
Компания Cerebras Systems выпустила самую большую микросхему в истории компьютерной техники. С площадью 46 225 мм? и 1,2 трлн транзисторов она примерно в 56,7 раз больше, чем самый большой GPU (21,1 млрд транзисторов, 815 мм?). Фото: Jessica Chou / The New York Times
Самые большие компьютерные чипы обычно помещаются в ладони. Некоторые могут уместиться на кончике пальца. Известно, что увеличение физических размеров вызывает массу проблем. Однако стартап из Кремниевой долины бросает вызов этой идее. Сегодня на конференции Hot Chips в Пало-Альто компания Cerebras Systems и её производственный партнер TSMC представили «крупнейшую микросхему в истории компьютерной техники» размером примерно с обеденную тарелку, пишет NY Times.
Процессор предназначен для дата-центров по обработке вычислений в области машинного обучения и искусственного интеллекта (AI).
Инженеры Cerebras Systems считают, что микросхему под названием WSE можно использовать для облачных вычислений в разных приложениях машинного обучения: от беспилотных автомобилей до цифровых ассистентов с распознаванием речи, таких как Alexa от Amazon.
Разработкой чипов для AI занимаются многие компании, в том числе традиционные представители индустрии, такие как Intel, Qualcomm, а также различные стартапы в США, Великобритании и Китае. Некоторые эксперты считают, что эти чипы будут играть ключевую роль в гонке за создание искусственного интеллекта, потенциально влияя на баланс сил между технологическими компаниями и даже странами. Теоретически, они могут дать преимущество в работе коммерческих продуктов и государственных технологий, включая системы наблюдения и автономное оружие.
Google уже разработала собственный AI-ускоритель, используя его в широком спектре проектов AI, включая Google Assistant, который распознаёт голосовые команды на телефонах Android, и Google Translate для перевода текстов: «В этой области наблюдается чудовищный рост, — говорит основатель и исполнительный директор Cerebras Эндрю Фельдман (Andrew Feldman), ветеран полупроводниковой индустрии, который продал свой предыдущий стартап AMD.
Новые системы AI полагаются на нейронные сети и требует специфических вычислителей. Сегодня большинство компаний обрабатывает данные на GPU. Хотя графические процессоры изначально предназначены для других задач, но хорошо подходят для обсчёта математики нейросетей.
Около шести лет назад, когда технологические гиганты Google, Facebook и Microsoft сосредоточились на технологиях AI, они начали покупать огромное количество GPU у Nvidia. За год компания продала графических процессоров на $143 млн, удвоив продажи по сравнению с предыдущим годом.
Но компаниям требовалось ещё больше вычислительной мощности, поэтому Google разработала чип специально для нейронных сетей — тензорный процессор, или TPU. Несколько других производителей последовали её примеру.
Системы AI работают в многопоточном режиме, а узким местом становится перемещение данных между чипами: «Соединение этих чипов на самом деле замедляет их — и требует много энергии, — объясняет Субраманьян Айер (Subramanian Iyer), профессор Калифорнийского университета в Лос-Анджелесе, который специализируется на разработке чипов для искусственного интеллекта.
Производители оборудования изучают множество различных вариантов. Некоторые пытаются расширить межпроцессорные соединения. Трёхлетний стартап Cerebras, который получил более $200 млн венчурного финансирования, предлагает новый подход. Идея в том, чтобы сохранить все данные на гигантском чипе — и тем самым ускорить вычисления.
Работать с одним большим чипом очень сложно. Обычно микросхемы создаются на круглых кремниевых пластинах диаметром около 12 дюймов (30,5 см). Каждая из них обычно содержит около 100 чипов.

