Представьте ситуацию: вы потратили много времени на написание и отладку правил корреляции, а через день обнаружили, что они не работают. Как говорится, никогда такого не было и вот опять! После выясняется, что ночью сеть в очередной раз модернизировали, а парочку серверов заменили, но правила корреляции этого не учитывают. В этой статье мы расскажем, как научить SIEM адаптироваться к постоянно изменяющемуся ландшафту инфраструктуры.

Мы все ближе подбираемся к концу цикла статей, посвященных созданию адаптивных правил корреляции, работающих «из коробки». Статья получилась длинной, кто хочет, может сразу перейти к выводам.
В статье «Методология нормализации событий» мы обобщили техники, которые помогут минимизировать проблему потери данных и некорректной нормализации исходных событий. Однако можно ли утверждать, что, если уменьшить роль ошибок нормализации, возможно сделать правила корреляции, работающие «из коробки»? Теоретически — да, если объект мониторинга, за которым наблюдает SIEM, был бы статичным и работал исключительно так, как написано в техническом задании. Но на практике оказывается, что в реальном мире нет ничего статичного.
Итак, рассмотрим подробнее объект мониторинга. SIEM собирает логи с источников, из них он извлекает IP-адреса, учетные записи пользователей, обращения к файлам и ключам реестра, сетевые взаимодействия. Если все обобщить, то это ничто иное, как информация о стадиях жизненного цикла автоматизированной системы (далее — АС). Таким образом, объект мониторинга SIEM — автоматизированная система в целом или какая-то ее часть.
АС не статичный объект, ей свойственно постоянно меняться: вводятся новые рабочие места и серверы, старое оборудование выводится из эксплуатации и заменяется новым, системы «падают» из-за ошибок и восстанавливаются из бэкапов. Динамика на уровне сети, например, динамическая адресация или маршрутизация ежедневно меняют облик АС. Как это проверить? Попробуйте в своей компании найти полную и актуальную L3-схему сети и уточните у сетевых администраторов, насколько она отражает текущее положение дел.
Разрабатывая правила корреляции, вы стараетесь исходить из того, как выглядит АС здесь и сейчас. Тестируя правила корреляции, вы дорабатываете их до такого состояния, при котором они способны работать с наименьшим числом ложных срабатываний в текущей конфигурации АС. Так как АС постоянно меняется, правила корреляции, рано или поздно, придется актуализировать.
Теперь усложним задачу и рассмотрим правила, поставляемые внешними экспертами, такими как коммерческие SOC, интеграторы, внедряющие SIEM, или сами разработчики SIEM-решений. Эти правила не включают особенности вашей АС — контекст исполнения — они под них не оптимизированы. Данная проблема — еще один камень преткновения в концепции правил корреляции, работающих «из коробки». Ее решение может заключаться в том, что SIEM внутри себя:
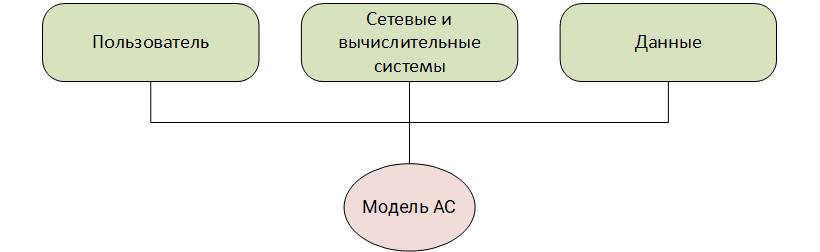
Для начала опишем состав модели АС. Если обратиться к классическому определению термина из ГОСТа 34.003-90, то АС — это «система, состоящая из персонала и комплекса средств автоматизации его деятельности, реализующая информационную технологию выполнения установленных функций». Важно, что при реализации информационной технологии персонал (пользователи) и средства автоматизации оперируют данными.
Поскольку SIEM собирает информацию со множества различных источников, включая средства IT, ИБ и бизнес-приложения, то все части данного определения будут нам «видны» непосредственно в событиях.
Далее расскажем, как выглядит модель, созданная для таких сущностей, как пользователь, комплекс средств автоматизации (далее — сетевые и вычислительные системы) и данные.
К сожалению, моделировать технологические процессы в рамках SIEM достаточно сложно, потому что такой класс решений для этого не предназначен. Тем не менее часть процессов видно через модели поведения указанных сущностей.
Общая модель АС
Дальше мы рассмотрим каждую сущность и подробно остановимся на:
Под пользователем АС следует понимать конкретного человека: сотрудника компании, подрядчика или фрилансера. Важно, что он имеет санкционированный доступ к АС.
Информация о пользователях АС, как правило, фрагментарно раскидана во множестве систем. Чтобы ее собрать, потребуется приложить усилия. Посмотрим на примере, где и какую информацию можно собрать по конкретному пользователю.
Таким образом, если в компании нет решений Identity Management или User Rights management, которые хоть как-то помогают собрать воедино эту разрозненную идентификационную информацию, придется делать это самим в SIEM вручную.
Подытожим:
Составляя модель любой сущности, разделим ее на два блока. Первый блок используется для хранения общей информации по сущности, второй — отвечает за составление модели поведения сущности. Данный профиль может использоваться правилами корреляции для выявления аномальных отклонений в поведении сущности.
В состав общей модели пользователя как минимум необходимо включать:
В состав поведенческой модели пользователя как минимум необходимо включать:
Модель пользователя
Профилирование информационных потоков — сложная задача, для решения которой в SIEM зачастую нет удобных и простых механизмов. Но построение такого профиля можно начать с электронной почты и используемых общих сетевых ресурсов.
Откуда взять данные, необходимые для построения модели? Рассмотрим два основных принципа получения информации, доступных в большинстве SIEM, — активные и пассивные способы сбора.
