Очередной пользователь хочет записать на жесткий диск новый кусок данных, но ему не хватает свободного места для этого. Удалять тоже ничего не хочется, так как "все очень важное и нужное". И что нам с ним делать?
Такая проблема встает ни у него одного. На наших жестких дисках покоятся терабайты информации, и это количество не стремится уменьшаться. Но насколько она уникальна? В конце-концов, ведь все файлы это лишь наборы бит определенной длины и, скорее всего, новая не сильно отличается от той, что уже хранится.
Понятное дело, что искать уже хранящиеся куски информации на жестком диске — задача если не провальная, то как минимум не эффективная. С другой стороны, ведь если разница небольшая, то можно немного и подогнать...

TL;DR — вторая попытка рассказать о странном методе оптимизации данных с помощью JPEG-файлов, теперь в более понятной форме.
О битах и разнице
Если взять два полностью случайных куска данных, то в них совпадает в среднем половина содержащихся битов. И правда, среди возможных раскладов для каждой пары ('00, 01, 10, 11') ровно половина имеет совпадающие значения, тут все просто.
Но конечно, если мы просто возьмем два файла и подгоним один под второй, то мы лишимся одного из них. Если же будем сохранять изменения, то просто переизобретем дельта-кодирование, которое и без нас прекрасно существует, хоть и не используется обычно в таких же целях. Можно пытаться встроить меньшую последовательность в большую, но даже так мы рискуем потерей критических сегментов данных при необдуманном использовании со всем подряд.
Между чем и чем тогда можно разницу устранять? Ну то есть, записываемый пользователем новый файл — просто последовательность бит, с которой самой по себе мы ничего сделать не можем. Тогда надо просто найти на жестком диске такие биты, чтобы их можно было изменять без необходимости хранить разницу, чтобы можно было пережить их потерю без серьезных последствий. Да и изменять есть смысл не просто сам файл на ФС, но какую-то менее чувствительную информацию внутри него. Но какую и как?
Методы подгонки
На помощь приходят файлы, сжатые с потерями. Все эти jpeg, mp3 и прочие хоть и являются сжатием с потерями, содержат кучу бит, доступных для безопасного изменения. Можно использовать продвинутые техники, незаметным образом модифицирующие их составляющие на различных участках кодирования. Подождите. Продвинутые техники… незаметная модификация… одни биты в другие… да это же почти что стеганография!
И правда, встраивание одной информации в другую как ни что напоминает ее методы. Импонирует также незаметность проведенных изменений для человеческих органов чувств. Вот в чем пути расходятся — так это в секретности: наша задача сводится к внесению пользователем на свой жесткий диск дополнительной информации, ему она только повредит. Забудет еще.
Поэтому, мы хоть и можем использовать их, нужно провести некоторые модификации. И дальше я расскажу и покажу их на примере одного из существующих методов и распространенного формата файлов.
О шакалах
Если уж сжимать, то самое сжимаемое в мире. Речь идет, конечно же, о JPEG-файлах. Мало того, что существует тонна инструментария и существующих методов для встраивания в него данных, так он является самым популярным графическим форматом на этой планете.

Тем не менее, чтобы не заниматься собаководством, нужно ограничить свое поле деятельности в файлах этого формата. Никто не любит одноцветные квадратики, возникающие из-за излишнего сжатия, поэтому нужно ограничиться работой с уже сжатым файлом, избегая перекодирования. Конкретнее — с целочисленными коэффициентами, которые и остаются после операций, отвечающих за потери данных — ДКП и квантования, что прекрасно отображено на схеме кодирования (спасибо вики национальной библиотеки им. Баумана):

Существует множество возможных методов оптимизации jpeg-файлов. Есть оптимизация без потерь (jpegtran), есть оптимизация "без потерь", которые на самом деле еще какие вносят, но нас они не волнуют. Ведь если пользователь готов встраивать одну информацию в другую ради увеличения свободного места на диске, то он свои изображения либо давно оптимизировал, либо совсем этого делать не хочет из-за боязни потери качества.
