
В настоящее время всё больше компаний переводят свою инфраструктуру с железных серверов и собственных виртуалок в облака. Такое решение легко объяснить: нет необходимости заботиться о железе, кластер легко конфигурируется множеством различных способов… а самое главное — имеющиеся технологии (вроде Kubernetes) позволяют просто масштабировать вычислительные мощности в зависимости от нагрузки.
Всегда важен и финансовый аспект. Инструмент, речь о котором пойдет в этой статье, призван способствовать сокращению бюджетов при использовании облачной инфраструктуры с Kubernetes.
Введение
Kubecost — калифорнийский стартап от выходцев из Google, создающий решение для подсчета затрат на инфраструктуру в облачных сервисах (внутри кластера Kubernetes + общие ресурсы), поиска узких мест в настройках кластера и отправления соответствующих уведомлений в Slack.
У нас есть клиенты с Kubernetes как в привычных облаках AWS и GCP, так и более редком для Linux-сообщества Azure — в общем, на всех платформах, поддерживаемых Kubecost’ом. Для некоторых из них мы считаем затраты по внутрикластерным сервисам самостоятельно (по методике, похожей на ту, что использует Kubecost), а также следим за расходами на инфраструктуру и стараемся их оптимизировать. Поэтому логично, что нас заинтересовала возможность автоматизировать такие задачи.
Исходный код основного модуля Kubecost открыт на условиях Open Source-лицензии (Apache License 2.0). Его можно использовать свободно, а доступных функций должно быть достаточно для небольших проектов. Однако бизнес есть бизнес: остальная часть продукта закрыта, ей можно воспользоваться по платным подпискам, которые также подразумевают коммерческую поддержку. Кроме того, авторы предлагают бесплатную лицензию для небольших кластеров (1 кластер с
Как всё устроено
Итак, основная часть Kubecost — это приложение cost-model, написанное на Go. Helm-чарт, описывающий всю систему целиком, называется cost-analyzer и по своей сути является сборкой из cost-model с Prometheus, Grafana и несколькими dashboard’ами.
Вообще говоря, у cost-model есть свой веб-интерфейс, который показывает графики и детальную статистику по затратам в табличном виде, а также, конечно, советы по оптимизации расходов. Представленные же в Grafana dashboard’ы являются более ранним этапом развития Kubecost и содержат во многом те же данные, что и cost-model, дополняя их привычной статистикой по расходу CPU/памяти/сети/дискового пространства в кластере и его составляющих.
Как же работает Kubecost?
- Cost-model через API облачных провайдеров получает цены на обслуживание.
- Далее, в зависимости от железного типа узла и региона, считается стоимость по узлам.
- На основе стоимости работы узлов каждый конечный pod получает стоимость за час использования процессора, расходования гигабайта памяти и стоимость часа хранения гигабайта данных — в зависимости от узла, на котором он работал, или класса хранилища.
- Исходя из стоимости работы отдельных pod’ов считается оплата по пространствам имён, сервисам, Deployment’ам, StatefulSet’ам.
- Для подсчета статистики используются метрики, предоставляемые kube-state-metrics и node-exporter.
Важно учитывать, что Kubecost по умолчанию считает только ресурсы, доступные в Kubernetes. Внешние базы данных, серверы GitLab, хранилища S3 и другие сервисы, отсутствующие в кластере (пусть и находящиеся в том же облаке), для него не видны. Хотя для GCP и AWS можно добавить ключи своих сервис-аккаунтов и посчитать всё вместе.
Установка
Для функционирования Kubecost требуются:
- Kubernetes версии 1.8 и выше;
- kube-state-metrics;
- Prometheus;
- node-exporter.
Так сложилось, что в наших кластерах все эти условия были соблюдены заранее, поэтому оказалось достаточным лишь указать правильный endpoint для доступа в Prometheus. Тем не менее, официальный Helm-чарт kubecost содержит в себе всё необходимое, чтобы запуститься и на «голом» кластере.
Установить Kubecost можно несколькими способами:
- Стандартный способ установки, описанный в инструкции на сайте разработчика.Необходимо добавить в Helm репозиторий cost-analyzer, после чего установить чарт. Останется лишь пробросить себе порт и допилить настройки до желаемого состояния вручную (через kubectl) и/или с помощью веб-интерфейса cost-model.
Данный способ мы даже не пробовали, поскольку не используем сторонние готовые конфигурации, однако он выглядит как хороший вариант «просто попробовать для себя». Если же у вас уже установлена часть компонентов системы или вы хотите более тонкой настройки, лучше рассмотреть второй путь.
- Использовать по сути тот же чарт, но самостоятельно сконфигурировать и установить его любым удобным способом.
Как уже упоминалось, помимо собственно kubecost’а этот чарт содержит чарты Grafana и Prometheus, которые также можно настроить по своему желанию.
Имеющийся в чартеvalues.yamlдля cost-analyzer позволяет настраивать:
- перечень компонентов cost-analyzer, которые требуется развернуть;
- свой endpoint для Prometheus (если он у вас уже есть);
- домены и другие настройки ingress’ов для cost-model и Grafana;
- аннотации для pod’ов;
- необходимость использования постоянных хранилищ и их размер.
