
Я вхожу в Tarantool Core Team и участвую в разработке движка базы данных, внутренних коммуникаций компонентов сервера и репликации. И сегодня расскажу, как устроена репликация.
О репликации
Репликация — это процесс создания копий данных из одного хранилища в другом. Каждая копия называется репликой. Репликация может использоваться, если нужно получить резервную копию, реализовать hot standby или горизонтально масштабировать систему. А для этого необходимо иметь возможность использовать одни и те же данные на разных узлах вычислительной сети кластера.
Классифицируем репликацию по двум основным признакам:
- Направление: master-master или master-slave. Master-slave репликация — это самый простой вариант. У вас есть один узел, на котором вы меняете данные. Эти изменения вы транслируете на остальные узлы, где они применяются. При master-master репликации изменения вносятся сразу на нескольких узлах. В этом случае каждый узел и сам изменяет свои данные, и применяет к себе изменения, сделанные на других узлах.
- Режим работы: асинхронная или синхронная. Синхронная репликация подразумевает, что данные не будут зафиксированы и пользователю не будет подтверждено выполнение репликации до тех пор, пока изменения не распространятся хотя бы по минимальному заданному количеству узлов кластера. В асинхронной репликации фиксация транзакции (её коммит) и взаимодействие с пользователем — это два независимых процесса. Для коммита данных требуется только, чтобы они попали в локальный журнал, и уже потом эти изменения каким-либо образом транслируются на другие узлы. Очевидно, что из-за этого у асинхронной репликации есть ряд побочных эффектов.
Как устроена репликация в Tarantool?
Репликация в Tarantool имеет несколько особенностей:
- Она строится из базовых кирпичиков, с помощью которых вы можете создать кластер любой топологии. Каждый такой базовый элемент конфигурации является однонаправленным, то есть у вас всегда есть master и slave. Master выполняет какие-то действия и формирует лог операций, который применяется на реплике.
- Репликация в Tarantool асинхронная. То есть система подтверждает вам коммит независимо от того, сколько реплик эту транзакцию увидели, сколько её к себе применили и получилось ли вообще это сделать.
- Ещё одно свойство репликации в Tarantool — она построчная (row-based). Tarantool ведёт внутри себя журнал операций (WAL). Операция попадает туда построчно, то есть при изменении какого-то тапла из спейса эта операция записывается в журнал как одна строка. После этого фоновый процесс считывает эту строку из журнала и отправляет её реплике. Сколько у master‘а реплик, столько у него фоновых процессов. То есть каждый процесс репликации на разные узлы кластера выполняется асинхронно от других.
- Каждый узел кластера имеет свой уникальный идентификатор, который генерируется при создании узла. Кроме того, узел имеет также идентификатор в кластере (номер члена). Это численная константа, которая присваивается реплике при подключении к кластеру, и она остаётся вместе с репликой в течение всего времени её существования в кластере.
В силу асинхронности, данные попадают на реплики с запаздыванием. То есть вы сделали какое-то изменение, система подтвердила коммит, на master'е операция уже применилась, но на репликах она применится с некоторым запаздыванием, которое определяется скоростью, с которой фоновый процесс репликации считывает операцию, отправляет её на реплику, а та применяет.
Из-за этого возникает вероятность рассинхронизации данных. Допустим, у нас есть несколько master'ов, которые изменяют взаимосвязанные между собой данные. Может получиться, что операции, которые вы используете, некоммутативны и относятся к одним и тем же данным, тогда два разных члена кластера будут иметь разные версии данных.
Если репликация в Tarantool однонаправленная master-slave, то каким же образом сделать master-master? Очень просто: создать ещё один канал репликации но в другую сторону. Надо понимать, что в Tarantool репликация master-master — это всего лишь комбинация двух независимых друг от друга потоков данных.
Используя тот же самый принцип, можем подключить и третий master, и в результате построить full mesh-сеть, в которой каждая реплика является master'ом и slave'ом для всех остальных реплик.
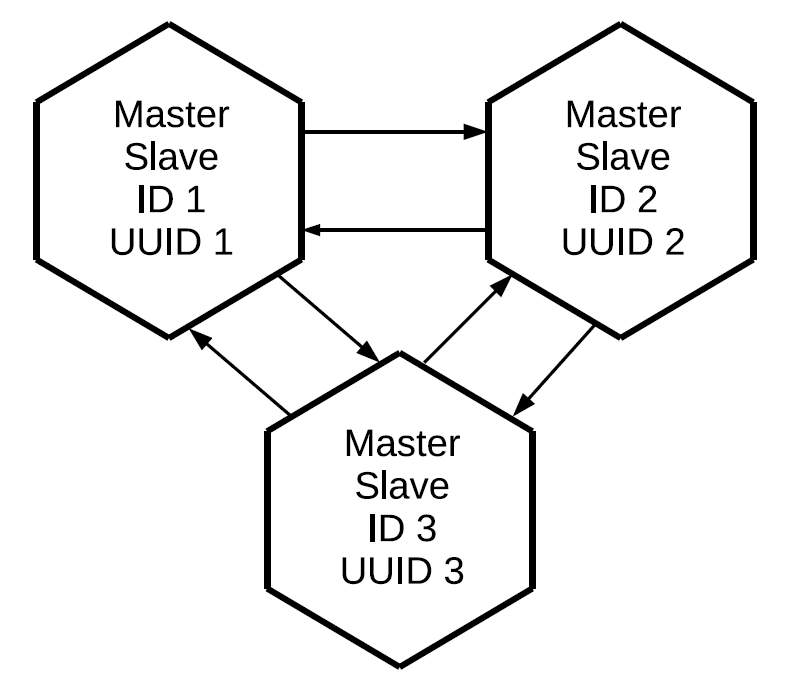
Обратите внимание, что реплицируются не только те операции, которые инициированы локально на данном master'е, но и те, которые он получил извне по репликационным протоколам. В данном случае изменения, созданные на реплике № 1, придут на реплику № 3 дважды: напрямую и через реплику № 2. Это свойство позволяет нам строить более сложные топологии, не используя full mesh. Скажем, вот такую.