При активном способе SIEM сам обращается к источникам, содержащим необходимые для построения модели данные.
При пассивном способе модель заполняется на основе данных из событий, поступающих в SIEM от источников.
Как правило, чтобы получить наиболее полную модель, лучше сочетать два способа.
Важно понимать, что собранные в рамках модели данные необходимо постоянно актуализировать и делать это в автоматическом, а не ручном режиме. Для актуализации данных подойдут ровно те же способы, что используются для их первоначального сбора.
Рассмотрим, какие источники могут предоставить данные для построения модели и какими способами из них можно получить нужную информацию.
Под элементами сетевых и вычислительных систем будем понимать рабочие станции, серверное и сетевое оборудование, средства защиты информации. На данный момент в SIEM и в решениях уровня Vulnerability Management именно их называют активами.
Кажется, это вполне очевидно, что такие активы можно легко идентифицировать по IP-адресу, MAC-адресу, FQDN или hostname (далее — исходные ключи идентификации). Всегда ли это так? Как и было обозначено выше, в АС постоянно происходят какие-то изменения. Посмотрим несколько таких изменений и подумаем, как себя ведут наши исходные ключи идентификации.
В небольшой компании данные изменения могут проходить крайне редко и их возможно обрабатывать руками экспертов, отвечающих за работу SIEM. Но что делать, если компания с широкой сетью филиалов? И далеко не всегда у службы ИБ есть хорошо налаженные коммуникации с IT-службой, а значит, до эксперта по SIEM нужная информация об изменениях в АС может не дойти.
Раз для идентификации актива нельзя опираться ни на IP,MAC, FQDN, и ни на Hostname по отдельности, то можно попробовать идентифицировать актив сразу по всем 4 параметрам. Здесь мы сталкиваемся с глобальной проблемой: SIEM оперирует событиями, а в них практически никогда не присутствуют одновременно все исходные ключи идентификации.
Как ее можно решить? Разберем несколько вариантов:
На данный момент я работал только с двумя решениями, где у производителей была экспертиза для реализации такого подхода — IBM QRadar (общее описание по ссылке, детали алгоритма закрыты) и Positive Technologies MaxPatrol SIEM (детали алгоритма закрыты). На данный момент обе компании продолжают использовать и совершенствовать именно гибридный подход.
Итак:
Вычислительные системы, включая системное и прикладное ПО, установленное на них, несут много информации, необходимой для повышения точности работы правил корреляции.
Так же, как и модель пользователя, модель сетевых и вычислительных систем состоит из общей и поведенческой части.
В состав общей модели сетевых и вычислительных систем как минимум необходимо включать:
В состав поведенческой модели сетевых и вычислительных систем как минимум необходимо включать:

Модель сетевых и вычислительных систем
Сбор информации для этой модели возможен двумя способами: активным и пассивным.
Рассмотрим общую модель:
Перейдем к последней составляющей контекста — модели защищаемых данных.
Чаще всего SIEM не используется для мониторинга защищаемых данных, так как для этого есть решения класса Data Leak Prevention (DLP). Однако эти знания помогают более точно оценивать значимость происходящего инцидента. К примеру, при написании правила корреляции было бы полезно знать, что инцидент происходит не просто на какой-то рабочей станции, а на станции, которая в данный момент хранит финансовый отчет за год или иную конфиденциальную информацию.
Идентификация конфиденциальной информации реализуется механизмом поиска цифровых отпечатков в самом DLP-решении. Специфика механизма не позволяет реализовать его внутри SIEM. Таким образом, в части идентификации защищаемых данных возможно использовать только тесную интеграцию с решениями класса DLP.
В связи с тем, что большую часть функций по мониторингу и защите конфиденциальной информации реализует DLP, состав модели в SIEM достаточно компактный.
В состав общей модели защищаемых данных, как минимум, необходимо включать:
В состав поведенческой модели защищаемых данных, как минимум, необходимо включать:
Модель защищаемых данных
Для построения модели защищаемых данных так же доступны два способа получения информации — активный и пассивный.
Рассмотрим общую модель:
Посмотрим, каким образом возможно реализовать модель АС в SIEM. Для этого на уровне SIEM необходимо решить два основных вопроса:
Активный сбор данных для модели, как правило, осуществляется встроенными в SIEM механизмами интеграции со сканерами безопасности. Также активный сбор может осуществятся путем выгрузки данных из внешних источников, например, баз данных.
Пассивный сбор осуществляется путем анализа событий, проходящих через SIEM.
Как правило, в SIEM текущего поколения для хранения указанных выше данных модели, применяются механизмы табличных списках/Active List/Reference set of set и тому подобное. При активном сборе данных создаются плановые задачи по их заполнению из внешних источников. При пассивном сборе создаются отдельные правила корреляции, в рамках которых при появлении нужных событий (создание пользователя, удаление софта, передача файла и т.д.) данные из события вставляются в табличный список.
В общем случае все современные SIEM-решения содержат все необходимые элементы для создания и наполнения данными описываемой модели АС.
АС постоянно меняется, это важно учитывать, если не в самих правилах корреляции, так как они работают в режиме близком к реальному времени и оперируют текущим состоянием АС, то при расследовании инцидента. С момента начала инцидента до его расследования могут пройти минуты, часы, а иногда и месяцы. При некоторых атаках между внедрением злоумышленника в систему и выявлением SIEM его активностей может пройти до 6 месяцев ( 2018 Cost of a Data Breach Study by Ponemon). За это время ландшафт системы может кардинально поменяться: добавились и удалились пользователи, изменилась конфигурация оборудования, вышла из эксплуатации важное для расследования инцидента оборудование, а скопированные злоумышленником данные с одних хостов «перетекли» на другие. Поэтому при расследовании важно смотреть на модель системы в том состоянии, в котором она находилась на момент инцидента, а не на текущее, когда мы только взялись его расследовать.
