Неправомерное Заимствование — это многоголовая гидра, враг, постоянно меняющий свое лицо. Наши лучшие частные сыщики готовы зацепиться за любое злодеяние, совершенное этим врагом. Однако противник не дремлет, он хитер и коварен: явно подставляясь в одном деле, он невероятно умело заметает следы в других. Иногда его удается поймать с поличным с помощью нашего самого шустрого сотрудника — Суффиксного Массива. Иногда противник мешкает, и скрупулезный, но неторопливый Поиск Парафраза успевает вычислить его местоположение. Но зло коварно, и нам постоянно нужны новые силы для борьбы с ним.
Сегодня мы расскажем о нашем новом детективе специального назначения по имени Нечеткий Поиск, а также о его первом столкновении с нечеткими заимствованиями.
С вами детективное агентство Антиплагиат, приготовьтесь к Делу о Таинственном Противнике

Источник изображения: pxhere.com
Место происшествия
При проверке местности (документа) Антиплагиат проверяет, не поступали ли звонки о возможном преступлении в этом районе. В качестве очевидцев, которые будут сигнализировать нам о преступлении, выступает Индекс шинглов.
«Шингл — это кусочек текста размером в несколько слов». Каждый такой кусочек хешируется, и в индексе ищутся документы, которые имеют шинглы с теми же хешами, что и в проверяемом документе.
Очевидец, видя совпадение по хешу двух шинглов, звонит нам с сообщением о преступлении. К сожалению, индекс шинглов нельзя наказать за ложный вызов, он невосприимчив к санкциям, из-за чего звонков происходит очень много. Агентство определяет документы с наибольшим скоплением таких звонков — места потенциального преступления.
Первая зацепка
Теперь ты детектив, сынок.
Отныне тебе запрещается верить в совпадения.
© «Темный рыцарь: возрождение легенды» («The Dark Knight Rises», реж. К. Нолан, 2012).
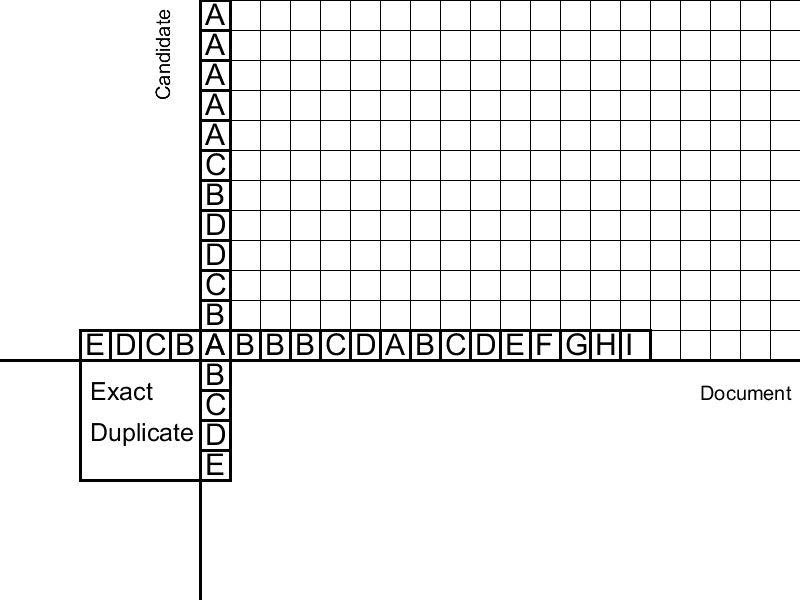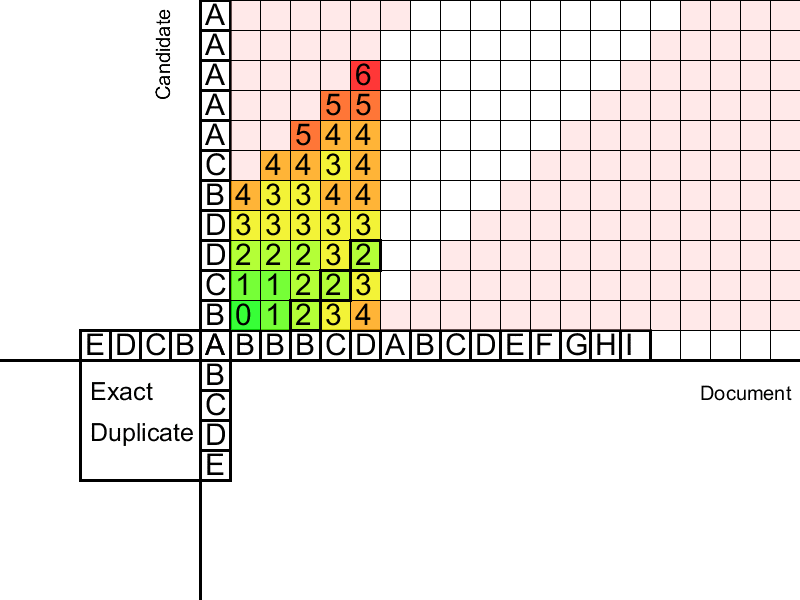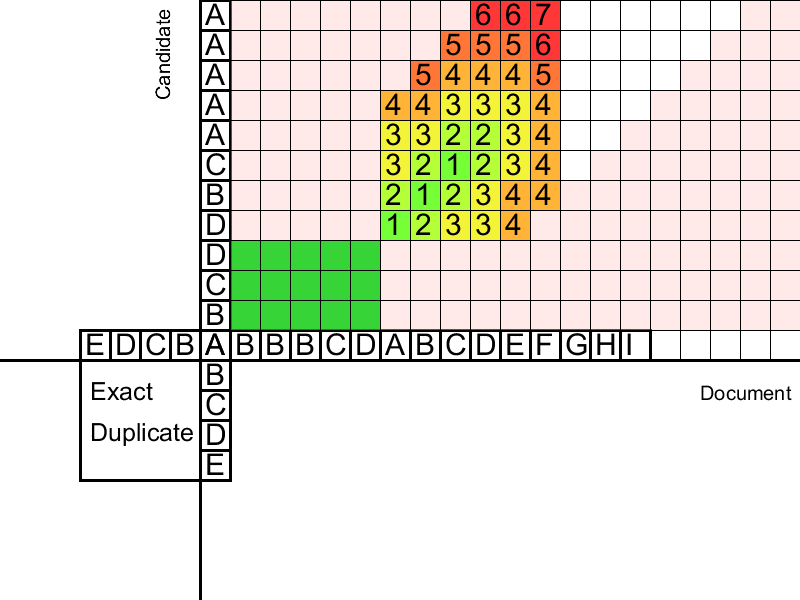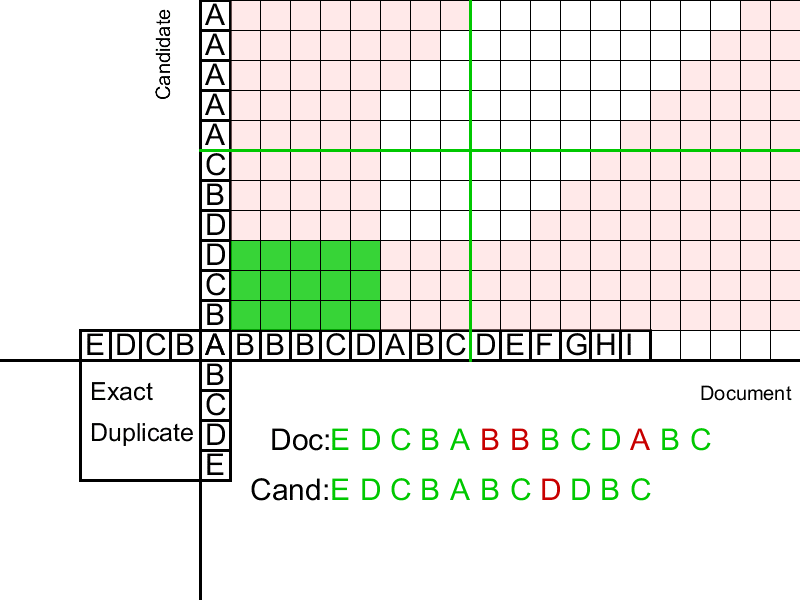
Детектив Нечеткий Поиск прибыл на место преступления. Достаточно крупные преступники не остаются незамеченными, ведь чем больше масштаб преступления, тем больше шансов оставить зацепку. Для Нечеткого Поиска такими зацепками являются короткие совпадения фиксированной длины. Кажется, что наш детектив упускает большую долю умело заметающих следы преступников, однако лишь 5% злоумышленников не оставляют такой зацепки. Важно не потерять преступников, поэтому детектив быстро сканирует местность, используя особую методику обнаружения совпадений.