Пример кремниевой пластины. Фото: ARM
Многие из этих микросхем после снятия с пластины выбрасываются и никогда не используются. Травление цепей в кремнии — такой сложный процесс, что производители не могут полностью устранить дефекты. Некоторые цепи просто не работают. Это одна из причин, почему производители предпочитают сохранять маленький размер микросхем — так остаётся меньше места для ошибок. А вот Cerebras Systems уверяет, что создала одну микросхему размером с целую пластину. Технологический партнёр TSMC производит эти чипы по техпроцессу 16 нм.
Некоторые стартапы раньше пробовали такой подход, но безуспешно. Пожалуй, самым известным является стартап под названием Trilogy, который основал в 1980 году известный инженер из компании IBM Джин Амдал (Gene Amdahl). Несмотря на более $230 млн финансирования, Trilogy в конечном итоге сочла задачу слишком трудной и спустя пять лет свернула деятельность.
Почти через 35 лет Cerebras собирается исправить ошибки предшественника. Стартап планирует начать поставки микросхем WSE небольшому числу клиентов уже в сентябре 2019 года. Основатель компании говорит, что WSE способен обучать системы AI в 100?1000 раз быстрее, чем существующее оборудование.
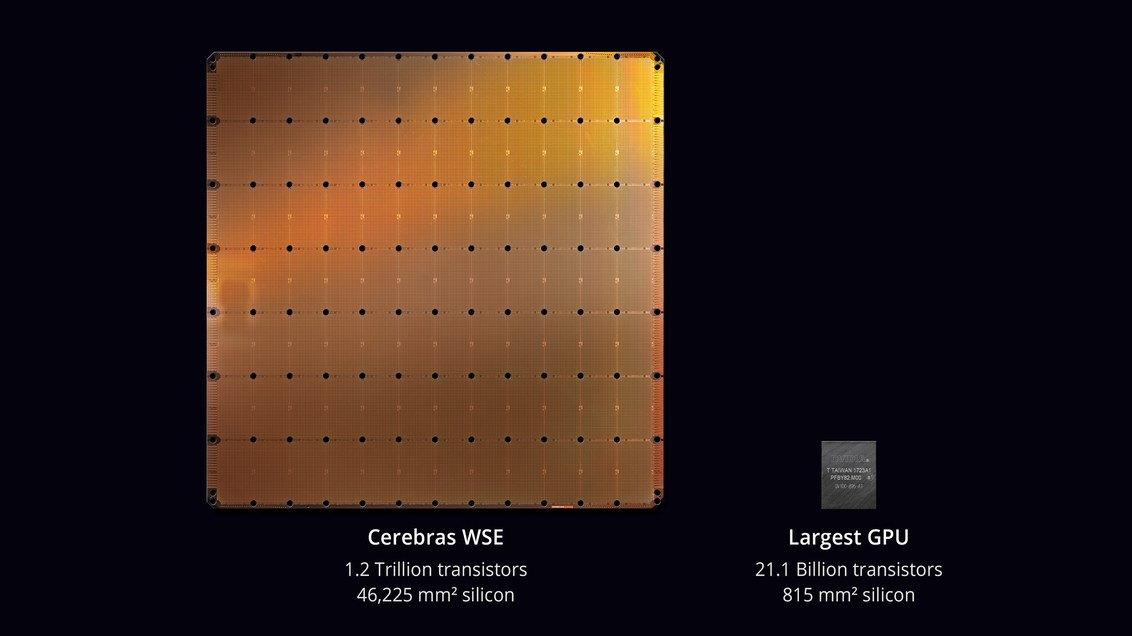
Фото: Cerebras Systems
18 гигабайт быстрой локальной SRAM — единственный уровень иерархии оперативной памяти. Скорость обмена данных с памятью — 9 петабайт в секунду, пишет VentureBeat.
Гигантская микросхема разделена на более мелкие секции (ядра), с учётом того, что некоторые из них не будут работать. Общее количество ядер — 400 000. Чип разработан с возможностью маршрутизации вокруг дефектных областей. Программируемые ядра SLAC (Sparse Linear Algebra Cores) оптимизированы для линейной алгебры, то есть для вычислений в векторном пространстве. Компания также разработала технологию «утилизации разреженности» (sparsity harvesting) для повышения производительности вычислений при разреженных рабочих нагрузках (содержащих нули), таких как глубокое обучение. Векторы и матрицы в векторном пространстве обычно содержат множество нулевых элементов (от 50% до 98%), поэтому на традиционных GPU большая часть вычислений уходит впустую. В отличие от них, ядра SLAC предварительно отфильтровывают нулевые данные.
Коммуникации между ядрами обеспечивает система Swarm с пропускной способностью 100 петабит в секунду. Маршрутизация аппаратная, задержки измеряются в наносекундах.
NY Times отмечает, что заявления Cerebras Systems не подтверждены независимыми экспертами. Достоверно не известно, какова производительность микросхемы и сколько ядер работоспособны в реальных образцах.
Цена микросхемы будет зависеть и от процента брака. Разработка и производство таких изделий является «намного более трудоёмким процессом», признаёт Брэд Полсен (Brad Paulsen), старший вице-президент TSMC. Чип такого размера также потребляет большое количество энергии: значит, и охлаждать его будет сложно и дорого. Другими словами, создание чипа — только часть задачи.
Cerebras планирует продавать чип в составе гораздо более крупной машины, которая включает сложное оборудование для жидкостного охлаждения. Это не совсем то, с чем привыкли работать крупные технологические компании и государственные учреждения: «Дело не в том, что люди не могли создать такой чип, — говорит Ракеш Кумар (Rakesh Kumar), профессор университета Иллинойса, который также изучает большие чипы для AI. — Проблема в том, что никто не мог сделать это коммерчески осуществимым».
Таким образом, основной вопрос — сколько будет стоить эта система с жидкостным охлаждением и микросхемой Cerebras внутри.
Комментарии (108)

paleblueillud
19.08.2019 20:15+1А как этот процессор в плане игор?)

perfect_genius
19.08.2019 21:10+11Крайзис должен потянуть.

monah_tuk
20.08.2019 04:11+2Через пару минут после запуска будет выводить сообщение игроку: "Фу, лузер! Смотри как надо!" После чего продолжает играть в игру сам, блокируя сообщения от мыши и клавиатуры.

