
Всем привет! Этой статьей компания AERODISK открывает блог на Хабре. Ура, товарищи!
В предыдущих статьях на Хабре были рассмотрены вопросы об архитектуре и базовой настройке СХД. В этой статье мы рассмотрим вопрос, который ранее не был освещен, но его часто задавали – об отказоустойчивости СХД AERODISK ENGINE. Наша команда будет делать все, чтобы СХД AERODISK перестала работать, т.е. ломать её.
Так получилось, что статьи об истории нашей компании, о наших продуктах, а также пример успешного внедрения уже висят на Хабре, за что огромное спасибо нашим партнерам — компаниям TS Solution и Softline.
Поэтому я не буду тут тренировать навыки copy-paste management-а, а просто дам ссылки на оригиналы этих статей:
- Статья №1. Об истории компании и архитектуре системы хранения AERODISK ENGINE
- Статья №2. О том, как быстро настроить СХД AERODISK ENGINE
- Статья №3. Интересный проект о внедрении большого видеонаблюдения под ЧМ по футболу 2018 в рамках проекта Безопасный город
Также хочу поделиться радостной новостью. Но начну, конечно же, с проблемы. Мы, как молодой вендор, кроме прочих издержек, все время сталкиваемся с тем, что многие инженеры и администраторы банально не знают, как нашу СХД правильно эксплуатировать.
Понятно, что управление большинством СХД выглядит примерно одинаково с точки зрения админа, но при этом у каждого производителя есть свои особенности. И мы тут не исключение.
Поэтому, чтобы упростить задачу по обучению ИТ-специалистов, этот год мы решили посвятить бесплатному образованию. Для этого во многих крупных городах России мы открываем сеть Центров компетенции AERODISK, в которых любой желающий технический специалист сможет абсолютно бесплатно пройти курс и получить сертификат по администрированию СХД AERODISK ENGINE.
В каждом Центре компетенции мы установим полноценный демо-стенд из системы хранения AERODISK и физического сервера, на котором нашим преподавателем будет проводиться очное обучение. Расписание работы Центров компетенции будем публиковать по факту их появления, но уже сейчас мы открыли центр в Нижнем Новгороде и на очереди город Краснодар. Записаться на обучение можно по ссылкам ниже. Привожу известную на данный момент информацию о городах и датах:
- Нижний Новгород (УЖЕ РАБОТАЕТ – записаться можно тут https://aerodisk.promo/nn/);
до 16 апреля 2019 года можно посетить центр в любое рабочее время, а 16-ого апреля 2019 года будет организован большой обучающий курс. - Краснодар (СКОРО ОТКРЫТИЕ – записаться можно тут https://aerodisk.promo/krsnd/ );
