
Apache Spark на сегодняшний день является, пожалуй, наиболее популярной платформой для анализа данных большого объема. Немалый вклад в её популярность вносит и возможность использования из-под Python. При этом все сходятся на том, что в рамках стандартного API производительность кода на Python и Scala/Java сопоставима, но касательно пользовательских функций (User Defined Function, UDF) единой точки зрения нет. Попробуем разобраться в том, насколько увеличиваются накладные расходы в этом случае, на примере задачи проверки решения SNA Hackathon 2019.
В рамках конкурса участники решают задачу сортировки новостной ленты социальной сети и загружают решения в виде набора отсортированных списков. Для проверки качества полученного решения сначала для каждого из загруженных списков вычисляется ROC AUC, а потом выводится среднее значение. Обратите внимание, что вычислить надо не один общий ROC AUC, а персональный для каждого пользователя — готовой конструкции для решения этой задачи нет, поэтому придется писать специализированную функцию. Хороший повод сравнить два подхода на практике.
В качестве платформы для сравнения мы будем использовать облачный контейнер с четырьмя ядрами и Spark, запущенный в локальном режиме, а работать с ним будем посредством Apache Zeppelin. Для сравнения функциональности будем зеркально выполнять один и тот же код в PySpark и Scala Spark. [здесь] Начнем с загрузки данных.
data = sqlContext.read.csv("sna2019/modelCappedSubmit")
trueData = sqlContext.read.csv("sna2019/collabGt")
toValidate = data.withColumnRenamed("_c1", "submit") .join(trueData.withColumnRenamed("_c1", "real"), "_c0") .withColumnRenamed("_c0", "user") .repartition(4).cache()
toValidate.count()val data = sqlContext.read.csv("sna2019/modelCappedSubmit")
val trueData = sqlContext.read.csv("sna2019/collabGt")
val toValidate = data.withColumnRenamed("_c1", "submit")
.join(trueData.withColumnRenamed("_c1", "real"), "_c0")
.withColumnRenamed("_c0", "user")
.repartition(4).cache()
toValidate.count()При использовании стандартного API обращает на себя внимание практически полная идентичность кода, с точностью до ключевого слова val. Время работы существенно не отличается. Теперь попробуем определить нужную нам UDF.
parse = sqlContext.udf.register("parse",
lambda x: [int(s.strip()) for s in x[1:-1].split(",")], ArrayType(IntegerType()))
def auc(submit, real):
trueSet = set(real)
scores = [1.0 / (i + 1) for i,x in enumerate(submit)]
labels = [1.0 if x in trueSet else 0.0 for x in submit]
return float(roc_auc_score(labels, scores))
auc_udf = sqlContext.udf.register("auc", auc, DoubleType())val parse = sqlContext.udf.register("parse",
(x : String) => x.slice(1,x.size - 1).split(",").map(_.trim.toInt))
case class AucAccumulator(height: Int, area: Int, negatives: Int)
val auc_udf = sqlContext.udf.register("auc", (byScore: Seq[Int], gt: Seq[Int]) => {
val byLabel = gt.toSet
val accumulator = byScore.foldLeft(AucAccumulator(0, 0, 0))((accumulated, current) => {
if (byLabel.contains(current)) {
accumulated.copy(height = accumulated.height + 1)
} else {
accumulated.copy(area = accumulated.area + accumulated.height, negatives = accumulated.negatives + 1)
}
})
(accumulator.area).toDouble / (accumulator.negatives * accumulator.height)
})При реализации специфичной функции видно, что Python лаконичнее, в первую очередь из-за возможности использовать встроенную функцию scikit-learn. Однако есть и неприятные моменты — необходимо явно указывать тип возвращаемого значения, тогда как в Scala он определяется автоматически. Выполним операцию:
toValidate.select(auc_udf(parse("submit"), parse("real"))).groupBy().avg().show()toValidate.select(auc_udf(parse($"submit"), parse($"real"))).groupBy().avg().show()Код выглядит практически идентично, но результаты обескураживают.

