Предисловие или как возникла идея секционирования
Начало истории здесь: Ты помнишь, как все начиналось. Все было впервые и вновь. После того, как почти все ресурсы для оптимизации запроса, на тот момент, были исчерпаны, встал вопрос — а что же дальше? Так и возникла идея о секционировании.

Лирическое отступление:
Именно 'на тот момент', потому, что как выяснилось, имелись неиспользованные резервы оптимизации. Спасибо asmm и Хабру !
Итак, как еще можно сделать заказчика как бы счастливым, заодно и прокачать собственные скилы?
Если предельно всё упростить, то, путей кардинально, что-то улучшить в быстродействии базы данных, всего два:
- Экстенсивный путь — наращиваем ресурсы, меняем конфигурацию;
- Интенсивный путь — оптимизация запросов.
Поскольку, повторюсь, на тот момент не понятно было, что же еще поменять в запросе для ускорения, был выбран путь — изменения дизайна таблиц.
Итак — возникает главный вопрос — а, что и как менять будем?
Начальные условия
Во-первых, имеется вот такая ERD (показано условно-упрощенно):
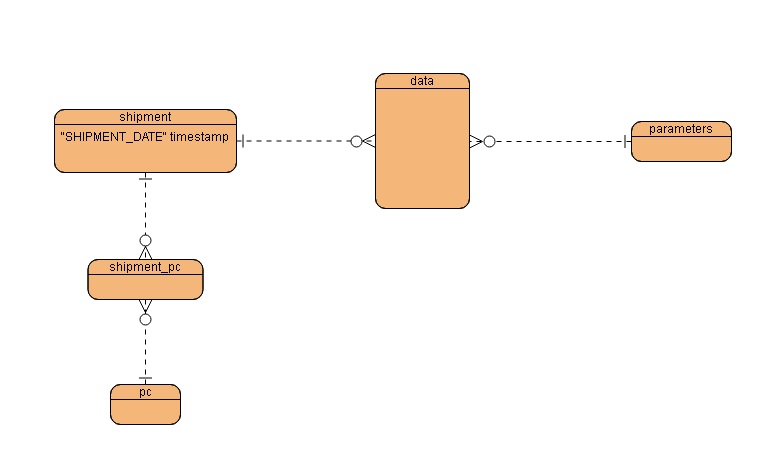
Основные особенности:
- отношения «многие ко многим»
- таблица уже имеет потенциальный ключ секционирования
Исходный запрос:
SELECT
p."PARAMETER_ID" as parameter_id,
pc."PC_NAME" AS pc_name,
pc."CUSTOMER_PARTNUMBER" AS customer_partnumber,
w."LASERMARK" AS lasermark,
w."LOTID" AS lotid,
w."REPORTED_VALUE" AS reported_value,
w."LOWER_SPEC_LIMIT" AS lower_spec_limit,
w."UPPER_SPEC_LIMIT" AS upper_spec_limit,
p."TYPE_CALCUL" AS type_calcul,
s."SHIPMENT_NAME" AS shipment_name,
s."SHIPMENT_DATE" AS shipment_date,
extract(year from s."SHIPMENT_DATE") AS year,
extract(month from s."SHIPMENT_DATE") as month,
s."REPORT_NAME" AS report_name,
p."SPARAM_NAME" AS SPARAM_name,
p."CUSTOMERPARAM_NAME" AS customerparam_name
FROM data w INNER JOIN shipment s ON s."SHIPMENT_ID" = w."SHIPMENT_ID"
INNER JOIN parameters p ON p."PARAMETER_ID" = w."PARAMETER_ID"
INNER JOIN shipment_pc sp ON s."SHIPMENT_ID" = sp."SHIPMENT_ID"
INNER JOIN pc pc ON pc."PC_ID" = sp."PC_ID"
INNER JOIN ( SELECT w2."LASERMARK" , MAX(s2."SHIPMENT_DATE") AS "SHIPMENT_DATE"
FROM shipment s2 INNER JOIN data w2 ON s2."SHIPMENT_ID" = w2."SHIPMENT_ID"
GROUP BY w2."LASERMARK"
) md ON md."SHIPMENT_DATE" = s."SHIPMENT_DATE" AND md."LASERMARK" = w."LASERMARK"
WHERE
s."SHIPMENT_DATE" >= '2018-07-01' AND s."SHIPMENT_DATE" <= '2018-09-30' ;
Результаты выполнения на тестовой базе данных:
Cost : 502 997.55
Execution time: 505 seconds.
