
Предисловие
Есть на свете такая простая и очень полезная утилита — BDelta, и так вышло, что она очень давно укоренилась в нашем производственном процессе (правда её версию установить не удалось, но она точно была не последней доступной). Используем её по прямому назначению — построение бинарных патчей. Если взглянуть, что там в репозитории, — становится слегка грустно: по сути он давным-давно заброшен и многое там сильно устарело (когда-то туда внёс несколько правок мой бывший коллега, но давно это было). В общем, решил я это дело воскресить: форкнулся, выкинул то, что не планирую использовать, перегнал проект на cmake, заинлайнил «горячие» микрофункции, убрал со стека большие массивы (и массивы переменной длины, от которых у меня откровенно «бомбит»), прогнал в очередной раз профилировщик — и узнал, что около 40% времени тратится на fwrite…
Так что там с fwrite?
В данном коде fwrite (в моём конкретном тестовом случае: построение патча между близкими 300 Мб файлами, входные данные полностью в памяти) вызывается миллионы раз с буфером малого размера. Очевидно, что штука данная будет тормозить, и потому хотелось бы как-то повлиять на это безобразие. Внедрять разного рода источники данных, асинхронный ввод-вывод пока нет желания, хотелось найти решение проще. Первое, что пришло в голову — увеличить размер буфера
setvbuf(file, nullptr, _IOFBF, 64* 1024)но существенного улучшения результата я не получил (теперь на fwrite приходилось около 37% времени) — значит дело всё же не в частой записи данных на диск. Заглянув «под капот» fwrite можно увидеть, что внутри происходит lock/unlock FILE структуры примерно так (псевдокод, весь анализ проводился под Visual Studio 2017):
size_t fwrite (const void *buffer, size_t size, size_t count, FILE *stream)
{
size_t retval = 0;
_lock_str(stream); /* lock stream */
__try
{
retval = _fwrite_nolock(buffer, size, count, stream);
}
__finally
{
_unlock_str(stream); /* unlock stream */
}
return retval;
}
Если верить профилировщику, на _fwrite_nolock приходится всего 6% времени, остальное — на оверхед. В моём конкретном случае потокобезопасность явное излишество, ей я и пожертвую, заменив вызов fwrite на _fwrite_nolock — даже с аргументами мудрить не надо. Итого: данная нехитрая манипуляция в разы сократила затраты на запись результата, которые в первоначальном варианте составляли почти половину временных затрат. Кстати, в мире POSIX есть аналогичная функция — fwrite_unlocked. Вообще говоря, то же касается и fread. Таким образом с помощью пары #define можно получить вполне себе кроссплатформенное решение без лишних блокировок в случае, если в них нет необходимости (а такое бывает весьма часто).
fwrite, _fwrite_nolock, setvbuf
Давайте абстрагируемся от оригинального проекта и займёмся тестированием конкретного случая: записи большого файла (512 Мб) предельно малыми порциями — в 1 байт. Тестовая система: AMD Ryzen 7 1700, 16 Гб ОЗУ, HDD 3.5" 7200 rpm 64 Мб кэша, Windows 10 1809, бинарь строился 32-х битный, оптимизации включены, библиотека статически прилинкована.
Сэмпл для проведения эксперимента:
#include <chrono>
#include <cstdio>
#include <inttypes.h>
#include <memory>
#ifdef _MSC_VER
#define fwrite_unlocked _fwrite_nolock
#endif
using namespace std::chrono;
int main()
{
std::unique_ptr<FILE, int(*)(FILE*)> file(fopen("test.bin", "wb"), fclose);
if (!file)
return 1;
constexpr size_t TEST_BUFFER_SIZE = 256 * 1024;
if (setvbuf(file.get(), nullptr, _IOFBF, TEST_BUFFER_SIZE) != 0)
return 2;
auto start = steady_clock::now();
const uint8_t b = 77;
constexpr size_t TEST_FILE_SIZE = 512 * 1024 * 1024;
for (size_t i = 0; i < TEST_FILE_SIZE; ++i)
fwrite_unlocked(&b, sizeof(b), 1, file.get());
auto end = steady_clock::now();
auto interval = duration_cast<microseconds>(end - start);
printf("Time: %lld\n", interval.count());
return 0;
}
В качестве переменных будут выступать TEST_BUFFER_SIZE, а также для пары случаев заменим fwrite_unlocked на fwrite. Начнём со случая fwrite без явной установки размера буфера (закомментируем setvbuf и связанный код): время 27048906 мкс, скорость записи — 18.93 Мб/с. Теперь установим размер буфера в 64 Кб: время — 25037111 мкс, скорость — 20.44 Мб/с. Теперь протестируем работу _fwrite_nolock без вызова setvbuf: 7262221 мкс, скорость — 70.5 Мб/с!
