Чем больше пользователей у вашего сервиса, тем выше вероятность, что им понадобится помощь. Чат с техподдержкой — очевидное, но довольно дорогое решение. Но если применить технологии машинного обучения, можно неплохо сэкономить.
Отвечать на простые вопросы сейчас может и бот. Более того, чат-бота можно научить определять намерения пользователя и улавливать контекст так, чтобы он мог решить большинство проблем пользователей без участия человека. Как это сделать, помогут разобраться Владислав Блинов и Валерия Баранова — разработчики популярного помощника Олега.
Двигаясь от простых методов к более сложным в задаче разработки чат-бота, разберем вопросы практической реализации и посмотрим, какой прирост качества можно получить и сколько это будет стоить.
Владислав Блинов — старший разработчик диалоговых систем в Тинькофф, часто бросается аббревиатурами: ML, NLP, DL и т.д. Кроме того, в аспирантуре исследует моделирование юмора через машинное обучение и нейросети.
Валерия Баранова пишет на Python крутые штуки в области NLP более 5 лет. Сейчас в команде диалоговых систем Тинькофф делает чат-ботов и преподает курс по Машинному обучению для студентов. Также занимается исследованиями в области computational humor, то есть учит AI понимать шутки и придумывать новые — об этом Валерия и Владислав расскажут на UseData Conf.
Услугами Тинькофф Банка пользуются миллионы людей. Для обеспечения круглосуточной поддержки такого количества пользователей необходим большой штат сотрудников, что приводит к высокой стоимости обслуживания. Кажется логичным, что на популярные вопросы пользователей можно отвечать автоматически с помощью чат-бота.
Первое, что нужно чат-боту — это понять, чего же хочет пользователь. Эта задача называется классификацией намерений или интентов. Далее все модели и подходы будем рассматривать в рамках этой задачи.
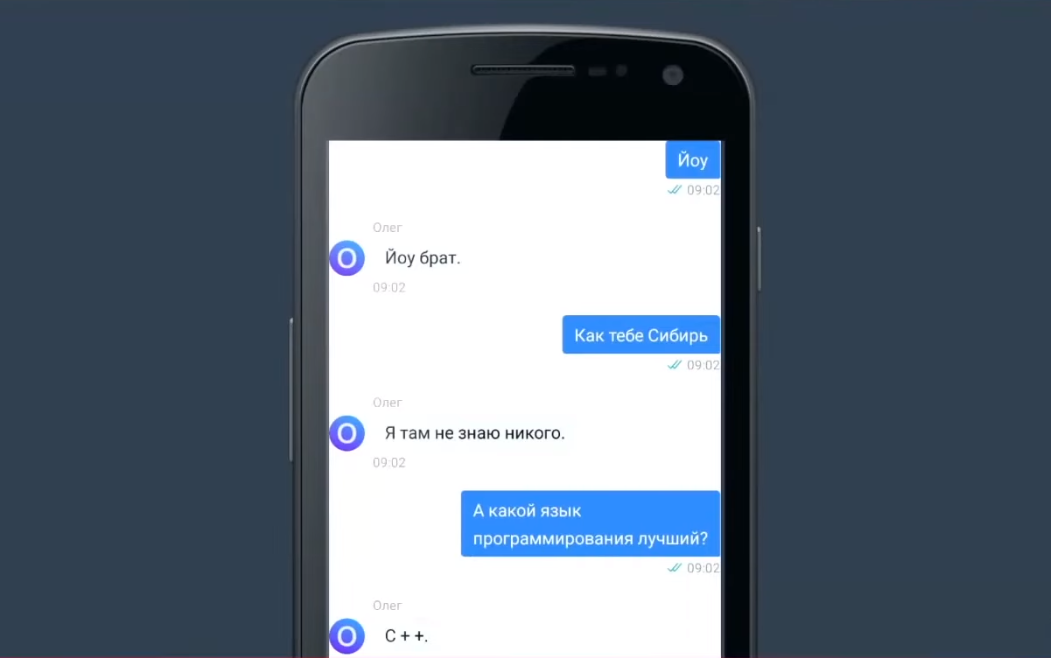
Посмотрим на пример классификации интентов. Если написать: «Переведи сотку Лере», чат-бот Олег поймет, что это интент денежного перевода, то есть намерение пользователя перевести деньги. А точнее, что нужно перевести Лере сумму в 100 рублей.
Сравнивать методы и тестировать качество их работы будем на тестовой выборке, которая состоит из реальных диалогов с пользователями. В нашей выборке более 30 000 размеченных примеров и 170 интентов, например: походы в кино, поиск ресторанов, открытие или закрытие вклада и т.д. Также у Олега на многое есть свое мнение, и он может просто с вами поболтать.
Самое простое, что можно сделать в задаче классификации интентов, — использовать словарь. Например, если во фразе пользователя встречается слово «переведи», считать, что нужно сделать денежный перевод.
Давайте посмотрим на качество такого простого подхода.
Если классификатор просто по слову «переведи» будет определять намерение пользователя как «денежный перевод», то качество уже будет достаточно высоким. Точность (precision) — 88%, при этом полнота низкая, равна всего 23%. Это и понятно: слово «переведи» не описывает всех возможностей сказать «переведи кому-то деньги».
Тем не менее, у этого подхода есть плюсы:
Однако, полнота такого решения скорее всего будет низкой, так как все вариации какого-либо класса описать трудно.
Рассмотрим контрпример. Если к «переведи» кроме интента денежного перевода, может относиться еще и второй интент — «переведи на оператора». Когда мы добавляем новый интент перевода на оператора, то получаем уже другие результаты.
Точность падает на 18 пунктов, при этом, естественно, полнота не растет. Это показывает, что нужен более продвинутый подход.
Прежде чем использовать машинное обучение, нужно понять, как представить текст в виде вектора. Один из самых простых подходов — использовать tf-idf-вектор.
Tf-idf-вектор учитывает встречаемость каждого слова во фразе пользователя и учитывает общую встречаемость слов в коллекции. Слова, которые часто встречаются в разных текстах, в этом векторном представлении имеют меньший вес.
Посмотрим на качество линейной модели на tf-idf-представлениях (в нашем случае логистической регрессии).
В результате резко увеличилась полнота, а точность осталась соизмерима с использованием словаря, f1-мера (взвешенное гармоническое среднее между точностью и полнотой) тоже возросла. То есть, модель уже сама разбирается, какие слова важны для какого интента — не нужно ничего придумывать самим.
Визуализация данных помогает понять, как выглядят интенты, насколько хорошо они группируются в пространстве. Но мы не можем напрямую визуализировать tf-idf-представления из-за большой размерности, поэтому будем использовать метод сжатия размерности — t-SNE.
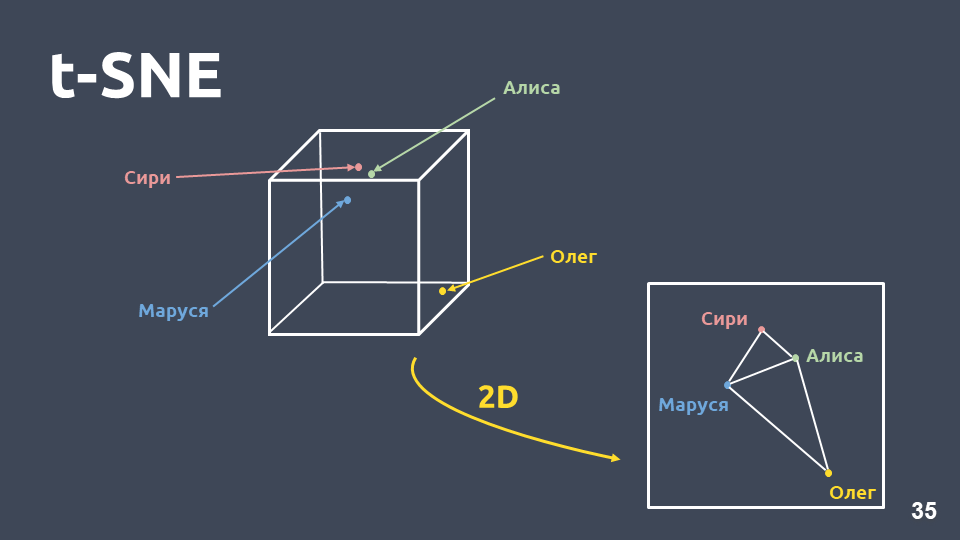
Основное отличие этого метода от PCA заключается в том, что при переводе в двумерное пространство относительное расстояние между объектами сохраняется.

t-SNE на tf-idf (топ-10 интентов), F1 score 0,92
Выше представлены топ-10 интентов по встречаемости в нашей коллекции. Здесь есть зеленые точки, которые не относятся ни к одному интенту, и 10 кластеров, которые помечены разными цветами — это разные интенты. Видно, что некоторые из них очень хорошо группируются. Взвешенная f1-мера равна 0,92 — это достаточно много, с этим уже можно работать.
Таким образом, с линейным классификатором над tf-idf:
Но есть и минусы:
Рассмотрим подробнее проблему перефразирования.
Tf-idf-векторы могут быть близкими только для текстов, которые пересекаются по словам. Близость между векторами можно посчитать через косинус угла между ними. На картинке посчитана косинусная близость по векторному представлению tf-idf для конкретных примеров.
