Сегодня я вам расскажу, как нам удалось решить задачу портирования Spark Structured Streaming Applications на Kubernetes (K8s) и реализовать CI стриминга.
Стриминг выступает ключевым компонентом BI-платформы ФАСТЕН РУС. Real-time данные используются командой дата анализа для построения оперативных отчетов.
Стриминговые приложения реализованы средствами Spark Structured Streaming. Этот фрэймворк обеспечивает удобный API трансформации данных, что отвечает нашим потребностям в плане оперативности доработок.
Сами стримы поднимались на кластере AWS EMR. Таким образом при подъёме нового стрима на кластер выкладывался ssh-скрипт на сабмит Spark-джобы, после чего запускалось приложение. И сначала нас всё вроде бы устраивало. Но с ростом числа стримов становилась всё более очевидной потребность в реализации CI стриминга, что повысило бы автономность команды дата анализа при запуске приложений на доставку данных по новым сущностям.
И сейчас мы рассмотрим, как нам удалось решить эту проблему путём портирования стриминга на Kubernetes.
Kubernetes как менеджер ресурсов в наибольшей степени отвечал нашим потребностям. Это и деплой без даунтайма, и широкий набор инструментов реализации CI на Kubernetes, включая Helm. Кроме того, наша команда обладала достаточной экспертизой по реализации CI-пайплайнов на K8s. Поэтому выбор был очевиден.

Клиент запускает spark-submit на K8s. Cоздаётся pod драйвера приложения. Kubernetes Scheduler привязывает pod к ноде кластера. Затем драйвер отправляет запрос на создание pod’s для запуска экзекьютеров, поды создаются и привязываются к нодам кластера. После чего выполняется стандартный набор операций с последующей конвертацией кода приложения в DAG, декомпозицией на stages, разбивкой на таски и их запуском на экзекьютерах.
Эта модель вполне успешно работает при ручном старте Spark-приложений. Однако, подход c запуском spark-submit вне кластера не устраивал нас с точки зрения реализации CI. Требовалось найти решение, которое позволило бы запускать Spark-джобу (выполнять spark-submit) непосредственно на нодах кластера. И здесь нашим требованиям вполне отвечала модель Kubernetes Operator.
Kubernetes Operator — концепция управления statefull-приложениями в Kubernetes, предложенная CoreOS, которая предполагает автоматизацию эксплуатационных задач, таких как деплой приложений, рестарт приложений в случае фэйлов, обновление конфигурации приложений. Одним из ключевых паттернов Kubernetes Operator выступает CRD (CustomResourceDefinitions), который предполагает добавление в кластер K8s кастомных ресурсов, что, в свою очередь, позволяет работать с этими ресурсами как с нативными объектами Kubernetes.
Operator представляет собой демон, который живет в pod’е кластера и реагирует на создание / изменения состояния кастомного ресурса.
Рассмотрим эту концепцию применительно к управлению жизненным циклом Spark-приложений.
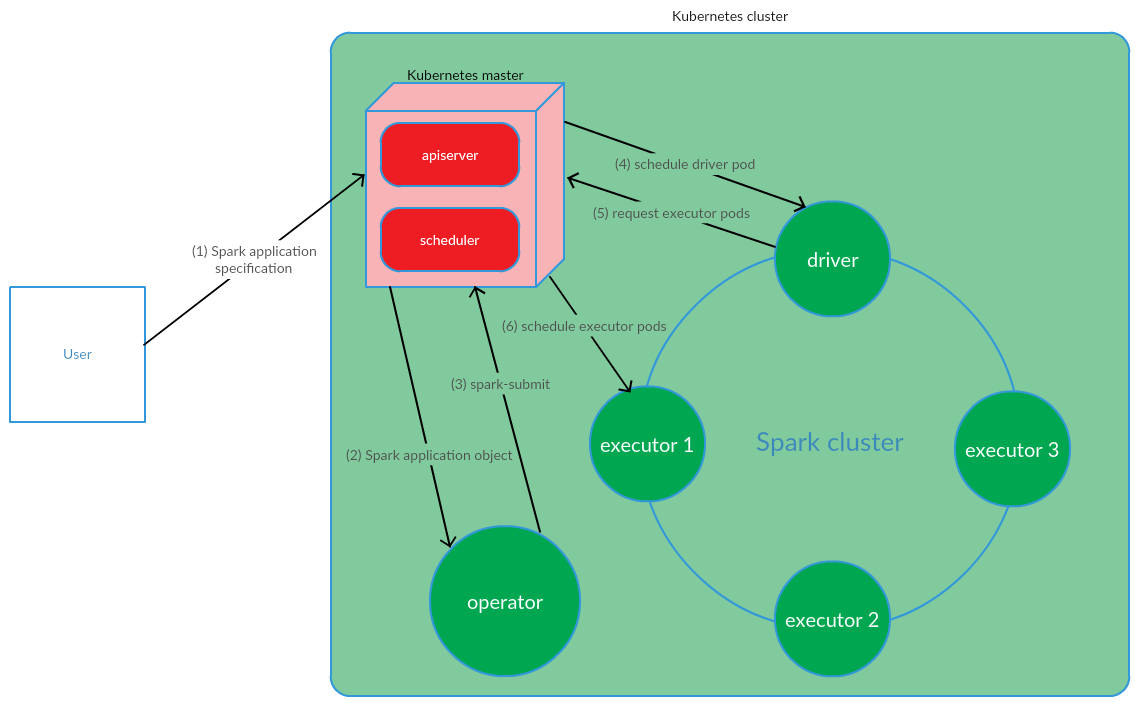
Пользователь выполняет команду kubectl apply -f spark-application.yaml, где spark-application.yaml — спецификация Spark-приложения. Operator получает объект Spark-приложения и выполняет spark-submit.
