4. Количественное сравнение числовых систем
4.1. Определение десятичной точности
Точность обратна ошибке. Если у нас есть пара чисел x и y (ненулевых и одного знака), расстояние между ними в порядках величин составляет десятичных порядков, это та же самая мера, которая определяет динамический диапазон между самым маленьким и самым большим представимым положительным числом x и y. Идеальным распределением десяти чисел между 1 и 10 в вещественной системе счисления было бы не равномерное распределение чисел по порядку от 1 до 10, а экспоненциальное: . Это шкала децибел, долгое время используемая инженерами для выражения отношений, например, 10 децибел — это десятикратное отношение. 30db означает коэффициент . Отношение 1db — это коэффициент около 1,26, если вы знаете значение с точностью 1db, вы имеете точность 1 десятичный знак. Если вы знаете величину с точностью 0,1 db, это означает 2 знака точности, и т.п. Формула десятичной точности — , где x и y — либо корректные значения, вычисленные с использованием систем округления, таких, какие используются в форматах float и posit, либо верхние и нижние границы, если используются строгие системы, использующие интервалы, или значения valid.
4.2. Определение множеств сравнения чисел float и posit
Мы можем создать масштабные модели чисел float и posit длиной по 8 бит каждое. Преимущество данного подхода в том, что 256 значений, это достаточно маленькое множество, чтобы мы могли проверить его полностью, и сравнить все вхождений в таблицах для операций сложения, вычитания, умножения и деления. Вещественные числа с точностью 1/4 имеют один знаковый бит, четыре бита экспоненты и три бита дробной части, и придерживаются всех правил стандарта IEEE 754. Наименьшее положительное число (денормализованное) равно 1/1024, наибольшее положительное равно 240, динамический диапазон ассиметричен и равен 5,1 десятичных порядков.14 битовых комбинаций представляют NaN.
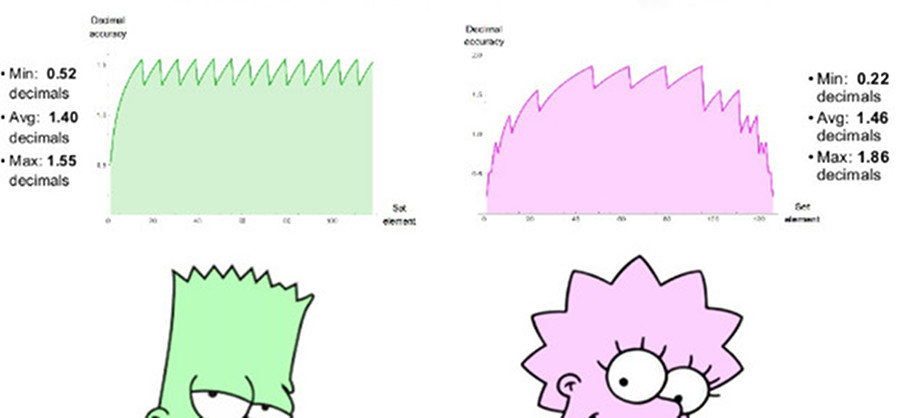
Сравнимое 8-битное posit использует es=1, имеет диапазон положительных чисел от 1/4096 до 4096, симметричный динамический диапазон 7,2 десятичных порядков. Значений NaN нет. Мы можем построить графики десятичной точности положительных чисел в обоих наборах, как показано на рис. 7. Отметим, что значения, представленные числами posit, имеют на два десятичных порядка больший динамический диапазон, чем числа float, и точность такую же или больше для всех значений, кроме тех, где числа float близки к переполнению или антипереполнению. Зазубренность графиков для обоих систем представляет собой логарифмическую аппроксимацию кусочно-линейной функции. У чисел float точность снижается только слева, на участке, близком к антиперепонению, справа функция обрывается, т.к. дальше идут значения NaN. Числа posit имеют более симметрично уменьшающуюся по краям функцию точности.
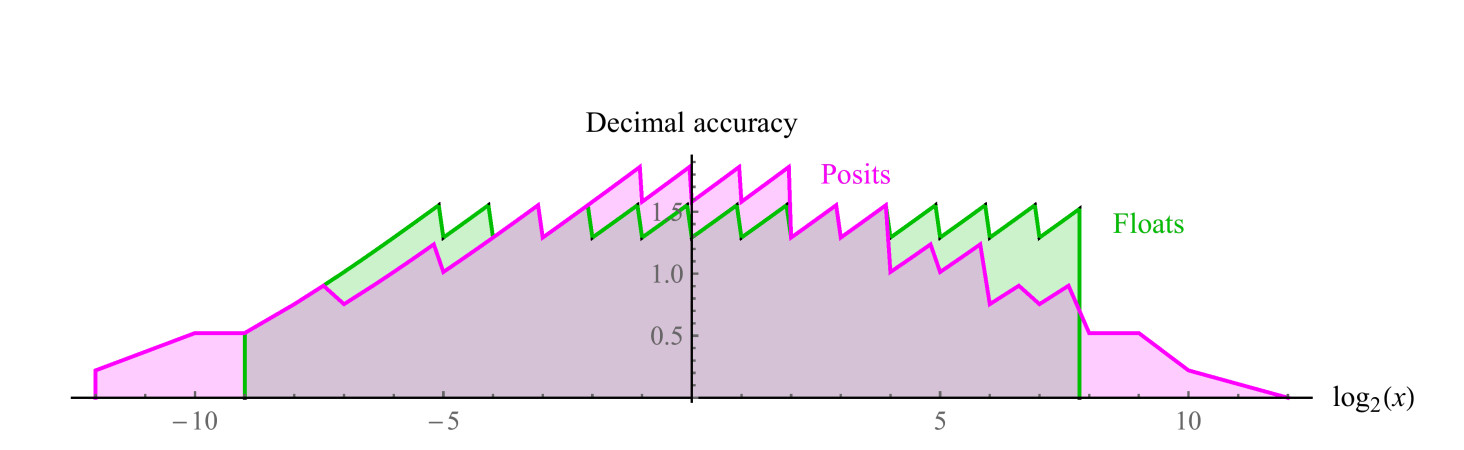
Рис. 7. Сравнение десятичной точности чисел float и posit
4.3. Сравнение операций одного аргумента
4.3.1. Обратное значение
Для каждого возможного входного значения x функции 1/x, результат может точно соответствовать другому значению в данном множестве, или может быть округлён, в этом случае мы можем измерить десятичную ошибку, используя формулу из раздела 4.1, для чисел float, результат может привести к переполнению или NaN. См. рис. 8.

