Почему мы вообще хотим писать конкурентный код? Потому что процессоры перестали расти по герцовке и начали расти по ядрам. С каждым годом увеличивается количество ядер процессора, и мы хотим их эффективно утилизировать. Go — тот язык, который создан для этого. В документации так и написано.
Мы берём Go, начинаем писать конкурентный код. Конечно, ожидаем, что легко сможем обуздать мощь каждого ядра нашего процессора. Так ли это?
Меня зовут Артемий. Этот пост — вольная расшифровка моего доклада с GopherCon Russia. Он появился как попытка дать толчок людям, которые хотят разобраться, как писать хороший, конкурентный код.
Видео с конференции GopherCon Russia
Модели взаимодействия
Чтобы понять, действительно ли Go облегчит нам задачу, давайте рассмотрим две модели взаимодействия: Shared Memory и Message Passing.

Shared Memory — это про разделяемую память, которую несколько потоков используют, чтобы обмениваться данными. Доступ к памяти нужно синхронизировать. Эта синхронизация обычно реализуется какими-то блокировками. Такой подход считается неявной коммуникацией.
Message Passing говорит о том, что мы будем взаимодействовать явно, и для этого использовать каналы, в которых будем отправлять сообщения. На этом подходе основаны CSP (Communicating Sequential Processes) и Actor Model.

Роб Пайк, который является отцом-основателем языка Go, говорит о том, что, нужно отказаться от низкоуровневого программирования с использованием Shared Memory и использовать подход Message Passing. Такой подход поможет писать код проще, эффективнее и, самое главное, с меньшим количеством багов. Go выбирает для себя подход CSP. Этот же подход сильно повлиял на становление такого языка как Erlang.
Вопрос: действительно ли, если мы возьмем Go, всё станет хорошо?

Я наткнулся на исследование, в котором была найдена эта табличка. Табличка показывает причины и количество багов связанных с блокировками. В первом столбце показаны продукты, которые были взяты в исследование. Это наиболее популярные продукты, написанные на языке Go. Столбец Shared Memory показывает количество багов, возникающих по причине неправильного использования Shared Memory, а столбец Message Passing, соответственно, показывает количество багов по причине Message Passing.
Самое главное в этой табличке — это строка Total. Если на неё посмотреть, то можно заметить, что багов при использовании Message Passing, даже больше, чем при использовании Shared Memory. Уверен, люди, которые пишут Kubernetes, Docker или etcd — достаточно опытные разработчики, но даже их Message Passing не спасает от ошибок, причем этих ошибок не меньше, чем с Shared Memory.
Так что просто взять Go и начать писать безошибочный код не получится.
Concurrency и Parallelism
Когда мы начинаем говорить о многопоточной разработке, нужно ввести такие понятия, как Concurrency и Parallelism. В мире Go есть выражение «Concurrency is not Parallelism». Суть в том, что Concurrency — это о дизайне, то есть о том, как мы проектируем нашу программу. Parallelism — это просто способ выполнения нашего кода.