Что мы видим? Обычный запрос, по временному срезу.
Делаем простейшее логическое предположение: если есть выборка временного среза, то нам поможет? Правильно — секционирование.
Что секционировать?
На первый взгляд, выбор очевиден — декларативное секционирование таблицы «shipment» по ключу «SHIPMENT_DATE» (забегая сильно вперед — в итоге на продакшн получилось немного не так).
Как секционировать?
Этот вопрос тоже не слишком сложный. Благо, в PostgreSQL 10, теперь человеческий механизм секционирования.
Итак:
- Сохраняем дамп исходной таблицы — pg_dump source_table
- Удаляем исходную таблицу — drop table source_table
- Создаем родительскую таблицу с секционированием по диапазону — create table source_table
- Создаем секции — create table source_table, create index
- Импортируем дамп, созданный на шаге 1 — pg_restore
Скрипты для секционирования
Для простоты и удобства, шаги 2,3,4 были объединены в одном скрипте.
Итак:
Сохраняем дамп исходной таблицы
pg_dump postgres --file=/dump/shipment.dmp --format=c --table=shipment --verbose > /dump/shipment.log 2>&1Удаляем исходную таблицу + Создаем родительскую таблицу с секционированием по диапазону + Создаем секции
--create_partition_shipment.sql
do language plpgsql $$
declare
rec_shipment_date RECORD ;
partition_name varchar;
index_name varchar;
current_year varchar ;
current_month varchar ;
begin_year varchar ;
begin_month varchar ;
next_year varchar ;
next_month varchar ;
first_flag boolean ;
i integer ;
begin
RAISE NOTICE 'CREATE TEMPORARY TABLE FOR SHIPMENT_DATE';
CREATE TEMP TABLE tmp_shipment_date as select distinct "SHIPMENT_DATE" from shipment order by "SHIPMENT_DATE" ;
RAISE NOTICE 'DROP TABLE shipment';
drop table shipment cascade ;
CREATE TABLE public.shipment
(
"SHIPMENT_ID" integer NOT NULL DEFAULT nextval('shipment_shipment_id_seq'::regclass),
"SHIPMENT_NAME" character varying(30) COLLATE pg_catalog."default",
"SHIPMENT_DATE" timestamp without time zone,
"REPORT_NAME" character varying(40) COLLATE pg_catalog."default"
)
PARTITION BY RANGE ("SHIPMENT_DATE")
WITH (
OIDS = FALSE
)
TABLESPACE pg_default;
RAISE NOTICE 'CREATE PARTITIONS FOR TABLE shipment';
current_year:='0';
current_month:='0';
begin_year := '0' ;
begin_month := '0' ;
next_year := '0' ;
next_month := '0' ;
FOR rec_shipment_date IN SELECT * FROM tmp_shipment_date LOOP
RAISE NOTICE 'SHIPMENT_DATE=%',rec_shipment_date."SHIPMENT_DATE";
current_year := date_part('year' ,rec_shipment_date."SHIPMENT_DATE");
current_month := date_part('month' ,rec_shipment_date."SHIPMENT_DATE") ;
IF to_number(current_month,'99') < 10 THEN
current_month := '0'||current_month ;
END IF ;
--Init borders
IF begin_year = '0' THEN
first_flag := true ; --first time flag
begin_year := current_year ;
begin_month := current_month ;
IF current_month = '12' THEN
next_year := date_part('year' ,rec_shipment_date."SHIPMENT_DATE" + interval '1 year') ;
ELSE
next_year := current_year ;
END IF;
next_month := date_part('month' ,rec_shipment_date."SHIPMENT_DATE" + interval '1 month') ;
END IF;
-- Check current date into borders NOT for First time
IF to_date( current_year||'.'||current_month, 'YYYY.MM') >= to_date( begin_year||'.'||begin_month, 'YYYY.MM') AND
to_date( current_year||'.'||current_month, 'YYYY.MM') < to_date( next_year||'.'||next_month, 'YYYY.MM') AND
NOT first_flag
THEN
CONTINUE ;
ELSE
--NEW borders only for second and after time
begin_year := current_year ;
begin_month := current_month ;
IF current_month = '12' THEN
next_year := date_part('year' ,rec_shipment_date."SHIPMENT_DATE" + interval '1 year') ;
ELSE
next_year := current_year ;
END IF;
next_month := date_part('month' ,rec_shipment_date."SHIPMENT_DATE" + interval '1 month') ;
END IF;
partition_name := 'shipment_shipment_date_'||begin_year||'-'||begin_month||'-01-'|| next_year||'-'||next_month||'-01' ;
EXECUTE format('CREATE TABLE ' || quote_ident(partition_name) || ' PARTITION OF shipment FOR VALUES FROM ( %L ) TO ( %L ) ' , current_year||'-'||current_month||'-01' , next_year||'-'||next_month||'-01' ) ;
index_name := partition_name||'_shipment_id_idx';
RAISE NOTICE 'INDEX NAME =%',index_name;
EXECUTE format('CREATE INDEX ' || quote_ident(index_name) || ' ON '|| quote_ident(partition_name) ||' USING btree ("SHIPMENT_ID") TABLESPACE pg_default ' ) ;
--Drop first time flag
first_flag := false ;
END LOOP;
end
$$;Импортируем дамп
pg_restore -d postgres --data-only --format=c --table=shipment --verbose shipment.dmp > /tmp/data_dump/shipment_restore.log 2>&1Проверяем результаты секционирования
Что же мы имеем в результате? Полный текст плана выполнения большой и скучный, поэтому вполне можно ограничиться итоговыми цифрами.