Рис. 8. Количественное сравнение чисел float и posit при вычислении обратного значения
Кривые на правом графике показывают величину ошибки при вычислении обратного значения, при этом числа float могут давать в результате NaN. Числа posit превосходят float в большом числе случаев, и это превосходство сохраняется во всём диапазоне. Вычисление обратного значения денормализованных чисел float приводит к переполнению, что приводит к бесконечному значению ошибки, и, конечно, аргумент NaN даёт обратное значение NaN. Числа posit замкнуты относительно вычисления обратного значения.
4.3.2. Квадратный корень
Функция квадратного корня не приводит к переполнению или антипереполнению. Для отрицательных аргументов, и для NaN результат будет NaN. Вспомним, что у нас «масштабная модель» чисел float и posit, преимущества posit возрастают с увеличением точности данных. Для 64-битных float и posit, ошибка posit будет составлять около 1/30 ошибки float, вместо 1/2.
4.3.3. Квадрат
Другая распространённая унарная операция — это . Переполнения и антипереполнения обычное дело при возведении float в квадрат. Почти для половины float возведение в квадрат не приводит к осмысленному результату, тогда как возведение числа posit в квадрат всегда даёт в результате число posit (квадрат беззнаковой бесконечности есть беззнаковая бесконечность).
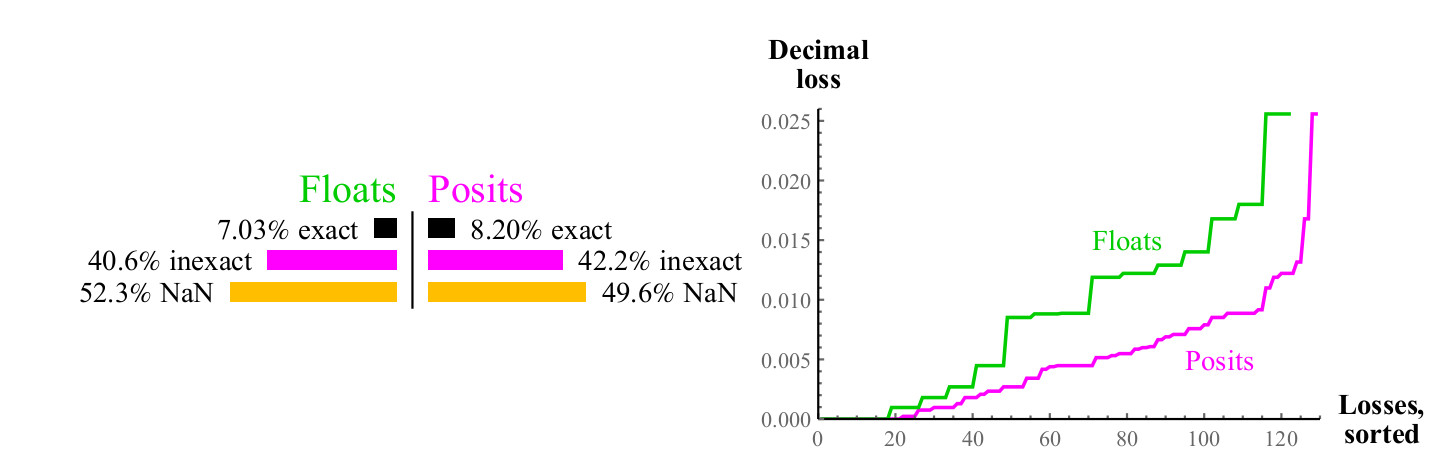
Рис. 9. Количественное сравнение чисел float и posit при вычислении
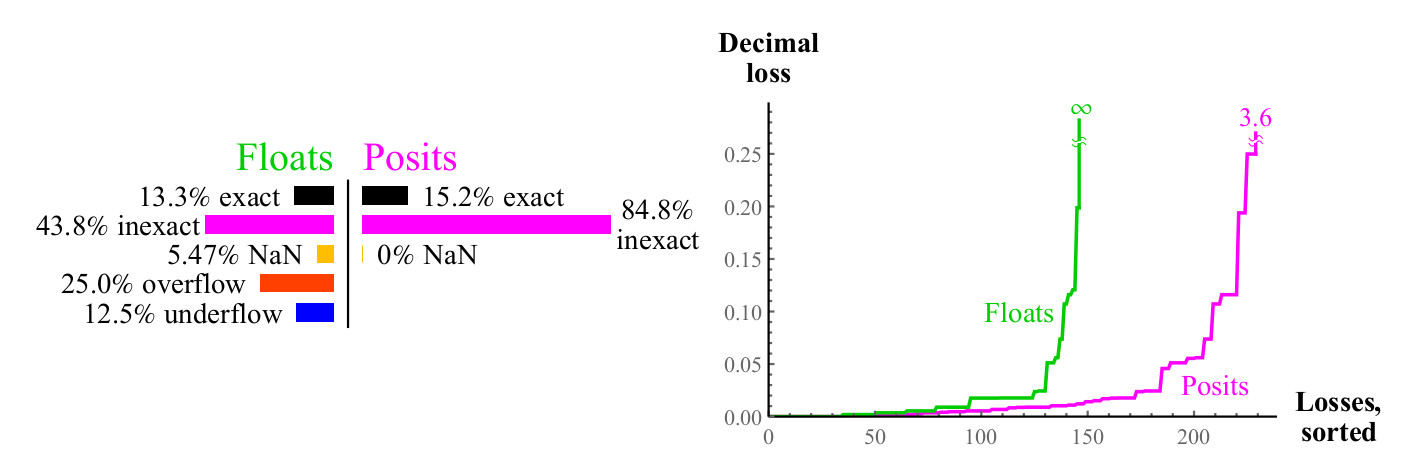
Рис. 10. Количественное сравнение чисел float и posit при вычислении
4.3.4. Логарифм по основанию 2
Мы также провели сравнение для покрытия функции логарифма по основанию 2, то есть процент случаев, при которых может быть точно представлен, и если он не может быть точно представлен, сколько десятичных знаков мы теряем. Числа float имеют в этом случае единственное преимущество: с их помощью можно представить как и как , но это более чем компенсируется большим словарём целых степеней двойки для чисел posit.