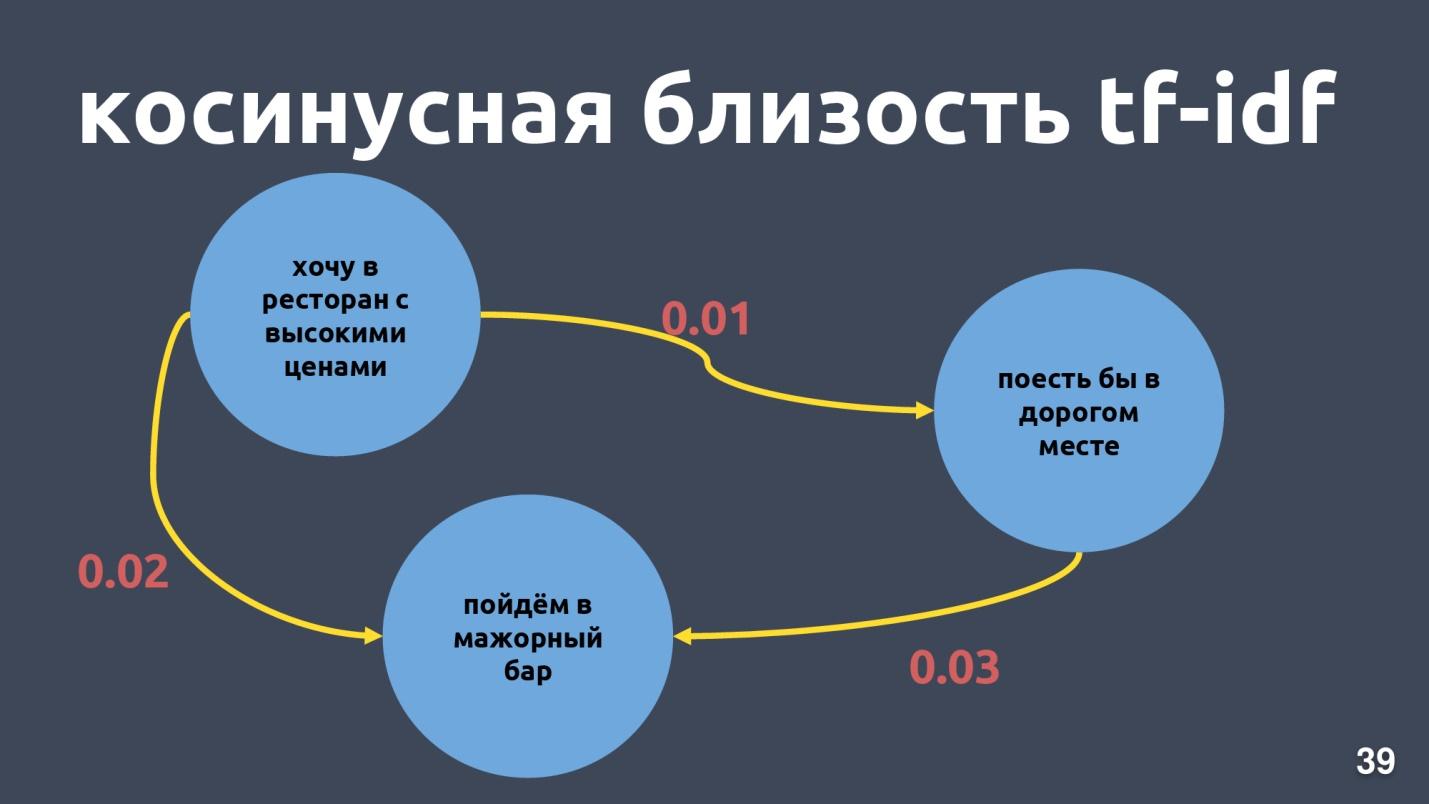
Для векторного представления tf-idf это не очень близкие фразы, хотя для нас это один и тот же интент и один и тот же класс.
Что можно с этим сделать? Например, можно вместо числа представлять слово целым вектором — это называется «эмбеддинг слова».
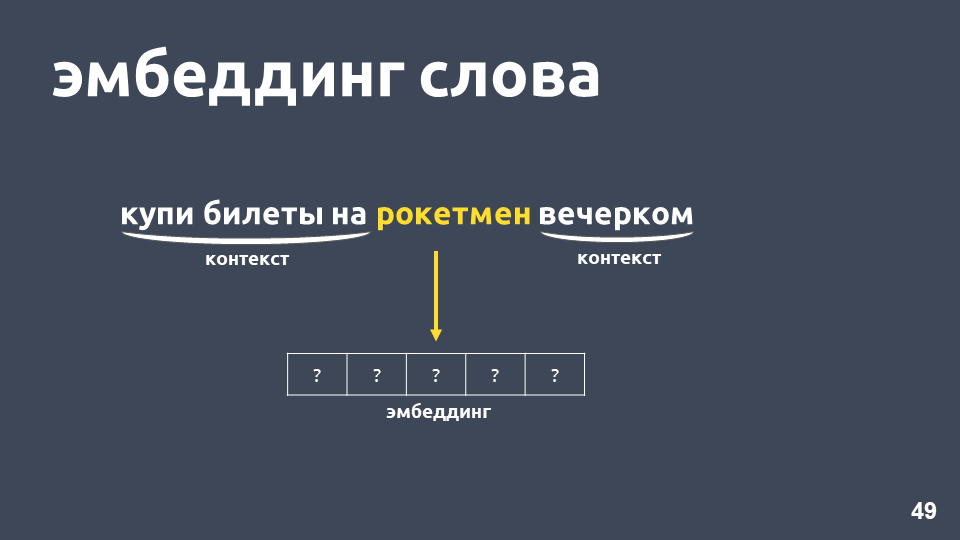
Одна из самых популярных моделей для решения этой задачи была предложена в 2013 году. Она называется word2vec и широко используется с тех пор.
Один из способов обучения Word2vec работает примерно следующим образом: берем текст, берем какое-то слово из контекста и выбрасываем его, затем берем другое случайное слово из контекста и представляем оба слова в виде one-hot векторов. One-hot вектор — это вектор по размерности словаря, где только координата, соответствующая индексу слова в словаре, имеет значение 1, остальные 0.
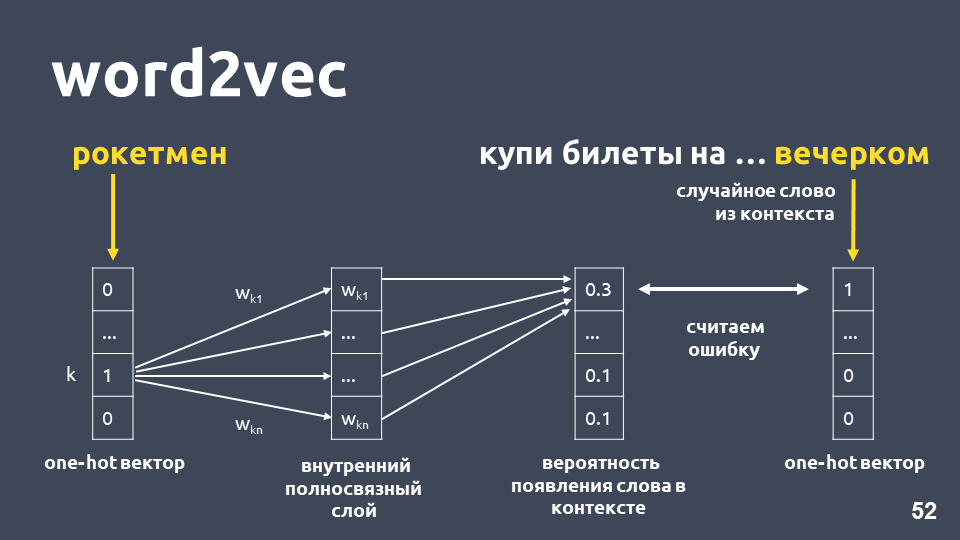
Далее обучаем простую однослойную нейронную сеть без активации на внутреннем слое предсказывать следующее слово в контексте, то есть, по слову «рокетмен» предсказывать слово «вечерком». На выходе получаем распределение вероятностей для всех слов из словаря быть следующим. Так как мы знаем, какое слово было в действительности, можем посчитать ошибку, обновить веса и т.д.

Обновленные веса, полученные в результате обучения на нашей выборке и являются эмбеддингом слова.
Преимущество использования эмбеддинга вместо числа, во-первых, в том, что учитывается контекст. Популярный пример: Трамп и Путин близки по word2vec, потому что они оба президенты и часто в текстах употребляются вместе.
Для слов, которые встречались в обучающей выборке, вы просто берете матрицу эмбеддингов, берете по индексу слова его вектор, получаете эмбеддинг.
Казалось бы, все хорошо, кроме того, что некоторых слов в вашей матрице может не быть, потому что модель их не видела при обучении. Для того чтобы бороться с проблемой незнакомых слов (out-of-vocabulary), в 2014 году придумали модификацию word2vec — fasttext.
Fasttext работает следующим образом: если слова нет в словаре, то оно разбивается на символьные n-граммы, для каждой n-граммы берется эмбеддинг из матрицы эмбеддингов n-грамм (которые обучаются подобно word2vec), усредняются эмбеддинги, получается вектор.
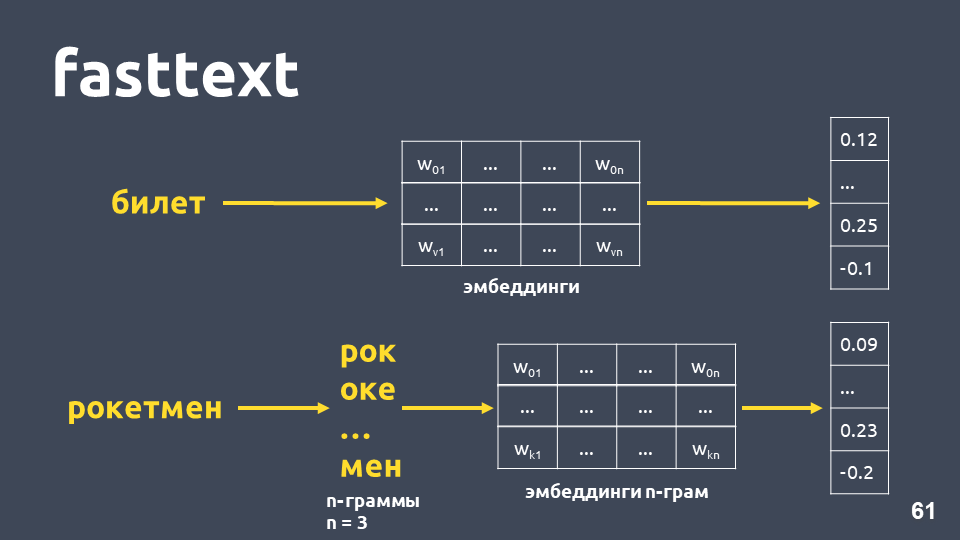
Итого, получаем векторы для слов, которых нет в нашем словаре. Теперь мы можем вычислять похожесть даже для незнакомых слов. И, что довольно важно, есть обученные модели для русского, английского и китайского языков, например, у Facebook и проекта DeepPavlov, поэтому это можно быстро включить в свой пайплайн.