Реализация на PySpark отрабатывала полторы минуты вместо двух секунд на Scala, то есть Python оказался в 45 раз медленнее. Во время работы top показывает 4 активных процесса Python, работающих на полную, и это говорит о том, что проблемы здесь создает совсем не Global Interpreter Lock. Но! Возможно, проблема именно во внутренней реализации scikit-learn — попробуем воспроизвести код на Python буквально, не обращаясь к стандартным библиотекам.
def auc(submit, real):
trueSet = set(real)
height = 0
area = 0
negatives = 0
for candidate in submit:
if candidate in trueSet:
height = height + 1
else:
area = area + height
negatives = negatives + 1
return float(area) / (negatives * height)
auc_udf_modified = sqlContext.udf.register("auc_modified", auc, DoubleType())
toValidate.select(auc_udf_modified(parse("submit"), parse("real"))).groupBy().avg().show()
Проведенный эксперимент показывает интересные результаты. С одной стороны, при таком подходе производительность выровнялась, но с другой — пропала лаконичность. Полученные результаты могут говорить о том, что при работе в Python с использованием дополнительных С++ модулей появляются существенные накладные расходы на переход между контекстами. Конечно, подобные накладные расходы есть и при использовании JNI в Java/Scala, однако с примерами деградации в 45 раз при их использовании мне сталкиваться не приходилось.
Для более детального анализа проведем два дополнительных эксперимента: с использованием чистого Python без Spark, чтобы измерить вклад именно от вызова пакета, и с увеличенным размером данных в Spark, чтобы амортизировать накладные расходы и получить более точное сравнение.
def parse(x):
return [int(s.strip()) for s in x[1:-1].split(",")]
def auc(submit, real):
trueSet = set(real)
height = 0
area = 0
negatives = 0
for candidate in submit:
if candidate in trueSet:
height = height + 1
else:
area = area + height
negatives = negatives + 1
return float(area) / (negatives * height)
def sklearn_auc(submit, real):
trueSet = set(real)
scores = [1.0 / (i + 1) for i,x in enumerate(submit)]
labels = [1.0 if x in trueSet else 0.0 for x in submit]
return float(roc_auc_score(labels, scores))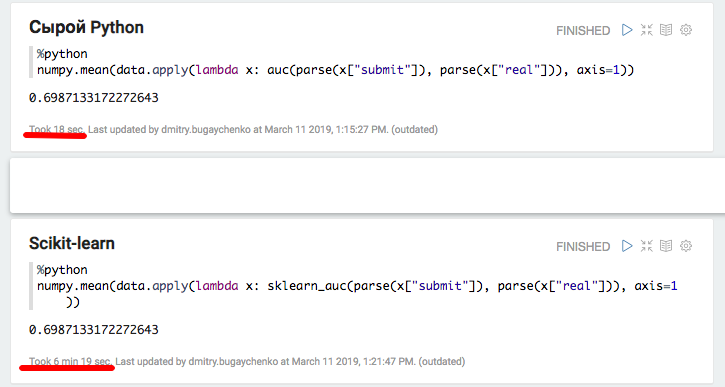
Эксперимент с локальным Python и Pandas подтвердил предположение о существенных накладных расходах при использовании дополнительных пакетов — при использовании scikit-learn скорость уменьшается более чем в 20 раз. Однако, 20 это не 45 — попробуем «раздуть» данные и снова сравнить производительность Spark.
k4 = toValidate.union(toValidate)
k8 = k4.union(k4)
m1 = k8.union(k8)
m2 = m1.union(m1)
m4 = m2.union(m2).repartition(4).cache()
m4.count()
Новое сравнение показывает преимущество по скорости Scala-реализации над Python в 7-8 раз — 7 секунд против 55. Напоследок попробуем «самое быстрое, что есть в Python» — numpy для подсчета суммы массива:
import numpy
numpy_sum = sqlContext.udf.register("numpy_sum",
lambda x: float(numpy.sum(x)), DoubleType())val my_sum = sqlContext.udf.register("my_sum", (x: Seq[Int]) => x.map(_.toDouble).sum)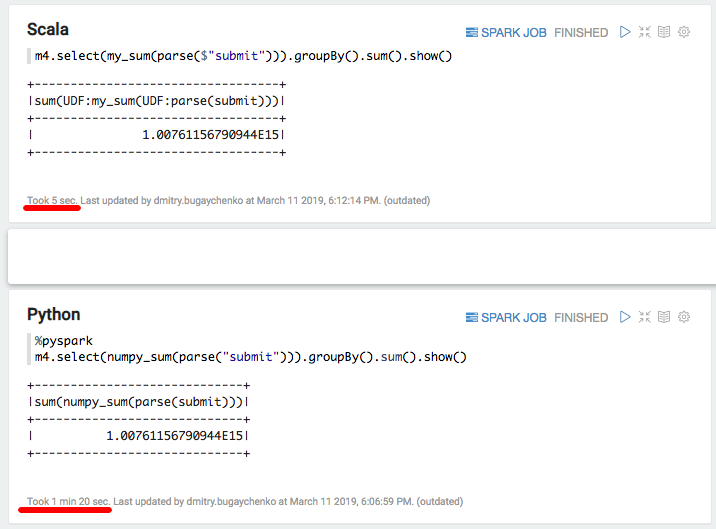
Опять существенное замедление — 5 секунд Scala против 80 секунда Python. Подводя итоги, можно сделать следующие выводы:
- Пока PySpark действует в рамках стандартного API, по скорости он действительно может быть сравним со Scala.
