
Я ведущий Java-разработчик в Яндекс.Деньгах.
Каждое рабочее утро в 2018 году меня встречали около 30 пулл-реквестов, ожидающих ревью, а у меня не хватало времени разобрать их все за день. В конце лета я ушел в отпуск, а когда вернулся, обнаружил очередь из 50 PR, назначенных на меня. Разгребать их не было никакого желания, а ведь это была лишь вершина айсберга, которую я видел своими глазами. В тот день я и решил, что пора что-то изменить.
Это история о том, как мы ускорили код-ревью, разгрузили ведущих разработчиков и улучшили инструменты, которыми пользуемся каждый день.
Код-ревью 1.0. Как было раньше?
В Яндекс.Деньгах код-ревью уже давно стало обязательным этапом разработки, и все к этому давно привыкли. Одни понимали, что это такая же нужная вещь, как тестирование; другие относились к этому как к необходимому злу, а кто-то сталкивался с код-ревью только в роли автора пулл-реквестов, но сторонился ревью чужого кода. Думаю, многие проходили путь последовательно от последнего к первому, и это нормально.
Для код-ревью мы с самого начала использовали Bitbucket. Для каждого репозитория компонента задавался список из 3-4 ревьюеров по умолчанию, которые добавлялись во все PR. Обычно этот список составлялся и редактировался начальником отдела, а иногда туда добавлялись добровольцы, которые сами хотели ревьюить тот или иной компонент. В репозиториях библиотек было чуть проще – список ревьюеров был единым для всех библиотек, и туда входили старшие разработчики.
В итоге почти вся нагрузка ложилась на ревьюеров из числа старших разработчиков, которых постепенно переставало хватать, с учетом роста отдела до 60 человек, увеличения количества репозиториев (60+ компонентов, 100+ библиотек) и ускорения нашего CI/CD.
Кроме большой нагрузки и нехватки ресурса ревьюеров, были и другие проблемы:
- в некоторых компонентах можно было ожидать реакции ревьюеров более суток,
- высокая загруженность тех, кто назначен ревьюером в нескольких компонентах,
- тяжело привлекать новых ревьюеров, в том числе из-за предыдущего пункта,
- если основной ревьюер заболел или в отпуске, время код-ревью компонентов начинало заметно увеличиваться,
- назначенные ревьюеры не всегда имели реальную экспертизу в компоненте, из-за этого страдало качество код-ревью.
Перед тем как решать эти проблемы, нужно определиться с тем, чего мы вообще ждем от код-ревью.
Правильное код-ревью — это как?
Мы выделили четыре пункта, которые должны быть в обновленном код-ревью:
- Проверка архитектуры решения. Довольно очевидная вещь. Ожидаем это от старших разработчиков с экспертизой в данном компоненте.
- Проверка технической реализации, которую ожидаем также от старших и мидлов с экспертизой в данном компоненте.
- Передача знаний, которая заключается в изучении бизнес-логики и кодовой базы новичками и джунами посредством код-ревью.
- Возможность оценки hard skills разработчиков. Хочется, чтобы за каждым разработчиком был закреплен наставник, который оценивает рост, определяет вектор развития, подмечает какие-то недостатки, делает замечания и так далее. Поэтому наставник также должен видеть код своих подопечных.
Возможно, кто-то видит другие цели или не согласен с нашими — делитесь в комментариях. А я пока перейду от формулирования целей к поиску средств их достижения – мы решили, что хотим достичь их все и (почти) сразу.
Код-ревью 2.0. Как стало?
Что же мы придумали? Мы стали рассуждать пошагово.
В Яндекс.Деньгах разработчики работают в командах по бизнес-направлениям, обычно по 2-4 бэкенд-разработчика в команде.
Допустим, я собираюсь открыть пулл-реквест, то есть я его автор. У меня есть моя команда, разработчики которой хорошо знают бизнес-логику того, что я делаю, потому что мы все участвуем в общих проектах, часто синхронизируемся и вообще активно взаимодействуем. Поэтому хочется добавлять их в мои пулл-реквесты в первую очередь, чтобы они как минимум были в курсе того, что я делаю.
За каждым компонентом в Яндекс.Деньгах закреплена команда, которая за него отвечает и сопровождает на продакшене.
