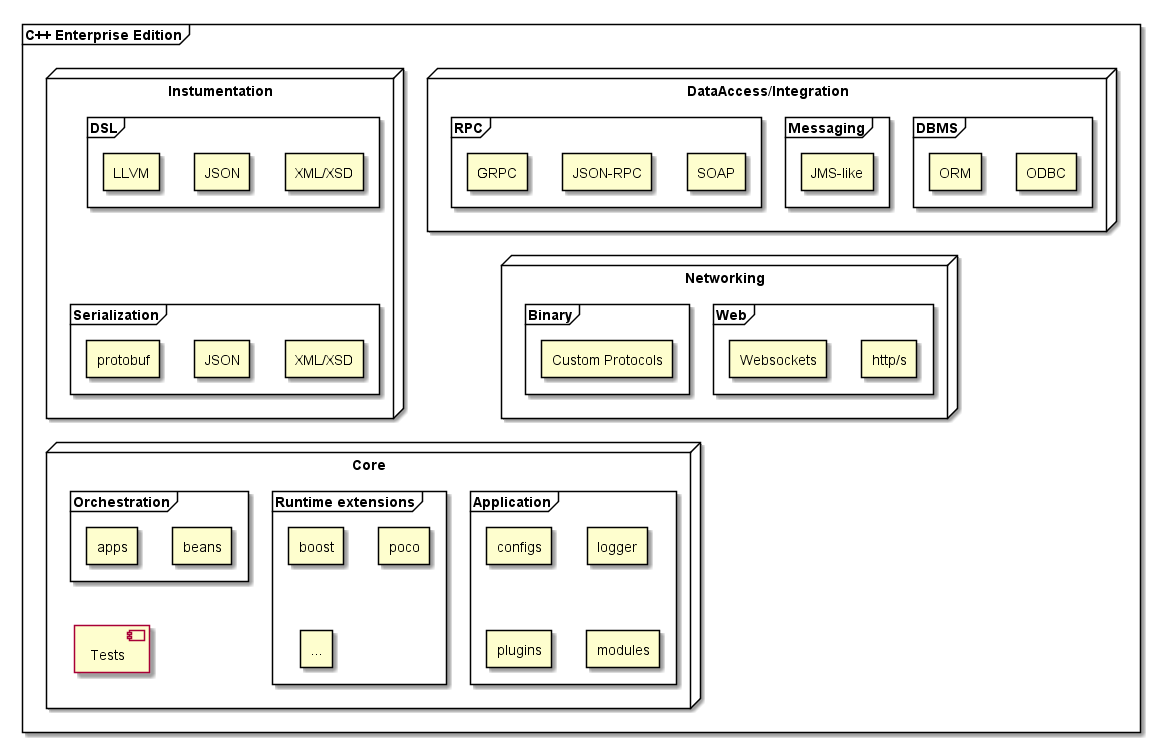
C++ Enterprise Edition
Что такое "enterprise edition"
Удивительно, но за все время моей работы в IT, я ниразу не слышал, чтобы кто-то говорил "enterprise edition" относительно языка программирования, кроме как для Java. Но ведь приложения для корпоративного сегмента люди пишут на многих языках программирования, и сущности, которыми оперируют программисты, если не идентичны, то схожи. И для c++ в частности, я бы хотел заполнить пробел enterpr'айзности, хотя бы рассказав об этом.
Применительно к c++, "enterprise edition" — это подмножество языка и библиотек, позволяющее "быстро" разрабатывать [кроссплатформенные] приложения для слабосвязных модульных систем с распределенной и/или кластерной архитектурой и с прикладной бизнес-логикой и, как правило, высокой нагрузкой.
Чтобы продолжить наш разговор, в первую очередь, необходимо ввести понятия приложения, модуля и плагина
- Приложение — это исполняемый файл, который может работать в качестве системной службы, имеет свою конфигурацию, может принимать параметры на вход и может иметь модульно-плагинную структуру.
- Модуль — это реализация интерфейса, живущая внутри приложения или бизнеслогики.
- Плагин — это динамически загружаемая библиотека, в которой реализован один или несколько интерфейсов, либо часть бизнеслогики.
Все приложения, выполняя свою уникальную работу, как правило нуждаются в общесистемных механизмах, таких как, доступ к данным (СУБД), обмен информацией через общую шину (JMS), исполнение распределенных и локальных сценариев с сохранением консистентности (Транзакции), обработка запросов, приходящих, например, по протоколу http(s) (fastcgi) или через websocket'ы и т.д… Каждое приложение должно иметь возможность оркестровки своих модулей (OSGI), а в распределенной системе должна быть возможность оркестровки приложений.
