
Зачем нужно QA на проде, если есть пре-продакшн окружение
В процессе разработки ПО всегда есть несколько окружений, на которых развёрнуто приложение. Среда, которой пользуются конечные пользователи, как вы знаете, называется production. Обычно предполагается, что тестирование нужно проводить на отдельном окружении, чаще на QA environment или Staging (пре-прод), чтобы предотвратить попадание ошибок к пользователям. Но есть такая методика, как QA на проде, которая отлично помогает решить задачи, которые на тестовом окружении решить физически невозможно.
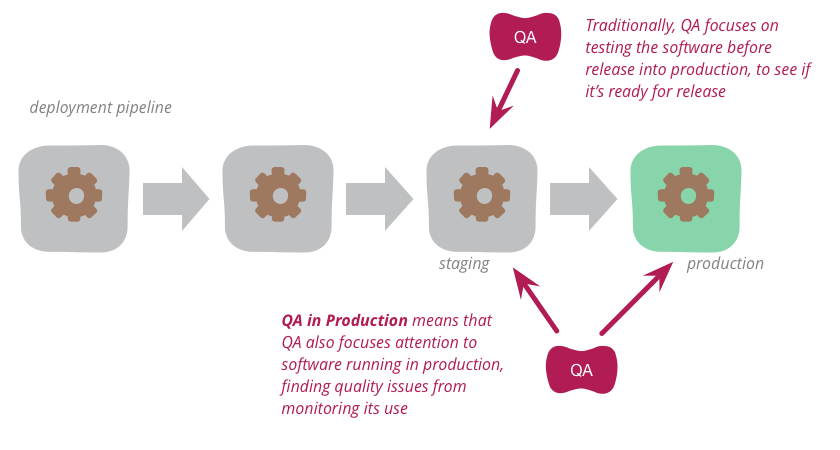
В каких задачах помогает QA на проде
1. Проблема различия Staging и Production окружений.
Staging часто считают копией продакшн среды, которая недоступна конечным пользователям, но максимально схожа с боевой средой. Когда приложение достаточно сложное, синхронизация и поддержание такой мини-копии становится трудоёмкой и не всегда рациональной задачей.
Например, на нашем проекте пре-прод используется больше для функционального тестирования на сделанных вручную тестовых сценариях. Он не обладает техническими ресурсами, сравнимыми с продакшн средой. Также мы обычно не делаем полную синхронизацию конфигураций и БД с продакшн средой, что никак не мешает проводить функциональные тесты. Почему мы не копируем прод среду? Представьте, сколько ресурсов бы ушло, чтобы создать копию, допустим, Facebook, с такими же супермощными серверами, сервисами, базой данных и конфигурациями как на production. Это фактически как развернуть ещё одно такое же приложение.
Кроме того, при интеграции со сторонними сервисами вы всегда имеете разные настройки для тестового и боевого окружения (то же самое API). Я не утверждаю, что тестовая и staging среды бессмысленны. Просто нельзя на 100% гарантировать, что при успешном прохождении определённых тестов на одной среде сервисы не упадут на другой. Помочь в решении этой проблемы как раз и может дополнительное тестирование на production.
2. Реальные уровни многозадачности и нагрузки.
Некоторые ошибки можно обнаружить только под продолжительным и реальным уровнем многозадачности и нагрузки. Это касается утечек памяти, стабильности, быстродействия и устойчивости системы. Например, у нас была ситуация, когда возникла проблема быстродействия системы из-за того, что две ресурсоемкие задачи выполнялись в один промежуток времени. Разработчики оптимизировали работу задач, команда сделала тесты на пре-прод окружении, изменения доставили, затем сделали проверку на production.
3. Ошибки развёртывания
Из определения развёртывание (deployment) — это установка рабочей группой новой версии программного кода сервиса в инфраструктуру продакшна. Соответственно лучший способ увидеть ошибки развёртывания — это тестирование в процессе самого развёртывания.
4. Недостаток мониторинга на пре-проде
Один из лучших и незаменимых способов контроля того, что приложение работает так, как мы ожидаем – это ведение мониторинга по определённым метрикам. Например, из простых и наиболее критичных примеров: ведение мониторинга на количество регистраций новых пользователей в час, на конверсию от одного целевого действия к другому, на количество выданных кредитов. Конечно, такой мониторинг имеет смысл только на боевом окружении.
5. Возможность анализа сценариев использования системы, которые осуществляют конечные пользователи
Продакшн – кладезь тест-кейсов для тестировщика. При возможности у тестировщика видеть и обрабатывать сценарии, которыми пользуются конечные пользователи, тестировщик может выявить наиболее критичные сценарии, или выяснить причину появившегося дефекта, или обратить внимание на нетривиальные кейсы при тестировании на пре-проде.
6. Возможность ведения более достоверной статистики и метрик качества ПО.
Например, количество ошибок в логах приложения или компонента, баг-репорты и другая отчётность, которую может делать прод-тестировщик, более реально демонстрирует качество ПО по сравнению с теми же отчётами из тестового окружения.
