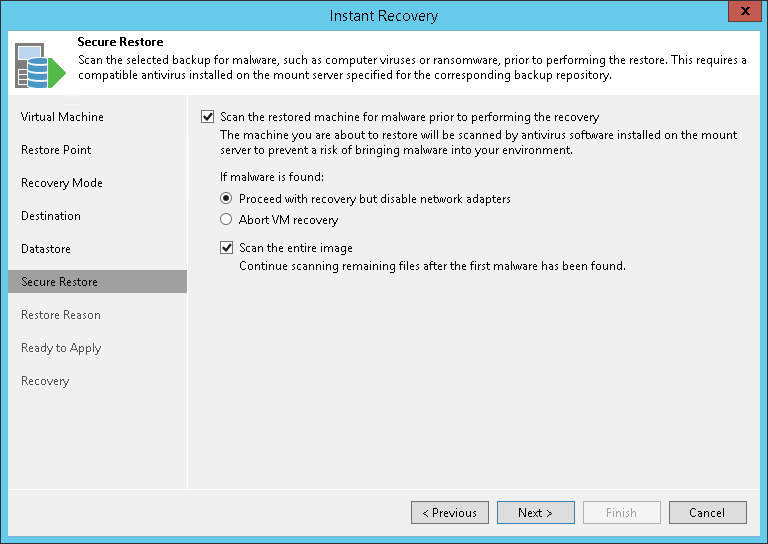
Подробнее можно почитать тут (на англ. языке).
Новое в работе с Microsoft Hyper-V
- В задания бэкапа и репликации теперь можно добавлять группы Hyper-V ВМ.
- Мгновенное восстановление в Hyper-V ВМ из бэкапов, созданных с использованием Veeam Agent, поддерживает Windows 10 Hyper-V в качестве целевого гипервизора.
Новое в работе с VMware vSphere
- Улучшенная в несколько раз производительность кэша записи у vPower NFS — для более эффективного мгновенного восстановления ВМ и оптимизации использования SSD.
- vPower NFS теперь более эффективно работает с репозиторием SOBR, что позволяет обрабатывать больше виртуальных машин параллельно.
- У сервера vPower NFS появилась опция авторизации хостов по IP-адресу (по умолчанию доступ предоставляется хосту ESXi, обеспечивающему vPower NFS datastore). Для отключения этой фичи в реестре mount-сервера нужно перейти к HKEY_LOCAL_MACHINE\
SOFTWARE\WOW6432Node\Veeam\Veeam NFS\ и создать под ним ключ vPowerNFSDisableIPAuth - Теперь можно настроить задание SureBackup на использование кэша vPower NFS (в дополние к перенаправлению записи изменений на vSphere datastore). Это решает вопрос с использованием SureBackup для ВМ с дисками более 2 ТБ в случаях, когда единственной СХД для vSphere является VMware VSAN.
- Реализована поддержка контроллеров Paravirtual SCSI controllers с более чем 16ю приаттаченными дисками.
- Quick Migration теперь автоматически переносит и тэги vSphere; эти тэги сохраняются и при мгновенном восстановлении ВМ.
Улучшения в поддержке Linux ВМ
- Для учетных записей, которые нужно поднять до root, теперь нет необходимости добавлять опцию NOPASSWD:ALL для sudoers.
- Добавлена поддержка включенной опции !requiretty в sudoers (это дефолтная настройка, например, для CentOS).
- При регистрации сервера Linux теперь можно выполнять переключение командой
su, если командаsudoнедоступна. - Проверка SSH-отпечатка (fingerprint) теперь распространяется на все подключения сервера Linux — для защиты от атак типа MITM.
- Повышена надежность алгоритма аутентификации PKI.
Новые плагины
Veeam Plug-in for SAP HANA — помогает задействовать интерфейс BACKINT для бэкапа и восстановления баз данных HANA в/из репозитория Veeam. Реализована поддержка HCI SAP HANA. Решение сертифицировано SAP.