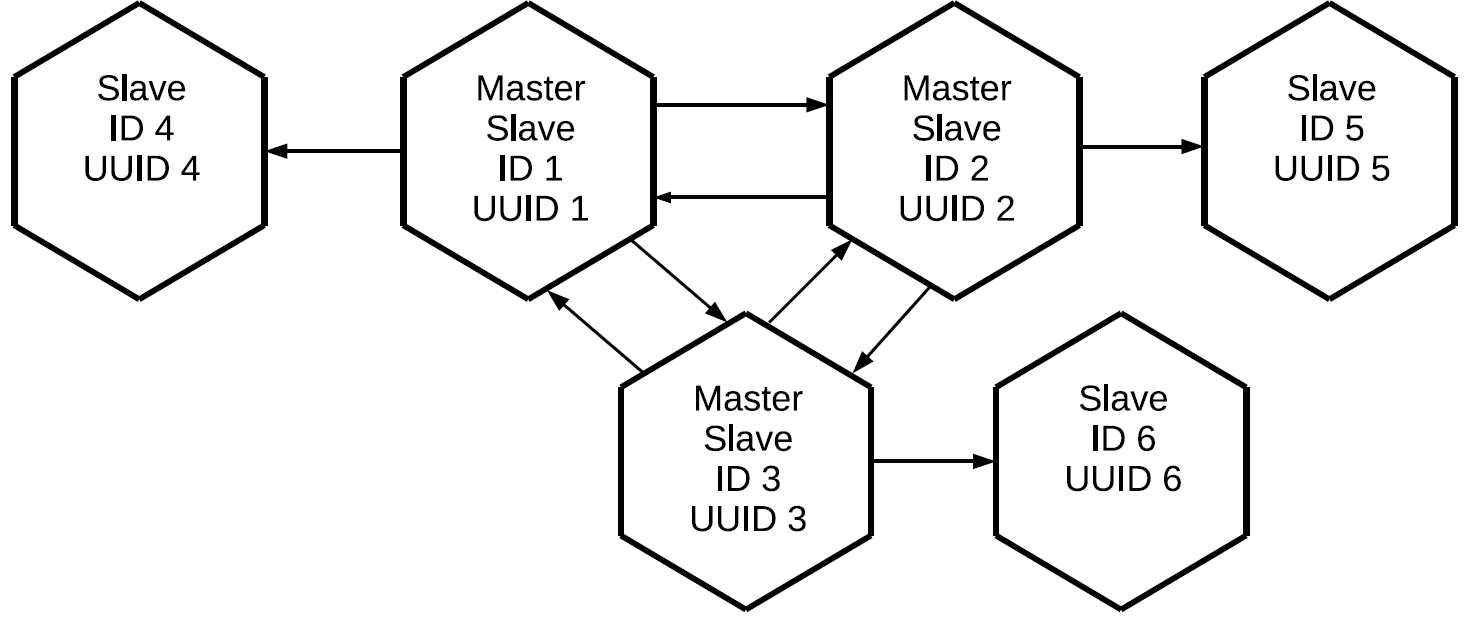
Всем master'ам, которые втроем составляют full mesh-ядро кластера, присоединили по индивидуальной реплике. Поскольку на каждом из master'ов выполняется проксирование логов, все три «чистых» slave’а будут содержать все операции, которые были выполнены на любом из узлов кластера.
Такую конфигурацию можно применять для самых разных задач. Можно не создавать избыточные связи между всеми узлами кластера, при этом если реплики размещать рядом, они будут иметь точную копию master'а с минимальным запаздыванием. И всё это делается с помощью базового элемента репликации «master-slave».
Маркировка операций в кластере
Возникает вопрос: если операции проксируются между всеми членами кластера и приходят в каждую реплику по несколько раз, как нам понять, какую операцию нужно выполнять, а какую нет? Для этого нужен механизм фильтрации. Каждой операции, считанной из лога, присваиваются два атрибута:
- Идентификатор сервера, на котором данная операция была инициирована.
- Порядковый номер операции на сервере, lsn, который является её инициатором. Каждый сервер при выполнении операции каждой полученной строке лога присваивает увеличивающийся номер: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10… Таким образом, если мы знаем, что для сервера с неким идентификатором мы применили операцию с lsn 10, то пришедшие по другим каналам репликации операции с lsn 9, 8, 7, 10 применять не надо. Вместо них применим следующие: 11, 12 и так далее.
Состояние реплики
А как Tarantool хранит информацию о тех операциях, которые он уже применил? Для этого существуют часы Vclock — это вектор последних lsn, применённых относительно каждого узла кластера.
[lsn1, lsn2, lsnn]где
lsni — номер последней известной операции с сервера с идентификатором i. Vclock можно назвать и неким известным данной реплике снимком всего состояния кластера. Зная идентификатор сервера пришедшей операции мы вычленяем нужный нам компонент локального Vclock, сравниваем полученный lsn с lsn операции и решаем, применять ли данную операцию. В результате операции, инициированные конкретным master’ом, будут отправляться и применяться последовательно. При этом потоки операций, созданные на разных master’ах, могут между собой перемешиваться в силу асинхронности репликации.
Создание кластера
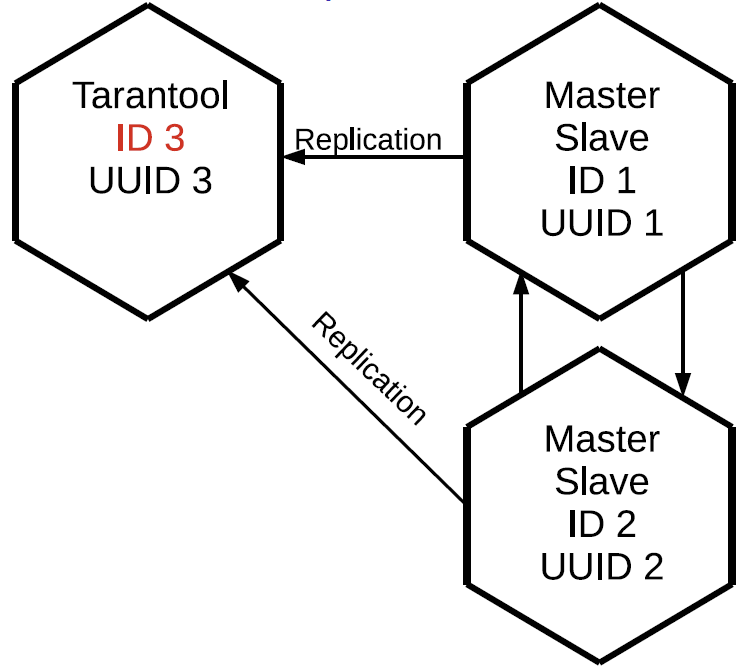
Пусть у нас есть кластер, состоящий из двух элементов master и slave, и мы хотим подключить к нему третий инстанс. У него есть уникальный идентификатор UUID, но при этом идентификатора кластера ещё нет. Если ещё не инициализированный Tarantool желает присоединиться к кластеру, он обязан послать операцию JOIN на один из master’ов, который может её выполнить, то есть находится в read-write режиме. В ответ на JOIN master отправляет подключающейся реплике свой локальный снимок. Реплика накатывает его у себя, при этом идентификатора у неё всё ещё нет. Сейчас реплика с небольшим отставанием синхронизирована с кластером. После этого master, на котором выполнялась JOIN, назначает данной реплике идентификатор, который записывается в лог и отправляется реплике. Когда реплике присваивается идентификатор, она становится полноценным узлом и после этого может инициировать репликацию логов в свою сторону.
