TL;DR: Четыре года назад я покинул Google с идеей нового инструмента для мониторинга серверов. Идея состояла в том, чтобы объединить в одну службу обычно изолированные функции сбора и анализа логов, сбора метрик, оповещений и панели мониторинга. Один из принципов — сервис должен быть действительно быстрым, обеспечивая девопсам лёгкую, интерактивную, приятную работу. Это требует обработки наборов данных по несколько гигабайт за доли секунды, не выходя за рамки бюджета. Существующие инструменты для работы с логами часто медленные и неуклюжие, поэтому мы столкнулись с хорошей задачей: грамотно разработать инструмент, чтобы дать пользователям новые ощущения от работы.
В этой статье описывается, как мы в Scalyr решили эту проблему, применив методы старой школы, подход грубой силы, устранив лишние слои и избегая сложных структур данных. Эти уроки вы можете применить к собственным инженерным задачам.
Анализ логов обычно начинается с поиска: найти все сообщения, соответствующие некоторому шаблону. В Scalyr это десятки или сотни гигабайт логов со многих серверов. Современные подходы, как правило, предполагают построение некоей сложной структуры данных, оптимизированной для поиска. Я, конечно, видел такое в Google, где они довольно хороши в таких вещах. Но мы остановились на гораздо более грубом подходе: линейное сканирование логов. И это сработало — мы обеспечиваем интерфейс с поиском на порядок быстрее, чем у конкурентов (см. анимацию в конце).
Ключевым озарением стало то, что современные процессоры действительно очень быстры в простых, прямолинейных операциях. Это легко упустить в сложных, многослоистых системах, которые зависят от скорости I/O и сетевых операций, а такие системы сегодня очень распространены. Таким образом, мы разработали дизайн, который минимизирует количество слоёв и лишнего мусора. С несколькими процессорами и серверами параллельно скорость поиска достигает 1 ТБ в секунду.
Ключевые выводы из этой статьи:
(В этой статье описывается поиск данных в памяти. В большинстве случаев, когда пользователь выполняет поиск по логам, серверы Scalyr уже кэшировали их. В следующей статье обсудим поиск по некэшерованным логам. Применяются те же принципы: эффективный код, метод грубой силы с большими вычислительными ресурсами).
Традиционно, поиск в большом наборе данных производится по индексу ключевых слов. Применительно к серверным логам это означает поиск каждого уникального слова в журнале. Для каждого слова нужно составить список всех включений. Это позволяет легко найти все сообщения с этим словом, например 'error', 'firefox' или «transaction_16851951» — просто смотрим в индексе.
Я использовал такой подход в Google, и он работал хорошо. Но в Scalyr мы ищем в логах байт за байтом.
Почему? С абстрактной алгоритмической точки зрения индексы ключевых слов гораздо эффективнее, чем грубый поиск. Однако мы не продаём алгоритмы, мы продаём производительность. И производительность — это не только алгоритмы, но и системная инженерия. Мы должны учитывать всё: объём данных, тип поиска, доступное оборудование и программный контекст. Мы решили, что для нашей конкретной проблемы вариант вроде 'grep' подходит лучше, чем индекс.
Индексы — это отлично, но у них есть ограничения. Одно слово найти легко. А вот поиск сообщений с несколькими словами, такими как 'googlebot' и '404' — уже намного сложнее. Поиск фразы вроде 'uncaught exception' требует более громоздкого индекса, который регистрирует не только все сообщения с этим словом, но и конкретное местоположение слова.
Настоящая трудность возникает, когда вы ищете не слова. Предположим, вы хотите посмотреть, сколько трафика приходит от ботов. Первая мысль — поиск в логах по слову 'bot'. Так вы найдёте некоторых ботов: Googlebot, Bingbot и многих других. Но здесь 'bot' — это не слово, а его часть. Если искать 'bot' в индексе, мы не найдём сообщений со словом 'Googlebot'. Если проверять каждое слово в индексе и затем сканировать индекс по найденным ключевикам, поиск сильно замедлится. В результате некоторые программы для работы с логами не разрешают поиск по частям слова или (в лучшем случае) позволяют использовать специальный синтаксис с более низкой производительностью. Мы хотим этого избежать.
