Часть 1 — здесь.
Большое спасибо читателям за положительные отзывы.
Обучение
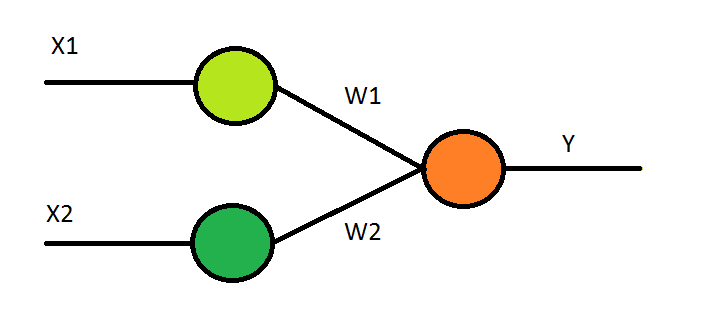
Ну вот, всё готово! Теперь можно начинать. Начинать обучать нейросеть, а потом пожинать плоды этого её обучения. Так думается поначалу, по неопытности… Но вернёмся к теории. К устройству нейрона. Есть дендриты, есть тело нейрона, есть аксон. По дендритам мы передаём входные сигналы (рост и вес), которые имеют свои веса W1 и W2, есть тело нейрона (активационная функция) и есть аксон(выход).
Какую функцию взять в качестве активационной? — Мой выбор пал на сигмойду (хотя, конечно, возможны другие варианты выбора активационной функции).

Первая проблема, с которой я столкнулся – сигмоида даёт слишком «маленький» отклик, уровень сигнала, не превышающий единицу, а значения ИМТ – не то что единицы, десятки! Но эта проблема решается достаточно легко – вводом коэффициента масштабирования. Я взял коэффициент 1/100.

Следующая проблема – сигмойда выдаёт значения от -0,5 до 0,5, а у меня в ИМТ отрицательных значений нет. Тоже решается достаточно просто – подвинем график по оси абсцисс влево с помощью ввода константы в функцию (то есть, чтобы X, равное нулю, давало Y, равное «0», а не «0,5»).

В итоге, для работы нашего искусственного нейрона имеем такой математический аппарат:
X = X1 * W1 + X2 * W2
Y = sigm(X) – 0.5
Где,
sigm – это сигмодальная функция:

Теперь переходим к обучению. — Берём функцию обратного распространения ошибки и … — И где её взять-то?! Кроме неясных «финтов ушами» в многочисленных статьях под рубрикой: «О, да нейросети – это просто! Как два пальца об асфальт!» никакой полезной инфы там не наблюдалось. Стало ясно, что необходима книга. Нормальная такая «человеческая» книга, где автор, без лишних «загибов пальцев», идёт от «простого к сложному» в построении нейросети и объясняет всё обстоятельно. И такая книга была найдена. Это книга Тарика Рашида «Создаём нейронную сеть».

Дня два-три я внимательно её изучал в поисках ответа на вопрос: «Какова же формула корректировки весов при обратном распространении ошибки?!», попутно проверяя правильность своих построений сверяясь с построениями Тарика. Тарик взял классический вариант использования нейросетей – «распознавание символов» и строил свою сеть для решения этой задачи (сеть у него двухслойная). Программный код в этой книге написан на языке Python, поэтому мне пришлось бегло изучить этот язык для того, чтобы понимать реализацию (я решил оставить добротное освоение Питона «на потом», так как это не только язык, но и среда разработки и инструментарий).
Шаг за шагом, постепенно я дошёл до главы, в которой производилась оценка ошибки и её корректировка. Метод вычисления корректирующих значений весов использует т.н. метод «градиентного спуска», использующий аппарат дифференциального исчисления (да-да, нейросети — это вам «не баран чихнул», это умные люди придумали).
Важное замечание: веса W1, W2 … Wn корректируются настолько, насколько они вносят свой вклад в ошибку. То есть:
Wновое = Wстарое — (dW * Wстарое)
dW – это вычисленная «общая» коррекция весов, которая затем распределяется по каждому весу.
В книге была приведена формула корректировки весовых коэффициентов для двухслойной сети, я адаптировал её для однослойной. Я не стану приводить эту формулу здесь, в статье, по сути дела, это и есть та самая «золотая монета» и сердце всего метода, без которого всякие разговоры о нейросетях превращаются в пустой трёп и дешёвый популизм интернетных статеек, рассказывающих о том, как быстро «освоить» нейросети и за полчаса стать в них «специалистом». Согласитесь, лучше, всё-таки, «быть», чем «казаться». Поэтому, если вы действительно интересуетесь нейронными сетями, рекомендую вам изучить эту книгу.