Дневник детектива о методике работы. Первый этап
Воспользуемся двумя особенностями задачи:
- Нас интересуют четкие дубликаты фиксированной длины.
- В хорошем документе один и тот же шингл не дублируется слишком много раз.
Второе условие необходимо, чтобы ограничить количество найденных четких дубликатов. Ведь шингл, встречающийся 1000 раз в документе и в источнике, даст 1000000 пар совпадений. Такие часто повторяющиеся шинглы можно увидеть только в неочищенных документах с попытками обхода.
Очищенный от обходов документ представлен в виде последовательности слов. Приводим слова к нормальной словоформе, затем хешируем их. Получим последовательность целых чисел (на гифке — последовательность букв). Все шинглы этой последовательности хешируются и заносятся в хеш-таблицу с значением позиции начала подстроки. Затем для каждого шингла в документе-кандидате ищутся совпадения в хеш-таблице. Так формируются четкие дубликаты фиксированной длины. Тесты показывают трехкратное ускорение при использовании нового метода в сравнении с суффиксным массивом.
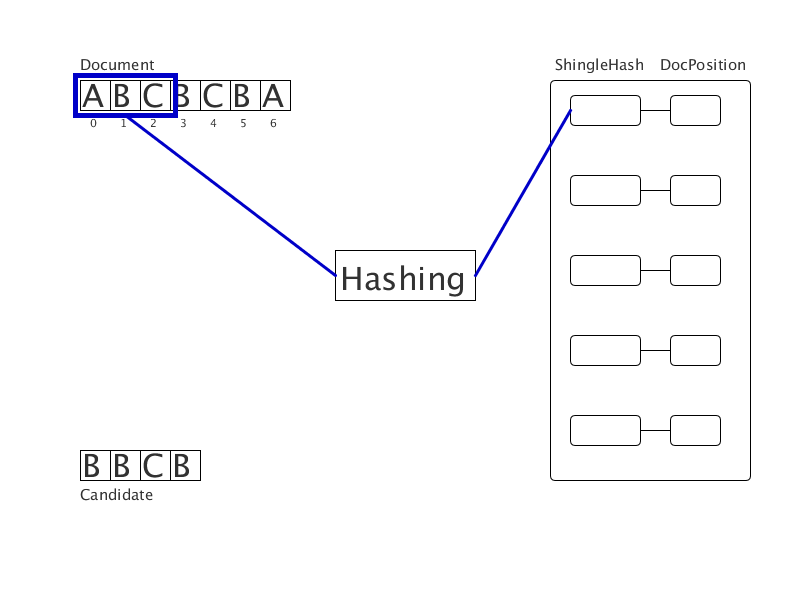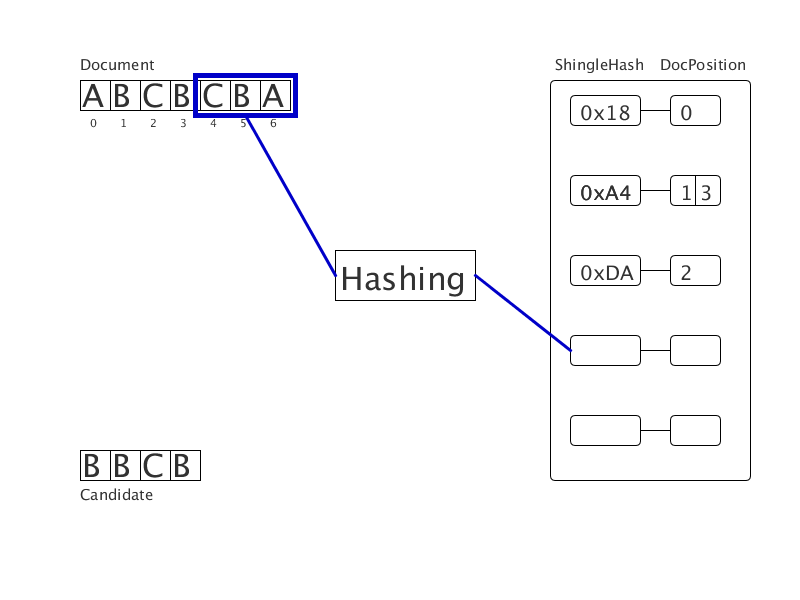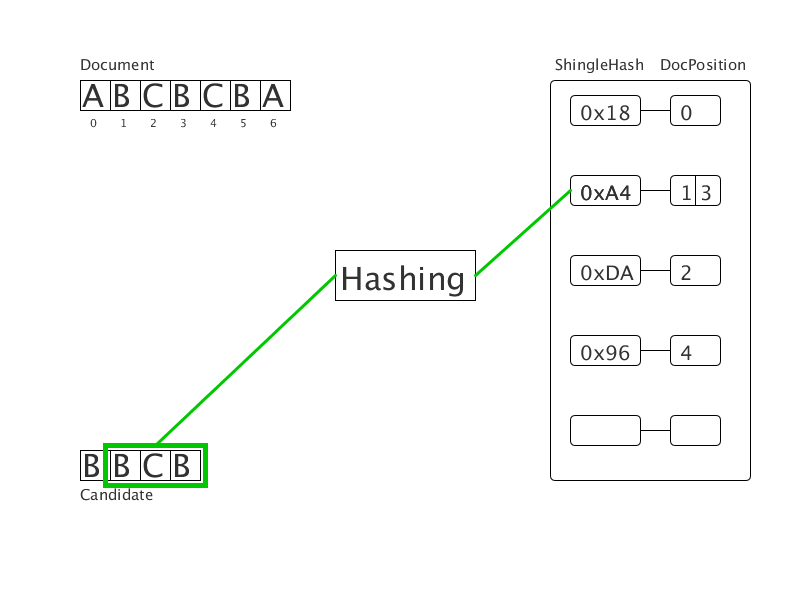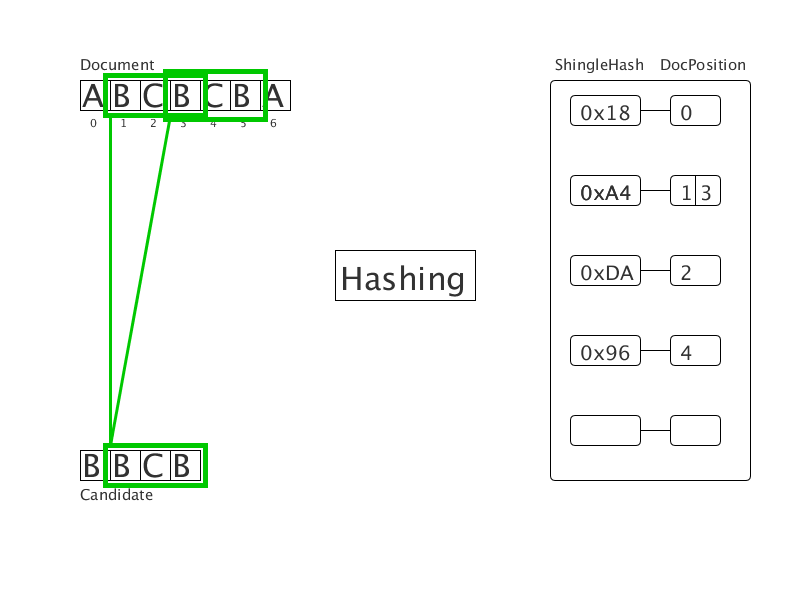
Вычисляем преступника
— Есть еще какие-то моменты, на которые вы посоветовали бы мне обратить внимание?
— На странное поведение собаки в ночь преступления.
— Собаки? Но она никак себя не вела!
— Это-то и странно, — сказал Холмс.
© Артур Конан-Дойль, «Серебряный» (из серии «Записки о Шерлоке Холмсе»)
Итак, Нечеткий Поиск отыскал несколько зацепок, по которым нужно установить преступников. Наш герой использует свои дедуктивные способности на полную катушку, чтобы по крупицам, постепенно восстановить образ преступника по найденным зацепкам. Сыщик постепенно расширяет картину происходящего, дополняя ее новыми деталями, обнаруживая все новые и новые улики, пока эта картина, наконец, не станет полной. Нашего детектива иногда заносит, и его приходится спускать с небес на землю и убеждать, что нам нужна личность преступника, а не биография его двоюродной сестры. Нечеткий Поиск ворчит, но смиренно сужает картину до желаемых масштабов.
Дневник детектива о методике работы. Второй этап

Источник изображения: pixabay.com
