Третья статья в цикле и небольшое ответвление от основной серии — в этот раз я покажу как устроена и как работает библиотека интеграционного тестирования Spring, что происходит при запуске теста и как можно тонко настраивать приложение и его окружения для теста.
Написать эту статью меня подтолкнул комментарий Hixon10 про то, как использовать реальную базу, например Postgres, в интеграционном тесте. Автор комментария предложил использовать удобную all-included библиотеку embedded-database-spring-test. И я уже было добавил абзац и пример использования в коде, но потом задумался. Конечно, взять готовую библиотеку это правильно и хорошо, но если цель все таки понять как писать тесты для Spring приложения, то полезнее будет показать, как самому реализовать самому тот же функционал. Во-первых, это отличный повод поговорить про то, что под капотом у Spring Test. А во-вторых, я считаю, что нельзя полагаться на сторонние библиотеки, если не понимаешь как они устроены внутри, это ведет только к укреплению мифа о "магии" технологии.
В этот раз пользовательской фичи не будет, но будет проблема, которую нужно решить — я хочу запустить реальную базу данных на случайном порту и подключить приложение к этой временной базе автоматически, а после тестов базу остановить и удалить.
Сначала, как уже повелось, немного теории. Людям не слишком знакомым с понятиями бин, контекст, конфигурация я рекомендую освежить знания, например, по моей статье Обратная сторона Spring / Хабр.
Spring Test
Spring Test это одна из библиотек, входящих в Spring Framework, по сути все, что описано в разделе документации про интеграционное тестирование как раз о ней. Четыре главных задачи, которые решает библиотека это:
- Управлять Spring IoC контейнерами и их кэшированием между тестами
- Предоставить внедрение зависимостей для тестовых классов
- Предоставить управление транзакциями, подходящее для интеграционных тестов
- Предоставить набор базовых классов чтобы помочь разработчику писать интеграционные тесты
Я крайне рекомендую прочитать официальную документацию, там написано много всего полезного и интересного. Здесь же я приведу скорее краткую выжимку и несколько практических советов, которые полезно держать в уме.
Жизненный цикл теста
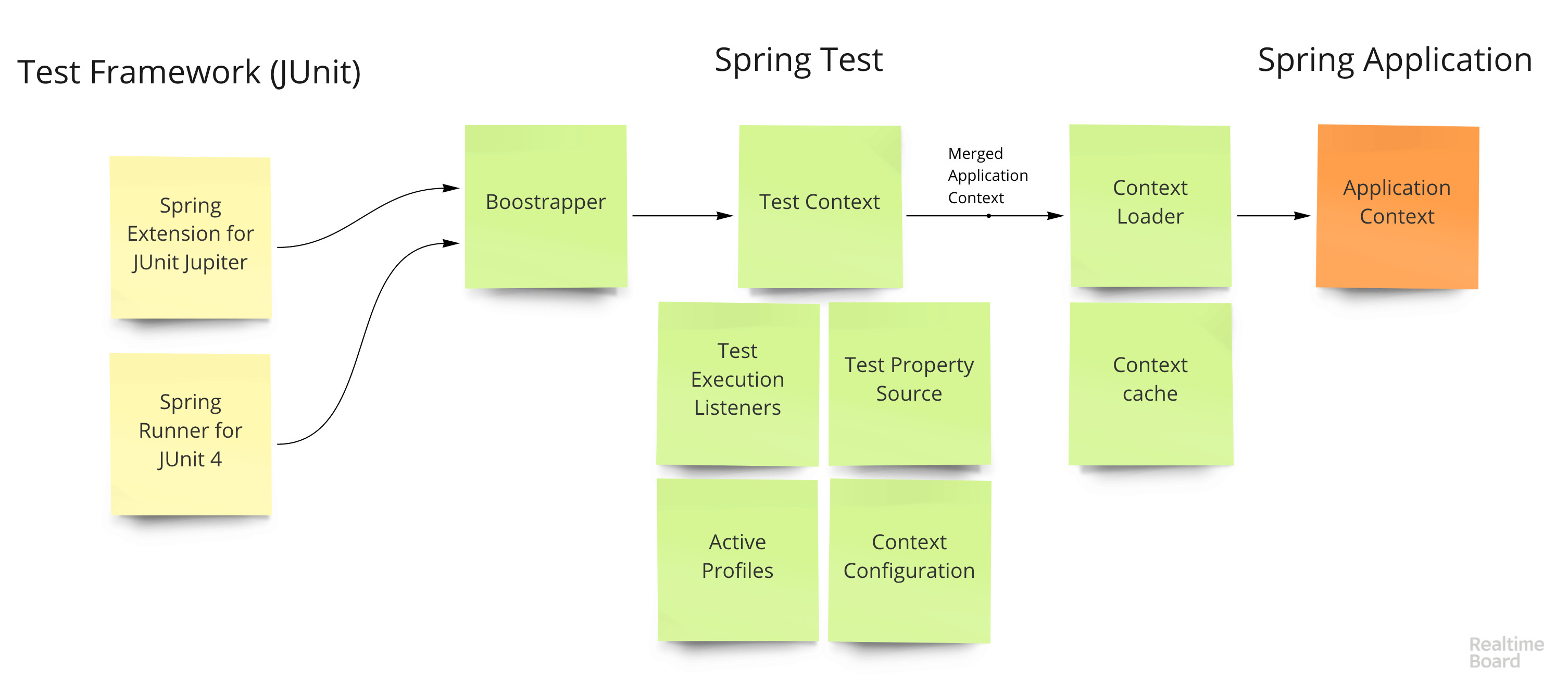
Жизненный цикл теста выглядит так:
- Расширение для тестового фреймворка (
SpringRunnerдля JUnit 4 иSpringExtensionдля JUnit 5) вызывает Test Context Bootstrapper - Boostrapper создает