Ух! — Теперь можно стереть пот со лба и приступить к фактическому обучению и тестированию сети… Правда, ещё понадобится небольшой инструментарий по оценке качества её работы, но об этом я расскажу в 3 части статьи.
Конец второй части.
Комментарии (7)

Dim0v
04.06.2019 11:29+1У меня несколько вопросов.
Вопросы к автору.
- Часть 2 состояла из одной формулы сигмоиды. Часть 3, надо понимать, будет состоять из одной формулы перекрестной энтропии?
- Сколько всего частей планируется?
- Я правильно понял, что вы логистической функцией планируете предсказывать не ответ на вопрос "есть ли ожирение", а значение ИМТ/100?
И вопросы к тем, кто поставил плюс этой статье и первой части.
Вы могли бы оставить коммент со своей мотивацией? За что плююс? Какую ценность несут в себе эти статьи?
В сети полно намного более качественных "введений в нейросети". Либо с упором на то, как все устроенно под капотом — в этом случае в статьях нормально описано выведение всех формул, есть объяснение, откуда берется значение магической "«общей» коррекции весов" с градиентами, частными производными и вот этим вот всем, а не "я не стану приводить эту формулу здесь, а не то вы будете «казаться», а не «быть». Читайте книгу". Либо с упором на практическое применение. В этом случае используются более сложные и более приближенные к реальному применению нейросетей примеры задач, которые действительно требуют нейросетей, а не логистической регрессии. И что не менее важно, используются адекватные общепринятые в индустрии инструменты: Tensorflow/Keras, Torch/PyTorch, Theano, Kaffe, вот это вот всё. А не голый бейсик в экселе.
imperror
04.06.2019 11:59Соглашусь с вами во всем кроме последнего пункта, иногда нужно смастерить свой велосипед, чтоб потом правильно выбрать «адекватные общепринятые в индустрии инструменты».
Dim0v
04.06.2019 12:15Смастерить безусловно нужно. Но ценность описания этого процесса в виде статьи — под большим вопросом. И уж тем более под вопросом описание в виде серии из уже как минимум 3, а скорее всего и 4+ статей.
Я бы еще понял написание статьи после получения готовой "нейросети" и результатов её работы. С описанием набитых шишек, встреченных проблем, ошибочных решений и их причин. Но у автора ничего еще не работает. А проблем и ошибок уже сделано множество. Но о том, что это ошибки, автор не подозревает, потому что единственный результат его работы — это пока-что 2 статьи. Результатов обучения "нейросети", в котором эти ошибки проявились бы, у автора еще нет.

lair
06.06.2019 14:34Мой выбор пал на сигмойду (хотя, конечно, возможны другие варианты выбора активационной функции).
сигмоида даёт слишком «маленький» отклик, уровень сигнала, не превышающий единицу, а значения ИМТ – не то что единицы, десятки!
Следующая проблема – сигмойда выдаёт значения от -0,5 до 0,5, а у меня в ИМТ отрицательных значений нет.А теперь объясните, зачем вы
(а) берете сигмоиду, если она вам не подходит ни по одному параметру, и
(б) вообще берете активационную функцию, чем вам линейная активация не подходит?
Теперь переходим к обучению. — Берём функцию обратного распространения ошибки и … — И где её взять-то?!
Берете курс deeplearning.ai Neural Networks and Deep Learning, и находите там и как делать back-prop, и чем отличаются функции активации, и много других вещей.
Coderanger Автор
07.06.2019 10:45Резонные замечания.
И, хотя третья часть статьи уже написана, я всё-же возьму линейную функцию и поэкспериментирую с ней. Так же, сравню свою формулу с «бэкпропом» из предложенных курсов.
Спасибо.
0xf0a00
Наконец то кто то приоткрыл «магию».
Veber
www.3blue1brown.com/neural-networks