
Компания «УРУС» попробовала Kubernetes в разных видах: самостоятельный деплоймент на bare metal, в Google Cloud, а затем перенесла свою платформу в облако Mail.ru Cloud Solutions (MCS). Как выбирали нового облачного провайдера и как удалось мигрировать к нему за рекордные два часа рассказывает Игорь Шишкин (t3ran), старший системный администратор «УРУС».
Чем занимается «УРУС»
Есть много способов улучшить качество городской среды, и один из них — сделать ее экологически безопасной. Как раз над этим работают в компании «УРУС — Умные цифровые сервисы». Здесь внедряют решения, которые помогают предприятиям контролировать важные экологические показатели и уменьшать негативное влияние на окружающую среду. Датчики собирают данные о составе воздуха, уровне шума и другие параметры, а затем отправляют их в единую платформу «УРУС — Экомон» для анализа и составления рекомендаций.
Как устроена работа «УРУС» изнутри
Типичный клиент «УРУСа» — компания, которая располагается в жилой зоне или рядом с ней. Это может быть завод, порт, железнодорожное депо или любой другой объект. Если наш клиент уже получал предупреждение, был оштрафован за загрязнение окружающей среды или сам хочет издавать меньше шумов, снизить количество вредных выбросов, он приходит к нам, и мы уже предлагаем ему готовое решение по экологическом мониторингу.
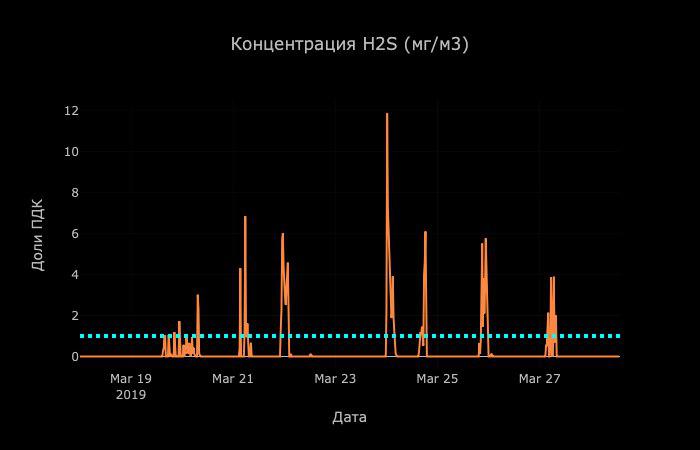
На графике мониторинга концентрации H2S видны регулярные ночные выбросы расположенного рядом предприятия
Устройства, которые мы используем в «УРУС», содержат в себе несколько сенсоров, которые собирают информацию о содержании определенных газов, уровне шума и другие данные для оценки экологической обстановки. Точное количество сенсоров всегда определяется конкретной задачей.

В зависимости от специфики измерений, устройства с датчиками могут располагаться на стенах зданий, столбах и в других произвольных местах. Каждое такое устройство собирает информацию, агрегирует ее и отправляет на шлюз приема данных. Там мы сохраняем данные на длительное хранение и предообратываем для последующего анализа. Простейший пример того, что мы получаем на выходе после анализа — это индекс качества воздуха, он же AQI.
Параллельно на нашей платформе работает много других сервисов, но в основном они носят обслуживающий характер. Например, сервис нотификации отправляет клиентам уведомления, если какой-то из отслеживаемых параметров (допустим, содержание СО2) превысил допустимое значение.
Как мы храним данные. История с Kubernetes на bare metal
В проекте экомониторинга «УРУС» есть несколько хранилищ данных. В одном мы держим «сырые» данные — то, что мы получили непосредственно от самих устройств. Это хранилище представляет собой «магнитную» ленту, как на старых кассетах, с историей всех показателей. Второй тип хранилища используется для предобработанных данных — данных с устройств, обогащенных метаданными о связях сенсоров и показания самих устройств, принадлежности к организациям, местам расположения и т. д. Эта информация позволяет в динамике оценить, как менялся за определенный промежуток времени тот или иной показатель. Хранилище «сырых» данных мы используем в том числе как бэкап и для восстановления предобработанных данных, если такая необходимость возникнет.
