В процессе изучения нейронных сетей возникла мысль, как бы применить их для чего-то практически интересного, и не столь заезженного и тривиального, как готовые датасеты от MNIST. Например, почему бы не распознавать азбуку Морзе.

Сказано, сделано. Для тех кому интересно, как с нуля создать работающий декодер CW, подробности под катом.
Для начала отвечу на вопрос, а собственно почему нейросеть. Во-первых, просто из интереса, проект скорее учебный, а не коммерческий, во-вторых, реальный сигнал при прохождении в атмосфере достаточно сильно искажается, и на выходе получается далеко не совсем то, что на картинке из точек и тире. Вот для примера реальные огибающие одной и той же буквы «C», записанные с эфира:
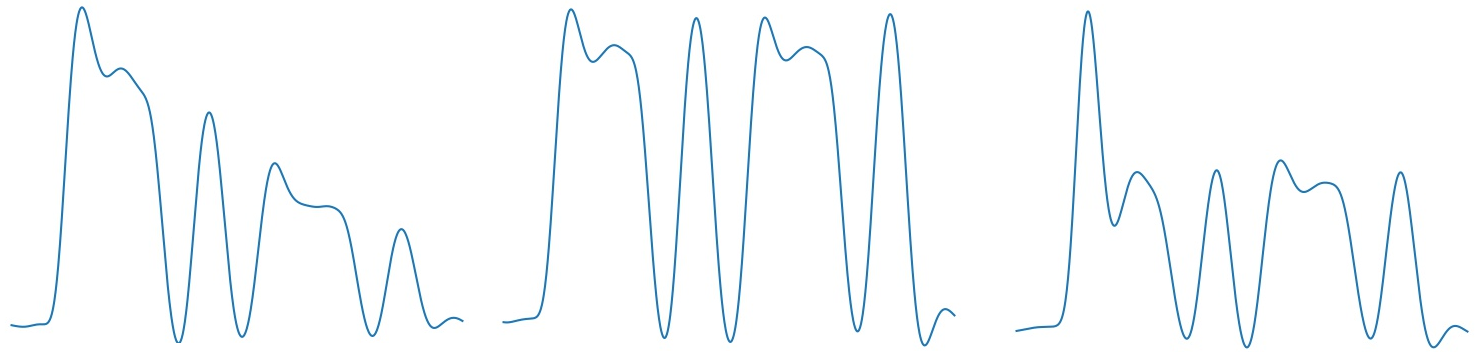
И это еще за образец взят довольно сильный сигнал, а на слабом может быть вообще что угодно. В общем, для таких вот нечетких данных нейросети как раз достаточно интересны и перспективны. Пока что программ, распознающих азбуку Морзе лучше профессионального радиста среди свистов, шумов и помех, насколько мне известно, не существует, и я на 95% уверен, что если такая и появится, то там будут использоваться подходы AI.
