Вы прочитали миниатюру о конфликте двух миров — промышленности и аналитики. Мы как раз из последнего, и вот как все выглядит для нас: с одной стороны — созданные для управления оборудованием и недоступные для простых смертных протоколы обмена данными с большим количеством цифр в названии. С другой — аналитические системы, красивая отчетность, удобные дэшборды и прочие приятности.

Не каждое производство дошло до высокого технологического уровня. Но помогать нужно всем. На фото кадр из х/ф «Завод».
В этом посте мы расскажем, как стараемся вылепить производству человеческое (по меркам простого дата-сайентиста) лицо — дать возможность бизнес-аналитикам обрабатывать промышленные данные и пользоваться красивой BI-отчетностью.
Что мы имеем сейчас
Недавно мы были в гостях у одной газоперерабатывающей компании. Компания большая, несколько заводов объединяет. Зашли в диспетчерскую. Оборудовано там все очень здорово: у каждого диспетчера по 6-8 мониторов, а на стенах огромные плазмы. Вот только содержимое этих плазм… оставляет желать лучшего. Странного вида карта, дурацкие стрелочки, поверх этого окошки из Windows, которые пережили страшные пытки и показывают какие-то цифры.
«Почему так вырвиглазно?» — спрашиваем мы. «Это лучшее, что можно выжать из наших промышленных систем» — слышим в ответ. Время реакции диспетчера на инцидент обычно не должно превышать 30 секунд, но с таким интерфейсом уложиться непросто. Никаким BI здесь и не пахнет.
Еще одна неинтерфейсная история. Приходят на завод дата-сайентисты и говорят: «Дайте вот эти данные по вашей установке, и мы с 95%-ной точностью сможем прогнозировать проблемы в ней». Ну, по крайней мере, они так обещают. На заводе кивают, и для дата-сайентистов начинается сценарий в лучших традициях Кафки. Точечный сбор данных. По сотне систем. Для каждой нужно написать пять заявлений. Приложить личную биографию и родословную до пятого колена. Сдать все анализы, приложить их к эссе на свободную тему и подловить хорошее настроение начальника. И только тогда можно рассчитывать на успех. Точнее, надеяться.
Заводская аналитика
Чтобы решить проблемы, подобные тем, что описаны выше, нужно подружить промышленность с аналитикой. Для этого мы строим единую систему с комплексной архитектурой. Такая система умеет работать с совершенно разными типами данных и на их основе решать аналитические задачи. Строим именно систему с комплексной архитектурой, а не что-то универсальное, потому что универсальные системы решают любые задачи одинаково плохо. В комплексной архитектуре мы объединяем инструменты аналитики разных типов данных. Вот как это может выглядеть:
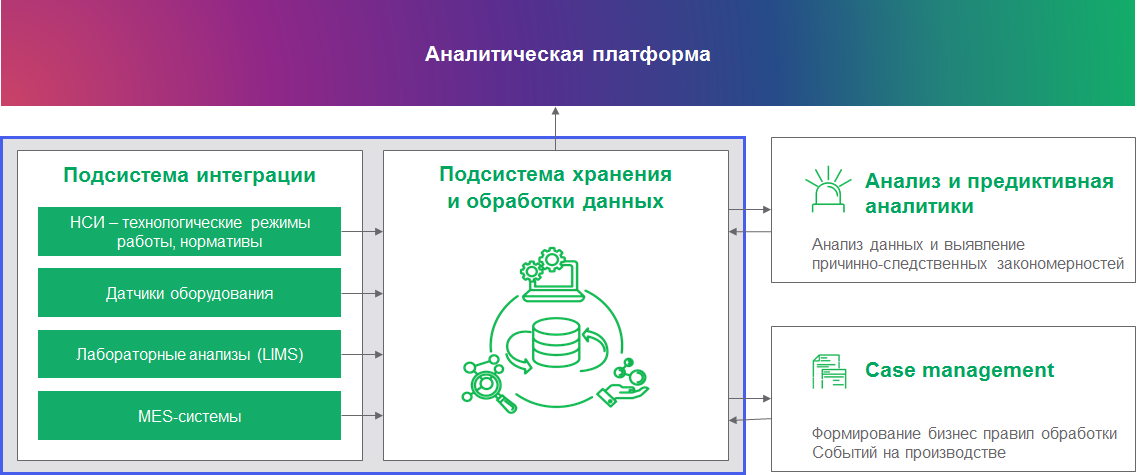
Типов данных на производстве немало. Есть классические реляционные данные из бизнес-систем и учетных систем. Есть данные с датчиков оборудования — временные ряды. Есть события из видеоаналитики — их складывают в даталэйк и делают по ним комплексный мониторинг (сейчас это популярная тема). Есть логи из бизнес-систем, которые нужно индексировать для последующей обработки (мы используем Apache Solr), чтобы получить реальную картину происходящего на производстве с учетом камер наблюдения и оценить, как операторы реагируют на те или иные события. И это еще не все, у каждого производства свое сочетание требований. А в итоге всю работу с данными стоит связать в рамках единой экосистемы, которая позволит собирать данные в централизованное хранилище с гибкой настройкой доступа и едиными инструментами анализа.