Ещё одна проблема — пунктуация. Хотите найти все запросы от
Наконец, инженеры любят мощные инструменты, а иногда проблему можно решить только регулярным выражением. Индекс ключевых слов не очень подходит для этого.
Кроме того, индексы сложны. Каждое сообщение нужно добавить в несколько списков ключевых слов. Эти списки следует постоянно держать в удобном для поиска формате. Запросы с фразами, фрагментами слов или регулярными выражениями нужно переводить в операции с несколькими списками, а результаты сканировать и объединять для получения результирующего набора. В контексте крупномасштабной многопользовательской службы такая сложность создаёт проблемы производительности, которые не видны при анализе алгоритмов.
Индексы ключевых слов также занимают много места, а хранилище — основная статья расходов в системе управления логами.
С другой стороны, на каждый поиск можно потратить много вычислительной мощности. Наши пользователи ценят высокоскоростной поиск по уникальным запросам, но такие запросы делаются относительно редко. Для типичных поисковых запросов, например, для панели мониторинга, мы применяем специальные приёмы (опишем их в следующей статье). Другие запросы достаточно редки, так что редко приходится обрабатывать более одного за раз. Но это не значит, что наши серверы не заняты: они загружены работой по приёму, анализу и сжатию новых сообщений, оценке оповещений, сжатию старых данных и так далее. Таким образом, у нас довольно существенный запас процессоров, которые можно задействовать для выполнения запросов.
Грубая сила лучше всего работает на простых задачах с маленькими внутренними циклами. Часто вы можете оптимизировать внутренний цикл для работы на очень высоких скоростях. Если код сложный, то намного труднее его оптимизировать.
Первоначально в нашем коде для поиска был довольно большой внутренний цикл. Мы храним сообщения на страницах по 4K; каждая страница содержит некоторые сообщения (в UTF-8) и метаданные для каждого сообщения. Метаданные — это структура, в которой закодированы длина значения, внутренний ID сообщения и другие поля. Цикл поиска выглядел так:

Это упрощённый вариант по сравнению с фактическим кодом. Но даже здесь видно несколько размещений объекта, копий данных и вызовов функций. JVM довольно хорошо оптимизирует вызовы функций и выделяет эфемерные объекты, поэтому этот код работал лучше, чем мы того заслуживали. Во время тестирования клиенты довольно успешно им пользовались. Но в конце концов мы перешли на новый уровень.
(Вы можете спросить, почему мы храним сообщения в таком формате со страницами по 4K, текстом и метаданными, а не работаем с логами напрямую. Есть много причин, которые сводятся к тому, что внутренне движок Scalyr больше похож на распределённую базу данных, чем на файловую систему. Текстовый поиск часто сочетается с фильтрами в стиле СУБД на полях после парсинга логов. Мы можем одновременно искать по многим тысячам логов одновременно, и простые текстовые файлы не подходят для нашего транзакционного, реплицированного, распределённого управления данными).
Изначально казалось, что такой код не очень подходит для оптимизации под метод грубой силы. «Настоящая работа» в
Так получилось, что мы храним метаданные в начале каждой страницы, а текст всех сообщений в UTF-8 упакован в другом конце. Воспользовавшись этим, мы переписали цикл для поиска сразу по всей странице:
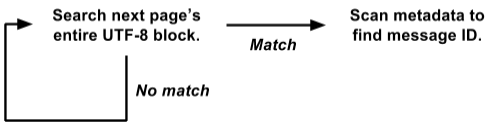
Такая версия работает непосредственно на представлении
Это гораздо легче оптимизировать для метода грубой силы. Внутренний поисковый цикл вызывается одновременно для всей страницы 4K, а не отдельно на каждом сообщении. Нет ни копирования данных, ни выделения объектов. И более сложные операции с метаданными вызываются только при положительном результате, а не на каждое сообщение. Таким образом, мы исключили тонну накладных расходов, а остальная нагрузка сосредоточена в небольшом внутреннем цикле поиска, который хорошо подходит для дальнейшей оптимизации.