Если у нас есть несколько потоков инструкций, которые выполняются одновременно, тогда мы выполняем код параллельно. Parallelism требует конкурентности. Без конкурентного дизайна распараллелить программу не получится, при этом конкурентность не требует параллелизма, потому что программа, которая может работать на многих ядрах, на самом деле, может работать и на одном ядре.
Go — это язык, который помогает нам писать конкурентные программы, помогает нам строить дизайн. Он позволяет чуть-чуть меньше задумываться о низкоуровневых вещах.
Закон Амдала
Мы хотим утилизировать ядра процессора, пишем для этого какой-то код. Но возникает вопрос: а какое увеличение производительности мы получим при увеличении количества ядер. Так вот, то ускорение, которое мы можем получить, оно, на самом деле, ограничено законом Амдала.
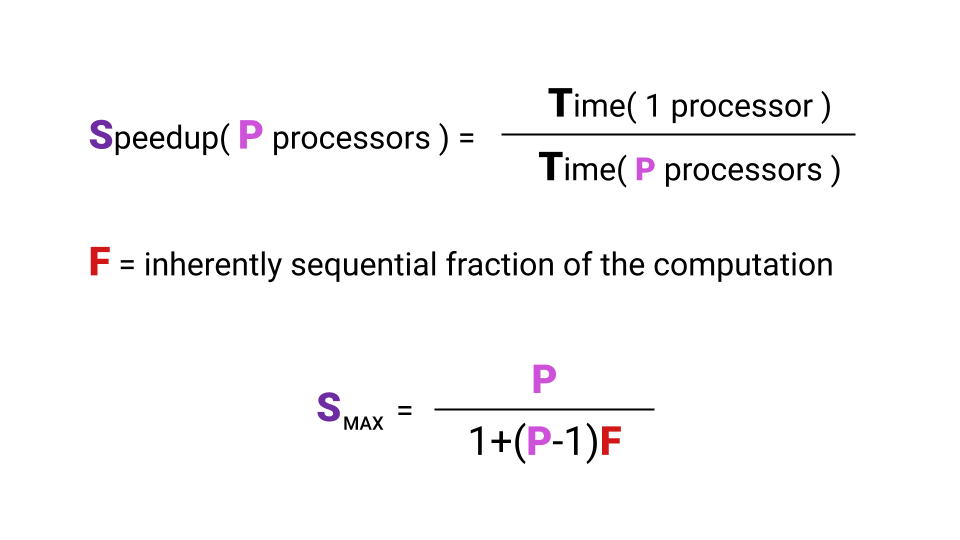
Что такое ускорение? Ускорение — это время, которое программа выполняется на одном процессоре, деленное на время, которое программа выполняется на Р процессорах. Буквой F (Fraction) обозначим ту часть программы, которая обязана выполниться последовательно. И тут даже не обязательно вникать в формулу, главное заметить, что от F сильно зависит максимальное ускорение, которое мы получим с увеличением количества ядер. Взгляните на график, чтобы визуально представить эту зависимость.
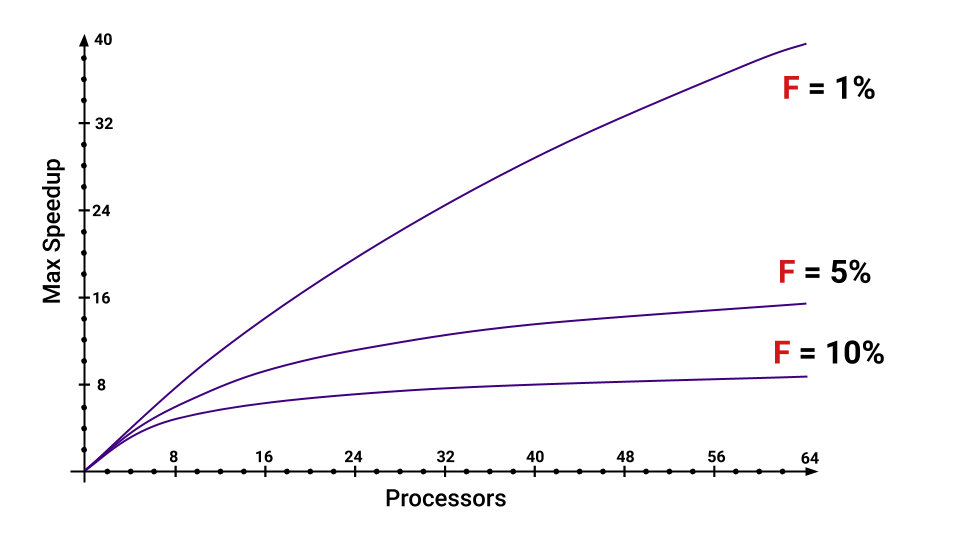
Даже если у нас всего лишь 5% программы должно выполняться последовательно, то сильно уменьшается максимальное ускорение, которое мы получим, с увеличением количества ядер. Можно прикинуть, какие есть части, увеличивающие F.
CPU Bound vs I/O Bound
Не всегда имеет смысл использовать многопоточность. Сначала нужно взглянуть на тип нагрузки. Есть два типа нагрузки: CPU Bound и I/O Bound. Разница в том, что при CPU Bound мы ограничены производительностью процессора, а при нагрузке I/O Bound мы ограничены скоростью работы нашей I/O-подсистемы. Даже не скоростью, а временем ожидания ответа. Поход в сеть — ждем ответа, поход на диск — опять ждем ответа. Какая разница, сколько имеется ядер, если большую часть времени мы ждём ответа?
Поэтому одно ядро или тысяча, увеличения производительности при I/O Bound нагрузке мы не получим. Но если у нас нагрузка CPU Bound, то есть шанс получить ускорение при распараллеливании нашей программы.
Хотя бывают ситуации, когда кажущаяся нам CPU Bound нагрузка, на самом деле вырождается в I/O Bound. Если мы, например, хотим взять и просуммировать все элементы большого массива, что мы сделаем? Мы напишем цикл, все будет работать. Потом мы подумаем: «Так у нас же куча ядер. Давайте просто возьмем, на чанки массив разделим и распараллелим все это дело». Что получится в итоге?
В итоге получается ситуация, когда наш процессор обрабатывает данные быстрее, чем они успевают приходить из памяти. В этом случае большую часть времени мы будем ждать данные из памяти, и нагрузка, которая казалась CPU Bound, на самом деле оказывается I/O Bound.
False Sharing
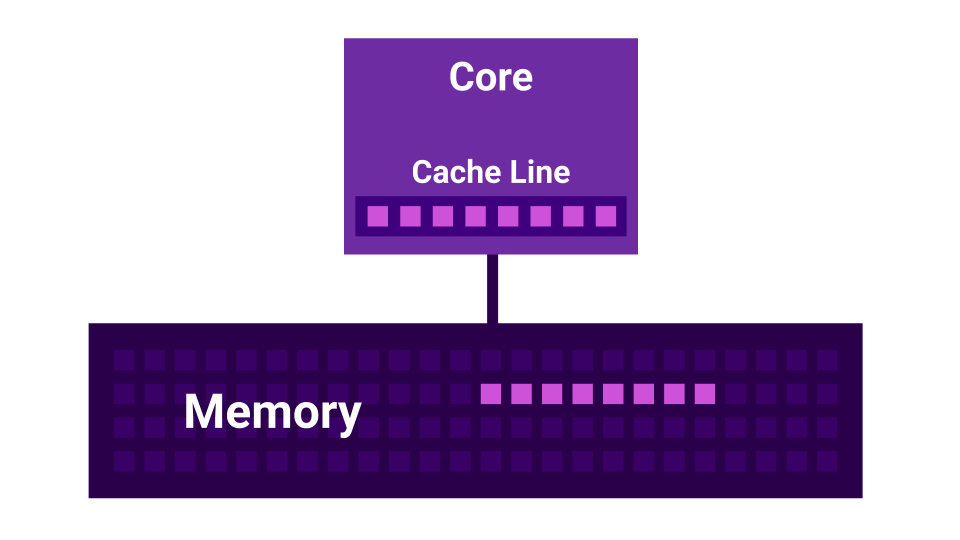
Более того, существует такая история, как False Sharing. False Sharing — это ситуация, когда ядра начинают мешать друг другу. Есть первое ядро, есть второе ядро, и у каждого из них есть свой L1 Cache. L1 Cache поделён на линии (Cache Line) по 64 байта. Когда мы получаем какие-то данные из памяти, мы всегда получаем не меньше, чем 64 байта. Изменяя эти данные, мы инвалидируем кэши всех ядер.