Недавно был у нас проект: организовать мониторинг технологического режима работы завода, а также качества сырья. Система мониторинга должна отслеживать в реальном времени все важные показатели и сверять их с нормативами по весьма оригинальным формулам. Из одной базы данных мы берем лабораторные анализы сырья, из другой — показатели работы оборудования.
В итоге оператор получает комплексную картину происходящего в его установке: на что нужно обратить внимание, стоит ли остановить работу и насколько все серьезно. По каждому отклонению от нормативной работы оператор должен зафиксировать причину сбоя. Таким образом, растет база знаний по случившимся инцидентам.
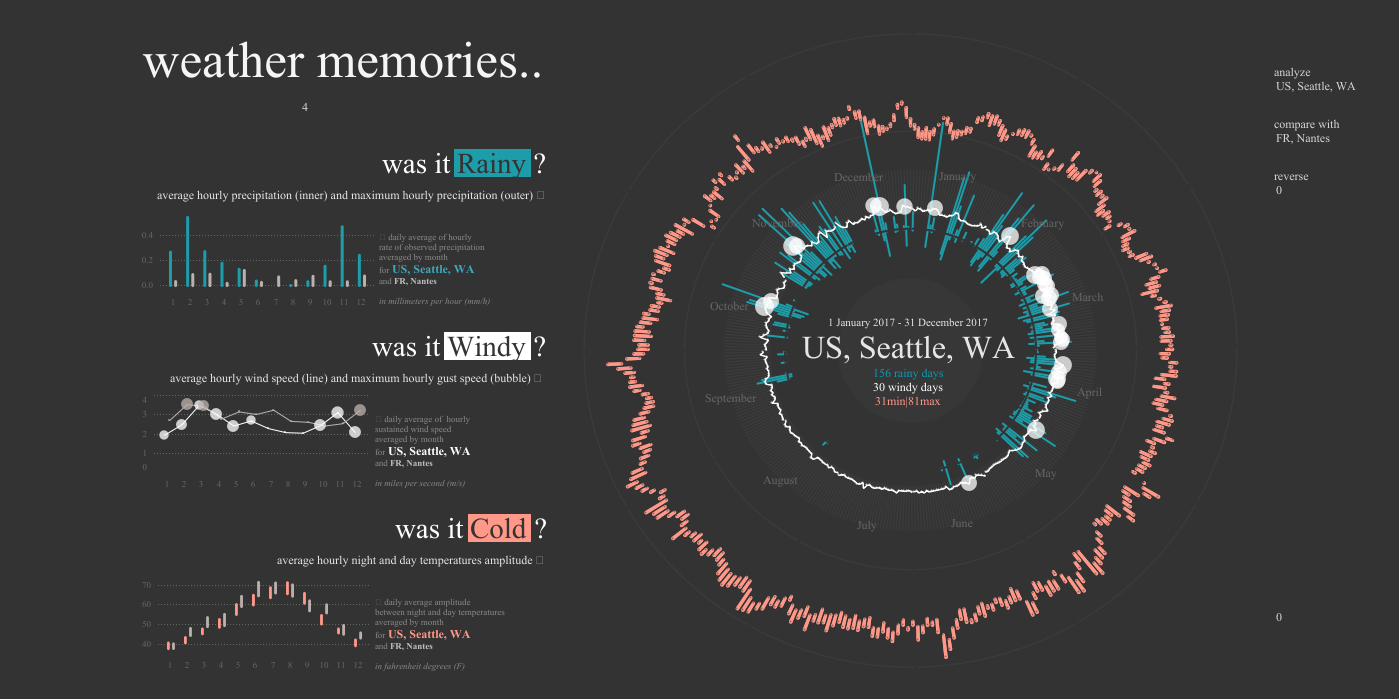
При этом вся аналитика отображается через красивую и удобную BI-систему. Она позволяет не только строить простую отчетность, но и создавать понятные и интуитивные информационные панели (дашборды). И это еще один аргумент, почему так важно подружить промышленные данные с аналитическими системами. По соображениям NDA мы не можем показать дашборды с этого проекта, но приведем для контраста публичные примеры подходов к визуализации BI систем и промышленных систем.