Вывод из всего этого такой: та, модель которая строится внутри SIEM, должна иметь историю, к которой можно обратиться в любой момент времени.
Изменение модели во времени
Подведем итоги:
Цикл статей:
Глубины SIEM: корреляции «из коробки». Часть 1: Чистый маркетинг или нерешаемая проблема?
Глубины SIEM: корреляции «из коробки». Часть 2. Схема данных как отражение модели «мира»
Глубины SIEM: корреляции «из коробки». Часть 3.1. Категоризация событий
Глубины SIEM: корреляции «из коробки». Часть 3.2. Методология нормализации событий
Глубины SIEM: корреляции «из коробки». Часть 4. Модель системы как контекст правил корреляции (Данная статья)
Мы все ближе подбираемся к концу цикла статей, посвященных созданию адаптивных правил корреляции, работающих «из коробки». Статья получилась длинной, кто хочет, может сразу перейти к выводам.
В статье «Методология нормализации событий» мы обобщили техники, которые помогут минимизировать проблему потери данных и некорректной нормализации исходных событий. Однако можно ли утверждать, что, если уменьшить роль ошибок нормализации, возможно сделать правила корреляции, работающие «из коробки»? Теоретически — да, если объект мониторинга, за которым наблюдает SIEM, был бы статичным и работал исключительно так, как написано в техническом задании. Но на практике оказывается, что в реальном мире нет ничего статичного.
Итак, рассмотрим подробнее объект мониторинга. SIEM собирает логи с источников, из них он извлекает IP-адреса, учетные записи пользователей, обращения к файлам и ключам реестра, сетевые взаимодействия. Если все обобщить, то это ничто иное, как информация о стадиях жизненного цикла автоматизированной системы (далее — АС). Таким образом, объект мониторинга SIEM — автоматизированная система в целом или какая-то ее часть.
АС не статичный объект, ей свойственно постоянно меняться: вводятся новые рабочие места и серверы, старое оборудование выводится из эксплуатации и заменяется новым, системы «падают» из-за ошибок и восстанавливаются из бэкапов. Динамика на уровне сети, например, динамическая адресация или маршрутизация ежедневно меняют облик АС. Как это проверить? Попробуйте в своей компании найти полную и актуальную L3-схему сети и уточните у сетевых администраторов, насколько она отражает текущее положение дел.
Разрабатывая правила корреляции, вы стараетесь исходить из того, как выглядит АС здесь и сейчас. Тестируя правила корреляции, вы дорабатываете их до такого состояния, при котором они способны работать с наименьшим числом ложных срабатываний в текущей конфигурации АС. Так как АС постоянно меняется, правила корреляции, рано или поздно, придется актуализировать.
Теперь усложним задачу и рассмотрим правила, поставляемые внешними экспертами, такими как коммерческие SOC, интеграторы, внедряющие SIEM, или сами разработчики SIEM-решений. Эти правила не включают особенности вашей АС — контекст исполнения — они под них не оптимизированы. Данная проблема — еще один камень преткновения в концепции правил корреляции, работающих «из коробки». Ее решение может заключаться в том, что SIEM внутри себя:
- Строит модель наблюдаемой АС.
- Всегда поддерживает данную модель в актуальном состоянии.
- Позволяет использовать данную модель в качестве контекста исполнения в правилах корреляции.
Контекст — модель автоматизированной системы
Для начала опишем состав модели АС. Если обратиться к классическому определению термина из ГОСТа 34.003-90, то АС — это «система, состоящая из персонала и комплекса средств автоматизации его деятельности, реализующая информационную технологию выполнения установленных функций». Важно, что при реализации информационной технологии персонал (пользователи) и средства автоматизации оперируют данными.
Поскольку SIEM собирает информацию со множества различных источников, включая средства IT, ИБ и бизнес-приложения, то все части данного определения будут нам «видны» непосредственно в событиях.
Далее расскажем, как выглядит модель, созданная для таких сущностей, как пользователь, комплекс средств автоматизации (далее — сетевые и вычислительные системы) и данные.
К сожалению, моделировать технологические процессы в рамках SIEM достаточно сложно, потому что такой класс решений для этого не предназначен. Тем не менее часть процессов видно через модели поведения указанных сущностей.
Общая модель АС
Дальше мы рассмотрим каждую сущность и подробно остановимся на:
- уникальной идентификации;
- составе модели;
- поиске данных, необходимых для модели;
- природе изменения данных сущности;
- актуализации данных в модели при их изменении.
Модель пользователя
Идентификация
Под пользователем АС следует понимать конкретного человека: сотрудника компании, подрядчика или фрилансера. Важно, что он имеет санкционированный доступ к АС.
Информация о пользователях АС, как правило, фрагментарно раскидана во множестве систем. Чтобы ее собрать, потребуется приложить усилия. Посмотрим на примере, где и какую информацию можно собрать по конкретному пользователю.
- Microsoft Active Directory и Microsoft Exchange. Из них мы сможем узнать его основной доменный логин и адрес электронной почты.
- Cisco Identity Services Engine (ISE) хранит его второй логин для удаленного доступа по VPN.
- База данных внутреннего портала хранит его третий логин.
- Если пользователь является администратором баз данных, то в СУБД хранится его четвертый логин, а может и не один.
- База данных HR, в которой хранится его полное ФИО (в случае, если в Active Directory поленились завести пользователя по всем правилам).
Таким образом, если в компании нет решений Identity Management или User Rights management, которые хоть как-то помогают собрать воедино эту разрозненную идентификационную информацию, придется делать это самим в SIEM вручную.
Подытожим:
- В SIEM необходимо иметь единый идентификатор пользователя.