7. Всегда лучше, если ошибку на проде заметит «свой» тестировщик, чем конечный пользователь.
Обычно после доставки задачи тестировщик делает базовые проверки новой или изменившейся функциональности на проде. Кроме того у нас в компании есть отдельно выделенный человек – тестировщик на проде. Хочу ещё раз отметить, что я не позиционирую QA на проде как замену тестированию на пре-продакшне, и, конечно предотвращать появление багов и проводить превентивные меры обязательно нужно. Но такое тестирование может стать отличной дополнительной техникой в процессе обеспечения качества на вашем проекте.

Полезные практики QA на production, которые эффективно работают у нас на проекте
1. Проверка доставленных задач с целью убедиться, что они хорошо задеплоились и работают на новом окружении.
Например, когда мы вводим интеграцию с новым партнёром, кроме тестов на пре-проде мы обязательно проверяем интеграцию после доставки, т.к существуют очень много настроек, зависящих от среды (API, урлы, компоненты). Также имеют место 3rd party issues – ошибки не на нашей стороне, а на стороне интегрируемых сервисов.
2. Логирование и аудит.
Хорошее логирование помогает разработчикам и тестировщикам заметить проблему ещё до того, как о ней догадается конечный пользователь, а также заметить места, нуждающиеся в оптимизации. Аудит действий и изменений позволяет всегда без проблем выяснить причины того или иного поведения. Например, если компонент кредитной политики не может выдать решение по кредиту, для анализа, почему это произошло, мы в первую очередь обращаемся к логам. Этот пункт касается как prodcution, так и pre-production сред.
3. Мониторинг и система оповещений
Как я упоминала выше, ведение мониторинга по определённым метрикам — один из лучших способов контроля того, что с нашим приложением всё «ok». Причём при возникновении какой-либо проблемы, надо обязательно слать об этом оповещение заинтересованным лицам (например, количество заявок по кредиту на 20% меньше ожидаемого – шлём оповещение IT и бизнес-отделам, нагрузка на CPU выше нормы – оповещение админам и девам). Нужно следить, чтобы оповещения о проблемах были своевременными и актуальными, а также реально указывали на проблему.
4. Регрессия и проверка стабильности
Классной практикой является периодическое прохождение регрессионных тестов, с целью убедиться, что нигде ничего не вышло из строя. Может помочь в каких-то узких и специфичных случаях, когда мониторинг не видит проблем.
5. Отчётность и ведение статистики
Как и в любом тестировании, отчётность и ведение статистики о результатах прод-тестирования делает процесс прозрачнее, качество ПО и причины возникновения дефектов более обозримыми.
Все ошибки невозможно выявить на пре-проде, поэтому они будут попадать в боевую среду. Если их обнаружат пользователи, это скажется на репутации компании и, в конечном счете, на потере денег. Тестирование на проде поможет это предотвратить.
Комментарии (11)

qaandtest
10.04.2019 16:40Плюс на проде к контексту отношение другое. Например, на тесте мы удаляли записи от имени пользователя не задумываясь. На проде сразу задались вопросом — а нужно ли удалять, а должен ли пользователь удалять? И скрыли весь функционал удаления.
mkovalevskyi
10.04.2019 21:16Наличие ошибок «развертывания» при деплое в прод — это таки хороший показатель уровня пофигизма команды…
Ну и если уж упомянули фейсбук, то если его еще и попалят на «логировании» всего и вся, и потом просмотре этого всеми желающими (а дев тим — это не тот контингент, который должен иметь неограниченый доступ к сенсетив информации), то у него будут большие проблемы.
И таких проэктов, где подобные эксперименты прямо запрещены — их имеет место быть.olgamirko97
11.04.2019 16:35По поводу первого замечания: при отличии инфраструктуры и конфигурации prod от pre-prod даже отлаженный билд может иметь ошибки. Тут вопрос масштаба, полная копия окружения это не всегда возможно или не эфективно, и тогда риск отличия покрывается тестированием.
По поводу логирования «всего и вся»: конечно сенсетив информации у нас заинкрипчена, доступа у «всех желающих» к ней нет.mkovalevskyi
11.04.2019 19:26Не билд, а билд деплой скрипт.
Который обязан быть именно скриптом, а не «вот тут если упадет — вы мне маякните я все исправлю, а тут мы ой забыли чейто вкоммитить, щас минутку все будет, а тут есть настройки только для куэя, а для прода почему-то нет, как неудобно получилось, и вообще у вас билд система не правильная у нас локально все деплоилось!»
Сам билд может падать по миллиону причин, включая внезапно проведенные на проде «non significant» тех работы с совсем мало мало апдейтами сертификатов, или даже не на проде, а у конечных клиентов ИЕ обновился — и привет юаю )
Vladimir_Naumov
11.04.2019 12:52Не сказал бы, что это «круто», а скорее дополнительная/крайняя мера в случае невозможности моделирования случаев с ошибками 3-party, интеграцией(которой нет на pre-проде).