Вот как могут выглядеть отчеты BI:
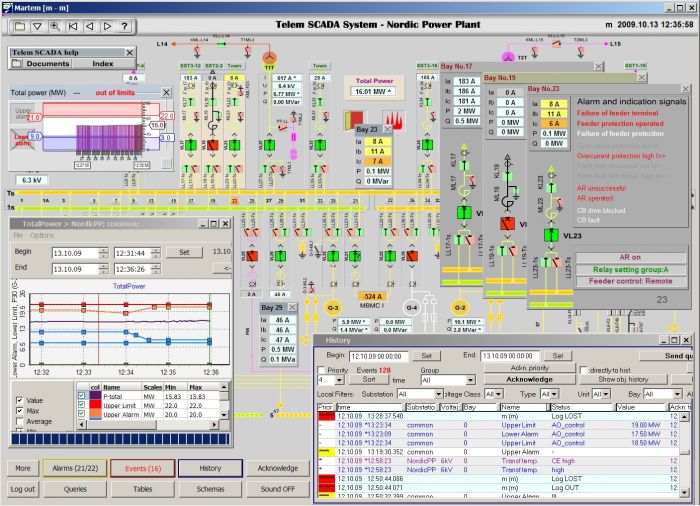
А вот интерфейс SCADA:
В рамках развития нашей платформы мы рассматриваем подключение средств предиктивной аналитики, которая выявляет причинно-следственные закономерности. Разные причины приводят к разным вариантам развития событий. Например, плохое качество сырья или неверная настройка оборудования после планового техобслуживания могут повлечь за собой снижение качества конечной продукции или выход оборудования из строя.
Одним из ключевых требований к системе аналитики является скорость получения информации. Это сбор телеметрии с датчиков и расчет показателей (план/факт агрегационнных показателей по цеху) в режиме near real-time. Это позволяет корректировать оперативное управление производством.
Примерно так все работает в дивном новом мире. Но в реальности есть нюансы.
Анализ промышленных данных, или головная боль бизнес-аналитика на производстве
Как свести данные промышленных систем (которые толком никто не собирает) в удобном для дата-аналитики виде? Один из стандартных протоколов для промышленных данных — OPC DA/HDA. Он вроде как является открытым, но доступ к его спецификации имеют только участники консорциума. Членство в консорциуме стоит дорого, а стабильных открытых реализаций этого протокола не существует.
Для того, чтобы связать этот и другие промышленные протоколы с современными системами аналитики, мы создаем для каждого протокола шлюзы. Этим занимается отдельная команда промышленных решений. Большое количество цифр в названиях протоколов их только вдохновляет. Команда имеет опыт написания промышленных коннекторов (например, по протоколу OPC DA/HDA, с использованием PI SDK и пр.).
А вот для связи промышленных протоколов с миром big data мы используем Apache NiFi — инструмент из экосистемы Hadoop, который позволяет реализовать интеграцию в потоковом режиме обработки.
Проложив этот самый важный мост между промышленностью и аналитическими системами, мы смогли решить задачу на привычном нам стеке Hadoop. В промышленных проектах мы чаще всего используем дистрибутивы нашего отечественного партнера Arenadata. С помощью Apache Phoenix мы выбираем данные по JDBC при помощи SQL. В последних версиях Phoenix был хорошо оптимизирован для работы с временными рядами, которые всегда появляются в промышленных проектах.