Строки из журнала отправляются начиная с состояния этой реплики на момент запроса лога репликации от master’а — то есть с vclock, который она получила в процессе JOIN, либо с того места, где реплика остановилась ранее. Если реплика по каким-то причинам отвалилась, то при следующем подключении к кластеру она JOIN уже не выполняет, потому что у неё уже есть локальный снимок. Она просто запрашивает все операции, которые произошли за время её отсутствия в кластере.
Регистрация реплики в кластере
Для хранения состояния о структуре кластера используется специальный спейс — cluster. В нём находятся идентификаторы серверов в кластере, их порядковые номера и уникальные идентификаторы.
[1, ’c35b285c-c5b1-4bbe-83b1-b825eb594aa4’]
[2, ’37b12cb7-d324-4d75-b428-cde92c18e708’]
[3, ’b72b1aa6-42a0-4d73-a611-900e44cdd465’]Идентификаторы не обязаны идти по порядку, ведь узлы могут выбывать и добавляться.
Здесь встречается первый подводный камень. Как правило, по одному узлу кластеры не собирают: вы запускаете некое приложение и оно развёртывает сразу целый кластер. Но ведь репликация в Tarantool асинхронная. Что если два master’а одновременно подключают новые узлы и назначают им одинаковые идентификаторы? Возникнет конфликт.
Вот пример неправильного и правильного JOIN:

У нас есть два master’а и две реплики, которые желают подключиться. Они делают JOIN на разных master’ах. Предположим, что реплики получают одинаковые идентификаторы. Тогда репликация между master’ами и теми, кто успеет прореплицировать их журналы, развалится, кластер распадётся на части.
Чтобы этого не происходило, нужно в каждый момент времени инициировать реплики строго на одном master’е. Для этого в Tarantool введено такое понятие, как лидер инициализации, и реализован алгоритм выбора этого лидера. Реплика, желающая подключиться к кластеру, сначала устанавливает соединение со всеми master’ами, известными ей из переданной конфигурации. Затем реплика выбирает те, что уже инициированы (при развёртывании кластера не все узлы успевают полноценно заработать). А из них выбираются master’ы, которые доступны для записи. В Tarantool бывает read-write и read only, регистрироваться на read only-узле мы не можем. После этого из списка отфильтрованных узлов мы выбираем тот, который имеет наименьший UUID.
Если на подключающихся к кластеру не инициализированных инстансах мы используем одну конфигурацию и один список серверов, то они выберут один и тот же master, а значит JOIN пройдёт, скорее всего, успешно.
Отсюда мы выводим правило: при параллельном подключении реплик к кластеру у всех этих реплик должна быть одинаковая конфигурация репликации. Если мы где-то что-то опустим, то существует вероятность, что инстансы с отличающейся конфигурацией будут инициироваться на разных master’ах и кластер не сможет собраться.
Предположим, что мы ошиблись, или админ забыл поправить конфиг, или сломался Ansible, и кластер всё-таки развалился на части. Что об этом может свидетельствовать? Во-первых, подключаемые реплики не смогут создать свои локальные снимки: реплики не запускаются и сообщают об ошибках. Во-вторых, на master’ах в логах мы увидим ошибки, связанные с конфликтами в space cluster.
Как нам разрешить эту ситуацию? Всё просто:
- Первым делом нужно отвалидировать ту конфигурацию, которую мы задавали подключающимся репликам, потому что если мы её не исправим, то всё остальное будет бесполезно.
- После этого вычищаем конфликты в cluster и делаем снимок.
Теперь можно попытаться инициализировать реплики заново.
Разрешение конфликтов
Итак, мы создали кластер и подключили. Все узлы работают в режиме подписки, то есть получают изменения, сгенерированные разными master’ами. Поскольку репликация асинхронна, возможны конфликты. Когда вы одновременно изменяете данные на разных master’ах, разные реплики получают разные копии данных, потому что операции могут примениться в разном порядке.
Вот пример кластера после выполнения JOIN:

У нас есть три master-slave, между ними передаются логи, которые проксируются в разном направлении и применяются на slave’ах. Рассинхронизация данных означает, что на каждой реплике будет своя собственная история изменений vclock, ведь потоки от разных master’ов могут между собой перемешиваться. Но тогда и порядок применения операций на инстансах может различаться. Если наши операции не коммутативны, как, например, операция REPLACE, то данные, которые мы получим на этих репликах, будут отличаться.
Небольшой пример. Предположим, у нас есть два master’а c vclock = {0,0}. И оба выполнят по две операции, обозначенные как op1,1, op1,2, op2,1, op2,2. Так выглядит второй квант времени, когда каждый из master’ов выполнил по одной локальной операции:

Зелёным цветом обозначено изменение соответствующей компоненты vclock. Сначала оба master’а меняют свои vclock, а потом второй master выполняет ещё одну локальную операцию и снова увеличивает vclock. Первый master получает по репликации операцию со второго master’а, это обозначено красной цифрой 1 в vclock первого узла кластера.

Затем второй master получает операцию с первого, а первый — вторую операцию со второго. И в конце первый master выполняет свою последнюю операцию, а второй master её получает.

Vclock в нулевом кванте времени у нас одинаковые — {0,0}. На последнем кванте времени мы тоже имеем одинаковые vclock {2,2}, казалось бы, данные должны быть одинаковые. Но порядок выполненных на каждом master’е операций разный. А если это операция REPLACE с разными значениями для одинаковых ключей? Тогда, несмотря на одинаковые vclock в итоге, мы получим разные версии данных на обеих репликах.
Такую ситуацию мы тоже умеем разрешать.
