
Краткие сведения о балансировке HTTP трафика
Существуют различные способы балансировки HTTP трафика. По уровням модели OSI бывают технологии балансировки на сетевом, транспортном и прикладном уровнях. В зависимости от масштабов приложения могут использоваться их комбинации.
Технология балансировки трафика дает положительные эффекты в работе приложения и его обслуживания. Вот некоторые из них. Горизонтальное масштабирование приложения, при котором нагрузка распределяется среди нескольких узлов. Плановый вывод из эксплуатации сервера приложений за счет снятия с него потока клиентских запросов. Реализация стратегии A/B тестирования измененного функционала приложения. Повышение отказоустойчивости приложения путем направления запросов на исправно функционирующие серверы приложений.
Последняя функция реализовывается в двух режимах. В пассивном режиме балансировщик в клиентском трафике оценивает ответы целевого сервера приложений и при определенных условиях исключает его из пула рабочих серверов. В активном режиме балансировщик периодически самостоятельно направляет запросы на сервер приложений по заданному URI, и по определенным признакам ответа принимает решение об исключении его из пула рабочих серверов. В дальнейшем, балансировщик, при определенных условиях, возвращает сервер приложений в пул рабочих серверов.
Пассивная проверка сервера приложений и его исключение из пула рабочих серверов
Рассмотрим подробнее пассивную проверку сервера приложений в свободно распространяемой редакции nginx/1.17.0. Серверы приложений выбираются поочередно алгоритмом Round Robin, их веса одинаковы.
На трех-шаговой схеме представлен временной участок, начинающийся с направления клиентского запроса на сервер приложений №2. Светлый индикатор характеризует запросы/ответы между клиентом и балансировщиком. Темный индикатор – запросы/ответы между nginx и серверами приложений.
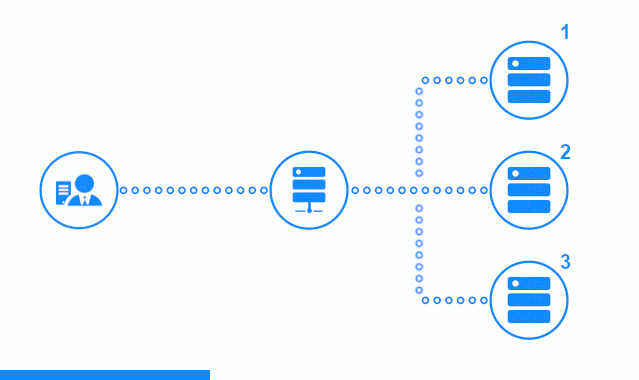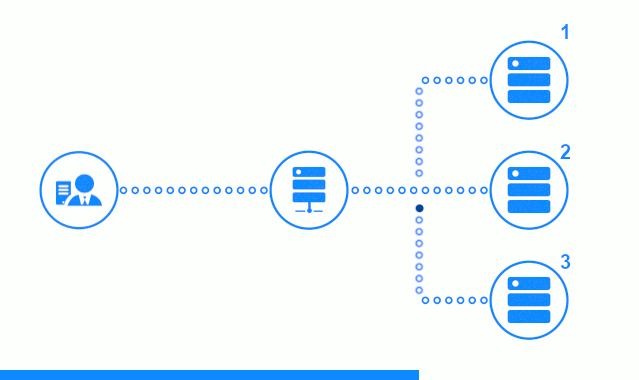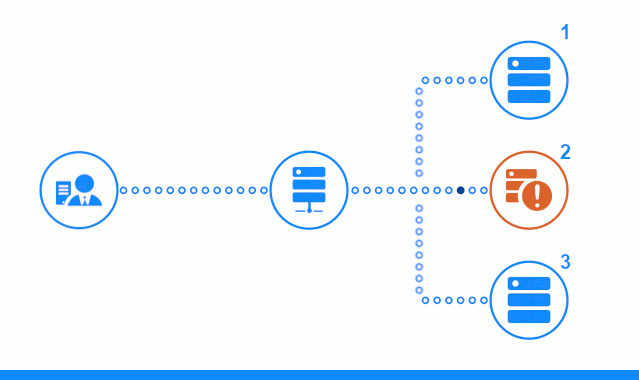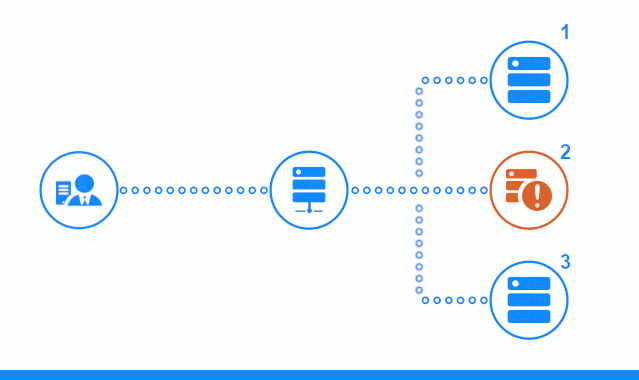
На третьем шаге схеме показано как балансировщик перенаправляет запрос клиента на следующий сервер приложений, в случае, если целевой сервер дал ответ с ошибкой или вообще не ответил.
Перечень HTTP- и TCP-ошибок, при которых сервер использует следующий сервер задается в директиве proxy_next_upstream.
По умолчанию nginx повторно перенаправляет на следующий сервер приложений только запросы c идемпотентными HTTP методами.