Но недостатки остаются:
Действительно, косинусная близость в нашем примере по fasttext выше, чем косинусная близость по tf-idf, даже несмотря на то, что в этих фразах общее только «в».
t-SNE на fasttext (топ-10 интентов), F1 score: 0,86
Однако при визуализации результатов fasttext по t-SNE разложению кластеры интентов выделяются гораздо хуже, чем для tf-idf. F1-мера здесь 0,86 вместо 0,92.
Мы провели эксперимент: объединили tf-idf и fasttext векторы. Качество получилось абсолютно такое же, как при использовании только tf-idf. Это верно не для всех задач, бывают задачи, где объединенные tf-idf и fasttext работают лучше, чем просто tf-idf, или где fasttext работает лучше tf-idf. Нужно экспериментировать и пробовать.
Давайте попробуем увеличить количество интентов (напомним, что у нас их 170). Ниже кластеры для топ-30 интентов на tf-idf векторах.
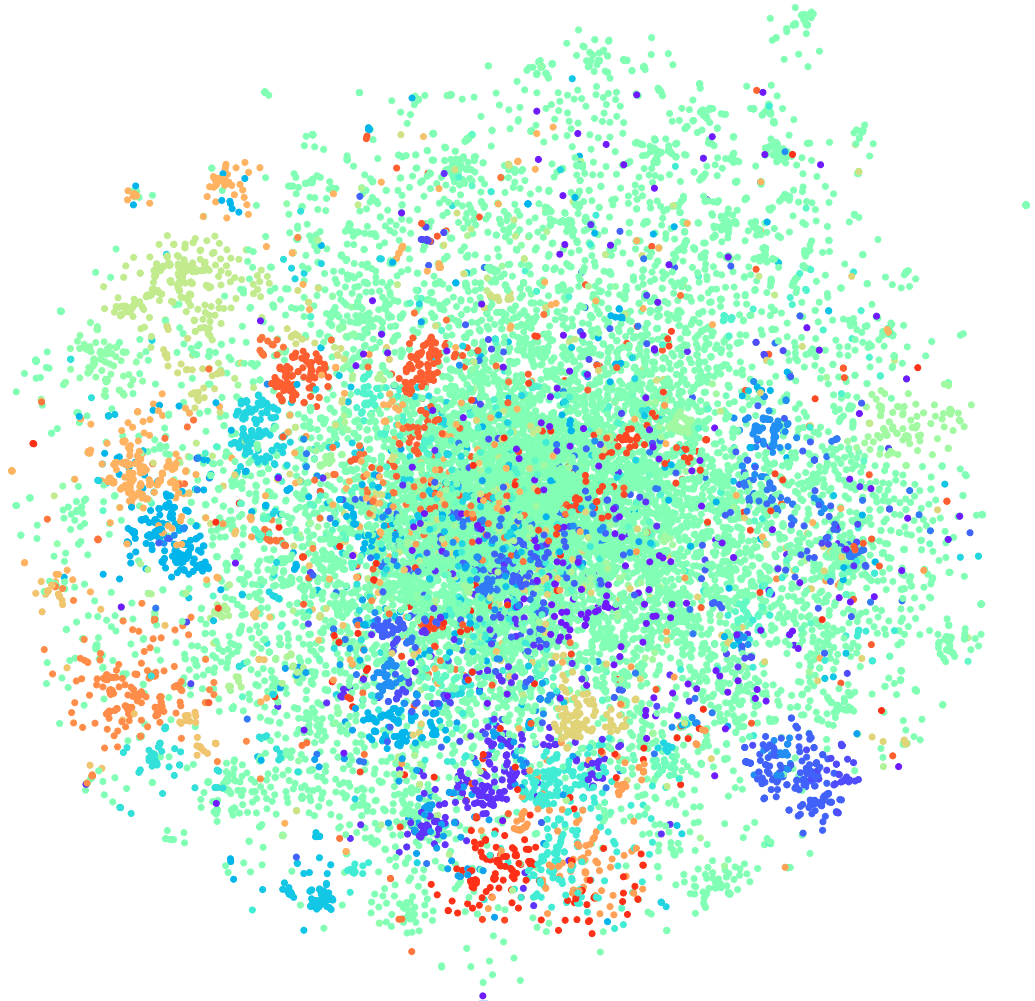
t-SNE на tf-idf (топ-30 интентов), F1 score 0, 85 (на 10 было 0,92)
Качество падает на 7 пунктов, и мы теперь не видим выраженной кластерной структуры.
Посмотрим на примеры текстов, которые начали путаться, потому что добавились еще интенты, которые пересекаются семантически и по словам.
Например: «А если открыть вклад, какие проценты по нему?» и «А я хочу открыть вклад под 7 процентов». Очень похожие фразы, но это разные интенты. В первом случае человек хочет узнать условия по вкладам, а во втором случае — открыть вклад. Чтобы разделять такие тексты на разные классы, нам понадобится что-то более сложное — deep learning.
Мы хотим получить вектор текста и, в частности, вектор слова, который будет зависеть от контекста употребления. Стандартным способом получить такой вектор является использование эмбеддингов из языковой модели.
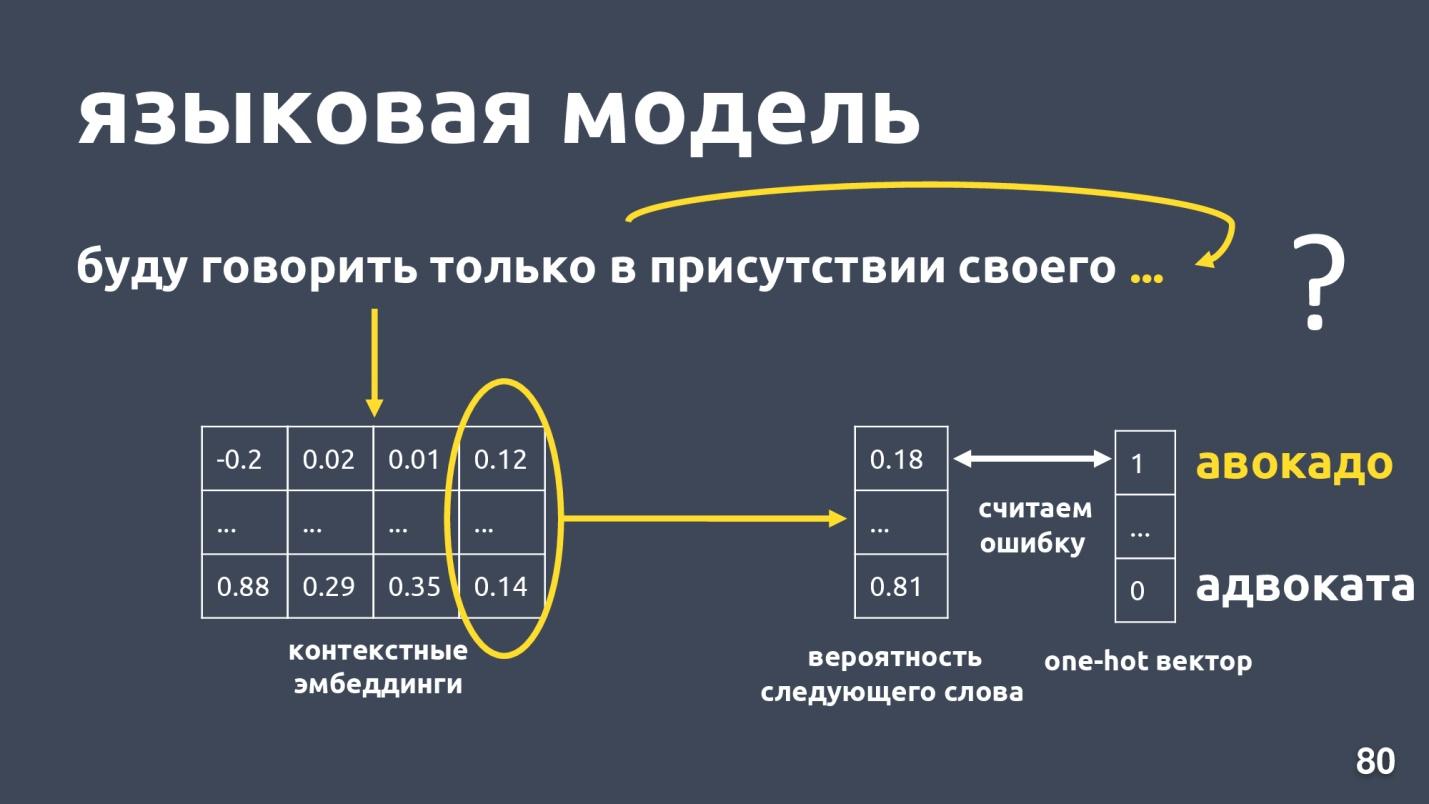
Языковая модель решает задачу языкового моделирования. А что это за задача? Пусть есть последовательность слов, например: «Буду говорить только в присутствии своего…», и мы пытаемся предсказать следующее слово в последовательности. Языковая модель выдает контекст на эмбеддинги. Получив контекстные эмбеддинги и векторы для каждого слова, можно предсказывать вероятность следующего слова.
Есть вектор размерности словаря, и каждому слову назначается вероятность быть следующим. Мы снова знаем, какое слово было в действительности, считаем ошибку и обучаем модель.
Языковых моделей довольно много, в прошлом году был бум? и было предложено очень много разных архитектур. Одна из них — ELMo.
