
Анонс WebAssembly состоялся в 2015-м — но сейчас, спустя годы, всё ещё немногие могут похвастаться им в продакшне. Тем ценнее материалы о подобном опыте: информация из первых рук о том, каково с этим жить на практике, пока что в дефиците.
На конференции HolyJS доклад об опыте использования WebAssembly получил высокие оценки зрителей, и теперь специально для Хабра подготовлена текстовая версия этого доклада (видеозапись также приложена).
Меня зовут Андрей, я расскажу вам про WebAssembly. Можно сказать, что я начал заниматься вебом в прошлом веке, но я скромный, поэтому так говорить не буду. За это время я успел поработать и над бэкендом, и над фронтендом, и даже немножко рисовал дизайн. Сегодня я интересуюсь такими вещами, как WebAssembly, C++ и прочими нативными штуками. Еще я очень люблю типографику и собираю старую технику.
Сначала я расскажу о том, как мы с командой внедряли WebAssembly в нашем проекте, потом мы обсудим, нужно ли вам что-то от WebAssembly, и закончим несколькими советами на случай, если вы захотите внедрить это у себя.
Как мы внедряли WebAssembly
Я работаю в компании Inetra, мы находимся в Новосибирске и делаем несколько собственных проектов. Один из них — ByteFog. Это технология peer-to-peer доставки видео пользователям. Нашими клиентами являются сервисы, которые раздают огромное количество видео. У них есть проблема: когда случается какое-то популярное событие, например, чья-то пресс-конференция или какое-то спортивное событие, как к нему не готовься, приходит куча клиентов, наваливается на сервер, и сервер грустит. Клиенты в это время получают очень плохое качество видео.
Но ведь все смотрят один и тот же контент. Давайте попросим соседние устройства пользователей поделиться кусочками видео, и тогда мы разгрузим сервер, сэкономим полосу, а пользователи получат видео в лучшем качестве. Вот эти облачка — наша технология, наш прокси-сервер ByteFog.
Мы должны быть установлены в каждом устройстве, которое умеет показывать видео, поэтому поддерживаем очень широкий спектр платформ: Windows, Linux, Android, iOS, Web, Tizen. Какой язык выбрать, чтобы иметь единую кодовую базу на всех этих платформах? Мы выбрали C++, потому что у него оказалась больше всего плюсов :-D Если серьёзнее, мы имеем хорошую экспертизу по C++, это действительно быстрый язык, и в портативности он уступает, наверное, только С.
У нас получилось довольно большое приложение (900 классов), но оно отлично работает. Под Windows и Linux мы компилируемся в нативный код. Под Android и iOS мы собираем библиотеку, которую подключаем к приложению. Про Tizen поговорим в другой раз, а вот на Web мы раньше работали как плагин к браузеру.
Это технология Netscape Plugin API. Как видно из названия, она довольно старая, а также имеет недостаток: дает очень широкий доступ к системе, так что пользовательский код может вызвать проблему с безопасностью. Наверное, поэтому в 2015 году Chrome отключил поддержку этой технологии, и следом все браузеры присоединились к этому флешмобу. Так мы остались без веб-версии почти на два года.
В 2017 году забрезжила новая надежда. Как вы догадываетесь, это WebAssembly. В итоге мы поставили перед собой задачу портировать наше приложение в браузер. Поскольку к весне уже появилась поддержка Firefox и Chrome, а к осени 2017 года подтянулись Edge и Safari.
Использовать готовый код нам было важно, так как у нас много бизнес-логики, которую не хотелось двоить, чтобы не удвоить количество багов. Берем компилятор Emscripten. Он делает то, что нам нужно, — компилирует плюсовое приложение в браузер и воссоздает среду, привычную нативному приложению в браузере. Можно сказать, что Emscripten — это такой Browserify для C++ кода. Также он позволяет пробрасывать объекты из C++ в JavaScript и наоборот. Первая наша мысль была: сейчас возьмем Emscripten, просто скомпилируем, и все заработает. Конечно же, вышло не так. С этого начался наш путь по граблям.
Первое, с чем мы столкнулись, — зависимости. В нашей кодовой базе было несколько библиотек. Сейчас их перечислять нет смысла, но для тех, кто понимает, у нас есть Boost. Это большая библиотека, которая позволяет писать кроссплатформенный код, но с ней очень сложно настроить компиляцию. Хотелось как можно меньше кода тащить в браузер.
Архитектура Bytefog
В итоге мы выделили ядро: можно сказать, что это прокси-сервер, в котором содержится основная бизнес-логика. Этот прокси-сервер берет данные по двум источникам. Первый и основной — это HTTP, то есть канал к серверу раздачи видео, второй — наша P2P сеть, то есть канал до другого такого же прокси у какого-то другого пользователя. Отдаем мы данные в первую очередь плееру, так как наша задача — показать качественный контент пользователю. Если остаются ресурсы, мы раздаем контент в P2P сеть, чтобы другие пользователи могли его скачать. Внутри находится умный кэш, который и делает всю магию.
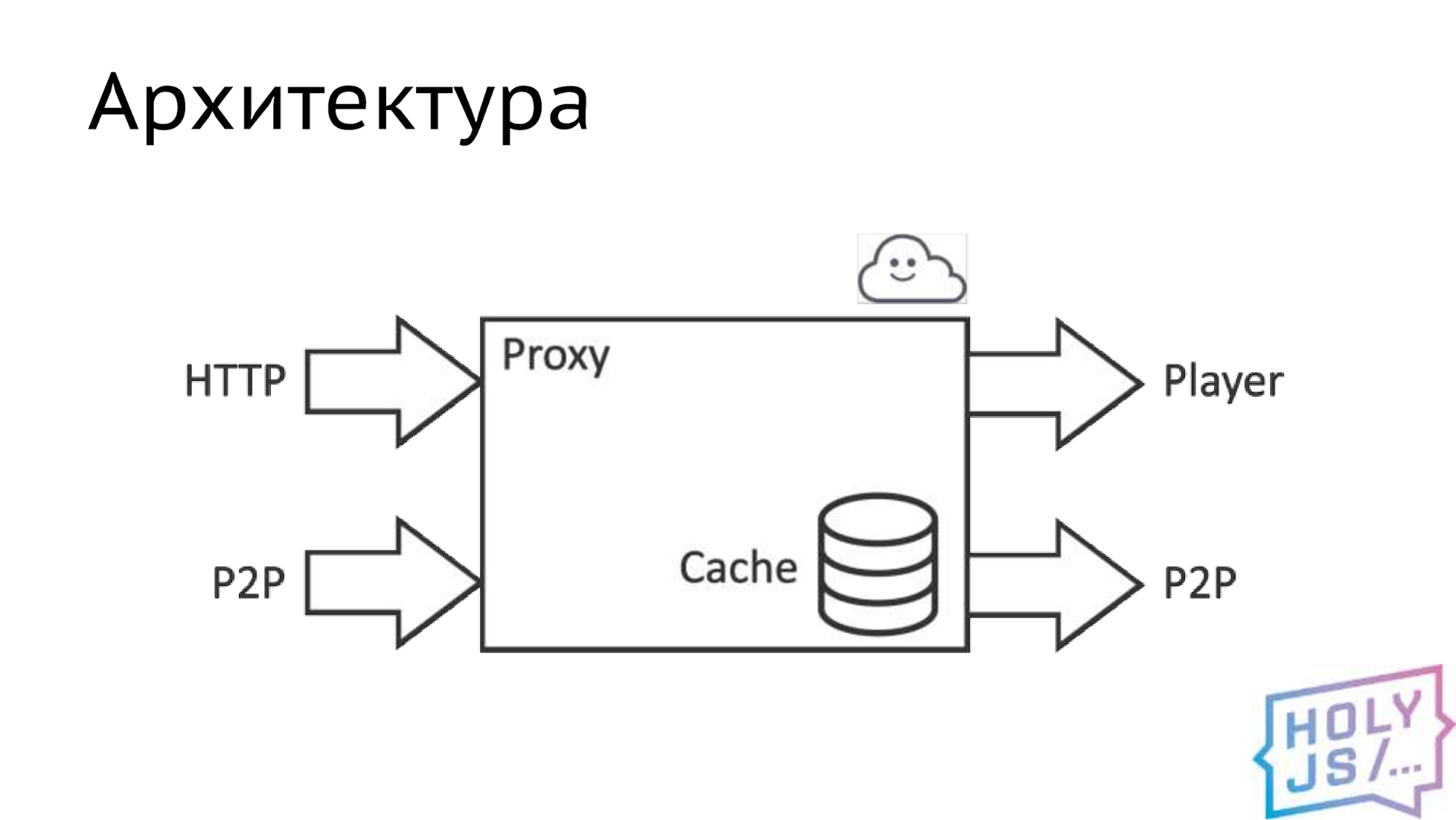
Скомпилировав это всё, мы столкнулись с тем, что WebAssembly выполняется в песочнице браузера. А значит, не может большего, чем дает JavaScript. В то время как нативные приложения используют много платформозависимых вещей, таких как файловая система, сеть или случайные числа. Все эти возможности придется реализовать на JavaScript с помощью того, что дает нам браузер. В этой табличке перечисленные достаточно очевидные замены.

Чтобы это стало возможным, необходимо в нативном приложении отпилить реализацию нативных возможностей и вставить там интерфейс, то есть провести некоторую границу. Затем вы реализуете это на JavaScript и оставляете нативную реализацию, а уже при сборке выбирается нужное. Итак, мы посмотрели на нашу архитектуру и нашли все места, где можно провести эту границу. Так совпало, что это транспортная подсистема.

