Всем привет. Меня зовут Данила, я работаю в команде, которая развивает аналитическую инфраструктуру в Авито. Центральное место в этой инфраструктуре занимает А/B-тестирование.
А/B эксперименты — ключевой инструмент принятия решений в Авито. В нашем цикле продуктовой разработки А/B-тест является обязательным этапом. Мы проверяем каждую гипотезу и выкатываем только позитивные изменения.
Мы собираем сотни метрик и умеем детализировать их до бизнес-разрезов: вертикали, регионы, авторизованные пользователи и т. д. Мы делаем это автоматизированно с помощью единой платформы для экспериментов. В статье я достаточно подробно расскажу, как платформа устроена и мы с вами погрузимся в некоторые интересные технические детали.

Основные функции платформы A/B мы формулируем следующим образом.
- Помогает быстро запускать эксперименты
- Контролирует нежелательные пересечения экспериментов
- Считает метрики, стат. тесты, визуализирует результаты
Другими словами, платформа помогает наиболее быстро принимать безошибочные решения.
Если оставить за скобками процесс разработки фич, которые отправляются в тестирование, то полный цикл эксперимента выглядит так:

- Заказчик (аналитик или продакт-менеджер) настраивает через админку параметры эксперимента.
- Сплит-сервис, согласно этим параметрам, раздает клиентскому устройству нужную группу A/B.
- Действия пользователей собираются в сырые логи, которые проходят через агрегацию и превращаются в метрики.
- Метрики «прогоняются» через статистические тесты.
- Результаты визуализируются на внутреннем портале на следующий день после запуска.
Весь транспорт данных в цикле занимает один день. Эксперименты длятся, как правило, неделю, но заказчик получает инкремент результатов каждый день.
Теперь давайте погрузимся в детали.
Управление экспериментом
В админке для конфигурации экспериментов используется формат YAML.

Это удобное решение для небольшой команды: доработка возможностей конфига обходится без фронта. Использование текстовых конфигов упрощает работу и пользователю: нужно делать меньше кликов мышкой. Похожее решение используется A/B-фреймворке Airbnb).
Для деления трафика на группы используем распространенную технику хеширования с солью.
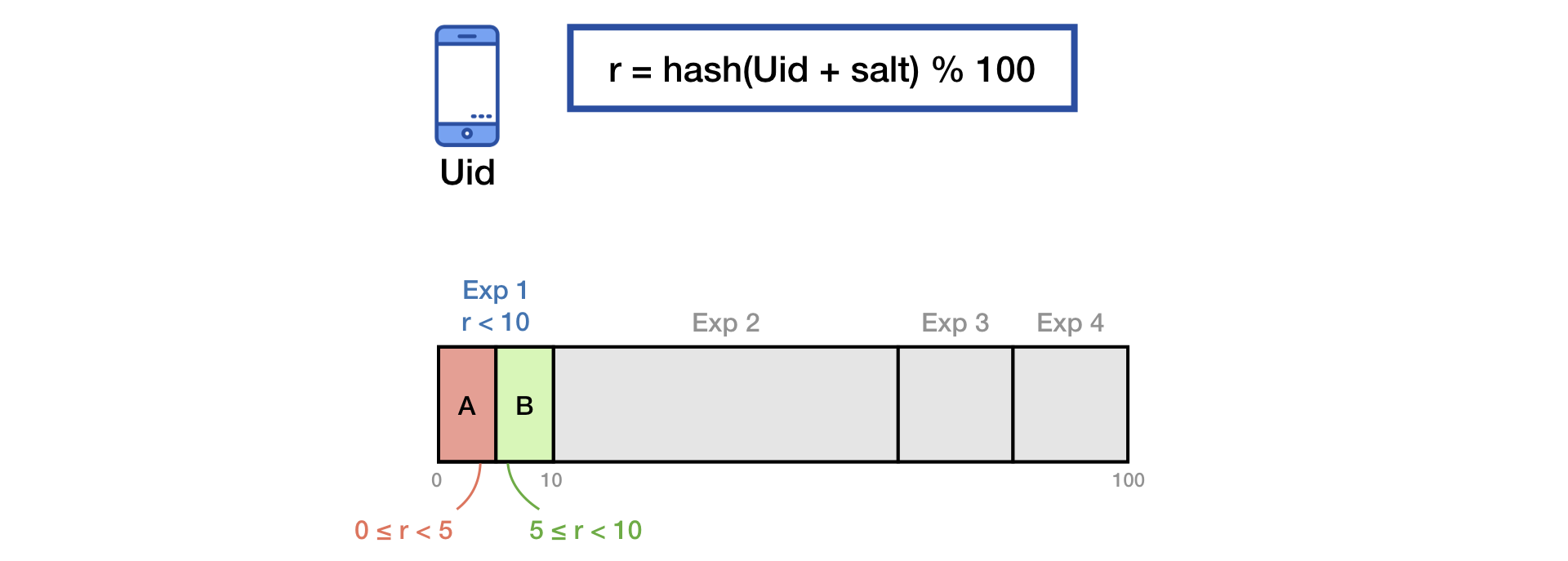
Для устранения эффекта «памяти» пользователей, при запуске нового эксперимента, мы делаем дополнительное перемешивание второй солью:
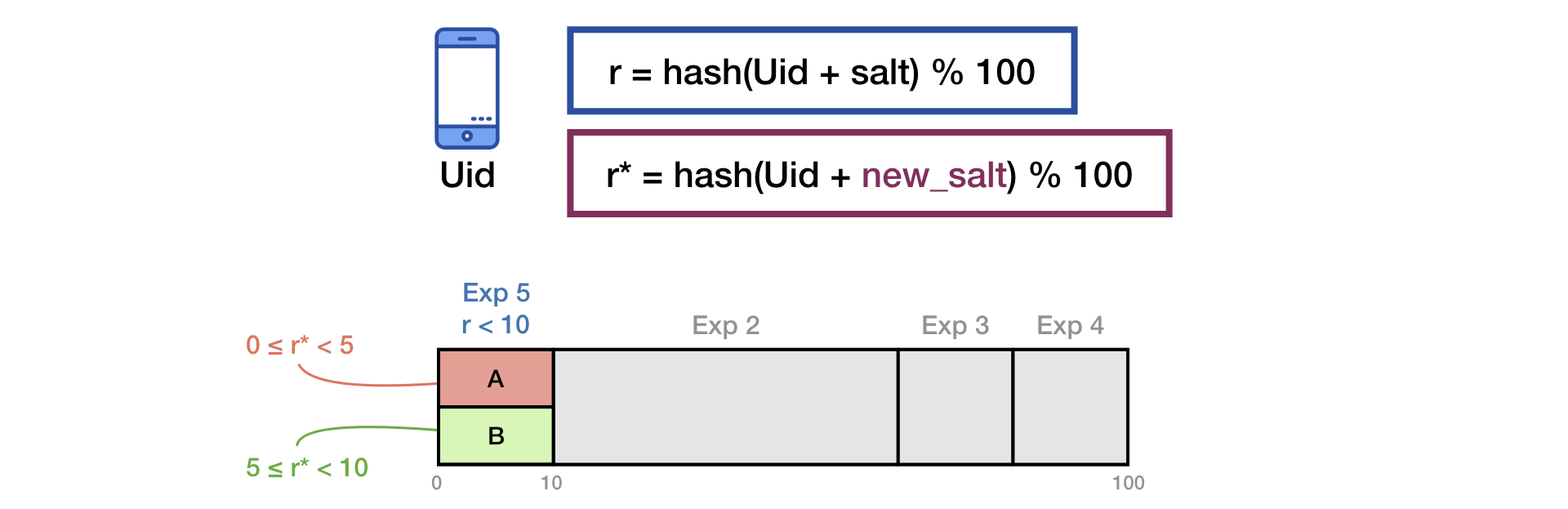
Этот же принцип описан в презентации Яндекса.