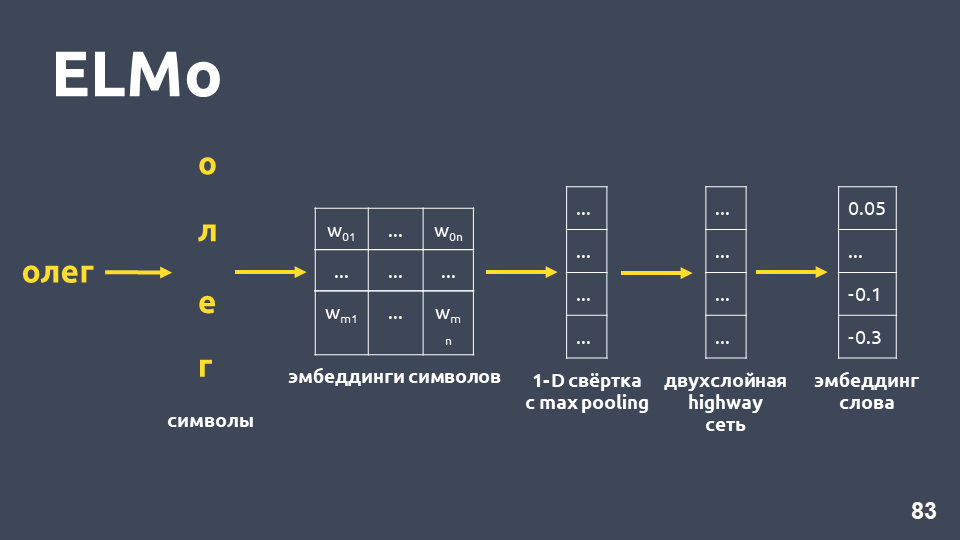
Идея модели ELMo в том, чтобы сначала построить для каждого слова в тексте посимвольный эмбеддинг слова, а потом для них применить LSTM-сеть таким образом, что получатся эмбеддинги, учитывающие контекст, в котором встретилось слово.
Рассмотрим, как получается посимвольный эмбеддинг: разбиваем слово на символы, для каждого символа применяем эмбеддинг-слой и получаем матрицу эмбеддингов. Когда речь идет только о символах, размерность такой матрицы небольшая. Потом к матрице эмбеддингов применятся одномерная свертка, как обычно делается в NLP, с max pooling в конце, получается один вектор. К этому вектору применяется двухслойная, так называемая, highway-сеть, которая вычисляет общий вектор слова.
Причем, модель построит какую-то гипотезу эмбеддинга даже для слова, которое не встречалось в обучающей выборке.
После того, как мы получили посимвольные эмбединги для каждого слова, применяем к ним двухслойную BiLSTM-сеть.
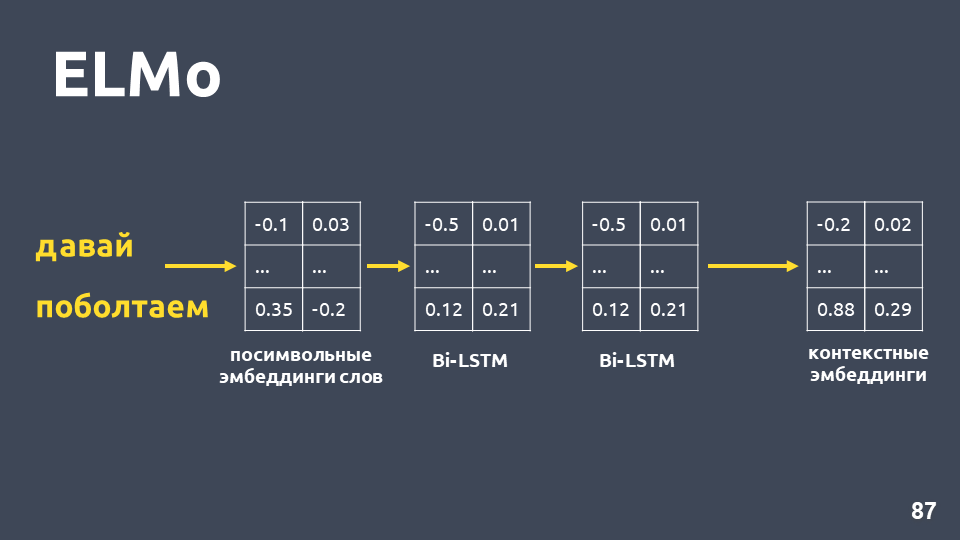
После применения двухслойной BiLSTM-сети обычно просто берутся hidden states последнего слоя, и считается, что это и есть контекстные эмбеддинги. Но в ELMo есть две особенности:
В нашей задаче мы использовали простое усреднение этих трех эмбеддингов и таким образом получали контекстный эмбеддинг для каждого слова.
Языковая модели дает следующие преимущества:
Остается единственный минус — языковая модель не дает гарантии, что тексты, которые относятся к одному классу, то есть, к одному интенту, будут близки в векторном пространстве.
В нашем примере с рестораном значения косинусной близости по модели ELMo действительно стали выше.

t-SNE на ELMo (топ-10 интентов), F1 score 0,93 (0,92 по tf-idf)
Кластеры при топ-10 интентах тоже более выражены. На рисунке выше четко видны все 10 кластеров, при этом точность чуть-чуть выросла.

t-SNE на ELMo (топ-30 интентов) F1 score 0,86 (0,85 по tf-idf)
Для топ-30 интентов все еще сохраняется кластерная структура, а также происходит прирост по качеству на один пункт.
Но в такой модели нет гарантии, что предложения «А если открыть вклад, какие проценты по ним?» и «А я хочу открыть вклад под 7 процентов» будут далеко друг от друга, хоть они и лежат в разных классах. С ELMo мы просто учим языковую модель, и, если семантически тексты похожи, то они будут близки. ELMo не знает ничего о наших классах, но можно сблизить векторы текстов одного интента в пространстве, используя метки классов.
Берём вашу любимую архитектуру нейросети для векторизации текстов и два примера интентов. Для каждого из примеров получаем эмбеддинги, а затем считаем косинусное расстояние между ними.
Косинусное расстояние равно единица минус косинусная близость, с которой мы ранее знакомились.
Такой подход называется сиамской сетью.
Мы хотим, чтобы тексты из одного класса, например, «сделай перевод» и «закинь денег», лежали близко в пространстве. То есть, косинусное расстояние между их векторами должно быть как можно меньше, в идеале — ноль. А тексты, относящиеся к разным намерениям, должны лежать как можно дальше друг от друга.
Но на практике такой способ обучения работает не так хорошо, поскольку объекты разных классов не получаются достаточно удалёнными друг от друга. Гораздо лучше работает функция потерь, называемая «triplet loss». В ней используются тройки объектов, называемые триплетами.
На иллюстрации изображен триплет: объект-якорь в синем кружочке, положительный объект в зеленом и отрицательный объект в красном кружочке. Отрицательный объект и якорь лежат в разных классах, а положительный и якорь — в одном.

Мы хотим добиться того, чтобы после обучения положительный объект был ближе к якорю, чем отрицательный. Для этого считаем косинусное расстояние между парами объектов и вводим гиперпараметр — «margin» — расстояние, которое мы ожидаем, что будет между положительным и отрицательным объектами.

Функция потерь выглядит так:
Другими словами, в ходе обучения мы добиваемся, чтобы положительный объект был к якорю ближе, чем отрицательный, хотя бы на margin. Если функция потерь равна нулю, то это получилось, и мы заканчиваем обучение, иначе продолжаем минимизировать целевую функцию.
После того, как обучили модель, мы еще не получаем классификатор, это просто метод для получения таких эмбеддингов, что объекты, которые лежат в одном интенте, скорее всего, будут иметь близкие векторы.
Когда мы получили модель, мы можем использовать другой метод классификации поверх эмбеддингов. Хорошо подойдет kNN, поскольку мы уже добились того, чтобы эмбеддинги были с ярко выраженной кластерной структурой.
Напомним, как работает kNN для текстов: берем элемент текста, получаем для него эмбеддинг, переводим его в векторное пространство, и затем смотрим, кто его сосед. Среди соседей считаем самый частый класс и заключаем, что новый объект принадлежит этому классу.
Размерность эмбеддингов, которые мы используем, равна 300, а в тренировочной выборке около 500 000 объектов. Стандартные методы поиска ближайших соседей нам не подходят по производительности. Мы использовали метод HNSW — Hierarchical Navigable Small World.
Navigable Small World — это связный граф, в котором мало ребер между вершинами, которые находятся на большом расстоянии, и много ребер между близкими вершинами. В нашем случае, длина ребра будет определяться косинусным расстоянием, т.е. для тренировочной выборки мы вычисляем расстояние между всеми примерами интентов, потом выбрасываем случайным образом очень большие расстояния так, чтобы граф все еще оставался связанным.
После этого разбиваем граф на уровни, отсюда в названии Hierarchical. На каждом уровне содержится только некоторое подмножество вершин, причем такое, что каждый следующий уровень содержит все вершины, которые есть на предыдущем. На каждом уровне мы проводим случайное выбрасывание ребер с сохранением связности графа.
Затем берем случайную вершину на первом уровне, смотрим, кто из ее соседей ближе всего к той точке, для которой мы ищем соседей, и двигаемся к соседу случайной вершины.
Затем перемещаемся на следующий уровень, повторяем процесс до тех пор, пока не наберем нужное количество таких соседей, что, скорее всего, они будут самыми близкими к начальной вершине. Это приближенный метод, то есть нет гарантии, что мы найдем самых близких соседей в каждом случае, но у него очень хорошая полнота — около 0,95-0,99, в зависимости от настроек.
Более того, преимуществом использования метода ближайших соседей является то, что при добавлении нового интента, который не слишком пересекается по словам с уже существующими интентами, необязательно переобучать всю модель. Можно просто добавить новые точки в векторное пространство и автоматически начать классифицировать новый класс.