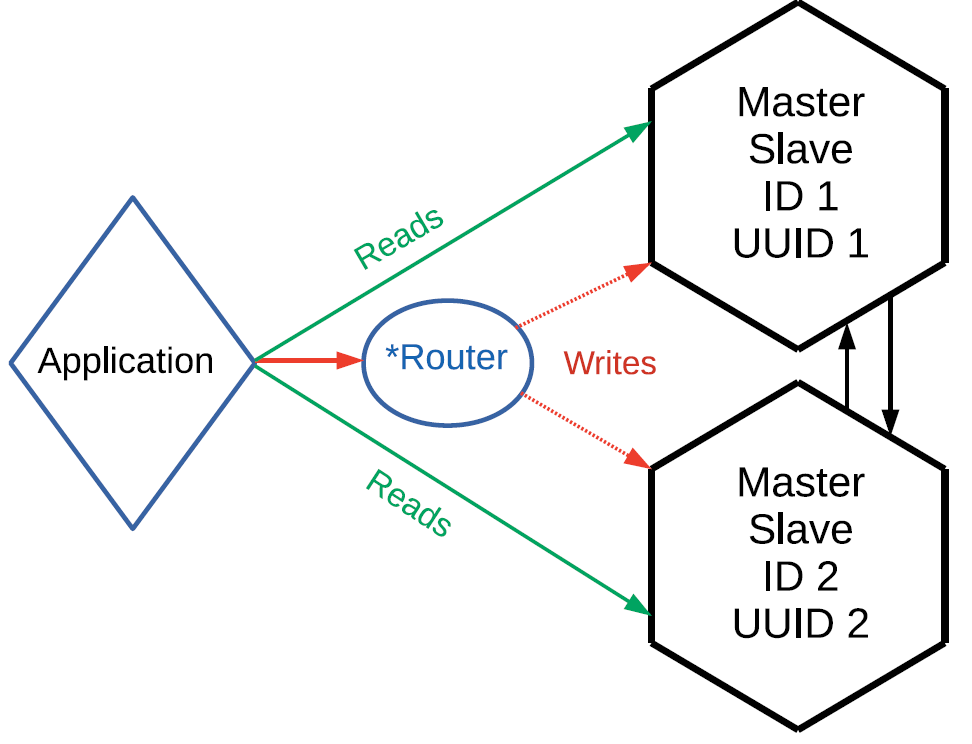
- Шардирование записи. Во-первых, мы можем выполнять операции записи не на случайным образом выбранных репликах, а каким-то образом их шардировать. Просто разнесли операции записи по разным master’ам и получить eventual consistence-систему. Например, изменились ключи от 1 до 10 на одном master’е и от 11 до 20 на другом — узлы обменяются своими логами и получат абсолютно одинаковые данные.
Шардирование подразумевает, что у нас есть некий роутер. Это вовсе необязательно должна быть отдельная сущность, роутер может быть частью приложения. Это может быть шард, который применяет к себе операции на запись или тем или иным образом передает их другому master’у. Но передаёт таким образом, чтобы изменения по связанным значениями уходили на какой-то конкретный master: один блок значения ушел одному master’у, другой блок — другому master’у. При этом операции чтения можно направлять на любой узел кластера. И не забывайте про асинхронность репликации: если записали на одном master’е, то прочитать может потребоваться тоже с него.
- Логическое упорядочивание операций. Предположим, что по условиям задачи можно каким-либо образом определить приоритет операции. Скажем, поставить timestamp, либо версию, либо иную метку, которая позволит нам понять, какая операция физически произошла раньше. То есть речь идёт о внешнем источнике упорядочивания.
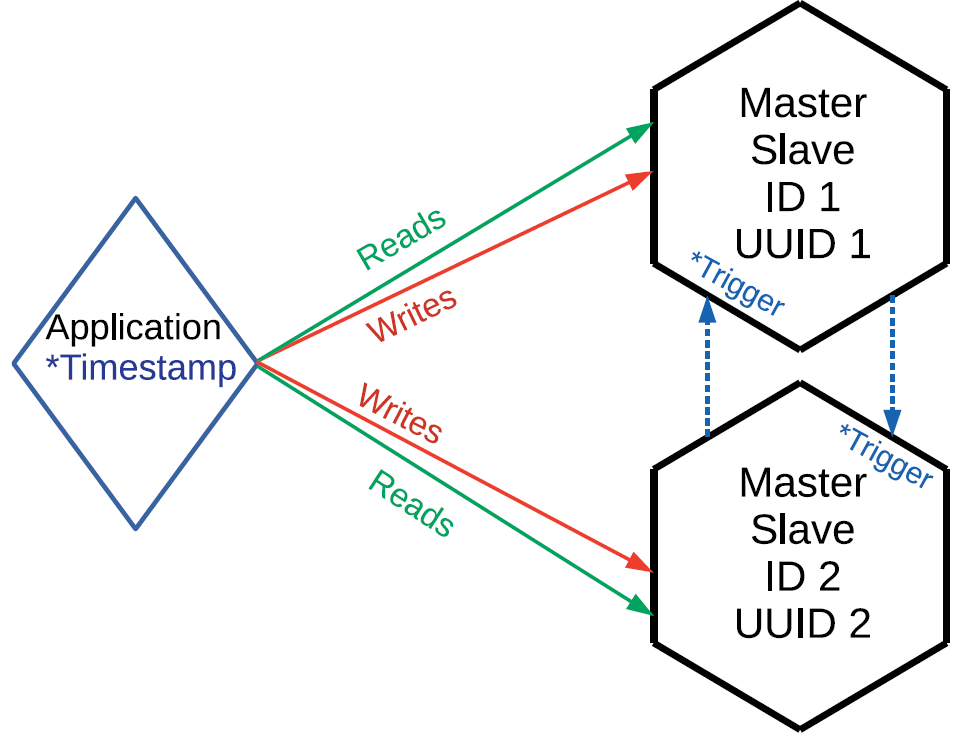
В Tarantool с есть триггерbefore_replace, который может выполняться при репликации. В данном случае мы с вами не ограничены необходимостью маршрутизировать запросы, можем слать их куда хотим. Но при выполнении репликации на входе потока данных у нас есть триггер. Он читает присланную строчку, сравнивает её с той строкой, которая уже хранится, и принимает решение, какая из строк имеет более высокий приоритет. То есть триггер либо игнорирует запрос по репликации, либо применяет его, возможно, с требуемыми модификациями. Данный подход мы уже применяем, хотя у него тоже есть свои недостатки. Во-первых, нужен внешний источник синхронизации. Допустим, оператор в салоне сотовой связи вносит изменения по какому-то абоненту. Для таких операций можно использовать время на компьютере оператора, потому что вряд ли вносить изменения по одному абоненту будут одновременно несколько операторов. Операции могли дойти разными путями, но если каждой из них можно присвоить некую версию, то при прохождении через триггеры останутся только те, которые являются актуальными.