Мы смогли закрыть комплексную аналитическую систему продуктами одного вендора, что важно, когда речь заходит об enterprise-решениях. Для расчета уставок (отклонений в режимах работы оборудования), расчетных показателей и других KPI используется Apache Spark — компонент для выполнения распределенных вычислений в режиме near real-time в рамках экосистемы Hadoop.
Нюансы
Увы, с промышленными протоколами все сложно. В первый раз, когда мы планировали делать интеграцию с PI, то рассчитывали, что возьмем его стандартный JDBC-интерфейс и будет нам простое и быстрое счастье. А когда начали с интерфейсом работать, оказалось, что его пропускной способности недостаточно даже для того, чтобы грузить текущие данные. Не говоря уже о загрузке истории. Но у коннектора есть свой внутренний API SDK, который умеет быстро работать с данными. Так что мы написали на этом API специальный шлюз и решили проблему.
Мы подошли к решению этой задачи таким образом, чтобы в итоге получилось представление периодов отклонений в виде витрины. Для этого нужно было посчитать, сколько раз и когда показатели выходили за пределы нормы. Если анализировать всю историю в поисках отклонений, это потребует много ресурсов. Так что мы просто проходили по ряду значений, сравнивая каждое последующее и предыдущее. Если оба в норме/не в норме — отклонения нет/оно продолжается. Если одно из двух не в норме — засчитываем, соответственно, начало или конец отклонения. Так мы смогли сэкономить вычислительные мощности при создании витрины со статистикой для аналитиков и технологов.
Перспективы
Цель этих проектов в промышленности — не только сделать все красиво и понятно, но и подготовить аналитическую платформу для производства, перейти к цифровому предприятию, где есть возможность собирать и анализировать все события в одном месте.
Что касается описанной платформы, то она полезна сразу нескольким подразделениям. Мы решили задачу людей, которые управляют производством. Если раньше операторы могли не реагировать на незначительные отклонения в работе оборудования, то сейчас им приходится отчитываться перед руководством за каждое несоответствие норме. Это обеспечивает value в данный момент. Цифровизаторам и R&D-службам мы дали удобный источник информации о производстве, который позволяет анализировать любые события за любой промежуток времени — это обеспечит value в будущем.
Сейчас мы активно занимаемся развитием таких технологичных платформ, экспериментируем с реализацией. В общем, стремимся отодвинуть промышленность подальше от ручного управления к автоматизации контроля производства, как на заводах у Илона Маска.
Мы будем рады пообщаться со всеми — как с разработчиками и архитекторами big data (которых можем пригласить в нашу команду), так и с цифровизаторами, руководителями производства, рассказать им о нашем опыте и предложить варианты совместной работы. Для всех желающих мы проводим big data-митапы, на которых с радостью готовы обсудить все вопросы и предложения.
Моя почта — EOsipov@croc.ru
Комментарии (25)

irsdkv
12.09.2019 14:17+2Вот как могут выглядеть отчеты BI
А вот интерфейс SCADA
Вот как может выглядеть кит:
кит.img
А вот табурет:
старый_табурет.img
Время реакции диспетчера на инцидент обычно не должно превышать 30 секунд, но с таким интерфейсом уложиться непросто. Никаким BI здесь и не пахнет.
И не должно там пахнуть BI.
Не буду спорить, многие интерфейсы систем АСУ ТП «режут глаз» сильнее, чем того требуют информативность и обратная совместимость (попробуй объясни 50-ти летней тете Маше что теперь давление в трубопроводе будет отображаться на другой стороне экрана, а после того как объяснишь — попробуй поверить в то, что она точно не перепутает это в критической ситуации), но сравниваются всё-таки разные вещи.
Supervisory Control And Data Acquisition — диспетчерское управление и сбор данных (Wiki).
Когда, в бытность еще студентом, я рисовал интерфейсы для реального заводского участка, были требования по информативности для оператора установки. Если он увидит перед собой интерфейс костюма Тони Старка он, наверное, ахнет (одобрительно при возрасте до 30-ти, матерно в противном случае), но это нисколько не поможет ему принимать решения в процессе работы. Интуитивность интерфейсов хороша, но только до того момента, пока он, интерфейс, предоставляет всю необходимую для принятия решения информацию. А такой информацией могут быть десятые (и меньшие) доли процента от какого-либо показателя или даже комбинация из нескольких параметров. А всего этих параметров могут быть десятки.