Что же получает клиент? С одной стороны, возможность перенаправления запроса на следующий сервер приложений увеличивает шансы предоставить удовлетворительный ответ клиенту при выходе из строя целевого сервера. С другой, очевидно, что последовательное обращение сначала на целевой сервер, а затем на следующий увеличивает общее время ответа клиенту.
В конце концов, клиенту возвращается ответ сервера приложений, на котором закончился счетчик допустимых попыток proxy_next_upstream_tries.
При использовании функции перенаправления на следующий рабочий сервер нужно дополнительно гармонизировать таймауты на балансировщике и серверах приложений. Верхним ограничением времени «путешествия» запроса между серверами приложений и балансировщиком является таймаут клиента, либо время ожидания, определенное бизнесом. При расчете таймаутов, также необходимо учесть запас на сетевые события (задержки/потери при доставке пакетов). Если клиент всякий раз будет завершать сессию по таймауту пока балансировщик добывает гарантированный ответ, благое намерение сделать приложение надежным будет тщетным.

Управление пассивной проверкой работоспособности серверов приложений выполняется директивами, например, со следующими вариантами их значений:
upstream backend {
server app01:80 weight=1 max_fails=5 fail_timeout=100s;
server app02:80 weight=1 max_fails=5 fail_timeout=100s;
}
server {
location / {
proxy_pass http://backend;
proxy_next_upstream timeout http_500;
proxy_next_upstream_tries 1;
...
}
...
}По состоянию на 02.07.2019 документацией установлено, что параметр max_fails задаёт число неудачных попыток работы с сервером, которые должны произойти в течение времени, заданного параметром fail_timeout.
Параметр fail_timeout задаёт время, в течение которого должно произойти заданное число неудачных попыток работы с сервером для того, чтобы сервер считался недоступным; и время, в течение которого сервер будет считаться недоступным.
В приведенном примере части конфигурационного файла балансировщик настроен на отлов 5 неудачных обращений в течение 100 секунд.
Возвращение сервера приложений в пул рабочих серверов
Как следует из документации, балансировщик после истечения fail_timeout не может считать сервер неработоспособным. Но, к сожалению, документацией не установлено явно, как именно оценивается работоспособность сервера.
Без проведения эксперимента можно только предположить, что механизм проверки состояния аналогичен ранее описанному.
Ожидания и реальность
В представленной конфигурации от баланисровщика ожидается следующее поведение:
- До тех пор, пока балансировщик не исключит сервер приложений №2 из пула рабочих серверов, на него будут направляться запросы клиента.