Было
Cost: 502 997.55
Execution time: 505 seconds.
Стало
Cost: 77 872.36
Execution time: 79 seconds.
Вполне хороший результат. Уменьшили стоимость и время выполнения. Таким образом использование секционирования дает ожидаемый эффект и в целом — без неожиданностей.
Обрадовать заказчика
Результаты тестирования были представлены заказчику на рассмотрение. И после ознакомления им был выдан несколько неожиданный вердикт: «Отлично, секционируйте таблицу «data»».
Да, но мы ведь исследовали совсем другую таблицу «shipment», таблица «data» не имеет поля «SHIPMENT_DATE».
Не проблема, добавляйте, меняйте. Главное, чтобы заказчика устраивало, что получится в результате, подробности реализации не особо то и важны.
Секционируем основную таблицу «data»
В общем-то никаких особых сложностей не возникло. Хотя, алгоритм секционирования, конечно, несколько поменялся.
Добавляем столбец «SHIPMENT_DATA» в таблицу «data»
psql -h хост -U база -d юзер
=> ALTER TABLE data ADD COLUMN "SHIPMENT_DATE" timestamp without time zone ;Заполняем значения столбца «SHIPMENT_DATA» в таблице «data», значениями одноименного столбца из таблицы «shipment»
-----------------------------
--update_data.sql
--updating for altered table "data" to values of "shipment_data" from the table "shipment"
--version 1.0
do language plpgsql $$
declare
rec_shipment_data RECORD ;
shipment_date timestamp without time zone ;
row_count integer ;
total_rows integer ;
begin
select count(*) into total_rows from shipment ;
RAISE NOTICE 'Total %',total_rows;
row_count:= 0 ;
FOR rec_shipment_data IN SELECT * FROM shipment LOOP
update data set "SHIPMENT_DATE" = rec_shipment_data."SHIPMENT_DATE" where "SHIPMENT_ID" = rec_shipment_data."SHIPMENT_ID";
row_count:= row_count +1 ;
RAISE NOTICE 'row count = % , from %',row_count,total_rows;
END LOOP;
end
$$;Сохраняем дамп таблицы «data»
pg_dump postgres --file=/dump/data.dmp --format=c --table=data --verbose > /dump/data.log 2>&1</sourceПересоздаем секционированную таблицу «data»
--create_partition_data.sql
--create partitions for the table "wafer data" by range column "shipment_data" with one month duration
--version 1.0
do language plpgsql $$
declare
rec_shipment_date RECORD ;
partition_name varchar;
index_name varchar;
current_year varchar ;
current_month varchar ;
begin_year varchar ;
begin_month varchar ;
next_year varchar ;
next_month varchar ;
first_flag boolean ;
i integer ;
begin
RAISE NOTICE 'CREATE TEMPORARY TABLE FOR SHIPMENT_DATE';
CREATE TEMP TABLE tmp_shipment_date as select distinct "SHIPMENT_DATE" from shipment order by "SHIPMENT_DATE" ;
RAISE NOTICE 'DROP TABLE data';
drop table data cascade ;
RAISE NOTICE 'CREATE PARTITIONED TABLE data';
CREATE TABLE public.data
(
"RUN_ID" integer,
"LASERMARK" character varying(20) COLLATE pg_catalog."default" NOT NULL,
"LOTID" character varying(80) COLLATE pg_catalog."default",
"SHIPMENT_ID" integer NOT NULL,
"PARAMETER_ID" integer NOT NULL,
"INTERNAL_VALUE" character varying(75) COLLATE pg_catalog."default",
"REPORTED_VALUE" character varying(75) COLLATE pg_catalog."default",
"LOWER_SPEC_LIMIT" numeric,
"UPPER_SPEC_LIMIT" numeric ,
"SHIPMENT_DATE" timestamp without time zone
)
PARTITION BY RANGE ("SHIPMENT_DATE")
WITH (
OIDS = FALSE