BI — уровень принятия решений в бизнесе, а не на технологической установке.
Скорее всего авторы понимали всё это, но в статье акценты расставлены странно.EgorOsipov Автор
12.09.2019 16:18Идея, что BI подходит только для принятия решений в бизнесе, мне видится не совсем точной. Действительно, это инструмент, который родился из решения задач бизнес-аналитики. Но мне кажется, что идея немного посмотреть вокруг и принести новые практики и инструменты из других отраслей — это то, что сейчас происходит во многих сферах и именно это дает существенный эффект в развитии. И чем более консервативна отрасль, тем больше аргументов это сделать.
Вы довольно удачно подметили: прямое сравнение в лоб BI и SCADA — это не совсем корректно. Но мы действительно сталкивались с ситуациями, когда в весьма современных компаниях, в прекрасно оборудованных диспетчерских на гигантских настенных плазмах отображались настолько неинтуитивные и неинформативные интерфейсы (тут мы сходились с мнениями с диспетчерами), что для нас это выглядело дико. То есть способ отображения информации мешал ее восприятию. BI инструменты сейчас позволяют отображать информационные панели в близком к реальному времени, но самое главное — они позволяют сделать это эргономично для пользователя, что, как мне видится, важно для оперативного реагирования.
Мы не призываем срочно менять одно на другое, если что :) Если тетя Маша всю жизнь эффективно работала с этим интерфейсом, то худшим решением будет идти и перевнедрять его на что-то модное. Но я верю, что за счет новых, часто непривычных подходов можно получать новое value. Если подходить с умом, конечно.
И в любом случае, BI тут — это лишь один из инструментов аналитики промышленных данных. Если вы собрали все промышленные данные в одном месте, интегрировали в эту среду данные из бизнес-систем, то для вас открываются весьма большие возможности, точно не ограничивающиеся их визуализацией.irsdkv
12.09.2019 18:50В такой постановке вопроса я полностью согласен с вами!
Все только выиграют если разработчики автоматизации и операторы будут иметь удобные, современные и гибкие инструменты для визуализации процессов, а не только вырвиглазные, громоздкие и несущие на себе тяжесть десятилетий TIA Portal-ы.
Хочется только пожелать вам удачи, т.к. и промышленному ПО давно пора перейти в 21-й век :)
skrimafonolog
13.09.2019 18:59Но я верю, что за счет новых, часто непривычных подходов можно получать новое value.
Это какой то сленг вашей области?
Потому как с точки зрения программиста фраза выглядит странно. «Получить новое значение» — и что?EgorOsipov Автор
13.09.2019 18:59В данном случаем я использовал термин value в значении «ценность». Речь идёт о том, что использование новых подходов приносит пользу )
skrimafonolog
14.09.2019 07:49А зачем по английски?
Я понимаю, когда не хватает переведенной терминологии в каких-то узких областях. Но здесь-то?
Слово «ценность» вполне понятно и уместно.
Или в английском изложении есть какой то тайный подсмысл?
somurzakov
12.09.2019 18:07а что старые интерфейсы АСУ ТП выдавали информацию как есть с датчиков, однако можно с внедрением умной аналитики, комбинирования показателей со всех систем и выставления порогов пробоя просто упростить весь интерфейс до одной лампочки — красная=тревога, желтая=обратить внимание, зеленая все хорошо
и показывать именно точечно показатели которые выходят из пределов допустимых значений, а не в нормеirsdkv
12.09.2019 18:39Если интерфейс можно сократить до одной лампочки то оператор там становится лишним, а значит и интерфейс SCADA отпадает, т.к. смотреть на него уже некому :)
Конечно, эта лампочка просто будет показываться на следующем уровне иерархии (если узел не будет отдан под управление программному/аппаратному автомату), рядом с другими лампочками. Но если вдруг трех цветов станет недостаточно то мы опять переходим к численным показателям, т.к. с цветом мозг человеческий работает по правилам, неприменимым для принятия операционных решений с техническими системами.