F5
Под такое условия подходит целое семейство алгоритмов, с которым можно ознакомиться в этой хорошей презентации. Самым продвинутым из них является алгоритм F5 за авторством Андреаса Вестфелда, работающий с коэффициентами компоненты яркости, так как человеческий глаз наименее чувствителен именно к ее изменениям. Более того, он использует методику встраивания, основанную на кодировании матрицы, благодаря чему позволяет можно совершать тем меньше их изменений при встраивании одного и того же количества информации, чем больше размер используемого контейнера.
Сами изменения при этом сводятся к уменьшению абсолютного значения коэффициентов на единицу в определенных условиях (то есть, не всегда), что и позволяет использовать F5 для оптимизации хранения данных на жестком диске. Дело в том, что коэффициент после такого изменения, скорее всего, будет занимать меньшее число бит после проведения кодирования Хаффмана из-за статистического распределения значений в JPEG, а новые нули дадут выигрыш при кодировании их с помощью RLE.
Необходимые модификации сводятся к устранению части, отвечающей за секретность (парольной перестановки), которая позволяет экономить ресурсы и время выполнения, и добавления механизма работы с множеством файлов вместо одного за раз. Более подробно процесс изменения читателю вряд ли будет интересен, поэтому переходим к описанию реализации.
Высокие технологии
Для демонстрации работы такого подхода я реализовал метод на чистом Си и провел ряд оптимизаций как по скорости выполнения, так и по памяти (вы не представляете, сколько эти картиночки весят без сжатия даже до DCT). Кросс-платформенность достигнута использованием комбинации библиотек libjpeg, pcre и tinydir, за что им спасибо. Все это собирается 'make''ом, поэтому пользователи Windows для оценки хотят установить себе какой-нибудь Cygwin, либо разбираться с Visual Studio и библиотеками самостоятельно.
Реализация доступна в форме консольной утилиты и библиотеки. Подробнее про использование последней желающие могут ознакомиться в ридми в репозитории на гитхабе, ссылку на который я приложу в конце поста.
Как использовать?
С осторожностью. Используемые для упаковки изображения выбираются поиском по регулярному выражению в заданной корневой директории. По завершению файлы можно перемещать, переименовывать и копировать по желанию в ее пределах, менять файловую и операционные системы и пр. Однако, стоит быть крайне аккуратным и никак не изменять непосредственное содержимое. Потеря значения даже одного бита может привести к невозможности восстановления информации.
По завершению работы утилита оставляет специальный файл архива, содержащий всю необходимую для распаковки информацию, включая данные об использованных изображениях. Сам по себе он весит порядка пары килобайт и хоть сколько существенного влияния на занятое дисковое пространство не оказывает.
Можно анализировать возможную вместимость помощью флага '-a': './f5ar -a [папка поиска] [Perl-совместимое регулярное выражение]'. Упаковка производится командой './f5ar -p [папка поиска] [Perl-совместимое регулярное выражение] [упаковываемый файл] [имя архива]', а распаковка с помощью './f5ar -u [файл архива] [имя восстановленного файла]'.
Демонстрация работы
Чтобы показать эффективность работы метода, я загрузил коллекцию из 225 абсолютно бесплатных фотографий собак с сервиса Unsplash и отрыл в документах большую pdf-ку на 45 метров второго тома Искусства Программирования Кнута.