Дальше поэкспериментируем с размером буфера (setvbuf):
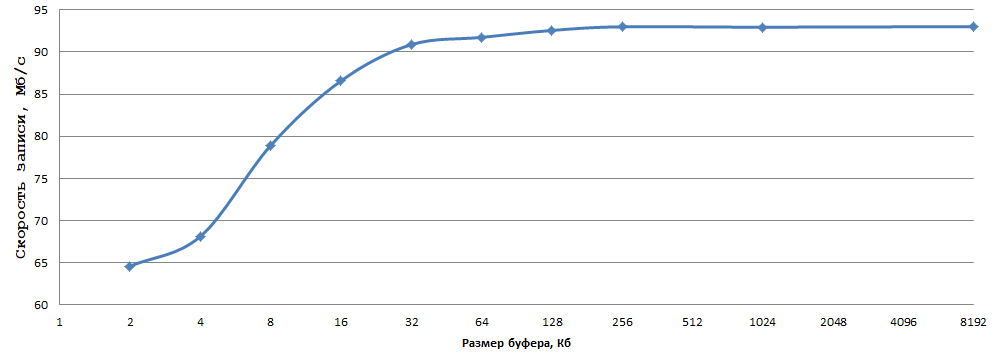
Данные получены усреднением 5 экспериментов, погрешности считать я поленился. Как по мне, 93 Мб/с при записи по 1 байту на обычный HDD — это очень неплохой результат, всего-то надо выбрать оптимальный размер буфера (в моём случае 256 Кб — в самый раз) и заменить fwrite на _fwrite_nolock/fwrite_unlocked (в случае, если не нужна потокобезопасность, разумеется).
Аналогично с fread в подобных условиях. Теперь посмотрим, как обстоят дела на Linux, тестовая конфигурация такая: AMD Ryzen 7 1700X, 16 Гб ОЗУ, HDD 3.5" 7200 rpm 64 Мб кэша, ОС OpenSUSE 15, GCC 8.3.1, тестировать будем x86-64 бинарь, файловая система на тестовом разделе ext4. Результат fwrite без явной установки размера буфера в данном тесте 67.6 Мб/с, при установке буфера в 256 Кб скорость увеличилась до 69.7 Мб/c. Теперь проведём аналогичные замеры для fwrite_unlocked — результаты тут 93.5 и 94.6 Мб/с соответственно. Варьирование размера буфера от 1 Кб до 8 Мб привело меня к следующим выводам: увеличение буфера увеличивает скорость записи, но разница в моём случае составила всего 3 Мб/с, различий в скорости между буфером в 64 Кб и 8 Мб не заметил вовсе. Из полученных на данной Linux машине данных можно сделать следующие выводы:
- fwrite_unlocked работает быстрее, чем fwrite, но разница в скорости записи не столь велика, как на Windows
- Размер буфера на Linux не оказывает столь существенного влияния на скорость записи через fwrite/fwrite_unlocked, как на Windows
Итого предложенный метод эффективен как на Windows, но и на Linux (хоть и в существенно меньшей мере).
Послесловие
Целью написания данной статьи было описание простого и действенного во многих случаях приёма (с функциями _fwrite_nolock/fwrite_unlocked я раньше как-то не сталкивался, не очень они популярны — а зря). На новизну материала не претендую, но надеюсь, что статья окажется полезной сообществу.
Комментарии (28)

arcman
17.03.2019 15:43Спасибо за исследование, это вполне годный вариант забесплатно получить ускорение, там где нет возможности что то кардинально поменять.
Но побайтное чтение/запись в stdio все равно слишком медленные и лучше менять алгоритм что бы было линейное чтение/запись большими кусками.
Хотел спросить как вы замеряли скорости что бы избежать побочных эффектов от кеширования файла в памяти после первого прогона, но судя по низким скоростям это не имеет большого смысла в данном случае.