- При появлении специфичной логики в виде User Defined Functions производительность PySpark заметно снижается. При достаточном объеме информации, когда время обработки блока данных превышает несколько секунд, Python-реализация работает в 5-10 медленнее из-за необходимости перемещать данные между процессами и тратить ресурсы на интерпретацию Python.
- Если же появляется использование дополнительных функций, реализованных в C++ модулях, то возникают дополнительные расходы на вызов, и разница между Python и Scala увеличивается до 10-50 раз.
В итоге, несмотря на всю прелесть Python, применение его в связке со Spark не всегда выглядит оправданным. Если данных не так много, чтобы накладные расходы на Python стали значимыми, то стоит подумать, а нужен ли здесь Spark? Если данных много, но обработка происходит в рамках стандартного Spark SQL API, то нужен ли здесь Python?
Если же данных много и часто приходится сталкиваться с выходящими за пределы SQL API задачами, то для выполнения того же объема работ при использовании PySpark придется увеличивать кластер в разы. Например, для Одноклассников стоимость капитальных расходов на кластер Spark увеличилась бы на многие сотни миллионов рублей. А если попробовать воспользоваться расширенными возможностями библиотек экосистемы Python, то есть риск замедления не просто в разы, а на порядок.
Некоторое ускорение можно получить, используя относительно новую функциональность векторизованных функций. В этом случае на вход UDF подается не отдельно взятый ряд, а пакет из нескольких рядов в виде Pandas Dataframe. Однако разработка этой функциональности еще не завершена, и даже в этом случае разница будет значительной.
Альтернативой может быть поддержание обширной команды data engineer-ов, способных оперативно закрывать потребности data scientist-ов дополнительными функциями. Или всё-таки погрузиться в мир Scala, благо это не так сложно: многие необходимые инструменты уже существуют, появляются обучающие программы, выходящие за рамки PySpark.
Комментарии (55)

rssdev10
13.03.2019 12:49Здесь бы было интересно сравнить также vanilla Java-код. И получить ответ на вопрос, стоит ли мучаться с поиском программистов под Scala ради экономии 10% объема кода.
nehaev
13.03.2019 13:14Между современной джавой и скалой не такая уж адская пропасть. При желании более-менее сеньорный джавер начинает писать вполне идеоматичный скала-код через несколько недель изучения. Конкретно для спарка — это время вообще измеряется часами, поскольку Java API транслируется в Scala практически дословно. Это гораздо проще и быстрее, чем искать людей с нужными скилами на стороне. При этом 10% (хотя мне кажется больше) вы все так же получите.
rssdev10
13.03.2019 13:24В настоящее время Scala практически не развивается. Именно потому, что Java за последние 10 лет довольно сильно изменилась в лучшую сторону, и возникает вопрос, зачем нужна Scala. Да и остались ли, хоть какие-то API у Spark (как, впрочем, и у любого другого BigData-инструмента), которые не были бы на 100% совместимы с Java?
PS: Я бы не решился сейчас начинать новый проект на Scala. Опыт её использования имеется. Очень дорого обходится в ней контроль за кодом разработчиков. Существенно проще написать write-only код, по сравнению с Java. + чисто скальные проблемы по интеграции разных библиотек, собранных в разных Скалах.dmitrybugaychenko Автор
13.03.2019 13:35В плане производительности и Java, и Scala в спарке одно и тоже. АПИ более заточен под Scala, но из Java тоже можно пользовать. Про write-only код согласен полностью, Scala требует куда большей ответственности.