Когда мы несколько лет назад искали, как решить проблему с хранением, у нас было два варианта для выбора платформы: Kubernetes и OpenStack. Но так как последний выглядит довольно монструозно (просто посмотрите на его архитектуру, чтобы убедиться в этом), то мы остановились именно на Kubernetes’е. Еще одним аргументом в его пользу стало относительно простое программное управление, возможность более гибко нарезать даже железные ноды по ресурсам.
Параллельно с освоением самого Kubernetes мы изучали и способы хранения данных, пока мы все наши хранилища держали в Kubernetes на своем железе, мы получили отличную экспертизу. Все, что у нас тогда было, жило именно на Kubernetes’е: statefull-хранилище, система мониторинга, СI/CD. Kubernetes стал для нас all-in-one платформой.
Но нам хотелось работать с Kubernetes’ом как с сервисом, а не заниматься его поддержкой и разработкой. Плюс нам не нравилось то, во сколько нам обходится его содержание на bare metal, а разработка требовалась нам постоянно! Например, одной из первых задач стало вписать Ingress-контроллеры Kubernetes в сетевую инфраструктуру нашей организации. Это громоздкая задача, особенно если представить, что на тот момент ничего не было готово для программного управления ресурсами вроде DNS-записей или выделения IP-адресов. Позже мы начали экспериментировать с внешним хранилищем данных. До имплементации PVC-контроллера так и не добрались, но уже тогда стало понятно, что это большой фронт работ, под который нужно выделять отдельных специалистов.
Переход на Google Cloud Platform — временное решение
Мы поняли, что так дальше продолжаться не может, и перенесли наши данные с bare metal на Google Cloud Platform. На самом деле, тогда для российской компании было не так много интересных вариантов: кроме Google Cloud Platform аналогичный сервис предлагал только Amazon, но мы все-таки остановились на решении от Google. Тогда оно показалось нам экономически более выгодным, более близким к Upstream, не говоря уже о том, что Google сам по себе — это своеобразный PoC Kubernetes в Production.
Первая серьезная проблема появилась на горизонте параллельно с тем, как росла наша клиентская база. Когда у нас появилась необходимость хранить персональные данные, мы оказались перед выбором: или работаем с Google и нарушаем российские законы, или ищем альтернативу в РФ. Выбор, в целом, был предсказуем. :)
Каким мы видели идеальный облачный сервис
К началу поисков мы уже знали, что хотим получить от будущего облачного провайдера. Какой сервис мы искали:
- Быстрый и гибкий. Такой, чтобы мы в любой момент оперативно могли добавить новую ноду или что-то развернуть.
- Недорогой. Нас очень волновал финансовый вопрос, так как мы были ограничены в ресурсах. Мы уже знали, что хотим работать с Kubernetes, и теперь стояла задача минимизировать его стоимость, чтобы увеличить или хотя бы сохранить эффективность использования этого решения.
- Автоматизированный. Мы планировали работать с сервисом через API, без менеджеров и телефонных звонков или ситуаций, когда нужно вручную поднимать несколько десятков нод в авральном режиме. Так как большинство процессов у нас автоматизированы, того же мы ждали от облачного сервиса.
- С серверами в РФ. Конечно, мы планировали соблюдать российское законодательство и тот самый 152-ФЗ.
В то время провайдеров Kubernetes по модели aaS в России было мало, при этом, выбирая провайдера, нам было важно не поступиться нашими приоритетами. Команда Mail.ru Cloud Solutions, с которой мы начали работать и сотрудничаем до сих пор, предоставила нам полностью автоматизированный сервис, с поддержкой API и удобной панелью управления, в которой есть Horizon — с ним мы могли быстро поднять произвольное количество нод.
Как нам удалось мигрировать в MCS за два часа
В подобных переездах многие компании сталкиваются с трудностями и неудачами, но в нашем случае их не было. Нам повезло: так как мы до начала миграции уже работали на Kubernetes’е, мы просто поправили три файла и запустили свои сервисы на новой облачной платформе, в MCS. Напомню, что к тому времени мы окончательно ушли с bare metal и жили на Google Cloud Platform. Потому сам переезд занял не больше двух часов, плюс еще немного времени (около часа) ушло на копирование данных с наших устройств. Тогда мы уже использовали Spinnaker (мультиоблачный CD-сервис для обеспечения Continous Delivery). Его мы тоже оперативно добавили в новый кластер и продолжили работать в обычном режиме.