Давайте посмотрим, какой прирост дает использование сиамской сети. Ниже на графике видно, что все интенты образуют отдельные кластеры. В таком случае даже линейная модель позволит неплохо разделить пространство.
t-SNE на siamese (топ-10 интентов), F1 score 0,95 (0,93 по ELMo)
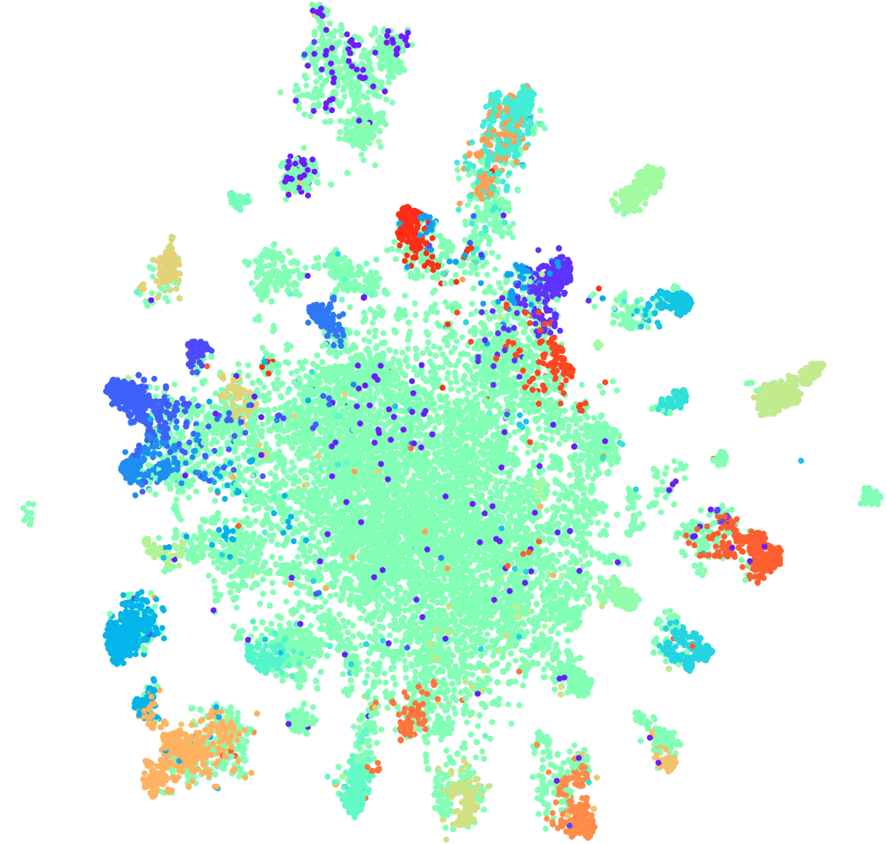
t-SNE на siamese (топ-30 интентов), F1 score 0,87 (0,86 по ELMo)
Для 10 интентов мы получили прирост на два пункта по сравнению с языковой моделью ELMo, для 30 — на один, при этом кластерная структура все еще сохраняется.
Метод использования шаблонов и словарей вполне допустим, если у вас немного интентов, например, 2-5, когда они хорошо разделимы и действительно описываются словарями или шаблонами. Он может хорошо сработать, если в классе мало примеров, в нашем случае это могут быть намерения пользователей, для которых не более 20-30 вариантов формулировок. Тогда нет смысла строить сложные модели, можно обойтись словарями.
Если интентов больше, но при этом они хорошо разделяются, у них мало пересекающихся слов, можно обходиться стандартными линейными моделями поверх tf-idf. Такие модели быстро обучаются, и с ходу дают хорошее качество, которое еще можно повысить, если поработать с выборкой и настроить параметры.
Если требуется учитывать перефразирование, обратите внимание на word2vec и fasttext. Это рабочие модели, несмотря на то, что в нашей конкретной задаче они не дали прироста. В вашей задаче классификации текстов их стоит попробовать, тем более это так же быстро, как и использовании более простых векторных представлений, потому что есть предобученные модели.
Чуть больше времени, скорее всего, займет обучение ELMo. Если вам понадобится дообучиться на своих данных, то, конечно, нужно будет разобраться с техническими деталями, но все это тоже не слишком долго, зато можно получить значительный прирост качества. Особенно хорошо сработает ELMo, когда в задаче требуется учесть семантические особенности текстов, то есть когда к одному классу относятся близкие по смыслу предложения.
Если же тексты из разных классов в задаче классификации сильно пересекаются по смыслу, то придется использовать что-то более продвинутое. В нашем случае хорошо сработала сиамская сеть. Применение этого метода займёт больше времени, потому что как минимум для обучения такой сети нужно много примеров из каждого класса. То есть, в нашем случае, каждое намерение нужно было представить большим количеством положительных и отрицательных примеров. Кроме того, нужно придумать подходящую нейронную архитектуру, протестировать несколько вариантов и т.д. Но эта работа окупится, и вы получите хороший прирост качества.
Полезные ссылки:
Отвечать на простые вопросы сейчас может и бот. Более того, чат-бота можно научить определять намерения пользователя и улавливать контекст так, чтобы он мог решить большинство проблем пользователей без участия человека. Как это сделать, помогут разобраться Владислав Блинов и Валерия Баранова — разработчики популярного помощника Олега.
Двигаясь от простых методов к более сложным в задаче разработки чат-бота, разберем вопросы практической реализации и посмотрим, какой прирост качества можно получить и сколько это будет стоить.
Владислав Блинов — старший разработчик диалоговых систем в Тинькофф, часто бросается аббревиатурами: ML, NLP, DL и т.д. Кроме того, в аспирантуре исследует моделирование юмора через машинное обучение и нейросети.
Валерия Баранова пишет на Python крутые штуки в области NLP более 5 лет. Сейчас в команде диалоговых систем Тинькофф делает чат-ботов и преподает курс по Машинному обучению для студентов. Также занимается исследованиями в области computational humor, то есть учит AI понимать шутки и придумывать новые — об этом Валерия и Владислав расскажут на UseData Conf.
Услугами Тинькофф Банка пользуются миллионы людей. Для обеспечения круглосуточной поддержки такого количества пользователей необходим большой штат сотрудников, что приводит к высокой стоимости обслуживания. Кажется логичным, что на популярные вопросы пользователей можно отвечать автоматически с помощью чат-бота.
Интент или намерение пользователя
Первое, что нужно чат-боту — это понять, чего же хочет пользователь. Эта задача называется классификацией намерений или интентов. Далее все модели и подходы будем рассматривать в рамках этой задачи.
Посмотрим на пример классификации интентов. Если написать: «Переведи сотку Лере», чат-бот Олег поймет, что это интент денежного перевода, то есть намерение пользователя перевести деньги. А точнее, что нужно перевести Лере сумму в 100 рублей.
Сравнивать методы и тестировать качество их работы будем на тестовой выборке, которая состоит из реальных диалогов с пользователями. В нашей выборке более 30 000 размеченных примеров и 170 интентов, например: походы в кино, поиск ресторанов, открытие или закрытие вклада и т.д. Также у Олега на многое есть свое мнение, и он может просто с вами поболтать.
Классификация на словаре
Самое простое, что можно сделать в задаче классификации интентов, — использовать словарь. Например, если во фразе пользователя встречается слово «переведи», считать, что нужно сделать денежный перевод.
Давайте посмотрим на качество такого простого подхода.
| precision | recall | f1-score | |
| Денежный перевод | 0,88 | 0,23 | 0,36 |
| Остальное | 0,97 | 0,99 | 0,98 |
Тем не менее, у этого подхода есть плюсы:
- Не нужна размеченная выборка (если не учишь модель, то и выборка не нужна).
- Можно получить высокую точность, если хорошо составить словари (но это потребует времени и ресурсов).
Однако, полнота такого решения скорее всего будет низкой, так как все вариации какого-либо класса описать трудно.
Рассмотрим контрпример. Если к «переведи» кроме интента денежного перевода, может относиться еще и второй интент — «переведи на оператора». Когда мы добавляем новый интент перевода на оператора, то получаем уже другие результаты.
| precision | recall | f1-score | |
| Денежный перевод | 0,70 | 0,23 | 0,34 |
| Остальное | 0,97 | 0,99 | 0,98 |
Анализ текста
Прежде чем использовать машинное обучение, нужно понять, как представить текст в виде вектора. Один из самых простых подходов — использовать tf-idf-вектор.
Tf-idf-вектор учитывает встречаемость каждого слова во фразе пользователя и учитывает общую встречаемость слов в коллекции. Слова, которые часто встречаются в разных текстах, в этом векторном представлении имеют меньший вес.
Посмотрим на качество линейной модели на tf-idf-представлениях (в нашем случае логистической регрессии).
| precision | recall | f1-score | |
| Денежный перевод | 0,74 | 0,86 | 0,80 |
| Остальное | 0,99 | 0,99 | 0,99 |
Визуализация данных
Визуализация данных помогает понять, как выглядят интенты, насколько хорошо они группируются в пространстве. Но мы не можем напрямую визуализировать tf-idf-представления из-за большой размерности, поэтому будем использовать метод сжатия размерности — t-SNE.
Основное отличие этого метода от PCA заключается в том, что при переводе в двумерное пространство относительное расстояние между объектами сохраняется.
t-SNE на tf-idf (топ-10 интентов), F1 score 0,92
Выше представлены топ-10 интентов по встречаемости в нашей коллекции. Здесь есть зеленые точки, которые не относятся ни к одному интенту, и 10 кластеров, которые помечены разными цветами — это разные интенты. Видно, что некоторые из них очень хорошо группируются. Взвешенная f1-мера равна 0,92 — это достаточно много, с этим уже можно работать.
Таким образом, с линейным классификатором над tf-idf:
- гораздо выше полнота, чем при использовании словаря, при соизмеримой точности;
- не нужно придумывать, какие слова какому интенту соответствуют.
Но есть и минусы:
- ограниченный словарь, можно получить вес только для тех слов, которые присутствуют в тренировочной выборке;
- не учитывается перефразирование;
- не учитывается порядок, в котором слова встречались в тексте.
Перефразирование
Рассмотрим подробнее проблему перефразирования.