Если я дорабатываю компонент, за который отвечает другая команда, то кажется логичным добавлять разработчиков из этой команды в ревьюеры – они ведь отвечают за этот компонент и должны следить за качеством его кода. Но, чтобы не перегружать ревьюеров, возьмем только одного случайного человека из этой команды — считаем, что этого достаточно.
Может случиться так, что команда, отвечающая за компонент, не владеет в нём достаточной экспертизой. Такое бывает, когда в команде появляются новички или им вверили этот компонент только недавно. Однако я знаю, что у нас в компании есть реальные эксперты по этому репозиторию, и было бы классно, чтобы кто-то из них посмотрел мой код! Конечно, моё знание сложно формализовать, но ведь можно взять историю репозитория и посчитать по количеству PR и статистике код-ревью, кто много дорабатывал и/или много ревьюил этот код. Посчитаем метрику экспертизы в репозитории, выделим топ разработчиков по этой метрике, назовем их экспертами и будем добавлять одного случайного эксперта в ревьюеры.
В 2018 году мы в компании ввели институт наставничества, поэтому сейчас за каждой командой приглядывает один наставник из числа старших разработчиков. Также у каждого новичка в компании на первых порах есть персональный наставник.
Пускай же мой код смотрит мой наставник! Он сможет прийти на помощь в случае проблем на код-ревью, а также будет иметь представление о моих слабых и сильных сторонах в технических навыках.
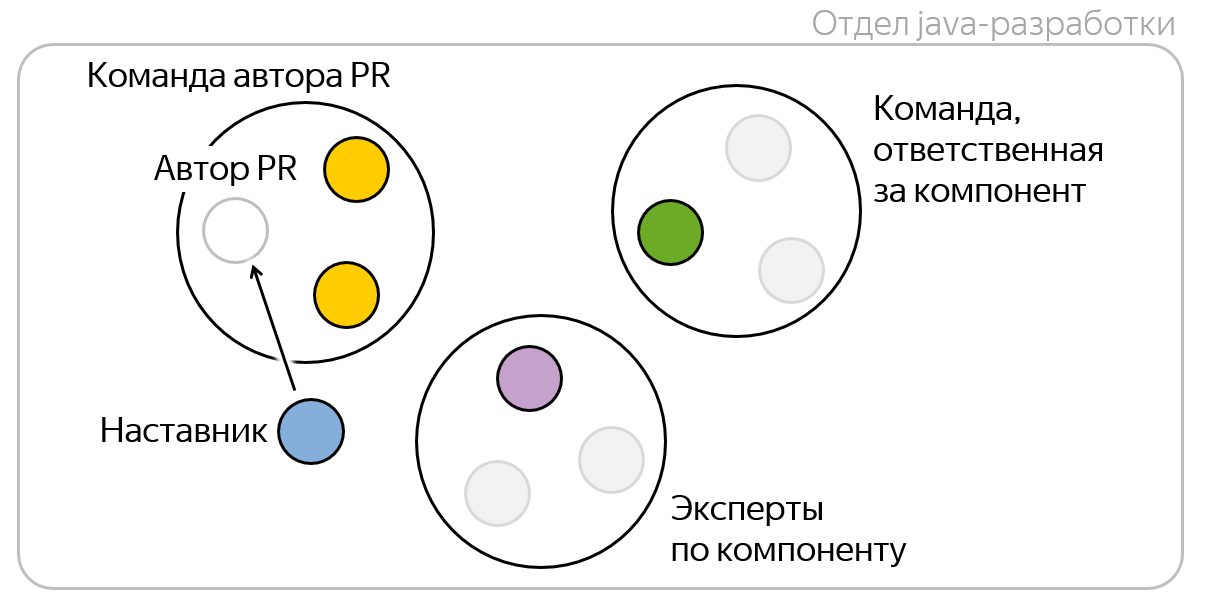
Итого в ревьюеры каждого пулл-реквеста может добавиться пять-шесть человек. Но на самом деле обычно их чуть меньше, потому что разные роли могут совмещаться в одном человеке. Мой наставник может одновременно быть и экспертом, а моя команда может быть ответственной за компонент. Субъективно кажется, что 3-4 ревьюера было бы оптимально для пулл-реквестов.