Deamhan Автор
17.03.2019 16:09Обычно кэширование содержимого позволяет быстро прочесть файл (например втихую замапив его в память), а тут шёл тест именно записи. Перед каждым файлом содержимое файла сбрасывается в 0, про какой кэш между запусками идёт речь? Или я Вас не так понял?
arcman
17.03.2019 16:45Про запись я вас случайно запутал. Да, я именно чтение имел в виду, мне одно время нужно было достоверно измерить разницу между разными вариантами чтения и кеш все портил.
Но у вас все равно получается, что измеряется время когда вы отдали файл в кеш ОС, а не когда он по факту был записан на диск.
В любом случае переделывание алгоритма на последовательную запись большими кусками позволит ускориться в несколько раз, потому что даже для HDD на 7200 rpm скорость линейной записи обычно > 200 МБ/с.
Но для бинарных патчей это наверное не актуально :)Deamhan Автор
17.03.2019 17:30Это уже чуть другая вещь, асинхронная, которая происходит прозрачно для алгоритма и её не так просто оценить (современная ОС штука очень хитрая, особенно если памяти много), да оно по сути и не нужно (в данном случае file.reset() можно затащить под end, но сути оно не поменяет). Запись в алгоритме и так по сути последовательная, решалась проблема огромного оверхеда при записи малыми порциями — и тут проблемы больше нет, теперь на вводе-выводе времени транится несколько процентов. Круче разве что прикрутить асинхронную запись, но смысла особого в этом пока нет — есть множество более «дорогих» с точки зрения времени фрагментов.

Pochemuk
17.03.2019 17:48А как коррелирует оптимальный размер кэша с размером аппаратного буфера самого HDD? Если взять HDD с буфером 32 или 128 Гб, то как изменится форма графика производительности?
Deamhan Автор
17.03.2019 18:08Если учесть, что скорости тут порядка обычной линейной записи, то возможно что корреляции почти 0. Думаю тут куда большее влияние оказывают особенности реализации системы ввода-вывода самой ОС. Лично у меня нет большого набора разных винтов, так что наверняка ответить не могу.
arcman
17.03.2019 19:32+1Это не кэш, это внутренний буффер в библиотеке. Потом все это попадет в кэш ОС.
А влияния в данном случае не будет, потому что бутылочное горлышко где то в другом месте.
Тут даже близко не подошли к пределу по линейной записи.
И вы точно не напутали с размерностью МБ/ГБ? :)Pochemuk
17.03.2019 21:15Ну, малость попутал :) Но это же такая мелочь :D
Так кому верить? «Близко не подошли к пределу линейной записи» или «Скорости тут порядка обычной линейной записи», если верить предыдущему оратору?
alan008
17.03.2019 23:07Вы еще не отметили, что hdd не только размером буфера отличаются, но и скоростью вращения, 5400, 7200, 10000 rpm точно дадут разную скорость записи. Но в целом, буфер играет роль только в сценариях, когда происходит например копирование неск. гигабайт данных из одной папки в другую, а когда на диск пишутся данные, которые генерирует какая-то программа, размер буфера не должен влиять на скорость записи, т.к. как только он заполнится, мы упремся в сам диск (вращение+головка).
Deamhan Автор
18.03.2019 00:17+1На самом деле эти утверждения не противоречат друг другу: предел линейной записи — это скорость внешней дорожки, внутренняя обычно в пару раз медленнее. Итого в среднем скорость линейного чтения файлов на современном 7200 rpm 3.5" HDD около 150 мб/с, тест скорости кэша в моём случае выдал почти 500 мб/с. Итого: к чему по порядку ближе полученные результаты? Достигнут ли предел по скорости линейной записи?
lorc
17.03.2019 18:06-1Почему бы просто не мапить файл в память? По идее, это будет ещё быстрее.
Deamhan Автор
17.03.2019 18:17Хотелось по-максимуму сохранить портабельность, не дописывая кейсов для разных ОС, и в целом обойтись минимальными изменениями. Если бы не удалось решить проблему так легко — перешёл бы к маппингу.
arcman
17.03.2019 19:27+1Совсем не факт, будет зависеть от разных факторов и нужно сравнивать все равно.

MisterParser
18.03.2019 10:41О чего конкретно защищает блокировка?
Deamhan Автор
18.03.2019 10:48От одновременного использования одной FILE структуры из нескольких потоков. По сути это лок/анлок мьютекса
polar_yogi
18.03.2019 12:02Попробовал на железном линуксе
HDD WDC WD20EZRZ — 5400 rpm буфер 64М.