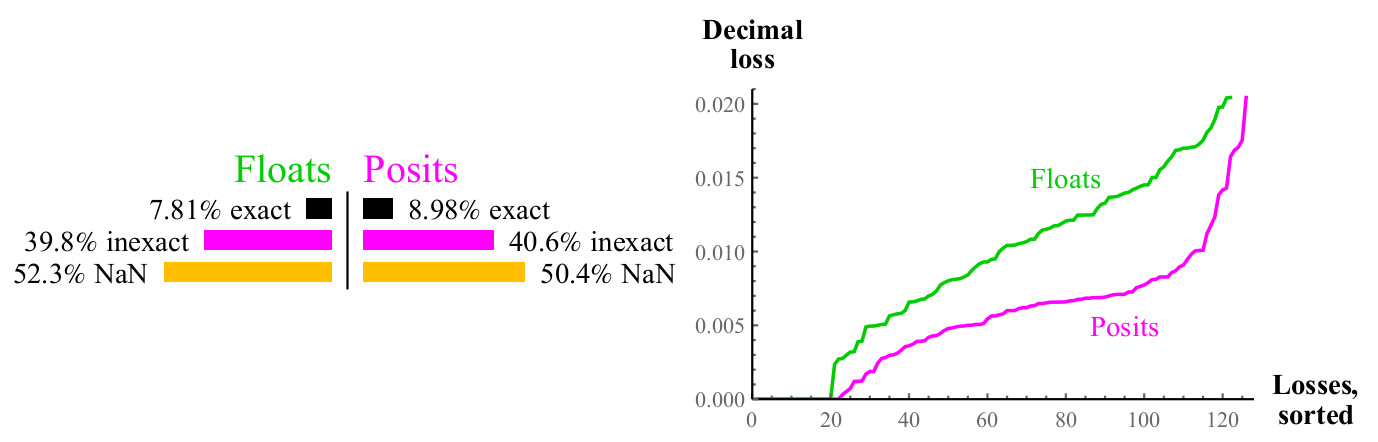
Рис. 11. Количественное сравнение чисел float и posit при вычислении
График похож на аналогичный для квадратного корня, примерно половина случаев даёт NaN в обоих случаях, но числа posit имеют вдвое меньшую потерю десятичной точности. Если вы можете вычислить , нужно только умножить результат на масштабирующий коэффициент, чтобы получить или или логарифм с любым другим основанием.
4.3.5. Экспонента,
Аналогично, если вы можете вычислять , вы можете легко с помощю масштабирующего коэффициента получить или и т.п. Числа posit имеют одно исключение, равно NaN, когда аргумент равен .
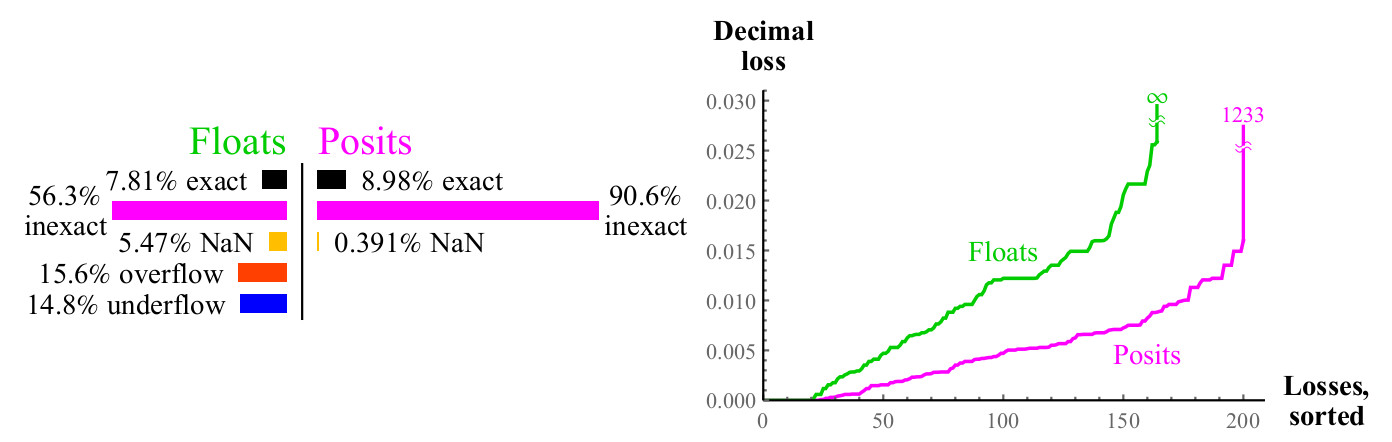
Рис. 12. Количественное сравнение чисел float и posit при вычислении
Максимальные десятичные потери для чисел posit могут показаться большими, так как будут округлены обратно до maxpos. В этом примере, только небольшое количество ошибок так же велико, как десятичных порядков. Решайте, что лучше: потерять свыше тысячи десятичны порядков, или потерять бесконечное количество десятичных порядков? Если вы можете не использовать настолько бльшие числа, числа posit по-прежнему выигрывают, потому что ошибки при маленьких значениях намного лучше. Во всех случаях, когда вы потеряете большое количество десятичных порядков при использовании чисел posit, входной аргумент лежит далеко за пределами того, что числа float могут даже выразить. Графики показывают, насколько числа posit более стабильны в терминах динамического диапазона, в котором результат имеет смысл, и имеют превосходство в точности в пределах этого диапазона.
Для обычных унарных операций и , числа posit всецело и неизменно более точны, чем числа float с тем же числом бит, и выдают осмысленный результат в широком динамическом диапазоне. Мы сейчас обратим наше внимание на четыре элементарных арифметических действия, имеющие два аргумента: сложение, вычитание, умножение и деление.
4.4. Сравнение операций двух аргументов
Мы можем использовать масштабную модель числовой системы для изучения арифметических операций двух аргументов, таких, как сложение, вычитание, умножение и деление. Для того, чтобы визуализировать 65536 результатов, мы делаем «график покрытия» 256*256, который наглядно показывает, какая доля результатов точна, неточна, вызывает переполнение, антипереполнение или NaN.