С 9 по 25 апреля 2019 года можно посетить центр в любое рабочее время, а 25-ого апреля 2019 года будет организован большой обучающий курс. - Екатеринбург (СКОРО ОТКРЫТИЕ, следите за информацией на нашем сайте или на Хабре);
май-июнь 2019 года. - Новосибирск (следите за информацией на нашем сайте или на Хабре);
октябрь 2019 года. - Красноярск (следите за информацией на нашем сайте или на Хабре);
ноябрь 2019 года.
Ну и, конечно, если Москва от вас недалеко, то в любое время можно посетить наш офис в Москве и пройти аналогичное обучение.
Все. С маркетингом завязали, переходим к технике!
На Хабре мы будем регулярно публиковать технические статьи о наших продуктах, нагрузочные тесты, сравнения, особенности использования и интересные внедрения.
Краш-тесты СХД AERODISK ENGINE N2, проверка на прочность
ACHTUNG! Прочитав статью, вы можете сказать: ну, конечно же, вендор сам себя проверит так, чтобы все отработало «на ура», тепличные условия и т.п. Отвечу: ничего подобного! В отличие от наших зарубежных конкурентов мы находимся здесь, близко к вам, и к нам всегда можно прийти (в Москву или любой ЦК) и протестировать нашу СХД любым способом. Таким образом, подгонять результаты под идеальную картину мира нам особого смысла нет, т.к. нас очень легко проверить. Для тех кому лень ходить у кого нет времени, можем организовать удаленное тестирование. Специальная лаба у нас для этого есть. Обращайтесь.
ACHTUNG-2! Данный тест не носит характер нагрузочного, т.к. тут нас волнует только отказоустойчивость. Через пару недель мы подготовим более мощный стенд и проведем нагрузочное тестирование СХД, опубликовав результаты тут (кстати, пожелания к тестам принимаются).
Итак, поехали ломать.
Тестовый стенд
Наш стенд состоит из следующего железа:
- 1 x СХД Aerodisk Engine N2 (2 контроллера, 64ГБ кэш, 8xFC портов 8Гб/с, 4xEthernet порта 10Гб/с SFP+, 4xEthernet порта 1Гб/с); в СХД установлены следующие диски:
- 4 x SAS SSD диска 900 GB;
- 12 x SAS 10k дисков 1,2 TB;
- 1 x Физический сервер с Windows Server 2016 (2xXeon E5 2667 v3, 96ГБ RAM, 2xFC порта 8Гб/с, 2xEthernet порта 10Гб/с SFP+);
- 2 x SAN 8G коммутатора;
- 2 x LAN 10G коммутатора;
Мы подключили сервер к СХД через коммутаторы и по FC, и по Ethernet 10G. Схема стенда ниже.
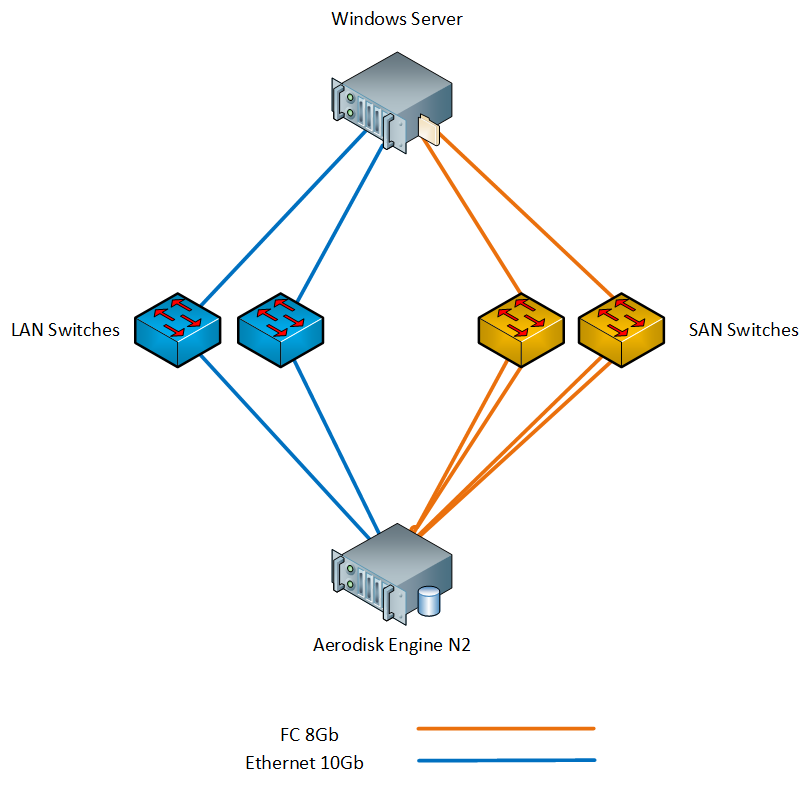
На Windows Server установлены необходимые нам компоненты, такие как MPIO и iSCSI initiator.
На FC коммутаторах настроены зоны, на LAN коммутаторах настроены соответствующие VLAN-ы и установлен MTU 9000 на портах СХД, коммутаторах и хосте (как всё это делать – описано в нашей документации, поэтому тут этот процесс расписывать не будем).