- При появлении учетных записей пользователя в любом логе, любой системы, мы должны однозначно его идентифицировать и проставить наш собственный единый идентификатор пользователя.
Состав модели
Составляя модель любой сущности, разделим ее на два блока. Первый блок используется для хранения общей информации по сущности, второй — отвечает за составление модели поведения сущности. Данный профиль может использоваться правилами корреляции для выявления аномальных отклонений в поведении сущности.
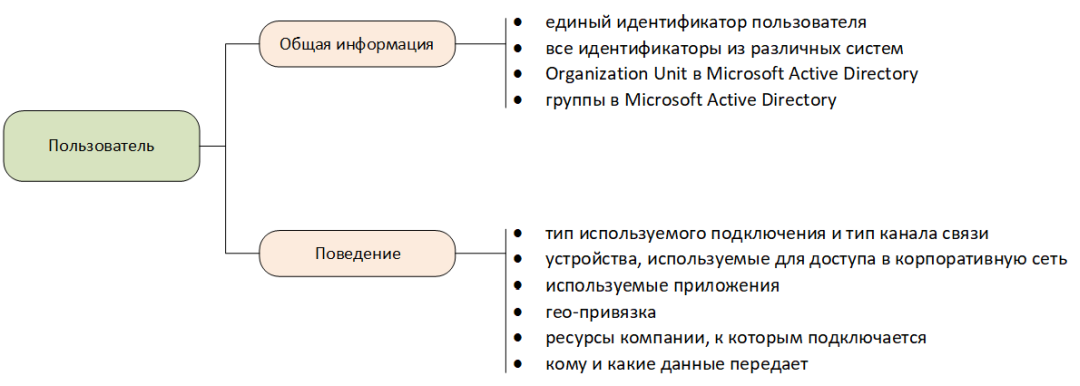
В состав общей модели пользователя как минимум необходимо включать:
- единый идентификатор пользователя в SIEM;
- все его идентификаторы из различных систем, включая:
- внешние и внутренние адреса электронной почты;
- ФИО;
- локальную учетную запись в ОС;
- доменную учетную запись;
- учетную запись для доступа по VPN;
- учетную запись на Proxy;
- учётные запись в СУБД;
- учетные записи в иных прикладных системах.
- Organization Unit в Microsoft Active Directory, в которые входит пользователь;
- группы в Microsoft Active Directory, в которые входит пользователь.
В состав поведенческой модели пользователя как минимум необходимо включать:
- тип используемого подключения (локальный, удаленный) и тип канала связи (проводной, беспроводной);
- устройства, используемые для доступа в корпоративную сеть;
- используемые приложения;
- гео-привязку, особенно для удаленных пользователей;
- ресурсы компании, к которым подключается пользователь;
- кому и какие данные передает (информационные потоки).
Модель пользователя
Профилирование информационных потоков — сложная задача, для решения которой в SIEM зачастую нет удобных и простых механизмов. Но построение такого профиля можно начать с электронной почты и используемых общих сетевых ресурсов.
Источники данных для модели
Откуда взять данные, необходимые для построения модели? Рассмотрим два основных принципа получения информации, доступных в большинстве SIEM, — активные и пассивные способы сбора.
При активном способе SIEM сам обращается к источникам, содержащим необходимые для построения модели данные.
При пассивном способе модель заполняется на основе данных из событий, поступающих в SIEM от источников.
Как правило, чтобы получить наиболее полную модель, лучше сочетать два способа.
Важно понимать, что собранные в рамках модели данные необходимо постоянно актуализировать и делать это в автоматическом, а не ручном режиме. Для актуализации данных подойдут ровно те же способы, что используются для их первоначального сбора.
Рассмотрим, какие источники могут предоставить данные для построения модели и какими способами из них можно получить нужную информацию.
Для общей модели 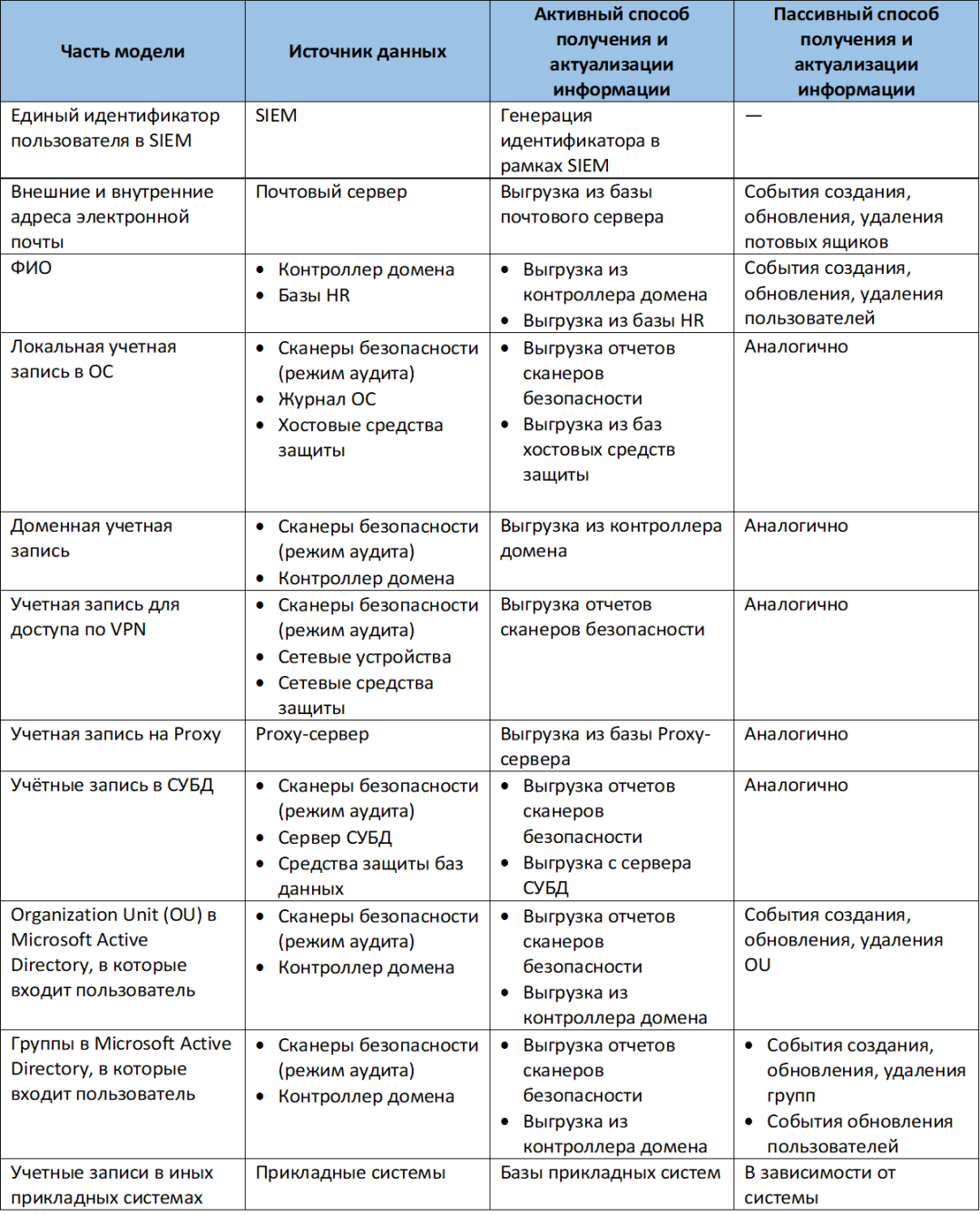
Для поведенческой модели 
Модель сетевых и вычислительных систем
Идентификация
Под элементами сетевых и вычислительных систем будем понимать рабочие станции, серверное и сетевое оборудование, средства защиты информации. На данный момент в SIEM и в решениях уровня Vulnerability Management именно их называют активами.
Кажется, это вполне очевидно, что такие активы можно легко идентифицировать по IP-адресу, MAC-адресу, FQDN или hostname (далее — исходные ключи идентификации). Всегда ли это так? Как и было обозначено выше, в АС постоянно происходят какие-то изменения. Посмотрим несколько таких изменений и подумаем, как себя ведут наши исходные ключи идентификации.