Наш фактический поисковый алгоритм основан на отличной идее Леонида Вольницкого. Он похож на алгоритм Бойера — Мура с пропуском примерно длины поисковой строки на каждом шаге. Главное отличие в том, что он проверяет два байта за раз, чтобы минимизировать ложные совпадения.
Наша реализация требует для каждого поиска создания поисковой таблицы 64K, но это ерунда по сравнению с гигабайтами данных, в которых мы ищем. Внутренний цикл обрабатывает несколько гигабайт в секунду на одном ядре. На практике стабильная производительность составляет около 1,25 ГБ в секунду на каждом ядре, и есть потенциал для улучшения. Можно устранить некоторые накладные расходы за пределами внутреннего цикла, и мы планируем поэкспериментировать c внутренним циклом на C вместо Java.
Мы обсудили, что поиск по логам можно реализовать «грубо», но сколько «силы» у нас есть? Немало.
1 ядро: при правильном использовании одно ядро современного процессора довольно мощное само по себе.
8 ядер: в настоящее время мы работаем на серверах Amazon hi1.4xlarge и i2.4xlarge SSD, на каждом из которых 8 ядер (16 потоков). Как упоминалось выше, обычно эти ядра заняты фоновыми операциями. Когда пользователь выполняет поиск, то фоновые операции приостанавливаются, освобождая все 8 ядер для поиска. Поиск обычно завершается за долю секунды, после чего фоновая работа возобновляется (программа-регулятор гарантирует, что шквал поисковых запросов не помешает важной фоновой работе).
16 ядер: для надёжности мы организуем серверы по группам master/slave. У каждого мастера в подчинении один сервер SSD и один EBS. Если главный сервер падает, то сервер на SSD немедленно занимает его место. Почти всё время master и slave работают нормально, так что каждый блок данных доступен для поиска на двух разных серверах (у подчинённого сервера EBS слабый процессор, поэтому мы его не рассматриваем). Делим задачу между ними, так что у нас доступны в общей сложности 16 ядер.
Много ядер: в ближайшем будущем мы распределим данные по серверам таким образом, чтобы все они участвовали в обработке каждого нетривиального запроса. Будет работать каждое ядро. [Примечание: мы реализовали план и повысили скорость поиска до 1 ТБ/с, см. примечание в конце статьи].
Ещё одно преимущество метода грубой силы заключается в довольно стабильной производительности. Как правило, поиск не слишком чувствителен к деталям задачи и набора данных (думаю, именно поэтому его называют «грубым»).
Индекс ключевых слов иногда выдаёт невероятно быстрый результат, а в других случаях нет. Предположим, у вас 50 ГБ логов, в которых термин 'customer_5987235982' встречается ровно три раза. Поиск по этому термину считает непосредственно из индекса три местоположения и завершится мгновенно. Но сложный поиск с подстановочными знаками может сканировать тысячи ключевых слов и занять много времени.
С другой стороны, поиск методом грубой силы для любого запроса выполняется с более или менее одинаковой скоростью. Поиск длинных слов лучше, но даже поиск одного символа происходит достаточно быстро.
Простота метода грубой силы означает, что его производительность близка к теоретическому максимуму. Здесь меньше вариантов для непредвиденной перегрузки дисков, конфликта при блокировках, погони указателя и тысяч других причин для сбоев. Я просто посмотрел на запросы, сделанные пользователями Scalyr на прошлой неделе на нашем самом загруженном сервере. Было 14 000 запросов. Ровно восемь из них заняли более одной секунды; 99% выполнено в пределах 111 миллисекунд (если вы не использовали инструменты анализа логов, поверьте: это быстро).
Стабильная, надёжная производительность важна для удобства использования сервиса. Если он периодически тормозит, пользователи будут воспринимать его как ненадёжный и неохотно использовать.