$ ./fwrite_test.fwrite_nosetbuf
Time: 11718859
$ ./fwrite_test.fwrite_unlock_nosetbuf
Time: 9806416
$ ./fwrite_test.fwrite_unlock_setbuf
Time: 9803208
Разница заметна, но не так как в виртуалке.
прогнал несколько раз, погрешность ~1% картины особенно не меняет.Deamhan Автор
18.03.2019 12:44Здорово, что общая закономерность та же, и похоже накладные расходы на lock/unlock в linux меньше. Вообще в Вашем случае, похоже, скорость ограничена самим накопителем (неудачное расположение файла и т.п.). Что за дистрибутив использовали? Какая версия gcc? Собирали с теми же параметрами, что я указывал? Раз уж зашёл разговор такой, у меня сейчас есть возможность произвести те же замеры на linux десктопе, как соберу данные — отпишусь.
polar_yogi
18.03.2019 13:59Я «дико извиняюсь». Вообще написал, потому что хотел заметить что виртуалка не лучшее место для проведения тестов и выводов по i/o. поэтому тупо скопировал строку
g++ -o2 -s -static-libgcc -static-libstdc++ fwrite_test.cpp -o fwrite_test
и только после вашего поста задумался — файло-то и правда, 512М а не Г, почему-же так медленно? Попробовал на tmpfs — та-же картина.
Дело в -o2, с -O2 — совсем другое дело. На hdd
$ ./fwrite_test.unlock_nobuf
Time: 4637970
$ ./fwrite_test.unlock_buf
Time: 4636879
$ ./fwrite_test.fwrite
Time: 6129556
Почти то-же самое на ssd/tmpfs.
И еще, вместо fwrite_unlocked(&b, 1, sizeof(b), file.get());
видимо, должно быть fwrite_unlocked(&b, sizeof(b), 1, file.get());
PS: linux gentoo x86_64 gcc 8.2
а еще — какая виртуалка у вас, на vbox/win7 разница получилась менее заметной.Deamhan Автор
18.03.2019 15:16Да, виртуалка не совсем то для тестов, но лучше варианта под рукой тогда не было (виртуалка HyperV из 1809 win 10). Сейчас я дорвался до железной линухи — соберу результаты и заменю таковые от виртуалки. Неточности исправил, спасибо. Отдельное спасибо за результаты теста.
Deamhan Автор
18.03.2019 16:26Заменил данные с виртуалки на таковые с реальной машины, в полученных данных та же закономерность, что и в ваших.
pfemidi
Как так?
Deamhan Автор
подмените сэмпл на
и посмотрите как он отработает.
ru.cppreference.com/w/cpp/memory/unique_ptr/release — вернётся nullptr в никуда и что? Вообще std::unique_ptr::release() noexcept метод
pfemidi
Моя недоглядел. Сыграло роль абсолютное незнание мной концепции «умных указателей». Я думал там нормальный указатель сравнивается с нулём, а чтобы получить нормальный указатель оказывается надо .get() сделать, «умный» то возвращается всегда, ещё и с переопределённым оператором '!'.
arcman
Собственно вопросы всё равно остались:
1. Зачем так сложно? Зачем там unique_ptr?
2. Почему в случае ошибки перед завершением программы делается file.release(), а при нормальном завершении — нет?
Readme
Это идиоматическое применение
unique_ptrв качестве RAII-обёрток над легаси/C-примитивами:unique_ptr<FILE*, ...>указывается кастомный удалитель, который вызываетfclose(file_ptr_)в деструкторе при штатной работе программы (или при генерации любого исключения).fopenпо стандарту возвращаетnullptr, поэтому в таком случае нет необходимости вызыватьfclose. Deamhan, скорее всего, здесьreleaseвообще не нужен, потому что deleterunique_ptr'а и так не вызовется надnullptr.Deamhan Автор
Да, Вы правы — по стандарту на пустом unique_ptr-е deleter не вызывается. Уже убрал избыточный release(). Вы слегка ошиблись в прототипе — std::unique_ptr<FILE, ...>, иначе придётся FILE** в конструктор передать.
azymohliad
Вау! Не знал, что с помощью умных указателей так легко оборачивать С-шные ресурсы в RAII. Я всегда для этого классы городил. Спасибо!
Deamhan Автор
Не за что. Вообще не думал, что малозначимые первые строки теста привлекут столько внимания. В принципе, можно и виндовые хэндлы так оборачивать через std::remove_pointer_t, правда выглядит это куда более «грязно».