Второй недостаток метода: поскольку триггер применяется к каждой дельте, пришедшей по репликации на каждый запрос, это создаёт лишнюю вычислительную нагрузку. Но зато у нас будет консистентная копия данных в масштабах кластера.
Синхронизация
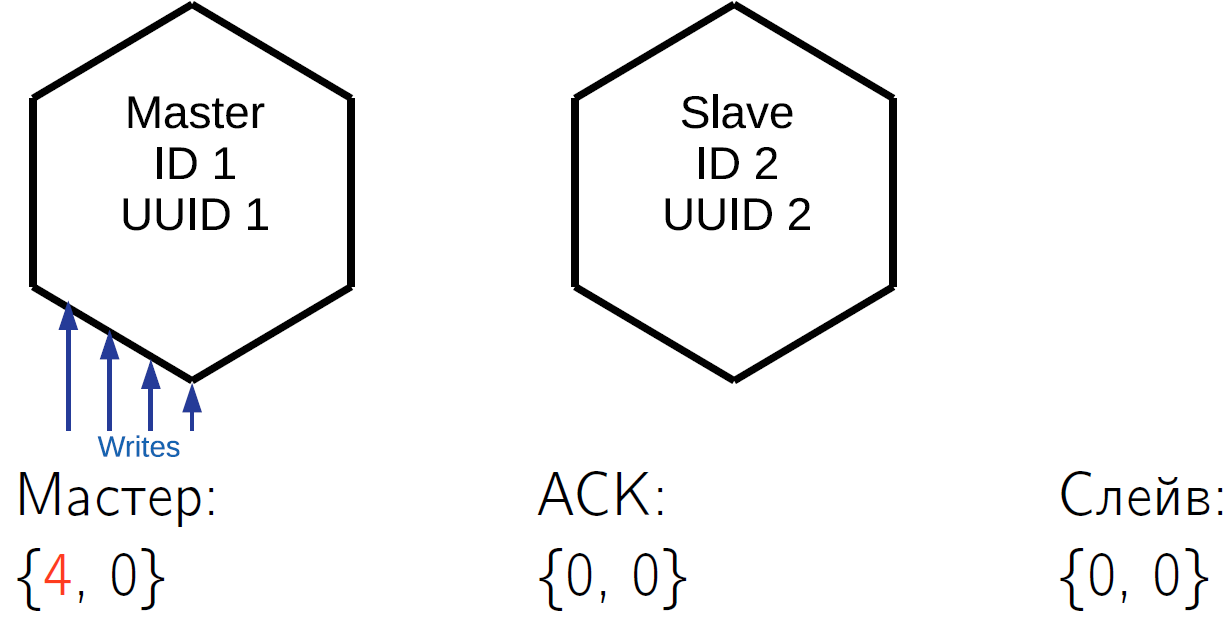
Наша репликация асинхронна, то есть по выполнению коммита вы не знаете, есть ли уже эти данные на каком-то другом узле кластера. Если вы на master’е выполнили коммит, вам его подтвердили, а master по каким-то причинам тут же перестал работать, то нельзя быть уверенным в том, что данные где-то ещё сохранились. Для решения этой проблемы в протоколе репликации Tarantool есть пакет ACK. Каждый master хранит у себя знания о том, какой последний ACK пришел от каждого slave.
Что такое ACK? Когда slave получает дельту, которая помечена lsn’ом master’а и его идентификатором, то в ответ он шлёт специальный ACK-пакет, в который запаковывает свой локальный vclock после применения этой операции. Давайте посмотрим, как это может работать.
У нас есть master, который выполнил в себе 4 операции. Предположим, что в какой-то квант времени slave получил первые три строки и его vclock увеличился до {3,0}.
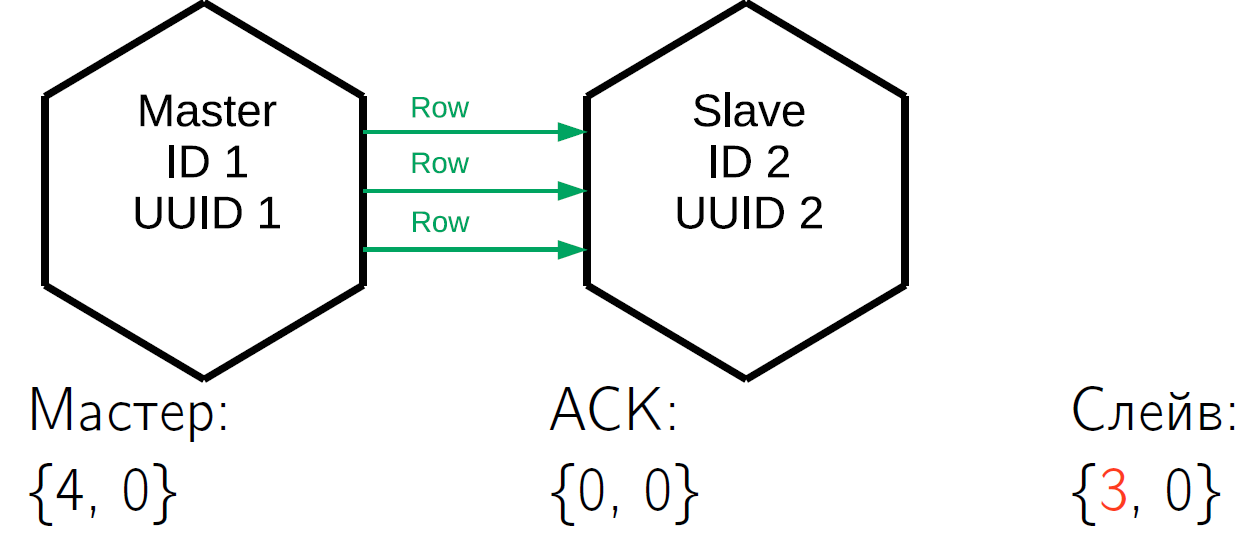
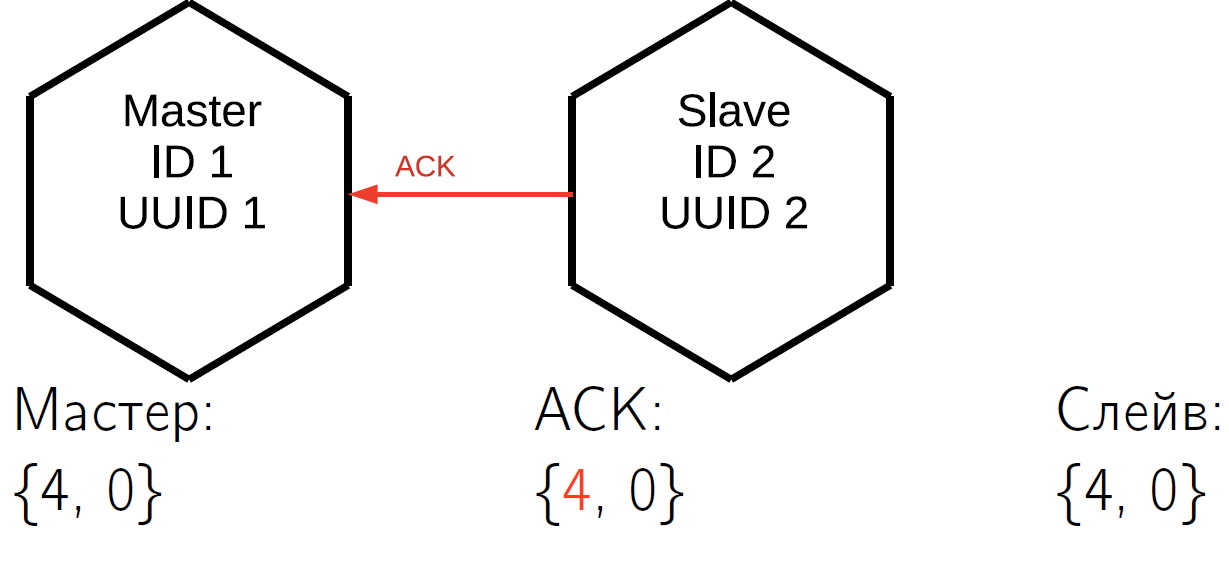
ACK пока не пришёл. Получив эти три строчки, slave отправляет ACK-пакет, в который зашил свой vclock по состоянию на момент отправки пакета. Пусть в тот же квант времени slave-master отправил ещё одну строчку, то есть vclock у slave увеличился. Исходя из этого, master № 1 точно знает, что первые три операции, которые он выполнил, уже применились на этом slave. Эти состояния хранятся для всех slave, с которыми работает master, они абсолютно независимы.

И в конце slave отвечает четвёртым ACK-пакетом. После этого master знает, что slave с ним синхронизирован.
Этот механизм можно использовать в прикладном коде. Когда вы закоммитили операцию, то не сразу же подтверждаете пользователю, а сначала вызываете специальную функцию. Она ждёт, когда lsn slave, известный master'у, окажется равен lsn вашего master'а на момент завершения коммита. Так что вам не нужно ждать полной синхронизации, достаточно дождаться упомянутого момента.
Предположим, что у нас первый вызов изменил три строчки, а второй вызов изменил одну. После первого вызова вы хотите убедиться, что данные синхронизировались. Изображённое выше состояние уже означает, что первый вызов синхронизировался, как минимум, на одном slave.
Где именно искать информацию об этом, мы рассмотрим в следующем разделе.
Мониторинг
Когда репликация синхронна, мониторить очень просто: стоит ей развалиться, и на ваши операции выдаются ошибки. А если репликация асинхронна, то ситуация становится запутанной. Вам master отвечает, что всё хорошо, он работает, принял, записал. Но при этом все реплики мёртвые, данные не имеют избыточности, и при потере master'а вы потеряете и данные. Поэтому очень хочется мониторить кластер, понимать, что происходит с асинхронной репликацией, где находятся реплики, в каком они состоянии.