Но если брать Spark, то без скалиста все-таки никуда — надо уметь же внутрь залезть и разобратся почему что не работает и как сделать чтобы заработало. Не важно на чем клиент.
nehaev
13.03.2019 14:10+1Java действительно сделала огромный рывок вперед за последние годы, но, насколько я понимаю, большая часть этих нововведений уже давно была в Scala, причем сделана там гораздо лучше. Это как Ахиллес и черепаха. Ресурсов у Оракла гораздо больше, и они очень стараются сделать из джавы хотя бы скалу "на минималках" (или колтин "на минималках", кому что больше нравится). Но все равно они никогда не догонят Scala, потому что нельзя из пожилого императивного языка сделать функциональную конфетку.
Я бы не решился сейчас начинать новый проект на Scala.
Ну если проект на Spark, то тут даже думать не надо. Любой вариант кроме Scala требует экстраординарных обоснований.
sshikov
13.03.2019 14:24Ну почему, Java 8 не требует. Эффект тот же.
nehaev
13.03.2019 14:30Не совсем. Во-первых, с большой вероятностью придется читать код спарка, который на Scala, т.е. не знать ее нельзя. Во-вторых, если знаешь Scala, зачем писать более многословный, сложночитаемый и склонный к ошибкам код, если можно этого не делать?
sshikov
13.03.2019 15:22>с большой вероятностью придется читать код спарка
Хм. Один раз читал за два года. Зачем его читать? Что там такого есть, чтобы туда регулярно лазать?
>Во-вторых, если знаешь Scala, зачем писать более многословный, сложночитаемый и склонный к ошибкам код, если можно этого не делать?
Это по большей части сильно преувеличено. Таких требований, чтобы обязательно писать на скале, спарк не предъявляет точно. У нас куча проектов в проме, бОльшая часть — Java.nehaev
13.03.2019 15:50Один раз читал за два года.
"Один раз — не скалист" — такая логика, что ли :)
Таких требований, чтобы обязательно писать на скале, спарк не предъявляет точно.
Про "обязательно", я вроде и не писал нигде. Можно конечно и на джаве превозмогать, если есть время и желание.
sshikov
13.03.2019 17:26>Про «обязательно», я вроде и не писал нигде. Можно конечно и на джаве превозмогать, если есть время и желание.
А вот это? На мой взгляд тут примерно тоже самое и написано.
>Любой вариант кроме Scala требует экстраординарных обоснований.
В нашей практике — скорее наоборот, вариант писать на скале потребует показать что у вас в команде достаточно людей, которые ее знают. Для Java этого не нужно (как и знания спарка в принципе). Считается что специалистов много (хотя найти их сложно ;)
rssdev10
13.03.2019 14:29+2Ну если проект на Spark, то тут даже думать не надо. Любой вариант кроме Scala требует экстраординарных обоснований.
Запустите опрос о том, кто и на чём на Spark пишет.
Да и, вопрос, если BigData, то Spark ли… И стоит для Ignite или Flink использовать что-то кроме Java?..nehaev
13.03.2019 14:59Запустите опрос о том, кто и на чём на Spark пишет.
В ход пошли нетехнические аргументы? Я нашел статистику от датабрикс за 2016 год. Если у кого есть свежее, пожалуйста, делитесь:

Да и, вопрос, если BigData, то Spark ли… И стоит для Ignite или Flink использовать что-то кроме Java?
Обычно инструмент подбирают исходя из задачи, а не из предпочтений относительно ЯП. Если нужен Spark и уже знаете Java — разумнее всего сделать полшага вперед и перейти на Scala. Если конечно это прагматический вопрос, а не религиозный.
rssdev10
13.03.2019 15:07+1Если нужен Spark и уже знаете Java — разумнее всего сделать полшага вперед и перейти на Scala. Если конечно это прагматический вопрос, а не религиозный.
Да вот, из чисто прагматических соображений, не кажется разумным делать этот шаг к Scala. Потому что для компании Одерского Scala уже два года как не приоритет.
Для нынешнего Java-кода я могу быть уверен, что найду программистов и через 10 лет. Для Scala — не факт, что и через 5 лет такие найдутся. Тем более, что то, что пишут на Java для Spark, по факту, синтаксически не сильно отличается от Scala.nehaev
13.03.2019 16:06К сожалению, не вижу прагматических соображений. Вижу домыслы, основанные на слухах.
Потому что для компании Одерского Scala уже два года как не приоритет.