показывать именно точечно показатели которые выходят из пределов допустимых значений, а не в норме
Хотелось бы, чтобы так было, но на практике все более или менее сложные системы, с которыми я сталкивался, требуют того, чтобы оператор видел точные показатели всегда. Потому что инерциальность и сложность некоторых из них настолько велика, что оператор без «лога» двух последних часов у себя в голове просто не сможет понять что, где и когда пошло не так.
На правах свободного полета творческой мысли, мне кажется что в самом описании проблемы кроется противоречие.
Как только мы сможем сократить вывод до красной/зеленой лампочки — мы автоматически переходим на следующий уровень иерархии и проблема снова восстает уже на нем. Единственным возможным вариантом, при котором можно будет сказать «мы победили» будет только описанная в статье ситуация, доведенная до крайности:
Сидят инженер, менеджер, аналитик и директор и смотрят на красивые и понятные графики, светящиеся всеми цветами радуги, попадающие прямо в подсознание, в котором складывается верная и полная картина происходящего.
Но, к сожалению, это кажется мне скорее зарисовкой для фантастического рассказа, пока что.somurzakov
12.09.2019 20:10ну как сказать, белковые организмы должны делать то, что делают хорошо они (эскалация руководсту, реакция на мониторинг, расследование с ответственными спецами на самом нижнем уровне — работа с людьми по сути)
А кремниевые организмы должны делать то, в чем хороши они — сбор, хранение, обработка и корреляция данных, реалтайм обработка и визуализация и т.д. — то что нужно делать монотонно, аккуратно и всегда, без перерывов на обед и туалет.
и эту работу можно детализировать/аггрегировать по уровням: датчик/оборудование/цех/завод и т.д. и показывать каждому руководителю свои «лампочки» по их зоне ответственности
opetrenko
14.09.2019 17:34Кой-чего можно почерпнуть из dark cockpit concept в авионике. Лампочки неподелу не горят. А когда горят — правильным цветом.
Да, заточить так интерфейс — очень много работы.
Интересно, есть гайдлайне по теме? Поделитесь если знаете.
korsarer
12.09.2019 16:46+2Я не разглядел в статье примеров ваших работ, где видна дружба Big Data и промышленности. Если таковые есть — где можно на них поглазеть? Хочется верить, что у вас есть неплохие результаты =)
EgorOsipov Автор
12.09.2019 17:43Заказчики не очень любят, когда на них напрямую ссылаются в публичных источниках.
Пишите на eosipov@croc.ru, обсудим кейс)
Komrus
12.09.2019 17:17+1Увидел замечательное заглавное фото. С вполне характерными станками. Начал читать. Но, увы, так и не нашёл вменяемой информации на тему Как свести данные промышленных систем (которые толком никто не собирает) куда-нибудь.
Особено, в условиях, когда у станка (например — изображеном на заглавном фото) нет никаких штатных интерфейсов.
Вот какие есть у Вас замечательные кейсы по подключению нештатных датчиков (чтобы получить хоть-какую-нибудь инфомрацию со станка) и прочие низкоуровневые проблемы — и хотелось бы видеть

BalinTomsk
12.09.2019 19:09---Не каждое производство дошло до технологического уровня Tesla
Это наверное была шутка?
Несколько недель назад американский телеканал деловых новостей CNBC со ссылкой на «многочисленные» анонимные источники «из числа нынешних и бывших сотрудников Tesla» рассказал о проблемах на Гигафабрике 1 в Неваде. Они рассказали, что сборка на конвейере частично выполняется дедовскими методами — вручную, практически без использования роботов.
habr.com/ru/post/411041
sshikov
12.09.2019 19:27Spark в контексте near real time смотрится странно. Если это просто спарк, не стриминг, то при запуске на хадупе он попадает в обычные очереди планировщика Yarn, где ни о каком near real time даже близко речи не идет. Можете пояснить?
EgorOsipov Автор
13.09.2019 11:29Конечно, мы используем Spark Streaming, который позволяет работать с относительно небольшой latency. Плюс сейчас уже существует функциональность Continuous Streaming, что позволяет снизить latency еще больше.