Код-ревью 2.0. Что под капотом?
Дело за малым: заставить всё это работать. Помогло здесь то, что все наши составы команд уже были заведены в отдельной системе, которая предоставляет REST API по их получению. Поэтому после пары недель неторопливой разработки в свободное время родилась первая версия плагина для Bitbucket, который постепенно дорабатывался и в течение осени обзавелся всем необходимым набором функциональности.
Как работает плагин
Обычно в Bitbucket при создании PR предзаполняются ревьюеры, которые заданы в настройках проекта или репозитория. Тут с точки зрения пользователя ничего не изменилось — все ревьюеры также предзаполняются при открытии этой страницы, разве что добавилось поле с описанием, какой ревьюер в какой роли добавился. А роли ревьюеров у нас появились следующие:
- teammate — член команды автора PR, легко добавляется благодаря REST API с составами команд,
- repository owner — случайный член команды, которая отвечает за компонент; понадобилось в настройках репозитория дать возможность выбирать ответственную команду,
- repository expert — случайный эксперт по репозиторию; об этом подробнее расскажу чуть позже,
- mentor — наставник команды или новичка, также доступен по REST API из сервиса с составами команд.
Эксперты по репозиториям
Чуть подробнее расскажу о том, как мы считаем экспертов. Ежесуточно плагин проходит по всем репозиториям, смотрит все пулл-реквесты за последний год и считает две простые метрики:
- количество пулл-реквестов, созданных разработчиком,
- количество PR, которые он отревьюил и поставил approve, needs work или decline.
Добавим веса к этим метрикам исходя из того, что с точки зрения экспертизы в коде, доработка этого кода важнее, чем ревью. Сначала мы оценили количество созданных пулл-реквестов в полтора раза важнее ревью, а позже увеличили соотношение до трех к одному. Суммируем этим метрики, умноженные на их веса, и получаем рейтинг разработчика.
Далее сортируем всех этих разработчиков по рейтингу, выбираем топ-5, попутно отсекаем тех, чей рейтинг ниже порогового, чтобы отсечь случайных прохожих. И получаем обычно от трех до пяти экспертов по каждому репозиторию.
Выше я описал вам подход к подбору ревьюеров, который мы выбрали и реализовали, но попутно мы реализовали сразу несколько небольших улучшений, которые сделали процесс код-ревью еще быстрее, удобнее и приятнее.
Запрет merge пулл-реквеста, пока не проверена задача в Jira
Такая очевидная и нужная вещь, которая, к сожалению, не идет из коробки. У нас в dev попадает только стабильный код, который прошел не только статические проверки и тесты разработчиков, но и интеграционное тестирование вместе с другими сервисами. Статус такого тестирования у нас отражается только в задаче Jira, и поэтому ранее разработчикам приходилось вручную смотреть, проверена ли задача, чтобы вмержить пулл-реквест.
Автоматический merge пулл-реквестов
Немалую часть своей жизни пулл-реквест может провести в состоянии, когда уже ничего не мешает его вмержить, но человек забывает это сделать или делает не сразу. Яркий пример — ожидание тестирования задачи, без которого мы не мержим ее в dev. Тут и пригождается автоматический merge, который работает по простому принципу: если PR можно вмержить, то мы это делаем.
Все необходимые условия для merge покрыты проверками. Мы проверяем успешность сборки, уровень покрытия тестами, отсутствие snapshot-зависимостей библиотек, статус задачи в Jira и наличие всех необходимых аппрувов. То есть у нас есть всё, чтобы использовать такую функциональность и забывать о PR с момента прохождения код-ревью и передачи задачи в тестирование (если конечно QA в ней не обнаружит проблем).
А реализовали мы это довольно удобным образом: ввели специального бота AutoMergeBot, которого просто нужно добавить в ревьюеры, чтобы он начал следить за этим пулл-реквестом и вмержил его, когда придет время.
Учет отсутствий ревьюеров
Если владелец компонента или эксперт в отпуске или на больничном, он не будет добавляться ревьюером, а его место займет тот, кто находится на рабочем месте. В качестве бонуса на этого ревьюера по выходе из отпуска не свалится гора чужих пулл-реквестов. Реализовать это было нетрудно благодаря тому, что все отсутствия сотрудников у нас заведены заявками в Jira.