Второй этап распространяет дубликаты влево и вправо по документу. Распространение происходит от «центров» — найденных четких дубликатов. Для сравнения суффиксов используем расстояние Левенштейна — минимальное количество удалений/замен/вставок слов, необходимое для приведения одной строки к другой. Дистанцию можно вычислять динамически для суффиксов дубликата, используя алгоритм Вагнера-Фишера, опирающийся на рекурсивное определение расстояния Левенштейна. Однако этот алгоритм квадратичный по сложности и не позволяет контролировать долю ошибок. Еще одной проблемой является точное определение границ дубликатов. Для решения этих вопросов мы применяем несколько прямолинейных, но, тем не менее, эффективных процедур.
На этом шаге предлагается сначала последовательно заполнять Матрицу Расстояний Левенштейна для суффиксов нечеткого дубликата (потом, аналогично, для префиксов). Поскольку мы проверяем суффиксы на «похожесть», нас интересуют только значения вблизи диагонали этой матрицы (Расстояние Левенштейна больше либо равно разности длин строк). Это позволяет добиться линейной сложности. Задав максимально допустимое расстояние Левенштейна, будем заполнять таблицу, пока не встретим столбец со значениями больше допустимых. Такой столбец сигнализирует о том, что наш нечеткий дубликат недавно закончился и слова практически полностью перестали совпадать. Заранее сохранив для каждой заполненной клетки предыдущую оптимальную, спускаемся из клетки с минимальным в критическом столбце штрафом, пока не встретим несколько совпадений, после которых ошибка начала резко расти. Это и будут границы найденного нечеткого дубликата.
Дополнительно, чтобы ошибки не накапливались, вводится процедура, которая сбрасывает число ошибок, начиная распространение заново, если мы наткнулись на «островок» из последовательных совпадений.
Банда преступников
— Завтра с одногруппниками планируем собраться!
— В одного большого одногруппника?
— Что?
© Bashorg
Нечеткому Поиску осталась несложная задачка: объединить преступников, пойманных в одном и том же месте, в банды, оправдать невиновных подозреваемых и собрать полученные результаты воедино.

Источник изображения: pixabay.com
Склейка дубликатов решает сразу 3 проблемы. Во-первых, второй этап «распространение дубликатов» поглощает модификации слов и словосочетаний, но не целых предложений. Если увеличить «способность распространения» алгоритма, то он начнет распространятся по случайно найденным совпадениям и на слишком большое расстояние, а границы дубликатов будут определяться хуже. Так мы потеряем столь важный нам Precision, которым обладал четкий поиск.