4.4.1. Сложение и вычитание
Так как прекрасно работает как для float, так и для posit, нет необходимости изучать вычитание отдельно. Для операции сложения, мы вычисляем точное значение , и сравниваем его с суммой, возвращённой в каждой из числовых систем. Может случиться, что результат неточный, тогда он должен быть округлён до ближайшего конечного ненулевого числа, может произойти переполнение или антипереполнение, или неопределённость вида , которая даёт в результате NaN. Каждый из этих случаев отмечен цветом, и мы можем охватить всю таблицу сложения одним взглядом. В случае округления результатов, цвет изменяется от чёрного (точное значение) до фиолетового (точное значение для posit и float). Рис. 13 показывает, на что похож график покрытия для чисел float и unum. Как и с унарными операциями, но имея гораздо больше точек, мы можем сделать выводы о способности каждой числовой системы давать осмысленные и точные ответы:
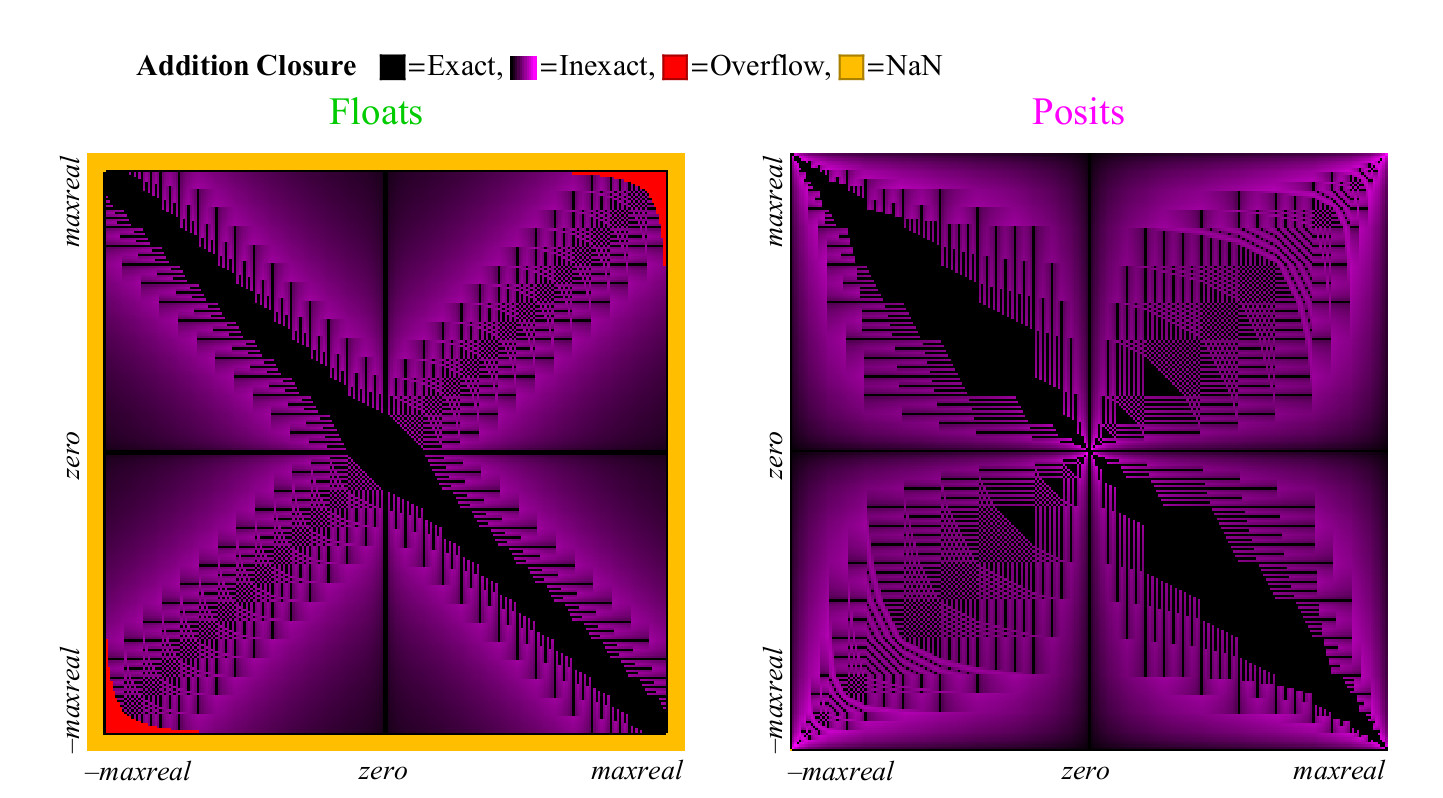
Рис. 13. Полный график покрытия для сложения чисел float и posit
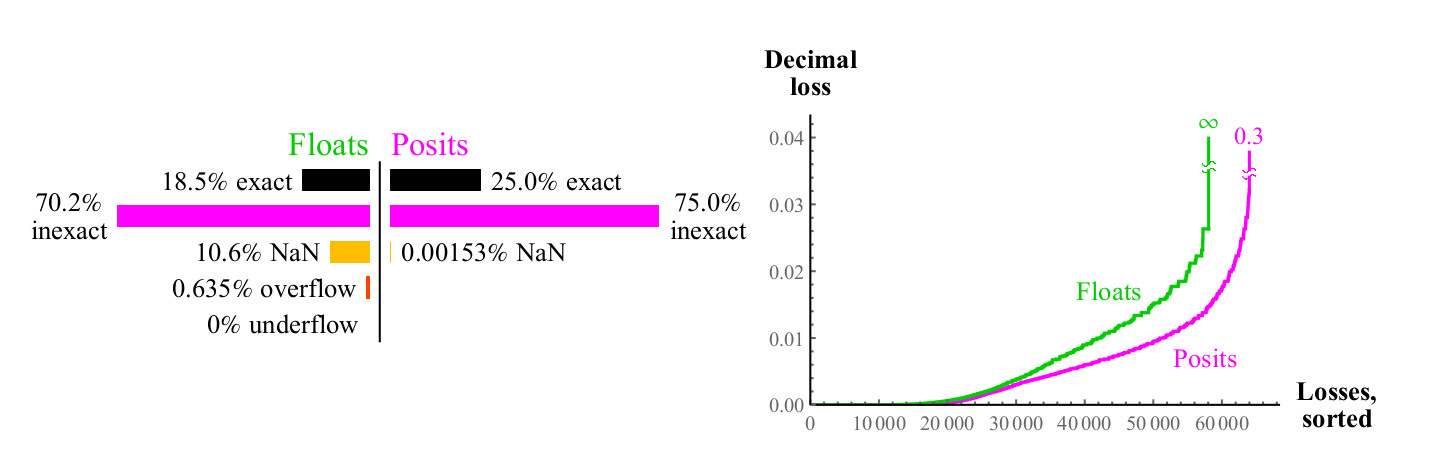
Рис. 14. Количественное сравнение чисел float и posit для сложения
С первого взгляда становится очевидно, что числа posit имеет существенно больше точек на графике сложения, в которых результат точный. Широкая чёрная диагональная полоса на графике покрытия для float гораздо шире, чем она будет для большей точности, потому что она представляет зону денормализованных чисел, в которой числа float отстоят друг от друга на равных промежутках, подобно числам с фиксированной точкой, такие числа составляют большую долю от общего числа только в случае 8-битных чисел.