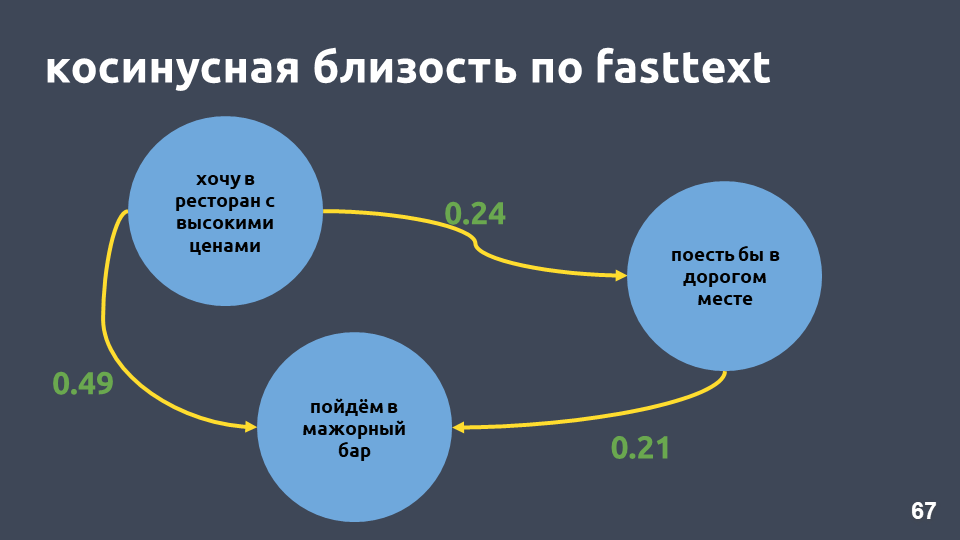
Tf-idf-векторы могут быть близкими только для текстов, которые пересекаются по словам. Близость между векторами можно посчитать через косинус угла между ними. На картинке посчитана косинусная близость по векторному представлению tf-idf для конкретных примеров.
Для векторного представления tf-idf это не очень близкие фразы, хотя для нас это один и тот же интент и один и тот же класс.
Что можно с этим сделать? Например, можно вместо числа представлять слово целым вектором — это называется «эмбеддинг слова».
Одна из самых популярных моделей для решения этой задачи была предложена в 2013 году. Она называется word2vec и широко используется с тех пор.
Один из способов обучения Word2vec работает примерно следующим образом: берем текст, берем какое-то слово из контекста и выбрасываем его, затем берем другое случайное слово из контекста и представляем оба слова в виде one-hot векторов. One-hot вектор — это вектор по размерности словаря, где только координата, соответствующая индексу слова в словаре, имеет значение 1, остальные 0.
Далее обучаем простую однослойную нейронную сеть без активации на внутреннем слое предсказывать следующее слово в контексте, то есть, по слову «рокетмен» предсказывать слово «вечерком». На выходе получаем распределение вероятностей для всех слов из словаря быть следующим. Так как мы знаем, какое слово было в действительности, можем посчитать ошибку, обновить веса и т.д.
Обновленные веса, полученные в результате обучения на нашей выборке и являются эмбеддингом слова.
Преимущество использования эмбеддинга вместо числа, во-первых, в том, что учитывается контекст. Популярный пример: Трамп и Путин близки по word2vec, потому что они оба президенты и часто в текстах употребляются вместе.
Для слов, которые встречались в обучающей выборке, вы просто берете матрицу эмбеддингов, берете по индексу слова его вектор, получаете эмбеддинг.
Казалось бы, все хорошо, кроме того, что некоторых слов в вашей матрице может не быть, потому что модель их не видела при обучении. Для того чтобы бороться с проблемой незнакомых слов (out-of-vocabulary), в 2014 году придумали модификацию word2vec — fasttext.
Fasttext работает следующим образом: если слова нет в словаре, то оно разбивается на символьные n-граммы, для каждой n-граммы берется эмбеддинг из матрицы эмбеддингов n-грамм (которые обучаются подобно word2vec), усредняются эмбеддинги, получается вектор.
Итого, получаем векторы для слов, которых нет в нашем словаре. Теперь мы можем вычислять похожесть даже для незнакомых слов. И, что довольно важно, есть обученные модели для русского, английского и китайского языков, например, у Facebook и проекта DeepPavlov, поэтому это можно быстро включить в свой пайплайн.
Но недостатки остаются:
- Модель не используется для вектора текста целиком. Чтобы получить общий вектор текста, нужно что-то придумывать: усреднять, или усреднять с перемножением на idf-веса, и в разных задачах это может работать по-разному.
- Вектор для одного слова все еще один, независимо от контекста. Word2vec обучает один вектор слова для любых контекстов, в которых это слово встречалось. Для многозначных слов (таких как, например, язык) будет один и тот же вектор.
Действительно, косинусная близость в нашем примере по fasttext выше, чем косинусная близость по tf-idf, даже несмотря на то, что в этих фразах общее только «в».
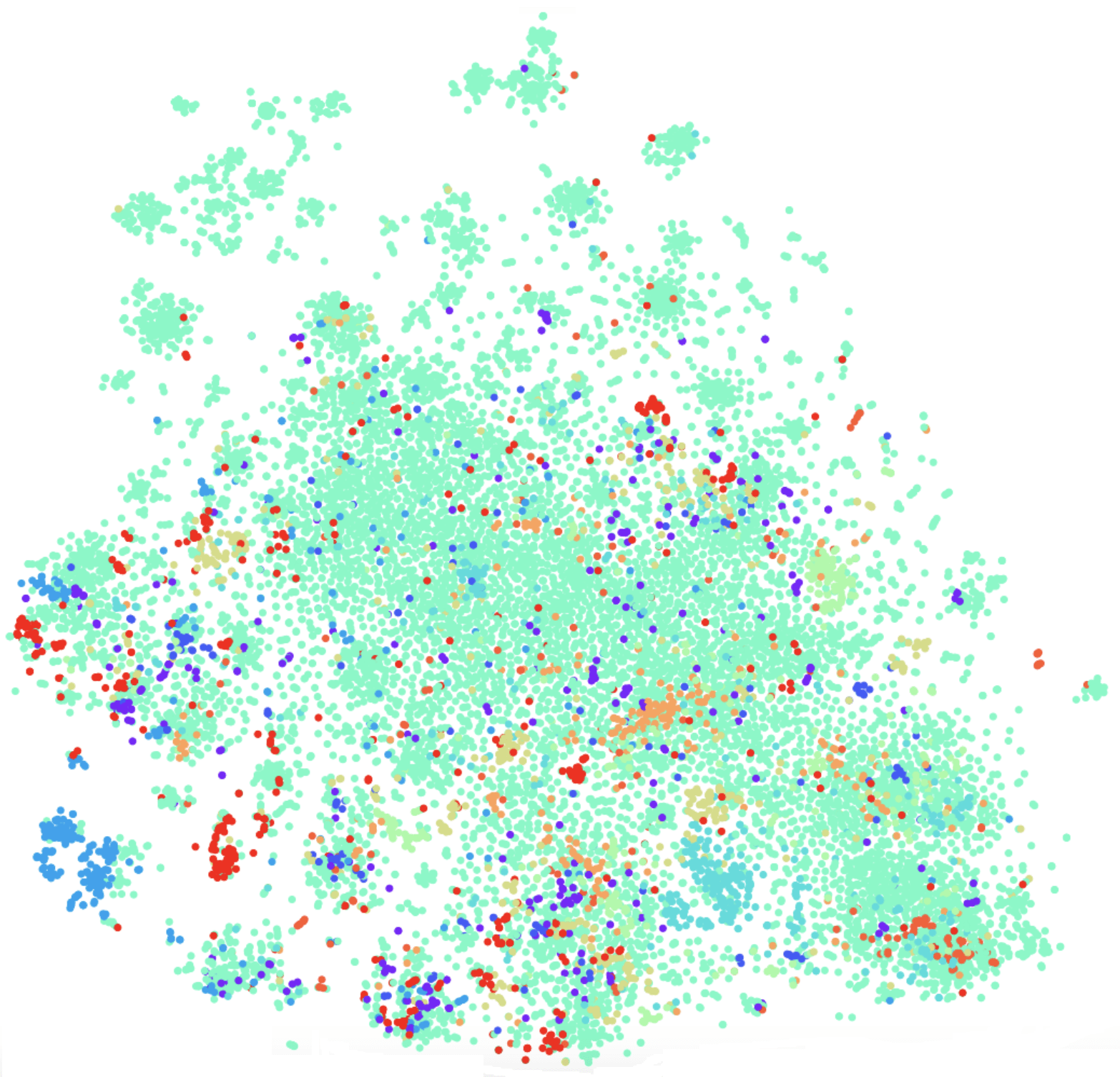
t-SNE на fasttext (топ-10 интентов), F1 score: 0,86
Однако при визуализации результатов fasttext по t-SNE разложению кластеры интентов выделяются гораздо хуже, чем для tf-idf. F1-мера здесь 0,86 вместо 0,92.
Мы провели эксперимент: объединили tf-idf и fasttext векторы. Качество получилось абсолютно такое же, как при использовании только tf-idf. Это верно не для всех задач, бывают задачи, где объединенные tf-idf и fasttext работают лучше, чем просто tf-idf, или где fasttext работает лучше tf-idf. Нужно экспериментировать и пробовать.
Давайте попробуем увеличить количество интентов (напомним, что у нас их 170). Ниже кластеры для топ-30 интентов на tf-idf векторах.
t-SNE на tf-idf (топ-30 интентов), F1 score 0, 85 (на 10 было 0,92)
Качество падает на 7 пунктов, и мы теперь не видим выраженной кластерной структуры.
Посмотрим на примеры текстов, которые начали путаться, потому что добавились еще интенты, которые пересекаются семантически и по словам.
Например: «А если открыть вклад, какие проценты по нему?» и «А я хочу открыть вклад под 7 процентов». Очень похожие фразы, но это разные интенты. В первом случае человек хочет узнать условия по вкладам, а во втором случае — открыть вклад. Чтобы разделять такие тексты на разные классы, нам понадобится что-то более сложное — deep learning.
Языковая модель
Мы хотим получить вектор текста и, в частности, вектор слова, который будет зависеть от контекста употребления. Стандартным способом получить такой вектор является использование эмбеддингов из языковой модели.
Языковая модель решает задачу языкового моделирования. А что это за задача? Пусть есть последовательность слов, например: «Буду говорить только в присутствии своего…», и мы пытаемся предсказать следующее слово в последовательности. Языковая модель выдает контекст на эмбеддинги. Получив контекстные эмбеддинги и векторы для каждого слова, можно предсказывать вероятность следующего слова.
Есть вектор размерности словаря, и каждому слову назначается вероятность быть следующим. Мы снова знаем, какое слово было в действительности, считаем ошибку и обучаем модель.
Языковых моделей довольно много, в прошлом году был бум? и было предложено очень много разных архитектур. Одна из них — ELMo.