Получается, что если два ядра меняют очень близкие друг к другу данные (на расстоянии меньше 64-х байт), они начинают друг другу мешать, инвалидируя кэши. В этом случае, если бы программа была написана последовательно, она работала бы быстрее, чем при использовании нескольких ядер, которые друг другу мешают. Чем больше ядер, тем меньшая производительность получится.
Schedulers
Будем подниматься на следующий уровень абстракции — к планировщикам.
Когда начинается работа с конкурентным кодом, появляются планировщики. В Go есть так называемый user-space scheduler, который оперирует горутинами. В операционной системе тоже есть свой scheduler, который оперирует потоками операционной системы. И даже в процессоре не всё так просто. Например, в современных процессорах есть branch prediction и другие способы испортить нашу красивую картину линеаризуемости мира.
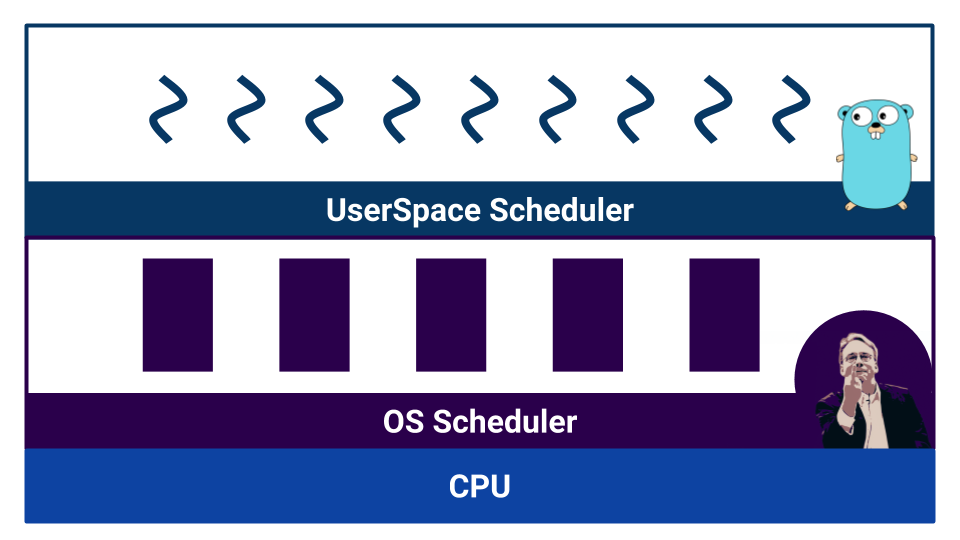
Планировщики разделяют по типу многозадачности. Существует кооперативная многозадачность (cooperative multitasking) и вытесняющая многозадачность (preemptive multitasking). В случае кооперативной многозадачности у нас выполняющийся процесс сам решает, когда ему нужно передать управление другому процессу, а в случае вытесняющей многозадачности есть внешний компонент — scheduler, который контролирует, сколько ресурса процессу отведено.