Как мы можем видеть, модель Kubernetes Operator предполагает управление жизненным циклом Spark-приложения непосредственно в кластере Kubernetes, что выступало серьезным аргументом в пользу данной модели в контексте решения наших задач.
В качестве Kubernetes Operator для управления стриминговыми приложениями было принято решение использовать spark-on-k8s-operator. Этот оператор предлагает достаточно удобный API, а также отличается гибкостью в настройке политики рестартов Spark-приложений (что достаточно важно в контексте поддержки стриминговых приложений).
Для реализации CI стриминга использовался GitLab CI/CD. Деплой Spark-приложений на K8s проводился средствами Helm.
Сам пайплайн предполагает 2 стадии:
Рассмотрим подробнее эти стадии.
На стадии test проводится рендеринг Helm-шаблона Spark-приложений (CRD — SparkApplication) значениями, специфичными для сред.
Ключевыми разделами Helm-шаблона выступают:
После выполнения рендеринга шаблона приложения деплоятся на тестовую среду dev средствами Helm.
Отработал CI-пайплайн.
После чего запускаем джобу deploy-prod — запуск приложений в продакшен.
Убеждаемся в успешном выполнении джобы.
Как мы можем видеть ниже, приложения запущены, поды — в статусе RUNNING.

Портирование Spark Structured Streaming Applications на K8s и последующая реализация CI позволили автоматизировать запуск стримов на доставку данных по новым сущностям. Для подъёма очередного стрима достаточно подготовить Merge Request с описанием конфигурации Spark-приложения в yaml-файле значений и при запуске джобы deploy-prod будет инициирована доставка данных в DWH (Redshift) / Data Lake (S3). Это решение обеспечило автономность команды дата анализа при выполнении задач, связанных с добавлением в хранилище новых сущностей. Кроме того, портирование стриминга на K8s и, в частности, управление Spark-приложениями средствами Kubernetes Operator spark-on-k8s-operator существенно повысили отказоустойчивость стриминга. Но об этом уже в следующей статье.
Как всё начиналось?
Стриминг выступает ключевым компонентом BI-платформы ФАСТЕН РУС. Real-time данные используются командой дата анализа для построения оперативных отчетов.
Стриминговые приложения реализованы средствами Spark Structured Streaming. Этот фрэймворк обеспечивает удобный API трансформации данных, что отвечает нашим потребностям в плане оперативности доработок.
Сами стримы поднимались на кластере AWS EMR. Таким образом при подъёме нового стрима на кластер выкладывался ssh-скрипт на сабмит Spark-джобы, после чего запускалось приложение. И сначала нас всё вроде бы устраивало. Но с ростом числа стримов становилась всё более очевидной потребность в реализации CI стриминга, что повысило бы автономность команды дата анализа при запуске приложений на доставку данных по новым сущностям.
И сейчас мы рассмотрим, как нам удалось решить эту проблему путём портирования стриминга на Kubernetes.
Почему Kubernetes?
Kubernetes как менеджер ресурсов в наибольшей степени отвечал нашим потребностям. Это и деплой без даунтайма, и широкий набор инструментов реализации CI на Kubernetes, включая Helm. Кроме того, наша команда обладала достаточной экспертизой по реализации CI-пайплайнов на K8s. Поэтому выбор был очевиден.
Как организована модель управления Spark-приложениями на базе Kubernetes?
Клиент запускает spark-submit на K8s. Cоздаётся pod драйвера приложения. Kubernetes Scheduler привязывает pod к ноде кластера. Затем драйвер отправляет запрос на создание pod’s для запуска экзекьютеров, поды создаются и привязываются к нодам кластера. После чего выполняется стандартный набор операций с последующей конвертацией кода приложения в DAG, декомпозицией на stages, разбивкой на таски и их запуском на экзекьютерах.
Эта модель вполне успешно работает при ручном старте Spark-приложений. Однако, подход c запуском spark-submit вне кластера не устраивал нас с точки зрения реализации CI. Требовалось найти решение, которое позволило бы запускать Spark-джобу (выполнять spark-submit) непосредственно на нодах кластера. И здесь нашим требованиям вполне отвечала модель Kubernetes Operator.