Полный список доступных опций конфигурирования с описанием есть в документации.
Поскольку kubecost в базовом варианте не умеет ограничивать доступ, потребуется сразу настроить basic-auth для веб-панели.
- Установить только ядро системы — cost-model. Для этого необходимо иметь в кластере установленный Prometheus и указать соответствующее значение его адреса в переменной
prometheusEndpointдля Helm’а. После этого — применить набор YAML-конфигураций в кластере.
Опять же, придётся вручную добавить Ingress с basic-auth. И наконец, потребуется добавить секцию для сбора метрик cost-model вextraScrapeConfigsв конфиге Prometheus:
- job_name: kubecost honor_labels: true scrape_interval: 1m scrape_timeout: 10s metrics_path: /metrics scheme: http dns_sd_configs: - names: - <адрес вашего сервиса kubecost> type: 'A' port: 9003
Что получаем?
При полноценной установке в нашем распоряжении оказывается веб-панель kubecost и Grafana с набором dashboard’ов.
Total cost, отображаемый на главном экране, фактически показывает расчетную стоимость ресурсов за месяц. Это прогнозируемая цена, отображающая стоимость использования кластера (в месяц) при текущем уровне потребления ресурсов.
Данная метрика — больше для анализа расходов и их оптимизации. Общие затраты за абстрактный июль в kubecost смотреть не очень удобно: за этим придется идти в биллинг. Зато можно посмотреть затраты с разбивкой по пространствам имён, лейблам, pod’ам за 1/2/7/30/90 дней, чего биллинг вам никогда не покажет.
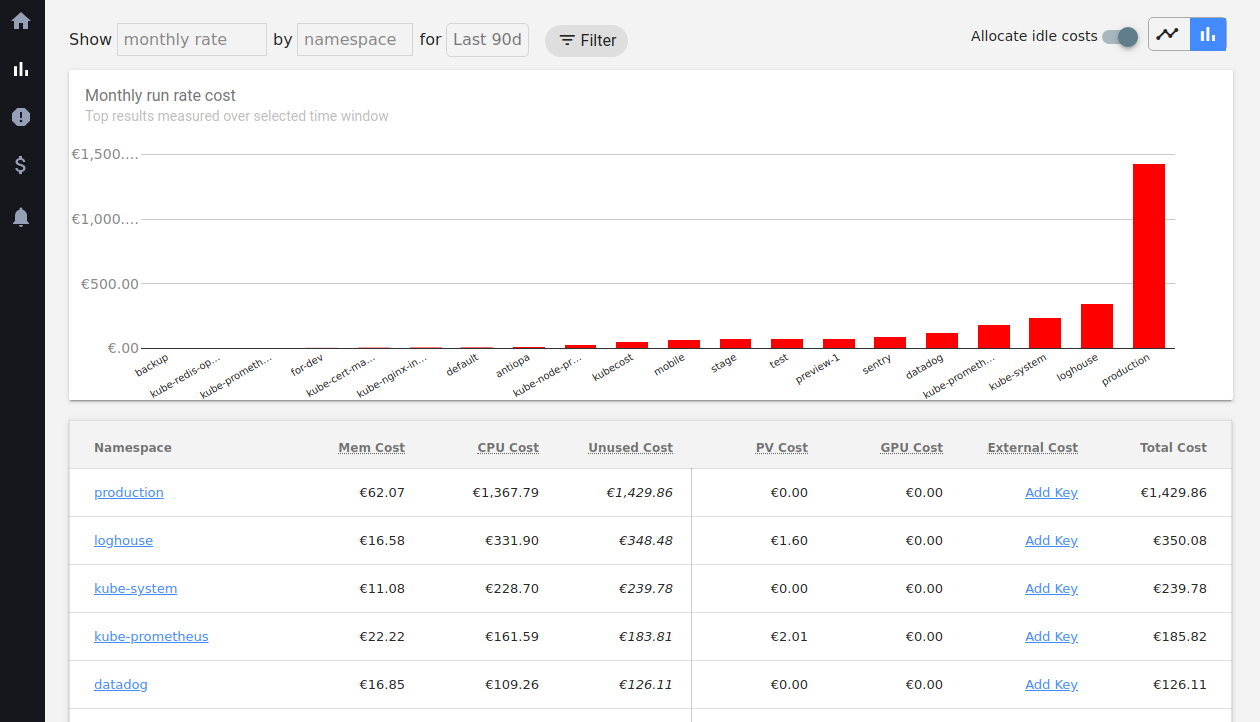
К слову о лейблах. Стоит сразу зайти в настройки и выставить названия лейблов, которые будут использоваться как дополнительные категории для группировки затрат:
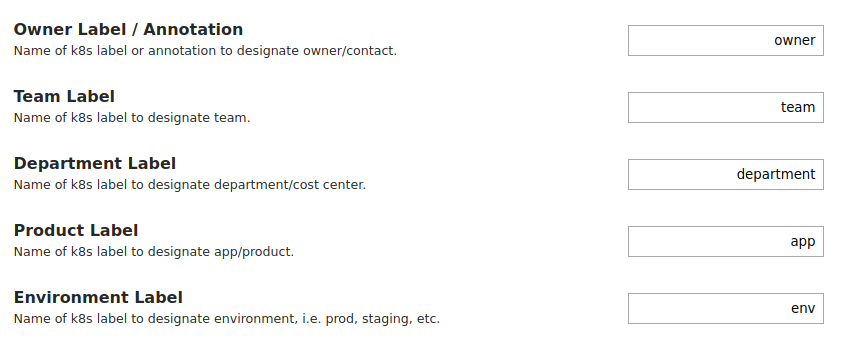
Лейблы на них можно повесить любые — удобно, если у вас уже существует своя система маркировки.