EvokSinister
21.08.2019 10:16Угу, а потом полученные знания будут переданы терминаторам.
Главное, не давать этой машине доступ к Rimworld и его сообществу на реддите.
ehots
20.08.2019 10:22На средний скорее всего и только 1080p.
А вообще, зачем он нужен, если есть FX.

scg
19.08.2019 20:32Некоторые стартапы раньше пробовали такой подход, но безуспешно. Пожалуй, самым известным является стартап под названием Trilogy, который основал в 1980 году известный инженер из компании IBM Джин Амдал (Gene Amdahl).
Ну не знаю. Для меня самым известным является проект «Массштабируемых Пластин» Клайва Синклера: Неизвестный Синклер.
v-oz
20.08.2019 10:11какое счастье, что этот проект не взлетел. чипы всё плотнее и элементов всё больше. дублирование имеет смысл только в критических местах.
а дополнительную логику встраивают лишь для исправления ошибок проектирования. и то с большими оговорками о длинных путях до этих элементов.
спасибо, открыли для меня откуда есть пошел спектрум. его я как-то пропустил в своей деревне.



wormball
19.08.2019 21:03+8%шутка про советские микросхемы%

norguhtar
20.08.2019 13:22Между тем уже

Kocmohabt314
20.08.2019 14:05А кто-нибудь знает где купить такие ручки как на фото или хотя бы как они называются?
Хочу сделать моддинг своего компьютера :)berez
20.08.2019 14:48+1Есть подозрение, что эта ручка называется «трубка системы жидкостного охлаждения». :)
Но это не точно.