Пример схемы распределенной слабосвязной системы
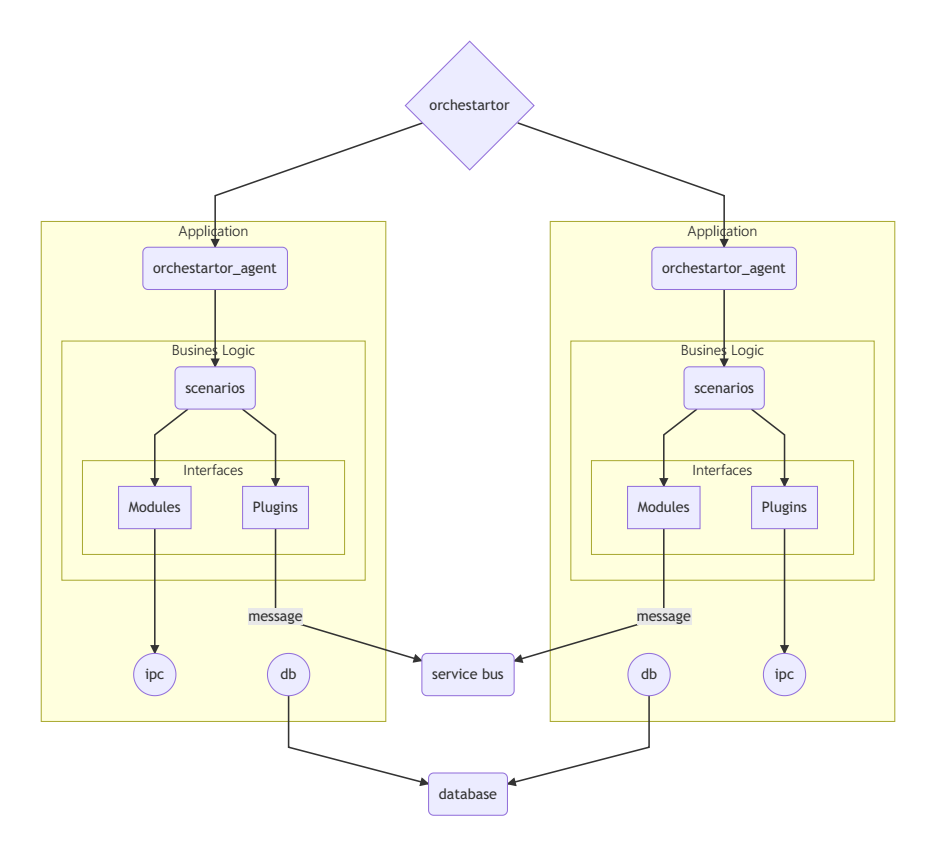
Приложение
Пример схемы "корпоративного" серверного приложения.

Общее определение приложению, я уже дал, так что разберемся, что же сейчас есть в мире c++ для имплементации этого понятия. Первыми показали реализацию приложения графические фреймворки, такие как Qt и GTK, но их версии приложения изначально предполагали, что приложение — это графическое "окно" со своим контекстом и только спустя время появилось общее видение приложения, в том числе и как системной службы, например, qtservice. Но тащить условно графический фреймворк для сервисной задачи не очень хочется, так что посмотрим в сторону неграфических библиотек. И первым на ум приходит boost… Но к сожалению в списке официальных библиотек нет Boost.Aplication и ей подобных. Есть отдельный проект Boost.Aplication. Проект весьма интересный, но, на мой взгляд, многословный, хотя идеология boost соблюдена. Вот пример приложения от Boost.Application
#define BOOST_ALL_DYN_LINK
#define BOOST_LIB_DIAGNOSTIC
#define BOOST_APPLICATION_FEATURE_NS_SELECT_BOOST
#include <fstream>
#include <iostream>
#include <boost/application.hpp>
using namespace boost;
// my application code
class myapp {
public:
myapp(application::context& context) : context_(context) {}
void worker() {
// ...
while (st->state() != application::status::stopped) {
boost::this_thread::sleep(boost::posix_time::seconds(1));
if (st->state() == application::status::paused)
my_log_file_ << count++ << ", paused..." << std::endl;
else
my_log_file_ << count++ << ", running..." << std::endl;
}
}
// param
int operator()() {
// launch a work thread
boost::thread thread(&myapp::worker, this);
context_.find<application::wait_for_termination_request>()->wait();
return 0;
}
bool stop() {
my_log_file_ << "Stoping my application..." << std::endl;
my_log_file_.close();
return true; // return true to stop, false to ignore
}
private:
std::ofstream my_log_file_;
application::context& context_;
};
int main(int argc, char* argv[]) {
application::context app_context;
// auto_handler will automatically add termination, pause and resume (windows)
// handlers
application::auto_handler<myapp> app(app_context);
// to handle args
app_context.insert<application::args>(
boost::make_shared<application::args>(argc, argv));
// my server instantiation
boost::system::error_code ec;
int result = application::launch<application::server>(app, app_context, ec);
if (ec) {
std::cout << "[E] " << ec.message() << " <" << ec.value() << "> "
<< std::endl;
}
return result;
}В приведенном примере определяется приложение myapp со своим основным рабочим потоком worker и механизм запуска этого приложения.