Последовательность довольно прост:
$ du -sh knuth.pdf dogs/
44M knuth.pdf
633M dogs/
$ ./f5ar -p dogs/ .*jpg knuth.pdf dogs.f5ar
Reading compressing file... ok
Initializing the archive... ok
Analysing library capacity... done in 17.0s
Detected somewhat guaranteed capacity of 48439359 bytes
Detected possible capacity of upto 102618787 bytes
Compressing... done in 39.4s
Saving the archive... ok
$ ./f5ar -u dogs/dogs.f5ar knuth_unpacked.pdf
Initializing the archive... ok
Reading the archive file... ok
Filling the archive with files... done in 1.4s
Decompressing... done in 21.0s
Writing extracted data... ok
$ sha1sum knuth.pdf knuth_unpacked.pdf
5bd1f496d2e45e382f33959eae5ab15da12cd666 knuth.pdf
5bd1f496d2e45e382f33959eae5ab15da12cd666 knuth_unpacked.pdf
$ du -sh dogs/
551M dogs/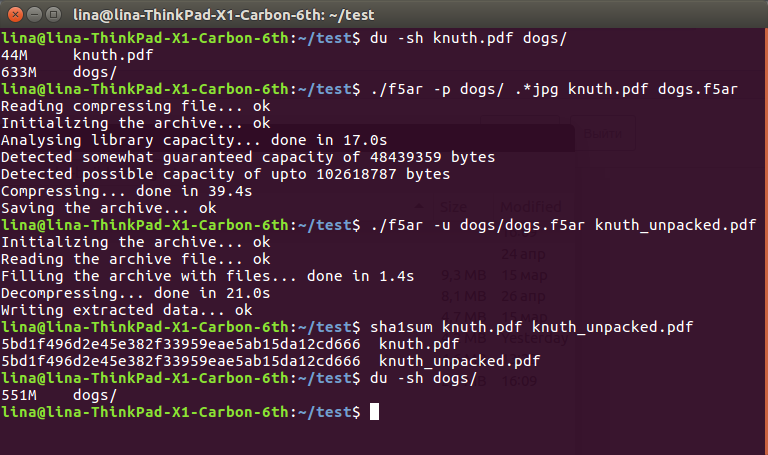
Распакованный файл все еще можно и нужно читать:

Как видно, с исходных 633 + 36 == 669 мегабайт данных на жестком диске мы пришли к более приятным 551. Такая радикальная разница объясняется тем самым уменьшением значений коэффициентов, влияющим на их последующее сжатие без потерь: уменьшение одного всего лишь на единичку может спокойно "срезать" парочку байт с итогового файла. Тем не менее, это все равно потери данных, пусть и крайне небольшие, с которыми придется мириться.
К счастью, для глаза они не заметны абсолютно. Под спойлером (так как habrastorage не умеет в большие файлы) читатель может оценить разницу как на глаз, так и их интенсивность, полученную вычитанием значений измененной компоненты из оригинальной: оригинал, с информацией внутри, разница (чем тусклее цвет, тем меньше различие в блоке).
Вместо заключения
Смотря на все эти сложности, купить жесткий диск или залить все в облако может показаться куда более простым решением проблемы. Но хоть сейчас мы и живем в такое прекрасное время, нет никаких гарантий, что завтра все еще можно будет выйти в интернет и залить куда-нибудь все свои лишние данные. Или придти в магазин и купить себе очередной жесткий диск на тысячу терабайт. А вот использовать уже лежащие дома можно всегда.
-> GitHub
Комментарии (42)

berez
24.05.2019 15:25Все это собирается 'make''ом, поэтому пользователи Windows для оценки хотят установить себе какой-нибудь Cygwin, либо разбираться с Visual Studio и библиотеками самостоятельно.
А использовали бы CMake — и виндоюзеры бы заплакали от восторга.
Смотря на все эти сложности, купить жесткий диск или залить все в облако может показаться куда более простым решением проблемы.
Меня всю статью не покидала мысль об архиваторах. Жаль, картинки и видео сжимаются плохо, а они — основной сжиратель места на винтах.Labunsky Автор
24.05.2019 17:55Cmake генерирует файлы для того же make

panter_dsd
24.05.2019 17:57+2Неправильно. CMake может генерировать много чего. Допустим, проект для VisualStudio. У него есть всякие генераторы.
Labunsky Автор
24.05.2019 19:39-1Не знал, последний вижак видел в версии 8го года, тогда таких фич еще не было. В любом случае, уж из обычного мейка на три файла любой справится сделать проект в вижаке
berez
24.05.2019 19:54При чем здесь версия вижулятины? CMake — это отдельный самостоятельный продукт, он от версии студии не зависит. Есть и другие кроссплатформенные системы сборки, просто cmake наиболее широко распространен и проработан.