Для каждого такого места мы определили спецификацию, то есть зафиксировали контракт: какие будут методы, какие у них будут параметры, какие типы данных. Как только вы это сделали, можно работать параллельно, каждый разработчик на своей стороне.
Что получилось в итоге? Основной канал доставки видео от провайдера мы заменили на обычный AJAX. К плееру мы выдаем данные через популярную библиотеку HLS.js, но есть принципиальная возможность интегрироваться с другими плеерами, если это будет нужно. Весь P2P-слой мы заменили на WebRTC.
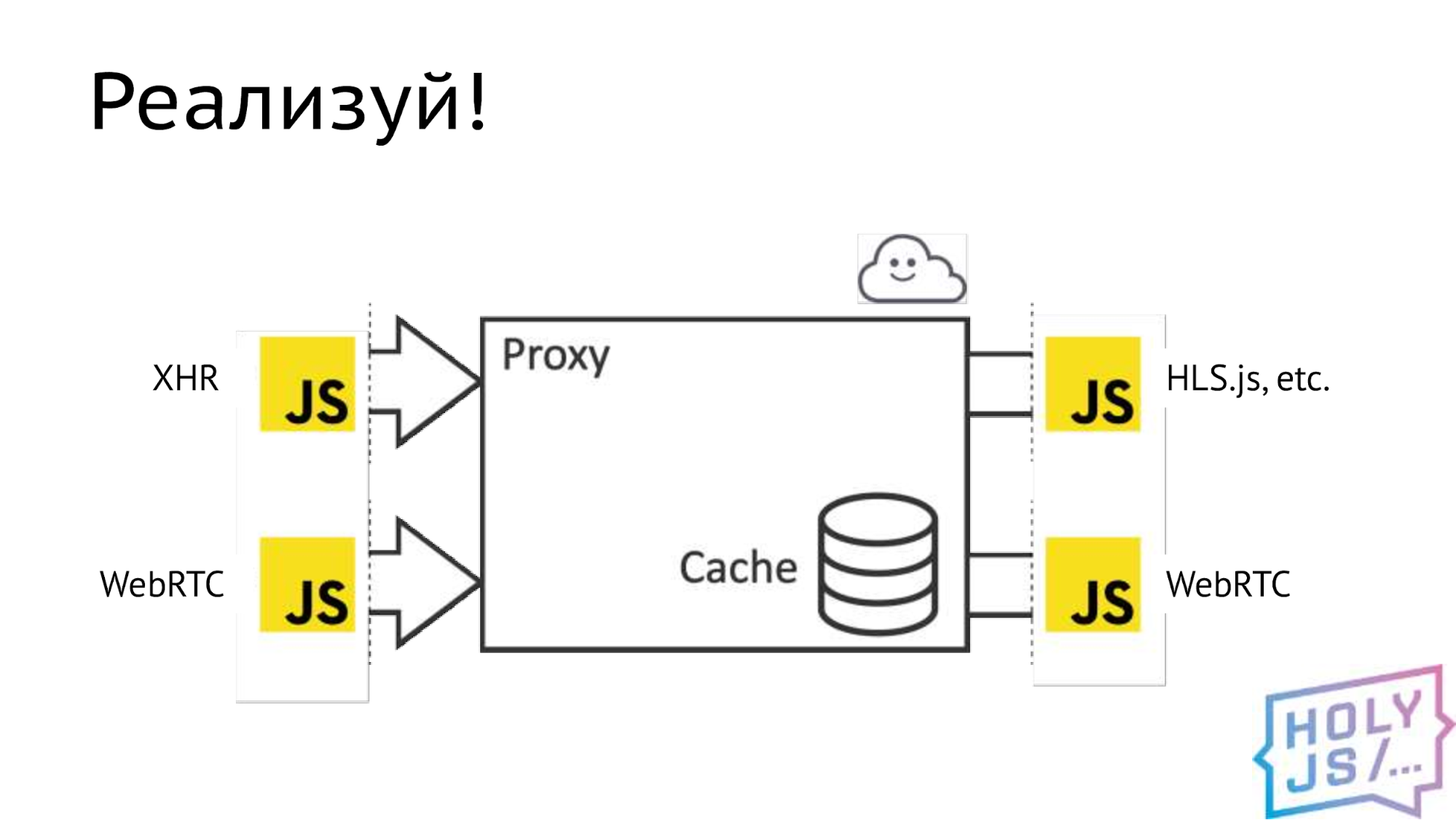
В результате компиляции получается несколько файлов. Самый главный — двоичный .wasm. В нем содержится скомпилированный байт-код, который браузер будет выполнять и в котором содержится все ваше наследство C++. Но сам по себе он не работает, необходим, так называемый «клеевой код», его также генерирует компилятор. Клеевой код занимается загрузкой двоичного файла, и оба этих файла вы выкладываете на продакшен. Для целей отладки можно сгенерировать текстовое представление ассемблера — .wast-файл и sourcemap. Нужно понимать, что они могут быть очень большого размера. В нашем случае достигали 100 мегабайт и более.
Собираем бандл
Рассмотрим клеевой код поближе. Это обычный старый-добрый ES5, собранный в один файл. Когда мы его подключаем на веб-страницу, у нас появляется глобальная переменная, в которой содержится весь наш инстанциированный wasm-модуль, который готов принимать запросы в свое API.
Но подключать отдельный файл — это достаточно серьезное усложнение для библиотеки, которую будут использовать пользователи. Мы хотели бы собрать все в единый бандл. Для этого мы используем Webpack и специальную опцию компиляции MODULARIZE.
Она оборачивает клеевой код в паттерн «Модуль», и мы можем подцепить его: импортировать или использовать require, если мы пишем на ES5, — Webpack спокойно понимает эту зависимость. Возникла проблема с Babel, — ему не понравился большой объем кода, но это ES5-код, его не нужно транспилировать, мы просто добавляем его в игнор.
В погоне за количеством файлов я решил использовать опцию SINGLE_FILE. Все двоичные файлы, которые получились при компиляции, она переводит в Base64-вид и заталкивает в клеевой код в виде строки. Звучит как отличная идея, но после этого бандл у нас стал размером 100 мегабайт. На таком объеме ни Webpack, ни Babel, ни даже браузер не работают. Да и вообще, не будем же мы заставлять пользователя грузить 100 мегабайт?!
Если задуматься, то эта опция не нужна. Клеевой код самостоятельно загружает двоичные файлы. Делает он это по HTTP, значит мы из коробки получаем кэширование, можем выставить любые заголовки, которые хотим, например, включить сжатие, а WebAssembly-файлы отлично сжимаются.
Но самая крутая технология — это потоковая компиляция. То есть WebAssembly-файл, пока скачивается с сервера, может уже компилироваться в браузере по мере поступления данных, и это очень ускоряет загрузку вашего приложения. Вообще вся технология WebAssembly имеет фокус на быстром старте большой кодовой базы.
Thenable
Другая проблема с модулем — то, что он является объектом Thenable, то есть имеет метод .then(). Эта функция позволяет навесить callback на момент старта модуля, и это очень удобно. Но хотелось бы, чтобы интерфейс соответствовал Promise. Thenable — это не Promise, но ничего страшного, обернем сами. Напишем такой простой код:
return new Promise((resolve, reject) => {
Module(config).then((module) => {
resolve(module);
});
});
Создаем Promise, стартуем наш модуль, и как callback вызываем функцию resolve и передаем туда тот модуль, который у нас инстанцировался. Все вроде бы очевидно, все прекрасно, запускаем — что-то не так, у нас завис браузер, у нас зависли DevTools, и у компьютера греется процессор. Мы ничего не понимаем — какая-то рекурсия или бесконечный цикл. Отлаживать это довольно сложно, и когда мы прервали работу JavaScript, мы оказались в функции Then в модуле Emscripten.
Module[‘then’] = function(func) {
if (Module[‘calledRun’]) {
func(Module);
} else {
Module[‘onRuntimeInitialized’] = function() {
func(Module);
};
};
return Module;
};
Давайте посмотрим на нее подробнее. Участок
Module[‘onRuntimeInitialized’] = function() {
func(Module);
};
отвечает за навешивание callback. Тут все понятно: асинхронная функция, которая вызывает наш callback. Все, как мы хотим. Есть другая часть этой функции.
if (Module[‘calledRun’]) {
func(Module);
Она вызывается, когда модуль уже стартовал. Тогда callback синхронно вызывается сразу же, и ему передается в параметр модуль. Это имитирует поведение Promise, и вроде бы это то, что мы ожидаем. Но что же тогда не так?
Если внимательно почитать документацию, оказывается, что есть очень тонкий момент про Promise. Когда мы резолвим Promise с помощью Thenable-объекта, браузер будет разворачивать значения из этого Thenable-объекта, и для этого он вызовет метод .then(). В итоге мы резолвим Promise, передаем ему модуль. Браузер спрашивает: Thenable ли это объект? Да, это Thenable-объект. Тогда у модуля вызывается функция .then(), и в качестве callback передается сама функция resolve.
Модуль проверяет, запущен ли он. Он уже запущен, поэтому callback вызывается сразу же, и ему передается снова этот же модуль. В качестве callback у нас функция resolve, и браузер спрашивает: это Thenable-объект? Да, это Thenable-объект. И все начинается снова. В результате мы впадаем в бесконечный цикл, из которого браузер не возвращается никогда.

Элегантного решения этой проблемы я не нашел. В результате я просто удаляю метод .then() перед resolve, и это работает.
Emscripten
Итак, модуль мы скомпилировали, JS собрали, но чего-то не хватает. Наверное, нам нужно сделать какую-то полезную работу. Для этого нужно передать данные и связать два мира — JS и C++. Как это сделать? Emscripten предоставляет целых три возможности:
- Первая — это функции ccall и cwrap. Чаще всего вы их встретите в каких-то туториалах по WebAssembly, но для реальной работы они не годятся, так как не поддерживают возможности C++.
- Вторая — это WebIDL Binder. Он уже поддерживает C++ функции, с ним уже можно работать. Это серьезный язык описания интерфейсов, которым пользуются, например, W3C для своей документации. Но мы не захотели нести его в свой проект и воспользовались третьей опцией
- Embind. Можно сказать, что это нативный способ связи объектов для Emscripten, он основан на шаблонах C++ и позволяет делать очень много вещей по пробросу разных сущностей из C++ в JS и обратно.
Embind позволяет:
- Вызывать из JavaScript-кода функции C++
- Создавать JS-объекты из C++ класса
- Из C++ кода обратиться к API браузера (если вы зачем-то этого хотите, можно, например, написать фронтенд-фреймворк целиком на C++).
- Главное для нас: реализовать на JavaScript интерфейс, описанный на C++.
Обмен данными
Последний пункт важен, так как это именно то действие, которое вы будете постоянно делать при портировании приложения. Поэтому я бы хотел остановиться на нем подробнее. Сейчас будет код на C++, но не пугайтесь, это почти как TypeScript :-D
Схема такая:

На стороне C++ есть ядро, которому мы хотим дать доступ, например, во внешнюю сеть — покачать видео. Раньше оно это делало с помощью нативных сокетов, был какой-то HTTP-клиент, который это делал, но в WebAssembly нет нативных сокетов. Нужно как-то выкручиваться, поэтому мы отрезаем старый HTTP-клиент, в это место вставляем интерфейс, и реализацию этого интерфейса делаем в JavaScript с помощью обычного AJAX, любым способом. После этого полученный объект мы передадим обратно в C++, где его будет использовать ядро.
Сделаем простейший HTTP-клиент, который может делать только get-запросы:
class HTTPClient {
public:
virtual std::string get(std::string url) = 0;
};
На вход он принимает строку с URL-адресом, который надо скачать, и на выход
строку с результатом запроса. В C++ строки могут иметь двоичные данные, поэтому для видео это подходит. Emscripten заставляет нас написать вот
такой страшный Wrapper:

В нем главное — две вещи — имя функции на стороне C ++ (я обозначил их зеленым цветом), и соответствующие им имена на стороне JavaScript, (их обозначил синим). В итоге мы пишем декларацию связи:

Она работает как кубики Lego, из которых мы её собираем. У нас есть класс, у этого класса есть метод, и мы хотим наследоваться от этого класса, чтобы реализовать интерфейс. Это все. Мы идем в JavaScript и наследуемся. Это можно сделать двумя путями. Первый — extend. Это очень похоже на старый добрый extend из Backbone.

В модуле содержится все, что накомпилировал Emscripten, и в нем есть свойство с экспортированным интерфейсом. Мы вызываем метод extend и передаем туда объект с реализацией этого метода, то есть в функции get будет реализован какой-то способ
получения информации с помощью AJAX.
На выходе extend дает нам обычный JavaScript-конструктор. Мы можем вызывать его сколько угодно раз и сгенерировать объекты в том количестве, которое нам необходимо. Но бывает ситуация, когда у нас есть один объект, и мы хотим его просто передать на сторону C++.

Для этого нужно как-то привязать этот объект к типу, который поймет C++. Это и делает функция implement. На выходе она дает не конструктор, а уже готовый к употреблению объект, наш клиент, который мы можем отдать обратно в C++. Сделать это можно, например, вот так:
var app = Module.makeApp(client, …)
Допустим, у нас есть фабрика, которая создает наше приложение, и в параметры она принимает свои зависимости, например, client и что-нибудь еще. Когда эта функция отработает, мы получим объект нашего приложения, который уже содержит API, которое нам нужно. Можно сделать наоборот:
val client = val::global(?client?);
client.call<std::string>(?get?, val(...) );
Прямо из C++ взять из глобальной области видимости браузера наш client. Причем на месте client может быть любое API браузера, начиная от консоли, заканчивая DOM API, WebRTC — всё, что вам заблагорассудится. Далее мы вызываем методы, которые есть у этого объекта, а все значения оборачиваем в магический класс val, который предоставляет нам Emscripten.
Ошибки биндинга
В целом это всё, но когда вы начнете разработку, вас подстерегают ошибки биндинга. Они выглядят как-то так:

Emscripten старается помогать нам и объяснять, что же происходит не так. Если это все просуммировать, то нужно следить, чтобы совпадали (легко опечататься и получить ошибку биндинга):
- Имена
- Типы
- Количество параметров
Синтаксис Embind непривычен не только для фронтендеров, но и для людей, которые занимаются C++. Это некий DSL, в котором легко сделать ошибку, нужно за этим следить. Говоря об интерфейсах, когда вы реализуете на JavaScript какой-то интерфейс, нужно, чтобы он точно соответствовал тому, что вы описали в своем контракте.
У нас произошел интересный случай. Мой коллега Юра, который занимался проектом со стороны C++, использовал Extend, чтобы проверять свои модули. У него они отлично работали, поэтому он их закоммитил и передал мне. Я использовал implement для интеграции этих модулей в JS-проект. И у меня они работать перестали. Когда мы разобрались, оказалось, что при биндинге в названиях функций получилась опечатка.
Как мы видим из названия, Extend — это расширение интерфейса, поэтому если вы где-то опечатались, Extend не выдаст ошибку, он решит, что вы просто добавили новый метод, и все в порядке.
То есть он скрывает ошибки биндинга до того момента, пока не будет вызван собственно метод. Я предлагаю использовать Implement во всех случаях, где он вам подходит, так как он сразу проверяет корректность проброшенного интерфейса. Но уж если вам нужен Extend, нужно обязательно покрыть тестами вызов каждого метода, чтобы не напортачить.
Extend и ES6
Другая проблема с Extend в том, что он не поддерживает ES6-классы. Когда вы наследуетесь объектом, порожденным от ES6-класса, Extend ожидает, что в нём все свойства перечислимые, но с ES6 это не так. Методы находятся в прототипе, и у них enumerable: false. Я использую вот такой костыль, в котором пробегаюсь по прототипу и включаю enumerable: true:
function enumerateProto(obj) {
Object.getOwnPropertyNames(obj.prototype)
.forEach(prop =>
Object.defineProperty(obj.prototype, prop,
{enumerable: true})
)
}
Надеюсь, когда-нибудь удастся избавиться от него, так как в сообществе Emscripten идут разговоры об улучшении поддержки ES6.
Оперативная память
Говоря про C++, нельзя не затронуть память. Когда мы проверяли всё на видео SD-качества, у нас всё было отлично, работало просто идеально! Как только мы сделали FullHD-тест — ошибка нехватки памяти. Не беда, есть опция TOTAL_MEMORY, которая задает стартовое значение памяти для модуля. Сделали полгигабайта, все хорошо, но как-то это негуманно для пользователей, ведь память мы резервируем у всех, но не все имеют подписку на FullHD-контент.
Есть другая опция — ALLOW_MEMORY_GROWTH. Она позволяет растить память
постепенно по мере надобности. Работает это так: Emscripten по умолчанию даёт модулю для работы 16 мегабайт. Когда вы все их использовали, происходит выделение нового куска памяти. Туда копируются все старые данные, и у вас еще остается столько же места для новых. Так происходит до тех пор, пока не достигнете 4 ГБ.
Допустим, вы выделили 256 мегабайт памяти, но вы точно знаете, вы посчитали, что вашему приложению достаточно 192. Тогда остальная память будет использована неэффективно. Вы ее выделили, забрали у пользователя, но ничего с ней не делаете. Хотелось бы как-то этого избежать. Есть небольшой трюк: мы начинаем работу с увеличенной в полтора раза памятью. Тогда на третьем шаге мы достигаем 192 мегабайт, и это именно то, что нам нужно. Мы сократили потребление памяти на тот остаток и сэкономили лишнее выделение памяти, а чем дальше, тем они занимают больше времени. Поэтому я рекомендую использовать обе эти опции совместно.
Dependency Injection
Казалось бы это все, но дальше грабли пошли побольше. Есть проблема с Dependency Injection. Пишем простейший класс, в котором нужна зависимость.
class App {
constructor(httpClient) {
this.httpClient = httpClient
}
}
Например, наш HTTP-клиент мы передаем в наше приложение. Сохраняем в свойство класса. Казалось бы, все будет работать хорошо.
Module.App.extend(
?App?,
new App(client)
)
Мы наследуемся от интерфейса на C++, сначала создаем наш объект, передаем ему зависимость, а потом происходит наследование. В момент наследования Emscripten делает что-то невероятное с объектом. Проще всего думать, что он убивает старый объект, создает новый на основе своего шаблона и перетаскивает туда все публичные методы. Но при этом состояние объекта теряется, и вы получаете объект, который не сформирован и не работает правильно. Решить эту проблему довольно просто. Надо использовать конструктор, который работает после стадии наследования.
class App {
_construct(httpClient) {
this.httpClient = httpClient
this._parent._construct.call(this)
}
}
Мы делаем практически то же самое: сохраняем зависимость в поле объекта, но это уже тот объект, который получился после наследования. Нужно не забыть пробросить вызов конструктора в родительский объект, который находится на стороне C++. Последняя строчка — это аналог метода super() в ES6. Вот так происходит наследование в этом случае:
const appConstr = Module.App.extend(
?App?,
new App()
)
const app = new appConstr(client)
Cначала мы наследуемся, потом создаем новый объект, в который уже передаем зависимость, и это работает.
Хитрость с указателем
Другая проблема — передача объектов по указателю из C++ в JavaScript. Мы уже делали HTTP-клиент. Для упрощения мы упустили одну важную деталь.
std::string get(std::string url)
Метод возвращает значение сразу, то есть получается, что запрос должен быть синхронным. Но ведь AJAX-запросы на то и AJAX, что они асинхронные, поэтому в реальной жизни метод будет возвращать либо ничего, либо мы можем вернуть ID запроса. А вот чтобы было кому вернуть ответ, вторым параметром мы передаем listener, в котором будут callback-и со стороны C++.
void get(std::string url, Listener listener)
В JS это выглядит так:
function get(url, listener) {
fetch(url).then(result) => {
listener.onResult(result)
})
}
Мы имеем функцию get, которая принимает этот объект listener. Мы запускаем скачивание файла и вешаем callback. Когда файл скачался, мы дергаем у listener нужную функцию и передаем в нее результат.
Казалось бы, план хороший, но когда функция get завершится, будут уничтожены все локальные переменные, а вместе с ними и параметры функции, то есть указатель будет уничтожен, а runtime emscripten уничтожит объект на стороне C++.
В итоге, когда дело дойдет до вызова строчки listener.onResult(result), listener уже не будет существовать, и при обращении к нему возникнет ошибка доступа к памяти, которая приведет к краху приложения.
Хотелось бы этого избежать, и решение есть, но на то, чтобы найти его, ушло несколько недель.
function get(url, listener) {
const listenerCopy = listener.clone()
fetch(url).then((result) => {
listenerCopy.onResult(result)
listenerCopy.delete()
})
}
Оказывается, есть метод клонирования указателя. Почему-то он не документирован, но отлично работает, и позволяет увеличить счетчик ссылок в указателе Emscripten. Это позволяет подвесить его в замыкании, и тогда, когда мы запустим наш callback, наш listener будет доступен по этому указателю и можно работать так, как нам нужно.
Самое важное — не забыть удалить этот указатель, иначе это приведёт к ошибке утечки памяти, а это очень плохо.
Быстрая запись в память
Когда мы качаем видео — это относительно большие объемы информации, и хотелось бы сократить количество копирования данных туда-сюда, чтобы сэкономить и память, и время. Есть один трюк, как записать большой объем информации напрямую в память WebAssembly со стороны JavaScript.
var newData = new Uint8Array(…);
var size = newData.byteLength;
var ptr = Module._malloc(size);
var memory = new Uint8Array(
Module.buffer, ptr, size
);
memory.set(newData);
newData — это наши данные в виде типизированного массива. Мы можем взять его длину и запросить выделение памяти нужного нам размера у модуля WebAssembly. Функция malloc вернет нам указатель, который является просто индексом массива, в котором содержится вся память WebAssembly. Со стороны JavaScript он выглядит просто как ArrayBuffer.
Следующим действием мы прорубуем окошко в этот ArrayBuffer нужного размера с определённого места и копируем туда наши данные. Несмотря на то, что операция set имеет семантику копирования, когда я смотрел на этот участок в профайлере, я не увидел долгого процесса. Я думаю, что браузер оптимизирует эту операцию с помощью move-семантики, то есть передает владение памятью от одного объекта другому.
И в нашем приложении мы также основываемся на move-семантике, чтобы экономить копирования памяти.
AdBlock
Интересная проблема, скорее, на сдачу, с Adblock. Оказывается в России все популярные блокировщики получают подписку на список RU Adlist, и в нем есть такое прекрасное правило, которое запрещает загрузку WebAssembly с сайтов третьей стороны. Например, с CDN.