Повторить описанные ниже эксперименты может любой, для этого даже не нужно иметь радиоприемник. Все исходные файлы были записаны через websdr, где легко можно услышать радиолюбителей, например на частотах 7 и 14МГц. Там же есть кнопка Record, с помощью которой любой сигнал можно записать в формате wav.
Выделение сигнала из записи
Чтобы нейросеть могла распознать символы азбуки Морзе, сначала их надо выделить из исходной записи.
Загрузим данные из wav-файла и выведем его на экран.
from scipy.io import wavfile
import matplotlib.pyplot as plt
file_name = "websdr_recording_2019-08-17T16_26_52Z_14026.0kHz.wav"
fs, data = wavfile.read(file_name)
plt.plot(data)
plt.show()Если все было сделано правильно, мы увидим что-то типа такого:
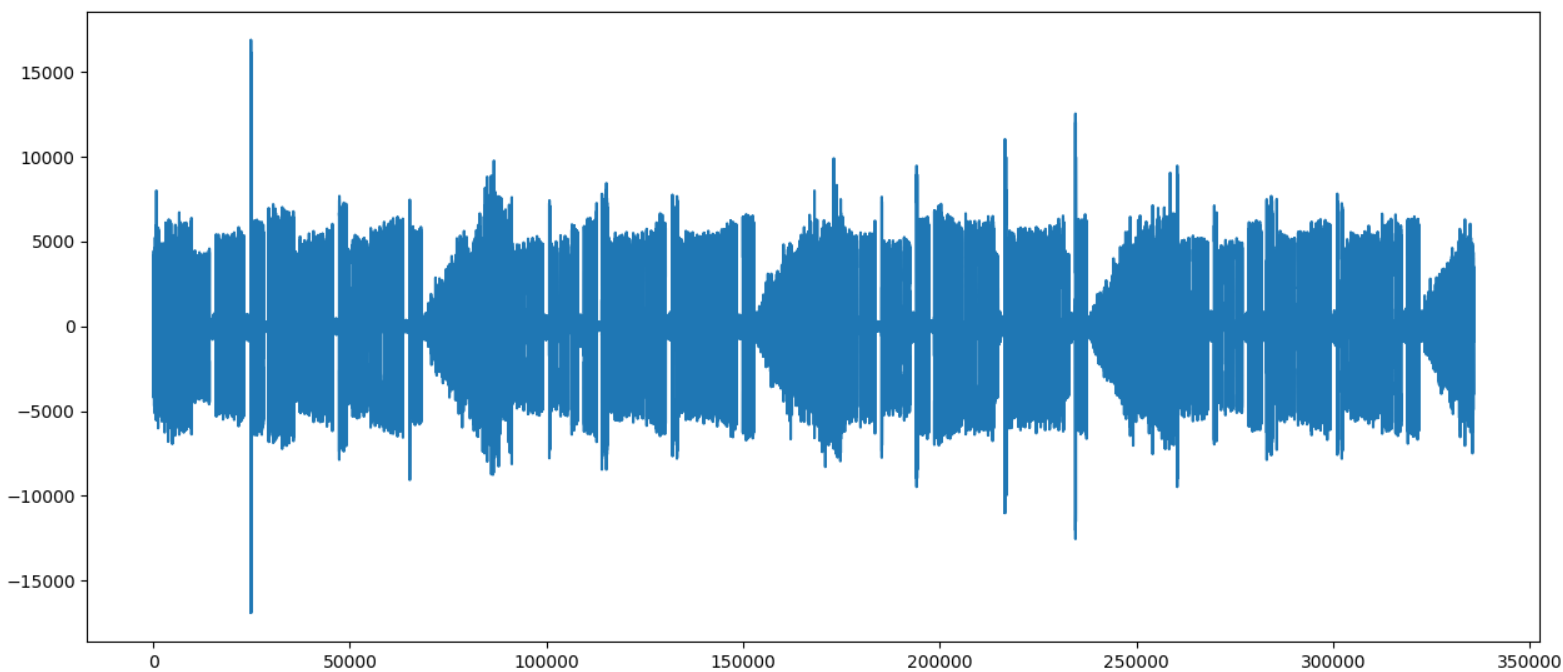
Исторически, сигнал азбуки Морзе это простейший вид модуляции, которую можно придумать — тон либо есть, либо его нет. Поэтому в записи может быть одновременно несколько сигналов, и они не мешают друг другу.