Так-то, конечно, накидать файлов в проект может любой, но есть один нюанс. Когда система сборки кроссплатформенная, подразумевается, что автор не прочь бы собрать свой проект на всяких платформах — а значит, будет не против патчей, исправляющих ошибки сборки под виндой. Ну а когда система сборки — *nix-only, то сразу понятно, что код под виндой даже не пытались собирать, а значит, придется разгребать ошибки. При этом не факт, что автор потом патчи примет.Labunsky Автор
24.05.2019 20:05-1Конечно отдельный, но с два-нуль-нуль-восьмой версией вижака он подобного не умел еще, временная шкала-то общая. Ну либо я не знал об этом уже тогда, просто пытаюсь прояснить причину
автор не прочь бы собрать свой проект на всяких платформах
Я сам использую MSYS и Cygwin на винде, в обеих средах все собирается и обычным мейком, куда уже кросс-платформеннее. Желания делать отдельно для вижака систему сборки не нашел, учитывая, что все равно натыкаюсь на стену непонимания в лице "пересжать лучши"
berez
24.05.2019 20:53Я сам использую MSYS и Cygwin на винде, в обеих средах все собирается и обычным мейком, куда уже кросс-платформеннее.
Это не кроссплатформенность, это эмулятор юниксов в винде. Так-то и «блокнот» виндовый можно под линуксом запустить через wine, но это не делает его кроссплатформенным. :)
Желания делать отдельно для вижака систему сборки не нашел,
Вы не понимаете смысла термина «кроссплатформенная система сборки», да? :)
Кроссплатформенная — значит, одна на все платформы. Не «отдельно для вижака», а одна на все.Labunsky Автор
24.05.2019 21:08MSYS'ом можно собрать чисто виндовый экзешник, который работает где угодно сам по себе. С вот cygwin'ом потребуется таскать dll"ку для запуска
Кроссплатформенная — значит, одна на все платформы
Именно. Вижак — не платформа, платформой является Windows. На ней можно собирать экзешники, используя makefile. То, что одна IDE на этой платформе требует совершенно отдельного подхода, дело десятое
berez
24.05.2019 23:59Вы слишком категоричны.
CMake позволяет использовать любой тулчейн из поддерживаемых. Вы же таскаете за собой всю экосистему — ну такая себе кроссплатформенность. :)Labunsky Автор
25.05.2019 00:19С каких пор make — экосистема? Простая консольная утилита для автоматизации базовых действий, не более
berez
25.05.2019 00:31А, так вы только голый make.exe на винде предлагали использовать парой комментов тому назад? А я вроде MSYS и Cygwin видел…
Показалось, наверное. :)Labunsky Автор
25.05.2019 01:13Ну нужен еще компилятор и стандартная библиотека, конечно же. К слову, тот же мсис их не содержит по умолчанию, надо самому ставить руками. Суть в том, что с их помощью компиляция является довольно тривиальным процессом, а вот вижаком даже зависимости (официально компилирующиеся им) без поллитра не скомпилить
Я предпочитаю всякие gcc и cmake, потому что пишу на си, поэтому в глубине души верю, что си-люди за пределами юникс-сред не обитают. Тот же вижак не поддерживает нормально даже C99, поэтому не знаю, кто вообще этим всем заниматься с ним
berez
24.05.2019 18:51+1Виндовая версия cmake умеет генерировать солюшены для Visual Studio и файлы для nmake.
Sly_tom_cat
24.05.2019 15:35части, отвечающей за секретность (парольной перестановки)
Мне кажется перестановка там не только для безопасности — она еще позволяет размазать вносимые искажения по изображению.
И еще — поясните поподробнее метод внедрения данных. Фраза «Сами изменения при этом сводятся к уменьшению абсолютного значения коэффициентов на единицу в определенных условиях (то есть, не всегда)» не дает понимания техники встраивания данных. Можно этот момент чуть подробнее?Labunsky Автор
24.05.2019 19:50Мне кажется перестановка там не только для безопасности — она еще позволяет размазать вносимые искажения по изображению
Так точно, сэр. Но это требуется только когда происходит работа над одним файлом, если же встраивание производится во все множество сразу, то значения и так будут распределены околоравномерно внутри каждого его элемента, кроме разве что последнего
Можно этот момент чуть подробнее
Подробнее — это описывать сам алгоритм F5. В статье я оставил ссылку на хорошую статью о нем
IgorKh
24.05.2019 16:16Вспомнился старый прикол о том, что любую информацию можно найти в числе PI, все что нам нужно знать — это ее смещение…
PS а вот и файловая система основанная на этом принципе
unC0Rr
24.05.2019 16:25Если уж снижать качество картинки в JPEG, то проще пережать с меньшим коэффициентом качества и использовать освободившееся за счёт уменьшения размера файла место.