Чтобы не допускать потенциально опасных пересечений экспериментов, мы используем логику, схожую со «слоями» в Google.
Сбор метрик
Сырые логи мы раскладываем в Vertica и агрегируем в таблицы-препараты со структурой:

Observations (наблюдения) — это, как правило, простые каунтеры событий. Наблюдения используются как компоненты в формуле расчета метрик.
Формула расчета любой метрики — это дробь, в числителе и знаменателе которой стоит сумма наблюдений:
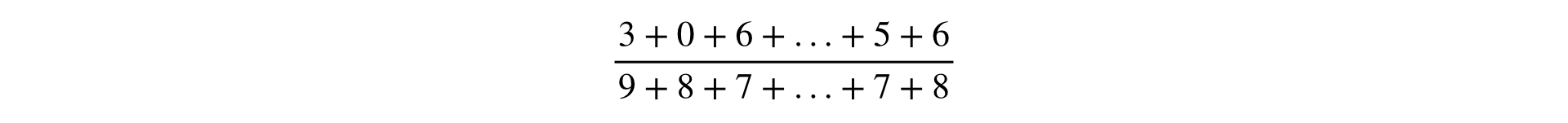
В одном из докладов Яндекса метрики подразделялись на два типа: по юзерам и Ratio. В этом есть бизнес-смысл, но в инфраструктуре удобнее все метрики считать единообразно в виде Ratio. Это обобщение валидно, потому что «поюзерная» метрика очевидно представима в виде дроби:
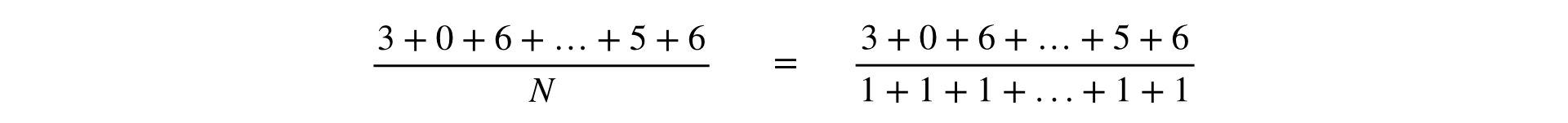
Наблюдения в числителе и знаменателе метрики мы суммируем двумя способами.
Простым:
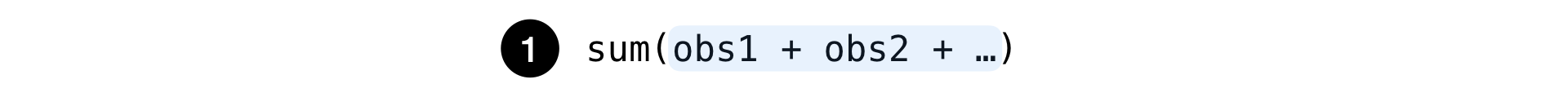
Это обычная сумма любого набора наблюдений: количество поисков, кликов по объявлениям и т. д.
И посложнее:

Уникальное количество ключей, в группировке по которым сумма наблюдений больше заданного порога.
Такие формулы легко задаются с помощью YAML-конфига:

Параметры groupby и threshold опциональны. Как раз они и определяют второй способ суммирования.
Описанные стандарты позволяют сконфигурировать почти любую онлайн-метрику, которую только можно придумать. При этом сохраняется простая логика, не накладывающая избыточную нагрузку на инфраструктуру.
Статистический критерий
Значимость отклонений по метрикам мы измеряем классическими методами: T-test, Mann-Whitney U-test. Главное необходимое условие для применения этих критериев — наблюдения в выборке не должны зависеть друг от друга. Почти во всех наших экспериментах мы считаем, что пользователи (Uid) удовлетворяют этому условию.

Теперь возникает вопрос: как провести T-test и MW-test для Ratio-метрик? Для T-test нужно уметь считать дисперсию выборки, а для MW выборка должна быть «поюзерной».
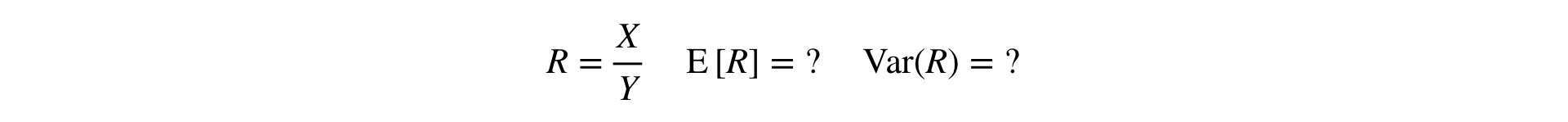
Ответ: нужно разложить Ratio в ряд Тейлора до первого порядка в точке :
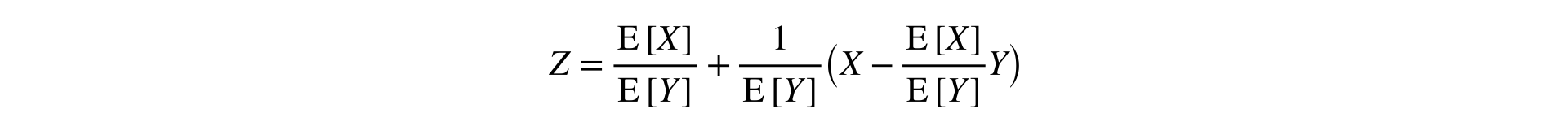
Данная формула преобразует две выборки (числитель и знаменатель) в одну, сохраняя среднее и дисперсию (асимптотически), что позволяет применять классические стат. тесты.