При записи сигналов CW я устанавливал частоту на 1КГц ниже и режим верхней боковой полосы (Upper Side Band), так что интересующий нас сигнал всегда находится в записи на частоте 1КГц. Выделим его с помощью полосового фильтра (фильтр Баттерворта).
from scipy.signal import butter, lfilter, hilbert
def butter_bandpass(lowcut, highcut, fs, order=5):
nyq = 0.5 * fs
low = lowcut / nyq
high = highcut / nyq
b, a = butter(order, [low, high], btype='band')
return b, a
def butter_bandpass_filter(data, lowcut, highcut, fs, order=5):
b, a = butter_bandpass(lowcut, highcut, fs, order)
y = lfilter(b, a, data)
return y
cw_freq = 1000
cw_width_hz = 50
data_filtered = butter_bandpass_filter(data, cw_freq - cw_width_hz, cw_freq + cw_width_hz, fs, order=5)
К получившемуся сигналу применяем преобразование Гильберта чтобы получить огибающую.
def hilbert_envelope(data):
analytical_signal = hilbert(data)
amplitude_envelope = np.abs(analytical_signal)
return amplitude_envelope
y_env = hilbert_envelope(data_filtered)
В результате получаем вполне узнаваемый сигнал кода Морзе:
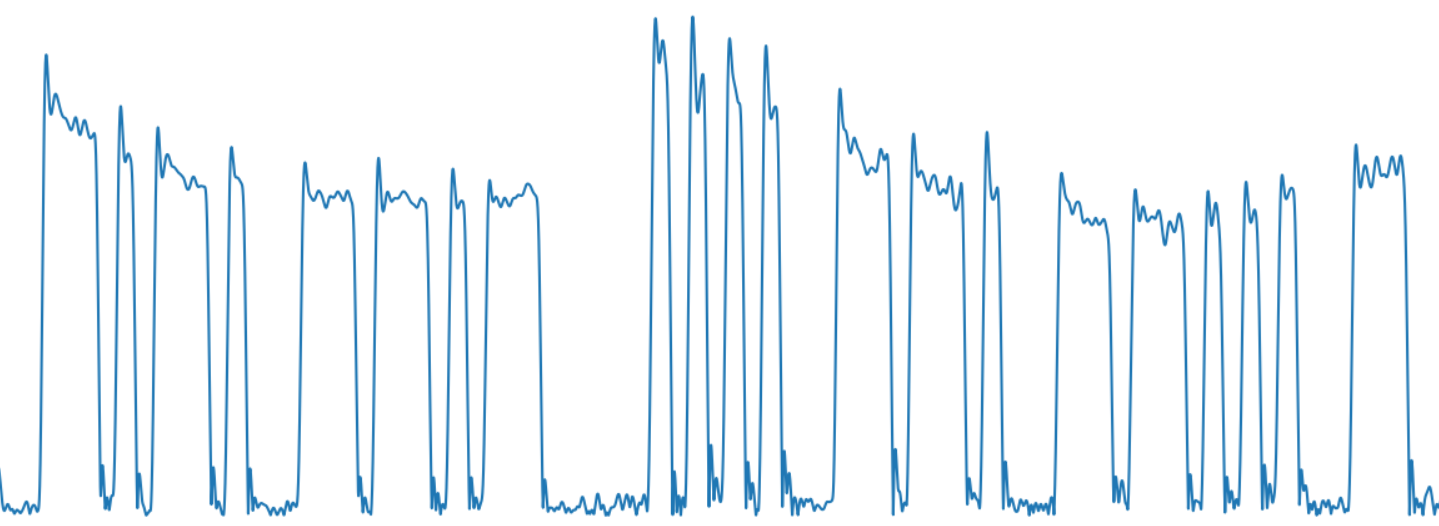
Следующей задачей является выделение отдельных символов. Сложность тут в том, что сигналы могут быть разного уровня — как видно на картинке, из-за особенностей распространения в атмосфере, уровень сигнала «плавает», он может затухнуть и усилиться вновь. Так что просто обрезать данные по некоторому уровню было бы недостаточно. Используем moving average («скользящее среднее») и фильтр низких частот чтобы получить сильно сглаженное текущее среднее значение сигнала.