TestContext— основной класс, который хранит текущее состояние теста и приложения TestContextнастраивает разные хуки (вроде запуска транзакций до теста и отката после), инжектит зависимости в тестовые классы (все@Autowiredполя на тестовых классах) и занимается созданием контекстов- Контекст создается используя Context Loader — тот берет базовую конфигурацию приложения и сливает ее с тестовой конфигурацией (перекрытые свойства, профили, бины, инициализаторы и т.п.)
- Контекст кешируется используя составной ключ, который полностью описывает приложение — набор бинов, свойств и т.п.
- Тест запускается
Всю грязную работу по управлению тестами делает, собственно,spring-test, аSpring Boot Testв свою очередь добавляет несколько вспомогательных классов, вроде уже знакомых@DataJpaTestи@SpringBootTest, полезные утилиты, вродеTestPropertyValuesчтобы динамически менять свойства контекста. Так же он позволяет запускать приложение как реальный web-server, или как mock-окружение (без доступа по HTTP), удобно мокать компоненты системы используя@MockBeanи т.п.
Кеширование контекста
Пожалуй, одна из очень непонятных тем в интеграционном тестировании, которая вызывает много вопросов и заблуждений — это кеширование контекста (см. пункт 5 выше) между тестами и его влияние на скорость выполнения тестов. Частый комментарий, который я слышу, это то, что интеграционные тесты "медленные" и "запускают приложение на каждый тест". Так вот, они действительно запускают — однако не на каждый тест. Каждый контекст (т.е. инстанс приложения) будет переиспользован по максимуму, т.е. если 10 тестов используют одинаковую конфигурацию приложения — то приложение запустится один раз на все 10 тестов. Что же значит "одинаковая конфигурация" приложения? Для Spring Test это значит что не изменился набор бинов, классов конфигураций, профилей, свойств и т.п. На практике это означает, что например эти два теста будут использовать один и тот же контекст:
@SpringBootTest
@ActiveProfiles("test")
@TestPropertySource("foo=bar")
class FirstTest {
}
@SpringBootTest
@ActiveProfiles("test")
@TestPropertySource("foo=bar")
class SecondTest {
}Количество контекстов в кэше ограничено 32-мя — дальше по принципу LRSU один из них будет удален из кэша.
Что же может помешать Spring Test переиспользовать контекст из кэша и создать новый?
@DirtiesContext
Самый простой вариант — если тест помечен это аннотаций, кэшироваться контекст не будет. Это может быть полезно, если тест меняет состояние приложение и хочется его "сбросить".