- Использование в сети DHCP. Меняются IP-адреса активов.
- Переключение нод в кластерной конфигурации. В зависимости от типа кластеризации могут меняться MAC и IP.
- Восстановление системы из резервной копии на другом сервере из-за критического сбоя. Меняются MAC-адреса, иногда IP, FQDN и Hostname.
- Плановая замена, модернизация оборудования или части АС. Могут меняться практически все ключи.
В небольшой компании данные изменения могут проходить крайне редко и их возможно обрабатывать руками экспертов, отвечающих за работу SIEM. Но что делать, если компания с широкой сетью филиалов? И далеко не всегда у службы ИБ есть хорошо налаженные коммуникации с IT-службой, а значит, до эксперта по SIEM нужная информация об изменениях в АС может не дойти.
Раз для идентификации актива нельзя опираться ни на IP,MAC, FQDN, и ни на Hostname по отдельности, то можно попробовать идентифицировать актив сразу по всем 4 параметрам. Здесь мы сталкиваемся с глобальной проблемой: SIEM оперирует событиями, а в них практически никогда не присутствуют одновременно все исходные ключи идентификации.
Как ее можно решить? Разберем несколько вариантов:
- Активный способ с использованием решений уровня Configuration management database (CMDB). Информацию об исходных ключах идентификации можно брать оттуда. Но содержит ли CMDB все необходимые для идентификации исходные ключи активов? И, самое главное, учитывает ли она описанные выше ситуации изменения АС? Также важно учитывать время обновления данных в CMDB, если данные отстают от реального состояния АС на десятки минут или часов, — скорее всего, такое решение не подойдет для использования в поточной корреляции событий в SIEM.
- Активный способ с использованием Vulnerability Management решением. Можно загружать его отчеты в SIEM, как, например, делает Micro focus ArcSight. Но есть ли гарантия, что сторонний сканер принесёт все нужные для идентификации данные? Насколько они будут актуальны, если сканирования выполняются не чаще раза в месяц (среднее значение для крупных компаний), да и покрывает далеко не всю инфраструктуру.
- Пассивный способ. Идентифицировать активы из событий, несмотря на их неполноту и неточность данных. События содержат не все ключи, разные источники отправляют разные наборы ключей. Однако это самый быстрый способ получить информацию об изменении АС. Источники, как правило, генерируют события во всех, описанных выше, ситуациях, за исключением плановой замены оборудования.
- Гибридный способ. Использовать преимущества сразу всех подходов:
- Активный сбор с CMDB позволяет осуществить быстрое первичное наполнение SIEM активами.
- Интеграция с Vulnerability Management добавит недостающей информации.
- Анализ событий позволит наиболее быстро актуализировать модель, с учетом специфика каждого источника в отдельности.
Гибридный способ позволяет нивелировать проблемы остальных, однако сложен в реализации.
На данный момент я работал только с двумя решениями, где у производителей была экспертиза для реализации такого подхода — IBM QRadar (общее описание по ссылке, детали алгоритма закрыты) и Positive Technologies MaxPatrol SIEM (детали алгоритма закрыты). На данный момент обе компании продолжают использовать и совершенствовать именно гибридный подход.