def moving_average(a, n=3):
ret = np.cumsum(a, dtype=float)
ret[n:] = ret[n:] - ret[:-n]
return ret[n - 1:] / n
def butter_lowpass_filter(data, cutOff, fs, order=5):
b, a = butter_lowpass(cutOff, fs, order=order)
y = lfilter(b, a, data)
return y
ma_size = 5000
y_env2 = y_env # butter_lowpass_filter(y_env, 20, fs)
y_ma = moving_average(y_env2, n=ma_size) # butter_lowpass_filter(y_env, 1, fs)
y_ma2 = butter_lowpass_filter(y_ma, 2, fs)
# Enlarge array from right to the original size
y_ma3 = np.pad(y_ma2, (0, ma_size-1), 'mean')
Как можно видеть из картинки, результат вполне адекватный изменению сигнала:
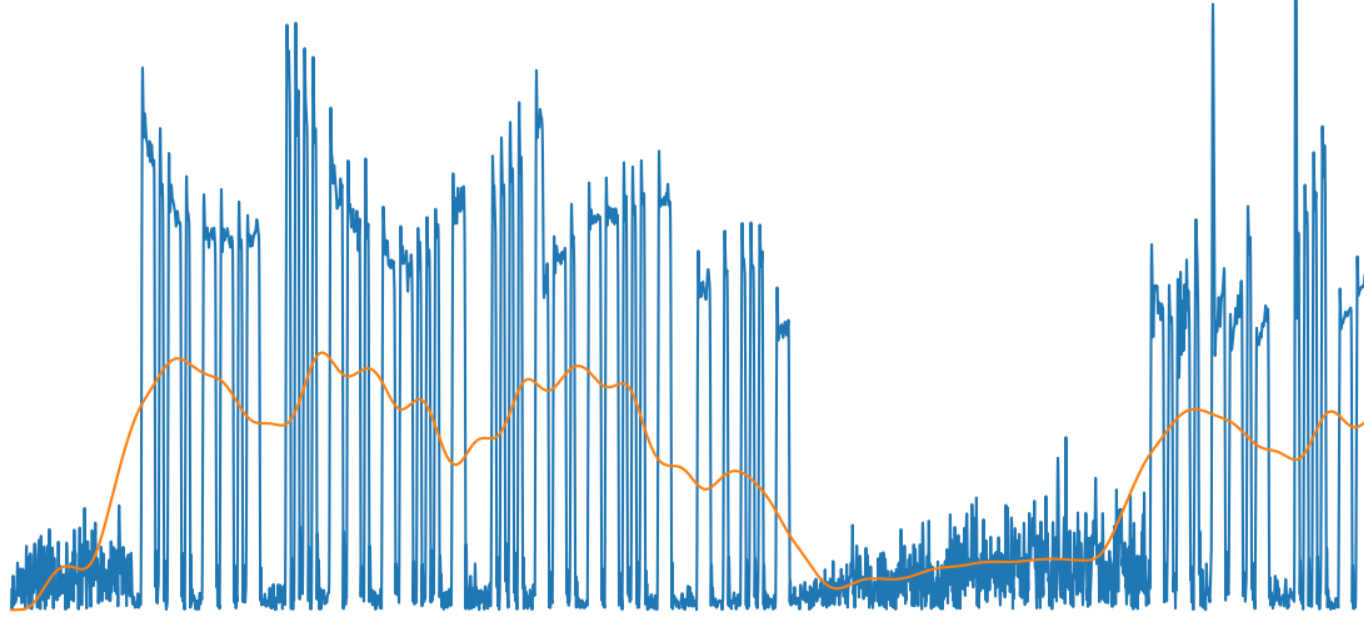
И наконец, последнее: получим битовый массив, показывающий наличие или отсутствие сигнала — считаем сигнал «единицей», если его уровень выше среднего.
y_normalized = y_ma3 < y_env2
y_normalized2 = y_normalized.astype("int16")
Мы перешли от шумного и неодинакового по уровню входного сигнала к заметно более удобному для обработки сигналу цифровому.
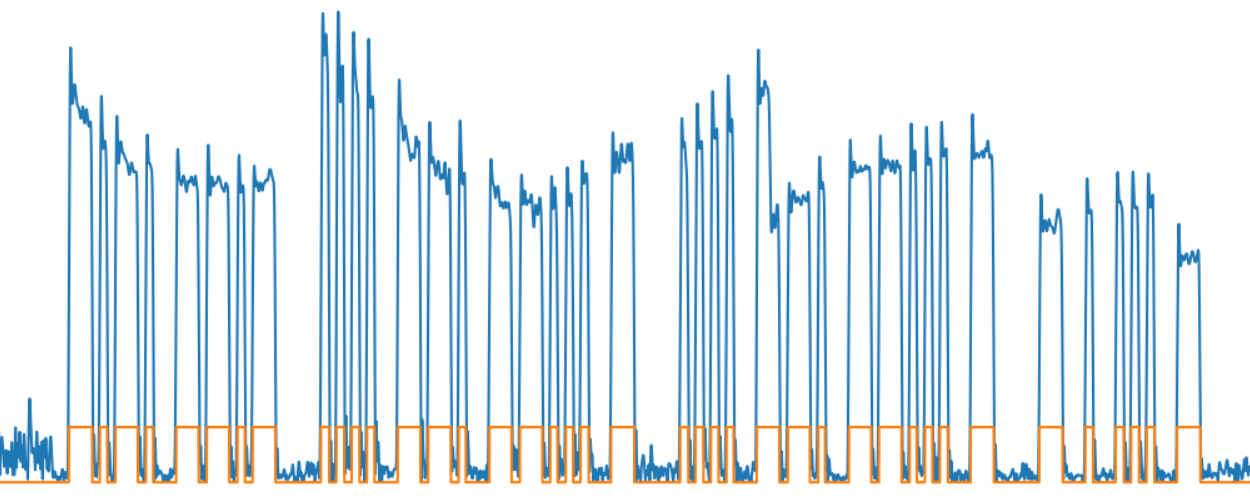
Выделение символов
Следующая задача — выделить отдельные символы, для этого нужно знать скорость передачи. Существуют определенные правила соотношения длительности точек, тире и пауз в азбуке Морзе (подробнее тут), для упрощения я просто задаю длительность минимальной паузы в миллисекундах. Вообще, скорость может варьироваться даже в пределах одной записи (в радиопередаче участвуют минимум два абонента, настройки передатчиков которых могут отличаться). Скорость также может сильно отличаться для разных записей — опытный радист может передавать в 2-3 раза быстрее, чем начинающий.