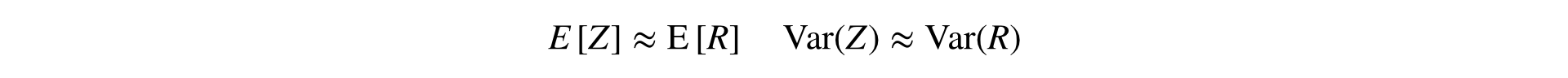
Похожую идею коллеги из Яндекса называют методом линеаризации Ratio (выступления раз и два).
Производительность при масштабировании
Использование быстрых для CPU стат. критериев дает возможность проводить миллионы итераций (сравнений treatment vs. control) за считанные минуты на вполне обычном сервере с 56 ядрами. Но в случае больших объемов данных производительность упирается, в первую очередь, в хранение и время считывания с диска.
Расчет метрик по Uid ежедневно порождает выборки общим размером в сотни миллиардов значений (ввиду большого количества одновременных экспериментов, сотен метрик и кумулятивного накопления). Каждый день выгребать такие объемы с диска слишком проблематично (несмотря на большой кластер колоночной базы Vertica). Поэтому мы вынужденно сокращаем кардинальность данных. Но делаем это почти без потери информации о дисперсии с помощью техники, которую называем «Бакеты».
Идея проста: хешируем Uid'ы и по остатку от деления «разбрасываем» их на некоторое количество бакетов (обозначим их число за B):
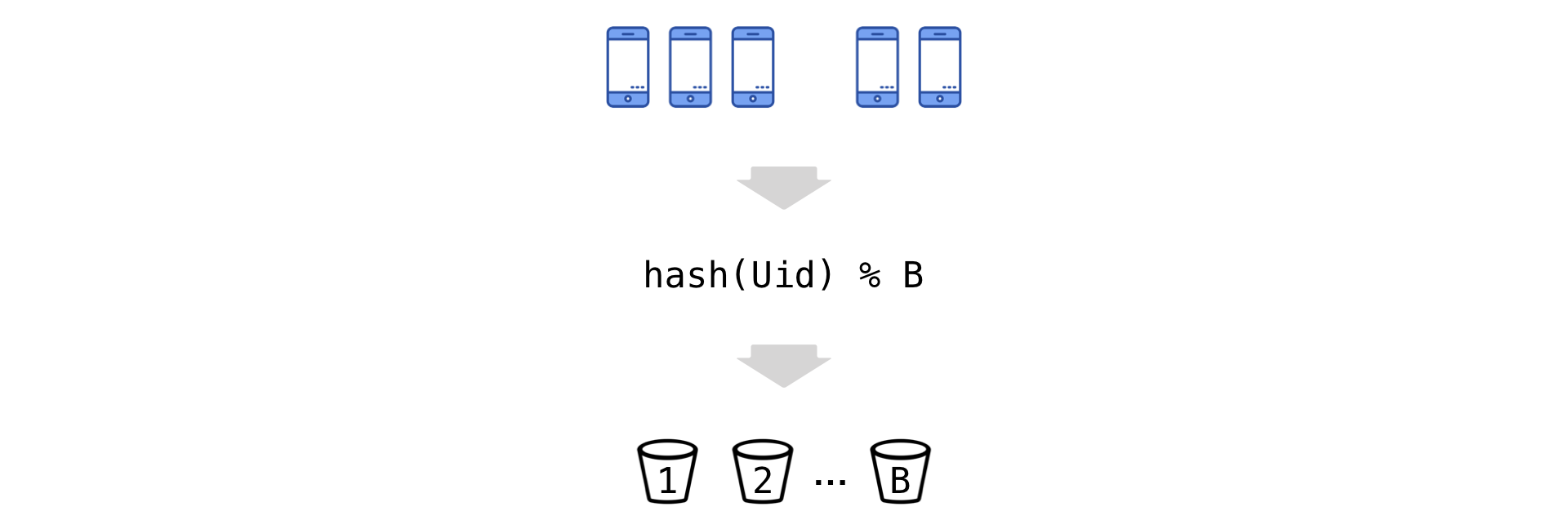
Теперь переходим к новой экспериментальной единице — бакет. Наблюдения в бакете суммируем (числитель и знаменатель независимо):

При таком преобразовании условие о независимости наблюдений выполняется, значение метрики не изменяется, и легко проверить, что и дисперсия метрики (среднего по выборке наблюдений) сохраняется:

Чем больше бакетов, тем меньше информации теряется, и тем меньше ошибка в равенстве. В Авито мы берем B = 200.
Плотность распределения метрики после бакетного преобразования всегда становится схожа с нормальным.
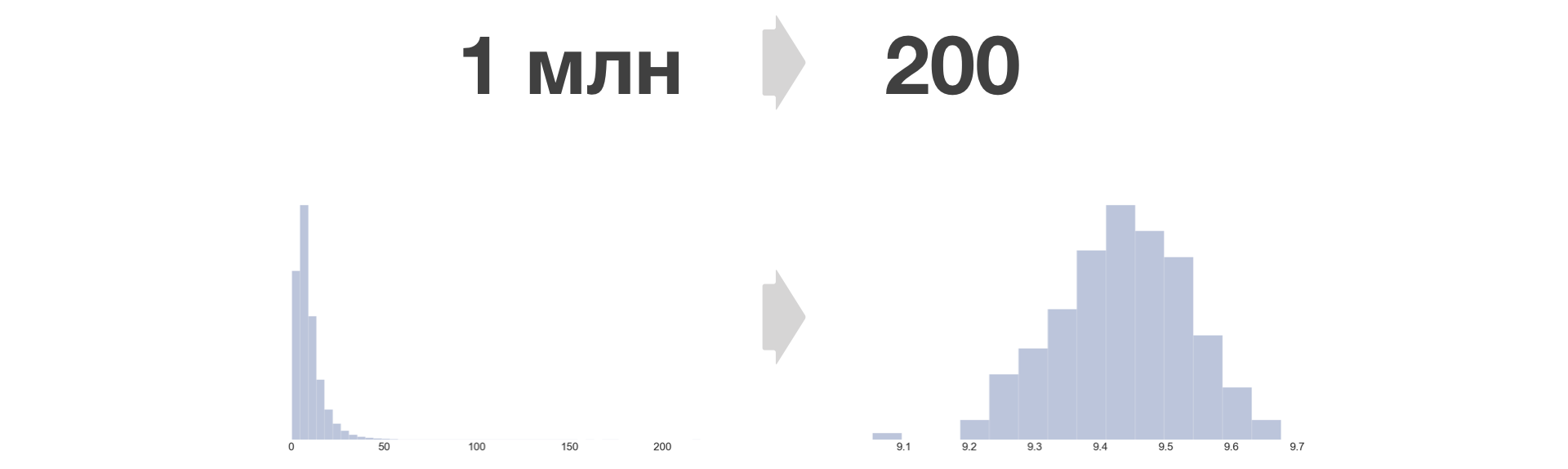
Сколь угодно большие выборки можно сокращать до фиксированного размера. Рост в количестве хранимых данных в таком случае лишь линейно зависит от количества экспериментов и метрик.