Также там можно сменить адрес API endpoint’а, к которому подключается cost-model, настроить размер скидки в GCP и выставить собственные цены на ресурсы и валюту для их измерения (фича почему-то не влияет на Total cost).
Kubecost умеет показывать различные проблемы в кластере (и даже алертить в случае опасности). К сожалению, опция не настраивается, а посему — если у вас есть окружения для разработчиков и они используются, можно будет постоянно наблюдать нечто подобное:
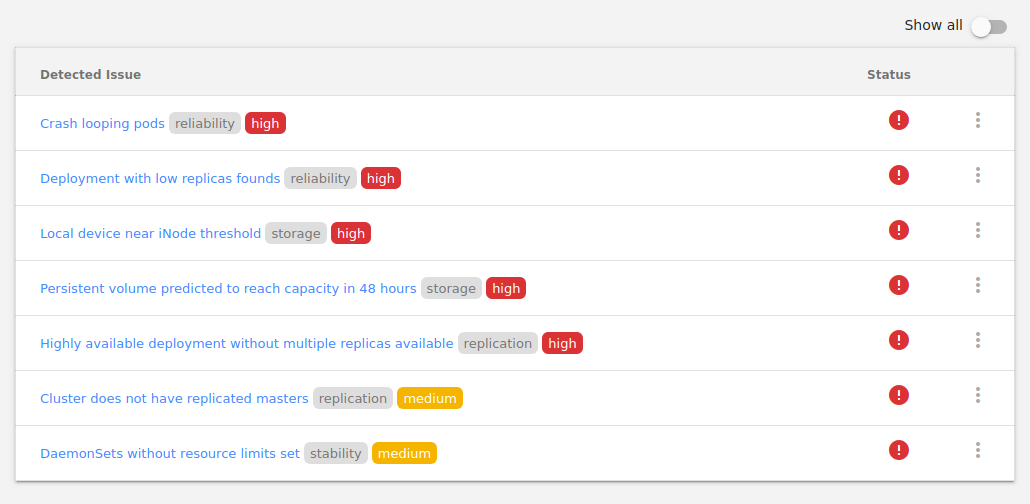
Важный инструмент — Cluster Savings. Он измеряет активность pod’ов (потребление ресурсов, в том числе и сетевых), а также считает, сколько денег и на чем можно сэкономить.
Может показаться, что советы по оптимизации — довольно очевидные, однако опыт подсказывает, что всё равно есть к чему присмотреться. В частности, отслеживается сетевая активность pod’ов (Kubecost предлагает обратить внимание на неактивных), сравнивается запрошенный и реальный расход памяти и CPU, а также CPU, используемый узлами кластера (предлагает свернуть несколько узлов в один), нагрузка на диски и еще пара десятков параметров.
Как и в любом вопросе, касающемся оптимизации, к оптимизации ресурсов на основе данных Kubecost нужно относиться с осторожностью. Например, Cluster Savings предлагает удалить узлы, утверждая, что это безопасно, однако не учитывает наличие у развернутых на них pod’в node-selector’ов и taint’ов, не имеющихся на остальных узлах. Да и вообще, даже авторы продукта в своей недавней статье (кстати, она может оказаться весьма полезной тем, кто интересуется темой проекта) рекомендуют не кидаться с головой в оптимизацию расходов, а подходить к вопросу обдуманно.
Итоги
После использования kubecost в течение месяца на паре проектов можем заключить, что это интересный (а ещё легкий в освоении и установке) инструмент для анализа и оптимизации расходов на услуги облачных провайдеров, используемых для Kubernetes-кластеров. Подсчеты получаются весьма точными: в наших экспериментах они совпадали с тем, что в реальности требовали провайдеры.
Не обошлось и без минусов: есть некритичные баги, функциональные возможности местами не покрывают специфичных для некоторых проектов потребностей. Однако, если нужно быстро понять, куда уходят деньги и что можно «порезать», чтобы стабильно снизить счет за облачные услуги на 5-30% (так и произошло в нашем случае), — это отличный вариант.
P.S.
Читайте также в нашем блоге:
shurup
Занятая история из жизни по теме: «Mistake that cost thousands (Kubernetes, GKE)».