Методика тестирования
План краш-тестов такой:
- Проверка отказа FC и Ethernet портов.
- Проверка отказа питания.
- Проверка отказа контроллера.
- Проверка отказа диска в группе/пуле.
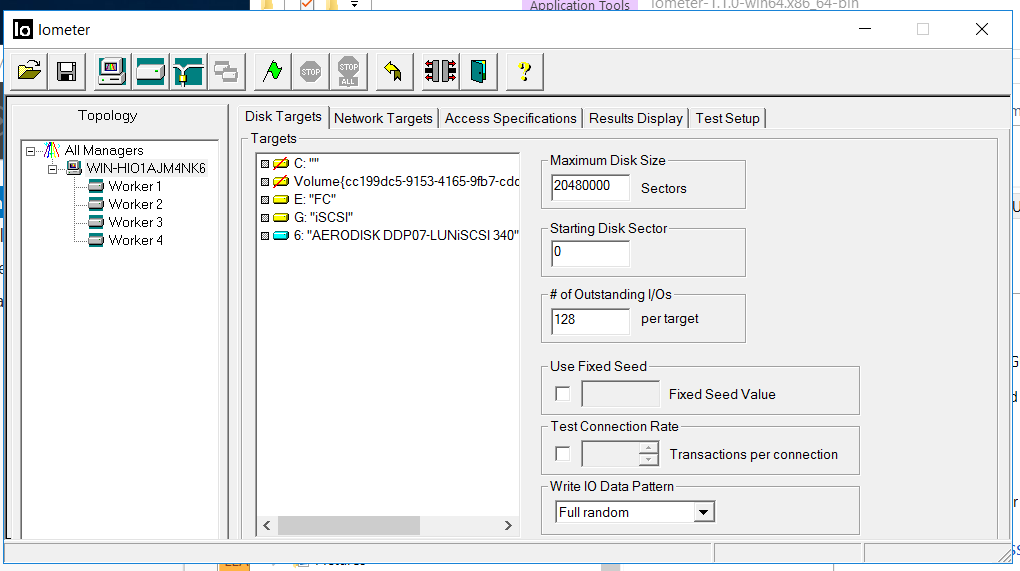
Все тесты будут выполняться в условиях синтетической нагрузки, которую мы будем генерировать программой IOMETER. Параллельно мы выполним те же тесты, но в условиях копирования больших файлов на СХД.
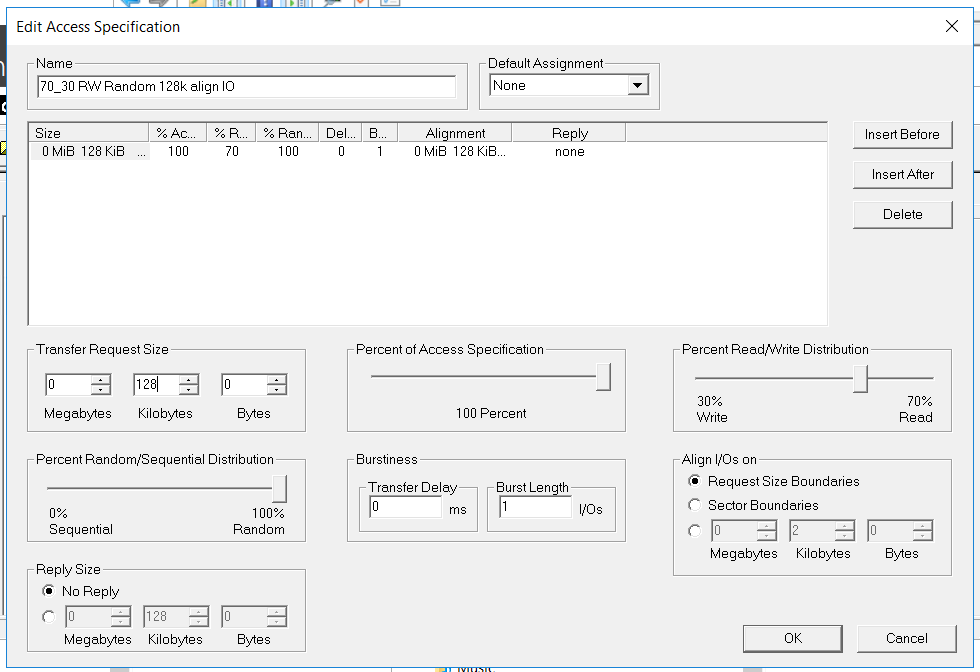
Конфиг IOmeter следующий:
- Чтение/Запись – 70/30
- Блок – 128k (решили мочить СХД большими блоками)
- Количество потоков – 128 (что очень похоже на продуктивную нагрузку)
- Full Random
- Количество Worker-ов – 4 (2 для FC, 2 для iSCSI)
Тест преследует следующие задачи:
- Убедиться, что синтетическая нагрузка и процесс копирования не прервутся и не вызовут ошибок при различных вариантах отказа.
- Убедиться, что процесс переключения портов, контроллеров и пр. в достаточной степени автоматизирован и не требует действий администратора при отказах (то есть при failover-ах, о failback-ах речь, понятно, не идет).
- Убедиться в корректности отображения информации в логах.
Подготовка хоста и СХД
На СХД мы настроили блочный доступ с использованием портов FC и Ethernet (FC и iSCSI, соответственно). Как это делать, ребята из TS Solution подробно описали в предыдущей статье (https://habr.com/ru/company/tssolution/blog/432876/). Ну и, конечно, мануалы и курсы никто не отменял.
Мы настроили гибридную группу, использовав все имеющиеся у нас диски. 2 ССД диска добавлены в кэш, 2 ССД диска добавлены как дополнительный уровень хранения (Online-tier). 12 SAS10k дисков мы сгруппировали в RAID-60P (тройная четность), для того, чтобы проверить выход из строя сразу трех дисков в группе. Один диск оставили для автозамены.
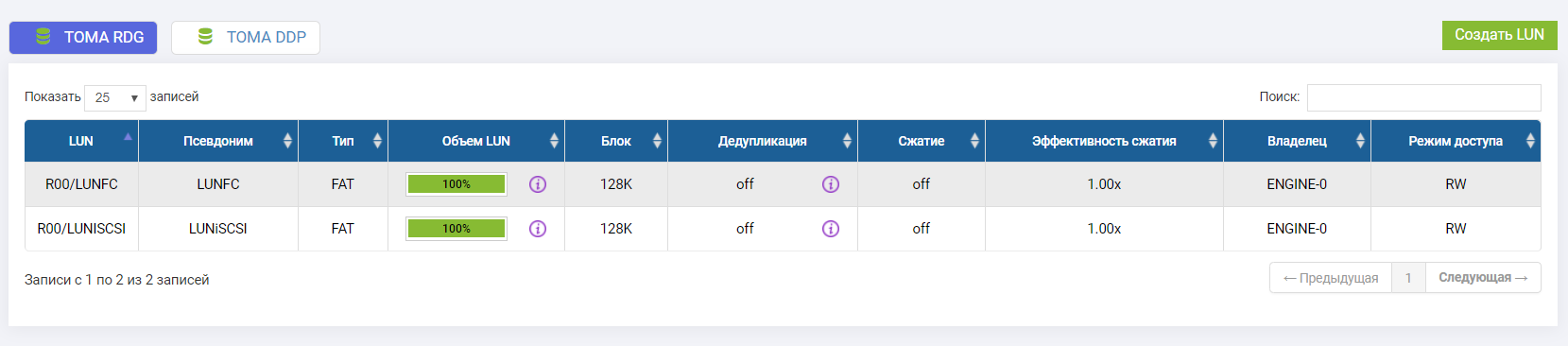
Подключили два LUN-а (один по FC, один по iSCSI).
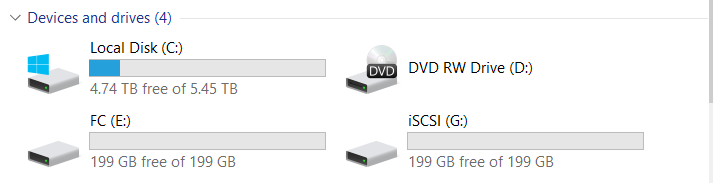
Владельцем обоих LUN-ов является контроллер Engine-0
Начинаем тест
Включаем IOMETER с конфигом выше.
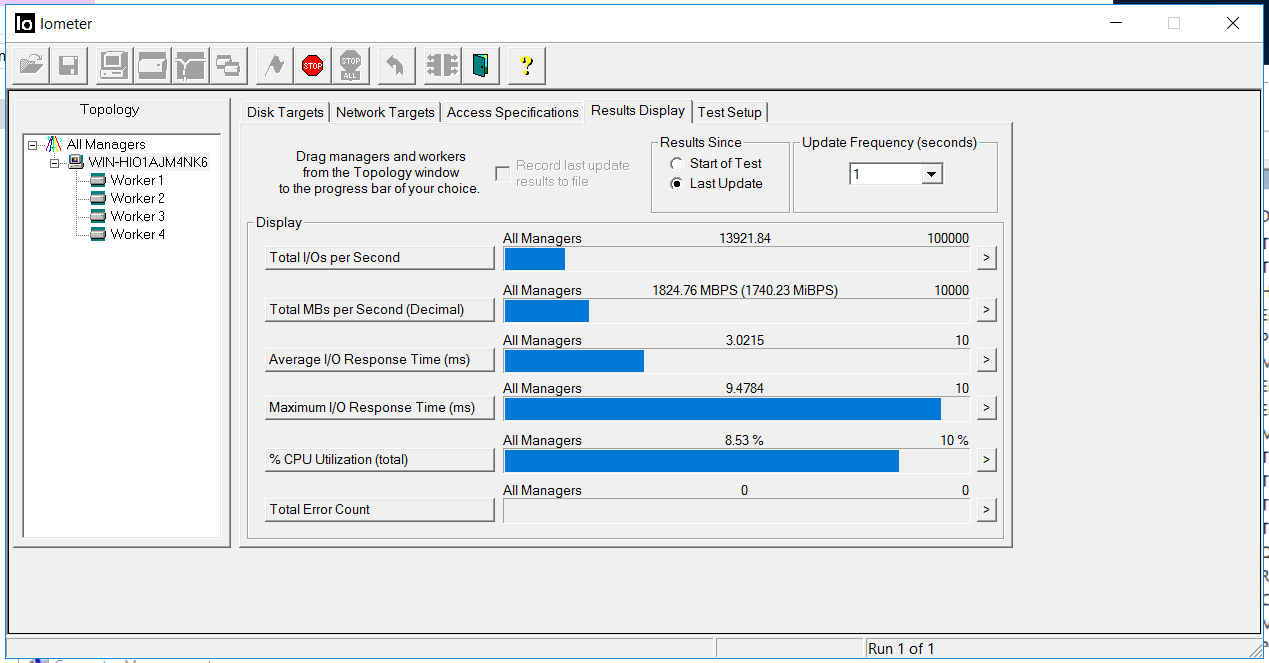
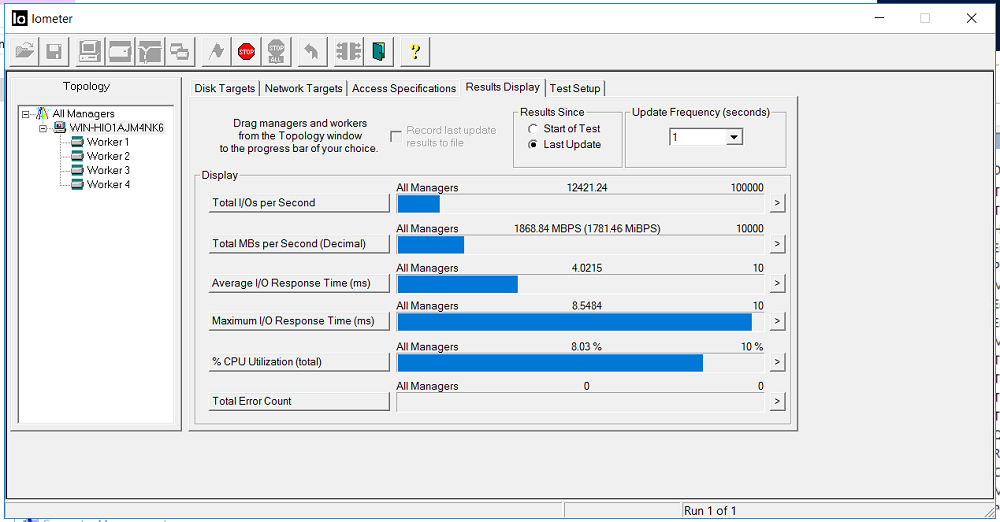
Фиксируем пропускную способность 1.8 ГБ/с и задержки 3 миллисекунды. Ошибок (Total Error Count) нет.
В это же время с локального диска "C" нашего хоста параллельно запускаем копирование двух больших файлов по 100GB на FC и iSCSI LUN-ы СХД (диски E и G в винде), задействовав другие интерфейсы.
Вверху процесс копирования на LUN FC, внизу на iSCSI.