Кооперативная многозадачность позволяет одному процессу «монополизировать» весь ресурс CPU. В вытесняющей многозадачности такого не произойдет, потому что есть контролирующий орган. Зато при кооперативной многозадачности переключение контекста происходит более эффективно, ведь процесс точно знает, в какой момент лучше отдать управление другому процессу. В вытесняющей многозадачности scheduler может остановить процесс в любой момент — это не очень эффективно. При этом в вытесняющей многозадачности мы можем обеспечить одинаковый ресурс каждому процессу благодаря внешнему планировщику.
В операционной системе используется планировщик на основе вытесняющей многозадачности, так как ОС обязана гарантировать каждому пользователю равные условия. А как обстоят дела в Go?
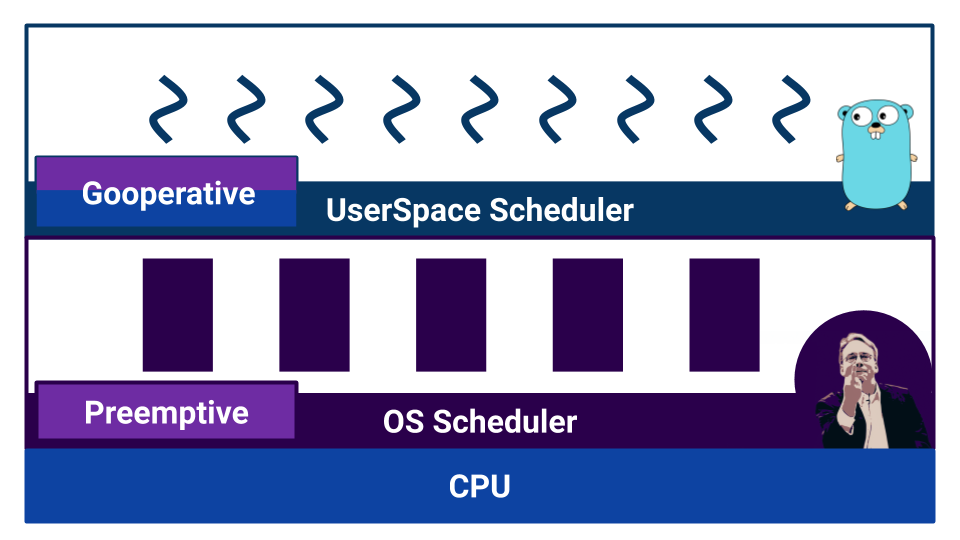
Если почитать документацию, мы узнаем, что планировщик в Go — вытесняющий. Но, когда начинаем разбираться, оказывается, что в Go нет планировщика как внешнего компонента. В Go компилятор расставляет точки переключения контекста. И хотя нам, как разработчикам, нет необходимости руками переключать контекст — контроль за переключением не выносится во внешний компонент. Благодаря этому в Go очень эффективно происходит переключение одной горутины на другую. Но непонимание особенностей работы такого «планировщика» может привести к неожиданному поведению. Например, что выведет вот такой код?