4.4.2. Умножение
Мы используем похожий подход для сравнения того, насколько хорошо числа float и posit умножаются. В отличие от сложения, умножение может вызвать антипереполнение чисел float. «Постепенное антипереполнение», зона, которую вы можете видеть в центре на рис.15. слева. (имеется в виду денормализованные числа. прим. перев.) Без этой зоны, голубая зона антипереполнения имела бы форму ромба. График умножения для чисел posit менее разноцветный, что лучше. Только два пиксела подсвечены как NaN, близко к месту, гда находится нулевая метка осей (пикселы крайний слева в центре по вертикали, и внизу в центре по горизонтали. прим. перев.) Там находятся результаты умножения . Числа float имеют больше случаев, при которых произведение оказывается точным, но ужасной ценой. Как показано на рис.15, почти 1/4 всех произведений float приводит либо к переполнению, либо к антипереполнению, и эта доля не снижается при увеличении точности float.
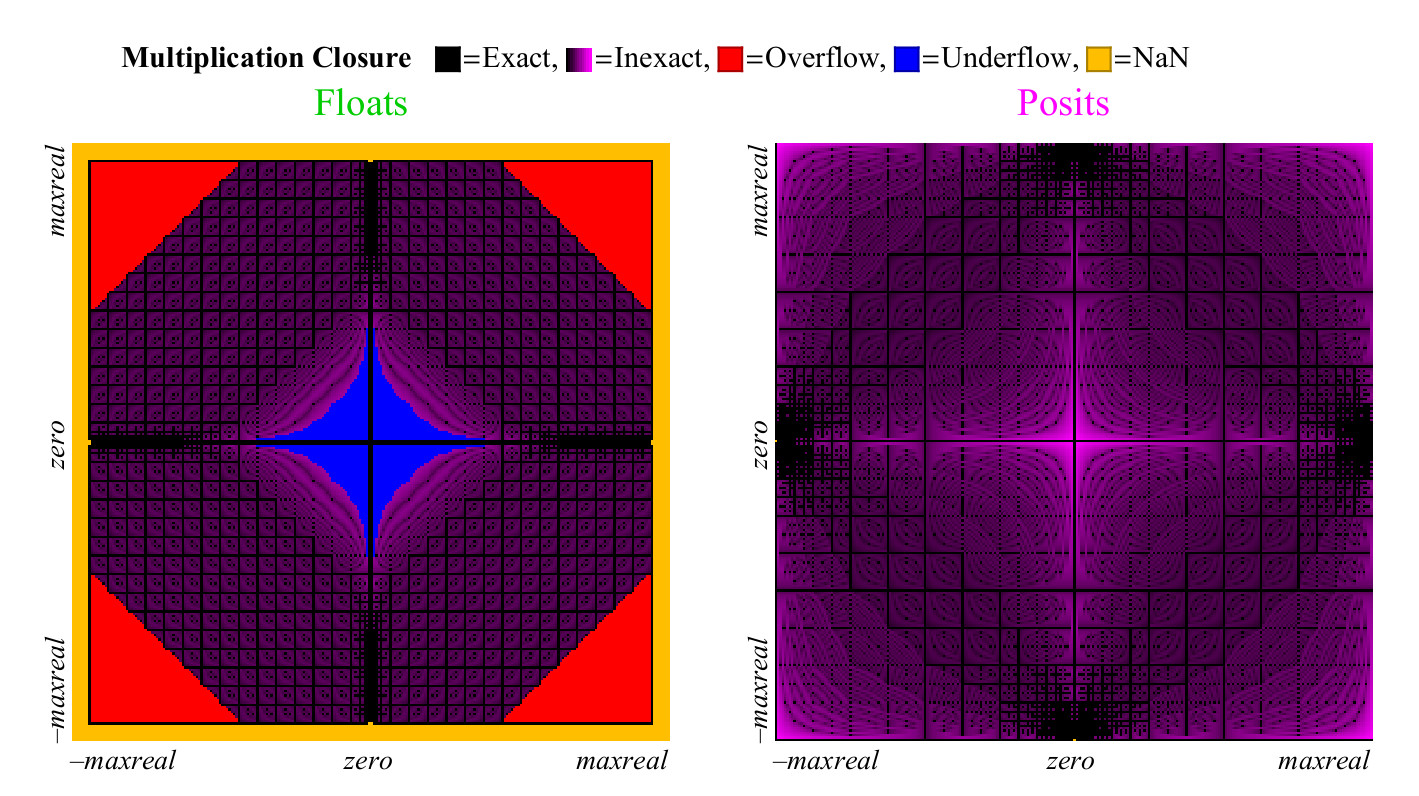
Рис 15. Полный график покрытия для умножения чисел float и posit
Наихудший случай округления для чисел posit наступает при , которое округляется снова до maxpos. Для таких случаев (очень редких) погрешность составлят 3,6 десятичных порядка. Как показываетграфик на рис. 16, числа posit существенно лучше, чем float, минимизируют ошибку умножения.

Рис. 16. Количественное сравнение чисел float и posit для умножения
График покрытия для операции деления похож на график для умножения, но зоны меняются местами, для экономии места, он не приведён здесь. Количественные показатели для деления практически такие же, как для умножения.
