
GNUplot
Наверное, это самое простое, что нам могли показать в первую очередь (за исключением, пожалуй, Word или Excel). Обработка данных с помощью гнуплота предельно проста и не требует особых знаний в программировании, язык близок к алгоритмическому. Идеально подходит для начала работы над графической обработкой данных.
Как пользоваться
Пусть у нас есть файл с данными — один столбец со значениями измерений какого-то параметра. Назовем этот файл data.dat. Мы знаем, что данные представляют собой нормальное распределение, пускай это будет распределение масс партии шурупов. Наша задача заключается в определении среднего значения массы шурупа. Мое решение заключается в построении гистограммы по данным и дальнейшей ее аппроксимации кривой . Ниже привожу пример кода такого построения:
bin_width=0.1
set boxwidth 0.9*bin_width absolute
bin_num(x)=floor(x/bin_width)
rounded(x)=bin_width*(bin_number(x)+0.5)
plot ‘data.dat’ using (rounded($1)):(1) smooth frequency with boxes
set table ‘table.dat’
replot #построение новой таблицы нужно, чтобы не покалечить аппроксимацией исходные данные
unset table
f(x)=a*exp(-(x-c)**2/b)
a=6#для точной аппроксимации необходимо "прикинуть" параметры сглаживающей кривой
b=0.01
c=2
fit f(x) ‘table.dat’ using 1:2 via a, b, c
plot f(x), ‘data.dat’ using (rounded($1)):(1) smooth frequency with boxes
При аппроксимации будут определены значения a, b и c с достаточно хорошей точностью. В нашей задаче нетрудно догадаться, что параметр c и есть среднее значение массы измеряемых объектов. Таким образом, с помощью простого кода и некоторых соображений можно быстро проанализировать собранные данные.
Мои выводы о работе с GNUplot
В случаях, когда нужна быстрая графическая обработка большого количества данных (большого в рамках лабораторной работы), GNUplot подходит идеально. Тем не менее, иногда появляются баги, о природе которых приходится подумать. Рекомендую использовать новичкам для каких-то базовых работ, например, статистических исследований.
LabVIEW
Этот монстр предназначен для настоящих лабников! Чисто визуальная платформа для моделирования лабораторной работы. Сама собирает данные с ComPortов, сама их обрабатывает, сама строит динамические графики. Возможностей — уйма. Большинство инженеров работают именно на Labview. НО! Требует больших усилий, чтобы разобраться.
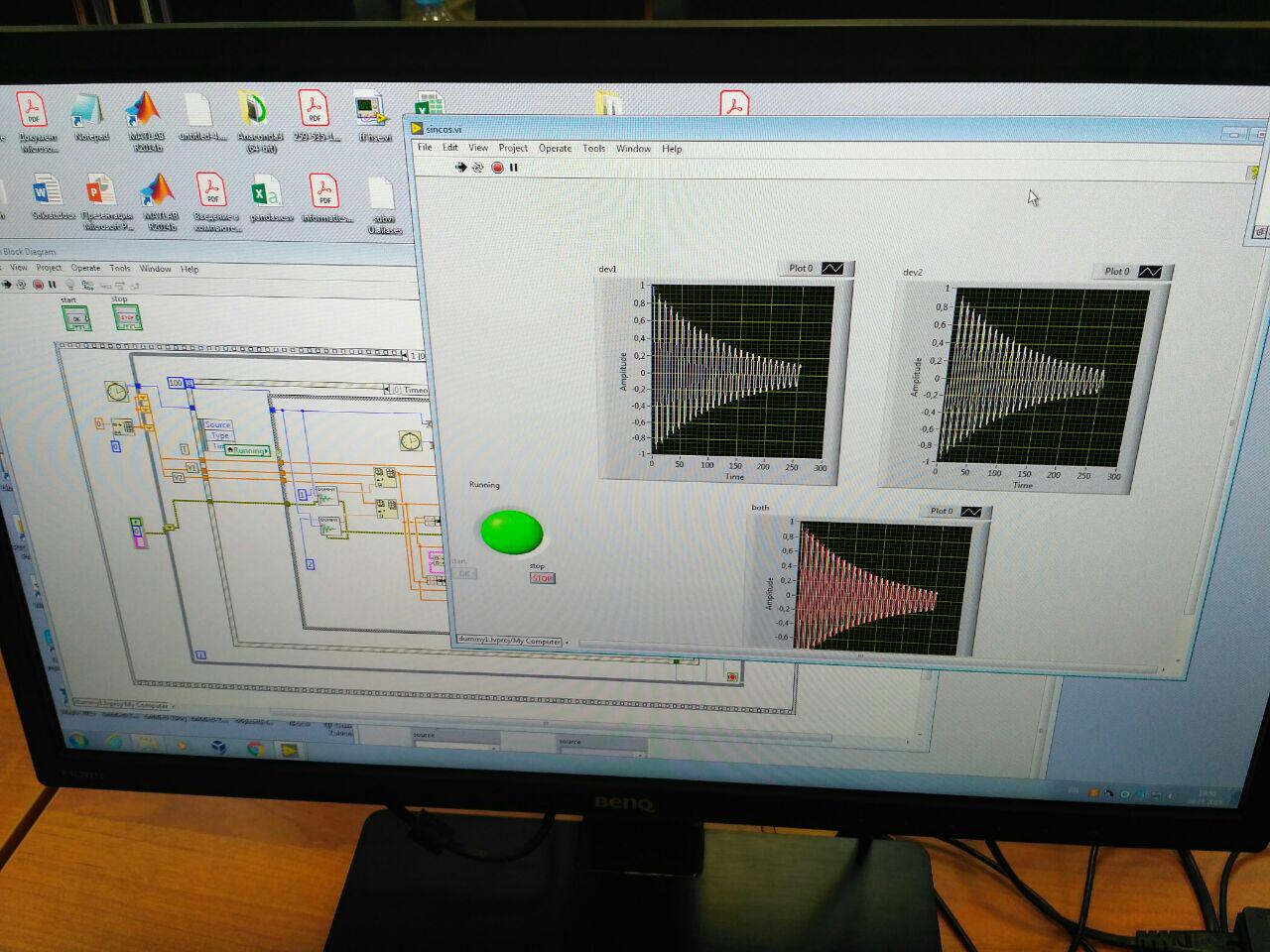