Визуализация результатов
В качестве инструмента визуализации мы используем Tableau и веб-вью на Tableau Server. У каждого сотрудника Авито есть туда доступ. Следует отметить, что Tableau с задачей справляется хорошо. Реализовать аналогичное решение с помощью полноценной бэк/фронт разработки было бы куда более ресурсоемкой задачей.
Результаты каждого эксперимента — это простыня из нескольких тысяч чисел. Визуализация обязана быть такой, чтобы минимизировать неправильные выводы в случае реализации ошибок I и II рода, и при этом не «проморгать» изменения в важных метриках и срезах.
Во-первых, мы мониторим метрики «здоровья» экспериментов. Т. е. отвечаем на вопросы: «Поровну ли участников "налилось" в каждую из групп?», «Поровну ли авторизованных или новых пользователей?».
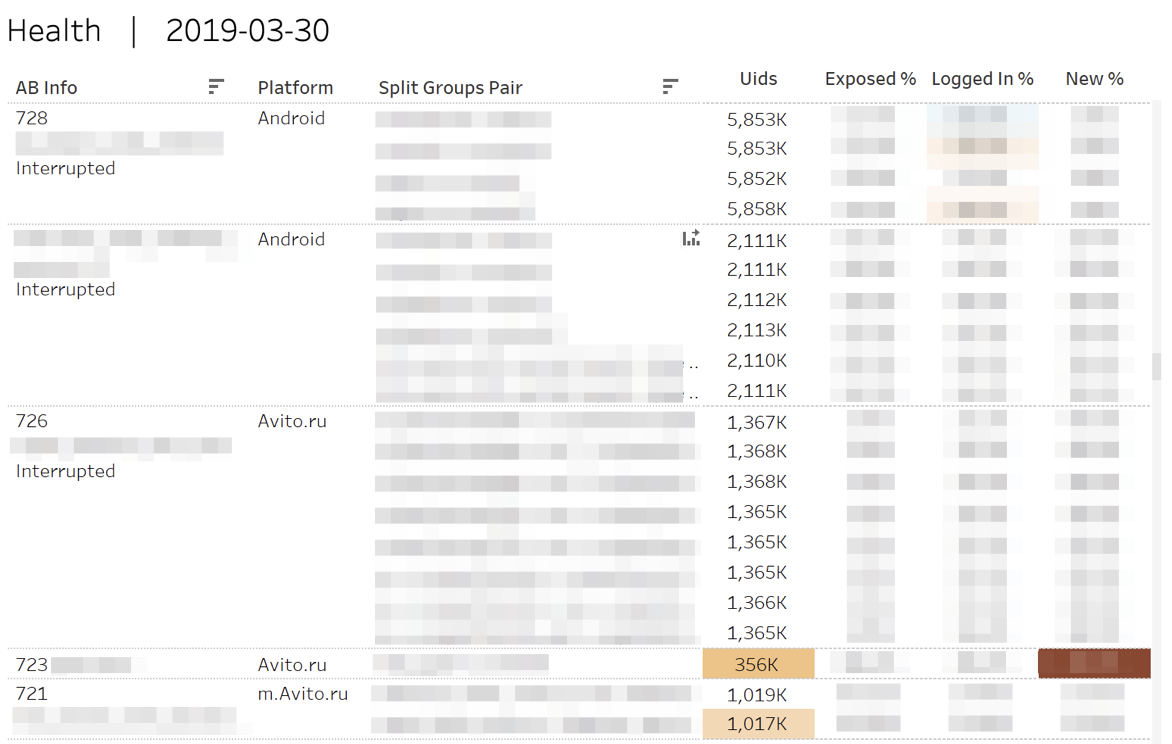
В случае статистически значимых отклонений соответствующие клеточки подсвечиваются. При наведении на любое число отображается кумулятивная динамика по дням.
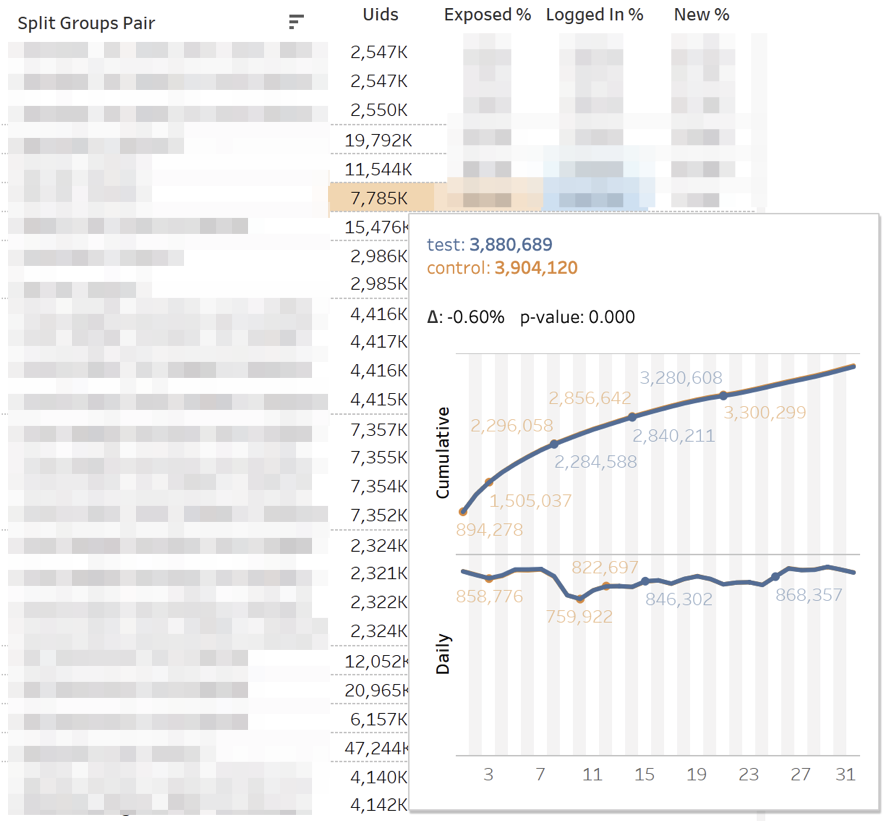
Главный дашборд с метриками выглядит так:
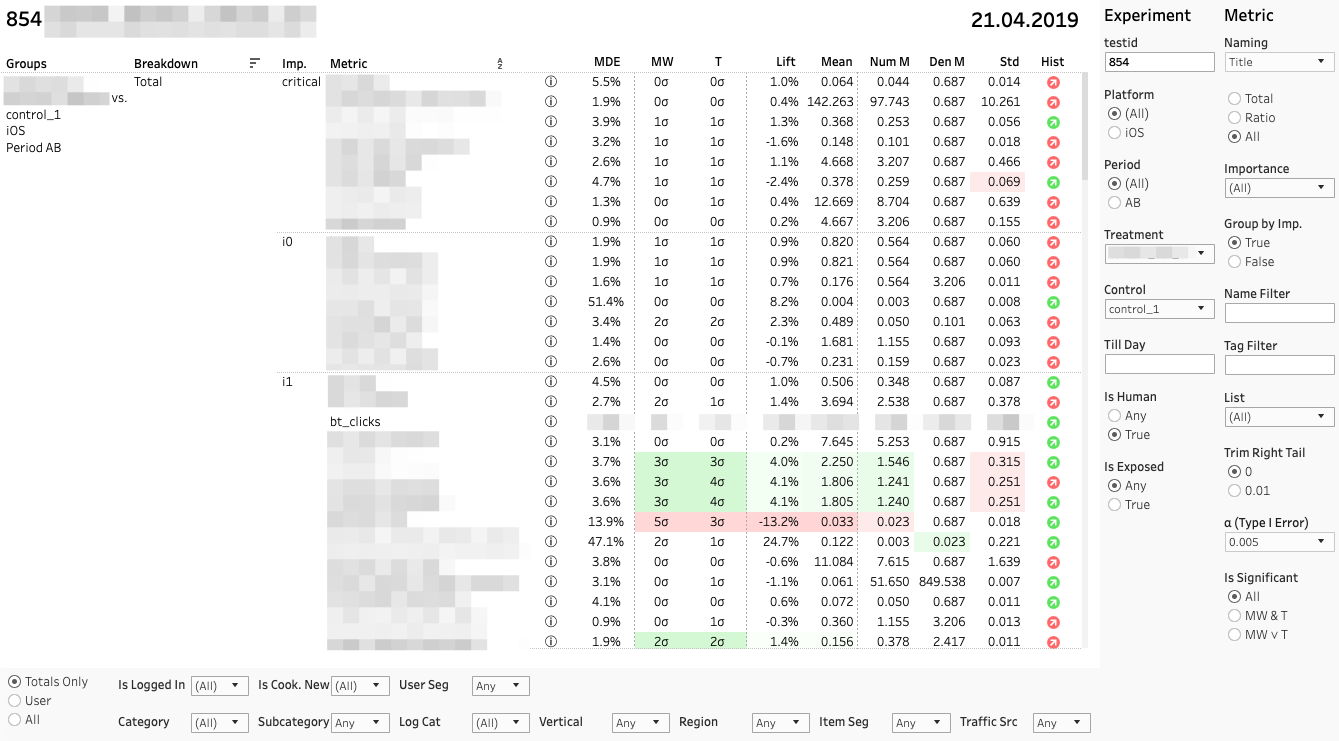
Каждая строка — сравнение групп по конкретной метрике в конкретном разрезе. Справа — панель с фильтрами по экспериментам и метрикам. Снизу — панель фильтров по разрезам.
Каждое сравнение по метрике состоит из нескольких показателей. Разберем их значения слева направо:
1. MDE. Minimum Detectable Effect

? и ? — заранее выбранные вероятности ошибки I и II рода. MDE очень важен, если изменение статистически не значимо. При принятии решения заказчик должен помнить, что отсутствие стат. значимости не равносильно отсутствию эффекта. Достаточно уверенно можно утверждать лишь то, что возможный эффект не больше, чем MDE.
2. MW | T. Результаты Mann-Whitney U- и T-test
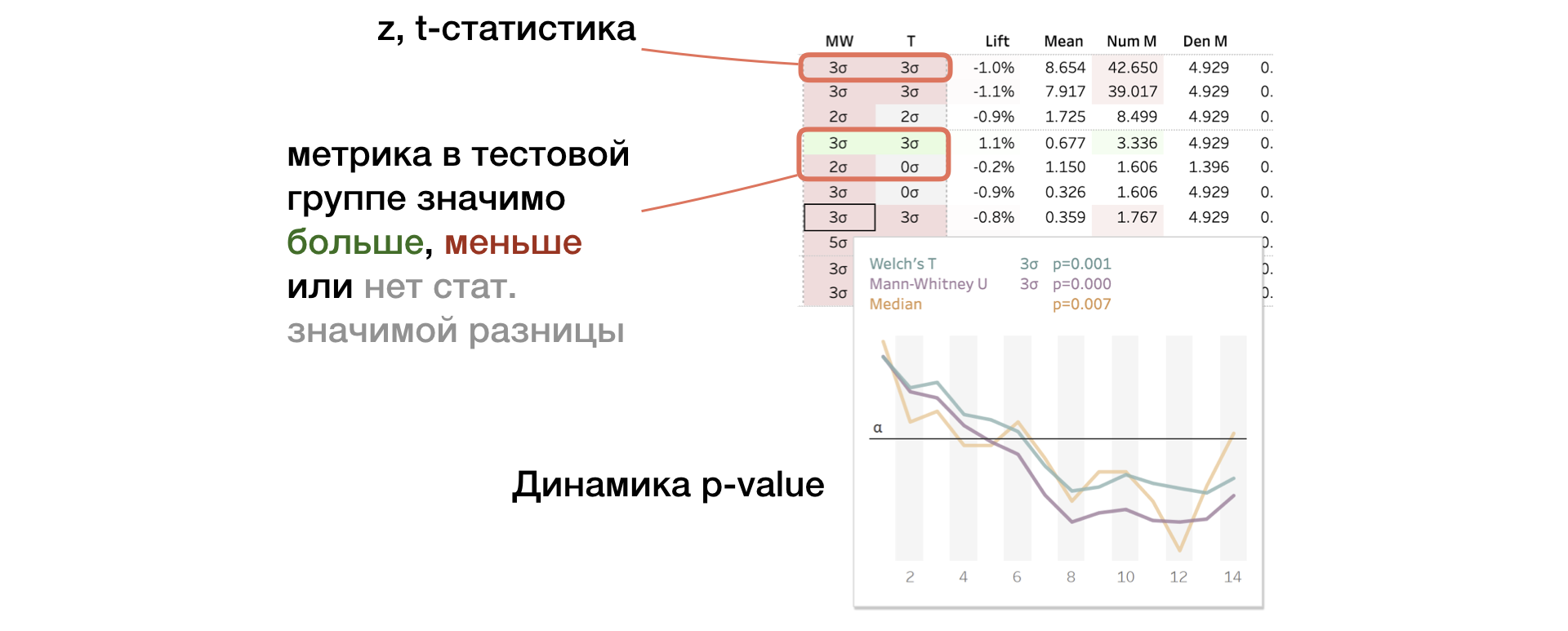
На панель выводим значение z- и t-статистики (для MW и T соответственно). В тултип — динамику p-value. Если изменение значимое, то клетка подсвечивается красным или зеленым цветом в зависимости от знака разницы между группами. В таком случае мы говорим, что метрика «прокрасилась».