Благодаря автоматизации процессов разработки и CI/CD Kubernetes’ом в «УРУС» занимается один специалист (и это я). На каком-то этапе со мной работал еще один системный администратор, но потом оказалось, что всю основную рутину мы уже автоматизировали а со стороны нашего основного продукта задач все больше и имеет смысл направить ресурсы на это.
Мы получили от облачного провайдера то, что ожидали, так как начали сотрудничество без иллюзий. Если и были какие-то инциденты, то в основном технические и такие, которые легко объяснить относительной свежестью сервиса. Главное, что команда MCS оперативно устраняет недочеты и быстро реагирует на вопросы в мессенджерах.
Если сравнивать опыт работы с Google Cloud Platform, то в их случае я даже не знал, где находится кнопка обратной связи, так как в ней просто не было необходимости. А если какие-то проблемы и случались, Google сам рассылал уведомления в одностороннем порядке. Но в случае с MCS большим плюсом я считаю то, что они находятся максимально близко к российским клиентам — и территориально, и ментально.
Как мы видим работу с облаками в будущем
Сейчас наша работа тесно завязана на Kubernetes’е, и он полностью устраивает нас с точки зрения инфраструктурных задач. Поэтому мы не планируем куда-то с него мигрировать, хотя постоянно вводим новые практики и сервисы для упрощения рутинных задач и автоматизации новых, повышения стабильности и надежности сервисов… Сейчас запускаем сервис Chaos Monkey (а конкретно мы используем chaoskube, но концепции это не меняет :), который изначально был создан в Netflix. Chaos Monkey делает одну простую вещь: в произвольное время удаляет произвольный под в Kubernetes’е. Это нужно, чтобы наш сервис нормально жил с количеством инстансов n–1, так мы приучаем себя быть готовыми к любым неполадкам.
Сейчас я вижу использование сторонних решений — тех же облачных платформ — как единственно правильное для молодых компаний. Обычно в начале пути они ограничены в ресурсах, как кадровых, так и финансовых, а строить и содержать собственное облако или дата-центр слишком дорого и трудозатратно. Cloud-провайдеры позволяют минимизировать эти затраты, у них можно быстро получить ресурсы, необходимые для работы сервисов здесь и сейчас, причем оплачивать эти ресурсы по факту. Что касается компании «УРУС», то мы пока останемся верны Kubernetes’у в облаке. Но кто знает, возможно, нам придется расширяться географически, или внедрять решения на базе какого-то специфического оборудования. Или, может, количество потребляемых ресурсов оправдает собственный Kubernetes на bare-metal, как в старые добрые времена. :)
Что мы вынесли из опыта работы с облачными сервисами
Мы начали использовать Kubernetes на bare metal, и даже там он был по-своему хорош. Но сильные его стороны удалось раскрыть именно в качестве aaS-компонента в облаке. Если поставить цель и все максимально автоматизировать, то получится избежать vendor lock-in и переезд между облачными провайдерами займет пару часов, а нервные клетки останутся с нами. Другим компаниям мы можем посоветовать: хотите запустить свой (облачный) сервис, имея ограниченные ресурсы и максимальный velocity для разработки — начинайте прямо сейчас с аренды облачных ресурсов, а свой дата-центр стройте после того, как о вас напишет Forbes.
Комментарии (18)

fessmage
13.09.2019 08:05Непонятен момент с необходимостью хоститься в РФ — по описанию у вас там только абстрактные метрики воздуха, о каких тут ПСД идет речь?

t3ran
13.09.2019 10:45Помимо собственно самих данных у нас есть компоненты отвечающие за аутентификацию, авторизацию, рассылку уведомлений, самый простой пример: для каждого пользователя мы можем хранить email, Ф.И.О., номер телефона, организацию пользователя — сочетание этих данных дает уже ПД.
Sovetnikov
13.09.2019 16:35Ещё в статье написано, что вы данные храните в Kubernetes, можно поконкретнее, где именно? Как вы решили задачу с контролем физического местонахождения данных?
t3ran
14.09.2019 11:57Ещё в статье написано, что вы данные храните в Kubernetes, можно поконкретнее, где именно?
Да, конечно, для хранения данных экологического мониторинга мы используем Kafka и ScyllaDB, запущенные в виде StatefulSet'ов с PVC, преимущественно на SSD.