hhba
19.08.2019 21:16+2Не увидел в тексте статьи, за счёт чего конкретно они сделали этот waferscale коммерчески оправданным. Сама по себе идея не нова, занимались этим тоже ради быстрого интерконнекта, и были рабочие образцы, но как-то не взлетело.
sim2q
20.08.2019 04:49за счёт чего конкретно они сделали этот waferscale коммерчески оправданным
Отдельные cpu получаются относительно мелкие. Возможно за счёт умного роутинга битых как пишут. Но вообще — слишком фантастично. Интересно, что сказал бы amartology
amartology
20.08.2019 08:55+1Я бы сказал, что более-менее понятно, как сделать коммерчески оправданным производство waferscale кристалла. Это очень сложно, но принцип ясен. Хотя «очень сложно» у всех остальных, включая Intel, AMD и Apple в итоге вылилось в 3D-интеграцию и чиплеты, которые дают почти то же результат, но радикально дешевле и при необходимости с меньшей площадью корпуса. Но в целом можно выразить респект TSMC за отличный демонстратор высокого выхода годных.
Сложный вопрос — это корпус, и на него у этих людей нет ответа. Как и во что упаковать такую пластину, не наловив при этом отказов при сборке, не сломав ее, не получив проблем с тем, что она, например, погнётся. Как обеспечить теплоотвод (оно же наверняка жрет не один килоВатт) и т.д. и т.п.
Отдельно представьте себе: вы разработчик печатной платы. В центре надо поставить эту штуку 30*30. И подвести к ней 5000 А тока. Ваши действия? )
И ещё представьте себе: вы венчурный инвестор из Долины, с финансовым образованием. Вы давно работаете с хайтеком, неплохо для финансиста в нем разбираетесь. Но не более того. И тут приходит Джонни и говорит «есть очень крутая идея». Вы спрашиваете каких-то своих аналитиков, они говорят «идея выглядит чрезмерно смелой и, кажется, не взлетит». Но на пятом слайде презентации Джонни была надпись «я продал свой предыдущий стартап в AMD за X». И этот X будет реально жечь вам мозг, потому что AMD-то понимают получше вас, и Джонни вот молодец же, а не обычный балабол, которые к вам ходят. А вдруг Джонни прав, а ваши аналитики — нет? Тогда вы заработаете на Джонни 100*Х. Рискнете ли вы в такой ситуации десятком-другим миллионов? Особенно с учётом того, что в ваш бизнес-план и так заложен процент фейла 80-90%? Я бы рискнул.
Вот так эти люди собрали деньги, а дальше начали разбираться, а что там с корпусами. И вот именно эта часть про отсутствие готовых ответов на вопросы, что дальше делать с чипом, заставляет меня думать, что эта история — типичное порождение венчурной модели Кремниевой долины. Если протянут достаточно долго — успеют разработать что-то полезное, что потом используют в менее монструозных проектах другие.
Lerk
20.08.2019 10:20Ты так говоришь, как будто не существует вариантов сделать большой корпус. Тут сходу можно кучу решений предложить, как это можно сделать. А охлаждение плоских чипов никогда не было проблемой, собственно 3D для сильно горячих чипов ничем не лучше. Не говоря уже о том, что раз решение специализированное, можно реализовать кастомный отвод тепла с обратной стороны печатной платы, равно как и питание подводить оттуда же толстыми медными проводами, а стабилизировать его уже на пластине.
Весь вопрос в том, насколько это экономически эффективно. Хотя, опять же, если эта штука эффективна настолько, насколько рассказывают авторы, крупные фирмы типа гугла или теслы могут забить на высокую цену ради получения преимущества в обучении нейросетей, чтобы захватить какую-то часть рынка.
Вообще, на картинке прекрасно видно матрицу 7*12, где один элемент примерно в 1.5раза меньше «топового гпу». Так что считаем условно 150Вт на один элемент, что дает 13кВт энергии на 46к кв. мм. Это всего то 0.3Вт на кв. мм. площади, что рассеять вообще говоря не так уж и сложно.
Дополнительно получается примерно 5к ядер на один большой матричный элемент, который внутри наверняка имеет свою память независимо от остальных матричных элементов. Дальше все это чудо стыкуется по кастомной NoC и готово.
В общем выглядит прикольно, но насколько это эффективнее кластера отдельно стоящих ускорителей — вопрос открытый.amartology
20.08.2019 11:16Ты так говоришь, как будто не существует вариантов сделать большой корпус.
Я не говорю, что их не существует в принципе. Я сомневаюсь, что есть экономически эффективные варианты. И эти сомнения усиливает то, что эти ребята много говорят про кристалл и много молчат про все остальное.
Например, у меня есть подозрения, что и такого монстра будут серьезные проблемы с тем, что пластину будет коробить от неравномерного нагрева, причем каждую пластину по-своему. И на таких размерах оно может иметь весьма заметный эффект. То есть усложнятся контакты от чипа к корпусу, чтобы их не отрывало. И так дале и тому подобное.
13кВт энергии на 46к кв. мм.
13 кВт, питание ядра 1 В, ток 13 кА, сечение провода питания 2100 кв. мм. Это полностью реалистично, но плата выглядеть должна очень красиво.
В общем выглядит прикольно, но насколько это эффективнее кластера отдельно стоящих ускорителей — вопрос открытый.
Именно так. Я бы даже сказал, что итоговая реализация наверняка будет более производительна, чем кластер (особенно если посчитать на единицу объема сервера), но вопрос состоит в том, насколько оно будет дороже и не получится ли выгоднее поставить два кластера, чем одного такого монстра.
Впрочем, суперкомпьютеры давно уже больше зависят от интерконнекта, а не от вычислительных мощностей, и вот там-то такие решения могут быть оправданными.
beeruser
20.08.2019 15:41Про корпус/охлаждение/питание тут:
www.anandtech.com/show/14758/hot-chips-31-live-blogs-cerebras-wafer-scale-deep-learningamartology
20.08.2019 16:02С расширением материалов справляются с помощью некоего переходника.
Мне интереснее скорее неравномерное расширение самой пластины и соединение пластины с корпусом, а не расширение корпуса относительно платы. Но окей, так оно намного лучше выглядит.
Особенно подача питания в перпендикулярном направлении.Lerk
20.08.2019 16:39В самом деле, ты прекрасно знаешь как это могло быть решено. Начиная с равномерного распределения нагрузки по пластине, заканчивая адаптивными алгоритмами, использующими массив датчиков температуры, рассеянных по пластине в огромном количестве. Что касается корпуса, то ТКР корунда почти такой же, как у кремния, емнип. Наверняка можно найти материалы, которые имеют крайне близкий ТКР, но существенно прочнее. А дальше вопрос техники — склеить бутерброд разных материалов с нужными допусками по ТКР и готово.
hhba
20.08.2019 17:37Redundancy is your friend: ну ок, допустим дефекты на отдельных ядрах можно купировать простым отключением этих ядер. Но что делать, если дефекты случились в некоторой common area? Или ее там совсем нет?
Да и локализация дефектов отдельных ядер далеко не всегда легко делается, например если шины питания хорошо замкнулись… Впрочем нельзя исключать, что питание каждого ядра (группы ядер) отдельно заводится с несущей платы, тогда этой проблемы не будет.
alexeykuzmin0
20.08.2019 13:59крупные фирмы типа гугла или теслы
Гугл сам делает почти то же самое, см TPUamartology
20.08.2019 14:46Гугл сам делает почти то же самое, см TPU
Сам гугл это делает с чипами нормального размера.