- Запросы, возвращаемые с 500 ошибкой от сервера приложений №2 будут пересылаться на следующий сервер приложений, и клиент получит положительные ответы.
- Как только балансировщик в течении 100 секунд получит 5 ответов с кодом 500, он исключит сервер приложений №2 из пула рабочих серверов. Все запросы, следующие после 100 секундного окна, будут сразу направляться на оставшиеся рабочие серверы приложений без дополнительных затрат времени.
- Балансировщик по истечению 100 секунд каким-то образом должен оценить работоспособность сервера приложений и вернуть его в пул рабочих серверов.
Проведя натуральные испытания, по журналам балансировщика установлено, что утверждение №3 не работает. Балансировщик исключает неработоспособный сервер, как только исполнится условие по параметру max_fails. Таким образом, неисправный сервер исключается из обслуживания не дожидаясь истечения 100 секунд. Параметр fail_timeout играет роль только верхнего предела времени накопления ошибок.
В части утверждения №4 выясняется, что nginx проверяет работоспособность ранее исключенного из обслуживания сервера приложения только одним запросом. И если сервер по-прежнему отвечает ошибкой, то следующая проверка состоится по истечению fail_timeout.
Чего не хватает?
- Реализованный в nginx/1.17.0 алгоритм, возможно, не самым справедливым образом проверяет работоспособность сервера перед его возвращением в пул рабочих серверов. Как минимум, по действующей документации ожидается не 1 запрос, а количество, указанное в max_fails.
- Алгоритм проверки состояния не учитывает скорость запросов. Чем она больше, тем сильнее спектр с неудачными попытками сдвигается влево, и сервер приложений слишком быстро выбывает из пула рабочих серверов. Предположу, что это может негативно сказаться на приложениях, которые позволяют себе «короткими во времени сгустками» давать ошибки. Например, при сборке мусора.

Хотел у вас спросить, есть ли практическая польза от алгоритма проверки работоспособности сервера, в котором оценивается скорость неудачных попыток?
Комментарии (4)

fessmage
03.07.2019 22:33+1В вашем примере есть гораздо более важный и тоже не очевидный из документации nginx нюанс — при proxy_next_upstream_tries 1 на второй бэкенд запросы не пойдут. За 1 считается уже попытка соединения с первым же сервером. Так что если вы хотите ограничить попытки например двумя серверами из четырех — ставьте proxy_next_upstream_tries 2. А proxy_next_upstream_tries 1 сработает по сути аналогично proxy_next_upstream off — запретит перебирать бэкенды и заставит отдать ответ от первого выбранного. Я проверял это поведение вживую.
Еще обязательно ставьте proxy_connect_timeout в значения не более 1 секунды. А параметры proxy_read_timeout и proxy_send_timeout считайте как общее время на весь запрос для клиента разделенное на количество попыток: proxy_next_upstream_timeout / proxy_next_upstream_tries. С округлением в меньшую сторону.
Из персонального опыта — люди не готовы ждать больше нескольких секунд, и уже после пяти секунд ожидания — некоторые просто закрывают сайт или приложение. Это видно по коду 499 в логах. Поэтому и proxy_next_upstream_timeout нет смысла делать больше тех же 10 секунд, а таймауты на бэкенд соответственно не должны превышать нескольких секунд. Лучше быстро попробовать несколько серверов и если кто-то живой — отдать ответ, а нет — вернуть клиенту ошибку. Чем ждать таймаута на его устройстве или пока терпение лопнет.
И вот еще очень полезная статья на тему high availability балансировки — https://m.habr.com/ru/company/oleg-bunin/blog/423085/
Sannis
Что если не пытаться тюнить пассивные проверки, а сразу перейти на активные?
fessmage
При большом потоке запросов активные healthchecks будут проходить реже, чем пассивная проверка обычного трафика. А значит от них будет меньше пользы.
Sannis
Согласен, но у автора другой случай как я понимаю.