Тест № 1. Отключение портов ввода-вывода
Подходим к СХД сзади))) и легким движением руки выдергиваем все FC и Ethernet 10G кабели из контроллера Engine-0. Как будто уборщица со шваброй прошла мимо и решила помыть пол как раз там, где валялись сопли лежали кабели (т.е. контроллер остается работать, но порты ввода-вывода умерли).

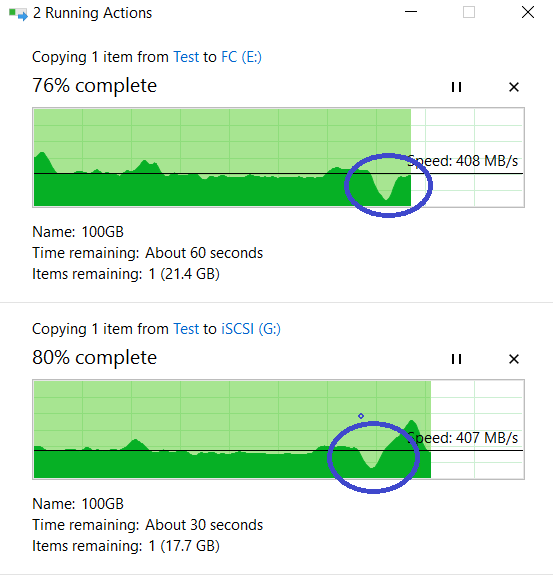
Смотрим на IOMETER и копирование файлов. Пропускная способность упала до 0,5 ГБ/с, но довольно быстро вернулась на прежний уровень (примерно за 4-5 секунд). Ошибок нет.
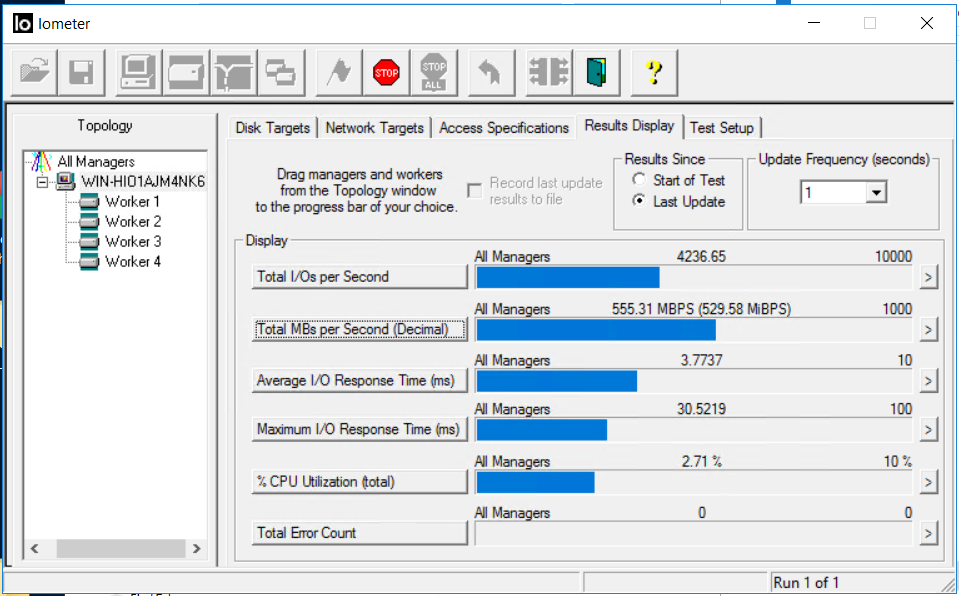
Копирование файлов не остановилось, просадка в скорости есть, но совсем некритична (с 840 МБ/с упала до 720 МБ/с). Копирование не остановилось.
Смотрим в логи СХД и видим сообщение о недоступности портов и автоматическом переезде группы.