А вопрос был в том, кому может быть экономически выгоден такой вот монстр.alexeykuzmin0
20.08.2019 16:36В плане того, под какие задачи заточено и сколько тепла выделяет с единицы площади — вполне похоже. Но да, Гугл объединяет несколько чипов на одной плате, а не в один чип
raamid
21.08.2019 02:33Выгодно это может быть кому угодно. Взять хотя бы биржевую аналитику. Очень соблазнительно оказаться наверху и при помощи нейросетей «видеть» все незаметные человеку (даже специалисту) процессы. Но это скучно. Вот натренировать с помощью такой вундервафли сильный ИИ, а затем использовать его уже с обычными чипами — это уже интереснее. Я бы начал с сортировки мусора на свалках.
amartology
21.08.2019 08:12Окей, ещё раз переформулирую вопрос. Допустим, такое решение дает пост производительности на 10% и рост стоимости в 10 раз относительно многокорпусного решения. Кому именно может быть нужно иметь 10% объема и 110% производительности за 1000% стоимости и почему? Что именно мешает натренировать сильный ИИ на обычном кластере?
С биржевой аналитикой как раз понятно, там реально может быть ситуация, когда сколь угодно малый рост производительности за сколь угодно большие деньги может окупиться, если девайс можно поставить рядом с местом событий, а не в качестве удаленного в пространстве сервера. Но считать, что эта штука нужна только для биржевых спекуляций, мне очень печально.DGN
22.08.2019 20:40Тем не менее, с чего то надо начинать, и если новую технологию окупают биржевые спекуляции, это прекрасно. Множество проектов не имеют даже такой окупаемости.
amartology
23.08.2019 11:10если новую технологию окупают биржевые спекуляции, это прекрасно.
Если так, то да. А если биржевые технологии — это единственное разумное применение этой «новой» (на самом деле хорошо забытой старой) технологии, то это весьма печально.

HiMem-74
20.08.2019 15:24М-м-м, «какая интересная задача»(с)
Сходу видится большой вопрос даже не в том, КАК отвести с такой пластины тепловой поток, а в том, что делать с ГРАДИЕНТОМ нагревания. Например, при 100% нагрузке ядро греется сильнее, соседнее ядро простаивает. Память в состоянии хранения или чтение/запись и пр. Вафлю такого размера должно очень сильно деформировать при этом. Для минимизации ее придется фигурно надрезать, предусматривать деформационные зазоры… Так и почему бы не пойти дальше и не порезать совсем? У меня пока картина не складывается.alexeykuzmin0
20.08.2019 16:35Можно задачи на самые холодные ядра кидать
raamid
21.08.2019 02:35Можно управлять интенсивностью охлаждения разных участков при помощи скорости подачи охлаждения. А еще, там нет фиксированной тактовой частоты. Если каждое ядро (или даже группа ядер) смогут иметь свою тактовую частоту, это конечно удар по производительности, но большой выигрыш в гибкости.
commanderxo
20.08.2019 19:08+1Фантастический сценарий, когда, показывая нейронке специально подготовленную картинку, можно в буквальном смысле сломать компьютеру мозг, становится всё менее фантастичным.
spc
20.08.2019 15:35В общем выглядит прикольно, но насколько это эффективнее кластера отдельно стоящих ускорителей — вопрос открытый.
Вот эта фраза натолкнула на мысль, которую, похоже, никто еще не высказал. Предположим, все получилось. Предположим, оно в продакшене. Но всем же понятно, что стоит эта фиговина не три копейки.
Предположим, что оно даже сверхнадежно. Но даже в этом случае фаталити с таким процессором — это, наверное, очень, очень большие финансовые потери. То есть, не как с кластером мух-ускорителей, когда сдох один, берем на Авито следующий, и алга.
ps. а вообще сильно похоже на анекдот про грузовик компакт-дисков.
hhba
20.08.2019 11:33Хотя «очень сложно» у всех остальных, включая Intel, AMD и Apple в итоге вылилось в 3D-интеграцию и чиплеты, которые дают почти то же результат, но радикально дешевле и при необходимости с меньшей площадью корпуса
Вот именно, борьба за уменьшение расстояний и упрощение сборки перешла немного в другую плоскость.
Но в целом можно выразить респект TSMC за отличный демонстратор высокого выхода годных
Да, и не более. Еще интересно было бы понять, за сколько итераций они его добились.
Параметры у процесса уж больно хорошие. Например на XS018 нам обещают делать относительно низкоскоростные waferscale-фотосенсоры на пластинах 8 дюймов с КВГ 0,9 (со встроенной «цифрой», поэтому КВГ вообще имеет место). А тут 16 нм (не Бог весть что, но все же), и размер побольше, и сплошная цифра…
заставляет меня думать, что эта история — типичное порождение венчурной модели Кремниевой долины
Предыдущие проекты хотя и были 30 лет назад, но кажется, что результат будет тот же.

perfect_genius
19.08.2019 21:16основной вопрос — сколько будет стоить
Всё же, основной вопрос пока — действительно ли у неё такая производительность, не подтверждена же ещё.
p1024x
19.08.2019 21:52А какое будет тепловыделение у такого кластера (не могу назвать это процессором)?
Охлаждать чем? Жидким азотом?algotrader2013
19.08.2019 22:12-2Подозреваю, что не такая уж и проблема. Что-то типа цельного куска меди килограмм на 20 со сквозными порами, через которые фреон гнать)
А холодильная установка будет вообще копейки стоить, учитывая, что даже топовые бытовые кондиционеры за $10к могут 30 киловат в час тепловой энергии отводить.
NetBUG
20.08.2019 10:22Проблема не в отведении 30 кВт от радиатора, а в передаче этой мощности с кремниевой пластины на радиатор без повреждения системы ни в холодном, ни в горячем состоянии, ни во время переходных процессов.