@MockBean
Очень неочевидный вариант, я даже вынес его отдельно — @MockBean заменяет реальный бин в контексте на мок, который можно тестировать через Mockito (в следующих статьях я еще покажу как это использовать). Ключевой момент — эта аннотация меняет набор бинов в приложении и заставляет Spring Test создать новый контекст. Если взять предыдущий пример, то например здесь уже будут созданы два контекста:
@SpringBootTest
@ActiveProfiles("test")
@TestPropertySource("foo=bar")
class FirstTest {
}
@SpringBootTest
@ActiveProfiles("test")
@TestPropertySource("foo=bar")
class SecondTest {
@MockBean
CakeFinder cakeFinderMock;
}@TestPropertySource
Любое изменение свойств автоматически меняет ключ кэша и создается новый контекст.
@ActiveProfiles
Изменение активный профилей тоже повлияет на кэш.
@ContextConfiguration
Ну и разумеется, любое изменение конфигурации тоже создаст новый контекст.
Запускаем базу
Итак, теперь со всем этим знанием мы попробуем взлететь понять как и где можно запускать базу. Единственного правильного ответа тут нет, зависит от требований, но можно подумать над двумя вариантами:
- Запускать один раз до всех тестов в классе.
- Запускать случайный инстанс и отдельную базу на каждый закешированный контекст (потенциально более чем один класс).
В зависимости от требований, можно выбрать любую опицю. Если в моем случае, Postgres стартует относительно быстро и второй вариант выглядит подходящим, то для чего-то более тяжелого может подойти и первый.
Первый вариант не завязан на Spring, а скорее на тестовый фреймворк. Например, можно сделать свой Extension для JUnit 5.
Если собрать воедино все знание про тестовую библиотеку, контексты и кеширование, то задача сводится к следующей: при создании нового контекста приложения нужно запустить базу на случайном порту и в контекст передать данные подключения.
За выполнение действий с контекстом до запуска в Spring отвечает интерфейс ApplicationContextInitializer.
ApplicationContextInitializer
У интерфейса всего один метод initialize, который выполняется до "запуска" контекста (т.е. до вызова метода refresh ) и позволяет внести изменения контекст — добавить бины, свойства.
В моем случае класс выглядит так:
public class EmbeddedPostgresInitializer
implements ApplicationContextInitializer<GenericApplicationContext> {
@Override
public void initialize(GenericApplicationContext applicationContext) {
EmbeddedPostgres postgres = new EmbeddedPostgres();
try {
String url = postgres.start();
TestPropertyValues values = TestPropertyValues.of(
"spring.test.database.replace=none",
"spring.datasource.url=" + url,
"spring.datasource.driver-class-name=org.postgresql.Driver",
"spring.jpa.hibernate.ddl-auto=create");
values.applyTo(applicationContext);
applicationContext.registerBean(EmbeddedPostgres.class, () -> postgres,
beanDefinition -> beanDefinition.setDestroyMethodName("stop"));
}
catch (IOException e) {
throw new RuntimeException(e);
}
}
}Первое что здесь происходит — запускается embedded Postgres, из библиотеки yandex-qatools/postgresql-embedded. Затем, создается набор свойств — JDBC URL для свежезапущенной базы, тип драйвера, и поведение Hibernate для схемы (автоматически создавать). Одна неочевидная вещь это только spring.test.database.replace=none — этим мы говорим DataJpaTest-у, что не надо пытаться подключится к встраиваемой БД, типа H2 и не надо подменять DataSource бин (так это работает).
И еще важный момент это application.registerBean(…). Вообще, этот бин можно, конечно, и не регистрировать — если в приложении его никто не использует, он не особо нужен. Регистрация нужна только чтобы указать destroy method, который Spring вызовет при уничтожении контекста, и в моем случае этот метод вызовет postgres.stop() и остановит базу.
В общем-то и все, магия закончилась, если какая-то и была. Теперь я зарегистрирую этот инициализатор в тестовом контексте:
@DataJpaTest
@ContextConfiguration(initializers = EmbeddedPostgresInitializer.class)
...Или даже для удобства можно создать свою аннотацию, потому что все мы любим аннотации!
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@DataJpaTest
@ContextConfiguration(initializers = EmbeddedPostgresInitializer.class)
public @interface EmbeddedPostgresTest {
}Теперь любой тест, аннотированный @EmbeddedPostgrestTest запустит базу на случайном порту и со случайным именем, настроит Spring на подключение к этой базе и в конце теста остановит ее.
@EmbeddedPostgresTest
class JpaCakeFinderTestWithEmbeddedPostgres {
...