Выход — не использовать CDN, а хранить все на своем домене (нам это не подходит). Либо переименовать .wasm-файл, чтобы он не подходил под это правило. Можно ещё пойти на форум этих товарищей и попытаться убедить их убрать это правило. Думаю, они оправдывают себя тем, что они борются с майнерами таким образом, правда, я не знаю, почему майнеры не могут догадаться переименовать файл.
Продакшен
В итоге, мы вышли в продакшен. Да, это было нелегко, это заняло 8 месяцев и хочется спросить себя, а стоило ли оно того. На мой взгляд — стоило:
Не нужно устанавливать
Мы получили то, что наш код доставляется пользователю без установки каких-либо программ. Когда у нас был плагин к браузеру, пользователь должен был его скачать и установить, и это огромный фильтр для распространения технологии. Сейчас пользователь просто смотрит видео на сайте и даже не понимает, что под капотом работает целая машинерия, и что там всё сложно. Браузер просто скачивает дополнительный файл с кодом, как картинку или .css.
Единая кодовая база и отладка на разных платформах
При этом нам удалось сохранить нашу единую кодовую базу. Мы можем один и тот же код крутить на разных платформах и уже неоднократно бывало, что баги, которые были незаметны на одной из платформ проявились на другой. И, таким образом, мы можем разными инструментами на разных платформах выявлять скрытые баги.
Быстрый релиз
Мы получили быстрый релиз, так как можем релизиться как простое web-приложение и с каждым новым релизом обновлять C++ код. Это не сравнится с тем, как релизить новые плагины, мобильное приложение или SmartTV-приложение. Релиз зависит только от нас: когда захотим, тогда он и выйдет.
Быстрая обратная связь
И это означает быструю обратную связь: если что-то идет не так, мы в течение дня можем узнать, что есть проблема и отреагировать на неё.
Я считаю, что все эти проблемы стоили этих плюсов. Не у всех есть C++ приложение но, если оно у вас есть, и вы хотите, чтобы оно было в браузере — WebAssembly для вас стопроцентный use case.
Где применить
Не все пишут на С++. Но не только С++ доступен для WebAssembly. Да, это исторически самая первая платформа, которая была доступна ещё в asm.js — ранней технологии Mozilla. Кстати, поэтому она имеет довольно хорошие инструменты, т.к. они старше самой технологии.
Rust
Новый язык Rust, который также разрабатывает Mozilla, сейчас догоняет и перегоняет С++ в отношении инструментов. Все идет к тому, что они сделают самый классный процесс разработки под WebAssembly.
Lua, Perl, Python, PHP, etc.
Почти все языки, которые интерпретируются, уже тоже доступны в WebAssembly, так как их интерпретаторы написаны на С++, их просто скомпилировали в WebAssembly и теперь можно крутить PHP в браузере.
Go
В версии 1.11 они сделали бета-версию компиляции в WebAssembly, в 2.0 обещают релизную поддержку. У них поддержка появилась позже, так как WebAssembly не поддерживает garbage collector, а Go — язык с управляемой памятью. Поэтому им пришлось затаскивать свой garbage collector под WebAssembly.
Kotlin/Native
Примерно такая же история с Kotlin. Их компилятор имеет экспериментальную поддержку, но им также придется что-то сделать с garbage collector. Я пока не знаю, какой там статус.
3D-графика
Что ещё можно придумать? Первое, что вертится на языке — 3D-приложения. И, действительно, исторически asm.js и WebAssembly начались с портирования игр в браузеры. И неудивительно, что сейчас все популярные движки имеют экспорт в WebAssembly.

Обработка данных локально
Можно ещё придумать обработку данных пользователя прямо у него в браузере, на его компьютере: взять загруженное изображение или с камеры, записать звук, обработать видео. Прочитать загруженный пользователем архив, или собрать его самостоятельно из пачки файлов и загрузить на сервер одним запросом.
Нейронные сети
На этой картинке изображены практически все архитектуры нейронных сетей. И, действительно, вы можете взять свою нейронную сеть, обучить и отдать на клиента, чтобы она обрабатывала живой поток с видеокамеры или микрофона. Или, например, отслеживать передвижение мышки пользователя и сделать управление жестами; распознавание лиц — возможности почти безграничны.
Например, кусочек Google Chrome, который отвечает за определение языка текста, уже доступен как WebAssembly-библиотека. Её можно подключить как npm-модуль и всё, вы используете Wasm, но работаете с обычным JS. Вы не связываетесь с нейронными сетями, С++ или чем-то ещё — всё доступно из коробки.
Есть популярная библиотека проверки орфографии HunSpell — просто ставите и используете как Wasm модуль.
Криптография
Ну и первое правило криптографии — «Не пишите свою криптографию». Если хотите подписывать данные пользователя, что-то шифровать и передавать в таком виде на сервер, генерировать устойчивые пароли или нужен ГОСТ — подключите OpenSSL. Уже есть инструкция как скомпилировать под WebAssembly. OpenSSL — это надёжный код, проверенный тысячами приложений, не нужно ничего изобретать.
Вынос вычислений с сервера
Классный use case есть на сайте wotinspector.com. Это сервис для игроков World of Tanks. Вы можете загрузить свой реплей, проанализировать его, соберется статистика по игре, нарисуется красивая карта, в общем, для профессиональных игроков очень полезный сервис.
Одна проблема — анализ такого реплея занимает много ресурсов. Если бы это происходило на сервере, наверняка это был бы закрытый платный сервис, доступный не всем. Но автор этого сервиса, Андрей Карпушин, написал бизнес-логику на С++, скомпилировал её в WebAssembly, и теперь пользователь может запустить обработку прямо у себя в браузере (а на сервер отправить, чтобы другие пользователи также получили к ним доступ).
Это интересный кейс с точки зрения монетизации сайта. Вместо того, чтобы брать деньги с пользователей, мы используем ресурсы их компьютера. Это похоже на монетизацию с помощью майнера. Но в отличие от майнера, который просто жжёт электроэнергию пользователей, а взамен приносит авторам сайта копейки, мы делаем сервис, который производит реально нужную пользователю работу. То есть пользователь согласен делиться с нами ресурсами. Поэтому эта схема работает.
Библиотеки
Также в мире существует куча библиотек, написанных за многолетнюю историю на С, С++. Например, проект FFmpeg, который является лидером по обработке видео. Многие пользуются программами для обработки видео, где внутри ffmpeg. И вот его можно запустить в браузере и кодировать видео. Это будет долго и медленно, да, но если вы делаете сервис, который генерирует аватарки или трехсекундные видеоролики, то ресурсов браузера будет достаточно.

Тоже самое с аудио — можно записывать в сжатый формат и отправлять на сервер уже маленькие файлики. И библиотека OpenCV — лидер по машинному зрению, доступна в WebAssembly, можно делать распознавание лиц и управление жестами рук. Можно работать с PDF. Можно использовать файловую базу данных SQLite, которая поддерживает настоящий SQL. Портирование SQLite под WebAssembly сделал автор Emscripten, он наверняка тестировал компилятор на нём.
Node.js
Не только браузер получает бонусы от WebAssembly, также можно использовать Node.js. Наверное, все знают Sass — препроцессор css. Он был написан на Ruby, а затем для ускорения переписан на С++ (проект libsass). Но никто не хочет запускать отдельную программу для обработки исходников, хочется встроиться в процесс сборки бандла Webpack’ом, а для этого нужен модуль для Node.js. Проект node-sass решает эту задачу, является JS-обёрткой для этой библиотеки.
Библиотека нативная, это значит мы должны компилировать её под ту платформу, под которой пользователь будет её запускать. И это приводит нас к матрице версий. Эти столбики нужно перемножить:

Это приводит к тому, что для одного релиза node-sass нужно сделать около 100 компиляций под каждую комбинацию из таблицы. Потом всё это нужно хранить, а это десятки мегабайт файлов на каждый (даже минорный) релиз. Как WebAssembly решает эту проблему: он сворачивает всю таблицу в один файл, потому что исполняемый файл WebAssembly не зависит от платформы.
Достаточно будет один раз скомпилировать код и загружать только один файл на все платформы независимо от архитектуры или версии Node. Такой проект уже есть, портированием под WebAssembly уже занимаются в проекте libsass-asm. Работа ведётся недавно, и проекту очень нужны помощники для работы. Это отличный шанс попрактиковаться с WebAssembly на реальном проекте…
Ускорение приложений
Есть популярное приложение Figma — редактор графики для web-дизайнеров. Это в какой-то мере аналог Sketch, который работает на всех платформах, потому что запускается в браузере. Он написана на С++ (о чем мало кто знает), и там изначально использовали asm.js. Приложение очень большое, поэтому стартовало не быстро.
Когда появился WebAssembly, разработчики перекомпилировали свои исходники, и старт приложения ускорился в 3 раза. Это серьезное улучшение для редактора, который должен быть готов к работе как можно быстрее.
Другое знакомое всем приложение Visual Studio Code, несмотря на то, что работает в Electron, использует нативные модули для самых критичных участков кода, поэтому у них такая же проблема с огромным количеством версий, как у Node-sass. Пожалуй, разработчики контролируют только версию Node, но для поддержки платформ ОС и архитектур им приходится пересобирать эти модули. Поэтому, я уверен, не за горами тот день, когда они тоже перейдут на WebAssembly.
Портирование приложений в браузер
Но самый крутой пример портирования кодовой базы — AutoCAD. Софту уже 30 лет, он написан на С++, и это огромная кодовая база. Продукт очень популярен в среде проектировщиков, чьи привычки давно устоялись, поэтому команде разработчиков пришлось бы совершить очень много работы по переносу всей накопившейся бизнес-логики на JavaScript, при портировании в браузер, что делало эту затею почти безнадёжной. Но теперь благодаря WebAssembly AutoCAD доступен как веб-сервис, где вы можете за 5 минут зарегистрироваться и начать им пользоваться.
Есть прикольная демка, которую сделал Фабрис Беллар, уникальный, по моему мнению, программист, поскольку он сделал много настолько популярных проектов, каких обычный программист делает, пожалуй, один за свою жизнь. Я упоминал FFMpeg — это его проект, а другая его разработка — QEMU. Возможно, мало кто о нем слышал, но на нем основана система виртуализации KVM, которая уж точно является лидером в своей области.