Также информационная панель нам подсказывает, что не очень все хорошо с портами FC.
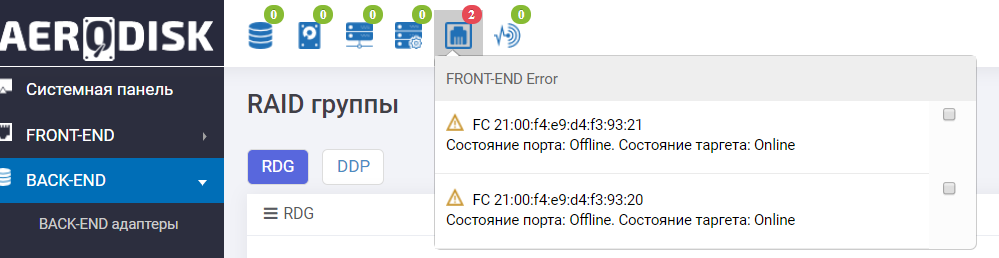
Отказ портов ввода-вывода СХД пережила успешно.
Тест № 2. Отключение контроллера СХД
Почти сразу (предварительно воткнув обратно кабели обратно в СХД) мы решили добить СХД, выдернув контроллер из шасси.
Опять подходим к СХД сзади (нам понравилось))) и на этот раз выдергиваем контроллер Engine-1, который в этот момент является владельцем RDG (на который переехала группа).
Ситуация в IOmeter следующая. Ввод вывод остановился примерно на 5 секунд. Ошибки не копятся.
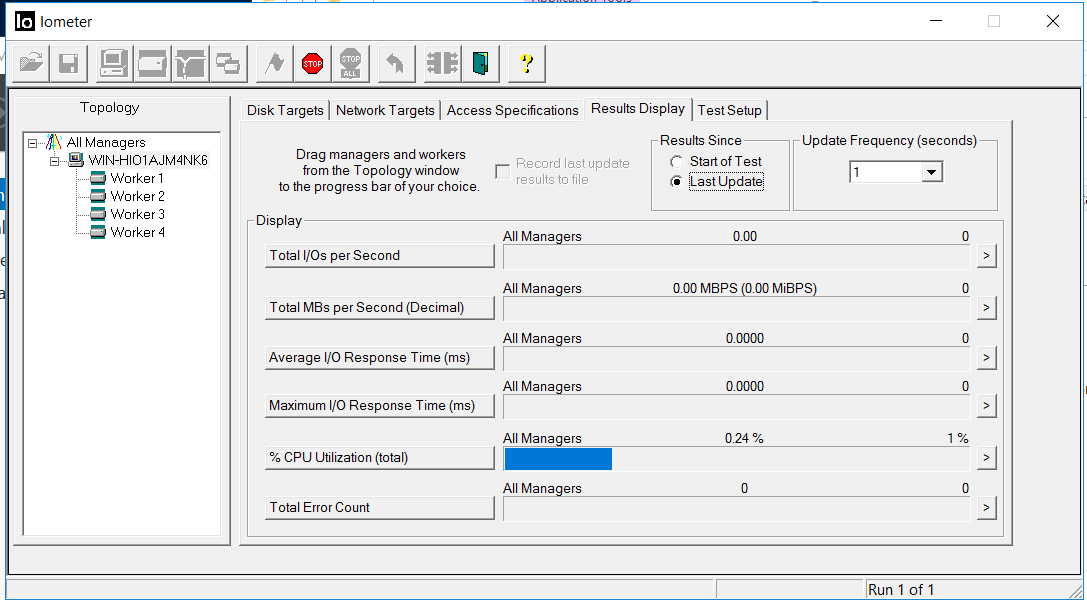
После 5 секунд ввод-вывод возобновился, примерно с теми же показателями пропускной способности, но с задержками в 35 миллисекунд (задержки исправились примерно через пару минут). Как видно из скриншотов, значение Total error count – 0, то есть ошибок записи или чтения не было.
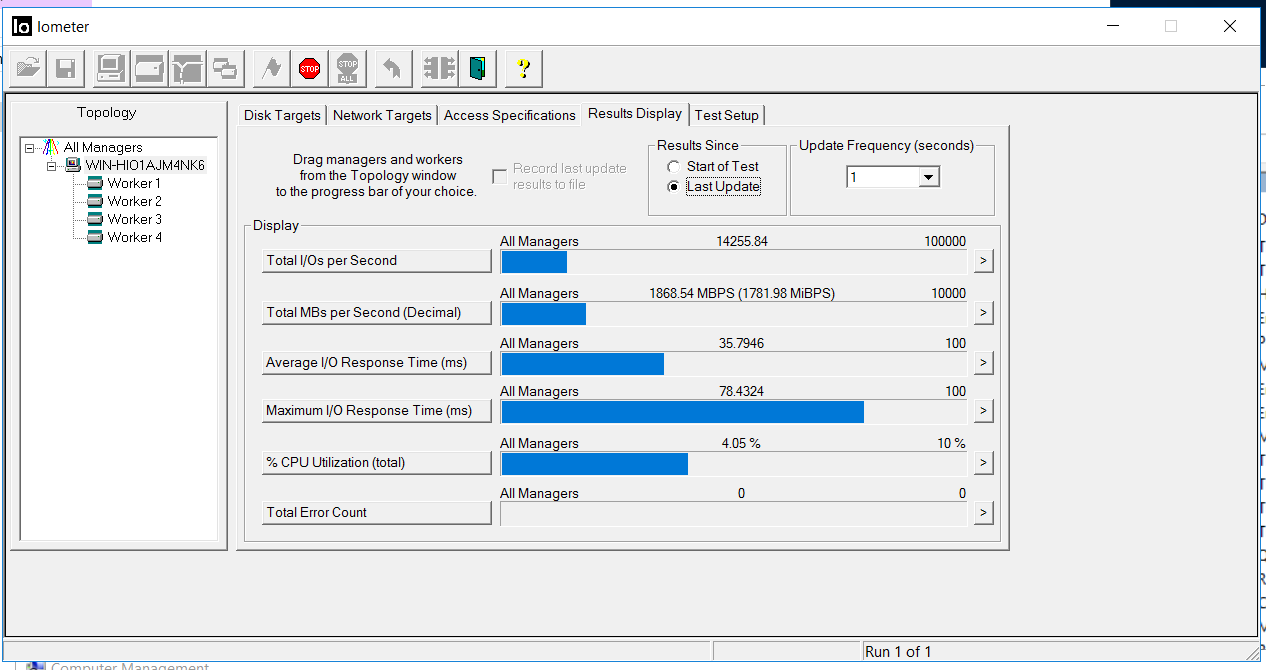
Смотрим на копирование наших файлов. Как видно, оно не прервалось, была небольшая просадка производительности, но в целом все вернулось на те же ~ 800 МБ/с.
Идем на СХД и видим там ругань в информационной панели о том, что контроллер Engine-1 недоступен (конечно, мы же его грохнули).
Также видим аналогичную запись в логах.