Итак:
- Рабочие станции, сетевое и серверное оборудование необходимо идентифицировать гибридным способом, агрегируя данные из CMDB, Vulnerability Management-систем и событий от самих источников.
- Для корректного объединения и актуализации собранной для идентификации информации необходимо иметь экспертные механизмы, учитывающие особенности каждого источника.
Состав модели
Вычислительные системы, включая системное и прикладное ПО, установленное на них, несут много информации, необходимой для повышения точности работы правил корреляции.
Так же, как и модель пользователя, модель сетевых и вычислительных систем состоит из общей и поведенческой части.
В состав общей модели сетевых и вычислительных систем как минимум необходимо включать:
- аппаратное обеспечение (включая внешние устройства);
- заведенные пользователи;
- установленные службы и их связка с открытыми портами;
- установленное ПО и его версии;
- установленные обновления;
- имеющиеся уязвимости;
- запланированные задачи;
- перечень ПО для автозагрузки;
- таблицы маршрутизации;
- общие сетевые ресурсы.
В состав поведенческой модели сетевых и вычислительных систем как минимум необходимо включать:
- сетевые взаимодействия L3 и L4 (с чем взаимодействует и по каким протоколам);
- средний объем передаваемых данных в неделю;
- какие пользователи используют;
- с каких узлов реализуется удаленное управление;
- статистика срабатывания средств защиты по данному хосту (сетевых и локальных).
Модель сетевых и вычислительных систем
Источники данных для модели
Сбор информации для этой модели возможен двумя способами: активным и пассивным.
Рассмотрим общую модель:
Для общей модели 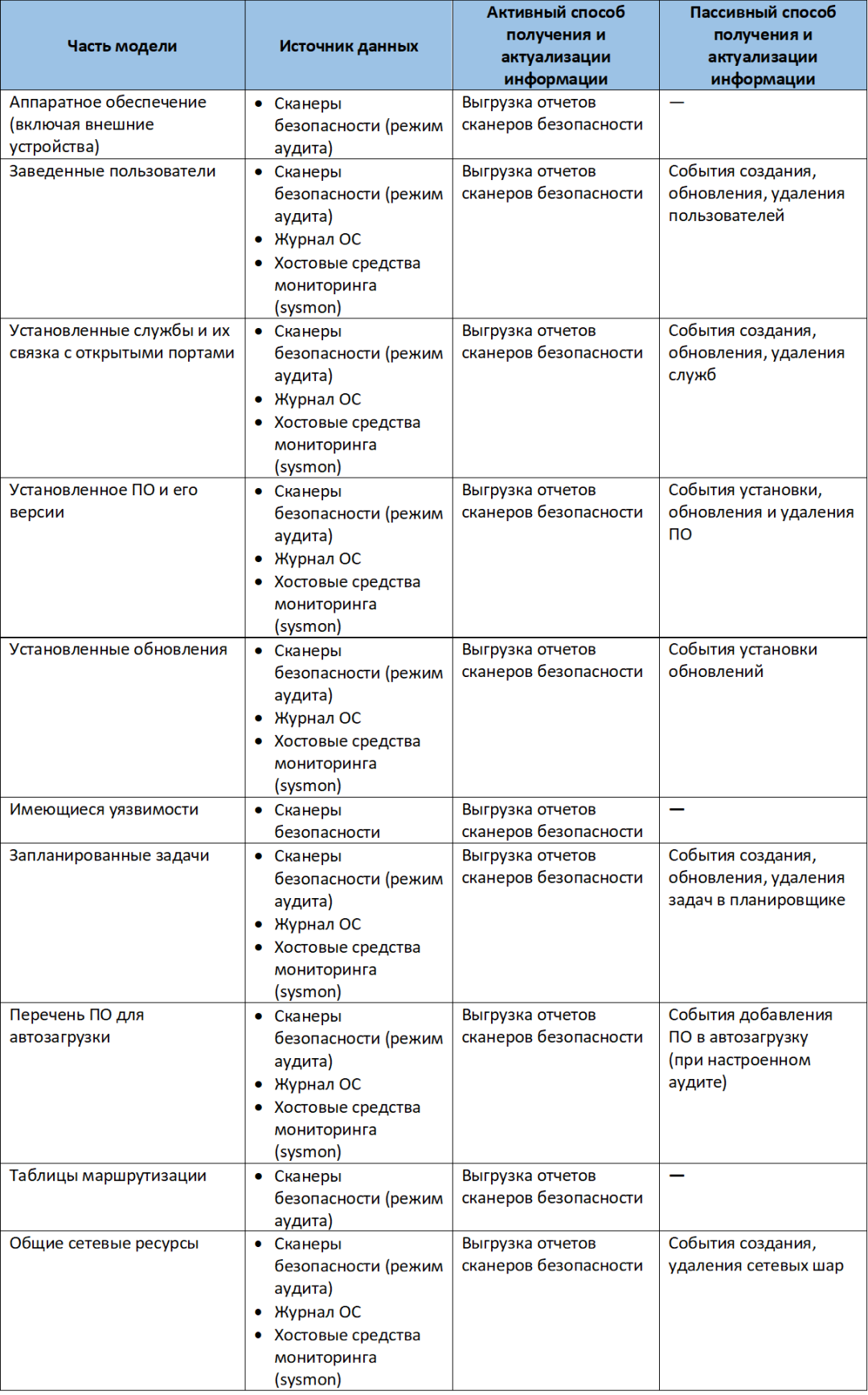
Для поведенческой модели 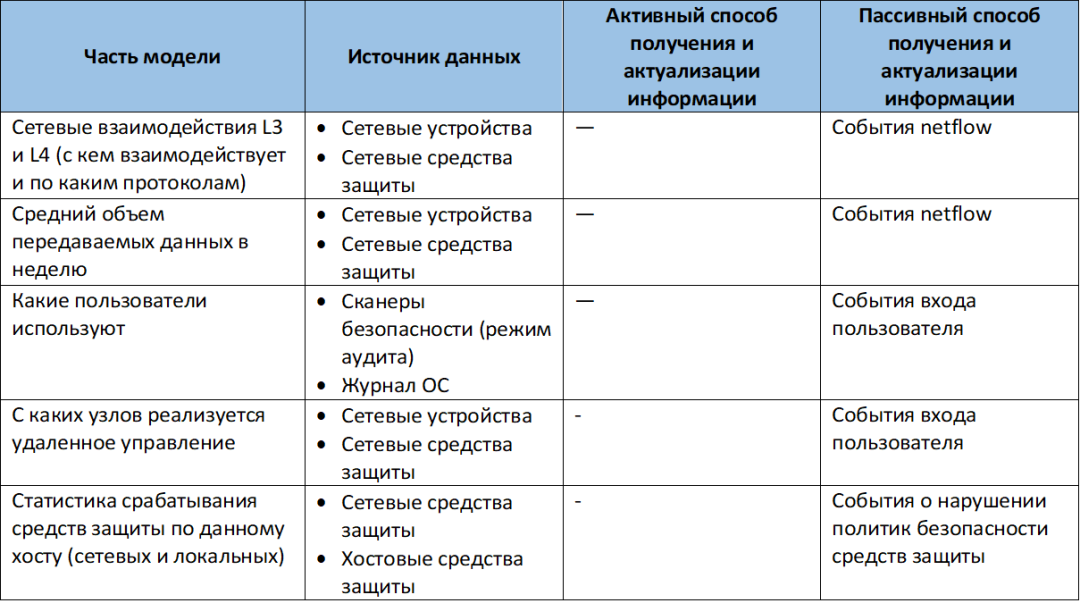
Модель защищаемых данных
Идентификация
Перейдем к последней составляющей контекста — модели защищаемых данных.
Чаще всего SIEM не используется для мониторинга защищаемых данных, так как для этого есть решения класса Data Leak Prevention (DLP). Однако эти знания помогают более точно оценивать значимость происходящего инцидента. К примеру, при написании правила корреляции было бы полезно знать, что инцидент происходит не просто на какой-то рабочей станции, а на станции, которая в данный момент хранит финансовый отчет за год или иную конфиденциальную информацию.