ELMo
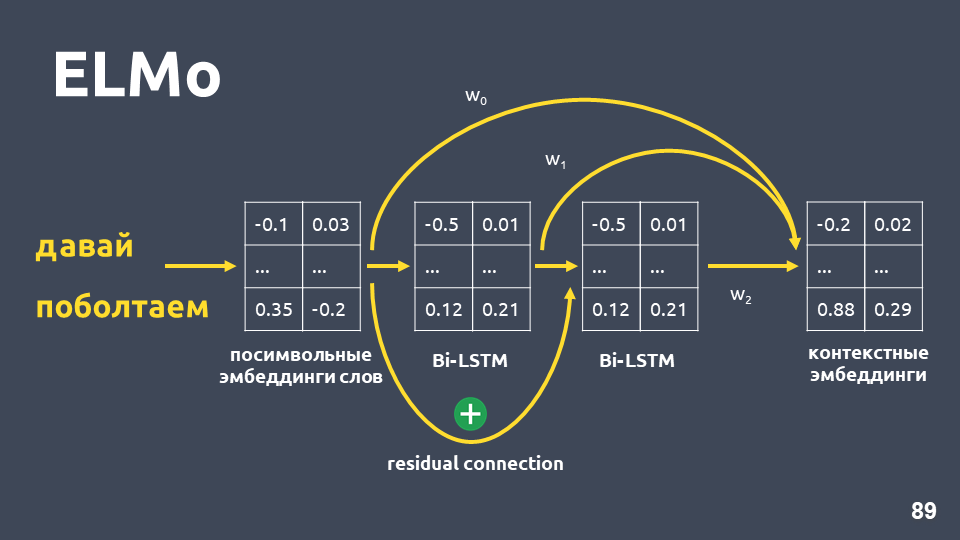
Идея модели ELMo в том, чтобы сначала построить для каждого слова в тексте посимвольный эмбеддинг слова, а потом для них применить LSTM-сеть таким образом, что получатся эмбеддинги, учитывающие контекст, в котором встретилось слово.
Рассмотрим, как получается посимвольный эмбеддинг: разбиваем слово на символы, для каждого символа применяем эмбеддинг-слой и получаем матрицу эмбеддингов. Когда речь идет только о символах, размерность такой матрицы небольшая. Потом к матрице эмбеддингов применятся одномерная свертка, как обычно делается в NLP, с max pooling в конце, получается один вектор. К этому вектору применяется двухслойная, так называемая, highway-сеть, которая вычисляет общий вектор слова.
Причем, модель построит какую-то гипотезу эмбеддинга даже для слова, которое не встречалось в обучающей выборке.
После того, как мы получили посимвольные эмбединги для каждого слова, применяем к ним двухслойную BiLSTM-сеть.
После применения двухслойной BiLSTM-сети обычно просто берутся hidden states последнего слоя, и считается, что это и есть контекстные эмбеддинги. Но в ELMo есть две особенности:
- Residual connection между входом первого слоя LSTM и ее выходом. Вход LSTM прибавляется к выходу, чтобы избежать проблемы исчезающих градиентов.
- Авторы ELMo предлагают объединять посимвольный эмбеддинг для каждого слова, выход первого слоя LSTM и выход второго слоя LSTM с некоторыми весами, которые подбираются для каждой задачи. Это нужно, чтобы учитывать как низкоуровневые признаки, так и более высокоуровневые признаки, которые дают первый и второй слои LSTM.
В нашей задаче мы использовали простое усреднение этих трех эмбеддингов и таким образом получали контекстный эмбеддинг для каждого слова.
Языковая модели дает следующие преимущества:
- Вектор слова зависит от того, в каком контексте слово употребляется. То есть, например, для слова «язык» в значении части тела и лингвистического термина получим разные векторы.
- Как и в случае word2vec и fasttext, есть много обученных моделей, например, от проекта DeepPavlov. Можно взять готовую модель и попробовать применить в своей задаче.
- Больше не нужно задумываться о том, как усреднять векторы слов. Модель ELMo выдаёт сразу вектор всего текста.
- Можно дообучить языковую модель для своей задачи, есть различные способы для этого, например, ULMFiT.
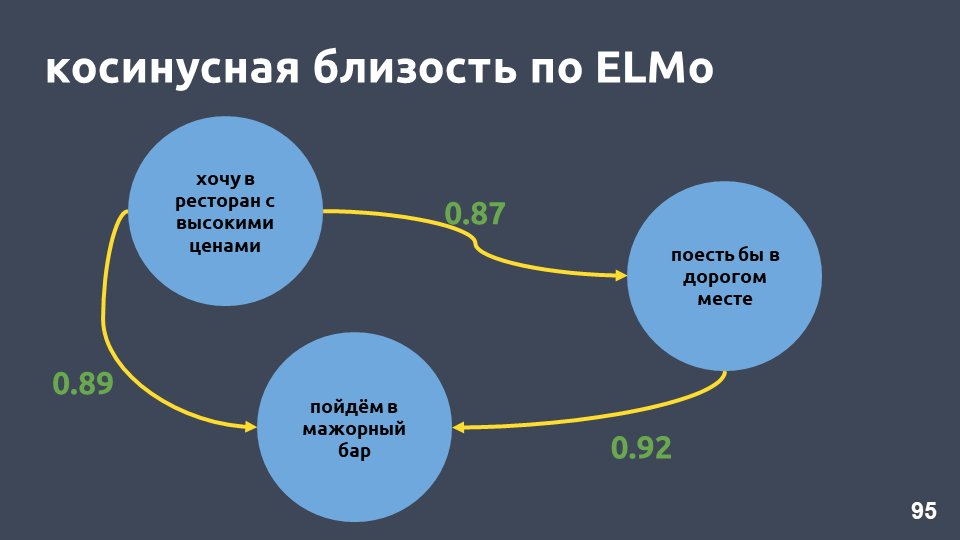
Остается единственный минус — языковая модель не дает гарантии, что тексты, которые относятся к одному классу, то есть, к одному интенту, будут близки в векторном пространстве.
В нашем примере с рестораном значения косинусной близости по модели ELMo действительно стали выше.
t-SNE на ELMo (топ-10 интентов), F1 score 0,93 (0,92 по tf-idf)
Кластеры при топ-10 интентах тоже более выражены. На рисунке выше четко видны все 10 кластеров, при этом точность чуть-чуть выросла.
t-SNE на ELMo (топ-30 интентов) F1 score 0,86 (0,85 по tf-idf)
Для топ-30 интентов все еще сохраняется кластерная структура, а также происходит прирост по качеству на один пункт.
Но в такой модели нет гарантии, что предложения «А если открыть вклад, какие проценты по ним?» и «А я хочу открыть вклад под 7 процентов» будут далеко друг от друга, хоть они и лежат в разных классах. С ELMo мы просто учим языковую модель, и, если семантически тексты похожи, то они будут близки. ELMo не знает ничего о наших классах, но можно сблизить векторы текстов одного интента в пространстве, используя метки классов.
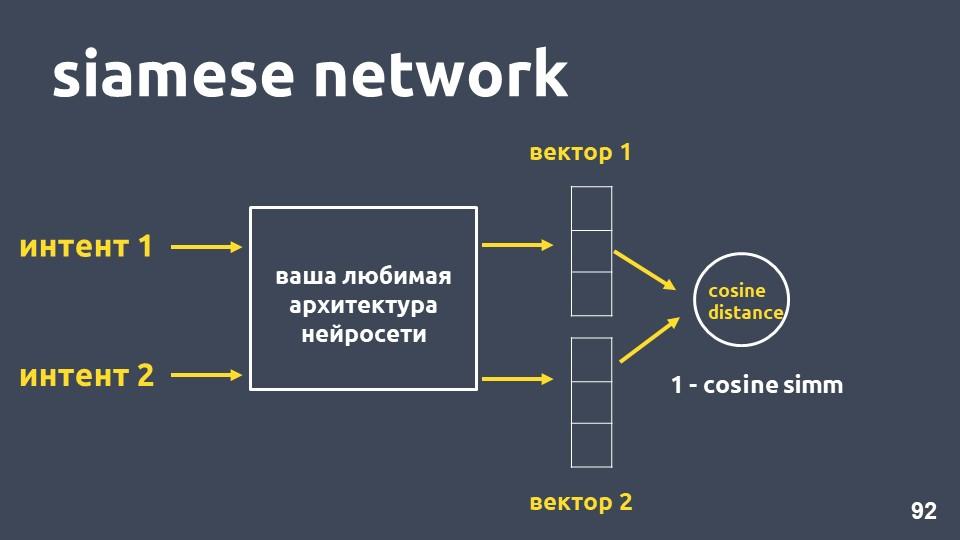
Сиамская сеть
Берём вашу любимую архитектуру нейросети для векторизации текстов и два примера интентов. Для каждого из примеров получаем эмбеддинги, а затем считаем косинусное расстояние между ними.
Косинусное расстояние равно единица минус косинусная близость, с которой мы ранее знакомились.
Такой подход называется сиамской сетью.
Мы хотим, чтобы тексты из одного класса, например, «сделай перевод» и «закинь денег», лежали близко в пространстве. То есть, косинусное расстояние между их векторами должно быть как можно меньше, в идеале — ноль. А тексты, относящиеся к разным намерениям, должны лежать как можно дальше друг от друга.
Но на практике такой способ обучения работает не так хорошо, поскольку объекты разных классов не получаются достаточно удалёнными друг от друга. Гораздо лучше работает функция потерь, называемая «triplet loss». В ней используются тройки объектов, называемые триплетами.
На иллюстрации изображен триплет: объект-якорь в синем кружочке, положительный объект в зеленом и отрицательный объект в красном кружочке. Отрицательный объект и якорь лежат в разных классах, а положительный и якорь — в одном.
Мы хотим добиться того, чтобы после обучения положительный объект был ближе к якорю, чем отрицательный. Для этого считаем косинусное расстояние между парами объектов и вводим гиперпараметр — «margin» — расстояние, которое мы ожидаем, что будет между положительным и отрицательным объектами.