Отказ контроллера СХД пережила также успешно.
Тест № 3. Отключение блока питания.
Копирование файлов мы на всякий случай запустили заново, а IOMETER не останавливали.
Дергаем БП-шник.

На СХД добавился еще один алерт в информационной панели.

Также в меню сенсоров видим, что сенсоры, связанные с выдернутым блоком питания, покраснели.

СХД продолжает работать. Отказ БП-шника никак не влияет на работу СХД, с точки зрения хоста скорость копирования и показатели IOMETER-а остались без изменений.
Тест на отказ питания пройден успешно.
Перед финальным тестом мы решили все-таки немного вернуть СХД к жизни, поставили обратно контроллер и БП-шник, а также навели порядок с кабелями, о чем СХД нам радостно сообщила зелеными значками в своей панели здоровья.

Тест № 4. Отказ трёх дисков в группе
Перед этим тестом мы выполнили дополнительный подготовительный шаг. Дело в том, что в СХД ENGINE предусмотрена очень полезная штука — разные политики ребилда (перестроения). Ранее TS Solution писал об этой фиче, но напомним её суть. Администратор СХД может указать приоритет выделения ресурсов при перестроении. Либо в сторону производительности ввода-вывода, то есть дольше ребилд, но нет просадки производительности. Либо в сторону скорости ребилда, но производительность будет снижена. Либо сбалансированный вариант. Поскольку производительность СХД во время ребилда дисковой группы – это всегда головная боль админа, мы будем тестировать политику с уклоном в сторону производительности ввода-вывода и в ущерб скорости ребилда.

Теперь проверим отказ дисков. Также включаем запись на LUN-ы (файлы и IOMETER). Поскольку у нас группа с тройной четностью (RAID-60P), значит, система должна выдержать отказ трех дисков, а после отказа должна сработать автозамена, один диск должен встать в RDG на место одного из отказавших, и на него должен начаться ребилд.
Начинаем. Для начала через интерфейс СХД подсветим диски, которые хотим выдернуть (чтобы не промахнуться и не дернуть диск автозамены).

Проверяем индикацию на железе. Все ОК, видим подсвеченные три диска.

И выдергиваем эти три диска.

Смотрим что на хосте. А там… ничего особенного не произошло.
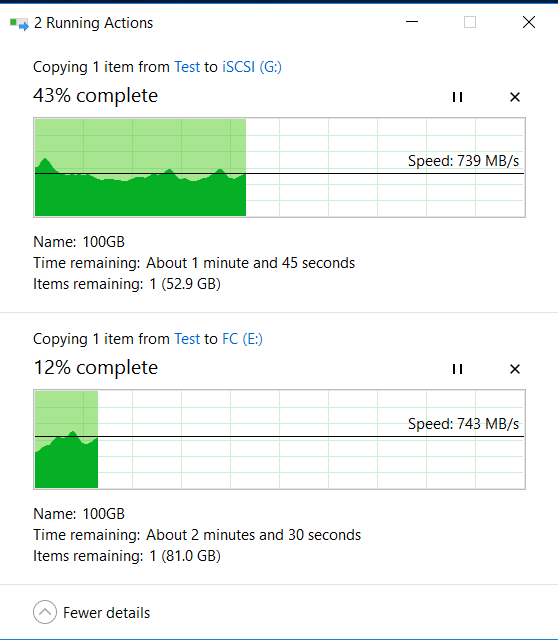
Показатели копирования (они выше, чем в начале, т.к. прогрелся кэш) и IOMETER-а при выдергивании дисков и старте ребилда сильно не меняются (в пределах 5-10%).
Смотрим, что на СХД.
В статусе группы видим, что пошел процесс перестроения и он близок к завершению.