Учет занятости ревьюеров
Кто-то ревьюит десять PR в день, а кто-то пять. У кого-то уже накопилось 20 непросмотренных PR, а у кого-то их почти нет. Мы всё это учитываем, чтобы более равномерно распределять нагрузку на ревьюеров. Чем больше нагрузки, тем меньше его добавляют в новые PR — всё просто.
Маркировка размеров PR при создании
На странице создания пулл-реквеста автор может выбрать его ориентировочный размер: S, M или L. Это помогает ревьюерам оценить примерное время, которое они потратят на код-ревью. Например, у меня есть свободные 5 минут, и я понимаю, что смогу успеть посмотреть пулл-реквест размера S. При этом нет смысла открывать M или L, потому что я не успею их досмотреть и в следующий раз придется начинать с чистого листа.
В будущем мы хотим учитывать эти атрибуты при подсчете статистики по PR.
Маркировка срочных PR
Также при создании PR автор может указать, что задача очень срочная, добавив такой символ в название PR. Его сразу увидят ревьюеры и постараются посмотреть в первую очередь. Вроде мелочь, а очень полезная и удобная.
Трекинг начала и окончания код-ревью
Если при улучшении процесса невозможно понять, насколько он улучшился, то и начинать нет смысла.
Так и с код-ревью — мы сколько угодно можем пытаться его улучшить, но как мы будем уверены в позитивной динамике без метрик и статистики? В нашем случае это не самая простая задача — из коробки Bitbucket и Jira не давали возможности отслеживать время код-ревью. На вооружении была только метрика времени жизни PR, которая не совсем нас устраивала, ведь мы мержим пулл-реквесты только после окончания тестирования задачи, поэтому в данную метрику замешивались и посторонние показатели.
Jira хранит и позволяет выгружать все контрольные точки жизненного цикла задачи, поэтому мы посчитали правильным обогатить эти данные двумя дополнительными метками: временем начала и окончания код-ревью. Нужно было просто научить плагин для Bitbucket пушить эти метку в Jira. Таким образом, Jira как была, так и остается single point of truth для задачи, и по этому набору данных мы можем отделить время код-ревью от времени тестирования задачи.
Самый тонкий момент здесь в том, как определить момент окончания код-ревью? Может, это время получения первого аппрува, может, последнего, а может, это время внесения последних правок автором PR? У меня нет ответа на этот вопрос, тут просто надо договориться между собой и выбрать что-то одно либо покрывать метриками все три события и следить за девиациями.
Трекинг загрузки ревьюеров
Еще одна полезная метрика — загруженность ревьюеров. Как я писал выше, мы учитываем её при назначении ревьюеров в новые PR, но также мы публикуем эту информацию для того, чтобы следить за динамикой по командам, отделу или компании. Иногда это помогает обнаруживать аномалии и потенциальные проблемы: если видно, что у одного или нескольких человек в команде каждый день висит по 10 и более непросмотренных PR, значит, есть повод узнать, всё ли в порядке.