Во-вторых, второй этап плохо распознает перестановку двух дубликатов. Хотелось бы, чтобы перестановка двух предложений местами образовывала фразу, близкую к исходной, но для строки из уникальных символов перестановка префикса и суффикса местами приводит к строке, максимально удаленной от исходной (в метрике Левенштейна). Получается, что второй этап при перестановке предложений находит два расположенных рядом дубликата, которые хочется объединить в один.
И третья причина — это Granularity, или Гранулярность. Гранулярность — это метрика, которая определяет усредненное количество найденных дубликатов в одном истинном заимствовании, которое мы обнаружили. Другими словами, гранулярность показывает, насколько хорошо мы находим заимствование целиком вместо нескольких частей, покрывающих его. Формальное определение гранулярности, а также определение микро-усредненной точности и полноты можно посмотреть в статье «An evaluation framework for plagiarism detection».
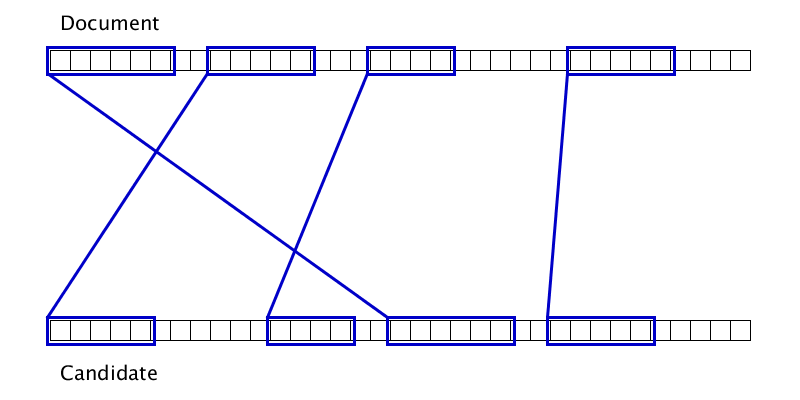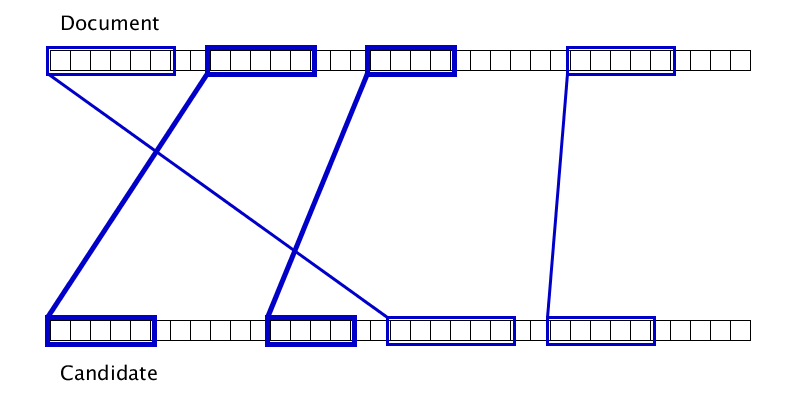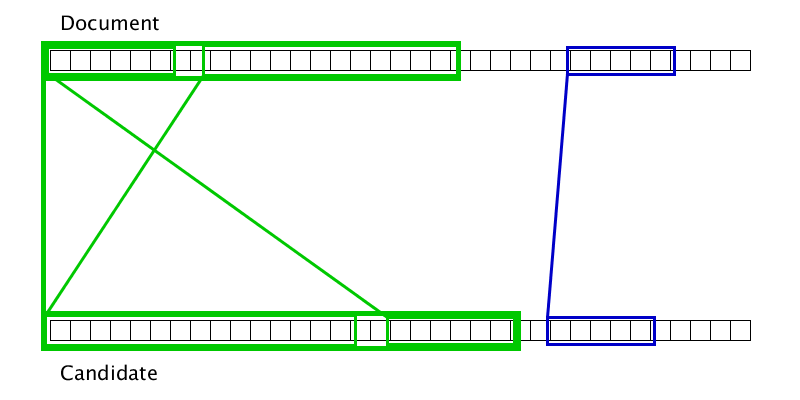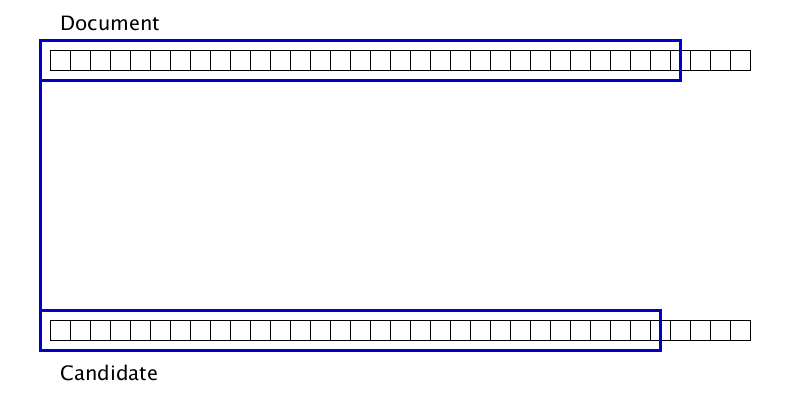
Гифка показывает, что иногда два дубликата можно склеить лишь после того, как один из них приклеится к третьему дубликату. Соответственно, просто одним проходом слева направо по документу полноценную склейку произвести не получится.
Список дубликатов на входе отсортирован по левой границе в документе.
Текущий дубликат пробуем склеить с несколькими ближайшими кандидатами перед ним.
Если получается, пробуем склеить еще раз, если нет — переходим к следующему дубликату.
Поскольку количество дубликатов не больше, чем длина документа, а каждая перепроверка уменьшает количество дубликатов на 1 и выполняется за константное время, то сложность этого алгоритма — O(n).
В качестве правила для склейки дубликатов используется набор нескольких параметров, но, если забыть про микрооптимизации качества, то мы будем склеивать те дубликаты, для которых максимум из расстояний в документе и источнике достаточно мал.
Локальность склейки обеспечивает O(1) дубликатов, к которым можно приклеить текущий дубликат.
Профессиональная подготовка новичка
Детективу необходимо было приспособиться под особенности нашего городка, адаптироваться под местность, прогуляться по неприметным улочкам и узнать получше его жителей. Для этого новичок проходит специальный курс обучения, в котором он изучает схожие ситуации на тренировочном полигоне. Детектив на практике изучает зацепки, дедукцию и построение социальных связей для максимально эффективной поимки преступников.