В скелете RDG видно, что 2 диска в красном статусе, а один уже заменился. Диска автозамены больше нет, он заменил собой 3-ий отказавший диск. Ребилд выполнялся несколько минут, запись файлов при отказе 3-х дисков не прервалась, производительность ввода-вывода особо не менялась.
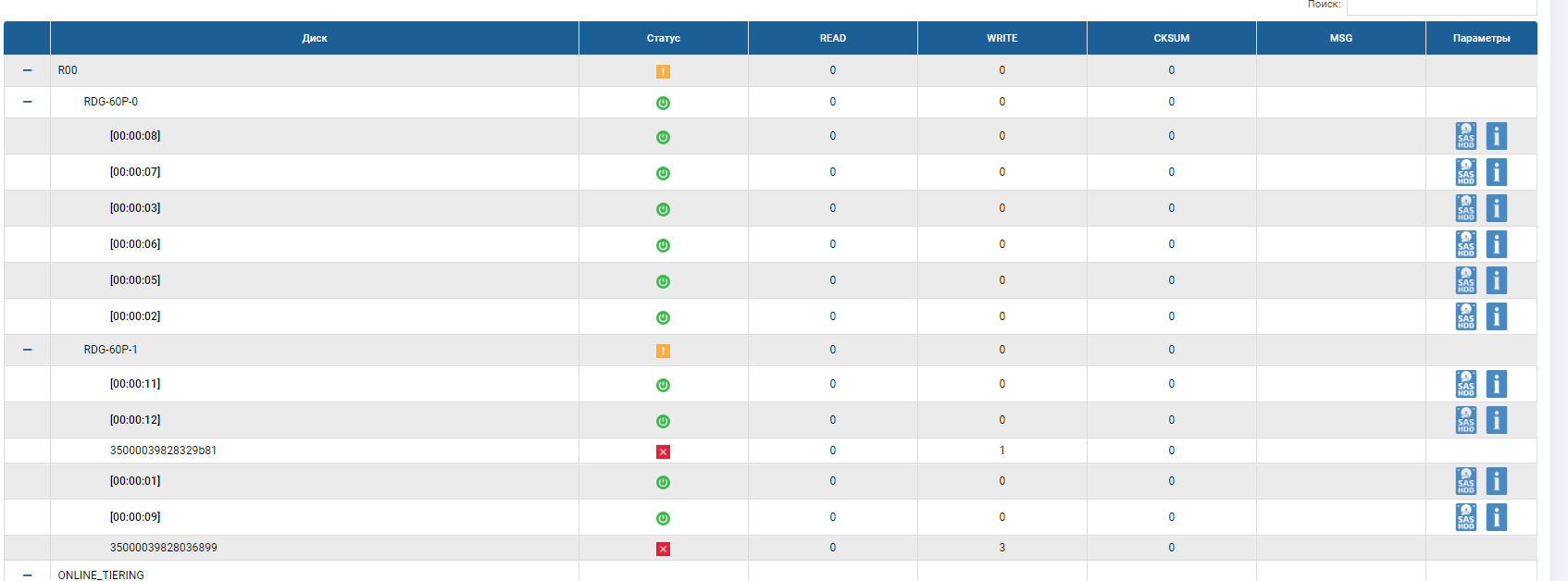
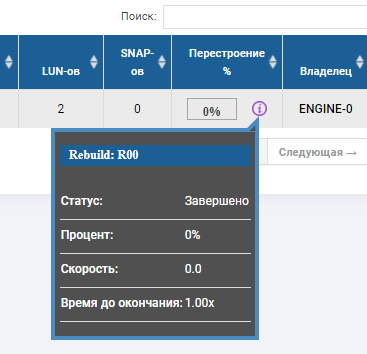
Тест на отказ дисков однозначно прошел успешно.
Заключение
На этом насилие над СХД мы решили прекратить. Подводим итоги:
- Проверка отказа FC портов — успешно
- Проверка отказа Ethernet портов – успешно
- Проверка отказа контроллера — успешно
- Проверка отказа питания — успешно
- Проверка отказа диска в группе\пуле — успешно
Ни один из сбоев не остановил запись и не вызвал ошибок синтетической нагрузки, просадка производительности, конечно, была (и мы знаем как это победить, что скоро и сделаем), но, учитывая то, что это секунды, вполне допустима. Вывод: отказоустойчивость всех компонентов СХД AERODISK отработала на уровне, точек отказа нет.
Очевидно, что в рамках одной статьи мы не можем оттестировать все сценарии отказа, но постарались охватить самые популярные. Поэтому, пожалуйста присылайте ваши комментарии, пожелания к следующим публикациям и, конечно, адекватную критику. Будем рады дискуссиям (а лучше приходите на обучение, на всякий случай дублирую расписание)! До новых тестов!
- Нижний Новгород (УЖЕ РАБОТАЕТ – записаться можно тут https://aerodisk.promo/nn/);
до 16 апреля 2019 года можно посетить центр в любое рабочее время, а 16-ого апреля 2019 года будет организован большой обучающий курс. - Краснодар (СКОРО ОТКРЫТИЕ – записаться можно тут https://aerodisk.promo/krsnd/ );
С 9 по 25 апреля 2019 года можно посетить центр в любое рабочее время, а 25-ого апреля 2019 года будет организован большой обучающий курс. - Екатеринбург (СКОРО ОТКРЫТИЕ, следите за информацией на нашем сайте или на Хабре);
май-июнь 2019 года. - Новосибирск (следите за информацией на нашем сайте или на Хабре);
октябрь 2019 года. - Красноярск (следите за информацией на нашем сайте или на Хабре);
ноябрь 2019 года.
Комментарии (20)


zacat
08.04.2019 10:50+1Нужно было протестировать отключение обоих БП (Не у всех же Tier3). Насколько корректно восстановится работа СХД после включения, естесственно, это лучше раз 10-20 сделать.
А одновременно еще дисков выдрать и один из контроллеров
Потом отключить еще один и вернуть первый контроллер =)
Viacheslav_V Автор
08.04.2019 10:54Спасибо. Пожелание учтём, добавим пункт для следующей статьи о краш-тестах.