AntonSor
19.08.2019 22:42+1Я скорее ожидал увидеть огромную гибридную схему — куча отдельных кристаллов обычных размеров на ситалловой подложке

dipsy
20.08.2019 05:11Но зачем? Тут пропускаем сразу несколько ненужных этапов, нарезку кристалла, изготовление отдельной подложки, напайку на подложку,… За счет наличия штатной возможности отключения бракованных кристаллов, конечно.
amartology
20.08.2019 10:01Так уже делают Intel и AMD — чиплеты, интерпозеры, вот это все. Тут ничего интересного-прорывного нет, и возможное увеличение производительности за счет отказа от соединений «корпус-корпус» уже достигнуто.
Londoner
20.08.2019 00:04+1А как у них с процентом выхода годных?
DrPass
20.08.2019 03:32+1Скорее всего, около 100%. В хренотени с 400000 одинаковыми ядрами достаточно просто выключить несколько дефектных ядер так, чтобы никто этого не заметил.
Porfus
20.08.2019 08:37Вопрос сколько это несколько? Если процентов 75, то кто-то может и заметить…
DrPass
20.08.2019 12:12Ну какой сейчас процент выхода годных для обычных чипов 16nm процесса? 95%? Вот, примерно 5% ядер могут быть неработоспособными. Полагаю, там даже резервирование всунули в достаточном объеме.
amartology
20.08.2019 12:27Ну какой сейчас процент выхода годных для обычных чипов 16nm процесса? 95%?
95% — это уже с учетом отключения неработоспособных ядер и выпуска их на рынок как младших моделей. Тут скорее всего существенно ниже итоговый выход годных, даже с учетом всех разумных мер по противодействию.
Разработка и производство таких изделий является «намного более трудоёмким процессом», признаёт Брэд Полсен (Brad Paulsen), старший вице-президент TSMC.
DrPass
20.08.2019 13:2995% — это уже с учетом отключения неработоспособных ядер и выпуска их на рынок как младших моделей.
Я, допустим, такой информации не имею. Я предполагаю, что если TSMC заявляет, что «на 14nm мы достигли уровня выхода годных более 90%», то имеются в виду не многоядерные процессоры, а некое усреднённое значение по всему, что у них там на линиях выпускается.
Но то такое. Какая здесь картина, думаю, будет сильно зависеть от топологии чипа. Там, естественно, есть какая-то управляющая схема, дефект на которой его убъет целиком. Также, вероятно, соотношение площади этой схемы и площади всего кристалла невелико. Вероятно также дефект на коммуникационной шине может грохнуть целую группу ядер. Впрочем, это всё гадание на кофейной гуще.amartology
20.08.2019 14:50если TSMC заявляет, что «на 14nm мы достигли уровня выхода годных более 90%», то имеются в виду не многоядерные процессоры, а некое усреднённое значение по всему, что у них там на линиях выпускается.
Процент выхода годных серьезно зависит от площади чипа и его конструкции (ECC, запасные части и т.д.), поэтому «усредненное значение по всему» — это даже менее информативно, чем средняя температура по больнице.
А дальше вопрос сводится к тому, какая гранулярность отключения неработающих частей у этого монстра. Если отключать надо целый элемент кластера, которых всего 84 — это один разговор. А если внутри у элемента кластера 1000 одинаковых ядер, каждое из которых отключаемое — это совсем другой разговор.
DGN
22.08.2019 20:32Дефекты растут от центра к краям пластины. Если в центр ставить ядра, а вокруг ставить всякую вспомогательную перифирию с более грубыми нормами, наверное можно изготовить процессор без дефектов.
DrunkBear
20.08.2019 12:17Судя по тому, что цена будет зависеть от количества годных ядер — сделают дешёвую версию и выкинут на рынок по ~себестоимости + 15%.
И все будут довольны.
saag
20.08.2019 07:30Энергопотребление то какое, даже если взять 1 Вт на ядро, то как на целый дом и эта беда как бойлер будет тепло выделять? Для запуска такого процессора нужна система soft-start, как для токарного станка, иначе пусковые токи будут огромными. Что вспомнилась ЕС-1022 с ее промышленным кондиционером для охлаждения машзала и шкафом питания только непосредственно самой ЭВМ
firedragon
20.08.2019 08:22По идее это у них уже сделано в дизайне, плюс возможность отключать отдельные ядра при перегреве или снижать их частоту. В настольных процессорах и GPU это уже есть. Так что даже без охлаждения он будет работать, но медленно.
halted
20.08.2019 08:25А ведь могли использовать путь 3д-микросхем. При такой площади даже разделив пополам схему и положив одну часть над другой можно сильно увеличить производительность банально за счет сокращения длины маршрутов электронов.
amartology
20.08.2019 10:00можно сильно увеличить производительность банально за счет сокращения длины маршрутов электронов.
На самом деле вообще не факт.
Во-первых, глобального роутинга совсем немного, и большая часть путей электронов (скажем, 99.99999%) находится внутри отдельных ядер.
Во-вторых, переходы с уровня на уровень имеют большие габариты (например пятьдесят микрон диаметр линии) и, вследствие этого, большие паразитные сопротивления, емкости и индуктивности. И площади на кристалле большое количество вертикальных связей заняло бы довольно много. А если вертикальных связей не так много, чтобы отгрызть существенный процент площади, то мы возвращаемся к первому пункту.