Параметрическую модель было необходимо оптимизировать. Для определения оптимальных параметров модели использовалась выборка PlagEvalRus.
Выборка разбита на 4 коллекции:
- Generated_Copypast (4250 пар) — дословные сгенерированные заимствования
- Generated_Paraphrased (4250 пар) — слабо и средне-модифицированные заимствования, сгенерированные машиной с помощью зашумления оригинальных отрывков (произвольные замены/удаления/вставки)
- Manually_Paraphrased (713 пар) Написанные вручную тексты с различными типами заимствований, преимущественно слабые и средне-модифицированные заимствования (заменено не более 30% слов в дубликате)
- Manually_Paraphrased 2 (198 пар) Написанные вручную тексты с средне и сильно-модифицированными (более 30% слов) заимствованиями
- DEL — Удаление отдельных слов (до 20%) из исходного предложения.
- ADD — Добавление отдельных слов (до 20%) в исходное предложение.
- LPR — Изменение форм (изменение числа, падежа, формы и времени глагола и т.п.) отдельных слов (до 30%) исходного предложения.
- SHF — Изменение порядка следования слов или частей предложения (оборотов, частей простого предложения в составе сложного) без значительных изменений «внутри» переставляемых частей.
- CCT — Склейка двух или более предложений исходного текста в одно предложение.
- SEP/SSP — Разбиение исходного сложного предложения на два или более самостоятельных предложения (возможно, с изменением порядка их следования в тексте).
- SYN — Замена отдельных слов или отдельных терминов на синонимы (например, «поваренная соль» – «хлорид натрия»), замена аббревиатур на их полные расшифровки и наоборот, раскрытие инициалов ФИО и наоборот, замена имени–отчества на инициалы и т.п.
- HPR — Сильная переработка исходного предложения, которая является комбинацией многих (3–5 и более) типов модификации текста, приведенных выше. Этот же тип предполагает сильное изменение исходного текста путем перифразы с использованием идиоматических выражений, сложных синонимических конструкций, перестановку слов или частей сложного предложения и т.п. приемы, в совокупности затрудняющие определение соответствия между источником-оригиналом и изменённым текстом.
Поиск оптимальных параметров модели мы осуществляли с помощью метода спуска с мультистартом. Максимизировалась -мера с (упор на точность). Приведем здесь наиболее значимые оптимальные параметры.
| Параметр модели | Описание | Manually_Paraphrased (более строгая модель) | Manually_Paraphrased 2 (менее строгая модель) |
|---|---|---|---|
| MinExactCiteLength | Длина четкого дубликата для 1-го этапа | 5 | 3 |
| MinSymbolCiteLength | Минимальная длины итоговой цитаты в символах | 70 | 95 |
| Limit | Максимально допустимое расстояние Левенштейна | 5 | 10 |
| MinExpandLength | Количество совпадение для обнуления штрафа распространения | 2 | 2 |
| GlueDistance | Расстояние в словах для склейки дубликатов | 11 | 29 |
| MinWordLength | Минимальная длины итоговой цитаты в словах | 10 | 11 |
Статистика раскрытых дел
Испытательный срок нашего Нечеткого Поиска подошел к концу. Давайте сравним его продуктивность с продуктивностью другого детектива, Суффиксного Массива. Тренировочный курс Нечеткий Поиск проходил по программе Manually_Paraphrased.

В полевых условиях новичок показал значительное превосходство в доле раскрытых дел. Скорость его работы также не может не радовать. В нашем агентстве не хватало такого ценного сотрудника.
Сравнивая качество модели с суффиксным массивом, заметим значительное улучшение гранулярности, а также более качественное обнаружение средне и сильно-модифицированных заимствований.
| Manually_Paraphrased | Manually_Paraphrased 2 | |
|---|---|---|
| Качество |
|
|
Тестируя на документах размером вплоть до 107 слов, убеждаемся в линейности обоих алгоритмов. На процессоре i5-4460 программа обрабатывает пару «документ-источник» длиной в миллион слов менее чем за секунду.

Сгенерировав тексты с большим числом заимствований, убеждаемся, что нечеткий поиск (синяя линия) не медленнее суффиксного массива (красная линия). Наоборот, суффиксный массив страдает на больших документах от слишком большого количества дубликатов. Мы сравнили быстродействие при минимальной длине дубликата равной 5 словам. Но для достаточного покрытия заимствованиями мы используем четкий поиск с минимальной длиной дубликата равной 3 словам, что на гигантских документах приводит к значительному падению производительности (оранжевая линия). Стоит заметить, что обычные документы содержат меньше заимствований, и на практике этот эффект выражен значительно меньше. Зато такой эксперимент позволяет понять расширение границ применимости моделей новым нечетким поиском.
Примеры:
| Оригинал | Заимствование |
|---|---|
| «За сочетание захватывающих историй с анализом человеческой натуры» в 2014 году он получил заслуженную награду — Национальную медаль США в области искусств | В 2014 году награжден Национальной медалью США в области искусств с формулировкой «за сочетание захватывающих историй с анализом человеческой натуры» |
| складываться культура тоталитаризма, где подавлялось всякое инакомыслие. Для построения социализма были поставлены следующие задачи: ликвидация безграмотности, создание системы высших учебных заведений, подготовку кадров |
Складывается культура тоталитаризма. Всякое инакомыслие подавлялось. Для достижения главной цели построения социализма были пост лены следующие задачи: 1.Культурная революция, включающая ликвидацию безграмотности, создание гигантской системы ВУЗов; НИИ, библиотек, театров, подготовку кадров |
Видно, что алгоритм, несмотря на малую вычислительную сложность, справляется с обнаружением замен/удалений/вставок, а третий шаг позволяет обнаруживать заимствования с перестановкой предложений и их частей.
Эпилог
Нечеткий Поиск работает в команде с другими нашими инструментами: Быстрым Поиском Документов-кандидатов, Извлечением Форматирования Документа, Масштабным Отловом Попыток Обхода. Такая команда позволяет быстро найти потенциальный плагиат. Нечеткий Поиск прижился в этой команде и выполняет свои поисковые функции качественнее, и, что немаловажно, быстрее, чем это делал Суффиксный Массив. Наше агентство будет еще лучше справляться со своими задачами, а недобросовестные авторы столкнутся с новыми проблемами при использовании не оригинального текста.
Творите собственным умом!
Комментарии (45)

alexxisr
31.07.2019 12:24+2Вам бы поиск по документации запилить, чтобы пишешь запрос на своем ламерском, а он выдает книжки где то же самое, но по человечески.