Такой код зависнет.
Почему? Потому что сначала, используя GOMAXPROCS, мы заставили программу использовать только одно ядро. После этого, в очередь поставили горутину, внутри которой должен работать бесконечный цикл. Дальше ждём 500 мс и выводим x. После time.Sleep горутина действительно запустится, но выхода из бесконечного цикла уже не будет, потому что компилятор не поставит точку переключения контекста. Программа зависнет.
А если внутри цикла добавим runtime.Gosched(), то все будет хорошо, потому что так мы явно укажем, что хотим переключить контекст.
Такие особенности тоже нужно знать и помнить.
Мы говорили о переключении контекста, а куда Go обычно вставляет точки переключения?

runtime.morestack() и runtime.newstack() обычно вставляются в момент, когда у нас происходит вызов функции. runtime.Goshed() мы можем поставить сами. Ну и конечно, переключение контекста происходит при блокировках, походах в сеть и системных вызовах. Можно посмотреть на эту тему доклад Кирилла Лашкевича. Очень хороший, советую.
Давайте подниматься дальше, ближе к коду. Будем смотреть на ошибки.
Race Condition
Одна из самых популярных ошибок, которую мы допускаем, — это Race Condition. Суть в том, что когда мы делаем, например, инкремент, на самом деле мы делаем не одну операцию, а несколько: процессор читает данные из памяти в регистр, обновляет регистр и пишет данные в память.

Эти три операции выполняются не атомарно. Поэтому планировщик в любой момент времени, на любой из этих операций, может взять и вытеснить наш поток. Получится, что действие не закончено, и мы из-за этого ловим баги.
Вот пример такого кода (инкремент сразу разложен на несколько операций).

Планировщик может вытеснить первый поток после выполнения первой строки, а второй поток уже после проверки условия. В таком случае оба потока попадут в критическую секцию, а она потому и «критическая» — обоим потокам одновременно туда попадать нельзя.
Мы можем поставить блокировку, используя sync.Mutex из стандартного пакета sync. Блокировка доступа позволяет нам явно указать, что код должен выполняться одним потоком единовременно. С таким кодом мы получим то, что нам необходимо.

Блокировки — это достаточно дорогая операция. Поэтому существуют атомарные операции на уровне процессора. В данном случае инкремент можно сделать атомарным, заменив его на операцию atomic.AddInt64 из пакета atomic.
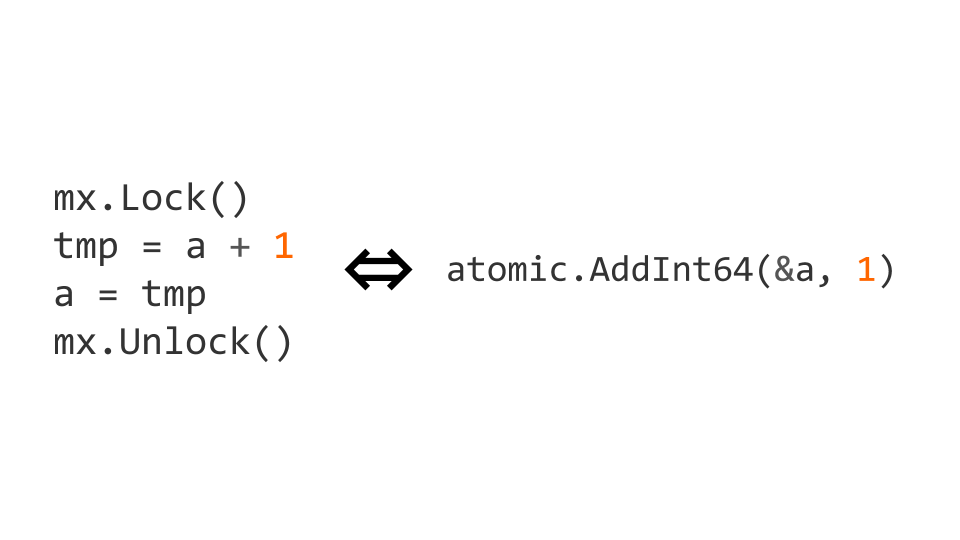
Если мы начинаем работать с атомарными инструкциями, то нам нужно не только писать атомарно, но и читать тоже атомарно. Если мы это не делаем, то могут возникнуть проблемы.
Оптимизации — What Could Possibly Go Wrong?
Блокировки — это хорошо, но может быть дорого. Атомики — это достаточно дешево, чтобы не переживать о производительности.
Вот мы узнали, что примитивы синхронизации привносят оверхед, и решили добавить оптимизацию — будем проверять флаг без оглядки на многопоточность, а потом перепроверять, используя примитивы синхронизации. Все выглядит нормально и должно работать.