Беллард с 2011 года поддерживает порт QEMU для браузера. Это значит, что вы можете запустить любую систему с помощью эмулятора напрямую в своем браузере. В общем, Linux с консолью, настоящим Linux-ядром, работающим в браузере без сервера, какой-то дополнительной связи.
Можно отключить интернет, и он будет работать. Там есть bash, можно делать всё то, что и в обычном Linux. Есть и другая демка — с GUI. В ней уже можно запустить настоящий браузер. К сожалению, в демке нет сети, и не получится открыть в ней саму себя…
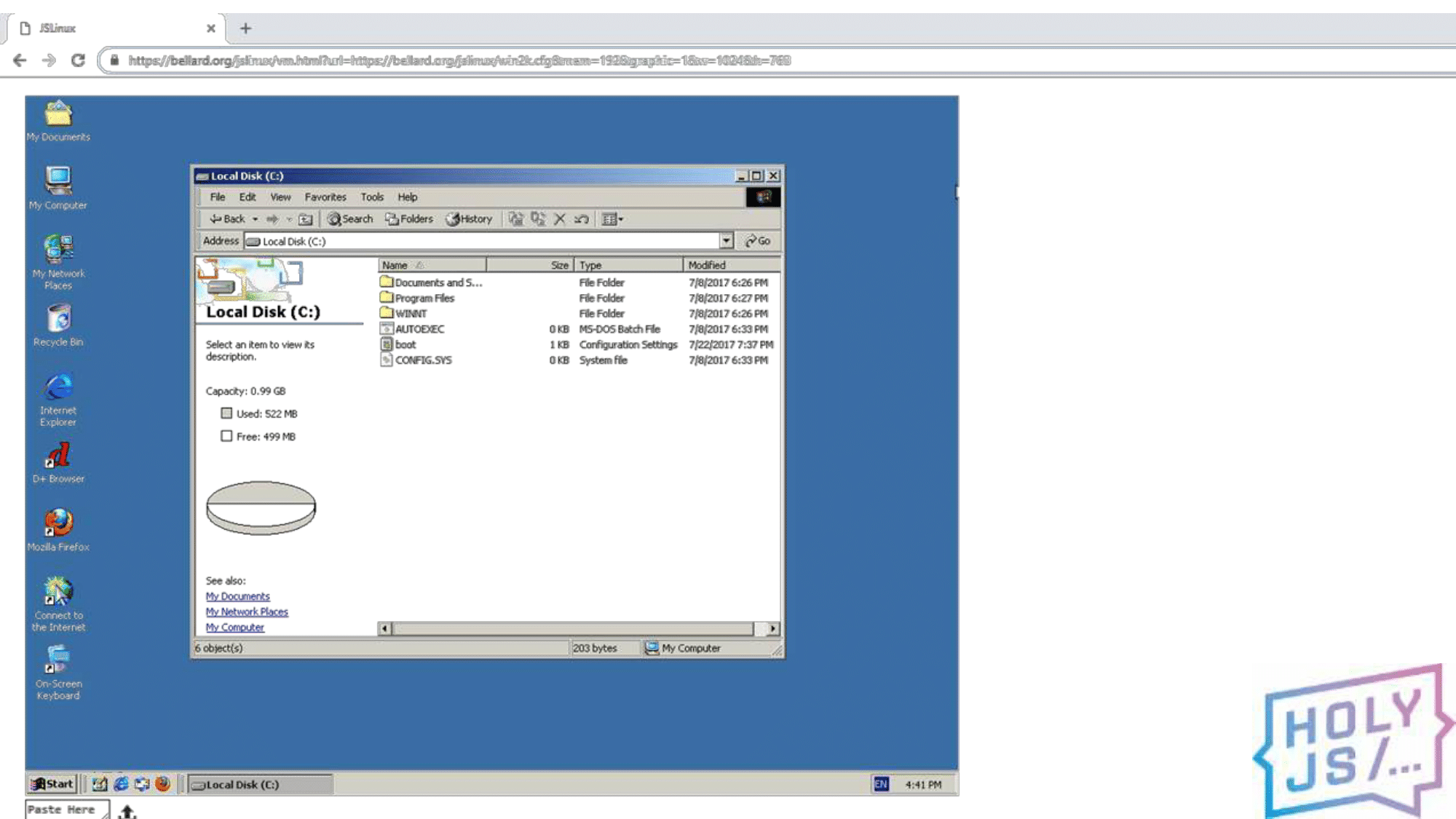
И, чтобы уж точно вас убедить, покажу что-то невероятное. Это Windows 2000, та самая, что была 18 лет назад, только сейчас она работает в вашем браузере. Раньше нужен был целый компьютер, а теперь достаточно просто Chrome (или FireFox).
Как вы видите, применений WebAssembly масса, я перечислил только то, что нашёл сам, а у вас возникнут новые идеи, и вы сможете их реализовать.
Как это внедрить у себя
Я хочу дать несколько советов для тех, кто задумает портировать своё приложение под WebAssembly. Первое, с чего стоит начать — с команды, конечно же. Минимальная команда — два человека, один со стороны нативных технологий и фронтендер.
Так бывает, что прикладные программисты на C++ не очень хорошо ориентируются в web-технологиях. Поэтому наша задача, как фронтендеров, если мы оказываемся в таком проекте — взять на себя эту часть работы. Но идеальная команда — те люди, кто интересуются не только своей платформой, но и хотят разобраться в той, что по другую сторону компилятора.
По счастью, в нашем проекте вышло именно так. Мой коллега Юра, большой специалист по C++, как выяснилось давно хотел изучить JavaScript, и книжка Флэнагана ему в этом очень помогла. Я же взял томик Страуструпа, и с Юриной помощью начал вникать в азы C++. В итоге за время проекта мы много рассказывали друг другу о своих основных языках, и нашли удивительно много общего у JS и C++, каким бы странным это ни казалось.
И если у вас подберётся именно такая команда — это будет идеально.
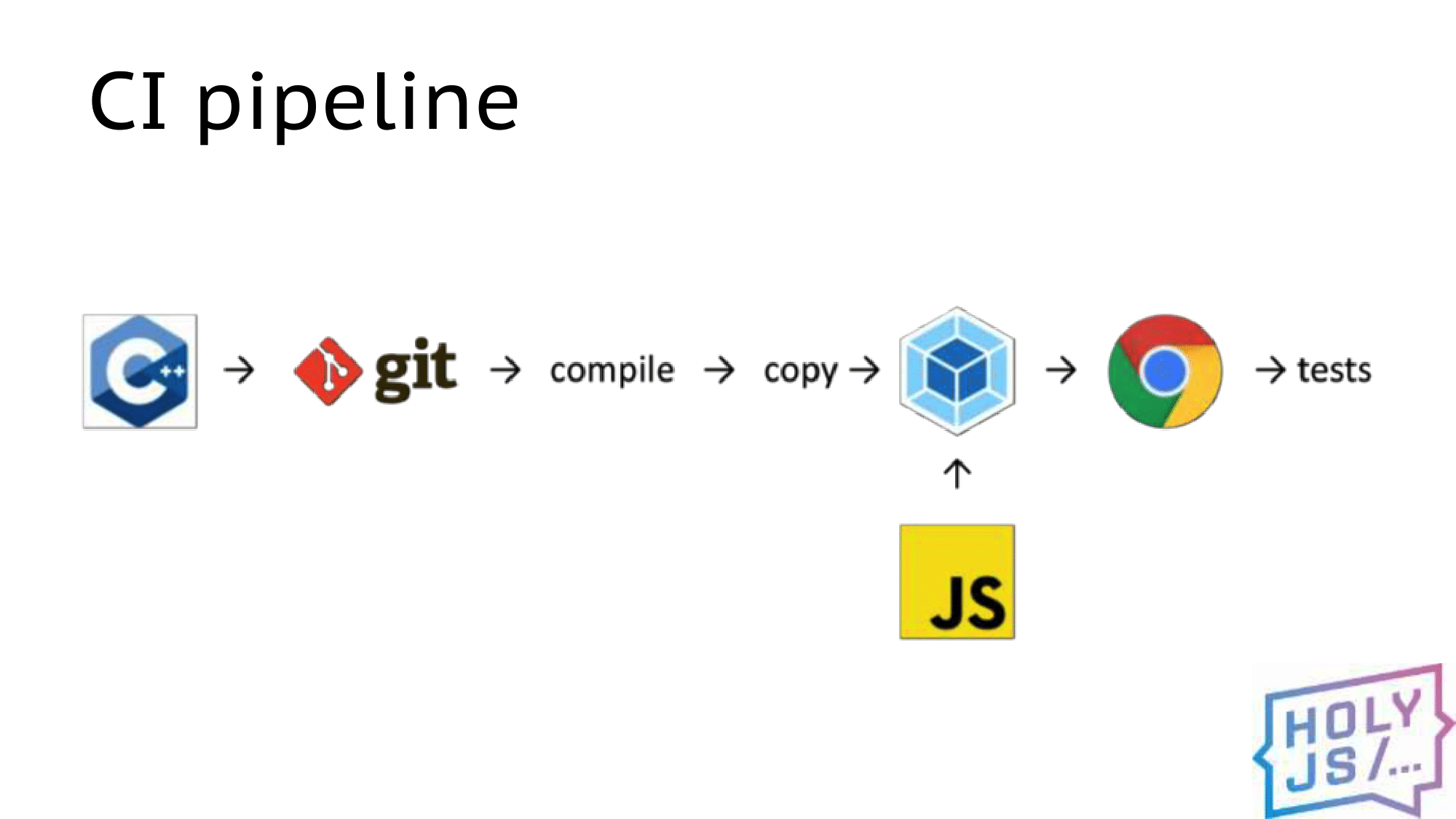
CI Pipeline
Как выглядел наш ежедневный процесс разработки? Мы вынесли все JS-артефакты в отдельный репозиторий, чтобы было удобнее настроить там сборку через Webpack. Когда появляются изменения в нативном коде, мы подтягиваем их, компилируем (порой это занимает больше всего времени), и результат компиляции копируется в проект JS. Дальше его подхватывает webpack в режиме watch, собирает бандл, и мы можем запускаем приложение в браузере или прогонять тесты.
Отладка
Конечно же, при разработке нам важна отладка. С этим, к сожалению, пока не очень хорошо.
Нужно в Chrome включить эксперименты DevTools, и мы увидим на закладке Sources папку с wasm-юнитами. Мы видим точки останова (можем остановить браузер в каком-то месте), но, к сожалению, код видим в текстовом представлении ассемблера.
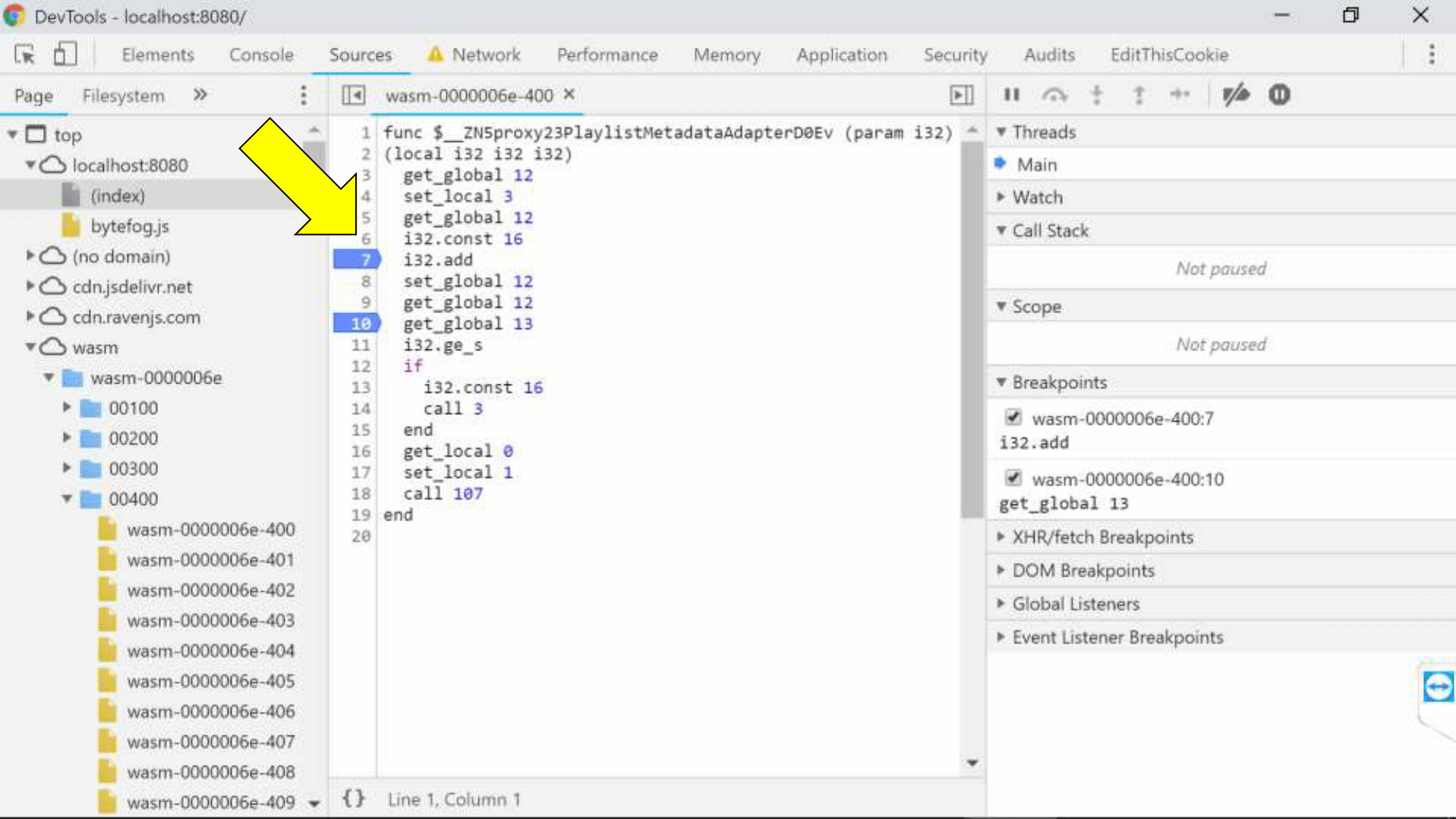
Хотя наш архитектор Коля, когда в первый раз посмотрел на эту картину, пробежался глазами по листингу и сказал: «Смотрите, да это же стековая машина, вот, тут с памятью работаем, тут арифметика, всё ж понятно!». В общем, Коля умеет писать под embedded-системы, а мы не умеем, и хотели бы какой-то явной привязки к исходному коду.
Есть небольшой трюк: на максимальном уровне отладки -g4 в wast-файле появляются дополнительные комментарии, и выглядит это вот так.
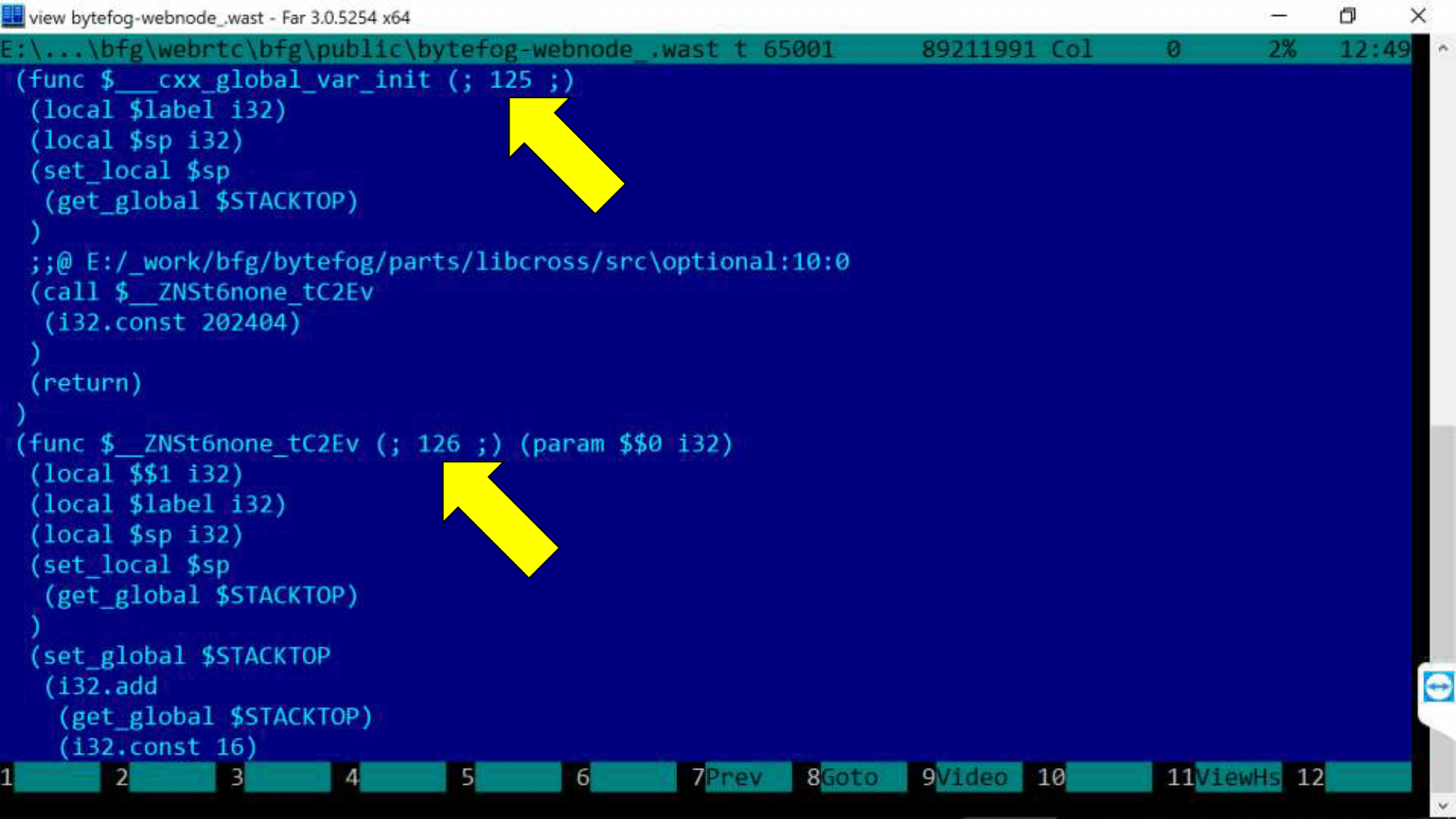
Вам нужен редактор, который сможет открыть файл размером 100 мегабайт (мы выбрали FAR). Цифры — номера модулей, которые мы уже видели в консоли Chrome. E:/_work/bfg/bytefrog/… — ссылка на исходный код. С этим можно жить, но хотелось бы увидеть настоящий С++ код прямо в отладчике браузера. И это звучит, как задача для SourceMap!
SourceMap
К сожалению, с нимипока есть проблемы.
- Работает только в Firefox.
- --sourcemap-base=http://localhost опцией указываем, что надо сгенерировать SourceMap и адрес веб-сервера, где будут храниться исходники.
- Доступ к исходникам по HTTP.
- Пути к файлам исходников должны быть относительные.
- На Windows есть проблема с «:» в путях. Все пути обрезаются до двоеточия.
Последние два пункта затронули нас. CMake при сборке приводит все пути к абсолютному виду, в результате файлы невозможно найти по такому URL на веб-сервере. Мы решили это так: предобрабатываем wast-файл и все пути приводим к относительному виду, убирая заодно и двоеточия. Думаю, вы с таким не столкнётесь.
В итоге, выглядит это следующим образом:

Код С++ в отладчике браузера. Теперь мы видели всё! Слева дерево исходников, есть точки останова, видим stack trace, который нас привел к этой точке. К сожалению, если дотронуться до любого wasm-вызова в stack trace, провалимся в ассемблер, это досадный баг, который, думаю, будет исправен.
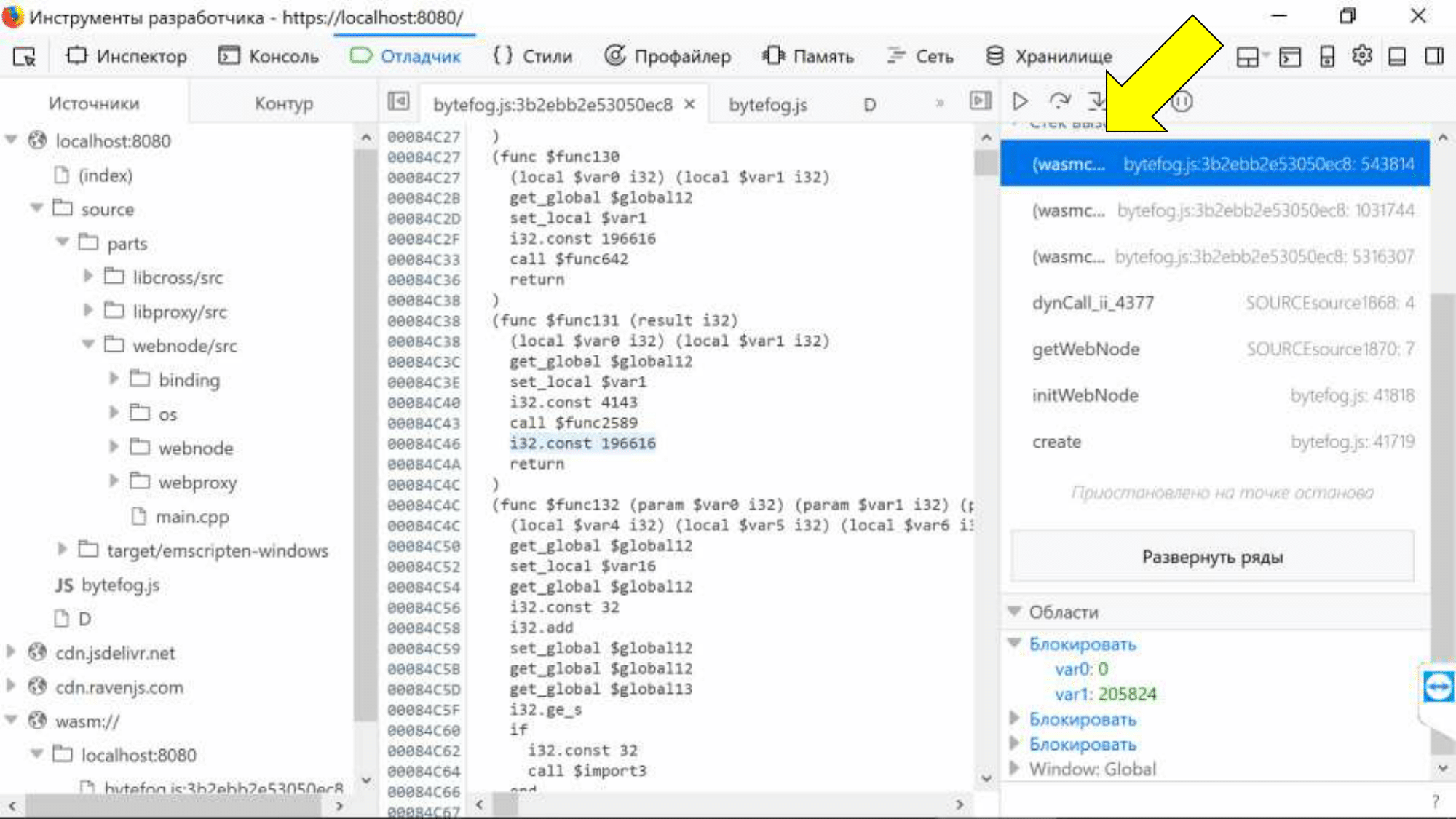
К сожалению, другой баг не будет исправлен — SourceMap принципиально не поддерживает связь переменных. Мы видим, что локальные переменные потеряли не только свои имена, но и свои типы. Их значения представлены в виде знакового целого и мы не узнаем, что там было на самом деле.
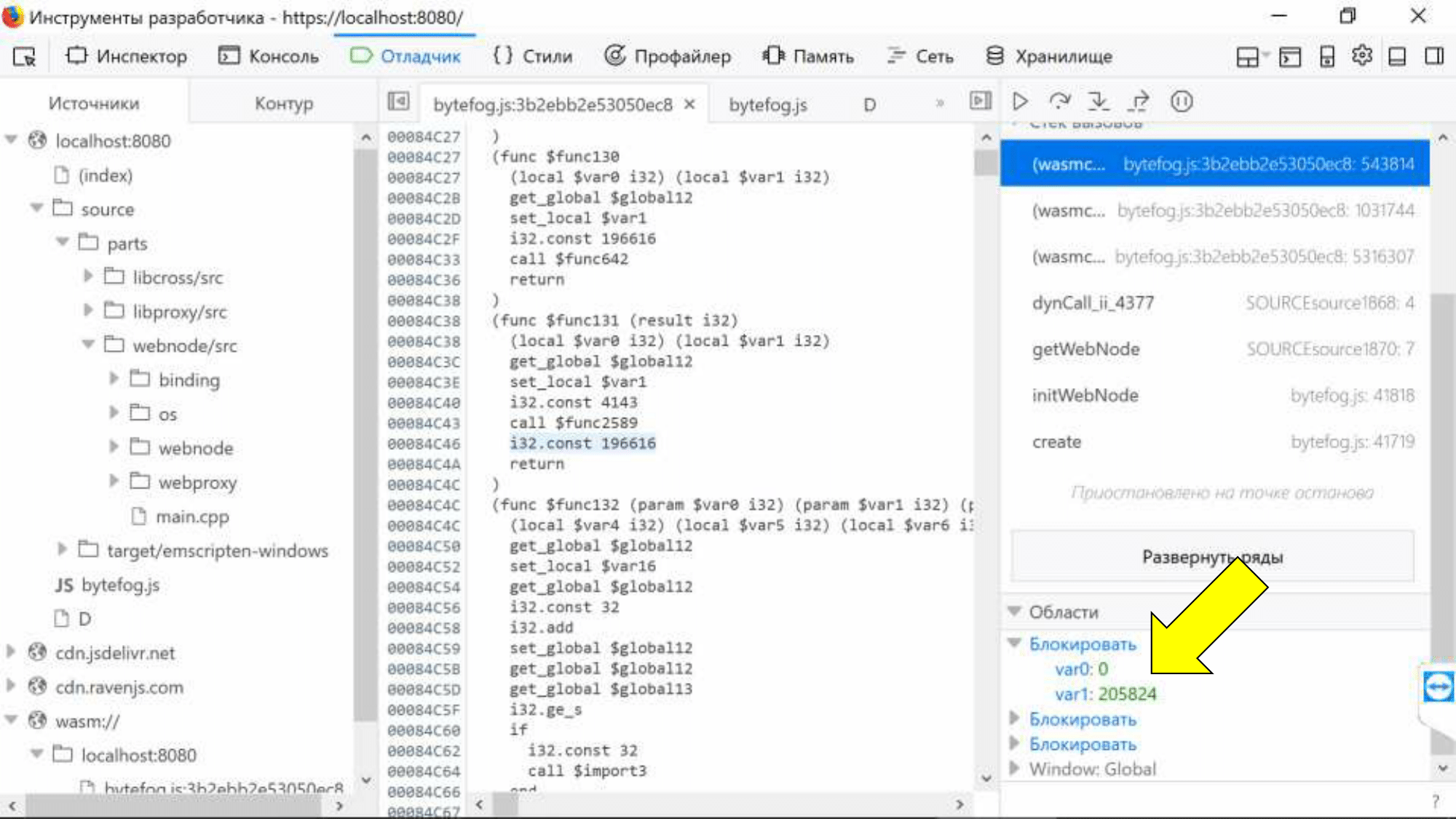
Но мы можем привязать их к конкретному месту ассемблера по сгенерированному имени «var0».
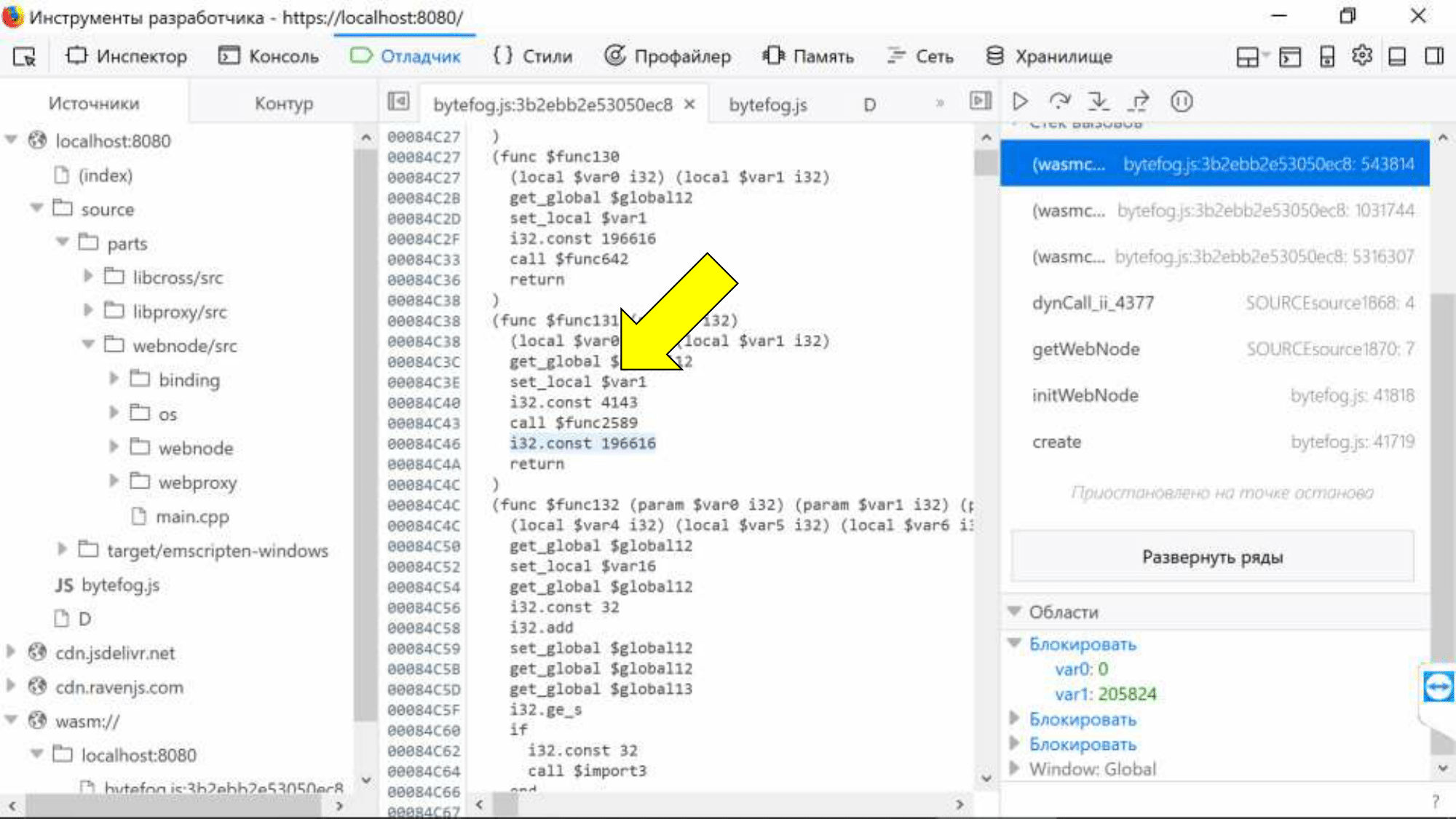
Конечно, хотелось бы просто навести мышью на имя переменной и увидеть значение. Возможно, в будущем придумают новый формат SourceMap, который позволит биндить не только кодовую базу, но и переменные.
Профайлер
Также можно взглянуть на профайлер. Он работает и в Chrome, и в Firefox. В Firefox получше — он «разматывает» имена, и их видно так, как они есть в исходном коде.
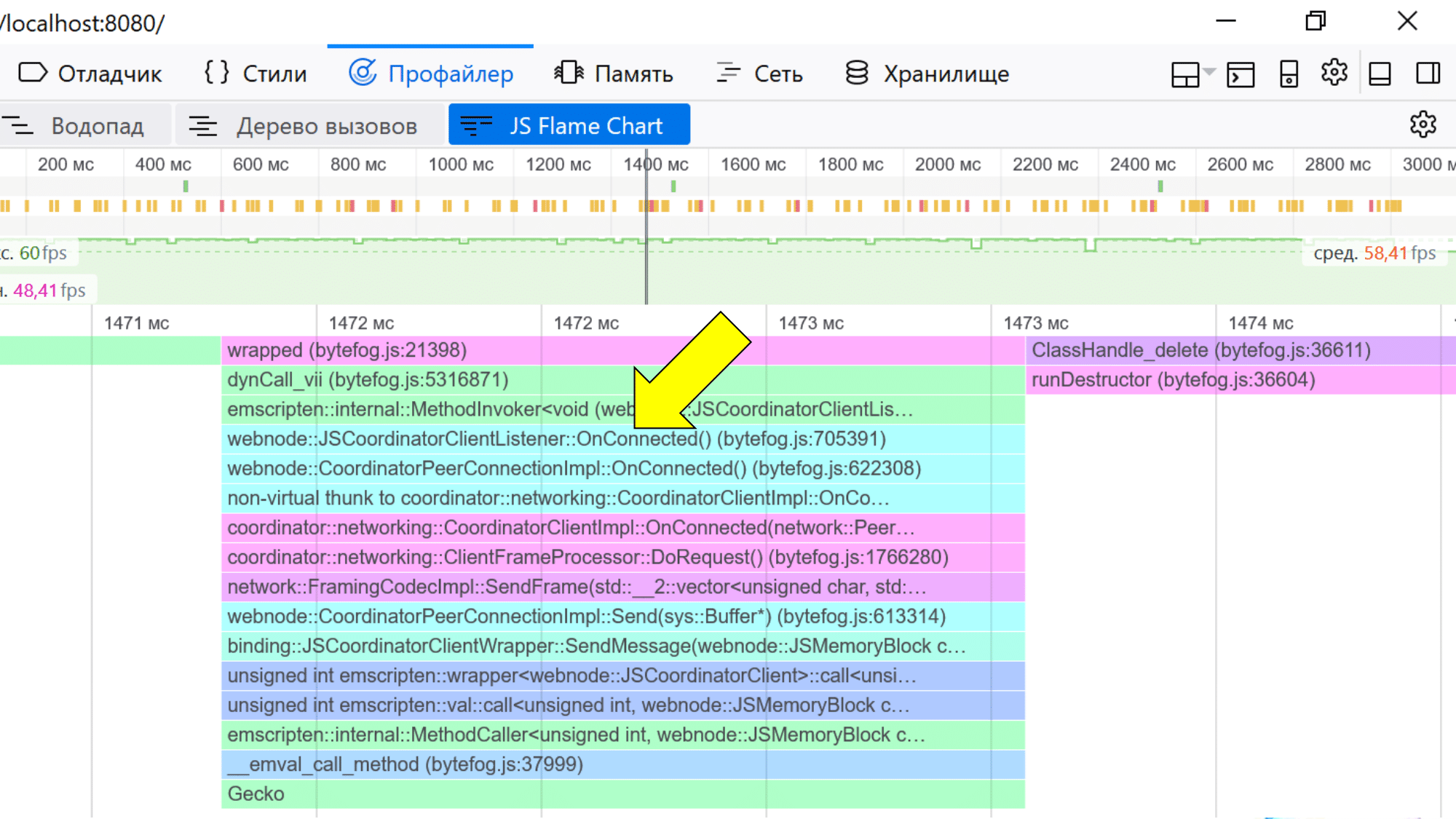
Chrome их немного кодирует (для тех, кто понимает, это Mangled имена функций), но, если прищуриться, можно понять, к чему они относятся.
Производительность
Поговорим о производительности. Это сложная и многогранная тема, и вот почему:
- Рантайм. Замер производительности зависит от runtime, который вы используете. Замеры в С++ будут отличаться от замеров в Rust или Go.
- Потери на границе JS — Wasm. Измерять математику не имеет смысла, потому что потери производительности происходят на пересечении границы JS и Wasm. Чем больше вы делаете вызовов туда-сюда, чем больше перебрасываете объектов, тем сильнее проседает скорость. Браузеры сейчас работают над этой проблемой, и постепенно ситуация улучшается.
- Технология развивается. Те замеры, которые сделали сегодня, не будут иметь смысла завтра, а уж тем более через пару месяцев.
- Wasm ускоряет старт приложения. Wasm не обещает, что ускорит ваш код или заменит JS. Команда WebAssembly сфокусирована на том, чтобы ускорять запуск больших кодовых баз приложений.
- В синтетике вы получаете скорость на уровне JS.
Мы сделали простой тест: графические фильтры для изображения.
- wasp_cpp_bench