Функция потерь выглядит так:
Другими словами, в ходе обучения мы добиваемся, чтобы положительный объект был к якорю ближе, чем отрицательный, хотя бы на margin. Если функция потерь равна нулю, то это получилось, и мы заканчиваем обучение, иначе продолжаем минимизировать целевую функцию.
После того, как обучили модель, мы еще не получаем классификатор, это просто метод для получения таких эмбеддингов, что объекты, которые лежат в одном интенте, скорее всего, будут иметь близкие векторы.
Когда мы получили модель, мы можем использовать другой метод классификации поверх эмбеддингов. Хорошо подойдет kNN, поскольку мы уже добились того, чтобы эмбеддинги были с ярко выраженной кластерной структурой.
Напомним, как работает kNN для текстов: берем элемент текста, получаем для него эмбеддинг, переводим его в векторное пространство, и затем смотрим, кто его сосед. Среди соседей считаем самый частый класс и заключаем, что новый объект принадлежит этому классу.
Размерность эмбеддингов, которые мы используем, равна 300, а в тренировочной выборке около 500 000 объектов. Стандартные методы поиска ближайших соседей нам не подходят по производительности. Мы использовали метод HNSW — Hierarchical Navigable Small World.
Navigable Small World — это связный граф, в котором мало ребер между вершинами, которые находятся на большом расстоянии, и много ребер между близкими вершинами. В нашем случае, длина ребра будет определяться косинусным расстоянием, т.е. для тренировочной выборки мы вычисляем расстояние между всеми примерами интентов, потом выбрасываем случайным образом очень большие расстояния так, чтобы граф все еще оставался связанным.
После этого разбиваем граф на уровни, отсюда в названии Hierarchical. На каждом уровне содержится только некоторое подмножество вершин, причем такое, что каждый следующий уровень содержит все вершины, которые есть на предыдущем. На каждом уровне мы проводим случайное выбрасывание ребер с сохранением связности графа.
Затем берем случайную вершину на первом уровне, смотрим, кто из ее соседей ближе всего к той точке, для которой мы ищем соседей, и двигаемся к соседу случайной вершины.
Затем перемещаемся на следующий уровень, повторяем процесс до тех пор, пока не наберем нужное количество таких соседей, что, скорее всего, они будут самыми близкими к начальной вершине. Это приближенный метод, то есть нет гарантии, что мы найдем самых близких соседей в каждом случае, но у него очень хорошая полнота — около 0,95-0,99, в зависимости от настроек.
Более того, преимуществом использования метода ближайших соседей является то, что при добавлении нового интента, который не слишком пересекается по словам с уже существующими интентами, необязательно переобучать всю модель. Можно просто добавить новые точки в векторное пространство и автоматически начать классифицировать новый класс.
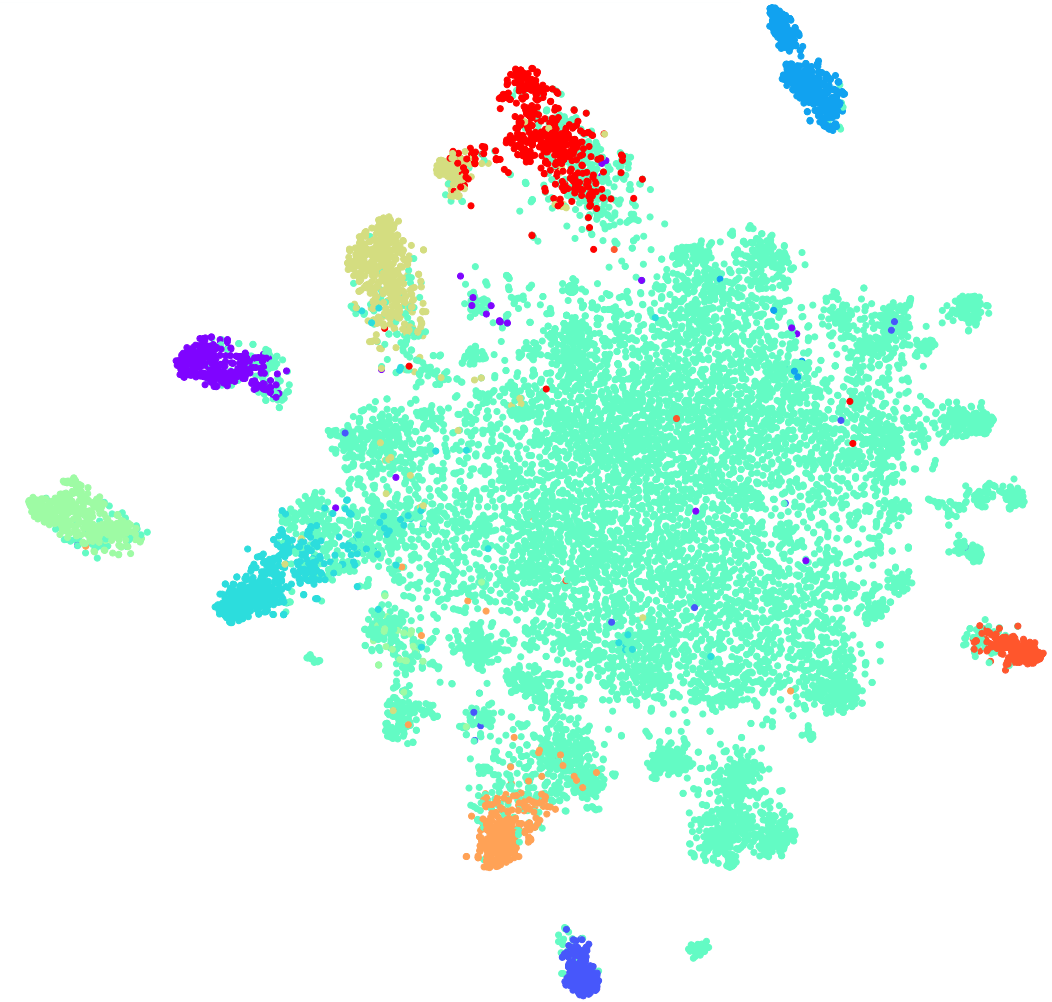
Давайте посмотрим, какой прирост дает использование сиамской сети. Ниже на графике видно, что все интенты образуют отдельные кластеры. В таком случае даже линейная модель позволит неплохо разделить пространство.
t-SNE на siamese (топ-10 интентов), F1 score 0,95 (0,93 по ELMo)
t-SNE на siamese (топ-30 интентов), F1 score 0,87 (0,86 по ELMo)
Для 10 интентов мы получили прирост на два пункта по сравнению с языковой моделью ELMo, для 30 — на один, при этом кластерная структура все еще сохраняется.
Итоги
Метод использования шаблонов и словарей вполне допустим, если у вас немного интентов, например, 2-5, когда они хорошо разделимы и действительно описываются словарями или шаблонами. Он может хорошо сработать, если в классе мало примеров, в нашем случае это могут быть намерения пользователей, для которых не более 20-30 вариантов формулировок. Тогда нет смысла строить сложные модели, можно обойтись словарями.
Если интентов больше, но при этом они хорошо разделяются, у них мало пересекающихся слов, можно обходиться стандартными линейными моделями поверх tf-idf. Такие модели быстро обучаются, и с ходу дают хорошее качество, которое еще можно повысить, если поработать с выборкой и настроить параметры.
Если требуется учитывать перефразирование, обратите внимание на word2vec и fasttext. Это рабочие модели, несмотря на то, что в нашей конкретной задаче они не дали прироста. В вашей задаче классификации текстов их стоит попробовать, тем более это так же быстро, как и использовании более простых векторных представлений, потому что есть предобученные модели.
Чуть больше времени, скорее всего, займет обучение ELMo. Если вам понадобится дообучиться на своих данных, то, конечно, нужно будет разобраться с техническими деталями, но все это тоже не слишком долго, зато можно получить значительный прирост качества. Особенно хорошо сработает ELMo, когда в задаче требуется учесть семантические особенности текстов, то есть когда к одному классу относятся близкие по смыслу предложения.
Если же тексты из разных классов в задаче классификации сильно пересекаются по смыслу, то придется использовать что-то более продвинутое. В нашем случае хорошо сработала сиамская сеть. Применение этого метода займёт больше времени, потому что как минимум для обучения такой сети нужно много примеров из каждого класса. То есть, в нашем случае, каждое намерение нужно было представить большим количеством положительных и отрицательных примеров. Кроме того, нужно придумать подходящую нейронную архитектуру, протестировать несколько вариантов и т.д. Но эта работа окупится, и вы получите хороший прирост качества.
| F1-score | ~2-5 интентов разная лексика |
~10 интентов разная лексика |
~30 интентов похожая лексика |
| шаблоны, словари | для MVP | лучше не надо | вам не понравится |
| ML + tf-idf | хм | 0,92 | 0,85 |
| ML + fasttext | зачем? | 0,86 | 0,82 |
| ELMo | зачем?? | 0,93 | 0,86 |
| siamese | серьезно??? | 0,95 | 0,87 |
- rusvectores.org/ru/models
- docs.deeppavlov.ai/en/master/intro/pretrained_vectors.html
- www.mihaileric.com/posts/deep-contextualized-word-representations-elmo
- omoindrot.github.io/triplet-loss
- towardsdatascience.com/review-highway-networks-gating-function-to-highway-image-classification-5a33833797b5
- habr.com/ru/company/mailru/blog/338360
- http://jalammar.github.io/illustrated-bert
Заголовок этой статьи — «Deep Learning vs common sense» — хорошо отражает наш подход к конференции UseData Conf. Следуя идее, что в каждом продакшен-решении необходим здравый смысл, мы собрали программу из 18 докладов о применении машинного обучения в практических задачах, в которых нет усложнения ради усложнения, а есть реально работающие подходы и результаты адекватные требованиям бизнеса.
Если вам надоело раз за разом самому придумывать, как применить алгоритмы из статей к реальным данным, или вы хотите знать, как современные методы машинного обучения могут помочь вашему проекту, ждем вас 16 сентября на UseData Conf.
ebt
Очень многообещающие, на мой взгляд, вещи для чат-ботов — это сохранение контекста (Какая погода в Питере? А в Нижнем?) и семантический вывод (Какие швейцарские кантоны граничат с Италией?). Как у вас с Олегом обстоят с этим дела?