Всё хорошо, кроме того, что компилятор пытается оптимизировать наш код. Что он делает? Он меняет местами инструкции присваивания, и мы получаем не валидное поведение, потому что у нас done становится true до того, как происходит присваивание значения переменной «а».
Не пытайтесь делать таких оптимизации — из-за них вы получите большое количество проблем. Советую почитать спецификацию The Go Memory Model и статью от Дмитрия Вьюкова (@dvyukov) Benign Data Races: What Could Possibly Go Wrong?, чтобы лучше разобраться в проблематике.
Если вы действительно упираетесь в производительность на блокировках — пишите lock-free код, но делать не синхронизируемый доступ к памяти не нужно.
Deadlock
Следующая проблема, с которой мы столкнемся, — это Deadlock. Может показаться, что тут все достаточно тривиально. Есть два ресурса, например, два Mutex. В первом потоке мы сначала захватим первый Mutex, а во втором потоке мы сначала захватим второй Mutex. Дальше мы захотим в первом потоке взять второй Mutex, но сделать этого не сможем, потому что он уже заблокирован. Во втором потоке мы попытаемся взять, соответственно, первый Mutex и тоже заблокируемся. Вот он, Deadlock.
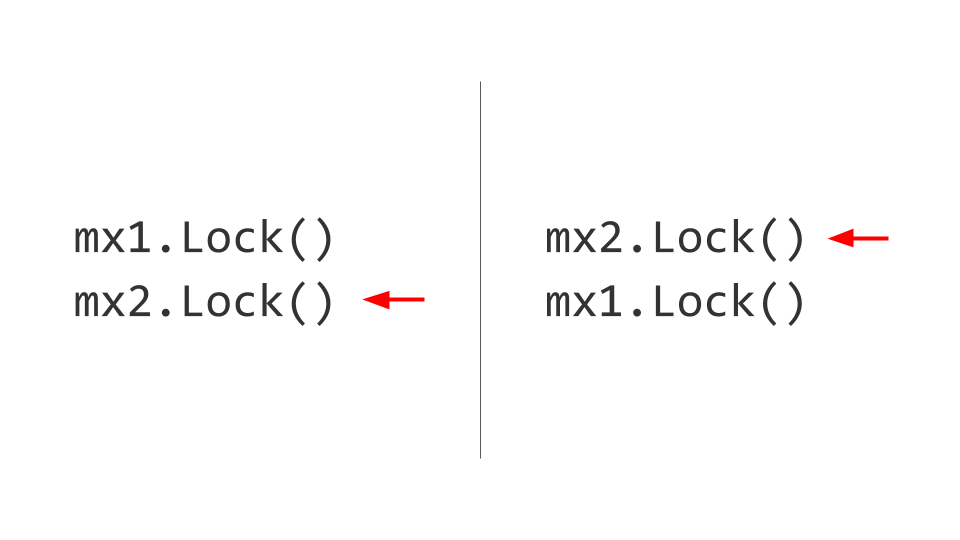
Никто из этих двух потоков не сможет дальше прогрессировать, потому что оба они будут ждать ресурса. Как это решается? Меняем местами взятие блокировок, и тогда никаких проблем не возникает. Конечно, легко сказать, но поддерживать это правило всё время жизни продукта не просто. Если возможно, делайте это — берите и отдавайте блокировки в одинаковом порядке.
Может показаться, что опытные разработчики не сталкиваются с такими ошибками, но вот пример deadlock'а из кода проекта etcd.

Тут основная загвоздка в том, что запись в небуферизированный канал — блокирующая, чтобы записать, нужен читатель с другой стороны. Взяв мьютекс, первый поток ждёт появление читателя. Второй поток уже не может захватить мьютекс. Deadlock.
Советую попробовать захватывающую игру The Deadlock Empire. В этой игре вы выступаете в роли планировщика, который должен переключать контекст так, чтобы помешать коду выполниться корректно.
Sort of Problems
Какие проблемы еще существуют? Мы начали с Race Conditions. Дальше мы взглянули на Deadlock (существует ещё его разновидность Livelock, это когда мы не можем захватить ресурс, но явных блокировок не происходит). Есть Starvation, это когда мы идем к принтеру распечатать бумажку, а там очередь, и мы не можем получить доступ к ресурсу. Мы взглянули на поведение программы при False Sharing. Ещё существует проблема — Lock Contention, когда производительность деградирует по причине большой конкуренции за ресурс (например, один мьютекс, который нужен большому количеству потоков).

Race Detection
Go силен набором инструментов, предоставляемых «из коробки». Race Detector — это один из таких инструментов. Использовать его просто: мы пишем тесты или запускаем его на боевой нагрузке и ловим ошибки.
Про использование Race Detector можно подробнее почитать в документации, но надо помнить, что у него есть ограничения. Остановимся на них подробнее.