- Chrome 65.0.3325.181 (64-bit)
- Core i5-4690
- 24gb ram
- 5 замеров; отброшены max и min; усреднение
Получили такие результаты. Здесь всё отнормировано к выполнению аналогичного фильтра на JS — жёлтый столбик, во всех случаях ровно единица.
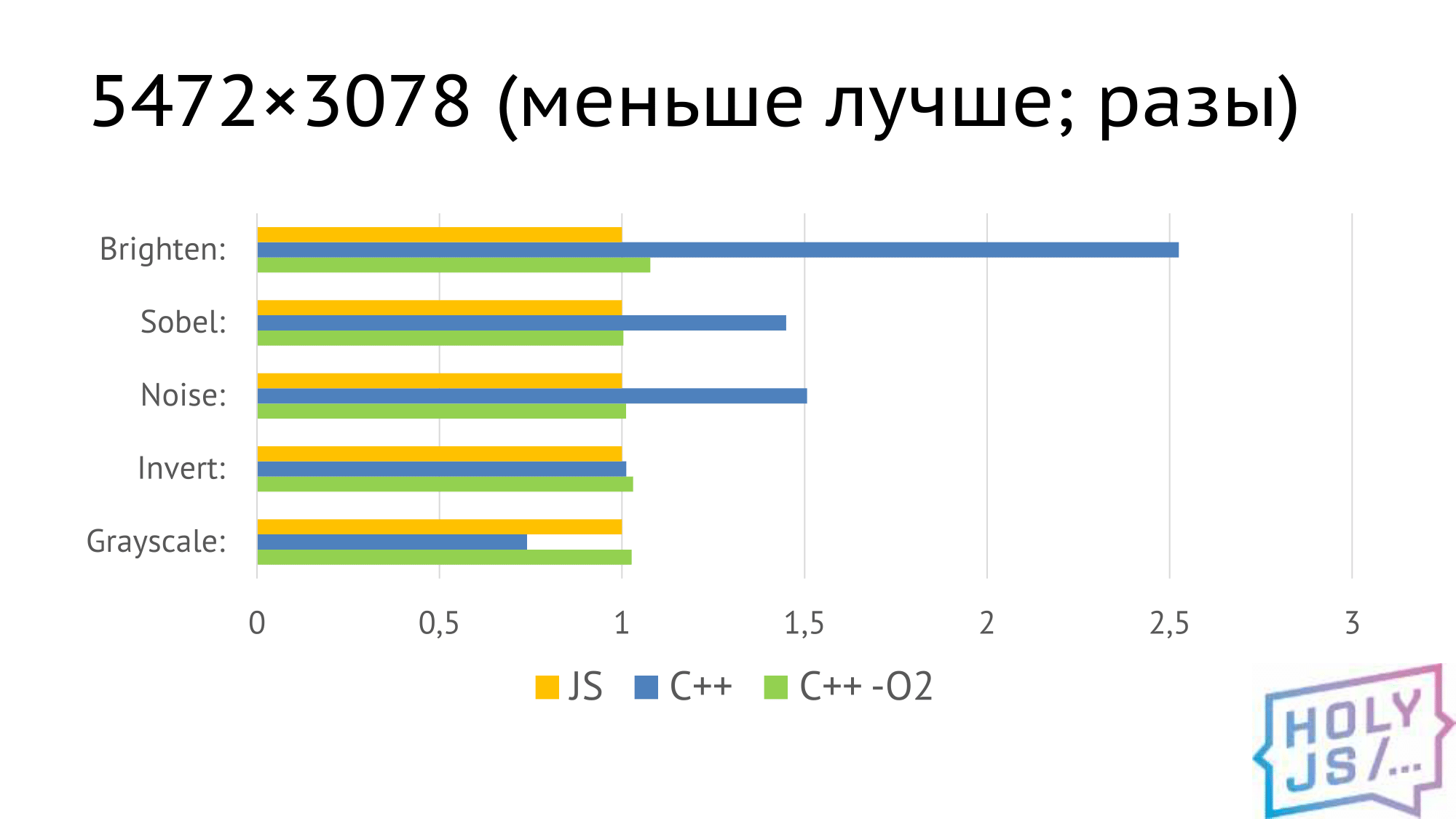
С++, скомпилированный без оптимизации, ведет себя каким-то странным образом. Это видно на примере фильтра Grayscale. Даже наши C++ разработчики не смогли объяснить, почему именно так. Но когда включается оптимизация (зеленый столбик), мы получаем время, практически совпадающее с JS. И, забегая вперед, мы получаем аналогичные результаты в нативном коде, если скомпилируем С++, как нативное приложение.
Сбор сбоев и ошибок
Мы используем Sentry, и с ним есть проблема — из стектрейсов пропадают фреймы wasm. Оказалось, что библиотека traceKit, которую использует клиент Sentry — Raven, — просто содержит регулярное выражение, в котором не учтено, что wasm существует. Мы сделали патч, и, наверное, скоро его отправим pull request, а пока применяем при npm install нашего JS-проекта.
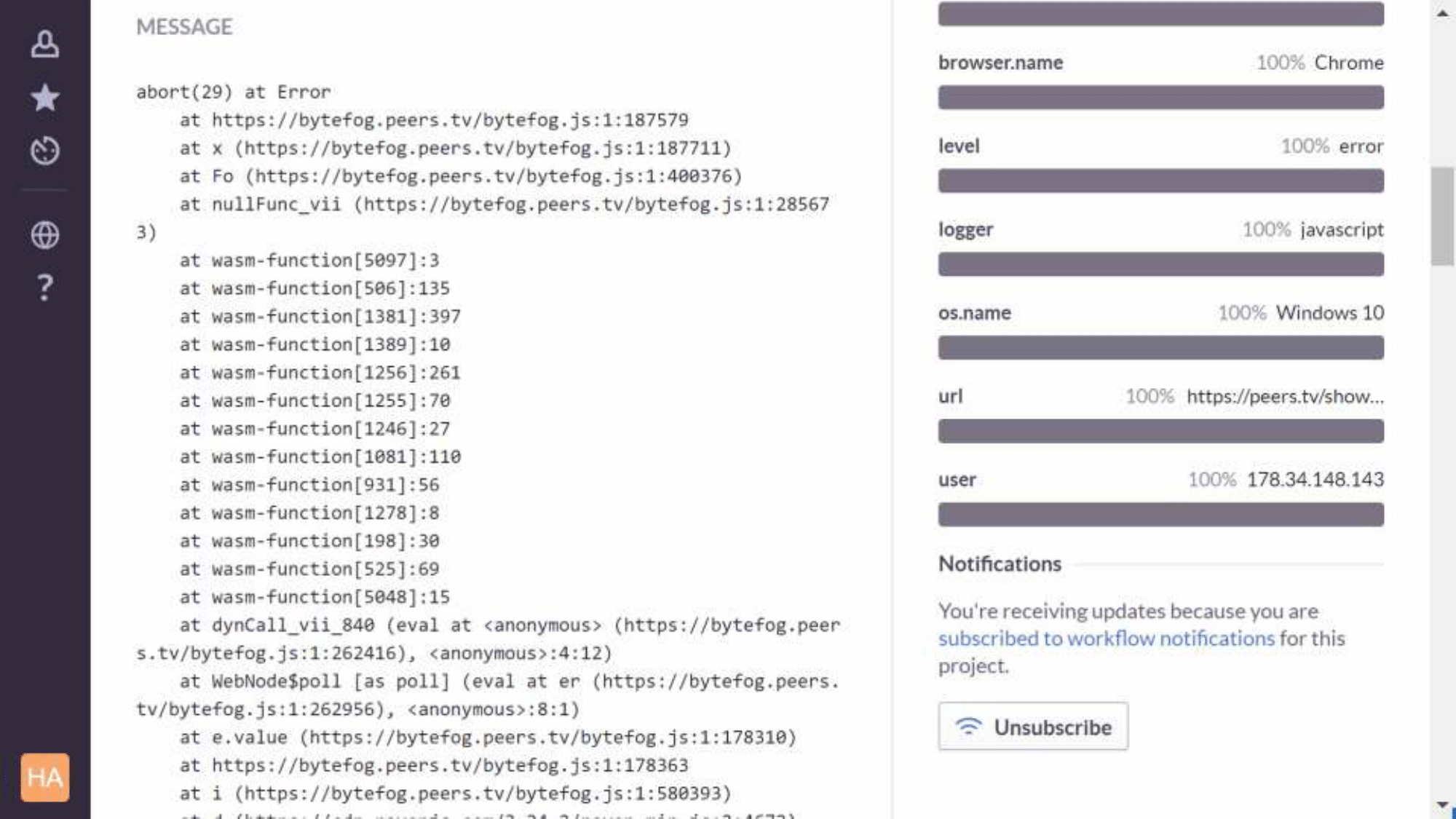
Выглядит вот таким образом. Это версия production, здесь не видно имён функций, только номера юнитов. А так выглядит debug-сборка, в ней уже можно разобраться, что пошло не так:
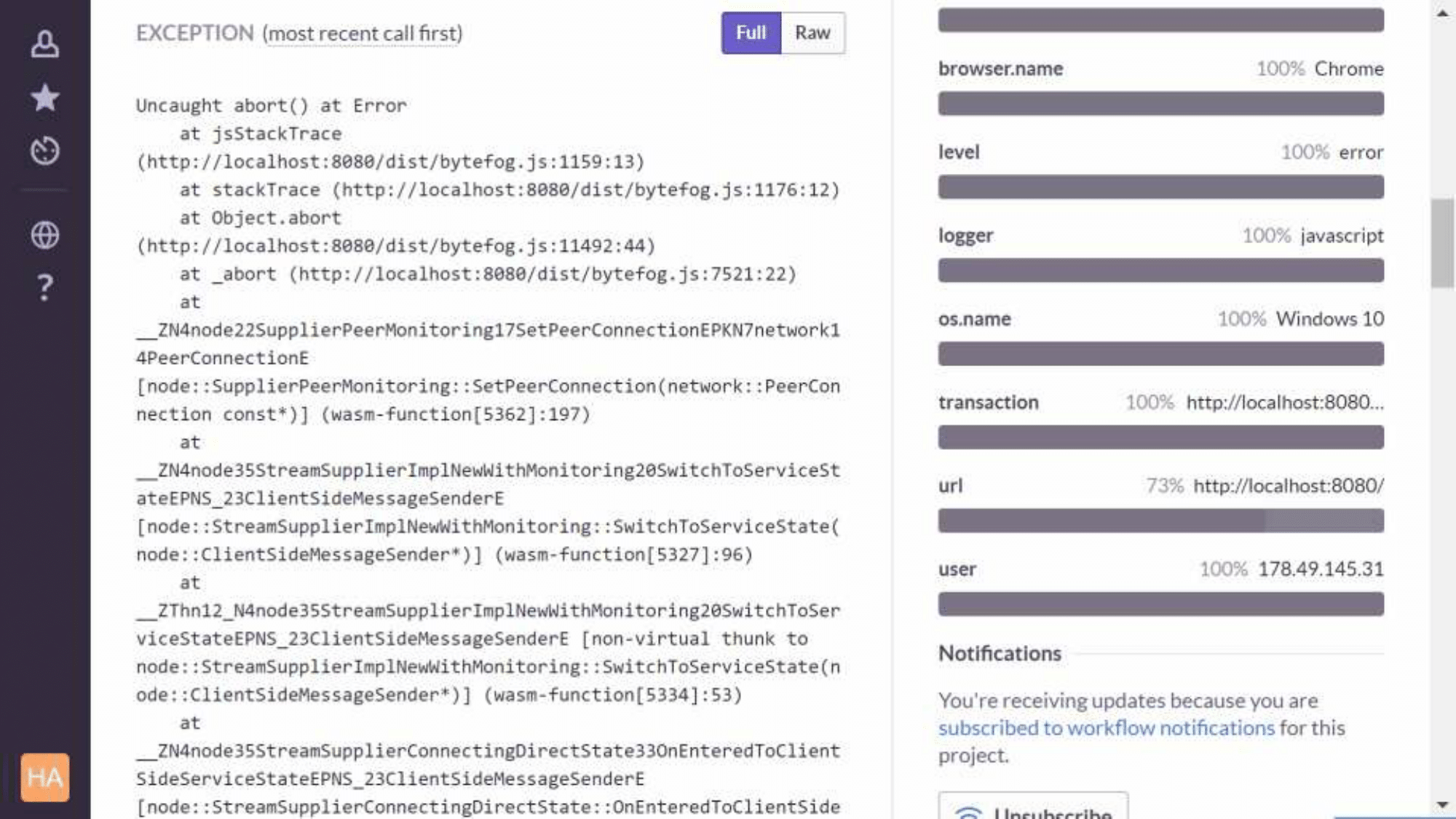
Итого
- WebAssembly уже можно использовать в бою, и наш проект это доказал.
- Портировать даже большое приложение — реально. У нас это заняло 8 месяцев, львиную долю которого мы потратили на рефакторинг своего приложения на C++, чтобы выделить границы, интерфейсы и так далее.
- Инструменты пока слабые, но работа в этом направлении ведется, так как WebAssembly — на самом деле будущее веба.
- Скорость — на уровне JS. Современные JS-машины оптимизируют программный код до такой степени, что он просто «проваливается» в машинные инструкции, и выполняется с той скоростью, с которой может ваш процессор.
Если возьметесь за работу, рекомендую:
- Берите Emscripten и Embind. Это хорошие и рабочие технологии.
- Если понадобится что-то странное в Emscripten — загляните в тесты. Документация есть, но охватывает не всё, а файл тестов содержит 3000 строк всех возможных ситуаций использования Emscripten.
- Для сбора ошибок подойдет Sentry.
- Отлаживайте в Firefox.
Спасибо за внимание! Я готов ответить на ваши вопросы.