amarao
20.08.2019 11:49В принципе, при таких размерах можно ожидать, что оно хотя бы киловатт рассеивает. Если там есть киловатт, её можно использовать как электроплитку. Надеюсь, они защищают поверхность от царапин и убегающего супа?
hhba
20.08.2019 17:48Кроме шуток — в Таиланде некая семья 45 лет варит один и тот же суп, постоянно добавляя компоненты. Теплосьем должен быть отличным, кастрюля у них вроде очень большая, как раз под такой чип, можно совместить два занятия — варить суп и майнить биткойны (сарказм).

blind_oracle
20.08.2019 18:44Лет 15 назад где-то видел теплый пол из первых пентиумов

Am0ralist
20.08.2019 22:09Ну вот пол не смогу, а коврик в ванну из каких-нибудь корок — вполне можно подумать)
Stanislav42
20.08.2019 13:25Ну если он один даст 2-3 петафлопа, то вот готовая система для фотореалистичного трехмерного вирта. Но лучше пару таких «чипов» конечно. И петабайтный диск для бэкапов и прочего. В перспективе буквально 10-15 лет — готовая Матрица.
alexeykuzmin0
20.08.2019 14:06Можно и не ждать 10-15 лет, берем стойку (не уверен, как по-русски называется, pod, в общем) Google TPU 3 поколения — в ней будет около 90 PFLOPS
Jetmanman
20.08.2019 15:07А еще говорят, что скорость света ограничивает размер процессора, думаю, что нет, и врядли даже на данный момент частоту ограничивает скорость света, иначе бы разгон был бы невозможен до 7 гигагерц. Скорее все ограничения только в тепловыделении и в сложности создния больших процессоров.
amartology
20.08.2019 15:35А еще говорят, что скорость света ограничивает размер процессора
Интересно, как именно она его ограничивает, если подвижность носителей заряда в любом применяемом в микросхемах материале радикально ниже скорости света.site6893
20.08.2019 20:40скорость света не размер процессора ограничивает, а длину линий передачи данных!
amartology
20.08.2019 22:31Но как она это делает? Ничто в микросхеме не движется со скоростью света.
DrPass
21.08.2019 00:55Скорость распространения сигнала и скорость носителей заряда — это две большие разницы. Электрон движется с небольшой скоростью. А вот электрическое поле распространяется со скоростью света. В металлическом проводнике чуть медленнее, где-то 0,9-0,7c в зависимости от проводника, но все равно, именно она играет роль в длине линий передачи данных. Нам ведь совершенно не обязательно, чтобы электрон из ключа А добежал до ключа В. Нас вполне устроит, что затвор ключа В будет насыщен электронами, которые находятся там поблизости, как только дойдёт фронт сигнала.
amartology
21.08.2019 08:57+2Скорость света также ограничивает максимальную скорость ракет с химическими двигателями. То есть в теории, конечно, да, а вот на практике намного раньше начинаются другие ограничения.
В частности, для размеров микросхемы реальными ограничителями являются параметры длинных линий (в электротехническом смысле), а также входные ёмкости и задержки переключения логических вентилей, а вовсе не скорость света.
Например, для частоты 1 ГГц и какого-то разумного запаздывания по фазе (допустим 60 градусов), скорость свет даёт нам ограничение длины линии в (1/6«10^-9)*(3*10^8) ~ 5 см для аналогового сигнала и ещё раза в два больше для цифрового. Если бы это было так, то в микропроцессорах и микроконтроллерах можно было бы вовсе не делать дерево тактовых сигналов (которое в реальности может занимать десятки процентов площади чипа и количества транзисторов). И была бы не нужна дорогая, нудная, сложная и долгая процедура экстракции паразитных параметров из металлических межсоединений, которую приходится делать при моделировании уже для технологий 180-350 нм при длинах линий в сотни, а то и десятки микрон.
И собственно, именно все вышеизложенное побуждает учёных продолжать искать возможности поместить на кристалл оптические линии передачи данных вместо того, чтобы просто использовать металлические. Потому что в случае с оптикой к теоретическому пределу, обусловленному скоростью света, можно подойти радикально ближе. С химическими ракетами и нуль-транспортировкой примерно такая же история)
BM_MacGregor