Мы еще смотрели в сторону Akka и Flink, но сейчас остановились на Spark. Во многом потому, что на рынке существует много людей с неплохими компетенциями по Spark и нам этот фреймворк был очень хорошо знаком на момент начала этих проектов.

Ryav
12.09.2019 22:27Советую взглянуть на System 1 от BN (GE), в которую помимо вибропараметров с рэка BN можно заводить и иные данные по технологическому процессу, а уже на основе их писать сценарии. При этом, насколько я помню, у них уже имеются немало заготовок по типовому роторному оборудованию.
Система подразумевает раздельное использование со SCADA, однако паставленную вами задачу вполне решает.
deniskreshikhin
12.09.2019 23:20> Не каждое производство дошло до технологического уровня Tesla или Foxconn. Но помогать нужно всем. На фото кадр из х/ф «Завод
Забавно, но фильм снимали на работающем предприятии =)
nZidan
13.09.2019 18:59У нас в Казахстане Назарбаев выдвинул лозунг «ЦИФРОВИЗАЦИЯ производства», потом такое же повторил Путин. Думал почитав статью z пойму, что имеется ввиду под старыми подобными коммунизму лозунгами. Вот конвеерное производство Форда понятно сразу, это скорость выпуска продукции, понижение себестоимости продукции.
Но увы так и не понял, что они улучшили засунув свои дашборды в диспетчерcкую, которая не нуждается в графичках с элементами ML/BigData
Вот если бы Ваша система повлияла на скорость и удешевления выпуска продукцииEgorOsipov Автор
13.09.2019 18:59Давайте расскажу на примере проектов, на основании которых написана эта статья.
Мы решали задачи двух подразделений – цифровизаторов и производства. Перед цифровизаторами стояла задача сделать систему, в которой агрегированы все данные производства и бизнес-данные. Для чего это нужно – понятно, если вы хотите построить какую-то аналитику, какие-либо ML модели, вам сначала необходимо собрать все данные в одном месте. Но на практике сложно решать задачу цифровизаторов, не дав никакой ценности производству. Такие проекты обязательно должны иметь прикладную часть.
И это как раз это один из бизнес кейсов использования всей этой техники под названием bigdata. Система может мониторить не только показатели оборудования (давление, температуру в печи и т.д.) но и показатели качества как сырья, так и готовой продукции. На текущем шаге мы увязывали эти показатели в рамках технологического процесса, так у операторов есть возможность быстро принимать управленческие решения, и не допускать или снижать % возможного брака продукции и повышать качество. На текущий момент также прорабатывается один из кейсов оптимизации режимов работы оборудования с целью повышения скорости изготовления продукции. В данном кейсе как раз прямой экономический эффект, чем быстрее производиться продукция, тем меньше общехозяйственных затрат приходиться на единицу продукции, соответственно производство становиться эффективнее.
McKinseyBA
EgorOsipov Автор
Честно говоря, цена поддержки здесь меньше всего играет роль. Мы очень долго занимались выбором дистрибутива для этих проектов, это был очень не простой вопрос для нас, так как у нас есть проектный опыт и на Cloudera, и на HW, и на Arenadata. Но глобально было три аргумента:
1. Набор продуктов. Когда мы начинали эти проекты, Cloudera еще не анонсировала свой Cloudera DataFlow, а мы видели, что для наших задач прекрасно подходит NiFi. Аналогичная же история с Phoenix. Поэтому вариант c Cloudera не подходил.
2. Мы делаем достаточно инновационные штуки, и в таких случаях очень удобно держать плотный контакт с вендором. При этом HW на тот момент был не очень заинтересован в российском рынке.
3. У многих компаний, для кого мы создавали это решение, есть фокус на импортозамещение. Соответственно, в этих компаниях не получится использовать другой дистрибутив, когда есть отечественный аналог. Невозможно будет пройти архитектурный комитет.
McKinseyBA
1-2. Вы правы, я забыл, что HW был куплен и начал растворятся в Cloudera лишь год назад.
3. Так и подумал, что импортозамещение — единственное объяснение :-)
PS: если NDA позволит, то было бы круто посмотреть под капот решения (на чем писали в Spark, объем и количество потоков интеграций, интересные примеры кода и т.д.)