В качестве дополнения приведу аналогичный пример из фреймворка pocoproject
#include <iostream>
#include <sstream>
#include "Poco/AutoPtr.h"
#include "Poco/Util/AbstractConfiguration.h"
#include "Poco/Util/Application.h"
#include "Poco/Util/HelpFormatter.h"
#include "Poco/Util/Option.h"
#include "Poco/Util/OptionSet.h"
using Poco::AutoPtr;
using Poco::Util::AbstractConfiguration;
using Poco::Util::Application;
using Poco::Util::HelpFormatter;
using Poco::Util::Option;
using Poco::Util::OptionCallback;
using Poco::Util::OptionSet;
class SampleApp : public Application {
public:
SampleApp() : _helpRequested(false) {}
protected:
void initialize(Application &self) {
loadConfiguration();
Application::initialize(self);
}
void uninitialize() { Application::uninitialize(); }
void reinitialize(Application &self) { Application::reinitialize(self); }
void defineOptions(OptionSet &options) {
Application::defineOptions(options);
options.addOption(
Option("help", "h",
"display help information on command line arguments")
.required(false)
.repeatable(false)
.callback(OptionCallback<SampleApp>(this, &SampleApp::handleHelp)));
}
void handleHelp(const std::string &name, const std::string &value) {
_helpRequested = true;
displayHelp();
stopOptionsProcessing();
}
void displayHelp() {
HelpFormatter helpFormatter(options());
helpFormatter.setCommand(commandName());
helpFormatter.setUsage("OPTIONS");
helpFormatter.setHeader(
"A sample application that demonstrates some of the features of the "
"Poco::Util::Application class.");
helpFormatter.format(std::cout);
}
int main(const ArgVec &args) {
if (!_helpRequested) {
logger().information("Command line:");
std::ostringstream ostr;
logger().information(ostr.str());
logger().information("Arguments to main():");
for (const auto &it : args) {
logger().information(it);
}
}
return Application::EXIT_OK;
}
private:
bool _helpRequested;
};
POCO_APP_MAIN(SampleApp)Обращаю Ваше внимание на то, что приложение должно содержать механизмы журналирования, загрузки конфигураций и обработки опций.
Например, для обработки опций есть :
Для конфигурирования :
Для журналироания :
Слабосвязность, модули и плагины.
Слабосвязность в "корпоративной" системе — это возможность быстрой и безболезненной подмены тех или иных механизмов. Это касается как модулей внутри приложения, так и самих приложений, как реализаций, например, микросервисов. Что же у нас есть, с точки зрения c++. С модулями все плохо, хоть они и реализуют интерфейсы, но живут внутри "скомпилённого" приложения, так что быстрой подмены не будет, но на помощь приходят плагины! С помощью динамических библиотек можно не только организовать быструю подмену, но и одновременную работу двух разных версий. Есть еще целый мир "удаленного вызова процедур" он же RPC. Механизмы поиска реализаций интерфейсов в купе с RPC, породили нечто похожее на OSGI из мира Java. Здорово иметь поддержку этого в экосистеме c++ и она есть, вот пара примеров:
Пример модуля для "сервера приложения" POCO OSP
#include "Poco/OSP/BundleActivator.h"
#include "Poco/OSP/BundleContext.h"
#include "Poco/ClassLibrary.h"
namespace HelloBundle {
class BundleActivator: public Poco::OSP::BundleActivator {
public:
void start(Poco::OSP::BundleContext::Ptr pContext) {
pContext->logger().information("Hello, world!");
}
void stop(Poco::OSP::BundleContext::Ptr pContext) {
pContext->logger().information("Goodbye!");
}
};
} // namespace HelloBundle
POCO_BEGIN_MANIFEST(Poco::OSP::BundleActivator)
POCO_EXPORT_CLASS(HelloBundle::BundleActivator)
POCO_END_MANIFESTПример модуля для "серврера приложения" Apache Celix
#include "Bar.h"
#include "BarActivator.h"
using namespace celix::dm;
DmActivator* DmActivator::create(DependencyManager& mng) {
return new BarActivator(mng);
}
void BarActivator::init() {
std::shared_ptr<Bar> bar = std::shared_ptr<Bar>{new Bar{}};
Properties props;
props["meta.info.key"] = "meta.info.value";
Properties cProps;
cProps["also.meta.info.key"] = "also.meta.info.value";
this->cExample.handle = bar.get();
this->cExample.method = [](void *handle, int arg1, double arg2, double *out) {
Bar* bar = static_cast<Bar*>(handle);
return bar->cMethod(arg1, arg2, out);
};
mng.createComponent(bar) //using a pointer a instance. Also supported is lazy initialization (default constructor needed) or a rvalue reference (move)
.addInterface<IAnotherExample>(IANOTHER_EXAMPLE_VERSION, props)
.addCInterface(&this->cExample, EXAMPLE_NAME, EXAMPLE_VERSION, cProps)
.setCallbacks(&Bar::init, &Bar::start, &Bar::stop, &Bar::deinit);
}Хочется отметить, что в распределенных слабосвязных системах необходимо иметь механизмы обеспечивающие транзакционность операций, но на текущий момент для c++ ничего подобного нет. Т.е. как нет возможности внутри одного приложения выполнить запрос к базе данных, файлу и esb в рамках одной транзакции, так и нет такой возможности для распределенных операций. Безусловно все можно написать, но чего-то обобщённого нет. Кто-то скажет, что есть software transactional memory, да, конечно, но это лишь облегчит написание транзакционных механизмов собственными силами.
Инструментарий
Из всего множество вспомогательных инструментов хочу выделить сериализацию и DSL, т.к. их наличие позволяет реализовать многие другие компоненты и сценарии.
Сериализация
Сериализация — процесс перевода какой-либо структуры данных в последовательность битов. Обратной к операции сериализации является операция десериализации (структуризации) — восстановление начального состояния структуры данных из битовой последовательности wikipedia. В контексте c++ важно понимать, что на сегодняшний день нет возможности сериализации объектов и передачи их в другую программу, которая об этом объекте ранее ничего не знала. Под объектом в этом случае я понимаю реализацию некоего класса с полями и методами. Поэтому выделю два основных подхода, применяемые в мире c++ :
- сериализация в бинарный формат
- сериализация в формализованный формат
В литературе и интернете часто встречается разделение на бинарный и текстовый формат, но я считаю такое разделение не совсем правильным, например, MsgPack не сохраняет информацию о типе объекта, соответственно, отдается контроль за правильным отображением программисту и формат MsgPack — бинарный. Protobuf, напротив, сохраняет всю метаинформацию в промежуточное представление, что позволяет использовать его между разными языками программирования, при этом, Protobuf тоже бинарный.