4.5. Сравнения чисел float и posit для оценки выражений
4.5.1. Тест “32-битный бюджет точности”
Тесты обычно делаются из расчёта минимального времени выполнения, и часто не дают полного представления, насколько точен результат. Другим типом теста является такой, при котором мы фиксируем бюджет погрешности, то есть число бит на переменную, и попробуем получить максимальную десятичную точность в результате. Вот пример выражения, которые мы можем использовать для сравнения числовых систем с бюджетом 32 бита на число:
Правило состоит в том, что мы начинаем с наилучшего представления чисел и , возможного в каждой из числовых систем, и представлений всех указанных целых чисел, и видим, сколько десятичных цифр совпадают с истинным значением X после выполнения девяти операций в выражении. Мы будем выделять неверные цифры оранжевым цветом.
Несмотря на то, что 32-битные числа IEEE float имеют десятичную точность, которая колеблется в диапазоне от 7.3 до 7.6 десятичных порядков, накопление ошибок округления при вычислении X даёт ответ 302.912?, имеющий всего три верные цифры. Это одна из причин того, что пользователи испытывают необходимость в использовании 64-битных float везде, так как даже простые выражения подвержены риску потери точности так сильно, что результат может оказаться бесполезен.
32-битные числа posit имеют переменную десятичную точность, которая колеблется между 8.2 и 8.5 десятичных порядков для чисел с абсолютным значением около 1. При вычислении X, они дают нам ответ 302.88231?, имеющий вдвое больше значащих цифр. Также не забываем, что 32-битные числа posit имеют динамический диапазон более 144 десятичных разрядов, а 32-битные float имеют гораздо меньший динамический диапазон 83 разряда. Следовательно, дополнительная точность результата достигается не за счёт сужения динамического диапазона.
4.5.2. Тест с четырёхкратной точностью: задача Голдберга о тонком треугольнике
Есть классическая задача о «тонком треугольнике» [1]: найти площадь треугольника со сторонами a, b, c, когда две из сторон b и c всего на 3 единицы младшего разряда (Units in the Last Place, ULPs) длиннее, чем половина длинной стороны (рис. 17).

Рис. 17. Задача Голдберга о тонком треугольнике
Классическая формула для площади A использует промежуточную переменную s:
Опасность в этой формуле заключается в том, что s очень близко к значению a, и вычисление увеличивает погрешность округления очень сильно. Попробуем 128-битные (с четырёхкратной точностью) числа IEEE float, для которых . (Если за единицу измерения принять световой год, то короткая сторона будет длиннее половины длинной стороны всего на 1/200 диаметра протона. Но это делает треугольник высотой с дверной проём у вершины.) Мы также вычисляем значение A, используя 128-битные числа posit (es=7). Ниже приведены результаты:
Числа posit имеют до 1.8 десятичных цифр точности больше по сравнению с float четырёхкратной точности в широком динамическом диапазоне: от до . Этого достаточно для предотвращения катастрофических последствий усиления погрешности в данном конкретном случае. Интересно также отметить, что ответ в формате posit будет более точным, чем в формате float, даже если мы в конце скорвертируем его в 16-битный posit.
4.5.3. Решение квадратного уравнения
Существует классический приём, предназначенный для того, чтобы избежать ошибки округления при вычислении корней , уравнения , используя обычную формулу , когда b намного больше, чем a и c, что приводит к пропаданию цифр слева, так как очень близко к b. Но вместо того, чтобы заставлять программистов запоминать мистические приёмы, возможно, лучше, чтобы posit сделал вычисление безопасным при использовании простой формулы из учебника. Положим и сравним результат в формате 32-битного float и posit.
Таблица 5. Решение квадратного уравнения

Численно неустойчивый корень — , но отметим, что 32-битный posit даёт 6 верных цифр вместо 4-х для float.
4.6. Сравнение систем floats и Posit для классического теста LINPACK
Основным методом оценки суперкомпьютеров долгое время было решение системы линейных уравнений . А именно, тест заполняет матрицу A псевдослучайными числами от 0 до 1, и вектор b суммами строк A. Это означает, что решением x будет вектор, состоящий из единиц. Тест вычисляет норму вычетов для проверки правильности, хотя нет жёстко установленного количества цифр, которые должны быть верными в ответе. Для теста типична потеря нескольких цифр точности, и обычно используются 64-битные float (не обязательно IEEE). Изначально тест предусматривал n=100, но этот размер оказался слишком мал для самых быстрых суперкомпьютеров, поэтому n было увеличено до 300, затем до 1000, и, наконец (с подачи первого автора), тест стал масштабируемым, и выдаёт количество операций в секунду, исходя из того, что тест выполняет операций умножения и сложения.
Сравнивая posit и float, мы отметили небольшой недостаток теста: ответ в общем случае не является последовательностью единиц, из-за ошибок округления сумм в строках. Такая ошибка может быть устранена, если мы найдём, какием вхождения в A вносят в сумму 1 бит, лежащий за пределами возможной точности, и установим этот бит в 0. Это даст нам уверенность, что сумма строки A представима без округления, и что ответ x на самом деле является вектором, состоящим из единиц. Для исходного варианта задачи, с размером 100х100, 64-битные IEEE float дают ответ такого вида:
0.9999999999999633626401873698341660201549530029296875
1.0000000000000011102230246251565404236316680908203125
1.000000000000022648549702353193424642086029052734375
Ни одно из 100 чисел не является верным; они близки к 1, но никогда не равны 1. С числами posit, мы можем сделать замечательную вещь. Использовав 32-битные числа posit и тот же самый алгоритм, вычислим вычет , используя операцию слияния — скалярное произведение. Затем решим (используя уже обработанное ) и используем для коррекции: . Результатом является беспреценднтно точный для теста LINPACK ответ: . Могут ли правила LINPACK запретить использовать новый 32-битный тип чисел, использование которого позволяет достичь совершенного результата с нулевой ошибкой, или продолжат настаивать на использовании 64-битного float, который этого не позволяет? Это решение будут принимать те, кто отвечает за этот тест. Тем же, кому нужно решение систем линейных уравнений для решения реальных задач, а не сравнение скорости суперкомпьютеров, posit предлагает ошеломляющие преимущества.
5. Заключение
Posit побеждает float в его собственной игре: с его помощью можно выполнять вычисления и уменьшать ошибки округления. Числа posit имеют большую точность, больший динамический диапазон и большее покрытие. Они могут использоваться для получения лучших результатов, чем float той же разрядности, или (что может быть ещё большим конкурентным преимуществом), тех же результатов при меньшей разрядности. Так как пропускная способность систем ограничена, использование операндов меньшего размера означает большую скорость и меньшую потребляемую мощность.