21.08.2019 14:41Слишком мало информации для процессора, который в сентябре уже планируется отгружать потребителю. Та же частота работы какая? Хотя бы примерный вид системы охлаждения?
Если все это жутко секретно, зачем тогда рассказывать о нем сейчас? В сентябре с помпой бы все показали.
p.s. Если честно, сомневаюсь, что чип такого размера вообще будет корректно работать. Есть небольшой опыт проектирования. Сложность у такого процессора просто запредельная.
amartology
21.08.2019 14:50Хотя бы примерный вид системы охлаждения?
Это было в презентации.
Если все это жутко секретно, зачем тогда рассказывать о нем сейчас? В сентябре с помпой бы все показали.
Ежегодная выставка сейчас, ждать следующего года не хотелось.
Если честно, сомневаюсь, что чип такого размера вообще будет корректно работать.
Там регулярный многоядерный кластер, почему бы ему не работать нормально, если все сделано без ошибок?
berez
Это ж сколько контактов надо в сокет будет завести, чтобы такую махину подключить и запитать? Тысяч двести? И прижимать к сокету паровым прессом…
kryvichh
Я так понял, железка заточена на обсчёт нейронок. Т.е. закачали данные, обсчитали веса, выгрузили результат.
LSDtrip
Она заточена на обсчёт разреженных матриц. Они везде. Математическое моделирование, дифференциальные уравнения, газо- и гидродинамика, физика твёрдых тел, нейронки (статистический анализ), и т.д. Везде, где нужно не только котиков по инстаграму погонять короче. Оптика на 100 гигабит скорее всего будет припаяна прямо к чипу, а там уже данные хоть со всего мира гнать.
Disasm
Для питания два контакта, но больших, под винт М10. Ими же и прижимать.
NetBUG
Хрусь! — сказала пластина.
Она при нагреве расширяется, и при толщине обычных подложек в миллиметр-два хрупкий кремний прикрутить болтом — верный шанс поломать её крайне быстро.
SergeyMax
Любой ребёнок понимает, что болт тоже должен быть из кремния.
playnet
Не выйдет. И дело даже не в «хрусть», а в равномерном распределении энергии. И если в материнке 2 слоя выделены под питание и землю, то в проце не выделить, будет куча контактов именно для равномерной подачи питания. Думаю, земля+питание будет минимум 200 ног.
amartology
Минимум две тысячи вы хотели сказать?
playnet
да, если там 13кА то счёт будет идти на тысячи.
ANIDEANI
Если бы интелы и амд, тратились на разработку а не на яхты и поседушки для топ менеджмента коих доходы в миллиарды$ то давно были бы рулонные процессоры где подключаешь к рулону питание и USB и считаешь — выгружаешь данные. Длинна может быть неограниченна.

mk2
Вашим благим намерениям мешает процент брака. Чем больше микросхема — тем больше шанс, что на ней есть дефект.
И к тому же как вы такой рулон охлаждать собираетесь?
yokotoka
Как пулемет Гатлинга, подозреваю — вращением "обоймы" процессоров. :)
Alexey2005
Ну светодиодные ленты же сделали? Почему бы не сделать множество тонких процессорных кристаллов, которые потом впаиваются на подложку в виде гибкой ленты? А то, что получится, уже свернуть хоть в рулон, хоть в морской узел.
Более того, так можно даже сделать модульный процессор. Когда на ленту можно по желанию наклеить хоть 10, хоть 100 модулей кэша, и любое требуемое количество ядер, причём ещё и разной специализации.
engine9
Можно то можно. Но зачем?
roscomtheend
И получить или многопроцессорный сервер (на нашей планете такое уже изобрели) или большие проблемы с микрокодом, которую нужно будет пилить и тестировать под разные варианты или он будет причиной тормозов. Не считая проблем с шинами для взаимодействия с этими модулями кеша (или падение скорости при росте цены).
alex6999
Погружать в жидкость в обойме, как для проявки фотопленок.
vvzvlad
И медленно вращать
roscomtheend
Длинна ли, коротка ли была кто? Но длина будет вполне ограничена. Главное — чтобы не окружность, а не то вдруг углов более миллиона будет и всё, USB уже не хватит для передачи данных. Кстати, к USB что планируется подключить и почему именно он?
engine9
А если дырочки прокалывать, получится еще и средство для долговременного бэкапа. (это шутка)
Kocmohabt314
А после устаревания рулончик можно в туалете повесить!
6opoDuJIo
К сожалению, мало кто понял сарказм)