Veeam Plug-in for Oracle RMAN — позволяет использовать RMAN manager для бэкапа и восстановления баз данных Oracle в/из репозитория Veeam. (При этом нет необходимости заменять имеющуюся встроенную интеграцию на основе OCI.)
Дополнительные возможности
- Экспериментальная поддержка клонирования блоков для дедуплицированных файлов на Windows Server 2019 ReFS. Для активации этой фичи в реестре сервера Veeam backup нужно найти ключ HKEY_LOCAL_MACHINE\SOFTWARE\Veeam\Veeam Backup and Replication и создать значение ReFSDedupeBlockClone (DWORD).
- В состав сетапа теперь входит Microsoft SQL Server 2016 SP1.
- Для работы с RESTful API реализована поддержка JSON.
Что еще почитать и посмотреть
Обзор решения (на русском языке)
Сравнение редакций (на русском языке)
Руководство пользователя (на англ.языке) для VMware и Hyper-V
Комментарии (25)

CodeImp
12.02.2019 16:36+1Конечно согласен, что изменений между версиями 7.5 и 7.6 было мало. Более того, модуль, собранный под 7.5 оказался совместим с 7.6. Кажется, что проблем нет.
Однако хочу напомнить, может кто не в курсе, у нас была колоссальная проблема при релизе 7.5, когда модуль, собранный для ядра 7.0 был kABI совместим с обновлённым, успешно загружался и гарантированно ронял серваки. Обычно пользователи не любят, когда их серваки падают.
В результате, было принято решение не пытаться работать на ядрах будущих релизов EL7, которые не прошли через наш QA.
Кроме того, шли работы по подготовке к релизу VBR 9.5, VAL 3.0 и VAW 3.0. Выделить ресурсы на hot fix для поддержки rhel 7.6 — а это несколько дней регресса — было сложно.
Да, согласен, что возможно мы недостаточно уделили внимание релизу 7.6. Выводы из этой ситуации мы сделали.
Но для нас всё же приоритетом является надёжность работы серверов наших пользователей.
DaemonGloom
13.02.2019 06:56В такой ситуации, если точно известно, что на новых ядрах модуль работать не должен, правильнее указать в зависимостях модуля максимальную версию ядра, равную текущей. Тогда при обновлении человек будет видеть, что у него есть проблема с зависимостями и будет ожидать, что могут быть проблемы с бэкапом, либо с версией ядра. Это уже частично решило бы проблему для клиентов, обновляющих систему своевременно.
CodeImp
13.02.2019 13:41+1Наверное да. Я подумаю об этом.
Тем не менее, недавний случай с ошибкой в ядре, которая прилетела с патчем в 2.6.32-754.6.3 (была починена в следующем) напоминает о том, что с обновлениями надо быть осторожным.
Как минимум не стоит делать обновления автоматически и для всей инфраструктуры сразу.
Ещё хочу заметить, что идея kABI совместимых модулей не очень соответствует идеям ядра Linux.
Dkms модуль ядра практически не вызывает проблем. Конечно он может не собраться из-за специфичного патча или из-за очередного обновления ядра. Но серваки пачками не кладёт. Если есть возможность использовать dkms модуль, я бы советовал использовать именно его.
strelec7
13.02.2019 13:45Скажите, почему у вас есть коммандлет Set-VBRJobAdvancedBackupOptions, но нету соттветствующего Get-* — иногда приходится перепроверять настройки десятков заданий и это геморно.
Настройки задания РК — Storage — Advanced — Integration — Limit processed per storage snapsho to == какая польза от этой фичи? Мне, например, интереснее такая схема — в задании на закладке Virtual Mashines выбраны датасторы (LUN-ы) с ВМ (к примеру на каждом датасторе по 15 ВМ), тот самый лимит, например 10, берет 10 ВМ с первого датастора, делает им снапшот (потом снапшот луна...) и бэкапит их, далее берет следующие 10 ВМ (5 с первого датастора и 5 со второго) и так далее. А сейчас у вас получается, что делается снапшет 10 ВМ на каждом датасторе (шторм снапшотов по всем лунам задания), а уже следующим этапом пяти ВМ. В общем, интересно чтобы ВМ бэкапились по очереди, как без storage snapshots.