Mishiko
08.04.2019 11:33Кстати да, отказ контроллера — реальный кейс. Причем иногда оказывается что к моменту отказа, контроллеры такого типа или с такой прошивкой уже невозможно найти в продаже, что рождает интересные проблемы — данные есть, а добыть их нельзя
dklm
08.04.2019 12:11А вы эксплуатируете схд в продакшене без сервисной поддержки? и без резервных копий?)))))
Mishiko
08.04.2019 12:33Я нет — вообще не использую СХД, а для своих задач использую софтовый рэйд или хранилку на основе HDFS, однако нагуглить погорельцев не сложно, вот первое что попалось:
Умер RAID-контроллер. Нужно восстановить информацию, сгорел древний аппаратный raid контроллер., «Raid контроллер сгорел. Как восстановить данные с raid 1+0 и т п, даже на хабре можно найти обсуждения подобных проблем: Что делать, если вышел из строя RAID-контроллер?. Это я к тому что проблема не редка. Из того что вспомнилось, были истории у каких то хостинг провайдеров, которые после аналогичной проблемы почти неделю ребилдили рейд и восстанавливали данные клиентов из пыльных бэкапов (естественно все восстановить не удалось) — это реальная жизнь.
ElvenSailor
08.04.2019 11:52+1А можете сымитировать вот такой случай — Отказ питания (сразу двух блоков) в момент ребилда массива на хот-спэйр-диск после отвала одного (или более) основных?
Т.е. условная вводная — «у нас не датацентр, а обычная серверная» некой компании, которая не может себе позволить две разных ветки электропитания, а в ИБП, вот незадача, внезапно умерли аккумуляторы (или они перестали держать нагрузку, так бывает, да :) )
Желательно, чтобы на ЛУНе лежал диск от виртуальной машины, и туда в момент падения что-то писалось.
С последующей проверкой — что выжило, что нет, внутри vhd-шки.
dklm
08.04.2019 12:15В вашем сценарии должно быть два ибп, даже если и нету двух вводов… и в этом случаи одновременный отказ обоих бп статистически маловероятен. После отказа одного бп, схд должна сбросить кеш записи на диски… если у вас один ИБП это ваш косяк.
Viacheslav_V Автор
08.04.2019 12:42Можем:-). Учитывая многочисленные пожелания, после статьи про нагрузочный тест сделаем еще Краш-тест 2.0, где учтем все пожелания. Спасибо!
dklm
08.04.2019 13:02А что вы хотите в этом случаи тестировать? абсолютно оторванный от реальности тест… Допустим в реальности пропало питание на обоих бп — в этом случаи данные не успели записаться и находятся в кеш памяти — сколько времени продержится батарея? если батарея умерла раньше чем восстановили полноценное питание вы проиграли. Скорее всего так и будет…
ElvenSailor
08.04.2019 13:22для тех, кто читает по диагонали:
смысл моего сценария не в том, что питание пропало, это ёжику понятно, что недописанная инфа пропадёт, а в том, что непосредственно перед пропаданием питалова вышел диск из массива, а в сам момент шёл ребилд массива!
И интересно, что произойдёт:
1 — ребилд продолжится с момента, на котором всё упало;
2 — ребилд начнётся заново;
3 — ребилд зафэйлится и лун развалится;
4 — ребилд зафэйлится, но лун сохранится в статусе degraded и можно будет исправить ситуацию руками, например, перевоткнуть hot spare;
5 — ребилд пройдёт, но часть информации пропадёт (потому что писалось как раз в момент падения.) Теоретически невозможен — софт по идее, стремится к атомарности операций, а вот практика показывает, что возможно всё.
Вот и интересно, как именно софт СХД отработает такое.
И да кстати — а какой будет в этом случае статус hot spare диска, на который шёл ребилд — останется в массиве, сбросится обратно или зависнет в промежуточном положении?
а насчётесли у вас один ИБП это ваш косяк.
Лучше быть богатым и здоровым, чем бедным и больным :)dklm
08.04.2019 13:28Сплю и вижу как вам признались что схд не способна выполнить ребилд (варианты 3 и 4)…
Viacheslav_V Автор
08.04.2019 14:39Батарея нужна не для того, чтобы пережить отсутствие электричества, а для быстрого но корректного выключения СХД. Батарея держит около 10 минут. В течение этого времени система автоматически сбрасывает все содержимое кэша на локальные диски своего контроллера (там где ОС установлена), а потом мягко выключается. Сброс кэша (даже самого большого длится) 3-4 минуты, этот сценарий мы постоянно отрабатываем в лаборатории. Конечно, если поставить в СХД несколько терабайт кэша, то никакая батарея не поможет, но мы в наших СХД так, очевидно, не делаем.

amarao
08.04.2019 13:43+1Вы проверяете ванильные сценарии.
Поскольку у вас в архитектуре фигрирует sas, то для sas существует простой метод положить шину: каждое устройство открывает канал для передачи данных. Если устройство-дятел не закрывает каналы, то через N операций SASxN шина окажется заблокирована и потребуется bus reset. Если устройство-дятел настойчиво, то bus reset будет достаточно частым, чтобы словить таймауты (т.е. ошибки IO).
Ещё можно попробовать устроить дребезг контактов (т.е. втык/вытык) — не всякая система переживает такое.
Ну и на закуску — slow-lorry на массив работает офигенно. Диск, который не выдаёт никаких ошибок, но принимает запись со скоростью в 2-3 Мб/с. Удачи работать на таком массиве, так сказать.
ElvenSailor
08.04.2019 14:07Ну и на закуску — slow-lorry на массив работает офигенно. Диск, который не выдаёт никаких ошибок, но принимает запись со скоростью в 2-3 Мб/с. Удачи работать на таком массиве, так сказать.
Некоторые современные СХД такие диски уже научились детектить и выплёвывать из массива со статусом «slow». Умеет ли конкретно эта — неизвестно. Вроде не заявлялось.
Но да, прикольный случай. Непонятно только, как его симулировать, это нужно где-то найти заведомо тормозной диск…
Nikobraz
А бывают СХД, имеется ввиду нормальные двухголовые с 2 БП, которые не выдержат эти тесты?
KorP
Да :D
Viacheslav_V Автор
К сожалению бывают. Но тест БП (как и все остальные) добавили не только для отработки отказа, но и для того чтобы убедиться в корректности оповещения администратора.