Во-первых, тот код, который не был выполнен, Race Detector'ом не проверяется. Поэтому покрытие тестами должно быть высоким. Кроме того, Race Detector запоминает историю обращений к каждому слову в памяти, но эта история обращений имеет глубину. В Go, например, эта глубина равна четырём — четыре элемента, четыре доступа. Если в рамках этой глубины Race Detector не поймал гонку, он считает, что гонки нет. Поэтому, хотя Race Detector никогда не ошибается, он поймает не все ошибки. Надеяться на Race Detector можно, но нужно помнить об его ограничениях. Отдельно можно почитать про алгоритм работы.
Block Profile
Block profile — еще один инструмент, который позволяет нам находить и исправлять проблемы с блокировками.

Его можно использовать как на уровне бенчмарк-тестов, так и смотреть при боевой нагрузке. Поэтому если вы ищете проблемы, связанные с синхронизацией доступа к данным, попытайтесь начать с Race Detector и продолжить использование Block Profile.
Пример программы
Давайте рассмотрим реальный код, на котором мы можем споткнуться. Напишем функцию, которая просто берет массив запросов и пытается их выполнить: последовательно каждый запрос. Если какой-то из запросов возвращает ошибку, функция завершает выполнение.

Если мы пишем на Go, надо использовать всю мощь языка. Пробуем. Получаем в три раза больше кода.

Вопрос: есть ли в коде ошибки?
Конечно! Давайте рассмотрим какие.
В цикле мы запускаем горутины. Для оркестрации горутин используем sync.WaitGroup. Но что мы делаем неправильно? Уже внутри запущенной горутины мы вызываем wg.Add(1), т.е добавляем для ожидания еще одну горутину. А используя wg.Wait(), мы ждем выполнения всех горутин. Но может случиться так, что к моменту вызова wg.Wait() еще ни одна горутина не запустится. В этом случае wg.Wait() посчитает, что всё выполнено, мы закроем канал и выйдем из функции без ошибок, считая, что всё хорошо.

Что произойдет дальше? Дальше горутины запустятся, код выполнится, и, возможно, один из запросов вернёт ошибку. Ошибка запишется в закрытый канал, а запись в закрытый канал — это паника. Наше приложение упадёт. Вряд ли это то, что хотелось получить, поэтому исправляем, заранее указав, сколько горутин мы запустим.

Может быть, ещё какие-то проблемы есть?
Есть ошибка, связанная с тем, как объект req оказывается внутри функции. Переменная req выступает в роли итератора цикла и мы не знаем, какое значение она будет иметь в момент запуска горутины.

На практике в таком коде значение req будет, скорее всего, равно последнему элементу массива. Поэтому вы просто N раз отправите один и тот же запрос. Исправляем: явно передаем наш request как аргумент функции.

Давайте подробнее посмотрим на то, как мы обрабатываем ошибки. Мы объявляем буферизованный канал на один слот. Когда происходит ошибка, мы в этот канал её отправляем. Вроде все хорошо: у нас произошла ошибка — вернули эту ошибку из функции.

А что, если все запросы вернутся с ошибкой?
Тогда записать в канал получится только первую ошибку, остальные заблокируют выполнение горутины. Так как к моменту выхода из функции чтений из канала больше не будет, получаем утечку горутин. То есть все те горутины, которые не смогли записать ошибку в канал, просто повиснут в памяти.
Исправляем очень просто: выделяем в канале слотов по количеству запросов. Это решает нашу проблему не очень эффективно по памяти, потому что, если у нас миллиард запросов, то нужно выделить миллиард слотов.

Проблемы мы решили. Код теперь конкурентен. Но с читаемостью беда — по сравнению с синхронной версией кода стало много. И это не круто, потому что разработка конкурентных программ — это и так сложно, зачем нам её усложнять большим количеством кода?

Errgroup
Предлагаю повысить читаемость кода.
Мне нравится использовать пакет errgroup вместо sync.WaitGroup. Этот пакет не требует указывать, какое количество горутин ждать, и позволяет абстрагироваться от сбора ошибок. Вот так будет выглядеть наша функция при использовании errgroup:

Более того, errgroup позволяет удобно оркестрировать компоненты нашей программы, используя context.Context. Что я имею ввиду?
Пусть у нас есть несколько компонентов нашей программы, при ошибке хотя бы в одном из них мы хотим аккуратно завершить все остальные. Так вот errgroup при появлении ошибки завершит context и, таким образом, все компоненты получат уведомление о необходимости завершить работу.