Просмотр метрик в Grafana
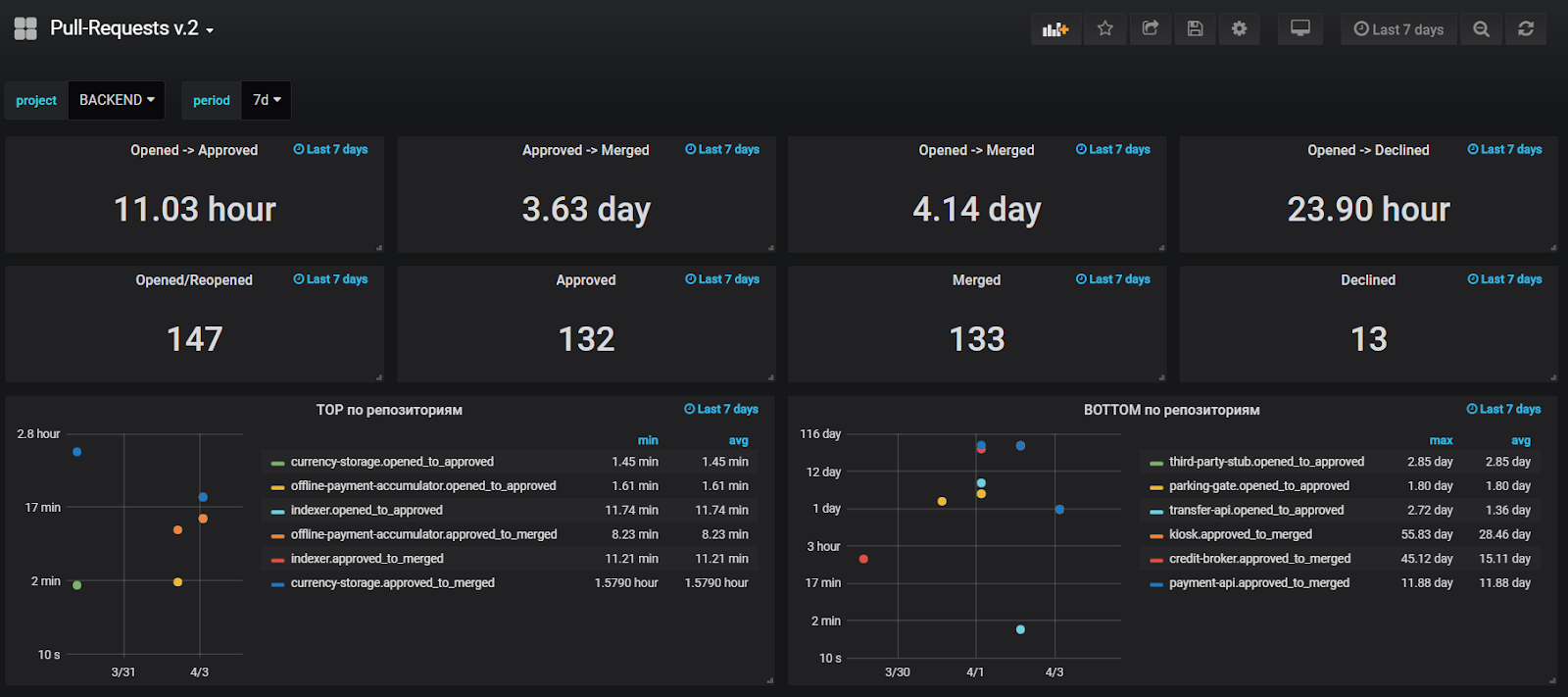
Строить отчеты по данным из Jira полезно, но не совсем удобно, поэтому мы одновременно с этим добавили отправку метрик по основным событиям в StatsD, чтобы строить графики по оперативным данным в Grafana. Мы следим за средним временем до первого аппрува, средним временем жизни PR, а также смотрим аномальные значения по этим метрикам, чтобы оперативно находить и решать проблемы.
На момент написания статьи наш дашборд выглядит так:
Что получили в итоге?
К сожалению, все мы сильны задним умом, поэтому упомянутые выше метрики код-ревью мы ввели не до начала изменения самого процесса (сентябрь-октябрь 2018), а уже по ходу, поэтому достоверно отслеживать улучшения или ухудшения мы можем только начиная с начала декабря 2018. Что же мы успели заметить?
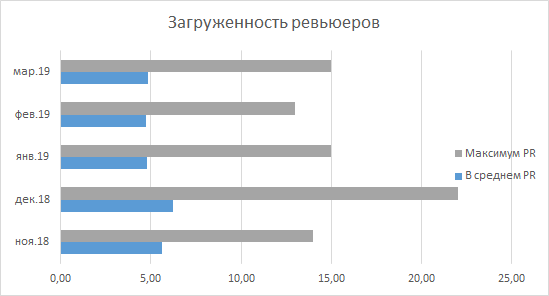
Первым делом бросается в глаза снижение нагрузки на ревьюеров из числа старших разработчиков, и я почувствовал это на собственном примере. Как я уже упоминал, для меня было нормой видеть с утра около 30 PR в очереди, сейчас же это число колеблется между 10 и 15. Статистика по отделу подтверждает это: начиная с декабря 2018 максимальное количество PR, ожидающих ревью, ни у кого не поднимается выше 15. В среднем же мы наблюдаем картину, которая говорит о том, что в среднем каждого разработчика с утра ожидает 4-5 непросмотренных PR, что видится вполне адекватным числом.