Вот небольшая анимация, которая показывает поиск Scalyr в действии. У нас есть демо-аккаунт, куда мы импортируем каждое событие в каждом публичном репозитории Github. В этой демонстрации я изучаю данные за неделю: примерно 600 МБ необработанных логов.
Видео записано в прямом эфире, без специальной подготовки, на моём десктопе (около 5000 километров от сервера). Производительность, которую вы увидите, во многом обязана оптимизации веб-клиента, а также быстрому и надёжному бэкенду. Всякий раз, когда возникает пауза без индикатора 'loading', это я делаю паузу, чтобы вы успели прочитать, что я собираюсь нажать.

При обработке больших объёмов данных важно выбрать хороший алгоритм, но «хороший» не значит «причудливый». Подумайте о том, как ваш код будет работать на практике. Из теоретического анализа алгоритмов выпадают некоторые факторы, которые могут иметь большое значение в реальном мире. Более простые алгоритмы легче оптимизировать и они стабильнее в пограничных ситуациях.
Также подумайте о контексте, в котором будет выполняться код. В нашем случае нужны достаточно мощные серверы для управления фоновыми задачами. Пользователи относительно редко инициируют поиск, поэтому мы можем позаимствовать целую группу серверов на короткий период, необходимый для выполнения каждого поиска.
Методом грубой силы мы реализовали быстрый, надёжный, гибкий поиск по набору логов. Надеемся, что эти идеи будут полезны для ваших проектов.
Правка: заголовок и текст изменились с «Поиск на скорости 20 ГБ в секунду» на «Поиск на скорости 1 ТБ в секунду», чтобы отразить увеличение производительности за последние несколько лет. Это увеличение скорости в первую очередь связано с изменением типа и количества серверов EC2, которые мы сегодня поднимаем для обслуживания возросшей клиентской базы. В ближайшее время ожидаются изменения, которые обеспечат ещё одно резкое повышение эффективности работы, и мы с нетерпением ждём, когда появится возможность об этом рассказать.
В этой статье описывается, как мы в Scalyr решили эту проблему, применив методы старой школы, подход грубой силы, устранив лишние слои и избегая сложных структур данных. Эти уроки вы можете применить к собственным инженерным задачам.
Сила старой школы
Анализ логов обычно начинается с поиска: найти все сообщения, соответствующие некоторому шаблону. В Scalyr это десятки или сотни гигабайт логов со многих серверов. Современные подходы, как правило, предполагают построение некоей сложной структуры данных, оптимизированной для поиска. Я, конечно, видел такое в Google, где они довольно хороши в таких вещах. Но мы остановились на гораздо более грубом подходе: линейное сканирование логов. И это сработало — мы обеспечиваем интерфейс с поиском на порядок быстрее, чем у конкурентов (см. анимацию в конце).
Ключевым озарением стало то, что современные процессоры действительно очень быстры в простых, прямолинейных операциях. Это легко упустить в сложных, многослоистых системах, которые зависят от скорости I/O и сетевых операций, а такие системы сегодня очень распространены. Таким образом, мы разработали дизайн, который минимизирует количество слоёв и лишнего мусора. С несколькими процессорами и серверами параллельно скорость поиска достигает 1 ТБ в секунду.
Ключевые выводы из этой статьи:
- Грубый поиск — вполне жизнеспособный подход для решения реальных, масштабных проблем.
- Грубая сила — это техника проектирования, а не освобождение от работы. Как и любая техника, она лучше подходит для одних проблем, чем для других, и её можно реализовать плохо или хорошо.
- Грубая сила особенно хороша для достижения стабильной производительности.
- Эффективное использование грубой силы требует оптимизации кода и своевременного применения достаточного количества ресурсов. Она подходит, если ваши серверы под большой нагрузкой, не связанной с пользователями, а пользовательские операции остаются в приоритете.
- Производительность зависит от дизайна всей системы, а не только от алгоритма внутреннего цикла.
(В этой статье описывается поиск данных в памяти. В большинстве случаев, когда пользователь выполняет поиск по логам, серверы Scalyr уже кэшировали их. В следующей статье обсудим поиск по некэшерованным логам. Применяются те же принципы: эффективный код, метод грубой силы с большими вычислительными ресурсами).