Дальше все просто, код не претендует на красоту и изящество, но вполне работает. Выделяем подъем и спад сигналов, и в зависимости от длины, разделяем слова и символы.
min_len = 0.05
symbols = []
pos_start, pos_end, sym_start = -1, -1, -1
data_mask = np.zeros_like(y_env2) # For debugging
pause_min = int(min_len*fs)
sym_min, sym_max = 0, 10*min_len
margin = int(min_len*fs)
for p in range(len(y_normalized2) - 1):
if y_normalized2[p] < 0.5 and y_normalized2[p+1] > 0.5:
# Signal rize
pause_len = p - pos_end
if pause_len > pause_min:
# Save previous symbol if exist
if sym_start != -1 and pos_end != -1:
sym_len = (pos_end - pos_start)/fs
if sym_len > sym_min and sym_len < sym_max:
# print("Code found: %d - %d, %fs" % (sym_start, pos_end, (pos_end - pos_start) / fs))
data_out = y_env2[sym_start - margin:pos_end + margin]
symbols.append(data_out)
data_mask[sym_start:pos_end] = 1
# Add empty symbol at the word end
if pause_len > 3*pause_min:
symbols.append(np.array([]))
data_mask[pos_end:p] = 0.4
# New symbol started
sym_start = p
pos_start = p
if y_normalized2[p] > 0.5 and y_normalized2[p+1] < 0.5:
# Signal fall
pos_end = p
Это временное решение, т.к. в идеале скорость нужно определять динамически.
На картинке зеленой линией показана огибающая выделенных символов и слов.