Для базового мониторинга в Tarantool есть сущность box.info. Стоит вызвать её в консоли, как вы увидите интересные данные.
id: 1
uuid: c35b285c-c5b1-4bbe-83b1-b825eb594aa4
lsn : 5
vclock : {2: 1, 1: 5}
replication :
1: id: 1
uuid : c35b285c -c5b1 -4 bbe -83b1 - b825eb594aa4
lsn : 5
2: id: 2
uuid : 37 b12cb7 -d324 -4 d75 -b428 - cde92c18e708
lsn : 1
upstream : status : follow
idle : 0.30358312401222
peer : lag: 3.6001205444336 e -05
downstream : vclock : {2: 1, 1: 5}Самый важный показатель — это идентификатор
id. В данном случае 1 означает, что lsn этого master'а будет храниться на первой позиции во всех vclock. Очень полезная вещь. Если у вас произошел конфликт при JOIN, то отличить один master от другого вы сможете только по уникальным идентификаторам. Также к локальному состоянию относятся такие величины, как lsn. Это номер последней строки, которую данный master выполнил и записал к себе в журнал. В нашем примере первый master выполнил пять операций. Vclock — это известное ему состояние тех операций, которые он к себе применил. И наконец, для master'а № 2 он выполнил одну его операцию по репликации. После показателей локального состояния можно посмотреть, что данный инстанс знает о состоянии репликации кластера, для этого существует раздел
replication. В нём перечислены все известные инстансу узлы кластера, в том числе он сам. Первый узел имеет идентификатор 1, id соответствует текущему инстансу. У второго узла идентификатор 2, его lsn 1 соответствует тому lsn, который записан в vclock. В данном случае мы рассматриваем master-master репликацию, когда master № 1 одновременно является и master'ом для второго узла кластера, и его slave'ом, то есть следует за ним. - Cущность
upstream. Атрибутstatus followозначает, что master 1 следует за master'ом 2. Idle — время, которое прошло локально с момента последнего взаимодействия с этим master'ом. Мы не шлём поток непрерывно, master отправляет дельту, только когда на нём происходят изменения. Когда мы отправляем какой-то ACK, мы тоже осуществляем взаимодействие. Очевидно, что если idle становится большим (секунды, минуты, часы), то что-то не так. - Атрибут
lag. Мы с вами говорили о запаздывании. Кроме lsn иserver idкаждая операция в логе маркируется еще и timestamp’ом — локальным временем, в течение которого данная операция была записана в vclock на master'е, который её выполнил. Slave при этом сравнивает свой локальный timestamp с timestamp’ом дельты, которую он получил. Последний текущий timestamp, полученный для последней строчки, slave выводит в мониторинге. - Атрибут
downstream. Он показывает то, что master знает о своём конкретном slave'е. Это ACK, который slave ему отправляет. Представленный вышеdownstreamозначает, что в последний раз его slave, он же master под № 2, отправил ему свой vclock, который был равен 5.1. Данный master знает, что все пять его строчек, которые он выполнил у себя, уехали на другой узел.