Kubernetes Operator как модель управления жизненным циклом Spark-приложения
Kubernetes Operator — концепция управления statefull-приложениями в Kubernetes, предложенная CoreOS, которая предполагает автоматизацию эксплуатационных задач, таких как деплой приложений, рестарт приложений в случае фэйлов, обновление конфигурации приложений. Одним из ключевых паттернов Kubernetes Operator выступает CRD (CustomResourceDefinitions), который предполагает добавление в кластер K8s кастомных ресурсов, что, в свою очередь, позволяет работать с этими ресурсами как с нативными объектами Kubernetes.
Operator представляет собой демон, который живет в pod’е кластера и реагирует на создание / изменения состояния кастомного ресурса.
Рассмотрим эту концепцию применительно к управлению жизненным циклом Spark-приложений.
Пользователь выполняет команду kubectl apply -f spark-application.yaml, где spark-application.yaml — спецификация Spark-приложения. Operator получает объект Spark-приложения и выполняет spark-submit.
Как мы можем видеть, модель Kubernetes Operator предполагает управление жизненным циклом Spark-приложения непосредственно в кластере Kubernetes, что выступало серьезным аргументом в пользу данной модели в контексте решения наших задач.
В качестве Kubernetes Operator для управления стриминговыми приложениями было принято решение использовать spark-on-k8s-operator. Этот оператор предлагает достаточно удобный API, а также отличается гибкостью в настройке политики рестартов Spark-приложений (что достаточно важно в контексте поддержки стриминговых приложений).
Реализация CI
Для реализации CI стриминга использовался GitLab CI/CD. Деплой Spark-приложений на K8s проводился средствами Helm.
Сам пайплайн предполагает 2 стадии:
- test — проводится проверка синтаксиса, а также рендеринг Helm-шаблонов;
- deploy — деплой стриминговых приложений на тестовую (dev) и продуктовую (prod) среды.
Рассмотрим подробнее эти стадии.
На стадии test проводится рендеринг Helm-шаблона Spark-приложений (CRD — SparkApplication) значениями, специфичными для сред.
Ключевыми разделами Helm-шаблона выступают:
- spark:
- version — версия Apache Spark
- image — используемый Docker-образ
- nodeSelector — содержит список (key > value), соответствующих лэйблам подов.
- tolerations — указывается список толерейшенов Spark-приложения.
- mainClass — класс Spark-приложения
- applicationFile — локальный путь, где находится jar-файл Spark-приложения
- restartPolicy — политика рестартов Spark-приложения
- Never — завершенное Spark-приложение не рестартуется
- Always — завершенное Spark-приложение рестартуется независимо от причины остановки
- OnFailure — Spark-приложение рестартуется только в случае фэйла
- maxSubmissionRetries — максимальное число сабмитов Spark-приложения
- driver/executor:
- cores — количество ядер, выделяемых драйверу/экзекьютору
- instances (используется только для конфигурации экзекьютеров) — число экзекьюторов
- memory — объём памяти, выделяемой процессу драйвера/экзекьютора
- memoryOverhead — объём off-heap memory, выделяемой драйверу/экзекьютору
- streams:
- name — наименование стримингового приложения
- arguments — аргументы стримингового приложения
- sink — путь к датасетам Data Lake на S3
После выполнения рендеринга шаблона приложения деплоятся на тестовую среду dev средствами Helm.
Отработал CI-пайплайн.
После чего запускаем джобу deploy-prod — запуск приложений в продакшен.
Убеждаемся в успешном выполнении джобы.
Как мы можем видеть ниже, приложения запущены, поды — в статусе RUNNING.
Заключение
Портирование Spark Structured Streaming Applications на K8s и последующая реализация CI позволили автоматизировать запуск стримов на доставку данных по новым сущностям. Для подъёма очередного стрима достаточно подготовить Merge Request с описанием конфигурации Spark-приложения в yaml-файле значений и при запуске джобы deploy-prod будет инициирована доставка данных в DWH (Redshift) / Data Lake (S3). Это решение обеспечило автономность команды дата анализа при выполнении задач, связанных с добавлением в хранилище новых сущностей. Кроме того, портирование стриминга на K8s и, в частности, управление Spark-приложениями средствами Kubernetes Operator spark-on-k8s-operator существенно повысили отказоустойчивость стриминга. Но об этом уже в следующей статье.
Yo1
Стриминг выступает ключевым компонентом BI-платформы ФАСТЕН РУС. Real-time данные используются командой дата анализа для построения оперативных отчетов.
глупый вопрос — а как с S3 данные оперативно в BI платформы попадают?
sergeysamsonov Автор
данные стримятся как в S3 (для обучения нейросетей), так и в DWH (для построения отчетности)
sergeysamsonov Автор
Соответственно, в Data Lake — история, в DWH — данные по ивентам за последние 3 месяца.