Мои выводы о работе с LabVIEW
Точно не для новичков! Если есть желание, можно посидеть пару дней и разобраться, после этого значительно сократится время обработки лабораторных работ, в которых вы можете использовать микроконтроллеры с датчиками (в моем случае это были лабораторные со всевозможными маятниками).

Python
Этот язык является отличной находкой для физиков. Чаще всего я использую его для решений задач вычислительной физики, к примеру, численное решение дифференциальных уравнений. Так же, как и гнуплот, этот язык хорош для графической обработки данных, обладает меньшим количеством багов и простотой синтаксиса (хотя и на гнуплот не жалуюсь). Лично мне больше нравится Python, но каждому — свое.
В качестве примера работы с Python привожу интерполяцию по точкам многочленом Лагранжа,
import numpy as np
import matplotlib.pyplot as plt
def f(x, y, t):
lag = 0
for j in range(len(y)):
n = 1
dn = 1
for i in range(len(x)): #Многочлен Лагранжа
if i == j:#Чтобы знаменатель не обращался в ноль
n = n * 1
dn = dn * 1
else:
n = n * (t - x[i])
dn = dn * (x[j] - x[i])
lag = lag + y[j] * n / dn
return lag
xk = np.linspace(-1, 1, 11)
yk = 1/(1+xk**2)
xnew = np.linspace(-1, 1, 200)
ynew = [f(xk, yk, i) for i in xnew]
plt.title(u'Интерполяция по точкам')
plt.xlabel(u'x')
plt.ylabel(u'y')
plt.plot(xk, yk, '.', xnew, ynew)
plt.grid()
plt.show()Мои выводы о работе с Python
Для меня Python является приоритетным. Гораздо больше возможностей, чем в GNUplot, не требует больших усилий, чтобы разобраться. Безусловно, использование Labview значительно профессиональнее, но так как
Вместо заключения
В этом небольшом обзоре я решила поделиться своим опытом использования некоторых программ для обработки данных. Надеюсь, он поможет вам в вашей исследовательской деятельности.
Успехов!
Комментарии (34)

GalVorbak
17.03.2019 20:49+1Как-то на самом деле не очень подробно раскрыта тема обработки данных :(
По своему опыту практики на ускорителе могу сказать, что пусть и не самый простой, но один из лучших пакетов для анализа и визуализации данных — ROOT от CERN. Набор возможностей просто колоссальный.
Ivanii
17.03.2019 21:04Когда приспичило лил данные с Ардуинки в Эксель через ком порт, а обратно команды управления, почти без потерь(строка раз в секунду, 1 — 2 строки терялись за 8 — 12 часов) и достаточно удобно, можно просто пририсовать любую аналитику и графики.