}Заключение
Я хотел показать, что никакой таинственной магии в Spring нет, есть просто много "умных" и гибких внутренних мехнизмов, но зная их можно получить полный контроль на тестами и самим приложением. Вообще, в боевых проектах я не мотивирую всех писать свои методы и классы для настройки интеграционного окружения для тестов, если есть готовое решение то можно взять и его. Хотя если весь метод это 5 строчек кода, то наверное тащить зависимость в проект, особенно не понимая реализацию, это лишнее.
Ссылки на остальные статьи серии
Комментарии (7)

poxvuibr
01.04.2019 13:29Вот этот механизм кеширования контекстов всё портит. Вернее портит всё тот факт, что этот механизм считает, что контекст нужно пересоздавать при изменении списка конфигураций.
Я вот хочу запустить тесты для той же конфигурации, что и везде, но один бин заменить тестовой реализацией. Делаю я это через создание дополнительной конфигурации, в которой метод, возвращающий новый бин помечен аннотацией Primary. В результате спринг замечает, что список конфигураций тут другой и создаёт новый контекст и, соответственно, поднимает ещё одну базу на случайном порту, что существенно замедляется тесты. Как это красиво решить я чего-то не нашёл.
Единственное, что пока приходит в голову это поднимать встроенную БД ещё до запуска тестов и прокидывать её в конфигурации спринга.
alek_sys Автор
01.04.2019 14:15Я вот хочу запустить тесты для той же конфигурации, что и везде, но один бин заменить тестовой реализацией.
В ваших рассуждениях есть логическая ловушка — если заменить один бин это уже не та же конфигурация. Конфигурация в Spring достаточно фундаментальная вещь, которая по-сути описывает приложение.
Вариантов решения есть несколько, зависит от задачи:
- Создать базовый класс для тестов с одинаковой конфигурацией. Обычно, это означает тесты для одного и того же компонента (когда замоканы boundaries, об этом еще буду говорить в следующих статьях).
- Как уже отмечено — иметь одну базу для всех тестов, если пересоздавать контексты совершенно необходимо.
- Подумать над каким-то runtime созданием бинов, но это уже немного воевать с фреймворком.
poxvuibr
01.04.2019 14:39В ваших рассуждениях есть логическая ловушка — если заменить один бин это уже не та же конфигурация.
Как не называй, суть не поменяется. Мне хочется, чтобы все тесты, требующие БД проходили на одном и том же экземпляре встроенного postgresql.
Создать базовый класс для тестов с одинаковой конфигурацией.
Это ничем не поможет. При необходимости незначительно изменить конфигурацию Spring всё равно будет поднимать БД ещё раз.
Как уже отмечено — иметь одну базу для всех тестов
Это формулировка задачи, а не вариант решения )). Интересно, как это красиво сделать спрингом, если база встроенная.
Подумать над каким-то runtime созданием бинов
Наверное можно, но жутко неохота, хотя подозреваю, что этим и кончится)). Помогла бы какая-нибудь аннотация в Junit наподобие BeforeAll, только чтобы она была BeforeSuite или как-то так, но её по моему нет.
alek_sys Автор
02.04.2019 09:38Помогла бы какая-нибудь аннотация в Junit наподобие BeforeAll
Да, ее нет, но например TestContainers выкручиваются используя
staticполя.
Hixon10
Алексей, спасибо за статью.
Если позволите, хотел бы написать один комментарий про:
ИМХО, но вы как раз в статье и показали магию: «всего-то надо реализовать такой-то интерфейс, и добавить вот такую вот аннотацию с таким-то значением».
Если взять в противовес условный go, то там мы бы явно (руками) создали нужные компоненты для теста, и всё явно бы запустили.
Да, гошный подход — более многословный. Но и более явный для человека, кто знает язык программирования, но не конкретный фреймворк.
alek_sys Автор
Я скорее имел в виду, что библиотеки, вроде указанной, не делают ничего магического внутри.
А "реализовать интерфейс" и "добавить аннотацию" это для меня знание инструмента (Спринга). Чтобы им эффективно пользоваться — да, его надо знать. Но зато можно получать преимущества в виде продуктивности после.
В условном Го просто другой подход: вместо абстракций — повторения. Не лучше и не хуже — каждый выберет свой. В общем-то, в Спринг тоже никто не мешает игнорировать библиотеки тестирования — и хоть руками создавать контексты и делать все, что делает Spring Test, получив полный контроль над тестом. Просто потом захочется абстрагировать одну вещь, чтобы не повторять. Потому другую. А потом получится еще один фреймворк для тестирования.