Потеря XLOG
Рассмотрим ситуацию с падением master’а.
lsn : 0
id: 3
replication :
1: <...>
upstream : status: disconnected
peer : lag: 3.9100646972656 e -05
idle: 1602.836148153
message: connect, called on fd 13, aka [::1]:37960
2: <...>
upstream : status : follow
idle : 0.65611373598222
peer : lag: 1.9550323486328 e -05
3: <...>
vclock : {2: 2, 1: 5}Первым делом поменяется статус.
Lag не меняется потому, что строчка, которую мы применили, так и осталась, новых мы не получали. При этом у нас растёт idle, в данном случае он уже равен 1602 сек., столько времени master был мертв. И видим некое сообщение об ошибке: отсутствует сетевое подключение. Что делать в подобной ситуации? Разбираемся, что случалось с нашим master'ом, привлекаем администратора, перезапускаем сервер, поднимаем узел. Выполняется повторная репликация, и когда master входит в строй, мы к нему подключаемся, подписываемся на его XLOG, получаем их себе и кластер стабилизируется.
Но есть одна маленькая проблема. Представим себе, что у нас был slave, который по каким-то причинам выключился и отсутствовал достаточно долго. За это время master, который его обслуживал, удалил у себя XLOG. Например, диск заполнился, сборщик мусора собрал журналы. Как вернувшийся slave может продолжить работу? Никак. Потому что логов, которую ему нужно применить, чтобы стать синхронизированным с кластером, уже нет и взять их неоткуда. В этом случае мы увидим интересную ошибку: статус уже не
disconnected, а stopped. И специфическое сообщение: нет log-файла, соответствующего таким-то lsn. id: 3
replication :
1: <...>
upstream :
peer : status: stopped
lag : 0.0001683235168457
idle : 9.4331328970147
message: ’Missing .xlog file between LSN 7 1: 5, 2: 2 and 8 1: 6, 2: 2’
2: <...>
3: <...>
vclock : {2: 2, 1: 5}На самом деле ситуация не всегда фатальна. Предположим, что у нас больше двух master’ов, и на каком-то из них эти логи ещё сохранились. Мы же их разливаем всем master'ам сразу, а не храним только на одном. Тогда получится, что данная реплика, подключаясь ко всем известным ей master'ам, на каком-то из них найдёт нужные ей логи. Она выполнит у себя все эти операции, её vclock увеличится, и она дойдёт до актуального состояния кластера. После этого можно попытаться переподключиться.
Если же логов совсем не осталось, продолжить работу реплики мы не можем. Остаётся только её переинициализировать. Запомним её уникальный идентификатор, можно записать на бумажку или в файлик. Потом локально зачищаем реплику: удаляем её снимки, логи и так далее. После этого заново присоединяем реплику с тем же UUID, который у неё был.
Зачистить кластер или переиспользовать UUID для новой реплики:
box.cfg{instance_uuid = старый uuid}.Эта строчка показывает, как переинициализировать реплику. Идентификаторы и UUID мы храним в space cluster, и пространство идентификаторов ограничено. При потере реплики не стоит выбрасывать идентификатор, лучше всего использовать вновь. Если использовать старый UUID, то master, на котором мы делаем JOIN, его обнаружит уже как зарегистрированный, присвоит этой реплике тот же самый UUID, отправит ей снимок, и история начнётся заново.
Если же предположить, что выяснить UUID невозможно, то придётся зайти в space cluster и найти в нём ту запись, которая соответствует потерянной реплике. После этого реплику цепляем как абсолютно новую. Она регистрируется, получает снимок, делает подписку на дельту и кластер становится консистентным и целостным.
Кворум
Предположим, что какая-то из реплик долго не работала и отстала от кластера на сутки. С одной стороны, мы не хотим её терять и заново инициализировать. Но с другой стороны, не хотим рисковать, чтобы пользователи прочитали сильно устаревшие данные.
В Tarantool реализован алгоритм кворума.
replication_connect_quorum: 2
replication_connect_timeout: 30
replication_sync_lag: 0.1Схема, указанная в конфигурации, означает, что данная реплика не вернёт вам управление из конфигурации до тех пор, пока не догонит, как минимум, два master'а с отставанием не более 0,1 сек. Если в течение 30 сек. эта реплика не сможет догнать, она выдаст ошибку. Отставание в 0,1 сек. считается синхронизированностью, но вы можете задавать другие значения.
Keep alive
Бывают ситуации, когда неаккуратный админ поставил в ip tables drop. Вы увидите, что соединение развалилось где-то через 30 минут или 30 секунд, в зависимости от того, какой таймаут стоит в вашей системе. Чтобы справляться с такими ситуациями, мы реализовали keep alive-пакеты.
У keep alive-пакета есть таймаут:
box.cfg.replication_timeout.Если реплика не видит от master'а никаких изменений в течение этого таймаута, она отсылает ему keep alive-пакеты, говоря, что она живая. Если в течение 4 таймаутов master и slave не видят keep alive-пакеты друг от друга, то они разрывают соединение и пытаются установить его заново. Это оказалось и очень удобным средством мониторинга состояния канала между репликой и master'ом.
Избыточность сетевого трафика
Мы говорили, что все изменения идут по кругу. Если у нас 6 реплик, то каждая получит все дельты 5 раз. А если у нас 10 реплик, то каждая получит 9 раз. Эту ситуацию тоже можно решить.
Когда кластер инициализирован, можно немного поменять топологию, чтобы уменьшить избыточность сетевого трафика. Кроме необходимости инициализации мы должны быть уверены, что к любой реплике есть маршрут от любого master'а, который производит изменения. И каким-то образом чисто логически обеспечить баланс между избыточностью канала и надёжностью. Вот примерная топология.