SvOlAl Автор
17.03.2019 21:12Хорошая идея!
Графики все-таки больше нравится строить в Python, но когда время поджимает, Эксель выручает.Ivanii
17.03.2019 21:16Нужны были не только графики, а нужны были зависимости от действий и поведение датчиков во времени, эксперимент в общем провалился но без этой аналитики еще долго пытались-бы идти этим путем.
surius
17.03.2019 21:32+2когда бедный студент, собирая данные с доисторического оборудования, замеряя период колебаний с помощью таймера вручную, мучительно пытается найти объяснение нереалистичности данных
<немного оффтопа>
Многим поколениям физиков и ученых других дисциплин ничего не мешало снимать аналоговые данные и получать реалистичные данные. Так что видимо наличие мк не является ни необходимым, ни достаточным условием… Особенно если мы речь ведем ни об исследовательской работе а об учебной. </немного оффтопа>
Для себя давно останови выбор на OriginPro от OriginLab. Но это скорее «ручной инструмент», который сроден exel, но более гибокий и результаты вызуализации красивее.
Еще, из общих соображений, конкуренцию питону может составить любой язык программирования. Другой вопрос что вызуализация в фортране например заметно более трудоемкая штука.SvOlAl Автор
17.03.2019 21:51Совершенно согласна, многие люди умеют выполнять эксперимент аккуратно. Я, к сожалению, не обладаю этим качеством. В целом, мне кажется, обеспечение учеников хорошим оборудованием — хорошая тенденция в наше время. Это заранее позволяет подготовить студента к «реальной» научной работе. Бонусом идет экономия времени и сил:) Повторюсь — это мое субъективное мнение.
Я пробовала Origin, но отношения с этим ПО далеко не пошли, быстро переключилась на Python. Ни в коем случае не претендую на то, чтобы называть Python единственным хорошим средством для обработки данных, лишь делюсь своим опытом и своими предпочтениями:)
McAaron
18.03.2019 19:07Все зависит от того, для чего график строится. Если для себя, это одно, если в издательство — другое. Поэтому одного инструмента никогда не будет. Для себя можно и эксель использовать, но с его помощью делать иллюстрацию в статью или доклад согласно требованиям издательства — это реально геморрой. Обычно издательство, исходя из требований к материалам и формату файла, само предлагает наиболее подходящий инструмент и даже шаблон-пример. При этом не исключаются и другие инструменты, но может оказаться так, что те, с которыми ты как-бы всех собак поел, принципиально не могут выдать требуемое, как бы не упирался. В таком случае проще и быстрее с нуля изучить инструмент и выполнит ь работу. Как говорится в известном мультике: "… лучше день потерять, потом за пять минут долететь...".
Я для себя во всех случаях использую gnuplot, который однажды освоил как раз по причине того, что ничем другим не получалось сделать иллюстрации, которые бы удовлетворили издательство.
Что я только не пробовал, потратил реально неделю на борьбу с тиками, шрифтами и прочими атрибутами, но получить результат, визуально и стилистически удовлетворяющий требованиям, так и не получилось. Однако, с gnuplot'ом все разрешилось менее, чем за час, включая освоение инструмента — выручил именно шаблон-пример, который уже содержал полностью все стилистическое от издательства, и мне пришлось возиться только с данными и подписями.

Shkaff
17.03.2019 21:40+2Python (Numpy+matplotlib) + Jupyter = идеальный ежедневный инструмент обработки и анализа данных, в том числе для совместной работы.
А вообще какое-то странное сравнение: Labview — это же для сбора данных и управления экспериментом, а совсем не для обработки. Gnuplot — в первую очередь для визуализации, а не для обработки. И только питон более или менее подходит под название статьи, хотя есть полно специализированных пакетов.SvOlAl Автор
17.03.2019 22:08+1Мне приятно, что вы поддерживаете мое мнение по поводу Python:)
Ваше замечание касательно Labview действительно значимое. Labview умеет собирать данные и визуализировать их, но анализом приходится заниматься дополнительно, если это требуется.