)
TABLESPACE pg_default ;
RAISE NOTICE 'CREATE PARTITIONS FOR TABLE data';
current_year:='0';
current_month:='0';
begin_year := '0' ;
begin_month := '0' ;
next_year := '0' ;
next_month := '0' ;
i := 1;
FOR rec_shipment_date IN SELECT * FROM tmp_shipment_date LOOP
RAISE NOTICE 'SHIPMENT_DATE=%',rec_shipment_date."SHIPMENT_DATE";
current_year := date_part('year' ,rec_shipment_date."SHIPMENT_DATE");
current_month := date_part('month' ,rec_shipment_date."SHIPMENT_DATE") ;
--Init borders
IF begin_year = '0' THEN
RAISE NOTICE '***Init borders';
first_flag := true ; --first time flag
begin_year := current_year ;
begin_month := current_month ;
IF current_month = '12' THEN
next_year := date_part('year' ,rec_shipment_date."SHIPMENT_DATE" + interval '1 year') ;
ELSE
next_year := current_year ;
END IF;
next_month := date_part('month' ,rec_shipment_date."SHIPMENT_DATE" + interval '1 month') ;
END IF;
-- RAISE NOTICE 'current_year=% , current_month=% ',current_year,current_month;
-- RAISE NOTICE 'begin_year=% , begin_month=% ',begin_year,begin_month;
-- RAISE NOTICE 'next_year=% , next_month=% ',next_year,next_month;
-- Check current date into borders NOT for First time
RAISE NOTICE 'Current data = %',to_char( to_date( current_year||'.'||current_month, 'YYYY.MM'), 'YYYY.MM');
RAISE NOTICE 'Begin data = %',to_char( to_date( begin_year||'.'||begin_month, 'YYYY.MM'), 'YYYY.MM');
RAISE NOTICE 'Next data = %',to_char( to_date( next_year||'.'||next_month, 'YYYY.MM'), 'YYYY.MM');
IF to_date( current_year||'.'||current_month, 'YYYY.MM') >= to_date( begin_year||'.'||begin_month, 'YYYY.MM') AND
to_date( current_year||'.'||current_month, 'YYYY.MM') < to_date( next_year||'.'||next_month, 'YYYY.MM') AND
NOT first_flag
THEN
RAISE NOTICE '***CONTINUE';
CONTINUE ;
ELSE
--NEW borders only for second and after time
RAISE NOTICE '***NEW BORDERS';
begin_year := current_year ;
begin_month := current_month ;
IF current_month = '12' THEN
next_year := date_part('year' ,rec_shipment_date."SHIPMENT_DATE" + interval '1 year') ;
ELSE
next_year := current_year ;
END IF;
next_month := date_part('month' ,rec_shipment_date."SHIPMENT_DATE" + interval '1 month') ;
END IF;
IF to_number(current_month,'99') < 10 THEN
current_month := '0'||current_month ;
END IF ;
IF to_number(begin_month,'99') < 10 THEN
begin_month := '0'||begin_month ;
END IF ;
IF to_number(next_month,'99') < 10 THEN
next_month := '0'||next_month ;
END IF ;
RAISE NOTICE 'current_year=% , current_month=% ',current_year,current_month;
RAISE NOTICE 'begin_year=% , begin_month=% ',begin_year,begin_month;
RAISE NOTICE 'next_year=% , next_month=% ',next_year,next_month;
partition_name := 'data_'||begin_year||begin_month||'01_'||next_year||next_month||'01' ;
RAISE NOTICE 'PARTITION NUMBER % , TABLE NAME =%',i , partition_name;
EXECUTE format('CREATE TABLE ' || quote_ident(partition_name) || ' PARTITION OF data FOR VALUES FROM ( %L ) TO ( %L ) ' , begin_year||'-'||begin_month||'-01' , next_year||'-'||next_month||'-01' ) ;
index_name := partition_name||'_shipment_id_parameter_id_idx';
RAISE NOTICE 'INDEX NAME =%',index_name;
EXECUTE format('CREATE INDEX ' || quote_ident(index_name) || ' ON '|| quote_ident(partition_name) ||' USING btree ("SHIPMENT_ID", "PARAMETER_ID") TABLESPACE pg_default ' ) ;