В результате работы программы мы получаем список, каждый элемент которого представляет собой отдельный символ, выглядит это примерно так.

Эти данные уже вполне достаточны, чтобы обрабатывать и распознавать их нейросетью.
Текст получается достаточно длинным, так что продолжение (оно же окончание) во второй части.
Комментарии (45)

MihhaCF
18.08.2019 23:14Тема с морзянкой, конечно, не нова и кто как ее только не декодировал, но как разминка для ума — очень интересно. Жду продолжение с реализацией нейросети))

PansOfLuck
18.08.2019 23:14забивание гвоздей микроскопом
DmitrySpb79 Автор
18.08.2019 23:30+1Вы примерно представляете, насколько сигнал искажается в атмосфере, да еще принимается на фоне помех, свистов и шумов?
Пока что программы, принимающей CW лучше профессионального радиста, никто не написал.GokenTanmay
19.08.2019 08:54Статья классная. Для разминки и как упражнение — задача хорошая.
НО мне кажется, что если сделать сеть энкодер-декодер и в «разрыв» поставить радиосвязь, то можно добиться большей плотности данных и меньшей ошибки при распознавании.
Да, мы теряем преимущество «человекочитаемости» сигнала, НО раз мы уж применяем технику которая умеет «в нейросетки», то почему бы не постараться выжать из них максимум, а морзянку выучить самому и оставить на экстренный случай?
Статья отличная, очень жду продолжения.

extempl
19.08.2019 10:45Пока неясно, что у вас будет во второй части, но в первой вы вроде как выделили отдельные символы. Соответственно, кое-как решив проблему шумов и различных перекрытий сигналов. То есть, тут даже выводы сложно сделать. Вот если бы вы скормили сетке исходный аудиофайл, научили её по корректным результатам — это другое. Вообще, кмк, именно эта часть (описанная в этой статье) уже должна быть давно покрыта и оттестирована.
P.S. Кажется, я опоздал с этим мнением, комментариев, эдак, на 10. Мы все тут ожидали выделение символов нейросетью.

proninyaroslav
19.08.2019 18:43+1И нет никакого алгоритмического решения? Как же тогда раньше для обработки сигналов обходились без нейронок то…

nikolay_karelin
19.08.2019 06:40Есть довольно большое исследовательское направление по декодированию сигналов из оптоволокна нейросетями. Насколько я в курсе — там все серьезно, ибо нелинейные искажения давить сложновато.
funnycar
18.08.2019 23:33Наша часть стояла в глухом лесу, летом вместо тонового сигнала доходили только помехи и по изменениям громкости помех иногда с первого раза без ошибок принимали радиограммы. Возможен ли приём радиограммы вашей программой сильно зашумлённого сигнала?
DmitrySpb79 Автор
19.08.2019 00:03При таком входном сигнале, как вы описываете, нет, не сработает :) Хотя теоретически прием слабых сигналов возможен, но тут нужны большие объемы данных для обработки и более хитрые алгоритмы выделения отдельных символов, в рамках одной страницы кода такое не сделать.

Aspos
19.08.2019 02:55Веселей было бы не выделять символы, а сырой сигнал подавать в нейросеть.
И ожидать от сети не буквы, а текст.
Человек же слышит «сырой» звук до обработки и чётко выделяет из неё морзянку.
В комбинации букв тоже есть некоторая информация которая могла бы помочь дискриминировать сырой сигнал. В слове «ИНФОРМАЦИЦ» последняя буква не может быть «Ц».
makser1
19.08.2019 07:32Есть не большой момент по детектированию сигнала (несущей) на практике.
Метод определять по превышению над средним скользящим имеет недостатки:
При большой скорости передачи и наоборот при низкой будут ложные срабатывания, так как среднее сравняется с амплитудой несущей.
Я в своем проекте использовал сравнение с амплитудой сигналов по бокам (вычислялись алгоритмом Гёрцеля). Но надежным назвать нельзя.
Вообще приходила мысль как то воспользоваться нейросетью для выделения несущей из помех.

emmibox
19.08.2019 08:56И наконец, последнее: получим битовый массив, показывающий наличие или отсутствие сигнала — считаем сигнал «единицей», если его уровень выше среднего.
Мы перешли от шумного и неодинакового по уровню входного сигнала к заметно более удобному для обработки сигналу цифровому.