3. Lift. Разница между группами в процентах
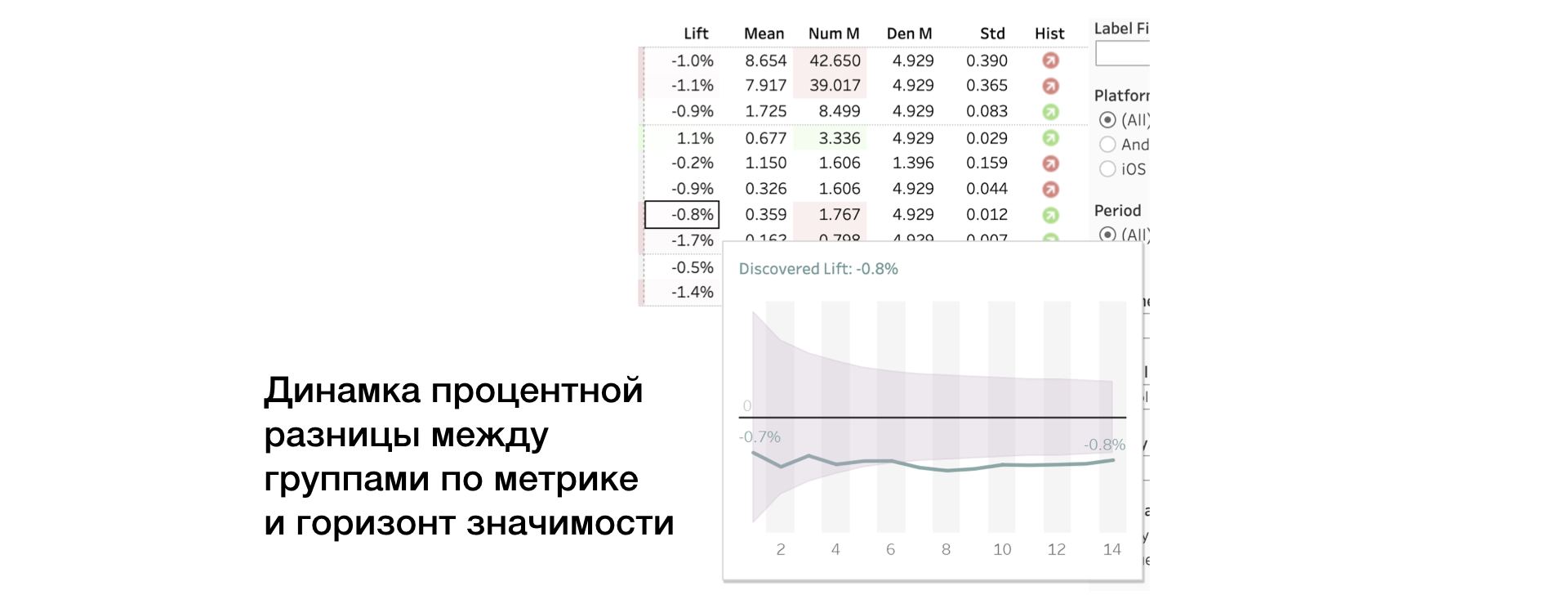
4. Mean | Num | Den. Значение метрики, а также числитель и знаменатель отдельно
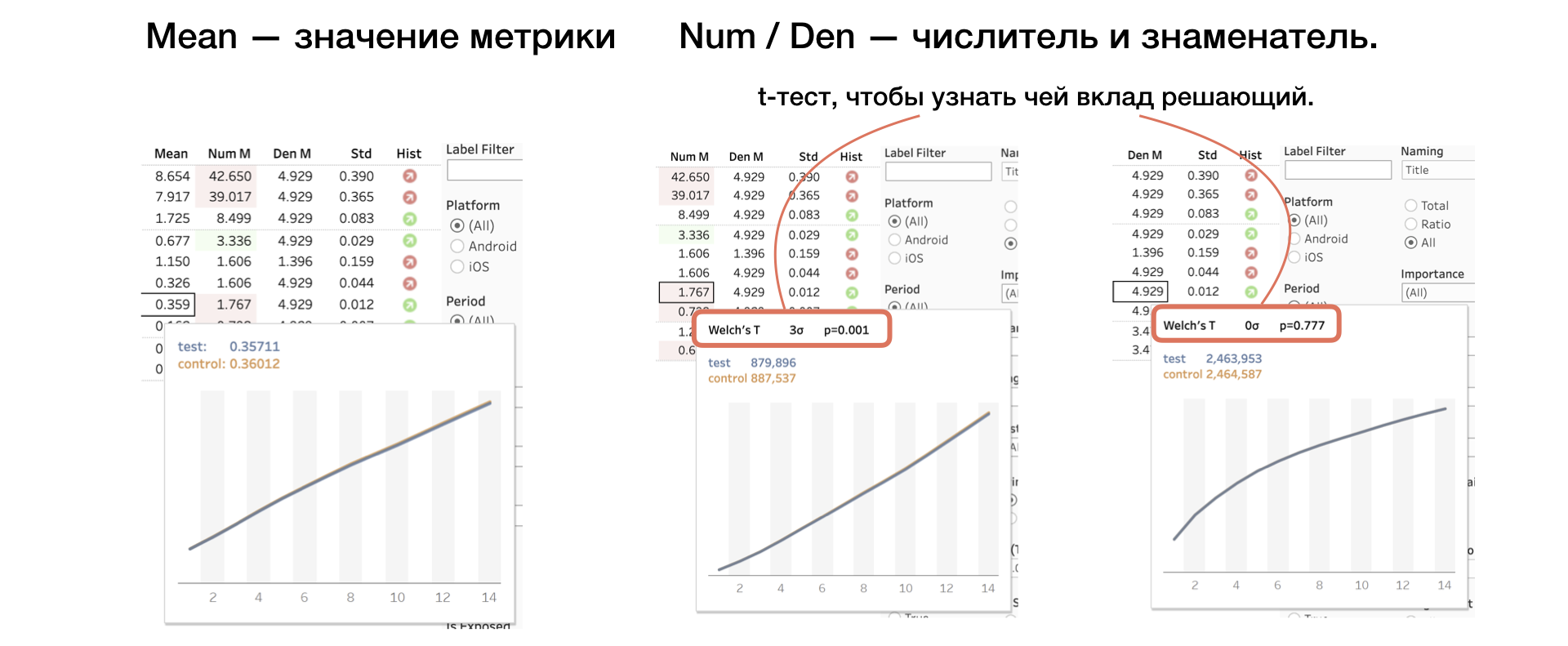
К числителю и знаменателю применяем еще один T-test, который помогает понять, чей вклад решающий.