Я привела пример обработки данных на Gnuplot, иногда (в ситуациях нехватки знаний языков программирования), мне кажется, это проще и быстрее, чем использовать Excel. Правда, это лишь мое личное мнение, мой опыт. Думаю, найдется мало людей с абсолютно схожими предпочтениями в способах обработки данных.Shkaff
17.03.2019 22:19+2На самом деле, с питоном получается удобный воркфлоу. Например, я использую atom+hydrogen для питона, в нем куча удобных фич (почти как ide), хорошая интеграция с гит/гитхаб и при этом там же можно latex писать с подсветкой кода и т.п. Как итог, можно в одном окружении и репозитории иметь и заметки с описанием работы и уравнениями (в latex), и данные, и собственно код для их анализа. Очень рекомендую:)
А gnuplot подходит для совсем уж простой обработки… везде, где нужно что-то более сложное, статистика или какие-нибудь многопараметрические функции — питон выигрывает по всем показателям. При этом python+seaborn производит графики не хуже gnuplotа.SvOlAl Автор
17.03.2019 22:33+1Большое спасибо за советы! Признаюсь, про редакторы не слышала, я думаю, вы мне очень упростили жизнь этой информацией:)
Shkaff
18.03.2019 00:12+1Не за что, надеюсь;) Для питона я долго пользовался IDE pycharm, но он тяжеловат, и ipython был ужасен. Не так давно открыл для себя atom и абсолютно по этому поводу счастлив, pycharm больше не запускал:) Как вариант, есть spyder, он идет по дефолту с anaconda (ее тоже рекомендую для научных целей) и заточен на научную разработку.
i_andreev
18.03.2019 00:00+1 к LabView. Это графическая среда программирования, ориентированная на автоматизацию эксперимента, а не на обработку данных.
qbertych
18.03.2019 00:38Вообще да.
При этом некоторые задачи, скажем, image processing'а LabVIEW решеет быстрее Matlab'а. С учетом того, что последний оптимизирован для работы с матрицами, это довольно неожиданно.

Sergey371
17.03.2019 22:52Python конечно инструмент универсальный, как напишешь так и обработаешь, но требует навыков и наработок. Для собственно обработки и анализа данных могу порекомендовать MatLab.
Shkaff
18.03.2019 00:05+1Справедливости ради, Python c numpy/scipy делает то же, что Matlab, только бесплатно;)
Matlab удобнее разве что для совсем начала, чтобы без программирования — чисто через тулбоксы.qbertych
18.03.2019 00:44А у тебя есть опыт работы с сырыми данными в Mathematica? В последнее время слышал немало положительных отзывов, хотя по личному опыту — ужас-ужас.
Shkaff
18.03.2019 09:07Небольшой опыт есть, но не очень положительный тоже.
Я всю аналитику проверяю в mathematica, и тут все ок, а вот нужно было делать фиты и монте-карло, и там все как-то очень медленно: 100 запусков по 1000 семплов занимали больше суток расчета. Может, правда, это кривизна рук:)
Мне в целом не очень понятно, как в ней адекватно работать с написанием своих функций эффективно… после питона все выглядит как-то костыльно. Но опять же, я не задавался целью это все изучить подробно.
Fox_Alex
18.03.2019 01:23LabView нужно, когда в установке собрано 100500 разношерстных готовых приборов и датчиков. Все современные осциллографы, генераторы и даже некоторые породистые мультиметры работают с лабвью из коробки. Писать на питоне свой драйвер для каждого из них будет намного дольше, чем освоить птичью грамоту графического интерфейса.
Ну а в случае простой установки на самопальных приборах — гораздо удобнее написать свой простенький сбор данных, чем учить свои датчики общению с лабвью.

dee3mon
18.03.2019 08:45+1Все-таки стоит разделять этапы сбора данных и их обработки.
На этапе обработки уже лет 15 назад вовсю преподавателями рекомендовалось использовать автоматизацию расчетов, с тем же экселем, например. Максимум во время одной из первых лаб с большим числом данных заставляли прочуствовать всю глубину статистики и больших таблиц формата а4, дальше все, чем считаешь не волновало никого.
А вот с этапом сбора данных все менее однозначно. С одной стороны, автоматический сбор данных это быстро и эффектно, выглядит круто, и вообще современные приборы все под автоматизацией. Однако, если весь этот стенд, включая выбор датчиков, управляющего устройства и какое никакое программирование, студент собирает не сам, а берет готовый в лабе, то вся эта лаба практически ничем не отличается от нажатия кнопки в каком-нибудь симуляторе. Ручная же работа с базовыми измерительными приборами дает очень четкое понимание что вообще происходит. Наравне со старым парком приборов это одна из главных причин, что в предметах с железячными лабами до сих пор много работы вручную (если это не предмет, посвященный автоматизации, естественно).