Если вам понравился этот доклад с конференции HolyJS, обратите внимание: 24-25 мая в Петербурге состоится следующая HolyJS. На сайте конференции уже есть описания части докладов (например, приедет создатель Node.js Ryan Dahl!), там же можно приобрести билеты — и с 1 марта они подорожают.
RPG18
На самом деле, если хочется человеко читаемого стека с прода, то делается простой сервис за две недели.
AndreyNagih Автор
Вы имеете в виду, что-то похожее на Sentry, но своё и заточенное под конкретный проект?
RPG18
Что-то типа того. Elastic+kibana на старте могут дать быстрый результат
AndreyNagih Автор
Да, выглядит отлично! У нас есть похожая штука, заточенная под C++, называется Ceburasko. Может быть когда-то расскажем о ней подробнее, если кому-то это будет интересно.
Кстати, необязательно брать Sentry целиком. Можно взять только их клиент Raven.js, а приёмную сторону написать самостоятельно.
Месяц назад ребята из ВК на митапе в Новосибирске рассказывали о том, как они провернули такое у себя. Даже на их гигантских масштабах это сработало.
RPG18
Если есть возможность дёрнуть c++filt из Sentry, то это поправит дебажный стек
AndreyNagih Автор
А, вас смущают Mangled имена? Emscripten поддерживает опцию компиляции -s DEMANGLE_SUPPORT, при включении которой в стектрейсах появляются уже размотанные имена.
Так они и попадают в Sentry, от Debug-сборок. Выглядит это вот так.
F0iL
Из демок можно еще упомянуть:
http://vps2.etotheipiplusone.com:30176/redmine/emscripten-qt-examples/kate/kate.html
(текстовый редактор Kate на базе Qt из KDE скомпилирован в WASM)
wasm.continuation-labs.com/d3demo
(Doom 3 собственной персоной в браузере, тоже WASM)
s3.amazonaws.com/mozilla-games/ZenGarden/EpicZenGarden.html
(очень красивая штука на базе UnrealEngine)
d2jta7o2zej4pf.cloudfront.net
(бенчмарк, реализующий одни и те же алгоритмы обработки видео на WASM и на чистом JS)
Deamon87
Вот еще мое поделие. Просмотрщик моделей для WoW.
bnet.marlam.in/mv
Требует поддержи WebGL2.0 Управление для моделей M2 — мышкой + колесико мышки. Для моделей WMO — wasd + мышка.
Сначала программа разрабатывалась на C++ + OpenGL 3.3. А потом, как возникла идея — все с достаточно малыми усилиями было скомпилировано в WebAssembly. В основном благодаря тому, что использовались только те команды OpenGL 3.3, которые присутствовали и в WebGL 2.0
PS: Работает лучше всего в Chrome'е. У Safari сейчас вообще нет поддержки WebGL 2.0, поэтому Mac в пролете
splav_asv
Под Linux на в Firefox, ни в Chromium не работает…
RPG18
На Firefox 65.0 работает.
faiwer
73 Chromium, x64, Mint. Работает
splav_asv
А что за видео-драйвер? Radeon RX 560 Series (POLARIS11, DRM 3.27.0, 4.20.3-arch1-1-ARCH, LLVM 7.0.1)
faiwer
nvidia-340, GeForce GTX 660
splav_asv
В Firefox в консоли:
AndreyNagih Автор
Ещё отличная демо, которую не успел добавить в доклад: Netscape Navigator ранних версий в среде Windows 3.11 с поддержкой TCP/IP сети внутри WebAssembly внутри WebGL сцены с видом от первого лица с поддержкой многопользовательности.
assets.metacade.com/emulators/win311vr.html
Рекомендуется смотреть в FireFox.
А также, классный пример синтеза WebAssembly и Electron: Windows 95, аккуратно упакованная в Electron приложение, и доступная для запуска где угодно. (Можно рассматривать как альтернативу DOSBox).
github.com/felixrieseberg/windows95
Про неё кстати уже была статья здесь, на Хабре.
Deamon87
Ну тащем-то сейчас WebAssembly дает три преимущества перед js:
1) Нативная поддержка int64
2) Более быстрое выполнение кода
На этом все. Сейчас WebAssembly стоит воспринимать просто как байткод, который содержит типы, за счет чего может более быстро выдавать результат по сравнению с JS. На данном этапе WebAssembly не может делать напрямую вызовы браузерного API(делается через прослойки в виде js функций). Поэтому полезность минимальна.
С другой стороны, я имел опыт, когда программа скомпилированная в asm.js из С++ не работала, где-то внутри неправильно срабатывала математика и программа отказывалась правильно работать. При этом в таргете WebAssembly все работало как часы.
PS: с нетерпением жду когда сделают SIMD.JS в WebAssembly. Linked issue здесь: github.com/WebAssembly/proposals/issues/1
AndreyNagih Автор
Это действительно так. То о чем вы говорите называется Host bindings и сейчас над ними ведётся активная работа. Когда их реализуют любой бэкенд компилирующийся в wasm сможет с низкими накладными расходами обращаться к функциональности хоста (это не обязательно будет браузер).
Но. В практическом смысле, подобное уже можно делать прямо сейчас. (Что мы и сделали в нашем проекте Bytefog. Оценить работу технологии можно, например, на сайте peers.tv). Технически, действительно, происходит проброс через JS. Но всю эту работу берет на себя Emscripten. На вход мы ему даём указания что именно мы хотим пробросить. Сделать это можно аж тремя разными способами. Мы выбрали Embind, и я подробно разбираю как его использовать в своём докладе.
AlexanderY
Крутой доклад. А кто-нибудь уже реализовал ffmpeg в браузере? Интересно было бы взглянуть и погонять, сравнить производительность на конкретных сценариях с консольным ffmpeg.
AndreyNagih Автор
Спасибо!
FFMpeg в браузере уже реализовали, да не один раз. Думаю, вам будут полезны вот эти ссылки:
github.com/bgrins/videoconverter.js
github.com/sopel39/audioconverter.js
github.com/Kagami/ffmpeg.js
Буду благодарен вам, если расскажете о результатах своих экспериментов с ними.
domix32
Его еще надо довольно особенным способом скомпилировать дабы избежать атак по времени. Так что тут не все так однозначно. Вероятно имеет смысл либо не писать криптографию либо использовать использовать другие проверенные альтернативы.
Whuthering
А можно подробнее про особый способ компиляции чтобы избежать атак по времени?
domix32
Основной референс по constant time wasm
Там же ссылка на иследовательскую бумагу по теме и репу с портами и прочим необходимым.
Видео с пояснениями, какие проблемы с секьюрностью могут вызывать наивные порты кода в васм.
FForth
Стековые языки — тоже не чужды WebAssembly :)
При просмотре поиска на Github по слову Forth встретился и проект конкатенавного, стекового языка Plorth github.com/RauliL/plorth основанного на языках программирования Forth и Factor.
и его WebAssembly репозиторий github.com/RauliL/plorth-webassembly
(Plorth interpreter as WebAssembly module, compiled with Emscripten)
P.S. Вероятно будут появлятся и другие подобные проекты.
Forth in JS github.com/hcchengithub/jeforth.3we (с красивыми примерами)
Запуск в браузере различных ОС copy.sh/v86 (например и KolibriOS)
domix32
v86 не на wasm же.
Prototik
Поперхнулся смузи
KVM не основан на QEMU, и даже не наоборот. QEMU может использовать KVM для аппаратного ускорения, но он даже не требует его.
AndreyNagih Автор
Спасибо за замечание. Возможно я неправильно понимаю сложные взаимоотношения KVM и QEMU. Я ориентировался на данные Википедии.
Насколько я понимаю, KVM использует QEMU для паравиртуализации. Как-то так?
Prototik
Да нет же, это не KVM использует QEMU, это QEMU использует KVM. И не только KVM.
KVM это ускоритель, который может использоваться кем угодно (в том числе и qemu). Собственно, на приведённой Вами иллюстрации это и видно: есть hardware, поверх него ядро с kvm, поверх ядра qemu (или любой другой проект, который умеет в kvm), поверх уже гостевые системы.
AndreyNagih Автор
Спасибо! Теперь я разобрался. Значит глупость сморозил публично :-)
Тем не менее, заслуг Беллара это ни сколько не умаляет.
kikiwora
Хорошая статья, я имел несколько другие представления о WASM, спасибо за пояснения, интерено!
AndreyNagih Автор
Спасибо! Рад, что удалось изменить ваше представление.
CHolfield
А вот подскажите насчет криптографии. Почитал я про эту технологию и вознамерился сделать электронную подпись на x.509 сертификатах без плагина, прямо в браузере на стороне клиента. И, ясен пень, жестоко обломался с доступом к хранилищу сертификатов пользователя винды. Юзал c#, если это важно. Это когда-нить будет возможно?
AndreyNagih Автор
В WebAssembly принципиально нет и никогда не будет доступа к системе. Доступ есть только к хосту, в случае веба это браузер. Поэтому нужно смотреть в сторону WebCrypto API и на основе него уже можно что-то соорудить.
Вы C# компилировали в Wasm? Расскажите об этом подробнее. Что вы использовали? Какие остались впечатления?
CHolfield
Не знаю, можно ли назвать это компиляцией, но пробовал собирать, отлаживать в браузере как в статье. Знатно подивился на шарп-код в отладчике браузера с возможностью пошаговой отладки. Как уже писал выше, задача была реализовать криптооперации в браузере без плагина и локального прокси, я прямо возбудился на эту тему, потому что она есть боль для меня лично (электронные торги и документооборот). И в итоге фиаско. Впечатление у меня лично такое: непонятно, зачем оно надо на прикладном уровне, с такими ограничениями. Разве что без смены ЯП фронтенд пилить, без перехода на javascript. Возможно, я неправильно понял или не дочитал, тогда сорян за тупизну.
RPG18
Сделано что бы приложения типа Dead Trigger 2 быстрее стартовал в браузере
Deamon87
Понятно зачем. Как я писал выше, у JS есть поддержка только чисел до 2^53. Поэтому некоторые программы, которые используют int64_t, переносятся на js, но с костылями. А в WebAssembly — честная поддержка численных типов. Отсюда и выгода.
Кроме того, современный v8 постоянно делает сбор статистики по входным параметрам в функцию, на их основании компилирует js код в байткод процессора. Если какой-то параметр изменил тип — запускается неоптимизированная версия функции и статистика начинает собираться по новой.
А для WebAssembly этот функционал не нужен в принципе. Все статически скомпилировано и связано, как в обычном MZP\ELF исполняемом файле
AlexPublic
Хорошая статья по WebAssembly. Единственное, чтобы я добавил, это что для сборки C++ кода в WASM не требуется обязательно Emscripten. Для собственно компиляции достаточно просто компилятора LLVM (естественно собранным с поддержкой WASM и Clang'ом). И именно его использует Emscripten внутри себя. А смысл проекта Emscripten не в генерации WASM (или даже asm.js, с чего всё начиналось), а в генерации JS обёрток, реализующих функциональность стандартных библиотек C++ через браузерное API. Т.е. без Emscripten (с чистым LLVM) не будет возможности даже для вызова функции типа printf (но при этом будет базовая возможность вызвать произвольную JS функцию из страницы, в которую загружен wasm модуль).
Да, ну и вот эта цитата:
означает, что у вас есть какие-то фундаментальные проблемы в вашем нативном C++ приложение. Т.е. мои тесты вполне подтверждают ваш результат, что WASM в данное время сравним по производительности с JS. Но при этом тот же C++ код скомпилированный в машинные коды всегда получается в разы быстрее. И на это есть две фундаментальные причины:
1. WASM с одной стороны предоставляет полный доступ к работе с указателями, а с другой должен гарантировать безопасное выполнение подобного кода внутри песочницы (у модуля не должно быть способа залезть в данные браузера или других модулей). Как следствие этого, IR код работы с памятью компилируется (при загрузке модуля в браузере) не в прямую инструкцию x86, а с дополнительной проверкой выхода за границы выделенной памяти. На активно работающем с памятью коде, это может давать просадку производительности х2 раза.
2. SIMD. В будущем в WASМ планируют завести поддержку SIMD инструкций, но пока этого нет. В JS этого нет тем более. А в любом приличном компиляторе C++ уже много лет как поддерживается автовекторизация циклов, которая может давать увеличение быстродействие вплоть до х7 раз (для самых подходящих циклов, но в коде графических фильтров изображений должно быть полно таких).
В общем не знаю где у вас там конкретные косяки с C++, но если у вас скомпилированное в машинные коды приложение исполняется столько же, сколько WASM и JS варианты, то эти косяки у вас однозначно есть.
RPG18
Все приложения разные, а JIT в браузерах творит чудеса.
AlexPublic
Нет там никаких чудес. Каждый раз, когда я видел утверждения о равенстве быстродействия с C++, всё сводилось к кривому использованию последнего (собственно иначе и быть не может, т.к. тогда бы уже давно писали бы браузеры на js). Для схожего с использованным в статье для тестов алгоритмом у меня были следующие результаты (это усреднённое время в мс):
JS 15,6
C# 15,1
ASM.JS (из C++) 12,5
WASM из ASM.JS 11,4
Java 10,1
C# unsafe 8,9
WASM 8,6
D 7,2
C++ nosimd 4,4
C++ 1,5
RPG18
Нужно рассматривать конкретные приложения и примеры. Есть классы приложений, для которых производительность особо не требуется.
AlexPublic
Само собой. Например, хотя у нас в имеются специалисты с экспертным знанием C++, но для бэкенда наших сайтов используется вообще дико медленный Питон, потому как C++ нам тут просто не нужен — мы не Гугл или Яндекс. Однако все эти размышления не имеют никакого отношения к моему изначальному замечанию — там речь шла совсем о другом:
если у ребят получилась одинаковая производительность подобного алгоритма на JS, WASM (C++) и нативном C++, то практически гарантированно у них что-то очень не так в варианте нативного C++.
RPG18
Кроме бэкенда, есть еще куча GUI приложений написанных на Qt/Gkt, которые тупо ждут когда пользователь проведет мышкой или кликнет по кнопке. А их нативное приложение в основном общается по сети.
konsoletyper
Мне кажется, что проверка на выход за границы heap-а в ряде случаев может убираться оптимизатором. Кроме того, часть работы по отлову выходов за границу хипа можно сделать через защиту памяти. Что касается SIMD, опять же, браузер может сам анализировать WASM и автоматом векторизовать его (для этого в WASM есть всё необходимое). По крайней мере, LLVM ровно так и делает. А вот ещё моменты, которые ещё, как мне кажется, могут сильно влиять на производительность:
AlexPublic
Каким это образом, если и значение указателя и значения границ определены только в рантайме?
Каким образом можно в рамках одного процесса закрыть некому коду доступ к какой-то области выделенной памяти?
Нет там ничего необходимого. В будущем появится (соответствующие инструкции), но пока нет.
А если бы можно было делать автовекторизацию напрямую из машинных кодов, то такой алгоритм давным давно внедрили бы непосредственно в конвейер CPU.
Ээээ что? Где это он так делает?
Хм, да это интересный момент. Я его не смотрел. Причём с учётом того, что итоговая машина всё же стековая, у WASM JIT'a в теории есть большое поле для оптимизации. А вот делается ли там сейчас что-то для этого или нет — не знаю. Хотя это не сложно посмотреть, т.к. исходники открыты.
С учётом того, что в наиболее требовательных к ресурсам приложениях (программирование различных МК, ядра ОС, дравейров и т.п.) как раз применяется режим C++ с отключёнными исключениями, то данная особенность если и влияет на производительность, то только положительно. )))
konsoletyper
Вот уж не знаю как. Я точно помню, как общался с сотрудниками Мозиллы и они мне говорили про багу в range analysis ещё в альфа-версии WebAssembly. Как минимум, нижняя граница определена в compile-time (в WebAssembly-модуле для heap необходимо указывать минимальный и максимальный размер хипа), а то, что указатель известен только в рантайме, ещё не значит, что его диапазон нельзя оценить с помощью статического анализа. Такое, например, реализовано в JVM для устранения проверки на выход за границу массива.
mprotect в POSIX. В Windows тоже был системный вызов, но я с ходу не вспомнил название.
Там есть всё необходимое. Вот как-то C-компиляторы делают это. А они, заметьте, никогда не оптимизируют непосредственно AST C. Т.е. они строят IR (промежуточное представление), которое как раз очень похоже на портабельный ассемблер, а потом уже находят в нём циклы, которые можно векторизовать. Для этого есть куча способов, есть много специализорованной литературы, которая рассказывает про это (вот даже последние редакции Dragon Book рассказывают про векторизацию), и есть ещё большая куча всяческих статей от авторов тех или иных компиляторов.
Полагаю, что статья автора как раз не про драйвера и ядра ОС.
AlexPublic
Так нужны гарантии, что эти значения не меняются. Именно в этом проблема, а не в определение самих значений. Собственно единственная оптимизация, которую реально делают все подобные инструменты, это убирание повторных проверок (ну типа если мы дважды обращаемся по одному указателю внутри одной итерации цикла).
VirtualProtect это в Винде. Только ничем эти функции не помогут для решения данной проблемы. Если закрыть с помощью них доступ к какой-то области памяти, то каким образом сам браузер будет работать с этой областью памяти?
С учётом того, что в LLVM IR имеются векторные типы, это конечно очень большая загадка, как это делается. ))) Кстати, ещё забавный вопрос: интересно, как укладывается в это ваше видение факт работы OpenMP SIMD (у уже молчу про intrinsics)?
Речь о том, что отказ от исключений уж точно не ведёт к потере производительности. )
konsoletyper
Гарантий нет, но ведь всегда есть достаточно безопасные и предсказуемые кусочки программы, про которые что-то можно доказать. Кроме того, повторяю, что для верхнего лимита адресуемой памяти есть как минимум нижняя граница, которая указана просто в модуле. Для оптимизатора не важны точные значения. Для доказательства неравенства Amin < A < Amax, Bmin < B < Bmax, где Amin, Amax, Bmin, Bmax — константы, достаточно доказать, что Amax < Bmin. Если считать, что B — это размер хипа, то Bmin и Bmax тупо указаны в модуле. А Amax можно попытаться каким-то образом оценить, хотя бы сверху. Можно даже не с константами работать, а с инвариантами цикла. Ну например есть код:
компилятор вставит проверку
далее, у нас есть два инварианта цикла: wasm_upper_bound и end. К сожалению, start таковым не является, так что классический loop unswitching сделать не получится. Но известно, что он выполняется неравенство start < end с инвариантом цикла, так что можно попробовать модифицировать loop unswitching, чтобы он делал следующее
А браузеру вовсе не нужно с данной памятью работать. Учитывая, что в WebAssembly пока размер кучи ограничен 2^32, а процессоры у нас 64-битные, можно тупо нарезервировать страниц как раз на 2^32, но на реальные физические отобразить ровно столько, сколько заявлено в дескрипторе wasm-модуля (ну и по мере вызова grow_memory отображать дополнительные).
Вы хотите сказать, что clang берёт и сам генерит векторные инструкции? Мне казалось, что они всё-таки получаются в процессе работы самого LLVM. Учитывая, что с точки зрения меня, как разработчика приложений, формат wasm является всего лишь форматом обмена данными, мне всё равно, в какой там IR браузер разворачивает мой wasm-модуль и как его оптимизировать. Или разработчики WebAssembly не хотят, чтобы браузер делал векторизацию и хотят переложить эту заботу на компилятор? Ну тогда я всё равно не вижу практической невозможности позволить генерацию быстрого кода, я вижу только невозможность сочетать это с быстрым запуском кода.