index_name := partition_name||'_lasermark_idx';
RAISE NOTICE 'INDEX NAME =%',index_name;
EXECUTE format('CREATE INDEX ' || quote_ident(index_name) || ' ON '|| quote_ident(partition_name) ||' USING btree ("LASERMARK" COLLATE pg_catalog."default") TABLESPACE pg_default ' ) ;
index_name := partition_name||'_shipment_id_idx';
RAISE NOTICE 'INDEX NAME =%',index_name;
EXECUTE format('CREATE INDEX ' || quote_ident(index_name) || ' ON '|| quote_ident(partition_name) ||' USING btree ("SHIPMENT_ID") TABLESPACE pg_default ' ) ;
index_name := partition_name||'_parameter_id_idx';
RAISE NOTICE 'INDEX NAME =%',index_name;
EXECUTE format('CREATE INDEX ' || quote_ident(index_name) || ' ON '|| quote_ident(partition_name) ||' USING btree ("PARAMETER_ID") TABLESPACE pg_default ' ) ;
index_name := partition_name||'_shipment_date_idx';
RAISE NOTICE 'INDEX NAME =%',index_name;
EXECUTE format('CREATE INDEX ' || quote_ident(index_name) || ' ON '|| quote_ident(partition_name) ||' USING btree ("SHIPMENT_DATE") TABLESPACE pg_default ' ) ;
--Drop first time flag
first_flag := false ;
END LOOP;
end
$$;
Загружаем дамп созданный на шаге 3.
pg_restore -h хост -юзер -d база --data-only --format=c --table=data --verbose data.dmp > data_restore.log 2>&1Cоздаем отдельную секцию для старых данных
---------------------------------------------------
--create_partition_for_old_dates.sql
--create partitions for keeping old dates
--version 1.0
do language plpgsql $$
declare
rec_shipment_date RECORD ;
partition_name varchar;
index_name varchar;
begin
SELECT min("SHIPMENT_DATE") AS min_date INTO rec_shipment_date from data ;
RAISE NOTICE 'Old date is %',rec_shipment_date.min_date ;
partition_name := 'data_old_dates' ;
RAISE NOTICE 'PARTITION NAME IS %',partition_name;
EXECUTE format('CREATE TABLE ' || quote_ident(partition_name) || ' PARTITION OF data FOR VALUES FROM ( %L ) TO ( %L ) ' , '1900-01-01' ,
to_char( rec_shipment_date.min_date,'YYYY')||'-'||to_char(rec_shipment_date.min_date,'MM')||'-01' ) ;
index_name := partition_name||'_shipment_id_parameter_id_idx';
EXECUTE format('CREATE INDEX ' || quote_ident(index_name) || ' ON '|| quote_ident(partition_name) ||' USING btree ("SHIPMENT_ID", "PARAMETER_ID") TABLESPACE pg_default ' ) ;
index_name := partition_name||'_lasermark_idx';
EXECUTE format('CREATE INDEX ' || quote_ident(index_name) || ' ON '|| quote_ident(partition_name) ||' USING btree ("LASERMARK" COLLATE pg_catalog."default") TABLESPACE pg_default ' ) ;
index_name := partition_name||'_shipment_id_idx';
EXECUTE format('CREATE INDEX ' || quote_ident(index_name) || ' ON '|| quote_ident(partition_name) ||' USING btree ("SHIPMENT_ID") TABLESPACE pg_default ' ) ;
index_name := partition_name||'_parameter_id_idx';
EXECUTE format('CREATE INDEX ' || quote_ident(index_name) || ' ON '|| quote_ident(partition_name) ||' USING btree ("PARAMETER_ID") TABLESPACE pg_default ' ) ;
index_name := partition_name||'_shipment_date_idx';
EXECUTE format('CREATE INDEX ' || quote_ident(index_name) || ' ON '|| quote_ident(partition_name) ||' USING btree ("SHIPMENT_DATE") TABLESPACE pg_default ' ) ;
end
$$;Итоговые результаты:
Было
Cost: 502 997.55
Execution time: 505 seconds.