Что касается релевантности подбора ревьюеров и качества проведения код-ревью, тут мы можем опираться только на субъективные показатели. По опросам коллег, мы и правда стали получать отличный подбор ревьюеров, никого теперь не приходится добавлять вручную, и никакие PR не остаются брошенными и забытыми.
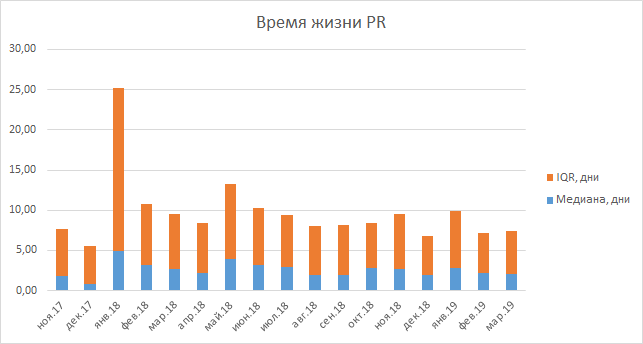
Если же говорить о времени прохождения код-ревью, то статистику по этому показателю пока рано подсчитывать, потому что мы начали её собирать совсем недавно. В нашем распоряжении есть только время жизни пулл-реквестов, которое на самом деле не выросло и не упало. Эта метрика включает в себя время тестирования задачи, поэтому однозначные выводы по ней сложно сделать, кроме того, изменив код-ревью, мы не сделали его более долгим.
Комментарии (21)

amarao
12.04.2019 11:29+2В code review самый ужас, когда написавший код, является единственным экспертом в области. И это не настолько патетично, как можно себе представить. Например, пишется коннектор из приложения в YASDB. В принципе, фича минорная и YASDB никто использовать всерьёз не хочет, но (другая) компонента использует библиотеку, у которой штатный режим работы — это YASDB. Окей, кто-то пошёл, разобрался как с ней работать. Написал. Засылает PR.
Дальше:
а) Других эспертов в YASDB в компании нет и не планируется.
б) Заславший эксперт только в сравнении с другими (почитал пару дней доки)
в) Логика происходящего понятна только написавшему (т.к. он сопровождает этот кусок).
Разумеется, такой PR принимают, и пользы от такого code review почти никакой. А в codebase прилетает liability в форме куска знаний, которые нужны, чтобы это «трогать».
YASDB = yet another sql database
bm13kk
12.04.2019 12:30+11 функциональные тесты* которые покажут команде как пользоваться этой либой. Если команда не понимает — надо больше функционыльных тестов.
* технически интеграционные так как проверяется работа либы с либой. Но по смыслу это именно функциональные
2 код все равно должен отвечать архитектуре приложения. Например правильные слои DDD, не нарушения SOLID и прочее. Для проверки архитектуры знать о чем пулл реквест не нужно.
3 опять же интеграционные тесты помогут разбить лапшу и и как-то обьяснить логику внутреннего кода. Но это будет работать при хороших тестах, а не для отписки где проверяют только едже-кейсы.
amarao
12.04.2019 13:44Фокус тут не на код. Бывает код, который не хочется втаскивать в компетенцию команды (сделал и забыл). Это плохо для сопровождения кода, но и команда — не резиновая.
Условно, предположим, что это не «sql», а, например, код для работы с библиотекой, которая позволяет считать шаровую часть тензора для передачи в библиотеку, которая по картинке может сказать виляет ли на ней собака хвостом или нет.
Ну напишите вы функциональные тесты. Как будто команда лучше будет понимать что такое шаровая часть тензора и чем оно от девиатора отличается.
Боль же возникает в тот момент, когда это приносят. И не принести нельзя, и ресурсов на разобраться тоже нет.
vassabi
12.04.2019 14:45… все это жизнь, а жизнь — это боль. Боль — это хорошо, это показатель, что принесенная часть проекта живая, кем-то используется, и значит — пора выделять ресурсы «на разобраться».