Так как они работают как float, а не как интервальная система, они могут рассматриваться как прямая замена float, как и было продемонстрировано здесь. Если алгоритм, использующий float, проходит тесты, и время и стабильность «достаточно хороши», то с posit он будет работать ещё лучше. Комбинированные операции (fused operations), доступные в posit, предоставляют мощное средство для предотвращения накопления ошибок округления, и в некоторых случаях позволяют безопасно использовать 32-битные числа posit вместо 64-битных float в приложениях, требующих высокую производительность. Это в общем случае повысит производительность приложения в 2-4 раза, и сокращает потребляемую мощность, экономит энергию и снижает стоимость хранения данных. Аппаратная поддержка posit даст нам эквивалент одного или двух шагов закона Мура, без необходимости уменьшать размер транзистора или повышать стоимость. В отличие от float, система posit даёт побитовую воспроизводимость результатов на разных системах, избавляя нас от главного недостатка стандарта IEEE 754. Числа posit проще и элегантнее, чем float, и позволяют сократить количество аппаратуры для их поддержки. Хотя числа float сейчас распространены повсеместно, числа posit вскоре могут сделать их устарешими.
Ссылки:
1. David Goldberg. What every computer scientist should know about floating-point arithmetic.
ACM Computing Surveys (CSUR), 23(1):5–48, 1991. DOI: doi:10.1145/103162.103163.
2. John L Gustafson. The End of Error: Unum Computing, volume 24. CRC Press, 2015.
3. John L Gustafson. Beyond Floating Point: Next Generation Computer Arithmetic. Stanford Seminar: https://www.youtube.com/watch?v=aP0Y1uAA-2Y, 2016. full transcription
available at http://www.johngustafson.net/pdfs/DebateTranscription.pdf.
4. John L Gustafson. A radical approach to computation with real numbers. Supercomputing
Frontiers and Innovations, 3(2):38–53, 2016. doi:http://dx.doi.org/10.14529/jsfi160203.
5. John L Gustafson. The Great Debate @ ARITH23. https://www.youtube.com/watch?v=
KEAKYDyUua4, 2016. full transcription available at http://www.johngustafson.net/pdfs/
DebateTranscription.pdf.
6. Ulrich W Kulisch and Willard L Miranker. A new approach to scientific computation, volume 7. Elsevier, 2014.
7. More Sites. IEEE standard for floating-point arithmetic. IEEE Computer Society, 2008.
DOI:10.1109/IEEESTD.2008.4610935.
8. Isaac Yonemoto. https://github.com/interplanetary-robot/SigmoidNumbers
Комментарии (16)

lamerok
16.09.2019 11:20Что-то у меня в голове не складывается. Правильно ли я понял, что мы расширяем динамический диапазон с потерей точности? Т.е. если с флоатом, при расчете мы получим либо значение с той же точностью, либо какую-нить ожидаемую ошибку типа оверфлоу или NAN то с positам мы как ни в чем не бывало продолжим считать дальше, с черт знает какой точностью?

32bit_me Автор
16.09.2019 11:28У posit выше точность в серединке диапазона, то есть для большинства практически значимых случаев. Для чисел с очень большим или очень малым показателем степени точность будет меньше, чем у float. Динамический диапазон также больше, чем у float, за счёт того, что по краям точность будет маленькой.
lamerok
16.09.2019 11:40Ну режим же съедает несколько бит от мантисы, верно? Т.е. по факту, края где точность упадет наступят намного раньше, чем у флоата. А ошибка за этими краями может быть сколь угодно большой.
32bit_me Автор
16.09.2019 11:47По задумке авторов, это должно компенсироваться большей точностью в середине диапазона.

Refridgerator
16.09.2019 11:25+1Просто авторы скромно умолчали о некоторых недостатках своего формата. Подробнее здесь.

trapwalker
16.09.2019 12:51Заинтриговали. Пожалуй подожду тут энтузиаста, который тезисно и с юморком тут всё в двух словах раскидает. А-то у меня так Pocket лопнет.

Pand5461
16.09.2019 14:59Тезисно в двух словах некто Марк Рейнольдс написал:
WARNING: All of the following statements about posits are false:
- You can just treat them like reals and they will give good results.
- They are drop-in-replacements for IEEE.
- All tried-and-true methods will work just as well or better.
lamerok
16.09.2019 15:53Ну тогда уж:
Let’s do some of that (roughly) define stuff shit:
- A well-conditioned problem is one where small changes in input result in small changes in output.
- an ill-conditioned problem is one where small changes in input result in large changes in output.
Что кажется и наблюдается в posit. Я так понял, что применять его можно, например в машинном обучении, но в основном, для измерений и точной науки вообще никак, так как можно напороться на ошибку, которая никак себя не проявит на этапе разработки… и ясно будет только когда ракета уже полетит не туда.32bit_me Автор
16.09.2019 16:14Теоретически, можно сделать так, что выход результата операции за определенный диапазон будет генерировать аппаратное исключение, и обработчик будет выводить необходимую диагностику.
Pand5461
16.09.2019 22:57+2Да нет, обусловленность — это свойство задачи, и устойчивость — это свойство задачи и алгоритма её решения. Густафсон подобрал несколько плохо обусловленных задач и предлагает их решать не очень устойчивыми методами. Но входные данные подобраны так, чтобы там появлялась разность двух близких чисел около 1, где у позитов на 3-4 бита больше.
Одна из проблем позитов в том, что любой из этих примеров умножить на что-то порядка 105 (или 10-5) — и точность позитов посыплется. А у IEEE, если не выходить в переполнение, сколько было значащих бит до масштабирования, столько и останется.
Для научных расчётов, в зависимости от задачи, позиты могут оказаться и лучше, и хуже. Были доклады, где на 16-битных позитах прогноз погоды считали, и даже более-менее адекватно.
Но меня неинвариантность по масштабу напрягает. Это означает, что для каждой решаемой задачи нужно будет подбирать свой масштаб, чтобы там появлялись цифры только около 1. А для сопряжения двух частей задачи нужно будет ещё как-то манипулировать с этими конвертирующими множителями, что у меня сразу в памяти поднимает Mars Climate Orbiter.