Идентификация конфиденциальной информации реализуется механизмом поиска цифровых отпечатков в самом DLP-решении. Специфика механизма не позволяет реализовать его внутри SIEM. Таким образом, в части идентификации защищаемых данных возможно использовать только тесную интеграцию с решениями класса DLP.
Состав модели
В связи с тем, что большую часть функций по мониторингу и защите конфиденциальной информации реализует DLP, состав модели в SIEM достаточно компактный.
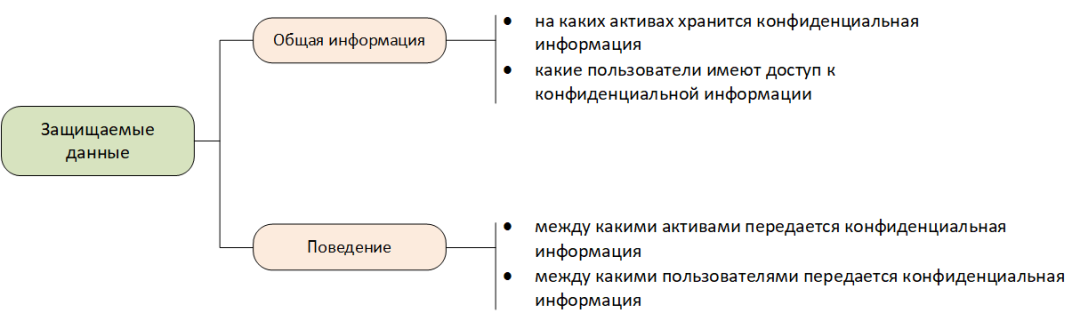
В состав общей модели защищаемых данных, как минимум, необходимо включать:
- на каких активах хранится конфиденциальная информация;
- какие пользователи имеют доступ к конфиденциальной информации.
В состав поведенческой модели защищаемых данных, как минимум, необходимо включать:
- между какими активами передается конфиденциальная информация;
- между какими пользователями передается конфиденциальная информация.
Модель защищаемых данных
Источники данных для модели
Для построения модели защищаемых данных так же доступны два способа получения информации — активный и пассивный.
Рассмотрим общую модель:
Для общей модели 
Для поведенческой модели 
Механизмы реализации модели в SIEM
Посмотрим, каким образом возможно реализовать модель АС в SIEM. Для этого на уровне SIEM необходимо решить два основных вопроса:
- Каким образом реализовать активный и пассивный сбор данных.
- Где и в каком виде хранить модель.
Активный сбор данных для модели, как правило, осуществляется встроенными в SIEM механизмами интеграции со сканерами безопасности. Также активный сбор может осуществятся путем выгрузки данных из внешних источников, например, баз данных.
Пассивный сбор осуществляется путем анализа событий, проходящих через SIEM.
Как правило, в SIEM текущего поколения для хранения указанных выше данных модели, применяются механизмы табличных списках/Active List/Reference set of set и тому подобное. При активном сборе данных создаются плановые задачи по их заполнению из внешних источников. При пассивном сборе создаются отдельные правила корреляции, в рамках которых при появлении нужных событий (создание пользователя, удаление софта, передача файла и т.д.) данные из события вставляются в табличный список.
В общем случае все современные SIEM-решения содержат все необходимые элементы для создания и наполнения данными описываемой модели АС.