Итак процесс сериализации, зачем он нам нужен. Для раскрытия всех нюансов, нужна еще одна статья, я постараюсь объяснить на примерах. Сериализация позволяет, оставаясь в терминах языка программирования, "упаковывать" программные сущности (классы, структуры) для передачи их по сети, для персистентного хранения, например, в файлах и других сценариев, которые, без сериализации, заставляют нас придумывать собственные протоколы, учитывать аппаратную и программную платформу, кодировку текста и.т.д.
Приведу пару примеров библиотек для сериализации:
DSL
Domain Specific Language — язык программирования для вашей предметной области. Действительно, когда мы занимаемся автоматизацией какого-то предприятия, то мы сталкиваемся с предметной областью заказчика и все бизнес-процессы описываем в терминах предметной области, но как только дело доходит до программирования, то программисты вместе с аналитиками занимаются отображением понятий бизнес-процессов в понятия фреймворка и языка программирования. И если бизнес-процессов не определенное количество, а предметная область определена достаточно строго, то имеет смысл создать свой DSL, для имплементации большей части существующих сценариев и добавления новых. В мире с++ не так много возможностей "быстрой" реализации своего DSL. Есть, конечно, механизмы встраивания lua, javascript и других языков программирования в c++-программу, но кому нужны уязвимости и потенциально неконтролируемый движок исполнения "всего" ?! Так что разберем те инструменты, что позволяют делать DSL самому.
Библиотека Boost.Proto как раз создана для создания собственных DSL, это её прямое предназаначение, вот пример
#include <iostream>
#include <boost/proto/proto.hpp>
#include <boost/typeof/std/ostream.hpp>
using namespace boost;
proto::terminal< std::ostream & >::type cout_ = { std::cout };
template< typename Expr >
void evaluate( Expr const & expr ) {
proto::default_context ctx;
proto::eval(expr, ctx);
}
int main() {
evaluate( cout_ << "hello" << ',' << " world" );
return 0;
}Flex и Bison используются для генерации лексеров и парсеров придуманных Вами грамматик. Синтаксис не простой, но задачу решает эффективно.
Пример кода для генерации лексера
/* scanner for a toy Pascal-like language */
%{
/* need this for the call to atof() below */
#include <math.h>
%}
DIGIT [0-9]
ID [a-z][a-z0-9]*
%%
{DIGIT}+ {
printf( "An integer: %s (%d)\n", yytext,
atoi( yytext ) );
}
{DIGIT}+"."{DIGIT}* {
printf( "A float: %s (%g)\n", yytext,
atof( yytext ) );
}
if|then|begin|end|procedure|function {
printf( "A keyword: %s\n", yytext );
}
{ID} printf( "An identifier: %s\n", yytext );
"+"|"-"|"*"|"/" printf( "An operator: %s\n", yytext );
"{"[^}\n]*"}" /* eat up one-line comments */
[ \t\n]+ /* eat up whitespace */
. printf( "Unrecognized character: %s\n", yytext );
%%
main( argc, argv )
int argc;
char **argv;
{
++argv, --argc; /* skip over program name */
if ( argc > 0 )
yyin = fopen( argv[0], "r" );
else
yyin = stdin;
yylex();
}А еще, существует спецификация SCXML — State Chart XML: State Machine Notation for Control Abstraction, описание конечного автомата в XML-подобной разметке. Это не совсем DSL, но тоже удобный механизм автоматизации процессов без программирования. Отличная имплементация есть у Qt SCXML. Есть и другие рализации, но они не такие гибкие.
Это пример FTP клиента в SCXML нотации, пример взят с сайта Qt Documentation
<scxml xmlns="http://www.w3.org/2005/07/scxml" version="1.0" name="FtpClient"
datamodel="ecmascript">
<state id="G" initial="I">
<transition event="reply" target="E"/>
<transition event="cmd" target="F"/>
<state id="I">
<transition event="reply.2xx" target="S"/>
</state>
<state id="B">
<transition event="cmd.DELE cmd.CWD cmd.CDUP cmd.HELP cmd.NOOP cmd.QUIT cmd.SYST
cmd.STAT cmd.RMD cmd.MKD cmd.PWD cmd.PORT"
target="W.general"/>
<transition event="cmd.APPE cmd.LIST cmd.NLST cmd.REIN cmd.RETR cmd.STOR cmd.STOU"
target="W.1xx"/>
<transition event="cmd.USER" target="W.user"/>
<state id="S"/>
<state id="F"/>
</state>
<state id="W">
<onentry>
<send eventexpr=""submit." + _event.name">
<param name="params" expr="_event.data"/>
</send>
</onentry>
<transition event="reply.2xx" target="S"/>
<transition event="reply.4xx reply.5xx" target="F"/>
<state id="W.1xx">
<transition event="reply.1xx" target="W.transfer"/>
</state>
<state id="W.transfer"/>
<state id="W.general"/>
<state id="W.user">
<transition event="reply.3xx" target="P"/>
</state>
<state id="W.login"/>
</state>
<state id="P">
<transition event="cmd.PASS" target="W.login"/>
</state>
</state>
<final id="E"/>
</scxml>А так это выглядит в визуализаторе SCXML

Доступ к данным и Интеграция
Это, пожалуй, одна из самых "наболевших" тем в мире с++. Мир данных для с++ разработчика всегда связан с необходимостью уметь отображать их на сущности языка программирования. Строку в таблице — в объект или структуру, json — в класс и так далее. В отсутствие рефлексии — это огромная проблема, но мы, с++-ники, не отчаиваемся и находим различные выходы из ситуации. Начнем с СУБД.