Loxmatiymamont
13.02.2019 17:42Польза от этой фичи ровна такая, как вы и описали (если я правильно понял посыл): ограничивать количество машин с варными снепшотами перед созданием storage snapshot. Меньше нагрузка, быстрее создаётся снепшот, быстрее бекап.
Но тут главная часть заключена в per storage snapshot т.е. это не отмена параллельной обработки.
Если стоит задача бекапить поочереди с разных датастор, то лучшее решение это разнести их по джобам. В каждую джобу добавить датастору, а не отдельные машины и включить последовательный запуск джоб (на шаге Scheduler выбрать After this job).
Про командлет постараюсь узнать.
strelec7
14.02.2019 14:32вот вы говорите, что нету запросов про командлет get, но кто в таком исполнении использует «Limit processed per storage snapsho to»? приходится делать делать задания на каждый лун отдельно и шедулить After this job (хотя вы же сами не рекомендуете так шедулить).
Loxmatiymamont
14.02.2019 14:45А если я скажу, что вы первый, кто обратился с запросом такого сценария?
Фичи появляются не по нашей прихоти, а исходя из запросов клиентов. Было много запросов на такое исполнение — мы сделали, будут запросы схожие с вашим — тоже сделаем.
Loxmatiymamont
13.02.2019 19:25Про Get.
Его не делали из-за отсутствия запросов на него. Звучит странно, но большинство работает с опциями напрямую, без сторонних кмдлетов.$Job.Options.etc.
Получить такие настройки для всех джоб достаточно легко:$Job.Options.BackupTargetOptions.
wizzard76
13.02.2019 15:30-1Однако маленькое уточнение теперь в новой версии о ESX(i)4.1 можно забыть:
VMware infrastructure
Platforms
vSphere 6.x
vSphere 5.x
Hosts
ESXi 6.x
ESXi 5.xLoxmatiymamont
13.02.2019 18:24Если не ошибаюсь, то сама VMware отказалась от её поддержки в 2014. Когда-то стюардессу всё же надо закопать насовсем.
DickCancer
А под Linux то планируется что нибудь, более серьёзное чем сегодняшний «агент»?
Loxmatiymamont
Например что? Агент проект живой и туда постоянно добавляются новые фичи.
gotch
Например, поддержка хостов KVM/oVirt/RHEV?
Loxmatiymamont
Отличное предложение (без шуток), но полноценная поддержка любой системы виртуализации проект по своим масштабам на порядок больший, чем скромный агент бекапящий ОС.
Как вы понимаете, разработчики не могут просто так взять и начать пилить фичи которые им кажутся интереснее. Есть план разработки построенный аналитиками, в том числе, и на основе количества запросов от пользователей на реализацию той или иной фукнции. Если буквально завтра все начнут просить поддержку KVM, вероятно будет странно не добавить её в ближайшем релизе. С другой стороны, если какой-то функции всё нет и нет, вероятно и запросов на неё практически нет. Такая вот правда рынка…
gotch
Вот это-то мы как раз очень хорошо понимаем, потому что «просто так» Veeam ничего не делает.
Хотя нет, можно просто так поднять цены на продление техподдержки, это факт. Можно вместо продукта продавать «подписку». Можно сделать уровень техподдержки по минимальному из всех приобретенных продуктов, чтобы никому в голову не приходило использовать Standard, там, где достаточно Standard.
Поэтому понимание, что разработку мы, разумеется, оплатим — есть. Такова правда рынка.
Loxmatiymamont
Всё верно, вот только к разработчикам это не имеет никакого отношения. Наше дело код писать, а продают его отдельные, специально обученные люди. И, вероятно, неплохо это делают, раз компании уже 12 лет.
gotch
Делают неплохо и разработчики, и продажники. Но совершенно честно скажу, что три основных момента, упомянутых выше, просто заставляют искать альтернативы, насколько бы не были талантливы разработчики.