Одерский занимается dotty (которая Scala 3.0), "компания Одерского" (Lightbend) готовится к релизу Scala 2.13. Если для них Scala уже два года как не приоритет, то что тогда приоритет, неужели Java? И еще вопрос, а для Оракла Java точно приоритет?
Да, ресурсы Oracle и Lightbend несопоставимы, да, Java-community гораздо больше, чем Scala. Но все равно Scala технически круче Java. Это хотя бы факты, а не странные домыслы насчет приоритетов.
Последний параграф, по-моему, несколько противоречит сам себе. Если синтаксически не сильно отличается, откуда возьмутся проблемы с поиском программистов? Ну и плюс Спарк же врядли перепишут на джаву, так что для него аргументы в пользу скалы будут в силе и через 5 лет.
sshikov
13.03.2019 15:18А это не технический вопрос. Не чисто технический.
У нас кстати в коллективе примерно так же все — большая часть задач пишется на spark + java. Никакого активного желания мигрировать на скалу не наблюдается, при том что спарк шелл вполне используем.nehaev
13.03.2019 16:15Ну когда технические вопросы решаются нетехническими аргументами, тут больше вопрос к девелоперам, согласны ли они тратить свое время на такие проекты. Выбор-то всегда есть.
Если вы писали production-level спарк джобы и на скале и на джаве, юзали спарк-шелл, сами скажите, только честно, какой язык больше подходит для спарка?
sshikov
13.03.2019 17:15В моих проектах разница непринципиальная. На том уровне, на каком нужна скала для спарка (если не включать сюда ML, где все слегка иначе), Java 8 практически не отличается ничем. На скале пишутся прототипы, или утилиты (например, в нашей старой версии Hive не работает как следует MSCK — переписывается на скале). То есть это скриптовый язык, а ля баш.

Alexey_mosc
13.03.2019 22:30Интересно, что R появился. А ещё, от статистика, почему больше 100% на диаграмме? )
dmitrybugaychenko Автор
13.03.2019 22:37Больше 100% обычно в опросах где можно выбрать несколько вариантов. R, кстати, не проверял в данной задаче. Опыта нет…
Ну а появился в 2016 потому что до этого нормальной поддержки не было, SparkR появился в 1.4, это июнь 2015-го.Alexey_mosc
14.03.2019 12:26Более актуален sparklyr от RStudio. Он удобнее, хотя, что там под капотом, — это фигзнает. Он мимикрирует под синтаксис dplyr с его mutate %>% group_by %>% ..., и позволяет вызывать sql и прочее из библиотек scala (как я понял из примерно 3-х месячного опыта ковыряния оного).
Но в целом есть шероховатости, которые прямо драчовым напильником надо спиливать. Например, не признает функцию median из R stats. То есть, ты ожидаешь, что вызов медиан для расчета чего нибудь на груп-бае должен же работать! А он не работает… Пришлось ее тащить из нутра спарка. Многие чисто фильтровачные и обработачные функции для набора данных не работают, нужно писать на sql в коде Ар… Мешанина с NULL, NA ®, None и т.д… Неожиданные результаты.
В общем, туго идет процесс предобработки данных. Про производительность не знаю, гонял на localhost, но заметил, что операция превращения из длинного в широкий массив шла в десятки раз дольше на датафреймах спарк, чем в памяти R скрипта. Намучился…dmitrybugaychenko Автор
14.03.2019 13:05Сравнивать локальный алгоритм в памяти и расспределенный на кластере нестоит — локальный почти всегда выиграет. Но вот вопрос насколько много R в разных вариантах дает оверхеда при использовании UDF открытый (при использовании стандартных конструкций транслирующихся в Spark SQL все понятно). Если кто-то погоняет бенчмарк будет круто.