Labunsky Автор
24.05.2019 19:41Разница между снижением качества пересжатием и таким методом коллосальна, их рядом даже ставить нельзя
unC0Rr
24.05.2019 21:32А вот это утверждение неплохо бы обосновать. Качество снижается в обоих случаях, в одном за счёт уменьшения количества информации в картинке и добавления хранимых данных в отдельный файл, в другом за счёт замены информации в картинке с оставлением примерно такого же количества оригинальной информации об изображении, как и в первом случае. Раз количество информации после применения каждого из методов одинаково, то и размеры файлов будут примерно одинаковыми.
Labunsky Автор
24.05.2019 21:37Все необходимое для обоснование уже есть в посте. Работа производится над квантованными DCT-коэффициентами, из которых в самом-самом (крайне редком) худшем случае модифицируется половина только у одной компоненты. Визуально такие изменения малозаметны
При перекодировании ДК преобразование и квантование с "более оптимальной" матрицей происходят заново, тем самым модифицируя в худшую сторону все (зачастую на дельту >1) коэффициенты в файле. Тем самым оно дает и больший выигрыш в размере, но и более заметную потерю качества

no404error
24.05.2019 22:22Повторяю во второй раз (поскольку первую прибили из-за неудобных комментов): ничего в статье нет. Нет ни обоснования превосходства для lossless-оптимизации, ни оправдания lossy, в контексте хранения данных.
Labunsky Автор
24.05.2019 22:35Потому что когда я попытался описать все со схемами, понял, что люди не умеют читать. Здесь есть вся необходимая информация со ссылками. Я ничего не продаю — если интересно, человек разберется. На конкретные вопросы отвечу сам, но тут их не вижу
unC0Rr
24.05.2019 23:13Можно снизить качество JPEG и уменьшить размер файла, работая непосредственно с матрицей, не обязательно распаковывать в растр и начинать всё с начала, я такой подход имел в виду. И если делать так, то преимуществ в запрятывании информации в этих коэффициентах не видно совсем.
Labunsky Автор
24.05.2019 23:29О какой матрице идет речь? До перевода в растр мы имеем дело лишь с последовательностью коэффициентах в блоках 8х8, и все способы уменьшения размера манипуляциями с ними приводят к большим потерям из-за все тех же вероятностей.
При встраивании инородной информации значение меняется лишь с определенным шансом. Как я написал в самом начале поста, две случайных битовых последовательности совпадают в среднем на 50%. Точно так же и здесь при встраивании изменяется лишь часть коэффициентов (заметно меньше этих 50%).
При их же оптимизации они выбираются и изменяются по детермерированному алгоритму, который (если специально не добавить в него ГСЧП) изменит бОльшую их часть в силу строгости критериев (не существует более мягкого для оптимизации JPEG-файла, чем выбор случайного с небольшой вероятностью)
Кроме того, после прогона им информация в изображении теряется впустую. При встраивании же она не просто исчезает, но начинает кодировать собой некоторую другую информацию
Одно дело убрать стереть пыль с машины, и совсем другое — написать на ней что-нибудь. Процессы схожи, но имеют разную цель
unC0Rr
24.05.2019 23:45Под матрицей я имел в виду матрицу коэффициентов дискретного косинусного преобразования.
Предлагаю рассмотреть такой вариант работы: вместо замены битов обнулим те же самые биты, JPEG точно так же изменится ненамного, всего 50% битов-«контейнеров» будут обнулены, но взамен данные будут лучше сжиматься за счёт более низкой энтропии, файл уменьшится, и освободившееся место можно будет использовать для своей информации. На мой взгляд, это места займёт столько же, но не нужно будет ничего упаковывать-распаковывать.Labunsky Автор
25.05.2019 00:22Так я это и делаю! Только вместо "простого" обнуления внутрь еще и информация кодируется, это как 2 в 1!