(я так всегда своим коллегам говорю, когда втаскиваем в проект зависимости из разных странных библиотек).amarao
12.04.2019 14:47Вы исходите из того, что всё, что делается — это для пользы. Часто бывает так, что что-то делается, и умирает не будучи доделанным. Из-за этого инвестировать силы и время во всё — никакого времени не хватит.
Кстати, как только вы выделили ресурсы на разобраться с одной неведомой фигнёй, у другой неведомой фигни рерсусов стало меньше.
bm13kk
12.04.2019 16:10Управляющая составляющая моей карьеры (менеджерская) не так чтобы бурно цветет.
Но я слишком хорошо вижу цену нарушения «правила бойскаута». Как пример — на каждое кажущуюся экономию в коде-лапше будет многократно превыщающая растрата позже. Чем позднее — тем дороже. Аналогично с артефактами — документация, инфраструктура, тулинг.
И аналогично с самими проектами. Нельзя сделать субпроект и забыть о нем. Всегда, всегда прийдется к нему возвращаться и доделывать. И чем хуже ты его сделал — тем дороже доделывать/переделывать.
Я неоднократно видел как компании оплачивают эти долги, чтобы убедиться что правило неизбежно. И дважды видел как компании все делают медленно и правильно с самого начала. И награждаются более бытсрой разбработкой и ростом полгода или год спустя. Чтобы знать что правильно таки нужно делать.
smarthomeblog
12.04.2019 17:14Справедливо. Просто есть большое количество компаний с большой текучкой народа — как айтишного, так и руководящего. И в этом случае, руководящему звену все равно, сколько будет стоить переделка или доделка проекта, сделанного на скорую руку. Так как это будет явно не их головной болью.
amarao
12.04.2019 17:17Ничуть не возражаю против этого. Но бывает и обратное. Инвестируются гигантские усилия в десятки тысяч долларов (в пересчёте на ЗП) в технологию, под которую бизнес-критикал код постепенно адаптируется, а потом выясняется, что очередной убийца мускуля не совсем ACID, и даже совсем не ACID. Или он ложится под нагрузкой. Или компания решает сменить лицензию и все дружно забивают на её продукт, выпиливают из репозиториев и т.д. После чего, все инвестиции идут лесом. Причём не только в форме потраченных денег, но и упущенного ресурса для тех кусков проекта, которые остались жить.
Оверинвестиции в то, что может и не взлететь — дорого. Недоинвестиции в то, на что будешь полагаться — чревато.bm13kk
14.04.2019 13:05Есть такой кейс, сталкивался.
Тут одно из двух. Это новый проект и он изначально написан поверх технологии. То есть без нее проекта уже не будет. Тогда проект надо просто выкидывать. Пока еще есть команда со знанием домена и проблем, чтобы вторую версию быстрее написать.
Либо это миграция рабочего проекта. В таком случае и нужны всякие прокси, фасады, инверсии зависимостей и далее по списку. Плюс штука название котороя я постоянно забываю. Когда выкатывается и деплоится новый функционал (код) но только в следующем релизе он включается одним нажатием. Таким образом проект сразу работает на двух технологиях. Это дороже. Но как раз дает возможность быстрого отката.
А лицензия — как мне кажется не является большой проблемой. Потому что ее нельзя менять на текущий код. Только на новую версию. А в энтерпрайзе и так все лочится где надо и где не надо.

ufna
12.04.2019 16:55Плагин звучит очень здорово, нет ли планов сделать его общедоступным? :) (т.к. проблема близка, идея примерно такая же, только приходится делать это всё ручками)
adrimmv Автор
12.04.2019 23:28Если есть спрос, будет и предложение :) Да, многие функции, не завязанные на наши внутренние инструменты (получение составов команд, отсутствий ревьюеров), вполне можно выделить в отдельный плагин и опубликовать.
А вам какие фичи были бы наиболее полезны?
XT2
12.04.2019 23:20Мы прямо сейчас как раз делаем плагин для Jira + интеграционный сервис между Jira <-> GitLab, но акцент больше на тикет систему и пайплайны. На вашем опыте вижу, что и ревью тоже классно ложится на эти рельсы. Спасибо за статью!