А эти антиплагиаты нормальным людям нужны также как роскопозоры интернету.yury_chekhovich
31.07.2019 12:38Сформулированная задача — поиск пертинентного ответа на нечеткий вопрос на естественном языке — это «поиск философского камня» в информационном поиске. Может быть и у нас получится внести свою скромную лепту ;)
yury_chekhovich
31.07.2019 12:43Что касается нужности/ненужности, то есть очень простой довод. Примерно к 2005 году письменная студенческая работа умерла как жанр — практически все скачивали и сдавали. Про диссертации тоже особо говорить не стоит. Можно было защититься за недорого.
Если решить, что этот жанр в информационную эпоху не нужен, а вместо написания диплома теперь нужно будет спеть, станцевать, художественно прочитать стихи, отлить заготовку или метнуть молот, то никаких проблем — закрываем антиплагиат вместе с необходимостью писать работы. Но пока люди работы пишут, должна быть возможность узнать, а не списывают ли?
Aniro
31.07.2019 13:07+1Проблема в том, что данная программа не способна именно в секторе студенческих работ сделать ничего кроме поиска прямых заимствований. Так-как ученические работы в принципе базируются на общеизвестном и открытом материале — в общем случае невозможно установить — является ли отдельный короткий фрагмент «творчески переработанным» фрагментом другой работы или самостоятельно написан на основании аналогичных источников — факты то должны быть изложены одни и те-же.
Так что за пределами поиска прямых заимствований — продукты антиплагиата чаще всего бесполезны или вредны. В принципе можно легко провести эксперимент который это подтвердит — если дать достаточно большой группе студентов написать ответ на простой и однозначный вопрос — алгоритмы нечеткого поиска найдут у них значительное количество перекрестных заимствований. Вероятно даже прямое цитирование обнаружится.anikeyev Автор
31.07.2019 13:45+1в общем случае невозможно установить — является ли отдельный короткий фрагмент «творчески переработанным» фрагментом другой работы или самостоятельно написан на основании аналогичных источников
Поэтому нечетким поиском мы определяем достаточно длинные фрагменты. И полнота и точность нечеткого поиска на средне-модифицированных заимствованиях превышают 90%, что адекватно задачам алгоритма.
Немного большего качества можно достичь семантическими моделями, но они работают в десятки (а то и сотни) раз медленнее.
yury_chekhovich
31.07.2019 14:36Проводили похожее исследование. Исследовались выпускные школьные сочинения по литературе. Темы у всех простые и однозначные и — это важно — одинаковые. Из источников, только сами произведения. Фактические даже задана структура работы. Введение, три аргумента, заключение. Естественно, учителя следили, чтобы не было общения и списывания. Результат — практически нет совпадений. Только цитаты. Что и требовалось доказать. А студент должен лучше владеть языком лучше чем выпускник школы. Так что финал немного предсказуем.
Aniro
31.07.2019 14:53+1У меня несколько другие сведения. Сам я простой программист и с образованием не связан, меня это только краем задело, когда ребенку в школе работы заворачивали, причем на основании бесплатной версии — определения и наименования длинной в несколько слов она склонна засчитывать в плагиат. Но я вам процитирую немножко цитаты людей с академической средой связанных непосредственно и в чьем владении языком сомневаться отнюдь не приходится:
… особенно когда запрос тебе стоит: перечислите функции органа Х/ механизма Y. Тут как идиот сидишь и десять раз переформулируешь, чтоб под антиплагиат не попасть. И на выходе получается, как в том описании кефирной диеты, мать ее, где кефир на седьмой итерации окрестили «основной питательной жидкостью»
Биология, боль моя, где термин как раз величиной в их шиндл в среднем, там вообще каждый раз удавишься, пока хотя бы 50% оригинала не получишь. Что в технических всяких трудах твориться — и думать не хочу
«Едва успев закончить со штековым будланием бокра, куздра (что немаловажно для нашего исследования, глокая), перешла к курдяченью бокренка»… И вот так мы теперь и пишем...
Т.е. понятно что дело не в инструменте, дело в его применении. Но это применение, в том числе, основано на том как вы свой инструмент позиционируете. Люди хотят снять с себя ответственность и необходимость напрягаться — вы им такую возможность предоставляете. Хорошему преподавателю ваш инструмент не нужен. Учитывая общий уровень дна на котором находиться наше образование — антиплагиат популярен. В странах с иной юридической системой вас бы уже раскатали исками, и заставили написать соответствующие предупреждения.anikeyev Автор
31.07.2019 15:03Статья как раз посвящена алгоритму, который начинает распространяться с шингла длиной в 5, а не 3 слова, как это делает дословный суффиксный массив. Если нечеткий дубликат в итоге оказался коротким он не будет учитываться
Оригинальные технические статьи (к примеру, на Хабре) имеют высокий процент уникального текста, хотя и не затачивались под Антиплагиат.
alexxisr
31.07.2019 13:15+5Если студент способен защитить списанную работу и ответить по ней на все дополнительные вопросы преподователя, то он вполне заслуживает хорошую оценку.
Смысл образования в том чтобы студент получил свои знания, а не в написании уникальных работ.yury_chekhovich
31.07.2019 13:24-1Смысл образования (особенно профессионального) в том, чтобы студент получил не только знания, но и умения и навыки. Одним из таких навыков является способность самостоятельно выполнить работу и изложить ее результаты в письменном виде. Полностью уникальной работа быть не должна — так сейчас и не бывает, но его собственные результаты, должны быть очень четко отделены от того, что сделано другими. А умение проводить такое разделение, также является оцениваемым навыком.
Aniro
31.07.2019 13:42+2При этом продукты антиплагиата позиционируются как готовое решение обнаруживающие именно «плагиат» и оценивающее «качество контента». Конечный пользователь склонен использовать их в соответстветствии с этим. Выдала умная программа 25% оригинальности — и ленивый преподаватель не будет разбираться — зачем ему? Результат — демотивация студента, который потратил на выполнение задания многие часы и знает что работа оригинальная.
anikeyev Автор
31.07.2019 14:53+1Если работа действительно была самостоятельной, Антиплагиат определит значительно больше 25% оригинальности.
Aniro
31.07.2019 15:06А давайте тест. Ответьте на вопрос: «Что такое вектор?»
yury_chekhovich
31.07.2019 15:37Мне кажется, что для темы дипломной (или даже курсовой) работы, это узковато. ;) Хотя, если припрет, несколько страниц текста высокой оригинальности можно написать и здесь.