Сейчас буду банален, но единственным универсальным механизмом доступа к реляционным СУБД является ODBC, других вариантов пока не придумали, но с++-сообщество не стоит на месте и на сегодняшний день есть библиотеки и фреймворки, предоставляющих обобщённые интерфейсы доступа к нескольким СУБД.
В первую очередь упомяну библиотеки, предоставляющие унифицированный доступ к СУБД с помощью клиентских библиотек и SQL
Все они хороши, но заставляют помнить о нюансах отображения данных из БД в объекты и структуры с++, плюс эффективность SQL-запросов сразу ложиться на ваши плечи.
Следующими примерами будут ORM на c++. Да такие есть! И кстаи, SOCI, поддерживает механизмы ORM, через специализацию soci::type_conversion, но её я намеренно не включил, так как это не прямое её предназначение.
- LiteSQL C++ — ORM, позволяющий взаимодействовать с СУБД SQLite3, PostgreSQL, MySQL. Эта библиотека требует от программиста предварительного оформить xml-файлы с описанием объектов и отношений, чтобы, с помощью litesql-gen сгенерировать дополнительные исходники.
- ODB от Code Synthesis — очень интересная ORM, позволяет оставаться в рамках c++, не использую промежуточные файлы описания, вот небольшой пример :
#pragma db object
class person {
// ...
private:
friend class odb::access;
person () {}
#pragma db id
string email_;
string name_;
unsigned short age_;
};
// ...
odb::sqlite::database db ("people.db");
person john ("john@doe.org", "John Doe", 31);
odb::transaction t (db.begin ());
db.persist (john);
typedef odb::query<person> person_query;
for (person& p: db.query<person> (person_query::age < 30));
cerr << p << endl;
jane.age (jane.age () + 1);
db.update (jane);
t.commit ();
- Wt++ — большой фреймворк, о нем можно вообще отдельную статью написать, тоже содержит ORM, умеющий взаимодействовать с СУБД Sqlite3, Firebird, MariaDB/MySQL, MSSQL Server, PostgreSQL и Oracle.
- Отдельно хочется упомянуть ORM над sqlite sqlite_orm и hiberlite. Так как sqlite встраиваемая СУБД, а ORM для него проверяет запросы, да и вообще все взаимодействие с БД, в compile-time, то инструмент становится очень удобным для быстрого развертывания и прототипирования.
- QHibernate — ORM для Qt5 с поддержкой Postgresql. Пропитан идеями hibernate от java.
Хоть и интеграцию через СУБД считают "интеграцией", я предпочту оставить это за скобками и перейти к интеграции через протоколы и API.
RPC — remote porocess call, всем известная техника взаимодействия "клиента" с "сервером". Как и в случае c ORM, главная трудность — это написание/генерация различных вспомогательных файлов для связывания протокола с реальными функциями в коде. Я намеренно не буду упоминать различные RPC, реализованные непосредственно в операционной системе, а сосредоточусь на кроссплатформенных решениях.
- grpc — фреймворк от Google для удалённого вызова процедур, весьма популярный и эффективный фреймворк от google. В основе своей использует google protobuf, его я упоминал в разделе сериализация, поддерживает множество языков программирования, но в корпрративной среде пока новичок.
- json-rpc — RPC, где в качестве протокола используется JSON, хороший пример реализации — это библиотека libjson-rpc-cpp, вот пример файла описания :
[ { "name": "sayHello", "params": { "name": "Peter" }, "returns" : "Hello Peter" }, { "name" : "notifyServer" } ]
На основе этого описания генерятся клиентский и серврерный код, который можно использовать в своем приложении. Вообще есть спецификация для JSON-RPC 1.0 и 2.0. Так что вызвать функцию из web-приложения, а обработать в c++ труда не составит.
- XML-RPC и SOAP — тут явный лидер — это gSOAP, очень мощная библиотека, не думаю, что есть достойные альтернативы. Также как и в предыдущем примере, содаем промежуточный файлик с xml-rpc или soap содержимым, натравливаем на него генератор, получаем код и пользуемся. Типичные примеры запроса и ответа в нотации xml-rpc:
<?xml version="1.0"?> <methodCall> <methodName>examples.getState</methodName> <params> <param> <value><i4>41</i4></value> </param> </params> </methodCall> <methodResponse> <params> <param> <value><string>State-Ready</string></value> </param> </params> </methodResponse>
- Poco::RemotingNG — очень интересный проект от pocoproject. Позволяет определеять какие классы, функции и т.п. могут быть вызваны удаленно с помощью аннотаций в комментариях. Вот пример,
typedef unsigned long GroupID; typedef std::string GroupName; //@ serialize struct Group { Group(GroupID _id_, const GroupName &_name_) : id(_id_), name(_name_) {} Group() {} //@ mandatory=false GroupID id; //@ mandatory=false GroupName name; }; // ... //@ remote class EXTERNAL_API GInfo { public: typedef Poco::SharedPtr<GInfo> Ptr; GInfo(); virtual Group getGroup() const = 0; virtual ~GInfo(); };
Для генерации вспомогательного кода используется собственный "компилятор". Долгое время эта функциональность была только в платной версии POCO Framework, но с появлением проекта macchina.io, Вы можете пользоваться этим бесплатно.