DmitrySpb79 Автор
19.08.2019 10:46Такой шум отсекается просто, при проверке на длительность импульса. Некоторые символы все же попадают, они отсекаются на этапе распознавания.
emmibox
20.08.2019 11:15«по длине импульса» после определенного SNR отсекаются и полезные символы… А потом рассказываются истории про то, что люди прекрасно слышут морзянку а софтовые реалиации ажно с нейросетями (на самом деле из палок) — нет…
DmitrySpb79 Автор
20.08.2019 11:47Да, такой подход не сработает если уровень сигнала ниже уровня шумов.
Непонятна странная тональность подобных вопросов для учебного примера. Я что, пытаюсь этот код продать кому-то или где-то заявлял что написал лучший в мире декодер?emmibox
20.08.2019 13:43А чему вы хотите научить вырезав кусок из картинки который вам не нравится?
Вы уже написали про использование нейросети — и эта нейросеть в вашей голове…DmitrySpb79 Автор
20.08.2019 14:34Еще раз
для тех кто в танке— так как скорость передачи символов известна, то высокочастотный шум этим отсекается, «вручную» никакие картинки не подгонялись и не обрезались.emmibox
20.08.2019 15:11С какого праздника в морзянке известна скорость? Она произвольная. Частота тоже. Подайте на вход вашей «учебной лабуды» пилот с белым шумом с SNR=0.5 — и что вы там после этого будете отсекать с методами опирающимися на амплитуду сигнала? И чему вы хотите кого то научить цепляясь за параметры которые не имеют никакого значения в тепличных условиях?
Картинка где вы перешли от аналога к цифре обрезанная половина той, что перед ней!DmitrySpb79 Автор
20.08.2019 15:48Вы торопитесь. Первая часть (эта) это получение датасета отдельных букв морзе из исходных записей. Вторая часть это собственно создание и обучение нейросети. Третья часть (которая в принципе и не планировалась для учебного проекта) это определение скорости, частоты передачи и прочие плюшки.
Впрочем, второй части судя по всему не будет тоже, т.к. это мало кому здесь интересно.makser1
21.08.2019 13:39Жаль, думаю многим было бы интересно.
Просто тут многие поначалу думали, что будет выделение из шума с помощью нейросети.
Но и тема декодирования тоже как пример использования нейросети интересен.DmitrySpb79 Автор
21.08.2019 14:30Код будет выложен на github, ссылку в статье я обновлю, так что кто захочет, сможет протестировать.
Это уже вторая моя попытка написать что-либо про нейросети на хабре, и судя по количеству просмотров/лайков/ответов по теме, кпд процесса стремится к нулю. Думаю что тонкости нейросетей аудитории здесь малоинтересны.
emmibox
22.08.2019 11:16Морзянка — 100% формализуемый на каждом отрезке разбора алгоритм с явно заданными и четко определенными критериями. Нейросеть там всунуть в принципе не куда. Нет конечно если ее за уши притянуть — то выяснится, что с ней алгоритм работает ЗНАЧИТЕЛЬНО ХУЖЕ чем без нее! Как всегда собственно и бывает в 100% формализуемых алгоритмах.