Alexey_mosc
14.03.2019 13:41Про оверхед вопрос хороший, я сам не знаю, насколько много там переливаний из пустого в порожнее прежде чем Спарк заводится. У меня остался осадок такого рода, что переписать то, что хорошо работает локально (на классах data.table()) и работает макс.быстро для R, очень муторно под Спарк. То есть, методы, которые должны быть user-friendly (высокоуровненые) вдруг не работают кое-где, и начинаешь вмешивать код SQL который прямо дословно идет в Spark SQL. А это еще страннее выглядит…
biggiemikkie
14.03.2019 16:25Ну тут на самом деле спорно про максимально быстро и data.table, только если у вас достаточно маленькие объемы данных. Вообще сравнить spark и data.table на локалке слегка не верно. А вот сравнивать iotools/bigmemory и sparklyr и с подкруткой под эти пакеты master-worker и map and reduce парадигм параллизации процессов соответственно, куда логичнее
Alexey_mosc
14.03.2019 17:37Ну да, не совсем то, или совсем не то. Просто был прецедент, дай как я раскатаю через dcast длииинный тейбл в широчееенный тейбл. Сравним с датафреймом на Spark. Оказалось совсем плохо (для последнего). Потом узнал, что, цитирую, «Spark is not optimized for wide dataframes». Услышал от спикера довольно опытного на конференции ODSC в Бостоне в прошлом году. Он мне говорит, зачем ты вообще такие широкие датафреймы строишь…
Ну и т.д. Это лишь один пример на небольших данных (пару сотен Мб).
Задача была а-ля мешок слов, а он же широкий, да.dmitrybugaychenko Автор
14.03.2019 18:12Работа в спарке с текстам делается обычно через переход к колонке-вектору (sparse разумеется) — соответственно все нужные утилиты типа TF-IDF, CountVectorizer, работ с N-gram и т.д. присутствуют. А датафреймы с очень большим количеством колонок он не любит, так как в памяти и при шафле все равно формат рядный, да еще и плотный.
Alexey_mosc
14.03.2019 18:37Я и хотел колонку-вектор сделать, если не ошибаюсь. Но я ее хотел собрать из предварительно созданных колонок… Ведь их нет изначально, а есть только две колонки — грубо говоря, document id, token. Как же сделать колонку-вектор, не разложив токены по колонкам. Вроде бы так было.
dmitrybugaychenko Автор
14.03.2019 18:49groupBy(document_id).agg(collect_list/collect_set) а дальше CountVectorizer из SparkML или MultinominalExtractor из PravdaML
biggiemikkie
14.03.2019 13:03Имел небольшой опыт работы с spark через пакет sparklyr. В общем и целом пакет новый, можно нарваться на ошибку и зависнуть над ней надолго, потому что невсегда она очевидна. Хотя синтексис очень близок к обычному dplyr, что конечно удобно, хоть и странно, тот же data.table тут был бы роднее. Мне кажется, многим роднее будет работать через iotools, чем вникать в spark
Alexey_mosc
14.03.2019 13:37Хотя синтексис очень близок к обычному dplyr, что конечно удобно, хоть и странно, тот же data.table тут был бы роднее.
Да!
sshikov
13.03.2019 14:30+1>Да и остались ли, хоть какие-то API у Spark (как, впрочем, и у любого другого BigData-инструмента), которые не были бы на 100% совместимы с Java?
Ну, таких чтобы совсем не, вряд ли. Но такие, где на выходе условно Seq, вы найдете легко, и они доставляют определенные неудобства. Не слишком большие. На ум приходит catalog.

Rhombus
13.03.2019 14:27+4python медленнее чем scala — действительно «неожиданный» результат
dmitrybugaychenko Автор
13.03.2019 14:48-1Для многих да… Ну а я совсем не ожидал бурной дискуссии Java/Scala в комментах — по мне так это практически родные сестры :)

Stas911
13.03.2019 17:36Это родные сестры, пока в дебри не углубишься (но, вроде, для типовых задач на Spark это особо и не требуется)
dmitrybugaychenko Автор
13.03.2019 18:54Характер у сестер, конечно, разный, но с любой можно найти общий язык и жить долго и счастливо. Даже выбирать не надо — вместе хорошо уживаются :)

Alex_Builder
13.03.2019 23:15-2А чего удивляться, что интерпретатор модных скриптов для школьников и продвинутых домохозяек aka Питон уступает в десятки раз в скорости чему-то что крутится на скоростной java-машине, которая уже давно известна своей блестящей JIT оптимизацией?
Ingas
14.03.2019 07:11«Не все так однозначно». В подобных задачах питон — скорее обертка над оптимизированным-переоптимизированным объектным кодом, так что результат действительно может оказаться неожиданным.

slonopotamus
14.03.2019 09:57В питоне быстро работает то что написано на C (с) я
dmitrybugaychenko Автор
14.03.2019 11:59Как выяснилось, к сожалению, не всегда. Здесь получилось что быстрее работает без C — это тоже неожиданный результат :)
Alex_Builder
14.03.2019 13:37> «Не все так однозначно»
Ой да не смешите мои тапки :) Что там может быть неоднозначно?