5. Std. Выборочное стандартное отклонение
6. Hist. Тест Шапиро-Уилка на нормальность «бакетного» распределения.
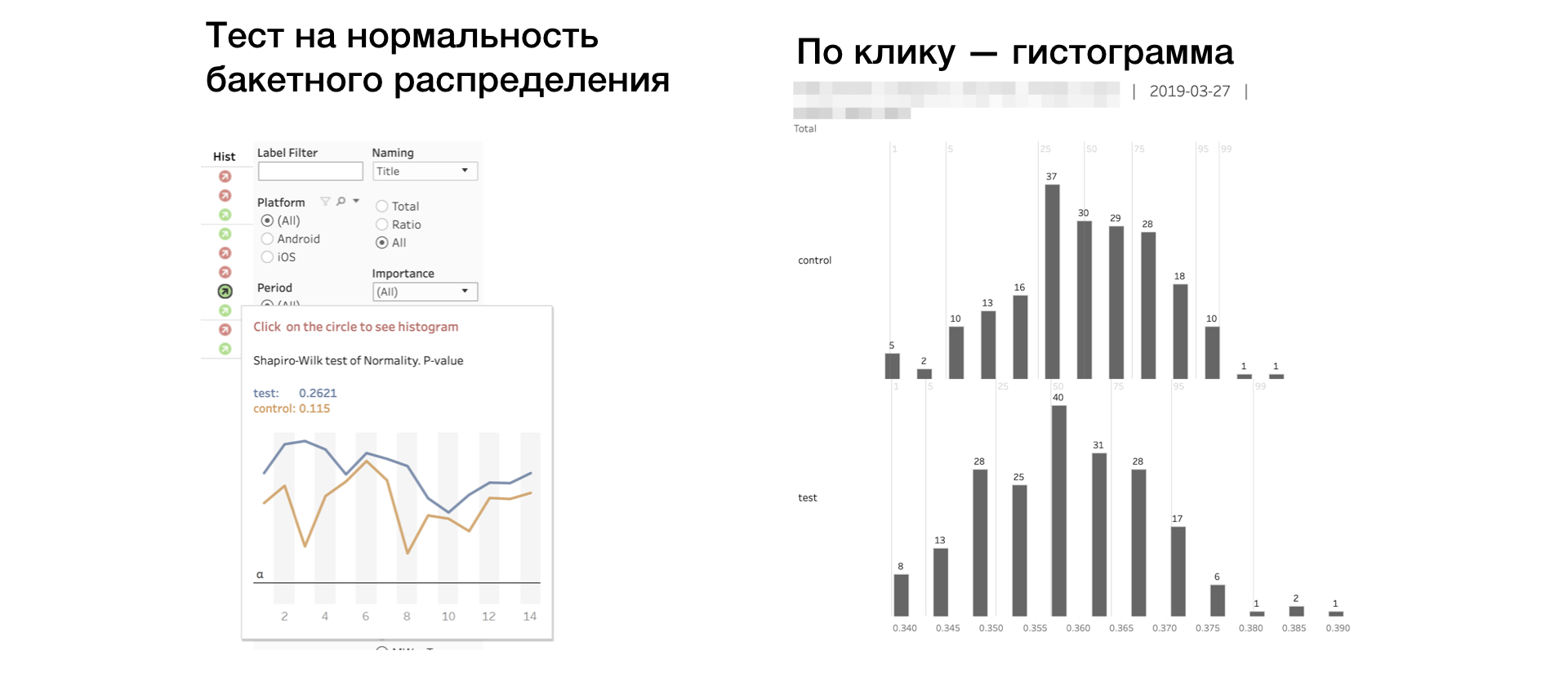
Если индикатор красный, то, возможно, в выборке есть выбросы или аномально длинный хвост. В таком случае принимать результат по этой метрике нужно осторожно, либо не принимать вовсе. Клик на индикатор открывает гистограммы метрики по группам. По гистограмме однозначно видны аномалии — так проще делать выводы.
Заключение
Появление платформы A/B в Авито — переломная точка, когда наш продукт стал развиваться быстрее. Каждый день мы принимаем «зеленые» эксперименты, которые заряжают команду; и «красные», которые дают полезную пищу для размышлений.
Нам удалось построить эффективную систему A/B-тестинга и метрик. Часто сложные проблемы мы решали простыми методами. Благодаря этой простоте, инфраструктура имеет хороший запас прочности.
Уверен, те, кто собирается построить платформу A/B в своей компании, нашли в статье несколько интересных инсайтов. Я рад поделиться с вами нашим опытом.
Пишите вопросы и комментарии — постараемся на них ответить.
Комментарии (20)

dienow
31.05.2019 14:16+1Огромное спасибо за статью!
Несколько вопросов, если можно:
1) В рамках эксперимента вы оцениваете сразу несколько метрик. Используете ли какие-то поправки для групповой проверки гипотез (бонферони и тп)?
2) В какой ситуации вы принимаете решение об остановке эксперимента? Только когда достигнут размер выборки необходимый для достижения нужной стат мощности?
3) Как вы формулируете нулевую / альтернативную гипотезы если нужно проверить что некоторая метрика не упала?lnkov Автор
31.05.2019 14:49Спасибо за правильные вопросы.
1) В рамках эксперимента вы оцениваете сразу несколько метрик. Используете ли какие-то поправки для групповой проверки гипотез (бонферони и тп)?
В репорте можно менять порог для вероятности ошибки I рода (по дефолту у нас он довольно низок: 0.005). Это «ручной» аналог различных поправок. Вообще говоря, поправки на множественность гипотез в нашем случае плохо применимы: с учетом разрезов в каждом тесте мы проверяем десятки тысяч гипотез, многие из них коррелируют друг с другом.
2) В какой ситуации вы принимаете решение об остановке эксперимента? Только когда достигнут размер выборки необходимый для достижения нужной стат мощности?
Крутим до тех пор, пока MDE не сойдется до приемлемых значений по самым важным метрикам. Бывает, что MDE вообще не сходится до нужных значений за адекватный срок, в таком случае нужно перезапускать эксперимент на большей доле трафика.
3) Как вы формулируете нулевую / альтернативную гипотезы если нужно проверить что некоторая метрика не упала?