Метод грубой силы
Традиционно, поиск в большом наборе данных производится по индексу ключевых слов. Применительно к серверным логам это означает поиск каждого уникального слова в журнале. Для каждого слова нужно составить список всех включений. Это позволяет легко найти все сообщения с этим словом, например 'error', 'firefox' или «transaction_16851951» — просто смотрим в индексе.
Я использовал такой подход в Google, и он работал хорошо. Но в Scalyr мы ищем в логах байт за байтом.
Почему? С абстрактной алгоритмической точки зрения индексы ключевых слов гораздо эффективнее, чем грубый поиск. Однако мы не продаём алгоритмы, мы продаём производительность. И производительность — это не только алгоритмы, но и системная инженерия. Мы должны учитывать всё: объём данных, тип поиска, доступное оборудование и программный контекст. Мы решили, что для нашей конкретной проблемы вариант вроде 'grep' подходит лучше, чем индекс.
Индексы — это отлично, но у них есть ограничения. Одно слово найти легко. А вот поиск сообщений с несколькими словами, такими как 'googlebot' и '404' — уже намного сложнее. Поиск фразы вроде 'uncaught exception' требует более громоздкого индекса, который регистрирует не только все сообщения с этим словом, но и конкретное местоположение слова.
Настоящая трудность возникает, когда вы ищете не слова. Предположим, вы хотите посмотреть, сколько трафика приходит от ботов. Первая мысль — поиск в логах по слову 'bot'. Так вы найдёте некоторых ботов: Googlebot, Bingbot и многих других. Но здесь 'bot' — это не слово, а его часть. Если искать 'bot' в индексе, мы не найдём сообщений со словом 'Googlebot'. Если проверять каждое слово в индексе и затем сканировать индекс по найденным ключевикам, поиск сильно замедлится. В результате некоторые программы для работы с логами не разрешают поиск по частям слова или (в лучшем случае) позволяют использовать специальный синтаксис с более низкой производительностью. Мы хотим этого избежать.
Ещё одна проблема — пунктуация. Хотите найти все запросы от
50.168.29.7? Что насчёт отладки логов, содержащих [error]? Индексы обычно пропускают пунктуацию.Наконец, инженеры любят мощные инструменты, а иногда проблему можно решить только регулярным выражением. Индекс ключевых слов не очень подходит для этого.
Кроме того, индексы сложны. Каждое сообщение нужно добавить в несколько списков ключевых слов. Эти списки следует постоянно держать в удобном для поиска формате. Запросы с фразами, фрагментами слов или регулярными выражениями нужно переводить в операции с несколькими списками, а результаты сканировать и объединять для получения результирующего набора. В контексте крупномасштабной многопользовательской службы такая сложность создаёт проблемы производительности, которые не видны при анализе алгоритмов.
Индексы ключевых слов также занимают много места, а хранилище — основная статья расходов в системе управления логами.
С другой стороны, на каждый поиск можно потратить много вычислительной мощности. Наши пользователи ценят высокоскоростной поиск по уникальным запросам, но такие запросы делаются относительно редко. Для типичных поисковых запросов, например, для панели мониторинга, мы применяем специальные приёмы (опишем их в следующей статье). Другие запросы достаточно редки, так что редко приходится обрабатывать более одного за раз. Но это не значит, что наши серверы не заняты: они загружены работой по приёму, анализу и сжатию новых сообщений, оценке оповещений, сжатию старых данных и так далее. Таким образом, у нас довольно существенный запас процессоров, которые можно задействовать для выполнения запросов.
Грубая сила работает, если у вас есть грубая проблема (и много силы)
Грубая сила лучше всего работает на простых задачах с маленькими внутренними циклами. Часто вы можете оптимизировать внутренний цикл для работы на очень высоких скоростях. Если код сложный, то намного труднее его оптимизировать.