Попутно пробуем операторы для stateful-приложений, но для Kafka и ScyllaDB пока не нашли подходящего решения.
Как вы решили задачу с контролем физического местонахождения данных?
Не понял вопроса.
gecube
14.09.2019 18:21Важный момент.
Вы используете локальное хранилище на нодах с кубом?
Или распределенное?
Там много нюансовt3ran
15.09.2019 03:19За все время использования Kubernetes на bare-metal мы пробовали разные варианты(в хронологическом порядке):
— Внешний сторадж с дисковой полкой и LVM over FC
— Оно же over iSCSI
— Локальный Ceph на нодах
— hostPath + nodeSelector
В GCP и MCS мы используем предоставляемые вендором сервиса внешние вольюмы через PVC. Не локальное хранилище на нодах(hostPath) потому что это сильно повлияет на отказоустойчивость и потребует ручного управления StatefulSet'ами, что хочется оставить соответствующим операторам.gecube
15.09.2019 08:59в GCP оно, понятное дело, прибито к региону. И по сути — может ездить между виртуалками.
А как в MCS сделано? Я помню, что там была целая куча разных типов стораджа. И были странные функции вроде подмонтировать сторедж из одного региона в другой. Поэтому и уточняю.t3ran
15.09.2019 11:54Там вообще три типа именно дисков: HDD, SSD, High IOPS SSD
«георепликация» — bool флаг для диска(High IOPS SSD его не умеют)
Обычно мы делаем кластер в одном регионе, диски к нему с георепликацией, там где это не контролируется (PVC) и/или невозможно(High IOPS SSD) — не настаиваем, т.к. репликация есть внутри statefulset'а.
Sovetnikov
Читаю и у меня, что-то не сходится, вопросы возникают.
Компания молодая, хотим Kubernetes, но на «своём» сервере его поддерживать дорого, а в облаке получилось дешевле.
Это сколько?
Не понимаю с какими сложностями в поддержке вы столкнулись «на своём» железе, чуть подробнее? Что вы разрабатывали?
Какой у вас объём данных? Пол часа на копирование всех данных между датацентрами, это достаточно быстро.
Какие у вас потребности в RAM и CPU?
А с переездом в облако задача просто отпала?
t3ran
Получилось дешевле за счет того, что это managed-решение, которое не требует с нашей стороны разработки low-level компонентов, например для интеграции с сетью компании или для PVC на своем оборудовании.
«Сколько» это в человеко-часах, два человека — DevOps на full-time + переодически привлекаемые разработчики под частные задачи, когда они накапливались.
Разрабатывали, например, компонент позволяющий в сервисах использовать IP'шники из корпоративной сети, интегрирующийся так же с DNS. В опенсорс он в итоге не пошел. Так же делали stage3 провижнинг нод с автодобавлением в кластер и апгрейдом кубернетеса, хотели перейти на stage4 с тестами конкретной сборки, но не успели :)
В настоящий момент у нас сырых пожатых данных всего ничего ~5GB в Kafka(~5M сообщений от конечных устройств), переливали мы их без нарушения работоспособности сервиса. Так что полчаса для такого объема даже очень долго :)
Суммарно используется 85 CPU, 322 GB RAM.
Общий объем CPU и памяти у нас обычно зависит от того, над чем мы эксперементируем в настоящий момент и какие стоят задачи, текущее значение достаточно скромное, потому что сейчас не проходит никаких экспериментов.
А с переездом в облако все уже сделали за нас :)
Sovetnikov
Не, не понимаю.
Всего 10 серверов, не так много, программисты штатные вполне с ними могут совладать :)
Вы всё о трудоемких интеграциях в вашу сеть пишете, а задачи решаемые вроде как вокруг обсчёта данных крутятся.
Не понимаю чем два человека на Full-time занимались.
В MCS вам сделали возможность использования IP-адресов из корпоративной сети?
И MCS сделали вам интеграцию в вашу копоративную сеть?
t3ran
Распределение ресурсов команд это вопрос продукт-, проджект- и релиз-менеджмента.