Кроме того, будет увлекательная конвертация между физическими единицами. Если, например, мне нужно перевести гигагерцы частоты в сантиметры длины волны для обсчёта какой-нибудь дифракции на препятствиях и в электронвольты энергии для обсчёта поглощения веществом — мне нельзя уже пользоваться фундаментальными константами, они слишком большие/маленькие и потому теряют точность. Мне каждый фактор нужно аккуратно выписать руками. Или иметь отдельные наборы арифметических операторов для флоатов и позитов, чтобы произведение постоянной Планка на скорость света до 8 десятичного знака считать на компьютере, а не на бумажке.

Mirn
17.09.2019 11:49Очень хотелось бы узнать потребление ресурсов FPGA и ASIC на posit в случае если его нормально оптимизировать по скорости или ресурсам.
А так же есть ли готовые либы чтоб можно было быстро сравнить RTL дизайн FPGA просимулировав (обсчитав) его хтябы со скоростью операций умножений с накоплением миллиарда в секунду?
А то находится совсем мало инфы и то что сделано пока что выглядит очень монструозно:
repository.tudelft.nl/islandora/object/uuid:943f302f-7667-4d88-b225-3cd0cd7cf37c/datastream/OBJ/download
на Accumulator (Product) posit<32,2> потребление LUT & REG порядка 2.4к (догадываюсь что это единичный dot product вида «acc+=x*w»)
(взято из Table 4.1)
в другом источнике:
www.eee.hku.hk/~hso/Publications/jaiswal_date_2018.pdf
fig.2 — числа аналогичного порядка, около 2.4к
у FPGA среднего ценового диапазона есть внутри порядка 1-2к классических DSP блоков
и около одного миллиона REG&LUT при этом 100% использоваться нельзя, приближаясь к 100% скорость (Fmax) ОЧЕНЬ сильно проседает, поэтому для примера возьмём 750к,
т.е. это 300 эквивалентных DSP. И они работают на скоростях 100-125МГц.
Более того если даже у бюджетных старых FPGA типа Cyclone V есть варианты под 600 дсп блоков с частотой в 250мгц. А дсп блоки из fpga статей вообще реально запустить на 300 (хотя официально 480 и выше, но у меня столько терпения не хватало да и дедлайн он обычно существует).
Вывод: для FPGA они существенно дороже по ресурсам, скорости в разы ниже уже имеющихся DSP блоков.
В случае ASIC: для posit чисел нужен очень комплексный и многоуровневый barrel-shifter и/или мультиплексор, есть подозрения что они и в этом случае тоже будут существенно дороже floatpoint классических. А по скорости я даже в ASIC флоаты не реализовывал — опыта нет, судить не имею права.
Жаль источников всего несколько и нормальный мета анализ по статьям не провести и поэтому мои выводы трудно назвать качественными и более глубокие выводы бессмыслено делать.
От себя могу добавить мой скромный частный случай из моей практики:если грамотно и качественно квантизировать нейросеть с 32битных флоатов до 16 бит с 32битным аккумулятором то погрешность практически не изменится, а благодоря 32битному аккумулятору скалярное умножение двух векторов в pointwise на таком fixedpoint получается даже точнее флоата т.е. у него 31битная мантисса.
posit имеет очень большой смысл применять для заметного сжатия памяти чтоб вся память используемая сеткой влезла в FPGA целиком и тогда можно получать сотни и тыщи FPS c latency меньше миллисекунды и даже сотен микросекунд (это ключевые и критические требования тз для индустрии и вооружений в нашей компании). Но и тут например если взять 16битную fixedpoint MobileNetv2 которая очень критична к квантизации и сложно ужать до 8 бит. То всё равно многие промежуточные буфера я смог сжать с 16 до 6 бит с потерей всего 0.5% точности простыми способами используемыми уже 30-40 лет в цифровой телефонии и потребляющие десятки LUT но не ТЫЩИ!!! как в случае с posit.
И вообще самая главная проблема не в точности а в скорости и объёме памяти: переход от DDR4 на HBM2 память даёт ускорение с пары сотен FPS до тысячь а в ряде случаев до десятков тысячь FPS потому что ВЕСЬ конвеер нейросети влазит в память и не нужно подгружать ничего динамически ради каждого кадра.
aamonster
Тесты не от создателей формата есть?
А то "в некоторых случаях позволяют безопасно использовать 32-битные числа posit вместо 64-битных float" – явно требует звёздочки и расшифровки "на практике вы не столкнётесь с этими случаями". Про сравнение на 8-битной модели я вообще молчу.
Ну то есть я верю, что формат может быть лучше текущего стандарта, но в текущем не вижу такого уж огромного "запаса прочности" (кроме как для конкретных случаев, где он избыточен – и порой может быть заменён просто на fixed point). И интересно знать, стоит ли овчинка выделки (впрочем, пока с этим не определятся производители процессоров – это не так уж важно)
Refridgerator
Есть, например отсюда:
Here are a few extreme examples of inexact multiplications by2 or 0.5 in Posit8 (similar example can be found in Posit16 andPosit32):
1.03125 * 2.0 returns 2.0
10.0 * 2.0 returns 16.0
64.0 * 2.0 returns 64.0
0.015625 * 0.5 returns 0.015625
0.984375 * 0.5 returns 0.5
amarao
На самом деле легко понять, что у posit есть ощутимое преимущество из-за того, что огромная площадь (на квадрате декартова произведения области определения бинарной операции) отдана nan'ам. Т.е. в общем случае, бинарная плотность posit выше. Дальше, там очевидно, уже чуть-чуть вкусовщины на тему "что более важно представлять", но снижение числа потерянных значений — это безусловный и резкий плюс.
Плавная кривая нарастания погрешности мне тоже кажется разумной идеей.
Pand5461
Это у 8-битных float, которых нет в IEEE 754, много NaN. Доля NaN — очевидно, 1/2число бит порядка, т.к. у NaN все биты порядка единичные.
Плавная кривая нарастания погрешности — ужасно. Хотите умножить ~106 на ~10-6 — пожалуйста, ответ даже будет иметь много бит в мантиссе. Только младшие биты будут мусором, т.к. в сомножителях нет столько бит мантиссы.
aamonster
Вы не по области определения сравнивайте, а по напрасно израсходованным битам (ну или по логарифму от числа "плохих" значений). Разница сразу окажется не такой большой.