Ну кроме шуток, я думал над этим как отдельным методом, даже код частично написал (для оптимизации RLE, до Хаффмана не добрался, но там и выхлоп меньше), но в процессе тестирования выяснил, что шумы заметны глазу при практически любых не вероятностных стратегиях выбора коэффициентов. Те, что не заметны, не дают почти никакого выхлопа :(
ALEX_k_s
25.05.2019 21:30А что как не по русски то написано, читать как то не приятно. Очень плохо объясняется, даже узко специализированному читателю мне кажется на очень то и ясно. Самое главное очень размыта именно сама суть алгоритма — откуда же там берется место и как это вообще работает.
Labunsky Автор
25.05.2019 22:25Первый пост был с деталями, но по комментариям и сообщениям быстро понял, что люди все равно читают пятой точкой, а лишние буквы их только смущают. Поэтому отсутствие объяснений целенаправленное. Тем не менее, информации для специалистов более чем достаточно. Если что-то все-таки не понятно, то могу ответить на любые вопросы тут, в личке или где-нибудь еще
Chuvi
26.05.2019 08:56Все это собирается 'make''ом, поэтому пользователи Windows для оценки хотят установить себе какой-нибудь Cygwin, либо разбираться с Visual Studio и библиотеками самостоятельно.
Нет, пользователи Windows этого не хотят. А вот вы хотите оформить кросс-платформенный проект как полагается, через Cmake.Chuvi
26.05.2019 12:15Labunsky, за инклуды .c -файлов мне хочется вас крайне сильно ненавидеть.
Labunsky Автор
26.05.2019 12:26Никто не мешает, но инклудить .c файл в лишь один другой .c файл — нормальная практика. Полезно бывает не загромаждать код и одновременно не выделять отдельный api, нигде не используемый. Ритчи не дурак, бесполезных фич не добавлял
Labunsky Автор
26.05.2019 12:23Тут всем так нравится костыли вместо ног использовать? Самое смешное, что проект собирается им в частности просто потому, что кривой CLion не умеет иначе подсвечивать синтаксис нормально. Мейк же пришлось писать отдельно как раз для того, чтобы от этих костылей избавиться и собирать нормально нормально на всех системах
P.S. Я не имею ничего против cmake в больших проектах с кучей зависимостей и логикой при сборке, но навязываение его использования ради компиляции всего тройки файлов напоминает лишь о микроскопе и гвоздях
berez
26.05.2019 13:36При чем тут навязывание? CMake просто удобнее, даже для проектов из одного-двух файлов. CMakeLists.txt получается минимальным — три строчки и все готово. :)
Плюс CMake позволяет расширять проект гораздо проще и единообразнее, чем даже automake (не говоря уже о голом make).
Единственное неудобство — надо аж две разных команды выучить: «cmake -G имя_генератора .» и «cmake --build .».Labunsky Автор
26.05.2019 13:43Чего ж удобного таскать с собой дополительную программу, которая ничего и не делает, считай? Кроме шуток, это простой проект на си, его в вижак все равно даже с симейком не запихнуть нормально, а за его пределами все равно тот же мейк использовать придется после генерации с вероятностью в 99%
staticlab
Почему бы просто не пережать JPG и не конвертнуть PDF в DJVU?
Labunsky Автор
Потому что гладиолус. Почему бы не в txt, а картинки псевдографикой? Ну вот так вот, каждый извращается в меру своих сил
staticlab
Не передёргивайте. То, что я привёл — вполне адекватный вариант в случае недостатка места на диске, а в случае со сканированным PDF — в любом случае полезный.
Labunsky Автор
Конечно, но я точно так же черным по белому написал, что пользователь не хочет больше ничего пережимать. Постановка задачи такая, ну мало ли бывает в жизни, я ж не предлагаю всем использовать. Вот захочется поизвращаться, а метод-то уже есть!
staticlab
А конвертация jpg -> f5ar -> jpg — это не «пережатие», да ещё и неудобное, с точки зрения пользователя? Почему бы тогда просто не сделать user-friendly утилиту-оптимизатор jpg, чем творить непонятную магию с lossy-архивами?
Labunsky Автор
Нет никакой конвертации, фото остаются фото. f5ar — это дополнительный файл, хранящий всю необходимую для извлечения информации, сами файлы хранятся и открываются как и до этого. Довольно ясно же написал, что изменяется только их содержимое немного для эффективного кодирования дополнительной информации