Alyoshka1976
19.08.2019 09:21Интересный подход! Я пытался декодировать морзянку, просто анализируя уровни — результат посредственный. Но я заметил, что факт передачи надежно (на фоне шумов) отмечается указателем уровня на WebSDR сайте. Осталость только до него добраться :-) Еще более интересным было бы автодекодирование морзянки на сверхдлинных волнах, там предварительно потребуется спектральный анализ выполнить. Но тут надо быть осторожным, а то это можно при сильном желании и под OSINT подвести :-)
svanichkin
19.08.2019 09:53после того как получены символы, распознать их с ИИ не нужно… Достаточно простого алгоритма ) Вся сложность как раз в получении из аудиосигнала (особенно зашумленного) точек и тире.
Sensimilla
19.08.2019 10:20+1По-хорошему, нейронную сеть надо применять для обучения распознаванию необработанных сырых сигналов, только в этом случае во всей этой затее будет смысл. И такая задача будет похожа на задачу распознавания речи
Pafnutyi
19.08.2019 12:30А где в статье нейронная сеть? Фильтры вижу, код на основе анализа первой посылки вижу, по результату в конце статьи сигнал уже декодирован, и собственно нейронная сеть дальше уже не особо и нужна. Автоматичесикий приём имеет смысл если идёт накопление сигнала, для телеграфа это варианты вида OPERA, WSPR и тп. Вот если бы нейронка могла SSB голос привести в нормальный вид, а то вроде кто-то бубунит в канале и даже некоторые слова разбираются, но такой напряг что нафиг неохота. И с другой стороны если морзянку слышно, её и на слух декодировать небольшой подвиг ;)
ЗЫ. По поводу радистов: пытал скиммеры(автоматические приёмники морзянки) своей ковырялкой, как ни изгалялся и ритм сбивал и мощность убавлял — принимают, хоть что делай. Так что есть программы принимающие лучше радистов, только ими(исходниками) никто не делится ;)

DarkByte
19.08.2019 19:44+1CW Skimmer совершенно никак не распознаёт слабые сигналы, которые ухом слышны и на водопаде видны. Ему нужен очень громкий и чёткий сигнал, и желательно, чтобы он ещё передавался железкой, а не дрожащей рукой. Впрочем остальные подобные программы делают это ещё хуже.
Astroscope
19.08.2019 22:42Да. Это не умаляет заслуг авторов и полезности программы для спортсменов, но пока что все еще точно не позволяет полностью заменить прием на слух автоматизацией. Для радиолюбителей, наверное, это наоборот хорошо, потому что для радиолюбителей это хобби и спорт.
Pafnutyi
20.08.2019 16:06Про «дрожжачую руку» это уже давно решено, принимают скиммеры прекрасно. Вот выбирайте частоту и поковыряйте на ключе сами любой позывной, распознают чёрта лысого и удивят ответом ;)
Скиммеры и автоматический приём для радиолюбителей нужны. Они позволяют не вслушиваться в постоянное пиканье, увидел своего/нужного абонента ответил. А уже после того как видим что нас вызывают, тогда уже работать с приёмом на слух, это получается быстрее чем принимать программой читать что там напринято, а потом отвечать…

{kind=link}
VT100
20.08.2019 21:09Используем moving average («скользящее среднее») и фильтр низких частот чтобы получить сильно сглаженное текущее среднее значение сигнала.
Рассмотрите вариант с использованием вместо MAV — медианы. Она и давит шум и не «размывает» резкие переходы.makser1
21.08.2019 13:34Что такое за медианы?
VT100
21.08.2019 21:32Попробую по памяти, а Вы — проверьте в поисковике или табличном процессоре.
Медиана — это функция, выделяющая в некоторой выборке данных такой член, что 50% выборки больше него, а 50% — меньше.
Вместо скользящего среднего — скользящая медиана.
Kitsok
День, когда нейросетью будут решать квадратное уравнение, все ближе.
Rim13
Используя камеру смартфона на рукописное уравнение.
Denai
Для этого уже есть работающие приложения
themurka
photomath
RealSaniok
Когда в руках молоток все вокруг кажется гвоздями
katzen
Перефразируя один мем, «когда у тебя сварочный аппарат — вокруг то, что ты только захочешь увидеть!».
mapron
Это вы под впечатлением от
habr.com/ru/post/301536
?