Но мне, как клиенту, издалека видится что ниша-то свободна. Волна «импортозамещения», которое по факту в лучшем случае заканчивается переходом на СПО, и пустующая ниша гипервизорного KVM бекапа.
В то же время мне понятно, что с одной стороны рынок России маленький, а с другой стороны, что новый гипервизор, это возможно абсолютно новый продукт с соответствующими издержками.
Loxmatiymamont
А если предположить, что эта ниша настолько мала, что распыляться на неё нет никакого смысла от слова совсем и затраты на её освоение будут в разы больше даже самых позитивных прогнозов на прибыль?
Лично мне видитися, что такие узкие ниши отличная почва для стартаперов. Конкурентов или совсем нет, или они в зачаточном состоянии, mvp можно запилить по быстренькому минимальным количеством людей с околонулевыми расходами и дальше по ситуации. Может окажется, что ваша аудитория это студенческие лабы и денег на этом рынке нет. А может выяснится, что ваша ниша испытывает взрывной рост и через месяц вы миллионер.
gotch
Предположить могу, а фактов у меня никаких нет. Если ваш маркетинг занимался, интересен результат иссследований.
Кстати, где-то я похожую историю слышал. Выдающаяся компания сконцентрировалась на продаже наиболее успешного и маржинального продукта. И даже топа себе из Пепсико переманила.
DickCancer
Функционалом он явно меньше чем вариант под Windows.
Loxmatiymamont
Как предлагаете сравнивать? Количество строчек в релиз нотах так себе вариант.
Вот, например, была добавлена поддержка BTRFS, которой на Windows нет. Функция запрашиваемая многими, а всего одна строчка в релизе. С другой стороны, на расширение функционала Windows агента приходит намного больше запросов (что не и не удивительно), а дальше чистая система приоритетов.
Агент для Linux проект молодой и требует более тщательного подхода в разработке из-за особенностей платформы. У него есть своя полноценная ветка на нашем форуме где любой желающий может написать свои предложения по развитию. Форум постоянно мониторится и написанное там учитвывается. Инфа 146% =)
DaemonGloom
Я могу тут только одну очевидную проблему назвать — поддержка свежих версий дистрибутивов откровенно хромает. Когда нельзя обновить Redhat 7.5 до 7.6 на протяжении трёх месяцев из-за veeam — это крайне неприятно. И с прошлыми апгрейдами такая же была ситуация.
Loxmatiymamont
Код модуля открыт и лежит на гите. Если сможете адаптировать быстрее, вам все скажут большое спасибо.
Если более по делу: святая обязанность создателей всех дистрибутивов линукса, это в каждом релизе изменить уйму существующих функций, отключить десяток не нужных(по их мнению), придумать пачку новых и не написать никакой документации по этому поводу. Во всяком случае так устроен мир по их версии.
Однако в реалиях настоящего мира, когда надо обеспечивать совместимость со старыми версиями с оглядкой на особенности каждого дистрибутива + не забывать добавлять новые фичи, даже просто понять что-же изменилось в новой версии дистра, занимает далеко не нулевое время. А потом вечный круг разработка-тестирование.
Так что обеспечить поддержку последний версий RHEL мы хотим не меньше вашего, однако причины…
DaemonGloom
Сможете рассказать, что критичного изменилось в ядре 4.14 из 7.6 по сравнению с 4.14 из 7.5, что потребовалось три месяца? Причём дело только в ядре, обновление прочих пакетов никак не затронуло veeam. По гиту этого не отследить — практика одного большого патча не способствует чтению изменений. Если верить документации редхата, ничего, что влияет на агент, не было. access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html-single/7.6_release_notes/index#new_features_kernel
Да, новая версия и новые функции — это хорошо. Но работающая текущая версия с минимальным обновлением для совместимости — важнее для пользователя со сломавшимся бэкапом.
Loxmatiymamont
Коллега ответил, но веткой промахнулся.