Messaging — несколько широкое понятие, но я разберу его с точки зрения обмена сообщениями через общую шину данных, а именно пройдусь по библиотекам и серврерам реализующим Java Message Service используя различные протоколы, например AMQP или STOMP. Общая шина данных, она же Enterprise Servise Bus (ESB), очень распространена в решениях корпоративного сегмента, т.к. позволяет достаточно быстро интегрировать различные элементы IT-инфраструктуры между собой, используюя паттерн "точка-точка" и "публикация-подписка". Промышленных брокеров сообщений, написанных на c++, мало, я знаю два: Apache Qpid и
UPMQ, причем второй написан мной и пока является закрытым проектом. Есть еще Eclipse Mosquitto, но он написан на си. Прелесть JMS для java заключается в том, что Ваш код не зависит от протокола, который использует клиент и сервер, JMS как ODBC, декларирует функции и поведение, так что Вы можете хоть деясть раз на дню менять JMS-провайдера и не переписывать код, для c++ такого, к сожалению нет. Вам прийдется переписывыать клиентскую часть под каждого провайдера. Перечислю, на мой взгляд, самые популярные c++ библиотеки для не менее популярных брокеров сообщений:
- ActiveMQ-CPP — клиентская библиотека к брокеру Apache AcriveMQ, который написан на java.
- Apache Kafka C++ client — cppkafka
- RabbitMQ C++ libs — наверное самый популярный брокер сообщений, имеет несколько библиотек на с/с++.
- IBM WebSphere MQ C++ classes — проприетарщина, но с очень развитым функционалом.
- Oracle Message Broker C++ API — тоже, он от Oracle
- MSMQ — версия от Microsoft
Принцип по которому эти библиотеки предоставляют функиональность общий, как правило соответствует спецификации JMS. В связи с этим есть желание собрать группу единомышленников и написать некое подобие ODBC, но для брокеров сообщений, чтобы каждый программист на c++ страдал чуть меньше, чем обычно.
Сетевое взаимодействие
Я умышлено оставил все что связано непосредственно с сетевым взаимодействием на последок, т.к. на этом поприще у c++ разработчиков меньше всего проблем, на мой взгляд. Остается лишь выбрать паттерн, который ближе всего к Вашему решению, и фреймворк, его реализующий. Прежде чем перечислить самые популярные библиотеки, хочу отметить важную деталь разработки собственных сетевых приложений. Если Вы решили придумать собственный протокол поверх TCP или UDP, будьте готовы, что всякие "умные" средства защиты будут блокировать Ваш трафик, так что озаботьтесь упаковкаой своего протокола, например, в https или могут быть проблемы. Итак библиотеки :
- Boost.Asio и Boost.Beast — одино из самых популярных реализаций для асинхронного сетевого взаимодействия, есть поддержка HTTP и WebSockets
- Poco::Net — тоже очень популярное решение, причем, помимо "сырого" взаимодействия можно использовать готовые классы TCP Server Framework, Reactor Framework, а также клиентские и серверные классы для HTTP, FTP и E-Mail. Так же есть поддержка WebSockets
- ACE — никогда не пользовался этой библиотекой, но коллеги говорят, что тоже стоящая внимания библиотека, с комплексным подходом для реализации сетевых приложений и не только.
- Qt Network — в Qt неплохо реализована сетевая часть. Единственный спорный момент — сигналы и слоты для серврерных решений, хотя сервер на Qt !?
Итого
Итак, что я хотел сказать обзором этих библиотек. Если у меня получилось, то у Вас осталось впечатление, что "enterprise edition", как бы, есть, а решения для его имплементации и использования — нет, только зоопарк библиотек. Так оно и есть на самом деле. Есть более-менее целостные библиотеки для разработки приложений корпоративного сегмента, но стандартного решения нет. От себя могу лишь рекомендовать pocoproject и maccina.io как отправную точку в исследованиях решений для бэкенда и boost для любых случаев, ну и конечно же ищу единомышленников для продвижения понятия "C++ Enterprise Edition" !
Комментарии (41)

firk
11.06.2019 18:29+1Какой ужас.
Ещё один не понял, что язык программирования это не реализация а стандарт, в случае с++ — можно считать публичный.
А статья пытается название этого стандарта приватизировать под какой-то конкретный программный продукт. Нехорошо так делать.
Если б это назвалось C++ raiSadam's Framework (хоть Enterprise хоть любое другое Edition) — никаких претензий бы не было, но и название сразу перестаёт быть таким громким.raiSadam Автор
11.06.2019 18:47-1Никаких "своих" фреймворков я и не предлагаю. Я говорю о том, что текущий "открытый" стандарт языка c++ не описывает некоторые сущности, например, логгер или application, а хотелось бы. А в статье собраны реализации того, что хотелось бы в c++ee.

Antervis
11.06.2019 19:47на с++ решаются очень много специализированных задач. Если бы было так просто сделать логгер, который всех устроит, он бы уже давно был стандартизован.
или application
что такое «application» и зачем оно нужно?raiSadam Автор
12.06.2019 20:11То, что есть в JavaEE по умолчанию тоже не всех устраивает, но есть стандарт и имплементацию можно заменить, предоставив тем самым гарантии совместимости.
firk
12.06.2019 19:21Стандарт языка и не должен описывать никакие высокоуровневые сущности, он должен описывать синтаксис и некоторые базовые элементы алгоритмов (которые либо тривиальны и безальтернативны, либо слишком платформенно-зависимы, но при этом всем гарантированно нужны) в виде стандартной библиотеки.