По п.3 тестировать deploy на проде не лучшая идея, тестирование самого развертывание необходимо проворачивать на pre-проде, а на прод отправлять уже отлаженный билд. ИМХО
Во время штатной работы системы вероятность обнаружения ошибки пользователем(клиентом) куда выше нежели одним тестировщиком, который будет параллельно пользователям проводить проверки, в т.ч. регрессионные. Регресс до прода обязателен.olgamirko97
11.04.2019 17:49Спасибо за Ваше мнение!
По поводу первого и третьего замечания: конечно, QA на проде это дополнительная активность в тестировании, она так и позиционируется в статье.
По поводу второго ответила выше.
fpsthirty
12.04.2019 10:24Тестирование на проде даёт самый ценный (и дорогостоящий) фидбэк. Заказчику не приносят прибыль безупречность тестовых стендов. Стороне исполнителя следует понимать, что они крайне заинтересованы в прибыли заказчика и балансировке фидбэка с тестовых и продовых окружений.
Последние полтора года, на одном из наших значимых проектов, дополнительно на проде по крону гоняем основные сценарии функциональных автотестов: создание заказов при различных входных данных по методам оплаты/доставки и т.д., с их последующей отменой. И это действительно оправданно в виду немалого количества интеграций со сторонними сервисами, которые периодически могут нестабильно себя вести, что следует отлавливать (получаем уведомления о фейлах автотестов в телеграм/почту) и пинговать поддержку сторонних сервисов. Вдобавок, имеются особые итерации на проде, минующие тестовые окружения (импорт сотен тысяч продуктов и т.д.), что могут повлечь за собой нестабильность прода. Для понимания жизнеспособности боевого окружения, в довесок к графикам из мониторингов (zabbix / newrelic / т.д.), ориентируемся на результаты автотестов.mkovalevskyi
12.04.2019 16:09и все сторонние сервисы адекватно обрабатывают тестовые даные? это ж сколько лет нужно убить на согласования )
fpsthirty
13.04.2019 15:55Нужный-правильный вопрос. Со всеми сервисами договариваться не пришлось, сделали упор лишь на те, где деятельность «ботов» давала заметный вред:
1. Call-центр. Заказчик заинтересован в стабильности, поэтому смогли быстро решить вопрос с тем, чтобы операторы не тратили время на заказы, выполненные под определёнными наборами данных (фио/email), по которым можно понять, что заказ совершён не человеком, а дружелюбным ботом, на которого нет нужды куда-либо жаловаться.
2. Склады с остатками продуктов. Тут всё просто: после автоматизированной отмены соответствующего заказа (в течение нескольких минут после создания), остатки по продуктам автоматически возвращались на склады. Обычная отлаженная ситуация, т.к. нередки случаи отмены заказов со стороны обычных пользователей.
3. Аналитика. Дабы избежать перекосов в конверсии и прочих направлениях, пришлось поколдовать: в автотестах при взаимодействии со ссылками и адресной строкой, проверять env по ответу isProduction(), в случае успеха — дописывать в линк особый get-параметр перед тем, как взаимодействовать с ним. На редиректящие кнопки без линков забили, т.к. все необходимые кейсы уже перекрывались применяемыми фильтрами в аналитике.
4. Эквайринг. Заказчик пошёл навстречу. Создавали заказы с определённым набором входных данных, позволяющий производить оплату определённых продуктов по минимально допустимой цене (дебетовая карточка настоящая, и баланс на ней не бесконечен). Правда, в первые дни словили бан со стороны эквайринга, посчитавшего наши операции подозрительными, но в итоге всё обошлось: со своей стороны, они добавили нашу подсеть и ещё-не-помню-какой набор данных в белый лист, после чего продолжаем спокойно оплачивать заказы. Возврат платежей происходил примерно через 30–45, так что в начале на карту закинули сумму, позволяющую создавать заказы в течение ~2+ месяцев.
Примечание: да, помимо факта создания заказа, процесс оплаты тоже тестим, ибо бывали случаи недоступности оплаты по карте, и все следы вели к стороне эквайринга.
5. Рекламные акции. Причём от различных сервисов, с неочевидной логикой появления баннеров в модальных окнах. При этом механика появления почему-то расходилась с теми задокументированными сценариями, которые были переданы со стороны их поддержки. Но успех не заставил себя долго ждать: каждый сервис предоставил набор cookie, с которыми на нашем целевом сайте не триггерился вызов соответствующей рекламной кампании.
olgamirko97
12.04.2019 18:34Интересное мнение и опыт, спасибо!
Мы в компании тоже сталкиваемся с подобными вопросами: большое количество интеграций со сторонними сервисами и итерации, минующие тестовые окружения (в основном по изменению настроек и импорт-экспорт данных). Это ещё один пункт, объясняющий необходимость проверок на проде.
Также мы идём к тому, чтобы в проверках на проде помогали автотесты.
EndUser
Цвета КДПВ напоминают логотип «самого большого в интернете архива „ничего“».