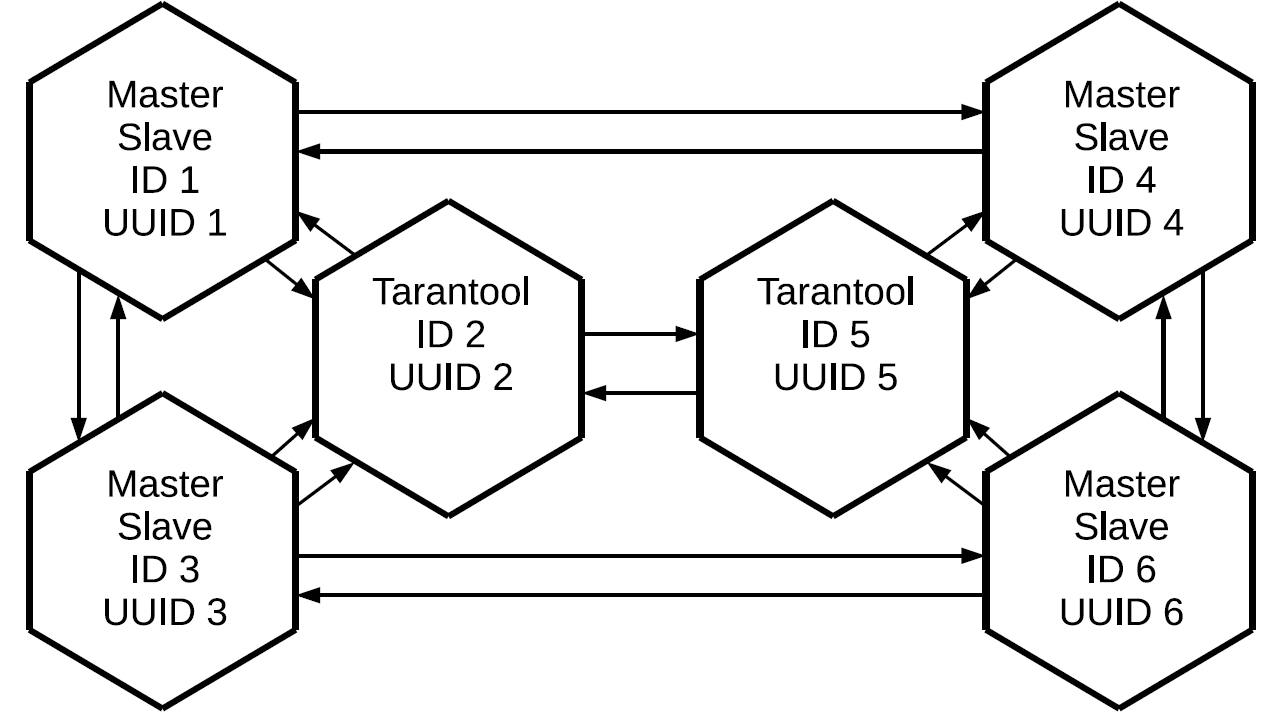
У нас здесь есть 6 реплик, но при этом избыточность равна всего 3. Можно потерять любые две реплики, а кластер останется целым. Вместо того, чтобы передавать каждую дельту 5 раз, мы будем передавать её только 3 раза.
Прочие проблемы с репликацией
Что нужно сделать, если у вас есть проблемы с репликацией:
- Проверить конфигурацию.
- Сделать бэкап, потому что когда вы начинаете чистить space cluster, очень интересно делать разные операции и пытаться разобраться. Тем самым вы рискуете очень легко и быстро потерять данные.
Если не получилось, пишите нам в Telegram-чат, постараемся помочь. Если же мы в чате не смогли решить вашу проблему, то напишите тикет на GitHub, мы обязательно сделаем.
Комментарии (11)

farwayer
12.02.2019 18:21А с шардированием из коробки у вас как теперь? Был модуль, помню, но до production-ready он не дотягивал тогда.

GeorgyK Автор
13.02.2019 09:24Сейчас у нас есть модуль vshard, он построен на бакетах, умеет балансировать бакеты между узлами, добавлять и удалять шарды, использовать сразу несколько роутеров и поддерживать на всех актуальную таблицу маршрутов до бакетов. Мы уже используем его в нескольких проектах в production.
shvez
13.02.2019 11:18Спасибо за статью. Очень познавательно.
У меня такой вопрос. Мы сейчас используем Редис. В нем тоже репликация асинхронная. Редис в Azure. Есть подозрение, что всякий раз, когда машина перегружается и нас переключают на новую состояние базы не соответствует действительности, что для нас критично.
Можно ли как-то от этого защититься используя Тарантул?GeorgyK Автор
13.02.2019 11:29+1В силу асинхронности, реплика может отстать, отставание мониторится в box.info.replication, параметр lag — время в секундах. Оценить отставание в записях можно сравнивая vclock на мастере и реплике. При этом «битых» данных быть не должно.
После возврата мастера реплика докачает все изменения с мастера.
Если есть возможность немного «подержать» мастер — то можно дождаться когда реплика дозагрузит все данные с мастера, сравнивая vclock самого мастера и реплики в replication.downstreamshvez
13.02.2019 11:36Благодарю. Нам всё таки для полной надёжности нужна синхронная репликация. несмотря на то, что продукт ваш очень привлекателен, надёжность репликации нам оч важна
GeorgyK Автор
13.02.2019 11:39Сейчас можно сделать «как-бы синхронную» репликацию — если код вынести в хранимые функции в которых дожидаться подтверждения от реплики — но это не так быстро как могло бы быть.
Либо подождать до лета, возможно синхронная репликация будет в ядре tarantool к этому времени (тикет 980 в тикетнице на гитхабе)
zuborg
Спасибо, расписано очень доступно и в то же время весьма подробно.
Я пока только присматриваюсь к Tarantool, в связи с чем у меня такой вопрос:
Допустим, есть большой плоский массив, скажем, на 100М штук uint64.
Может ли кластер Tarantool эффективно реплицировать работу с таким массивом — поддерживать консистентное состояние, хранить данные в компактном виде (т.е. именно массив, а не хеш-таблица), и пересылать обновления только для изменяемых элементов массива, а не весь массив целиком при каждой операции?
GeorgyK Автор
Добрый день.
Tarantool хранит таплы в msgpack, а для построения индекса используется по умолчанию b+* дерево. Под эту задачу можно оценить количество памяти в несколько гигабайт.
При репликации пересылаются только изменённые строки (row based репликация), весь массив массив будет пересылаться тольео если вы подключаете новый узел.
babylon
Почему не используется col based репликация.
Будет ли создан нативный аллокатор для msgpack? Без того чтобы преобразовывать в lua объекты. В чём nosql-ность тарантула? Таплы подразумевают неизменность порядка полей в записи. Непонятно тогда чем row лучше col?
funny_falcon
Простите пожалуйста, а что такое col based репликация?
Я знаю, что сторадж бывает column based. Но про репликацию не слышал.
А вообще, если я правильно помню, тарантул реплицирует операции: т.е. если был
update c=c+1 where id=100, то только эта операция и будет реплицирована. Могу ошибаться.