То что хотите вы — это не язык, а фреймворк, и не надо выдавать это под вводящими в заблуждение названиями.
С джавой сравнивать не надо, она не только язык и никогда "только языком" не была, а была весьма обособленной средой для запуска софта.
raiSadam Автор
12.06.2019 20:02Тогда JavaEE — это фреймворк?
firk
13.06.2019 19:22Несмотря на то, что Java — это коммерческий бренд, и владельцы его могут под ним выпускать что им вздумается, они всё же поступили разумно и в официальной расшифровке "JavaEE" всё указали: Java Platform Enterprise Edition. То есть это платформа. Что-то похожее на фреймворк, да.
Для нативно выполняемых программ платформой является операционная система, в которой обычно имеется пакетный менеджер для установки всего того что вы описали в статье. И такая, с одной стороны, глобальность, а с другой, такое разделение труда (кто-то придумал язык, а кто-то ОС, и работают они независимо) — это плюс нативного софта, а не минус.
raiSadam Автор
13.06.2019 19:54Конечно JavaEE, как платформа, имеет дефолтовые реализации всех спецификаций, но не запрещает их поменять. Так что Вы правы отчасти. А наивные приложения зависят от библиотек, так что все аналогично Java, только на другом уровне.

sashagil
12.06.2019 09:48Интересно, спасибо. В разделе про DSL вы пишете про «Реализации на базе flex и bison», это очень сурово и олдскульно — у меня опыт с ANTLR довольно позитивный (не уверен, что буду в следующий раз использовать ANTLR, скорее, попробую ещё что-нибудь… Но уж точно не flex и bison! 21 век всё-таки настал :) ). Что сегодня важно для хорошего DSL — реализация LSP (Language Server Protocol) с самого начала. Дойдёт до «следующего раза», буду ориентироваться на инструменты, облегчающие реализацию LSP в первую очередь.
tangro
12.06.2019 11:30+1Для Java существует «энтерпрайз эдишн», поскольку джавоские задачи в энтерпрайзе преимущественно одинаковые: понятно, что будет реализовываться, в каком окружении работать, требования к производительности, нагрузке. В мире С++ разброс куда больше. Кому-то нужен логгер с кучей возможностей, а кому-то с одной записью в один файл, но очень быстро, а кому-то нужен header-only логгер, а кому-то кросплатформенный, а кому-то многопоточный, а кому-то под старый компилятор, а кому-то под С++17, а кому-то только уже собранный (под определённый тулсет) и т.д.
Чёрта с два вы этот логгер специфицируете как-то так, чтобы всем подошло, уж не говоря о его реализации.
gecube
12.06.2019 12:07-1Я соглашусь, т.к. такая же история со стандартными контейнерами. Внезапно выясняется, что каждый, кто серьезно программирует на С++, делает свою реализацию....

sergey-b
12.06.2019 15:41Что неужели до сих пор так? Я тоже делал свою реализацию, только лет 10 назад.
Antervis
12.06.2019 16:11уже не делает. С приходом с++11 в языке появились мув семантика (с которой COW оптимизация потеряла большую часть актуальности) и несколько недостающих контейнеров. Кто-то завязался на свои велосипеды и до сих пор ими пользуются, кто-то пишет свои контейнеры под свои же очень специфичные нужды.
khim
12.06.2019 17:05COW убила не «мув семантика», а банальная многопоточность. Если вы в COW свои счётчики увеличиваете/уменьшаете без атомарных операций — то «огребаете» очень быстро. А если атомарно — то тут же выясняете, что скопировать сотню байт быстрее, чеим дёрнуть атомарно счётчик один раз. Структур же размером больше сотни байт в программе обычно [относительно] немного и за ними можно уследить и так.
C++11 строки появились в libstdc++ в 2007м году, когда ещё ни о какой мув семантике никто и не мечтал — просто их нельзя было сделать стандартом до GCC 5 ибо совместимость же!Antervis
13.06.2019 00:53А если атомарно — то тут же выясняете, что скопировать сотню байт быстрее, чеим дёрнуть атомарно счётчик один раз
Ну вы неправильно сравниваете. Всё-таки скопировать какую-нибудь строчку это не только «скопировать сотню байт», а еще и сделать аллокацию/деаллокацию. Которые в свою очередь тоже используют разделенное между потоками состояние. А если у нас какой-нибудь старый добрый и повсеместно используемый «вектор строк», то получается что даже на нескольких элементах атомарно дернуть счетчик во много раз быстрее. Без мув семантики у копирования/COW альтернативы только велосипедные — писать кастомные swap функции, жонглировать указателями и т.д.khim
13.06.2019 14:41Всё-таки скопировать какую-нибудь строчку это не только «скопировать сотню байт», а еще и сделать аллокацию/деаллокацию.
Не обязательно. Есть short-string optimization.
Которые в свою очередь тоже используют разделенное между потоками состояние.
И это тоже не обязательно — tcmalloc (и другие современные) держит про запас немного per-thread буферов… опять-таки, чтобы с atomic'ами не связываться.
Без мув семантики у копирования/COW альтернативы только велосипедные — писать кастомные swap функции, жонглировать указателями и т.д.