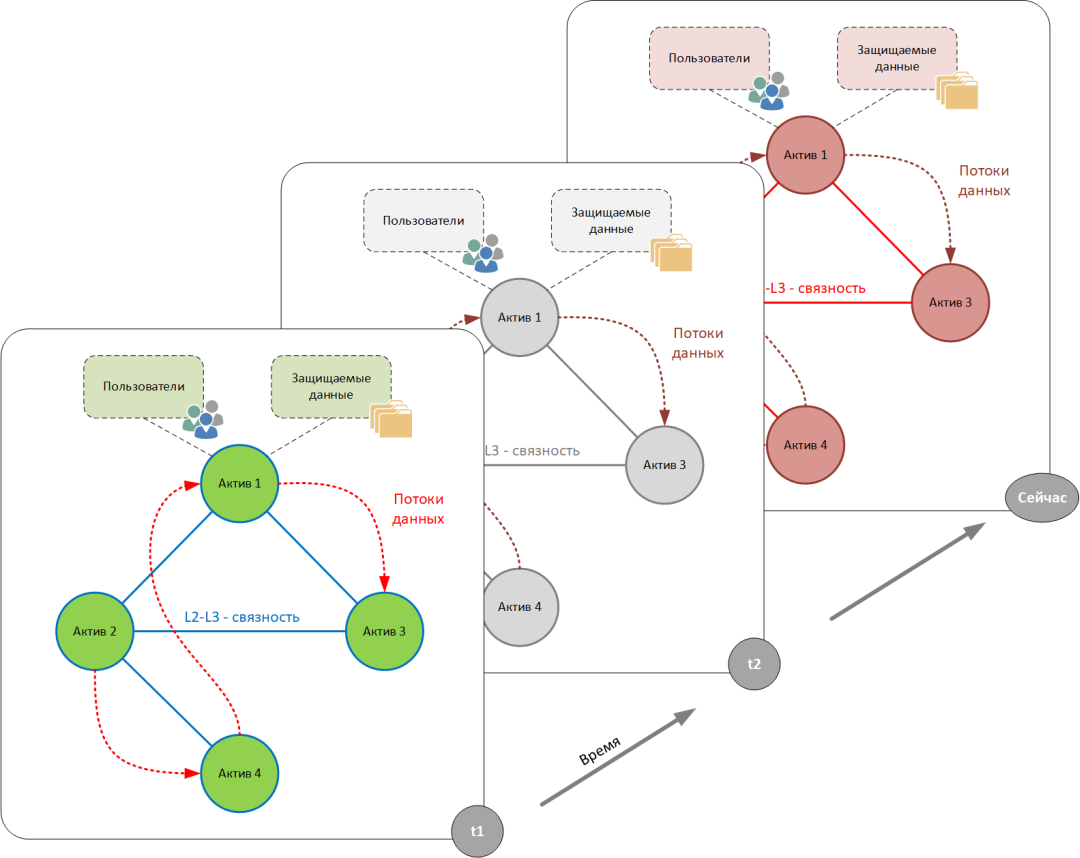
Историчность модели
АС постоянно меняется, это важно учитывать, если не в самих правилах корреляции, так как они работают в режиме близком к реальному времени и оперируют текущим состоянием АС, то при расследовании инцидента. С момента начала инцидента до его расследования могут пройти минуты, часы, а иногда и месяцы. При некоторых атаках между внедрением злоумышленника в систему и выявлением SIEM его активностей может пройти до 6 месяцев ( 2018 Cost of a Data Breach Study by Ponemon). За это время ландшафт системы может кардинально поменяться: добавились и удалились пользователи, изменилась конфигурация оборудования, вышла из эксплуатации важное для расследования инцидента оборудование, а скопированные злоумышленником данные с одних хостов «перетекли» на другие. Поэтому при расследовании важно смотреть на модель системы в том состоянии, в котором она находилась на момент инцидента, а не на текущее, когда мы только взялись его расследовать.
Вывод из всего этого такой: та, модель которая строится внутри SIEM, должна иметь историю, к которой можно обратиться в любой момент времени.
Изменение модели во времени
Выводы
Подведем итоги:
- Для того чтобы правила корреляции функционировали с минимальным количеством ложных срабатываний, они должны учитывать контекст, в котором работают.
- Контекстом для правил корреляции служит модель автоматизированной системы компании.
- SIEM обязана строить данную модель в процессе своей работы.
- Модель автоматизированной системы состоит из трех основных частей:
- модель пользователя и его поведения;
- модель сетевых и вычислительных систем, их сетевые связи и их поведение;
- модель защищаемых данных и их поведение.
- Сбор данных, необходимых для модели, может осуществляться двумя способами:
- активным через выгрузку информации с источников;
- пассивным через выделение необходимой для модели информации из событий.
- Каждый из методов сбора имеет свои плюсы и минусы, влияющие на полноту и точность модели. Для построения наиболее точной модели необходимо использовать оба способа одновременно.
- Модель не статична и меняется вслед за изменениями в автоматизированной системе.
- Начало инцидента и его расследование могут разделять дни или даже месяцы, поэтому при расследовании важно оперировать моделью системы в том состоянии, в котором она была на момент начала инцидента, а не ее текущей конфигурации.
- Модель автоматизированной системы в SIEM должна иметь историчность.
Цикл статей:
Глубины SIEM: корреляции «из коробки». Часть 1: Чистый маркетинг или нерешаемая проблема?
Глубины SIEM: корреляции «из коробки». Часть 2. Схема данных как отражение модели «мира»
Глубины SIEM: корреляции «из коробки». Часть 3.1. Категоризация событий
Глубины SIEM: корреляции «из коробки». Часть 3.2. Методология нормализации событий
Глубины SIEM: корреляции «из коробки». Часть 4. Модель системы как контекст правил корреляции (Данная статья)