Aniro
31.07.2019 16:20Так о чем и речь. Написать можно, но возможно — придется налить воды. Нормальный краткий ответ будет определением.
Для проверки дипломной работы или диссертации в общем случае антиплагиат не нужен — приемку осуществляет квалифицированная комиссия и она должна оценивать оригинальность работы опираясь не на объем цитирования. А если её члены так не могут — то их бы стоило лишить ученых званий. В сложившейся практике антиплагиат применяется для проверки рядовых школьных и студенческих работ, и проблема тут не в самом инструменте.yury_chekhovich
31.07.2019 16:40Вы смешиваете. Определения — это одно. Тут важна точность. Дипломная работа — это результат исследования. Это не определения. Работа может быть и краткой, но если мы говорим о работе специалиста или магистра, то в ней должны быть новые результаты. А комиссия просто технически не в состоянии оценить оригинальность — на один диплом у нее 10-15 минут. Поэтому нужен инструмент, который, как и любой другой, нужно использовать с умом.
Кстати, говоря про несколько страниц про вектор, я не собирался лить воду. Это могло быть интересное исследование, основанное на сопоставлении источников с моими собственными выводами. Если бы было на это время. И еще раз подумайте о сочинении. Если человек пишет сам, то текст будет точно оригинальным.Aniro
31.07.2019 16:58Госкомиссии на дипломных и диссертациях и сейчас не используют антиплагиат — зачем он им? Члены комиссии обычно в курсе последних значимых работ по теме и знают весь опорный материал. И если сплагиаченая диссертация проходит комиссию — ну значит кому-то это было надо. Наверное, просто человек уважаемый.
Речь об учебных работах. В которых научной новизны и оригинальности должно быть 0.0%. И на которых антиплагиат регулярно срабатывает даже при полностью ручном написании. В конце концов сколькими разными способами можно изложить одну и ту же мысль? Очень скоро все они окажутся в архивах учебного заведения. Смотрите, первая попавшаяся ссылка:
www.hse.ru/studyspravka/plagiat
К письменным учебным работам (далее – письменные работы) относятся все письменные работы, выполняемые студентами в ходе промежуточной аттестации в соответствии с программой учебной дисциплины, а также в ходе государственной итоговой аттестации. Они включают письменные домашние задания ...
yury_chekhovich
31.07.2019 17:06Госкомиссии на дипломных и диссертациях и сейчас не используют антиплагиат — зачем он им?
Неправда ваша, дяденька Биденко ;)
Используют, потому что обязаны. Есть соответствующая нормативка от правительства и министерства и каждый вуз принял у себя необходимые локальные акты. Если нужно дам ссылки на соответствующие документы.
Членам комиссии знать весь опорный материал не возможно. В индексе АП только из области экономики десятки миллионов разных документов (не дубликатов).
Посмотрите здесь: habr.com/ru/company/antiplagiat/blog/413361Aniro
31.07.2019 17:11Ок, соглашусь, не был в курсе. Скоро вообще комиссии разгоним, пусть нейросети принимают. Соглашусь даже с тем что в области диссертаций от антиплагиата возможно есть польза.
Но. Вы действительно считаете возможным применение антиплагиата для проверки домашних заданий? За исключением сочинений и эссе — там по опыту действительно все нормально.yury_chekhovich
31.07.2019 17:12Можно проверять домашние задания только очень ограниченных видов. В остальных случаях — будет полная глупость.
Aniro
31.07.2019 17:17+1О. Ура. Мы поняли друг-друга. Теперь осталось это идею донести до учебных заведений, у которых прямо в руководящих документах написано применять антиплагиат к домашним работам, я выше привел типичный вариант.
yury_chekhovich
31.07.2019 17:19О! Сколько же до них всего нужно донести. Я встречаюсь с представителями не менее чем 100 вузов ежегодно и чувствую, что и этого не хватает.
Sabubu
01.08.2019 10:04+1Студенческие работы придуманы, чтобы облегчить труд преподавателя. Ему платят фиксированную сумму за проверку работ; следовательно в его интересах минимизировать свое затрачиваемое время, чтобы получить максимальную почасовую оплату. Они делают это, задавая студентам сделать работу, которую они пролистают по диагонали за минуту (проверяя наличие ключевых слов в заголовках).
С точки зрения студента стратегии получаются такие:
если у вас есть тема, которая вас интересует, уговариваете преподавателя дать вам ее, всерьез изучаете тему, делаете хорошую работу, которую он все равно не прочтет, вывешиваете на сайт, ссылку кидаете на хабр
для получения моего критического комментария. Получаете знания, известность и материал для привлечения внимания топовых работодателей.
Ну вот например, какой-то чувак сделал работу про анализ регулярных выражений, и по ней сразу понятно, что он умный и его надо брать: https://swtch.com/~rsc/regexp/regexp1.html. Этот чувак наверно умнее любого кандидата, с которым вы столкнетесь на среднестатистическом собеседовании в среднестатистическую компанию.
если вам неинтересно, копируете работу с Интернета, меняете слова в заголовках, печатаете и с невозмутимым видом сдаете. У препода нет времени сканировать ее и загонять в антиплагиат, да и даже если она скопирована, а у вас нет времени на формальные задания.
Там ниже еще пишут про серьезные работы, диссертации и проч. Ну а где гарантия, что у преподавателей к ним не такое же отношение? Может, преподаватели думают "вы делаете вид, что платите, мы делаем вид, что проверяем работы". А может там просто сидят выгоревшие люди, которые ничего другого делать не умеют и которым больше некуда пойти. Когда я учился, у меня были преподаватели, которые бубнили лекции по бумажке.
А этот сервис, я думаю, больше для сео-шников. Как известно, поисковики ценят уникальный (по мнению их робота) контент, потому для поднятия сайта надо размещать на нем больше приятных роботу статей. При заказе таких статей надо проверять, чтобы тебе фрилансер-лентяй не подсунул копипасту. Отсюда и все эти фильтры для отлова перефразированных предложений.
P.S. Хотел из любопытства загрузить свои комментарии и флуд с других ресурсов для проверки на уникальность (я уверен, что он уникален на 100%), но без регистрации нельзя воспользоваться системой, так что отказался от этой идеи.
yury_chekhovich
01.08.2019 11:421. Все-таки в нормальных вузах выбор темы диплома — является совместным творчеством научрука и студента. Если не так, то следует задуматься о нормальности вуза.
2. Даже если тема студенту неинтересна, то это не повод читерствовать при подготовке диплома. На работе тоже вкусные задачи прилетают не каждый день, но работодатель не поймет, если сотрудник будет халтурить. В общем не так все однозначно.