В самом начале у нас было именно так — 8 серверов и с ними вполне справлялись разработчики, но затем, как у любого развивающегося проекта у нас появились задачи:
— воспроизводимости окружения
— апгрейдов kubernetes
— интеграции kubernetes с корпоративными сервисами
— трейсинга ошибок наших собственных приложений
— мониторинга
— централизованного доступа к логам
— CI
— CD
— процедур и сервисов для Code Review
— песочницы для экспериментов
— SLA и отслеживание его соблюдения
… этот перечень можно еще продолжать, но важно одно: это все не задачи разработчиков продуктовой команды. Это инфраструктурные задачи.
Все это нужно для того, чтоб команда разработки могла эффективно выполнять свои функции, а именно:
— занималась разработкой
— делала это с максимальной эффективностью
— т.е. не отвлекаясь на задачи инфраструктуры
— имея при этом воспроизводимый результат
— и наиболее свежие технологии в стеке
Продуктовые задачи это не только обсчет данных, это целый набор задач по архитектуре сервисов, UI/UX, непосредственно арифметике и, самое главное, применимости конкретных экологических методик к нашим реалиям и целям.
Ровно всем этим — обеспечивали работу остальных команд, беря на себя инфраструктурные функции и организацию процессов.
Это самая интересная часть — еще переезжая в GCP(где, кстати есть возможность Interconnect'а с корпоративными сегментами) мы осознали что, это лишнее. У нас ушло понимание зачем нам держать сервис(даже его девелопмент часть) исключительно во внутренней сети. Так что в MCS мы приехали с полностью публично-доступными(в сетевом смысле этого слова) сервисами, а дальше — BeyondCorp model(хотя к полной ее имплементации мы еще только стремимся).
Sovetnikov
Из вашего списка задач MCS решает только две:
— апгрейдов kubernetes (MCS это сами делают)
— интеграции kubernetes с корпоративными сервисами (это просто отпадает по сути)
Остальное это каждодневная рутинная работа команды разработки.
А SLA MCS будет соблюдать до тех пор, пока у них не случится авария, как и все остальные хостинги :)
В MCS файлы наши уже теряли…
t3ran
Это сильно натянутое заключение.
Мы получаем on-demand сервис с API, который нам позволяет получить произвольное число нод/CPU в считанные минуты независимо от времени суток. Скейлиться точно так же. Это справедливо для любого Kubernetes-aaS на самом деле, не только для MCS.
И фактически уйдя с bare-metal мы решили проблемы:
Все связанные с физическим оборудованием и своей OS:
— провиженинг
— деплоймент
— мониторинг
— апдейты
— замена комплектующих
т.е. все, что до
kubectl apply.Как там в анекдоте было, «админы делятся на два типа...»
У нас уже есть позитивный опыт решения подобных проблем с MCS.
Подробно рассказать не могу, но суть сводится к тому, что наш менеджер в MCS готов такие вопросы обсуждать и договариваться.
gecube
Я тоже не понимаю.
Тон статьи — реклама mcs, ура-ура, мы умеем кубернетис
Честно говоря, я ожидал каких-то кровавых подробностей из серии "как организовать петабайтный dwh" на кубе. Это реально интересно. А у коллег всего 5ГБ в кафке. Ну, смешно. С таким объемом даже один жирный сервер справится
Касательно интеграции с Корп сетью — тоже неудомение. Действительно, с одной стороны это сложно. Но не с технической, а организационной стороны. А с другой — какие такие компоненты понадобились? Знаете, проблема решается вообще очень просто. Просто заводить в кубе coredns, и ему отдать зону *.kube-cluster-1.mycompany.com. Проблема решена. С айпишниками — посмотрите опыт букинга, когда они на каждую ноду просто выделяют подсесть из корпсети все коуто
gecube
Ещё добавлю, что в российских компаниях стандарт де-факто — vmware. И вмварь очень активно разрабатывает отличные интеграции с кубернетесом, как со стороны стореджа, так и со стороны сети, и даже прозрачной интеграции куба в панели управления (!!!)
Viceroyalty
Немного оффтоп, но какая виртуализация используется "у них"? (Имею в виду виртуальные машины с виндой для разработчиков, а не корпоративный сегмент)
gecube
Извините, пожалуйста, не совсем понял Вашего вопроса. Разверните, его, пожалуйста.
Если локально — вагрант. Можно в hyper-v. А вообще разрабы могут и на VDI пастись (есть компании с такими требованиями по ИБ).