На этом можно строить сложные многокомпонентные программы, которые ведут себя предсказуемо.
Выводы
Делайте максимально просто. Лучше синхронно. Разработка многопоточных программ — это вообще сложный процесс, приводящий к появлению неприятных багов.

Не используйте неявной синхронизации. Если вы действительно упёрлись именно в неё, думайте как избавиться от блокировок, как сделать lock-free алгоритм.
Go — это хороший язык для того, чтобы писать программы, которые эффективно работают с большим количеством ядер, но он ничем не лучше, чем все остальные языки, и ошибки всегда будут появляться. Поэтому даже вооружившись Go, старайтесь понимать на несколько уровней абстракций ниже, чем работаете.

Комментарии (15)

gecube
18.09.2019 15:55+3Отличная статья с обзором типовых ошибок.
В очередной раз подтверждается тезис, что независимо от языка нужно писать аккуратно и вдумчиво. И покрывать код тестами.
Ну, и голанг — не серебряная пуля, как некоторые фанаты утверждают.

kuznetsovin
19.09.2019 10:54+2Go выбирает для себя подход CSP. Этот же подход используется, например, в таком языке, как Erlang.
У erlang модель акторов а не csp
Flaker Автор
19.09.2019 12:08Да, вы правы, сейчас это так. Хотел скорее написать, что на становление Erlang сильно оказала влияние теория Хоаровского CSP, и практическая реализация Smalltalk и Prolog.
Robert Virding (один из отцов Erlang) про это написал так: "Actually we had never heard of the actor model, not before ppl told us we had implemented it" (https://twitter.com/rvirding/status/766242280592277504)
Более подробное обсуждение можно вот тут почитать: elixirforum.com/t/does-earlier-erlang-concurrency-model-stem-from-csp/16905
Спасибо за ваше замечание, я поправлю текст!)

AlexeySoshin
24.09.2019 11:04Основная проблема с решениями вроде
errgroupи прочими заключается в том, что в Go все эти библиотеки — second class citizens.TonyLorencio
24.09.2019 11:25С точки зрения языка нет же никакой разницы между стандартной библиотекой и внешними пакетами. Или речь не об этом?
AlexeySoshin
24.09.2019 11:44go statement— часть языка, а не стандартной библиотеки. Будь это частью библиотеки, как в том же Kotlin, проблем было бы меньше. Но по факту, приходится городить всякиеg.Go(func()), которые не равныgo func()
kalterdev
24.09.2019 11:55Проблема не в инструменте, а отказе думать. Чтобы написать хорошо, нужно выбрать подходящий подход.
Если мы пишем на Go, надо использовать всю мощь языка. Пробуем. Получаем в три раза больше кода.
И показываете пример мощи WaitGroup. Вы незаметно отождествили "мощь Go" и "мощь WaitGroup".
Если утилита синхронизации неудобная, нужно выбрать подходящую. Go не сделает выбор за программиста.
kalterdev
24.09.2019 12:38-1В последнем примере последовательный код решает одну задачу – выполнение запросов, – а конкуретный две – выполнение запросов и их оркестрация. Поэтому конкурентный вариант выглядит справедливо сложнее последовательного.
Если оставить оркестрацию на ответственность вызывающего, код станет проще:
func call(ctx context.Context, requests <-chan Request, errors chan<- error) { for r := range requests { go func(r Request) { if e := send(ctx, r); e != nil { errors <- e } }(r) } }kalterdev
24.09.2019 14:54Я ошибся в том, что в моём коде вызывающий может оркестрировать выполнение запросов (не может, хотя это можно доработать), но главное утверждение всё ещё верно: в примере конкурентный код сложнее, потому что выполняет две задачи – отправку запросов и оркестрирование, – и если не делать оркестрирование, то последовательный и конкурентный код будут не особо отличаться как по объёму, так и по размеру.
korjavin
Про то что не вытеснит горутину с for {x++;} — интересно.
QtRoS
А как Вы думали оно реализовано? В случайных местах в коде вставлены проверки? :)
В Go вообще не так уж и много происходит за кадром, ассемблер на выходе получается без сюрпризов, отсюда и вывод напрашивающийся, что переключение контекста происходит в особенные моменты в рантайме.
korjavin
Да милионом способов реализовать можно.
meduza
Flaker, эх… такой вопрос классный был на собеседованиях) придётся теперь замену искать)