Вот когда Питон обзаведется своим собственным JIT компилятором, вот тогда и можно его скорость сравнивать с Java-машинами, а пока это похоже на сравнение тёплого с мягким.
Но боюсь, что тогда окажется что нужно еще вводить строгую типизацию для повышения производительности и снижения впустую сжираемой памяти и т.д. и т.п.
Но тогда это будет уже не такой простой скрипт для обучения школьников или для общего скриптописательства (как кроссплатформенная замена VBA), а значит он потеряет свое главное предназначение.dmitrybugaychenko Автор
14.03.2019 16:28Ну тут дело в том, что часто расспределение времени работы между питоном и «бэкендом» 1/999. Например, когда тренируем нейросетку, или когда работаем со спарком, но в рамках Spark SQL. В таких задачах все работает максимально быстро. Но как только баланс работы смещается хотя бы к 1/9 уже становится заметна разница.
eugene08
14.03.2019 23:07Вот когда Питон обзаведется своим собственным JIT компилятором..
pypy, numba…dmitrybugaychenko Автор
15.03.2019 12:01Попробовал с PyPy — 55 секунд Python, 30 секунд PyPy, 7 секунд Scala. Т.е. разница уже не 7-8 раз, а всего 4-5 раз :)


time2rfc
15.03.2019 12:22Не могу понять отчего люди используют слово ВСЕГО при обсуждении такой разницы, у нас scala код считает отчет месячный чуть меньше суток, разница между сутками и половиной неделе совсем не ВСЕГО
dmitrybugaychenko Автор
15.03.2019 12:24Ну это ирония была если что :). Для нас тоже 4-5 раз это сотни миллионов дополнительных трат.
sshikov
16.03.2019 12:14Ну там же смайл был… а так вы правы конечно, если мы должны за сутки обработать некоторый поток данных, то разница даже между восемью часами и четырьмя совсем не маленькая. Ну или уменьшение потребления ресурсов во столько же раз.
rotlis
15.03.2019 12:44Холивар в чистом виде с попытками предьявить «unbiased» аргументацию. Как тут не поучаствовать? Тим-лидю небольшой BigData проект в телекоме. Толковых работящих людей на рынке понимающих как делать биг дату и писать на питоне в разы больше чем людей которые могут на скале написать «hello world». Если проект подразумевает развитие и поддержку то выбор скалы имеет риск что в один прекрасный день вы все будете тащить один плача после очередного неудачного интервью.
dmitrybugaychenko Автор
15.03.2019 12:50Ну, по опыту собеседований, Java разработчики, которые могут написать не только hello world на Scala, на рынке есть. Они стоят дороже питонистов, но при этом результат который они создадут будет куда как надежнее чем поделка среднестатистического питониста. К сожалению, средний уровень базовых программистких скилов в среде питонистов существенно ниже… В том числе из-за набежавших на хайп «датасаентистов тюню xgboost за 300 к/c».
sshikov
16.03.2019 12:10У нас вменяемые не слишком опытные java разработчики вполне пишут на спарке. Может не сразу, но обычно стандартного месяца вполне хватает, чтобы включиться, а месяц все равно нужен, чтобы в бизнес вникнуть.
Stas911
15.03.2019 15:36А вот такой вопрос — все ли пакеты Python, использованные в UDF, были заранее установлены на всех нодах?
CrazyElf
15.03.2019 18:15И всё же без профайлера не очень понятно, что именно в питоне тут тормозит. Может там вообще parse тормозит, или использование Series из Pandas как-то не оптимально работает. Когда преобразований всяких много тяжело понять, где же узкое место.
pklemenkov
А почему не использовали pandas_udf? Там же за счет Arrow и векторизации очень большой буст получается. Ну и реализацию самой udf через векторизованные операции очень помогло бы
dmitrybugaychenko Автор
Это хорошо может помочь если действительно можно реализовать udf без pandas.apply внутри, на стандартных функциях. Но тогда не очень понятно зачем UDF — базовых функций и в Spark SQL много. Но в нашем случае надо выполнить некоторую логику именно для каждого ряда — с Arrow будет не в 7-8 раз разница, а в 3-4, если без скайлерна, а с ним мрак по любому. Попробую погонять отдельно.