Первоначально в нашем коде для поиска был довольно большой внутренний цикл. Мы храним сообщения на страницах по 4K; каждая страница содержит некоторые сообщения (в UTF-8) и метаданные для каждого сообщения. Метаданные — это структура, в которой закодированы длина значения, внутренний ID сообщения и другие поля. Цикл поиска выглядел так:
Это упрощённый вариант по сравнению с фактическим кодом. Но даже здесь видно несколько размещений объекта, копий данных и вызовов функций. JVM довольно хорошо оптимизирует вызовы функций и выделяет эфемерные объекты, поэтому этот код работал лучше, чем мы того заслуживали. Во время тестирования клиенты довольно успешно им пользовались. Но в конце концов мы перешли на новый уровень.
(Вы можете спросить, почему мы храним сообщения в таком формате со страницами по 4K, текстом и метаданными, а не работаем с логами напрямую. Есть много причин, которые сводятся к тому, что внутренне движок Scalyr больше похож на распределённую базу данных, чем на файловую систему. Текстовый поиск часто сочетается с фильтрами в стиле СУБД на полях после парсинга логов. Мы можем одновременно искать по многим тысячам логов одновременно, и простые текстовые файлы не подходят для нашего транзакционного, реплицированного, распределённого управления данными).
Изначально казалось, что такой код не очень подходит для оптимизации под метод грубой силы. «Настоящая работа» в
String.indexOf() даже не доминировала в профиле CPU. То есть оптимизация только этого метода не принесла бы существенного эффекта.Так получилось, что мы храним метаданные в начале каждой страницы, а текст всех сообщений в UTF-8 упакован в другом конце. Воспользовавшись этим, мы переписали цикл для поиска сразу по всей странице:
Такая версия работает непосредственно на представлении
raw byte[] и выполняет поиск всех сообщений сразу на всей странице 4K.Это гораздо легче оптимизировать для метода грубой силы. Внутренний поисковый цикл вызывается одновременно для всей страницы 4K, а не отдельно на каждом сообщении. Нет ни копирования данных, ни выделения объектов. И более сложные операции с метаданными вызываются только при положительном результате, а не на каждое сообщение. Таким образом, мы исключили тонну накладных расходов, а остальная нагрузка сосредоточена в небольшом внутреннем цикле поиска, который хорошо подходит для дальнейшей оптимизации.
Наш фактический поисковый алгоритм основан на отличной идее Леонида Вольницкого. Он похож на алгоритм Бойера — Мура с пропуском примерно длины поисковой строки на каждом шаге. Главное отличие в том, что он проверяет два байта за раз, чтобы минимизировать ложные совпадения.
Наша реализация требует для каждого поиска создания поисковой таблицы 64K, но это ерунда по сравнению с гигабайтами данных, в которых мы ищем. Внутренний цикл обрабатывает несколько гигабайт в секунду на одном ядре. На практике стабильная производительность составляет около 1,25 ГБ в секунду на каждом ядре, и есть потенциал для улучшения. Можно устранить некоторые накладные расходы за пределами внутреннего цикла, и мы планируем поэкспериментировать c внутренним циклом на C вместо Java.
Применяем силу
Мы обсудили, что поиск по логам можно реализовать «грубо», но сколько «силы» у нас есть? Немало.
1 ядро: при правильном использовании одно ядро современного процессора довольно мощное само по себе.
8 ядер: в настоящее время мы работаем на серверах Amazon hi1.4xlarge и i2.4xlarge SSD, на каждом из которых 8 ядер (16 потоков). Как упоминалось выше, обычно эти ядра заняты фоновыми операциями. Когда пользователь выполняет поиск, то фоновые операции приостанавливаются, освобождая все 8 ядер для поиска. Поиск обычно завершается за долю секунды, после чего фоновая работа возобновляется (программа-регулятор гарантирует, что шквал поисковых запросов не помешает важной фоновой работе).
16 ядер: для надёжности мы организуем серверы по группам master/slave. У каждого мастера в подчинении один сервер SSD и один EBS. Если главный сервер падает, то сервер на SSD немедленно занимает его место. Почти всё время master и slave работают нормально, так что каждый блок данных доступен для поиска на двух разных серверах (у подчинённого сервера EBS слабый процессор, поэтому мы его не рассматриваем). Делим задачу между ними, так что у нас доступны в общей сложности 16 ядер.