3. Диплом — это квалификационная работа. Подтверждается квалификацию студента по умению провести исследование на заданную (пусть и не очень интересную ему тему). Если такого умения нет (работа списана), значит квалификация отсутствует.
4. Проверил ваш коммент. Результат пока нулевой. Так что все ок — писали сами. :) Через некоторое время будет находиться адрес этой страницы на habr.Aniro
01.08.2019 12:10С нулевыми результатами (по крайней мере в бесплатной версии) сейчас крайне интересно — взял статью про блоху с английской версии википедии, прогнал через гугл-транслэйт, скормил антиплагиату — 100% оригинальности. Выглядит как лайфхак.
yury_chekhovich
01.08.2019 12:33статью про блоху с английской версии википедии, прогнал через гугл-транслэйт, скормил антиплагиату — 100% оригинальности.
Проверяли бесплатным сервисом? Там нет поиска переводных заимствований, поэтому результат предсказуем.
WinPooh73
31.07.2019 12:31+1Артур Конан-Дойль, «Серебрянный» (из серии «Записки о Шерлоке Холмсе»)
Стеклянный, оловянный деревянный. Здесь "н" двойное.
В остальных прилагательных — одинарное. Серебряный.
Сорри, что не в личку — не нашёл ссылку в мобильном интерфейсе.

arozhankov
31.07.2019 13:51Наши законотворцы не планируют использовать подобные системы? А то встречается огромное кол-во ворованного текста, немного переделанного рерайтерами. Сделать ничего с ними нельзя, т.к. с точки зрения закона — новый текст не похож на оригинальный. Однако затраты на рерайтера в сотни раз меньше, чем затраты на авторов оригинального текста.
yury_chekhovich
31.07.2019 14:22-1Мы готовим инструмент. Использовать может каждый. Как говорится, можно привести коня к водопою, но заставить его пить…
.arozhankov
31.07.2019 14:34Спасибо за ответ. На Хабре последнее время повышенное напряжение у аудитории. Минусуют как на развлекательных ресурсах без высказываний и обсуждений.

amarao
31.07.2019 15:48+2Во всей этой истории с диссертациями у меня ощущение, что идёт борьба за формальный признак (оригинальность) при этом куда-то исчезает суть.
В чём суть диссертации? Это же не курсовая работа, в которой ученик должен показать знания. Это же научная работа, которая нетривиально новая. Не "отсутствуют заимствования", а нетривиально новая научная работа. Как мне кажется, вместо упора на "нетривиально новая" лучше фокусироваться на "научная работа".
Вот если я нетривиальным новым образом натыкаю рандомных кнопок и отформатирую шрифтами по ГОСТу — это будет научная работа? Эм...
yury_chekhovich
31.07.2019 16:42Согласен, что суть существенно важнее. Но что делать, когда в стране защищены тысячи диссертаций, в которых практически нет оригинального текста? Оригинальность не самоцель. Но ее отсутствие — это верный признак проблем.
amarao
31.07.2019 16:49У этих диссертаций отсутствие оригинального текста — это главная проблема? Неужели все они были научными работами?
… каков критерий научности работы для средней руки историка-политолога, напомните? Отсутствие заимствований — и пусть развернётся фантазия на 100500 кнопок?
yury_chekhovich
31.07.2019 16:56Еще раз: неоригинальный текст — это не критерий, это признак. Прочитать больше 30 тысяч диссертаций в год (столько защищалось работ во второй половине нулевых) никто не в состоянии. А для того, чтобы с вполне приличным качеством исследовать их на на заимствования нужно несколько часов машинного времени. Дальше начинайте разбираться с содержанием начиная с топовых по доле заимствованного текста. Это будет погружение в ад. ;) Их уже должны были прочитать несколько человек, но очевидно этого никто не сделал. За что степень?
Просто когда нет проверки на заимствования, то очевидно защищается всякий мусор. Сейчас этот путь уже закрыт. Да открыты другие (перечислять не буду), но это не значит, что закрывание самого просто бесполезно.
anikeyev Автор
31.07.2019 17:01Для проверки научности работы и квалификации выпускника или ученого существуют другие, не менее важные процессы: защиты, комиссии, экзамены, преподавательские и экспертные оценки. Тем не менее, проблема списывания одна из самых популярных. Мы предоставляем сопутствующий этим процессам инструмент, чтобы упростить оценку в случаях, когда работа должна быть самостоятельной.
amarao
31.07.2019 17:12+1А как вы можете доказать, что у вас низкий уровень ложно-положительных срабатываний?
Я бы вот не отказался от анализа работ, за которые давали нобелевки. Желательно, без предварительного файн-тюнинга вашего алгоритма под этот "специальный" случай.
anikeyev Автор
31.07.2019 17:45+1
Последняя опубликованная работа лауреата Новоселова. У нас нет размеченного корпуса с работами Нобелевских лауреатов, но после прогона на различных тестовых корпусах, не использованных в обучении, микро-усредненная точность была в пределах 85-95% для сильно модифицированных заимствований и 98% для слабо-модифицированных.amarao
31.07.2019 18:03Это один из примеров. С другой стороны, если бы его работу завернули за "заимствования" в объёме 1.5%, то кому было бы обидно?

imanushin
01.08.2019 11:14+1Подскажите, пожалуйста, а как в работе можно явно выделить заимствование (чтобы читатель не думал, что это часть исследования, а антиплагиат игнорировал блок, так как автор подтвердил цитирование)?
Например, фразами вида "по мнению ХХХХ из работы QQQQ, термин PPPP означает GGGG" автор осознанно добавляет в свою статью заимствованный блок, так что вроде как нет смысла запрещать/ограничивать подобное.

Rikkitik
03.08.2019 16:07Чувствую, скоро «Антиплагиат» будет комментировать документы на уровне: «Автор явно читал книгу ххх и статью ууу, но не указал их в списке литературы».
Aniro
Приведенные в качестве примеров фрагменты не являются плагиатом — по крайней мере первый точно. Это просто та-же самая информация изложенная на том же самом языке.
Ещё лучшего результата можно достичь если построить семантические деревья для текстов и их сравнить. Только вот к плагиату это будет иметь крайне опосредованное отношение, особенно когда речь идет не об оригинальном исследовании а о перечислении общеизвестных фактов.
anikeyev Автор
Вы правы, первый пример не является плагиатом. Но он также и не является оригинальным текстом: этот факт явно заимствован из некоторого источника. Не любое заимствование является плагиатом, поэтому так важна проверка отчета экспертом.