P. S. А Labview это вообще для инопланетян, у меня на переписование в качестве саморазвития простенького алгоритма на 30 строк (правда, со вложенными циклами и ветвлением) ушло 3,5 дня.SvOlAl Автор
18.03.2019 08:56Очень здорово, если в большинстве университетов используют Эксель. Я столкнулась с тем, что многие мои знакомые из разных вузов (МГУ, МИФИ) достаточно редко используют что-то помимо бумаги и ручки.
У нас (в ВШЭ) лабораторные проходили так: каждому студенту вручались отдельно платы, датчики, провода и т. д. и т. п., далее каждый (с помощью преподавателя или без) собирал все это дело, подключал и сам писал программу. Мне кажется, это достаточно хороший подход, который не уменьшит понимание происходящего.dee3mon
18.03.2019 10:11Это крутой подход к лабам, без шуток. Но я так понимаю, к этому моменту уже должен быть приличный багаж по составлению измерительных стендов. И программировать уже надо уметь. Иначе все время уйдёт только на подготовку этого стенда. Сколько у вас вообще времени выделено на лабу целиком и на подготовку стенда?
SvOlAl Автор
18.03.2019 13:24На лабы выделен один день (пять пар) Сюда входит время всего, что связано с лабораторной. Обработкой данных обычно занимаемся дома, на все две недели, дальше защита работы перед преподавателем.
На подготовку к началу лабораторных работ был отдельно выделен модуль, в течение которого мы учились программировать.
Polaris99
18.03.2019 14:59LabView для сбора и обработки данных? Автор точно ничего не попутал? LabView вообще ценна поддержкой измерительных устройств из коробки, а не тем, как эти данные потом обрабатываются.
SvOlAl Автор
18.03.2019 16:07Выше я комментировала похожее замечание:
Ваше замечание касательно Labview действительно значимое. Labview умеет собирать данные и визуализировать их, но анализом приходится заниматься дополнительно, если это требуется.
t2ton
18.03.2019 20:26+2Как учёный физик(15 лет стаж) докину свои три капли:
- Сбор от инструментов, связка, первичная обработка и сохранение — лабвью без вариантов. Ну или одной софт инструмента, живущий по собственным законам..
- Обработка — тот же лабвью (мой выбор ибо мне лениво синтаксис учить) для сравнительно простых вещей или Матлаб для всего остального. К нему написана куча пакетов, анализ многомерных данных, статистика и тд. Как только у вас появляется больше одного измерения — все остальное нервно курит в углу, а Эксель ещё и тихонько навзрыд. Кто то использует математику, но это, имхо, изврат.
2б. Простейшая обработка одномерных данных — Эксель и Origin. В ориджине удобно работать колонками, но просто адски неудобно ссылаться на индивидуальные ячейки — в итоге связка ориджин+эксель лучшая и быстрая.
Также Ориджин хорошо работает с фитированием и "графической" обработкой. - Построение всех видов двухмерных графиков — Ориджин без вариантов. Простой, удобный, красивый и настраиваемый. Куча темплейтов для различных журналов и тд.
Уже Матлаб тут курит, а Эксель уже рыдает навзрыд, ибо понимает, что урод :) - Трехмерные графики строить сложно везде. Частично возможно в ориджине, но вращение и настройка просто ужасные, в итоге самые удачные — разнесение по одной оси или яркостная диаграмма.
Знание питона и др. конечно может сильно помочь — можно дописать процедуры которых нет. Почти во всех упомянутых "программах" есть возможность дописывать свои процедуры на общепринятых языках.
SvOlAl Автор
18.03.2019 21:17Большое спасибо за такой подробный и информативный комментарий! :)
Мне приятно, что вы поделились своим ценным опытом, теперь попробую освоить Origin (увы, с первого раза не пошло).
qbertych
19.03.2019 06:06Люто плюсую Origin — он умеет строить абсолютно любые двумерные графики. А еще делать их сколь угодно красивыми (настраивается абсолютно все), экспортировать их во множество форматов, работать через GUI и командную строку — это не говоря о базовой обработке данных (фиты/статистика) и прочих мелких радостях жизни.
Главный минус — он не бесплатен, причем довольно сильно.
KennyGin
Это в каких российских вузах сейчас микроконтроллеры на физических лабах для студентов?
SvOlAl Автор
На физическом факультете Высшей школы экономики :)
Sergey371
Для физиков конечно отличная технология, вполне современно (y)
Shamrel
Сибирский государственный университет телекоммуникаций и информатики. На множестве кафедр. Сам лично разрабатывал и внедрял.