Стало
Cost: 68 533.70
Execution time: 69 seconds
Достойно, вполне достойно. А учитывая, что по пути удалось более-менее освоить механизм секционирования в PostgreSQL 10 — Отличный результат.
Лирическое отступление
А можно, сделать еще лучше - ДА, МОЖНО!
Для этого нужно использовать MATERIALIZED VIEW.
В очередной раз переписываем запрос:
И получаем еще один итог:
Было
Cost: 502 997.55
Execution time: 505 seconds
Стало
Cost: 42 481.16
Execution time: 43 seconds.
Хотя конечно, столь многообещающий результат он обманчив, представления-то надо рефрешить. Так что итоговое время получения данных не сильно-то и поможет. Но в качестве эксперимента вполне интересно.
На самом деле, как выяснилось, ещё раз спасибо asmm и Хабру !- запрос можно еще улучшить.
CREATE MATERIALIZED VIEW LASERMARK_VIEW
CREATE MATERIALIZED VIEW LASERMARK_VIEW
AS
SELECT w."LASERMARK" , MAX(s."SHIPMENT_DATE") AS "SHIPMENT_DATE"
FROM shipment s INNER JOIN data w ON s."SHIPMENT_ID" = w."SHIPMENT_ID"
GROUP BY w."LASERMARK" ;
CREATE INDEX lasermark_vw_shipment_date_ind on lasermark_view USING btree ("SHIPMENT_DATE") TABLESPACE pg_default;
analyze lasermark_view ;
В очередной раз переписываем запрос:
Запрос с использованием materialized view
SELECT
p."PARAMETER_ID" as parameter_id,
pc."PC_NAME" AS pc_name,
pc."CUSTOMER_PARTNUMBER" AS customer_partnumber,
w."LASERMARK" AS lasermark,
w."LOTID" AS lotid,
w."REPORTED_VALUE" AS reported_value,
w."LOWER_SPEC_LIMIT" AS lower_spec_limit,
w."UPPER_SPEC_LIMIT" AS upper_spec_limit,
p."TYPE_CALCUL" AS type_calcul,
s."SHIPMENT_NAME" AS shipment_name,
s."SHIPMENT_DATE" AS shipment_date,
extract(year from s."SHIPMENT_DATE") AS year,
extract(month from s."SHIPMENT_DATE") as month,
s."REPORT_NAME" AS report_name,
p."STC_NAME" AS STC_name,
p."CUSTOMERPARAM_NAME" AS customerparam_name
FROM data w INNER JOIN shipment s ON s."SHIPMENT_ID" = w."SHIPMENT_ID"
INNER JOIN parameters p ON p."PARAMETER_ID" = w."PARAMETER_ID"
INNER JOIN shipment_pc sp ON s."SHIPMENT_ID" = sp."SHIPMENT_ID"
INNER JOIN pc pc ON pc."PC_ID" = sp."PC_ID"
INNER JOIN LASERMARK_VIEW md ON md."SHIPMENT_DATE" = s."SHIPMENT_DATE" AND md."LASERMARK" = w."LASERMARK"
WHERE
s."SHIPMENT_DATE" >= '2018-07-01' AND s."SHIPMENT_DATE" <= '2018-09-30';
И получаем еще один итог:
Было
Cost: 502 997.55
Execution time: 505 seconds
Стало
Cost: 42 481.16
Execution time: 43 seconds.
Хотя конечно, столь многообещающий результат он обманчив, представления-то надо рефрешить. Так что итоговое время получения данных не сильно-то и поможет. Но в качестве эксперимента вполне интересно.
На самом деле, как выяснилось, ещё раз спасибо asmm и Хабру !- запрос можно еще улучшить.
Послесловие
Итак, заказчик удовлетворен. И нужно пользоваться ситуацией.
Новая задача: Что можно такого придумать, чтобы углубить и расширить?
И тут вспоминается — ребята, а ведь у нас нет мониторинга наших баз данных PostgreSQL.
Положа руку на сердце, некий мониторинг в виде Cloud Watch на AWS все-таки есть. Но какая польза от этого мониторинга для DBA? В общем-то практически никакой.
Если выпал шанс сделать полезное и интересное и для себя, не воспользоваться таким шансом нельзя…
ИБО

Вот так мы и подошли к самому интересному:
3 Декабря 2018 года.Но это уже совсем, другая история.
Принятие решения о начале работ по исследованию имеющихся возможностей мониторинга производительности запросов PostgreSQL.
Продолжение, следует...
gsl23
И как заказчик? Обрадовался исчезновению данных?