Так и формулируем: метрика M не должна упасть больше чем на X%. В течение эксперимента ждем прокраса на X%, либо отсутствие прокраса при MDE <= X%.
svp777
31.05.2019 17:51С одной стороны вы пришите, что что-то контролирует нежелательные пересечения экспериментов, с другой стороны вы ссылаетесь на пересекающиеся эксперименты в Google, причем говорите, что «Чтобы не допускать потенциально опасных пересечений экспериментов, мы используем логику, схожую со «слоями» в Google». В итоге непонятно. Так пересекаются у Вас эксперименты или не пересекаются? Или Вы только опасные пересечения не допускаете, а неопасные пересечения допускаете? Каким же образом?
Во скольких экспериментах одновременно может участвовать Ваш посетитель? Если больше одного, то как много посетителей участвуют в более чем одном эксперименте? Сколько максимум экспериментов одновременно система тестирования выдерживает? Прокомментируйте 17 слайд презентации Google.lnkov Автор
31.05.2019 18:08Вы верно сформулировали: опасные пересечения не допускаем, опасные допускаем.
Невозможно одновременно проводить много экспериментов, не допуская пересечений. Поэтому мы делим все экспы на подмножества (слои), в каждом из которых обеспечивается отсутствие пересечений: т. е. ни один пользователь не может попасть одновременно в два эксперимента из одного слоя. Подробное объяснение, как реализована эта логика, осталась за пределами статьи, но презентация Google наглядно объясняет идею.
Статистику по количеству экспериментов разглашать не могу.svp777
31.05.2019 19:43Дайте пожалуйста определение опасного пересечения.
Опасное пересечение это такое, которое в одном слое или опасное пересечение это нечто, что вредит посетителю?
Так в скольких экспериментах максимум может участвовать один пользователь одновременно? Увеличивается ли количество слоев с течением времени, как на 17 слайде, или же количество слоев более менее постоянная величина, условно — дизайн, реклама, поиск? Может ли быть в слое «дизайн» много подслоев дизайна?

kikiwora
31.05.2019 18:05-1Правильно ли я понимаю что пользователю не дают выбора и не сообщают о том что над ним проводят эксперимент?
lnkov Автор
31.05.2019 18:10+4Правильно. Также как и при медицинских исследованиях пациенту не сообщают, дают ли ему экспериментальный препарат или плацебо.
Corsonamor
01.06.2019 21:41А если пользователь уже пользовался этим функционалом (на другом устройстве из другой сети) и подумал что «что-то пошло не так» и вернулся, не мешает ли эта ошибка наблюдателя анализировать выводы?
Сколько примерно случаев должно быть обработано, чтобы принять решение?
gban
01.06.2019 01:57-6С точки зрения пользователя, вы оживляете стюардессу, закопайте уже..
gban
03.06.2019 10:06-2Ну я не отрицаю, что каких-то целей вы достигаете, но судя по исключительно негативным отзывам пользователей о работе avito, на качестве сервиса в целом ваша работа не влияет. Ну либо дает вашему руководству основания продолжать ту же политику...

flyer2001
01.06.2019 13:12Спасибо за то, что показываете кухню! А для людей, кто не сильно в теме можете в двух словах рассказать о примерах таких «зеленых» и «красных» экспериментов?
lnkov Автор
01.06.2019 13:20+2Зеленые эксперименты = успешные, которые решили катить в прод. Красные = решили не катить и отправить на следующую итерацию разработки.
К сожалению, в виду NDA не могу рассказывать в паблик о конкретных примерах успешных и неуспешных экспериментов.
venheads
01.06.2019 22:33Весь транспорт данных в цикле занимает один день. Эксперименты длятся, как правило, неделю, но заказчик получает инкремент результатов каждый день.
Не возникает ли здесь проблемы многократного тестирования гипотезы?lnkov Автор
01.06.2019 22:48+1В теории возникает, на практике — нет. Во-первых, MDE не дает принимать преждевременные решения, если важные метрики не прокрасились. Во-вторых, когда у тебя в распоряжении много метрик и разрезов, легко отличить реальный эффект от false positive.
venheads
01.06.2019 22:50Если смотреть каждый день в тест в ожидании MDE, возрастает верояность его ложно принять. Даже наличие стат значимого MDE при разовом просмотре теста не гарантирует что не будет ошибки, при многократном просмотре риск растет, разве нет?
Промоделировать это довольно просто или можно посмотреть здесь
varianceexplained.org/r/bayesian-ab-testing
venheads
01.06.2019 22:34Теперь возникает вопрос: как провести T-test и MW-test для Ratio-метрик? Для T-test нужно уметь считать дисперсию выборки, а для MW выборка должна быть «поюзерной».
Что мешает считать дисперсию для метрика отношения, говорим что это биномиальное распределение/бернули, оценочная дисперсия p*(1-p)
Теперь переходим к новой экспериментальной единице — бакет. Наблюдения в бакете суммируем (числитель и знаменатель независимо):
Вы оценивали процент ошибок (например на синтетике или уже проведенном А/Б) первого/второго рода, при разных B, от B = N до B = const c разными значениеяси
Теперь возникает вопрос: как провести T-test и MW-test для Ratio-метрик? Для T-test нужно уметь считать дисперсию выборки, а для MW выборка должна быть «поюзерной».
Ответ: нужно разложить Ratio в ряд Тейлора до первого порядка в точке:
Данная формула преобразует две выборки (числитель и знаменатель) в одну, сохраняя среднее и дисперсию (асимптотически), что позволяет применять классические стат. тесты.
Похожую идею коллеги из Яндекса называют методом линеаризации Ratio (выступления раз и два).
Почему не стали использовать линеаризацию, она выглядит вычислительно проще и элегантнееlnkov Автор
01.06.2019 22:51+1Что мешает считать дисперсию для метрика отношения, говорим что это биномиальное распределение/бернули, оценочная дисперсия p*(1-p)
Это не то же самое, что ratio-метрика в общем смысле.
Вы оценивали процент ошибок (например на синтетике или уже проведенном А/Б) первого/второго рода, при разных B, от B = N до B = const c разными значениеяси
Оценивали. Чем больше B, тем меньше ошибка. 200 — хороший компромисс между размером ошибки и объемом данных, которые нужно хранить.
Почему не стали использовать линеаризацию, она выглядит вычислительно проще и элегантнее
Наш метод — это абсолютно то же самое немного в другом ракурсе. Но при этом он сохраняет mean для выборки и не зависит от mean в контрольной группе, а выборочная дисперсия равна оценке по дельта-методу.
devpony
Очень классно, спасибо что поделились.
lnkov Автор
Спасибо, что прочитали!
Отвечаю на вопросы:
1. Можно, cистема полностью для этого подходит.
2. Зависит от настроек в самом эксперименте. Но чтобы метрики собирались со всех платформ, необходимо делить пользователей на группы по хешу от id учетной записи, а не устройства.
3. В таком случае мы не собираем метрики со старых приложений. Это поведение также настраивается через конфиг.