sergey-b
13.04.2019 22:06На загруженность ревьюеров больше всего влияет количество неодобренных PR. Каждый отклоненный реквест — это новая доработка и новое ревью в ближайшем будущем. На мой взгляд, именно здесь наибольший потенциал для оптимизации. Хотя, в Яндекс.Деньгах, возможно, ситуация иная.
Я в свое время, чтобы разгрести завалы code review, составил чек-лист, чего я смотрю в коде. Получилось где-то 100 пунктов. Попросил всех разработчиков перед передачей кода мне на ревью прочекать этот чек-лист и проставить напротив каждого отметку вида Соблюдается/Не применимо/Нарушается там-то по тому-то по согласованию с тем-то.
После этого процесс ревью у меня выглядел так:
- Чек-лист заполнен? Нет — PR на доработку, минус в карму.
- Смотрю, где в чек-листе отмечены отклонения от требований, и иду туда смотреть
- Если автор имеет низкую карму, тщательно просматриваю весь код.
- Если автор имеет хорошую карму, выборочно просматриваю самые интересные файлы.
- Если нашел косяк, предусмотренный чек-листом, — PR на доработку, минус в карму.
- Если нашел что-то новенькое, тщательно просматриваю весь код, обновляю чек-лист. Создаю задачу на доработку. Если проблема не очень критична, ставлю approve. Если проблема критична, то PR отправляю на доработку.
Поначалу пришлось повозиться, отсмотреть все замечания по всем ревью за последний год, прочитать комментарии по всем зарегистрированным дефектам, затем скомпилировать это все в чек-лист. Самое сложное было — уговорить команду использовать этот чек-лист. Зато потом трудоемкость code review сократилась в разы, и, самое главное, сократилось количество повторных ревью.tangro
15.04.2019 11:23Согласно приведённому алгоритму карма в нескольких случаях уменьшается и никогда не увеличивается, т.е. рано или поздно алгоритм сведётся к пункту №3, поскольку низкая карма будет у всех :)
PastorGL
Интересно, почему в описаниях проектов Яндекса (и связанных с ними) общепринятые в индустрии решения так часто выдаются за инновацию. Вы описали обычное, стандартное peer review. Практика эта хорошо формализована, и все более-менее продвинутые ребята так делают, причём давно.
Вам запрещено брать чужой опыт, и поэтому вы вынуждены додумываться до best practices самостоятельно? Это очень странно.
gre
А ребята автоматизировали это, получили отчёты и поделились.
В чём проблема?
PastorGL
Так проблемы-то как раз никакой нет %) Особенно её не должно быть для такой серьёзной на вид конторы.
А основная странность — в том, что заняться этим они решили только сейчас. Обычно к автоматизации peer review приходят ещё в течение первого года, когда команда вырастает до ~15 человек, и надо выстраивать процессы, чтобы завалов с PR не было. Тут же явно припозднились, яндекс-деньги сколько уже существуют?
Но так-то я рад за них. Лучше иметь хорошие процесссы поздно, чем никогда.
adrimmv Автор
Проблемы обычно решаются по мере их появления и обнаружения. При взгляде извне проблем не наблюдалось — время жизни PR было приемлемым (а это была по сути единственная метрика), а значит все ОК. За нагруженностью ревьюеров просто никто не следил, а качество код-ревью оценить тем более очень сложно.
А стоило всплыть проблеме излишней загрузки ревьюеров «изнутри», и когда стало ясно, что это не случайный всплеск, а закономерность, тогда и начали ее решать, а заодно пересмотрели весь процесс код-ревью и опыт других компаний учли. Не думаю, что это странность.
Вот то что не было нормальных метрик код-ревью раньше — это скорее было ошибкой на мой взгляд, теперь исправились.
Aingis
Просто в Яндекс приходят те, кто эти практики попросту не знают.
roman_kashitsyn
Яндекс ? Яндекс.Деньги.
Сомневаюсь, что в Яндексе ещё кто-то пользуется Jira, там есть отличный внутренний багтрекер, рядом с которым Jira несколько лет назад выглядела мамонтом (по скорости работы, интерфейсу, удобству и отказоустойчивости).
Ну и наверняка Император уже навёл порядок и унифицировал код-ревью почти везде.
kentilini
(=