Ну вот Google померил — и при переходе с GCC 2.95 на GCC 4.2 сделал
#define __gnu_cxx::__versa_string stringгде достаточно
Главное - не использовать аргументы типа stringconst string&
А после перехода на C++11 - там уже, в основном, от std::string_view экономия.Antervis
13.06.2019 21:03Не обязательно. Есть short-string optimization.
которая очевидно работает для маленьких строк )
И это тоже не обязательно — tcmalloc (и другие современные) держит про запас немного per-thread буферов… опять-таки, чтобы с atomic'ами не связываться.
«немного»
А после перехода на C++11 — там уже, в основном, от std::string_view экономия.
с++17 то?
maydjin
12.06.2019 15:55Интересно, почему же таких спецификаций и/или решений нет?
Наверное, потому, что писать системы упирающиеся в i/o в 99% случаев на C++ — избыточно и дорого, притом — без какого либо видимого профита(и это если не поднимать тему стрельбы по ногам). Если где-то таки есть ботлнек в памяти или процессоре — то гораздо проще подключить через jni подобный интерфейс точечное решение.
Обзор хороший, но enterprise edition нам, надеюсь, и не светит в общепринятом смысле в каком-то обозримом будующем. Ну разве что железо совсем перестанет развиваться и повышение его утилизации на n% станет выгодно не только гуяндобукам относительно трат на разработку.
raiSadam Автор
12.06.2019 20:22Спецификаций действительно нет, а вот решений есть, особенно востребовано это в системах с высоким уровнем защиты и сертификации, т.е. там, где можно только компилировать и нельзя интерпретировать, и нельзя виртуальных машин. Я как то уже отписываться о СЭД Министерства Обороны, так вот там все на c++ и это очень даже Enterprise, теперь, я работаю на антивирусную компанию, и тут тоже c++, который дополнен своим Enterprise Edition. Т.е. и в СЭД и в антивирусе есть разная реализация одних и тех же сущностей, естественно выборка моя не ограничивалась двумя компаниями, их было больше, и общая картина такова, что все мы делаем одно и тоже, только разными способами.
maydjin
12.06.2019 21:11Вам виднее — а я всегда думал, что виртуальные машины "безопаснее". Как минимум всякая обфускация и защита кода зачастую делается с их помощью, но с этой стороной вопроса мне пересекаться практически не довелось.
общая картина такова, что все мы делаем одно и тоже, только разными способами
Вот тут — можно спорить. То, что я видел на плюсах было обычно либо middleware либо разруливанием узкого места. Видел только два решения где был "enterprise" и развесистая логика на плюсах. Система АРМ для автоматизации и учёта инспекций из нулевых(почему там выбрали плюсы и desktop формат — для меня загадка, после 10+ лет развития, за несколько месяцев её переписали на .Net, и в течении года запустили в прод, сократив косты на саппорт в разы, если не на порядок и получили почти бесплатно ещё и web морду) и толстый шлюз с бизнес логикой(там плюсы выбрали в силу немасштабируемости решения горизонтально, т.е. в силу нефункциональных требований, переплевались(все кроме плюсовиков :)), побенчмаркали и всё равно сначала наделали js/java/python адапторов для логики, а потом, насколько я знаю — переписали на java и оставили только пару нативных библиотек с циклами обработки сообщений и парсерами).
raiSadam Автор
12.06.2019 21:18Действительно, многие так поступают, перепысывая с плюсов на что-то ещё, с более богатым рантаймом, но это не всегда приемлемо, яркий тому пример — это любое ПО, подвергающееся сертификации, что в России, что в Европе, его нельзя писать не на компилируемых языках, если есть хоть намёк на гриф информации, так вот в этом случае от плюсов не уйти просто. Может пример узковатый получился, но показательный, есть и другие примеры из медицины, например,…

SirEdvin
А вы точно понимаете, что такое Java EE? Это разрозненный набор спецификаций, а не реализаций. В случае Java основный смысл именно в том, что это стандарт.
raiSadam Автор
Вы правы, я и сетую на то, что нет такого же стандарта для c++, а есть лишь реализации.
Antervis
в с++ есть просто «стандарт» и нет особого смысла разбивать его на подмножества наборов спецификаций отдельных фич.
raiSadam Автор
Но ведь стандарт не определяет понятия Applicaton или Logger, а этим пользуются. И то, что нет «стандарта» только добавляет боли поиска решения. Текущий же стандарт он не про «сериализацию», DSL и подобное, текущий стандарт — это про базовые контейнеры и алгоритмы. И я не «за подмножество наборов фич», я за типовые решения в рантайме языка, ну или где-то очень рядом, например в бусте.
pvsur
Borland раньше очень любил всякие едишены, как и его преемник ембаркадеро… Потому меня там и нет более.
Antervis
типовые задачи, которые можно решить ограничившись одним фреймворком, обычно решаются не на с++, а на каком-нибудь питончике. Но фреймворки у плюсов всё же есть — boost (который можно считать расширением стандартной библиотеки) или Qt (отличный компромисс функциональности/практичности/удобства/производительности).
данные можно сериализовывать миллионом способов
ну плюсы всё-таки являются универсальным языком
raiSadam Автор
Безусловно, плюсы — универсальный язык, но, к сожалению, его стандартная библиотека не покрывает некоторых "универсальных" потребностей, которые я назвал c++ee. Фреймворки предоставляют эти возможности, но заставляют тянуть паровозом то, что может и не надо, так что хочется стандартизации того, что есть во всех фреймворках.
Antervis
настолько ли универсальных?