Много ядер: в ближайшем будущем мы распределим данные по серверам таким образом, чтобы все они участвовали в обработке каждого нетривиального запроса. Будет работать каждое ядро. [Примечание: мы реализовали план и повысили скорость поиска до 1 ТБ/с, см. примечание в конце статьи].
Простота обеспечивает надёжность
Ещё одно преимущество метода грубой силы заключается в довольно стабильной производительности. Как правило, поиск не слишком чувствителен к деталям задачи и набора данных (думаю, именно поэтому его называют «грубым»).
Индекс ключевых слов иногда выдаёт невероятно быстрый результат, а в других случаях нет. Предположим, у вас 50 ГБ логов, в которых термин 'customer_5987235982' встречается ровно три раза. Поиск по этому термину считает непосредственно из индекса три местоположения и завершится мгновенно. Но сложный поиск с подстановочными знаками может сканировать тысячи ключевых слов и занять много времени.
С другой стороны, поиск методом грубой силы для любого запроса выполняется с более или менее одинаковой скоростью. Поиск длинных слов лучше, но даже поиск одного символа происходит достаточно быстро.
Простота метода грубой силы означает, что его производительность близка к теоретическому максимуму. Здесь меньше вариантов для непредвиденной перегрузки дисков, конфликта при блокировках, погони указателя и тысяч других причин для сбоев. Я просто посмотрел на запросы, сделанные пользователями Scalyr на прошлой неделе на нашем самом загруженном сервере. Было 14 000 запросов. Ровно восемь из них заняли более одной секунды; 99% выполнено в пределах 111 миллисекунд (если вы не использовали инструменты анализа логов, поверьте: это быстро).
Стабильная, надёжная производительность важна для удобства использования сервиса. Если он периодически тормозит, пользователи будут воспринимать его как ненадёжный и неохотно использовать.
Поиск по логам в действии
Вот небольшая анимация, которая показывает поиск Scalyr в действии. У нас есть демо-аккаунт, куда мы импортируем каждое событие в каждом публичном репозитории Github. В этой демонстрации я изучаю данные за неделю: примерно 600 МБ необработанных логов.
Видео записано в прямом эфире, без специальной подготовки, на моём десктопе (около 5000 километров от сервера). Производительность, которую вы увидите, во многом обязана оптимизации веб-клиента, а также быстрому и надёжному бэкенду. Всякий раз, когда возникает пауза без индикатора 'loading', это я делаю паузу, чтобы вы успели прочитать, что я собираюсь нажать.
В заключение
При обработке больших объёмов данных важно выбрать хороший алгоритм, но «хороший» не значит «причудливый». Подумайте о том, как ваш код будет работать на практике. Из теоретического анализа алгоритмов выпадают некоторые факторы, которые могут иметь большое значение в реальном мире. Более простые алгоритмы легче оптимизировать и они стабильнее в пограничных ситуациях.
Также подумайте о контексте, в котором будет выполняться код. В нашем случае нужны достаточно мощные серверы для управления фоновыми задачами. Пользователи относительно редко инициируют поиск, поэтому мы можем позаимствовать целую группу серверов на короткий период, необходимый для выполнения каждого поиска.
Методом грубой силы мы реализовали быстрый, надёжный, гибкий поиск по набору логов. Надеемся, что эти идеи будут полезны для ваших проектов.
Правка: заголовок и текст изменились с «Поиск на скорости 20 ГБ в секунду» на «Поиск на скорости 1 ТБ в секунду», чтобы отразить увеличение производительности за последние несколько лет. Это увеличение скорости в первую очередь связано с изменением типа и количества серверов EC2, которые мы сегодня поднимаем для обслуживания возросшей клиентской базы. В ближайшее время ожидаются изменения, которые обеспечат ещё одно резкое повышение эффективности работы, и мы с нетерпением ждём, когда появится возможность об этом рассказать.